
Snowflake 전송 예약
BigQuery Data Transfer Service에서 제공하는 Snowflake 커넥터를 사용하면 공개 IP 허용 목록을 사용하여 Snowflake에서 BigQuery로 데이터를 마이그레이션하는 자동 전송 작업을 예약하고 관리할 수 있습니다.
개요
Snowflake 커넥터는 Google Kubernetes Engine의 마이그레이션 에이전트와 연결되어 Snowflake에서 Cloud Storage 버킷 내 스테이징 영역으로의 로드 작업을 트리거합니다.
- Amazon Web Services (AWS) 또는 Azure 또는 Google Cloud호스팅 Snowflake 계정의 경우 데이터가 먼저 Cloud Storage 버킷에 스테이징된 후 BigQuery Data Transfer Service를 통해 BigQuery로 전송됩니다.
다음 다이어그램은 Amazon Web Services (AWS) 또는 Azure에서 호스팅되는 Snowflake 계정 또는 Google Cloud에서 호스팅되는 Snowflake 계정에서 공개 데이터 전송을 보여줍니다.
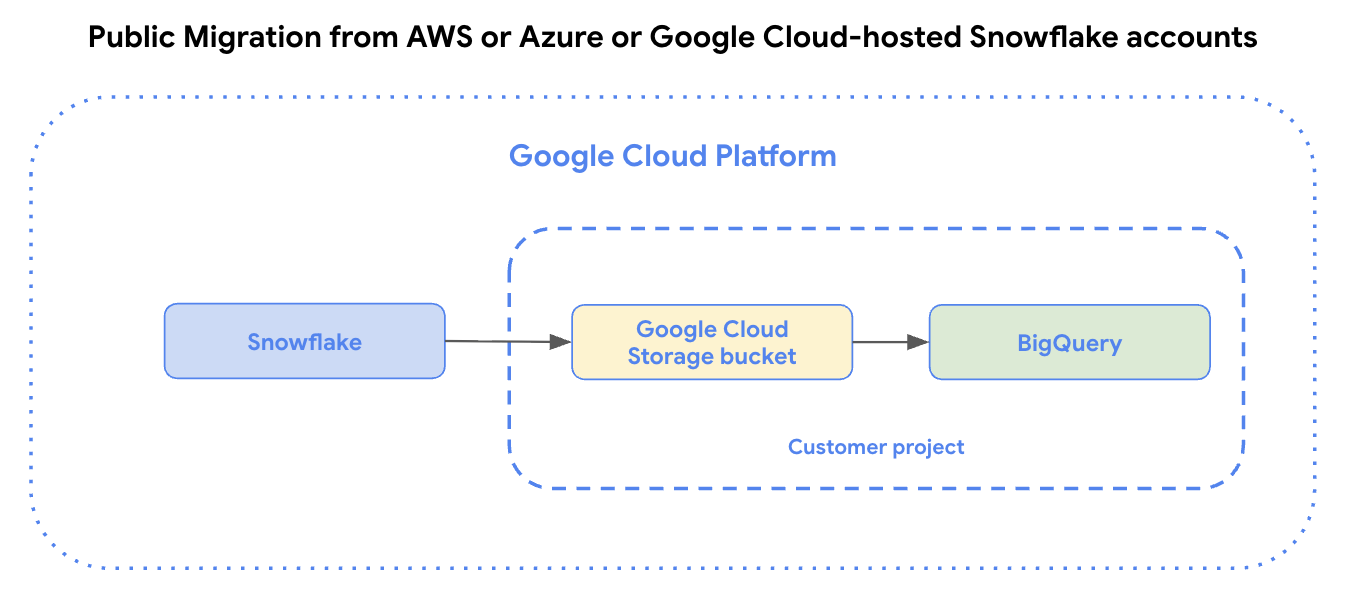
제한사항
Snowflake 커넥터를 사용하여 데이터를 전송할 때는 다음과 같은 제한사항이 적용됩니다.
- Snowflake 커넥터는 단일 Snowflake 데이터베이스 및 스키마 내 테이블에서만 전송을 지원합니다. Snowflake 데이터베이스 또는 스키마가 여러 개 있는 테이블에서 전송하려면 각 전송 작업을 별도로 설정하면 됩니다.
- Snowflake에서 Amazon S3 버킷, Azure Blob Storage 컨테이너 또는 Cloud Storage 버킷으로 데이터를 로드하는 속도는 이 전송에 선택한 Snowflake 웨어하우스에 따라 제한됩니다.
- BigQuery는 Snowflake의 데이터를 Cloud Storage에 Parquet 파일로 씁니다. Parquet 파일은
TIMESTAMP_TZ및TIMESTAMP_LTZ데이터 유형을 지원하지 않습니다. 데이터에 이러한 유형이 포함되어 있으면 CSV 파일로 Amazon S3에 내보낸 후 CSV 파일을 BigQuery로 가져올 수 있습니다. 자세한 내용은 Amazon S3 전송 개요를 참조하세요.
시작하기 전에
Snowflake 전송을 설정하기 전에 이 섹션에 나와 있는 모든 단계를 수행해야 합니다. 다음은 필요한 모든 단계의 목록입니다.
- Google Cloud 프로젝트 준비
- 필요한 BigQuery 역할
- 스테이징 버킷 준비하기
- 필요한 권한이 있는 Snowflake 사용자 만들기
- 네트워크 정책 추가
- 선택사항: 스키마 감지 및 매핑
- Snowflake에서 지원되지 않는 데이터 유형 평가
- 선택사항: 증분 전송 사용 설정
- 선택사항: 비공개 연결 사용 설정
- 전송 정보 수집
- 고객 관리 암호화 키(CMEK)를 지정하려는 경우 서비스 계정에 암호화 및 복호화 권한이 있어야하며, Cloud KMS 키 리소스 ID가 필요합니다. CMEK가 전송과 함께 작동하는 방식에 대한 자세한 내용은 전송에 암호화 키 지정을 참고하세요.
Google Cloud 프로젝트 준비
다음 단계를 수행하여 Snowflake 전송에 사용할 Google Cloud 프로젝트를 만들고 구성합니다.
Google Cloud 프로젝트를 만들거나 기존 프로젝트를 선택합니다.
BigQuery Data Transfer Service 사용 설정에 필요한 모든 작업을 완료했는지 확인합니다.
데이터를 저장할 BigQuery 데이터 세트를 만듭니다. 테이블을 만들지 않아도 됩니다.
필요한 BigQuery 역할
BigQuery 데이터 전송 서비스 데이터 전송을 만드는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 BigQuery 관리자 (roles/bigquery.admin) IAM 역할을 부여해 달라고 요청하세요.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이 사전 정의된 역할에는 BigQuery Data Transfer Service 데이터 전송을 만드는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
BigQuery Data Transfer Service 데이터 전송을 만들려면 다음 권한이 필요합니다.
-
BigQuery Data Transfer Service 권한:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery 권한:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
자세한 내용은 bigquery.admin 액세스 권한 부여를 참고하세요.
스테이징 버킷 준비
Snowflake 데이터 전송을 준비하려면 스테이징 버킷을 만든 후 Snowflake에서 쓰기 액세스를 허용하도록 구성합니다. Snowflake 데이터를 BigQuery에 로드하려면 먼저 Cloud Storage 버킷에 스테이징해야 합니다.
- Cloud Storage 버킷 생성
- Snowflake에서 Cloud Storage 버킷에 데이터를 외부 단계로 쓸 수 있도록 Snowflake 스토리지 통합 객체를 만들고 구성합니다.
DESCRIBE INTEGRATION명령어를 실행하면 Cloud Storage 서비스 계정이STORAGE_GCP_SERVICE_ACCOUNT필드에 나열됩니다. Cloud Storage 버킷에서 Cloud Storage 서비스 계정에 다음 권한을 부여합니다.storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
스테이징 버킷에 대한 액세스를 허용하려면 다음 명령어를 사용하여 DTS 서비스 에이전트에
roles/storage.objectViewer역할을 부여합니다.gcloud storage buckets add-iam-policy-binding gs://STAGING_BUCKET_NAME \ --member=serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com \ --role=roles/storage.objectViewer
Snowflake 비공개 데이터 전송의 경우 스테이징 버킷을 만들고 비공개 연결을 위해 구성합니다.
필요한 권한이 있는 Snowflake 사용자 만들기
Snowflake 전송 중에 Snowflake 커넥터는 JDBC 연결을 통해 Snowflake 계정에 연결됩니다. 데이터 전송을 수행하는 데 필요한 권한만 있는 커스텀 역할로 새 Snowflake 사용자를 만들어야 합니다.
// Create and configure new role, MIGRATION_ROLE
GRANT USAGE
ON WAREHOUSE WAREHOUSE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON DATABASE DATABASE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON SCHEMA DATABASE_NAME.SCHEMA_NAME
TO ROLE MIGRATION_ROLE;
// You can modify this to give select permissions for all tables in a schema
GRANT SELECT
ON TABLE DATABASE_NAME.SCHEMA_NAME.TABLE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON INTEGRATION STORAGE_INTEGRATION_OBJECT_NAME
TO ROLE MIGRATION_ROLE;
다음을 바꿉니다.
MIGRATION_ROLE: 만들려는 커스텀 역할의 이름WAREHOUSE_NAME: 데이터 웨어하우스 이름DATABASE_NAME: Snowflake 데이터베이스 이름SCHEMA_NAME: Snowflake 스키마 이름TABLE_NAME: 이 데이터 전송에 포함된 Snowflake의 이름STORAGE_INTEGRATION_OBJECT_NAME: Snowflake 스토리지 통합 객체의 이름입니다.
인증에 사용할 키 쌍 생성
Snowflake에서 단일 요소 비밀번호 로그인 지원을 중단했으므로 인증에 키 쌍을 사용하는 것이 좋습니다.
암호화되거나 암호화되지 않은 RSA 키 쌍을 생성한 후 공개 키를 Snowflake 사용자에게 할당하여 키 쌍을 구성할 수 있습니다. 자세한 내용은 키 쌍 인증 구성을 참조하세요.
인라인 외부 위치로 언로드 허용
Snowflake 커넥터는 전송 중에 인라인 외부 위치로 데이터를 언로드합니다. Snowflake 계정에서 인라인 위치로의 언로드를 제한하는 경우 전송이 실패합니다.
인라인 위치로 언로드를 허용하려면 Snowflake 계정에서 다음 SQL 명령어를 실행하세요. 이 명령어를 실행하려면 Snowflake에 ACCOUNTADMIN 역할이 있어야 합니다.
ALTER ACCOUNT SET PREVENT_UNLOAD_TO_INLINE_URL = false;
네트워크 정책 추가
공개 연결의 경우 Snowflake 계정은 기본적으로 데이터베이스 사용자 인증 정보로 공개 연결을 허용합니다. 하지만 Snowflake 커넥터가 계정에 연결되지 않도록 하는 네트워크 규칙이나 정책을 구성했을 수 있습니다. 이 경우 필요한 IP 주소를 허용 목록에 추가해야 합니다. 자세한 내용은 Snowflake 전송을 위한 네트워크 정책 구성을 참고하세요.
스키마 감지 및 매핑
스키마를 정의하려면 BigQuery Data Transfer Service를 사용하여 Snowflake에서 BigQuery로 데이터를 전송할 때 스키마와 데이터 유형 매핑을 자동으로 감지하면 됩니다. 또는 변환 엔진을 사용하여 스키마와 데이터 유형을 수동으로 정의할 수 있습니다.
자세한 내용은 Snowflake의 스키마 감지 및 매핑을 참고하세요.
증분 전송 사용 설정
증분 Snowflake 데이터 전송을 설정하려면 Snowflake의 증분 전송 설정을 참고하세요.
비공개 연결 사용 설정
비공개 Snowflake 데이터 전송을 만들려면 비공개 연결을 위해 네트워크를 구성해야 합니다.
전송 정보 수집
BigQuery Data Transfer Service로 마이그레이션을 설정하는 데 필요한 정보를 수집합니다.
- Snowflake 계정 식별자(Snowflake 계정 URL의 프리픽스). 예를 들면
ACCOUNT_IDENTIFIER.snowflakecomputing.com입니다. - Snowflake 데이터베이스에 대한 적절한 권한이 있는 사용자 이름과 연결된 비공개 키. 데이터 전송을 실행하는 데 필요한 권한만 있으면 됩니다.
- 전송에 사용할 스테이징 버킷의 URI입니다. 불필요한 비용이 청구되지 않도록 이 버킷에 수명 주기 정책을 설정하는 것이 좋습니다.
- 변환 엔진에서 가져온 스키마 매핑 파일을 저장한 Cloud Storage 버킷의 URI.
Snowflake 전송 설정
다음 옵션 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 데이터 전송 페이지로 이동합니다.
전송 만들기를 클릭합니다.
소스 유형 섹션의 소스 목록에서 Snowflake 마이그레이션을 선택합니다.
전송 구성 이름 섹션에서 전송 이름(예:
My migration)을 표시 이름 필드에 입력합니다. 표시 이름은 나중에 수정해야 할 경우를 대비해 전송을 식별할 수 있는 값이면 됩니다.대상 설정 섹션의 데이터 세트 목록에서 만든 데이터 세트를 선택합니다.
Snowflake 사용자 인증 정보 섹션에서 다음을 수행합니다.
- 계정 식별자에 Snowflake 계정의 고유 식별자를 입력합니다. 이 고유 식별자는 조직 이름과 계정 이름의 조합입니다. 식별자는 Snowflake 계정 URL 프리픽스이며 전체 URL이 아닙니다. 예를 들면
ACCOUNT_IDENTIFIER.snowflakecomputing.com입니다. - 사용자 이름에 Snowflake 테이블을 전송하기 위해 데이터베이스에 액세스하는 데 사용되는 사용자 인증 정보와 승인이 있는 Snowflake 사용자의 사용자 이름을 입력합니다. 이 전송을 위해 만든 사용자를 사용하는 것이 좋습니다.
- 인증 메커니즘에서 Snowflake 사용자 인증 방법을 선택합니다.
비밀번호
- 비밀번호에 Snowflake 사용자 비밀번호를 입력합니다.
KEY_PAIR
- 비공개 키에 Snowflake 사용자와 연결된 공개 키와 연결된 비공개 키를 입력합니다.
- 비공개 키가 암호로 암호화된 경우 비공개 키가 암호화됨 필드를 선택합니다.
- 비공개 키 암호에 암호화된 비공개 키의 암호를 입력합니다. 비공개 키가 암호화됨을 선택한 경우 이 필드는 필수입니다. 자세한 내용은 인증을 위한 키 쌍 생성을 참고하세요.
- 웨어하우스에 이 데이터 전송 실행에 사용되는 웨어하우스를 입력합니다.
- Snowflake 데이터베이스에 이 데이터 전송에 포함된 테이블이 있는 Snowflake 데이터베이스의 이름을 입력합니다.
- Snowflake 스키마에 이 데이터 전송에 포함된 테이블이 있는 Snowflake 스키마의 이름을 입력합니다.
- 계정 식별자에 Snowflake 계정의 고유 식별자를 입력합니다. 이 고유 식별자는 조직 이름과 계정 이름의 조합입니다. 식별자는 Snowflake 계정 URL 프리픽스이며 전체 URL이 아닙니다. 예를 들면
스토리지 구성 섹션에서 다음을 수행합니다.
- 스토리지 통합 객체 이름에 Snowflake 스토리지 통합 객체 이름을 입력합니다.
- 선택사항: 최대 파일 크기에 Snowflake에서 스테이징 위치로 언로드되는 각 파일의 최대 크기를 지정합니다 (MB).
클라우드 제공업체에서 Snowflake 계정을 호스팅하는 클라우드 제공업체에 따라
AWS,AZURE또는GCP를 선택합니다.- GCS URI에 스테이징 버킷으로 사용할 Cloud Storage 버킷의 URI를 입력합니다.
서비스 계정 섹션에서 다음을 수행합니다.
- 서비스 계정에 이 데이터 전송에 사용할 서비스 계정을 입력합니다. 서비스 계정은 전송 구성과 대상 데이터 세트가 생성된 동일한Google Cloud 프로젝트에 속해야 합니다. 서비스 계정에는
storage.objects.list및storage.objects.get필수 권한이 있어야 합니다.
- 서비스 계정에 이 데이터 전송에 사용할 서비스 계정을 입력합니다. 서비스 계정은 전송 구성과 대상 데이터 세트가 생성된 동일한Google Cloud 프로젝트에 속해야 합니다. 서비스 계정에는
스키마 구성 섹션에서 다음을 수행합니다.
- 수집 유형에서 전체 또는 증분을 선택합니다. 자세한 내용은 증분 전송 구성을 참고하세요.
- 테이블 이름 패턴에 스키마의 테이블 이름과 일치하는 이름이나 패턴을 입력하여 전송할 테이블을 지정합니다. 정규 표현식을 사용하여 패턴을 지정할 수 있습니다(예:
table1_regex;table2_regex). 이 패턴은 Java 정규 표현식 문법을 따라야 합니다. 예를 들면 다음과 같습니다.lineitem;ordertb는lineitem및ordertb테이블과 일치합니다..*은 모든 테이블을 찾습니다.
- 선택사항: BigQuery Translation Engine 출력 사용의 경우 맞춤 변환 출력 경로를 지정하려면 이 필드를 선택합니다.
- 선택사항: 변환 출력 GCS 경로에 변환 엔진의 스키마 매핑 파일이 포함된 Cloud Storage 폴더의 경로를 지정합니다. Snowflake 커넥터가 스키마를 자동으로 감지하도록 하려면 이 필드를 비워 두면 됩니다.
- 경로는
translation_target_base_uri/metadata/config/db/schema/형식을 따라야 하며/로 끝나야 합니다.
- 경로는
- 선택사항: 맞춤 스키마 파일 경로에 맞춤 스키마 파일의 Cloud Storage 경로를 지정합니다.
- 선택사항: 0 스케일 Snowflake NUMBER를 BigQuery INT64에 매핑의 경우 Snowflake
NUMBER(p, 0)유형을 BigQueryINT64에 매핑하려면 이 필드를 선택합니다.
네트워크 연결 섹션에서 다음을 수행합니다.
- 비공개 네트워크 사용의 경우 비공개 데이터 전송을 만드는 경우 True를 선택합니다.
- PSC 서비스 연결에서 비공개 연결을 만드는 경우 서비스 연결 URI를 입력합니다. 자세한 내용은 비공개 Snowflake 전송 구성 만들기를 참고하세요.
- 비공개 네트워크 서비스의 경우 비공개 데이터 전송을 만드는 경우 서비스 디렉터리 자체 링크를 입력합니다. 자세한 내용은 비공개 Snowflake 전송 구성 만들기를 참고하세요.
선택사항: 알림 옵션 섹션에서 다음을 수행합니다.
CMEK를 사용하는 경우 고급 옵션 섹션에서 고객 관리 키를 선택합니다. 선택할 수 있는 CMEK 목록이 표시됩니다. CMEK가 BigQuery Data Transfer Service에서 작동하는 방식에 대한 자세한 내용은 전송에 암호화 키 지정을 참조하세요.
저장을 클릭합니다.
Google Cloud 콘솔에 이 전송의 리소스 이름을 포함하여 모든 전송 설정 세부사항이 표시됩니다.
bq
bq mk 명령어를 입력하고 전송 생성 플래그 --transfer_config를 지정합니다. 다음 플래그도 필요합니다.
--project_id--data_source--target_dataset--display_name--params
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters'
다음을 바꿉니다.
- project_id: Google Cloud 프로젝트 ID입니다.
--project_id를 지정하지 않으면 기본 프로젝트가 사용됩니다. - data_source: 데이터 소스(
snowflake_migration) - dataset: 전송 구성에 사용할 BigQuery 대상 데이터 세트
- name: 전송 구성의 표시 이름입니다. 전송 이름은 나중에 수정해야 할 경우를 대비해 전송을 식별할 수 있는 값이면 됩니다.
- service_account: (선택사항) 전송을 인증하는 데 사용되는 서비스 계정 이름. 전송을 만드는 데 사용한 것과 동일한
project_id에서 서비스 계정을 소유해야 하며 이 계정에 모든 필요한 역할이 있어야 합니다. - parameters: JSON 형식으로 생성된 전송 구성의 매개변수. 예를 들면
--params='{"param":"param_value"}'입니다.
Snowflake 전송 구성에 다음 매개변수를 구성할 수 있습니다.
account_identifier: Snowflake 계정의 고유 식별자를 지정합니다. 이 고유 식별자는 조직 이름과 계정 이름의 조합입니다. 식별자는 Snowflake 계정 URL 프리픽스이며 전체 URL이 아닙니다. 예를 들면account_identifier.snowflakecomputing.com입니다.username: Snowflake 테이블을 전송하기 위해 데이터베이스에 액세스하는 데 사용되는 사용자 인증 정보와 승인이 있는 Snowflake 사용자의 사용자 이름을 지정합니다.auth_mechanism: Snowflake 사용자 인증 방법을 지정합니다. 지원되는 값은PASSWORD및KEY_PAIR입니다. 자세한 내용은 인증을 위한 키 쌍 생성을 참조하세요.password: Snowflake 사용자 비밀번호를 지정합니다.auth_mechanism필드에PASSWORD를 지정한 경우 이 필드는 필수입니다.private_key: Snowflake 사용자와 연결된 공개 키와 연결된 비공개 키를 지정합니다.auth_mechanism필드에KEY_PAIR를 지정한 경우 이 필드는 필수입니다.is_private_key_encrypted: 비공개 키가 암호로 암호화된 경우true를 지정합니다.private_key_passphrase: 암호화된 비공개 키의 암호를 지정합니다.auth_mechanism필드에KEY_PAIR를 지정하고is_private_key_encrypted필드에true를 지정한 경우 이 필드는 필수입니다.warehouse: 이 데이터 전송 실행에 사용되는 웨어하우스를 지정합니다.service_account: 이 데이터 전송에서 사용할 서비스 계정을 지정합니다. 서비스 계정은 전송 구성과 대상 데이터 세트가 생성된 동일한 Google Cloud 프로젝트에 속해야 합니다. 서비스 계정에는storage.objects.list및storage.objects.get필수 권한이 있어야 합니다.database: 이 데이터 전송에 포함된 테이블이 있는 Snowflake 데이터베이스의 이름을 지정합니다.schema: 이 데이터 전송에 포함된 테이블이 있는 Snowflake 스키마의 이름을 지정합니다.table_name_patterns: 스키마에서 테이블 이름과 일치하는 이름이나 패턴을 입력하여 전송할 테이블을 지정합니다. 정규 표현식을 사용하여 패턴을 지정할 수 있습니다(예:table1_regex;table2_regex). 이 패턴은 Java 정규 표현식 문법을 따라야 합니다. 예를 들면 다음과 같습니다.lineitem;ordertb는lineitem및ordertb테이블과 일치합니다..*은 모든 테이블을 찾습니다.지정된 스키마에서 모든 테이블을 마이그레이션하려면 이 필드도 비워 두면 됩니다.
ingestion_mode: 전송의 수집 모드를 지정합니다. 지원되는 값은FULL및INCREMENTAL입니다. 자세한 내용은 증분 전송 구성을 참고하세요.translation_output_gcs_path: (선택사항) 변환 엔진의 스키마 매핑 파일이 포함된 Cloud Storage 폴더의 경로를 지정합니다. Snowflake 커넥터가 스키마를 자동으로 감지하도록 하려면 이 필드를 비워 두면 됩니다.- 경로는
gs://translation_target_base_uri/metadata/config/db/schema/형식을 따라야 하며/로 끝나야 합니다.
- 경로는
storage_integration_object_name: Snowflake 스토리지 통합 객체 이름을 지정합니다.max_file_size_mb: (선택사항) Snowflake에서 스테이징 위치로 언로드된 각 파일의 최대 크기(MB)를 지정합니다. 값은16에서5120사이여야 합니다. 기본값은512입니다.staging_gcs_uri: 데이터를 스테이징하는 데 사용할 Cloud Storage 버킷의 URI를 입력합니다.use_private_network: 비공개 데이터 전송을 만드는 경우TRUE으로 설정합니다.service_attachment: 비공개 데이터 전송을 만드는 경우 서비스 연결 URI를 지정합니다. 자세한 내용은 비공개 Snowflake 전송 구성 만들기를 참고하세요.private_network_service: 비공개 데이터 전송을 만드는 경우 NLB 서비스의 자체 링크를 지정합니다. 자세한 내용은 비공개 Snowflake 전송 구성 만들기를 참고하세요.
예를 들어 AWS 호스팅 Snowflake 계정의 경우 다음 명령어는 대상 데이터 세트 이름이 your_bq_dataset이고 프로젝트 ID가 your_project_id인 Snowflake transfer config라는 Snowflake 전송을 만듭니다.
PARAMS='{ "account_identifier": "your_account_identifier", "auth_mechanism": "KEY_PAIR", "aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_aws_secret_access_key", "cloud_provider": "AWS", "database": "your_sf_database", "ingestion_mode": "INCREMENTAL", "private_key": "-----BEGIN PRIVATE KEY----- privatekey\nseparatedwith\nnewlinecharacters=-----END PRIVATE KEY-----", "schema": "your_snowflake_schema", "service_account": "your_service_account", "storage_integration_object_name": "your_storage_integration_object", "max_file_size_mb": "512", "staging_s3_uri": "s3://your/s3/bucket/uri", "table_name_patterns": ".*", "translation_output_gcs_path": "gs://sf_test_translation/output/metadata/config/database_name/schema_name/", "username": "your_sf_username", "warehouse": "your_warehouse" }' bq mk --transfer_config \ --project_id=your_project_id \ --target_dataset=your_bq_dataset \ --display_name='snowflake transfer config' \ --params="$PARAMS" \ --data_source=snowflake_migration
API
projects.locations.transferConfigs.create 메서드를 사용하고 TransferConfig 리소스의 인스턴스를 지정합니다.
전송을 통한 암호화 키 지정
고객 관리 암호화 키(CMEK)를 지정하여 전송 실행의 데이터를 암호화할 수 있습니다. CMEK를 사용하여 Snowflake에서의 전송을 지원할 수 있습니다.전송에 CMEK를 지정하면 BigQuery Data Transfer Service는 CMEK를 수집된 데이터의 모든 중간 디스크 캐시에 적용하여 전체 데이터 전송 워크플로가 CMEK를 준수하도록 합니다.
원래 CMEK를 사용해 생성되지 않은 전송의 경우 기존 전송을 업데이트하여 CMEK를 추가할 수 없습니다. 예를 들어 원래 기본적으로 암호화된 대상 테이블을 지금 CMEK로 암호화되도록 변경할 수 없습니다. 반대로 CMEK로 암호화된 대상 테이블을 다른 유형의 암호화가 적용되도록 변경할 수도 없습니다.
전송 구성이 원래 CMEK 암호화를 사용하여 생성된 경우 전송에 대해 CMEK를 업데이트할 수 있습니다. 전송 구성에 대해 CMEK를 업데이트하면 BigQuery Data Transfer Service는 전송의 다음 실행 시 CMEK를 대상 테이블에 전파하는데, 여기서 BigQuery Data Transfer Service는 전송 실행 중 오래된 CMEK를 새 CMEK로 대체합니다. 자세한 내용은 전송 업데이트를 참고하세요.
프로젝트 기본 키를 사용할 수도 있습니다. 전송과 함께 프로젝트 기본 키를 지정하면 BigQuery Data Transfer Service는 프로젝트 기본 키를 새 전송 구성의 기본 키로 사용합니다.
할당량 및 한도
BigQuery에는 테이블별 로드 작업당 15TB의 로드 할당량이 기본적으로 있습니다. 내부적으로 Snowflake는 테이블 데이터를 압축하므로 내보낸 테이블 크기는 Snowflake에서 보고한 테이블 크기보다 큽니다.
더 큰 테이블의 로드 시간을 개선하고 15TB BigQuery 로드 한도를 삭제하려면 예약 할당에 PIPELINE 작업 유형을 지정하세요.
Amazon S3 일관성 모델로 인해 일부 파일이 BigQuery로 전송되지 않을 수 있습니다.
데이터 전송 성능 최적화
데이터 전송 로그를 확인하여 데이터 전송 성능을 모니터링할 수 있습니다. 데이터 전송 성능을 개선하려면 다음 최적화 단계를 수행하는 것이 좋습니다.
- Snowflake 인스턴스, 스테이징 버킷, BigQuery 데이터 세트를 동일한 리전에 유지
- 다음을 수행하여 테이블 언로드 속도를 개선할 수 있습니다.
- 특히 대규모 Snowflake 테이블 (1TiB 이상)을 전송할 때는 Snowflake 가상 웨어하우스의 크기를 늘리세요.
- 전송 구성에서
MAX_FILE_SIZE옵션을 조정합니다.- 파일 크기가 작을수록 전송 속도가 빨라지지만 너무 작게 만들면 파일이 너무 많아질 수 있습니다.
PIPELINE및QUERY작업 유형의 BigQuery 슬롯 예약 수를 늘려 테이블 로드 속도를 개선할 수 있습니다.- 전체 전송을 수행할 때는 대상 BigQuery 테이블에서 클러스터링 및 파티셔닝을 피하세요.
- Upsert 모드에서 증분 전송을 실행할 때는 기본 키 열에서 클러스터링 및 파티션 나누기를 고려하여 전송 성능을 개선하세요.
- 하지만 병합 작업 속도를 늦추지 않으려면 기본 키가 아닌 열에서 클러스터링 및 파티셔닝을 피하세요.
가격 책정
BigQuery Data Transfer Service 가격에 대한 자세한 내용은 가격 책정 페이지를 참고하세요.
- Snowflake 웨어하우스와 Amazon S3 버킷이 서로 다른 리전에 있는 경우 Snowflake 데이터 전송을 실행하면 Snowflake에서 이그레스 요금을 적용합니다. Snowflake 웨어하우스와 Amazon S3 버킷 모두 같은 리전에 있으면 Snowflake 데이터 전송에 이그레스 요금이 청구되지 않습니다.
- 데이터가 AWS에서 Google Cloud로 전송되면 클라우드 간 이그레스 요금이 적용됩니다.
다음 단계
- BigQuery Data Transfer Service 자세히 알아보기
- SQL 일괄 변환으로 SQL 코드 마이그레이션