
Snowflake-Übertragung planen
Mit dem Snowflake-Connector, der vom BigQuery Data Transfer Service bereitgestellt wird, können Sie automatisierte Übertragungsjobs planen und verwalten, um Daten aus Snowflake in BigQuery zu migrieren. Dazu verwenden Sie Zulassungslisten für öffentliche IP-Adressen.
Übersicht
Der Snowflake-Connector aktiviert die Migrations-Agents in der Google Kubernetes Engine und löst einen Ladevorgang von Snowflake zu einem Staging-Bereich im Cloud Storage-Bucket aus.
- Bei Amazon Web Services- (AWS-) oder Azure- oder Google Cloud-gehosteten Snowflake-Konten werden die Daten zuerst in Ihrem Cloud Storage-Bucket bereitgestellt und dann mit dem BigQuery Data Transfer Service nach BigQuery übertragen.
Das folgende Diagramm veranschaulicht öffentliche Datenübertragungen von Snowflake-Konten, die auf Amazon Web Services (AWS) oder Azure gehostet werden, oder von Google Cloud-gehosteten Snowflake-Konten.
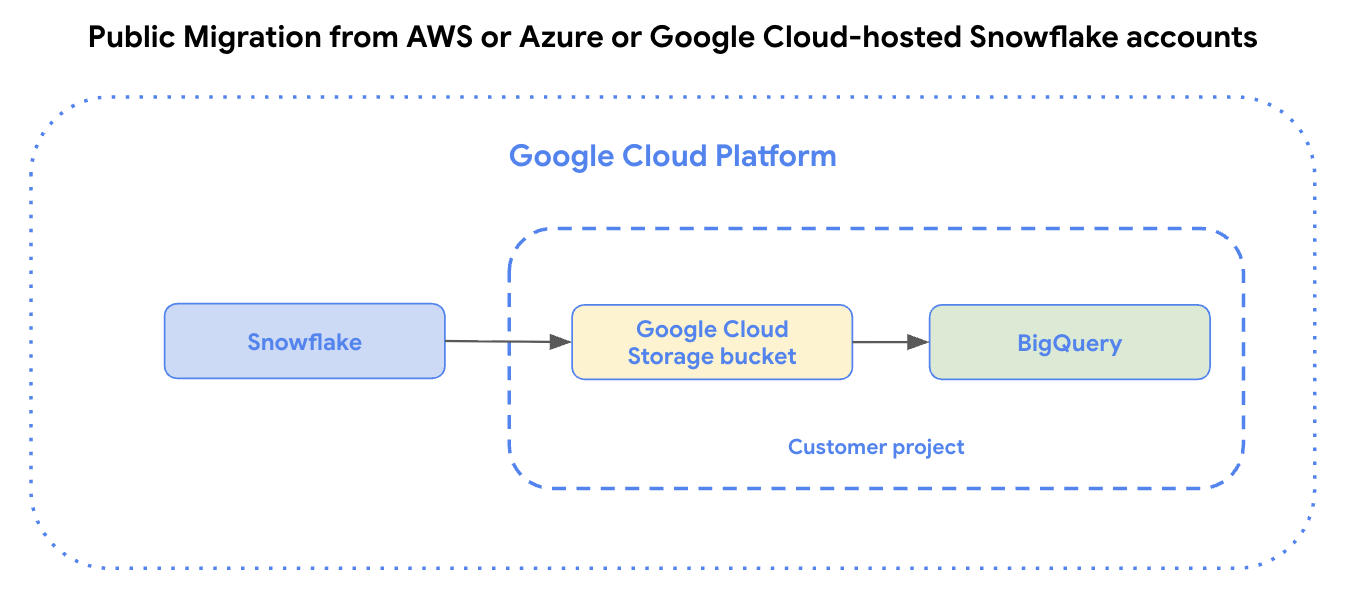
Beschränkungen
Für Datenübertragungen mit dem Snowflake-Connector gelten die folgenden Einschränkungen:
- Der Snowflake-Connector unterstützt nur Übertragungen von Tabellen innerhalb einer einzelnen Snowflake-Datenbank und eines einzelnen Snowflake-Schemas. Wenn Sie Daten aus Tabellen mit mehreren Snowflake-Datenbanken oder ‑Schemas übertragen möchten, können Sie jeden Übertragungsjob separat einrichten.
- Die Geschwindigkeit des Ladens von Daten aus Snowflake in Ihren Amazon S3-Bucket, Azure Blob Storage-Container oder Cloud Storage-Bucket wird durch das Snowflake-Warehouse begrenzt, das Sie für diese Übertragung ausgewählt haben.
- BigQuery schreibt Daten aus Snowflake als Parquet-Dateien in Cloud Storage. Die Datentypen
TIMESTAMP_TZundTIMESTAMP_LTZwerden in Parquet-Dateien nicht unterstützt. Wenn Ihre Daten diese Typen enthalten, können Sie sie als CSV-Dateien in Amazon S3 exportieren und die CSV-Dateien dann in BigQuery importieren. Weitere Informationen finden Sie unter Übersicht über Amazon S3-Übertragungen.
Hinweis
Bevor Sie einen Snowflake-Transfer einrichten, müssen Sie alle in diesem Abschnitt aufgeführten Schritte ausführen. Im Folgenden finden Sie eine Liste aller erforderlichen Schritte.
- Projekt in Google Cloud vorbereiten
- Erforderliche BigQuery-Rollen
- Staging-Bucket vorbereiten
- Snowflake-Nutzer mit den erforderlichen Berechtigungen erstellen
- Netzwerkrichtlinien hinzufügen
- Optional: Schemaerkennung und ‑zuordnung
- Snowflake auf nicht unterstützte Datentypen prüfen
- Optional: Inkrementelle Übertragungen aktivieren
- Optional: Private Verbindung aktivieren
- Übertragungsinformationen erfassen
- Wenn Sie einen kundenverwalteten Verschlüsselungsschlüssel (CMEK) angeben möchten, muss Ihr Dienstkonto über die Berechtigungen zum Verschlüsseln und Entschlüsseln verfügen und Sie müssen die für die Verwendung von CMEK erforderliche Cloud KMS-Schlüsselressourcen-ID haben. Informationen zur Funktionsweise von CMEK mit Übertragungen finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.
Google Cloud -Projekt vorbereiten
So erstellen und konfigurieren Sie Ihr Google Cloud Projekt für eine Snowflake-Übertragung:
Erstellen Sie ein Google Cloud Projekt oder wählen Sie ein vorhandenes Projekt aus.
Überprüfen Sie, ob Sie alle erforderlichen Aktionen ausgeführt haben, damit Sie den BigQuery Data Transfer Service aktivieren können.
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihrer Daten. Sie müssen keine Tabellen erstellen.
Erforderliche BigQuery-Rollen
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle BigQuery-Administrator (roles/bigquery.admin) für Ihr Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen einer BigQuery Data Transfer Service-Datenübertragung benötigen.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierte Rolle enthält die Berechtigungen, die zum Erstellen einer BigQuery Data Transfer Service-Datenübertragung erforderlich sind. Maximieren Sie den Abschnitt Erforderliche Berechtigungen, um die notwendigen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind erforderlich, um eine Datenübertragung für den BigQuery Data Transfer Service zu erstellen:
-
Berechtigungen für BigQuery Data Transfer Service:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery-Berechtigungen:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Weitere Informationen finden Sie unter Zugriff auf bigquery.admin gewähren.
Staging-Bucket vorbereiten
Erstellen Sie zur Vorbereitung auf eine Snowflake-Datenübertragung einen Staging-Bucket und konfigurieren Sie ihn so, dass Schreibzugriff von Snowflake möglich ist. Sie müssen die Snowflake-Daten in einem Cloud Storage-Bucket bereitstellen, bevor Sie sie in BigQuery laden können.
- Cloud Storage-Bucket erstellen
- Erstellen und konfigurieren Sie ein Snowflake-Speicherintegrationsobjekt, damit Snowflake Daten als externe Phase in den Cloud Storage-Bucket schreiben kann.
- Wenn Sie den
DESCRIBE INTEGRATION-Befehl ausführen, wird das Cloud Storage-Dienstkonto im FeldSTORAGE_GCP_SERVICE_ACCOUNTaufgeführt. Gewähren Sie dem Cloud Storage-Dienstkonto die folgenden Berechtigungen für den Cloud Storage-Bucket:storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
Um Zugriff auf den Staging-Bucket zu gewähren, weisen Sie dem DTS-Dienst-Agent mit dem folgenden Befehl die Rolle
roles/storage.objectViewerzu:gcloud storage buckets add-iam-policy-binding gs://STAGING_BUCKET_NAME \ --member=serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com \ --role=roles/storage.objectViewer
Für eine private Datenübertragung in Snowflake müssen Sie den Staging-Bucket erstellen und für private Verbindungen konfigurieren.
Snowflake-Nutzer mit den erforderlichen Berechtigungen erstellen
Bei einer Snowflake-Übertragung wird über den Snowflake-Connector eine JDBC-Verbindung zu Ihrem Snowflake-Konto hergestellt. Sie müssen einen neuen Snowflake-Nutzer mit einer benutzerdefinierten Rolle erstellen, die nur die erforderlichen Berechtigungen für die Datenübertragung hat:
// Create and configure new role, MIGRATION_ROLE
GRANT USAGE
ON WAREHOUSE WAREHOUSE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON DATABASE DATABASE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON SCHEMA DATABASE_NAME.SCHEMA_NAME
TO ROLE MIGRATION_ROLE;
// You can modify this to give select permissions for all tables in a schema
GRANT SELECT
ON TABLE DATABASE_NAME.SCHEMA_NAME.TABLE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON INTEGRATION STORAGE_INTEGRATION_OBJECT_NAME
TO ROLE MIGRATION_ROLE;
Ersetzen Sie Folgendes:
MIGRATION_ROLE: der Name der benutzerdefinierten Rolle, die Sie erstellenWAREHOUSE_NAME: der Name Ihres Data WarehouseDATABASE_NAME: der Name Ihrer Snowflake-DatenbankSCHEMA_NAME: der Name Ihres Snowflake-SchemasTABLE_NAME: der Name der Snowflake-Instanz, die in dieser Datenübertragung enthalten istSTORAGE_INTEGRATION_OBJECT_NAME: Der Name Ihres Snowflake-Speicherintegrationsobjekts.
Schlüsselpaar für die Authentifizierung generieren
Da Snowflake die Anmeldung mit einem Einzelfaktor-Passwort einstellt, empfehlen wir, für die Authentifizierung ein Schlüsselpaar zu verwenden.
Sie können ein Schlüsselpaar konfigurieren, indem Sie ein verschlüsseltes oder unverschlüsseltes RSA-Schlüsselpaar generieren und dann den öffentlichen Schlüssel einem Snowflake-Nutzer zuweisen. Weitere Informationen finden Sie unter Authentifizierung mit Schlüsselpaar konfigurieren.
Entladen an Inline-Standorten zulassen
Mit dem Snowflake-Connector werden Daten während der Übertragung an Inline-Speicherorte entladen. Wenn in Ihrem Snowflake-Konto das Entladen auf Inline-Speicherorte beschränkt ist, schlägt die Übertragung fehl.
Führen Sie den folgenden SQL-Befehl in Ihrem Snowflake-Konto aus, um das Entladen an Inline-Speicherorte zu ermöglichen. Sie benötigen die Rolle ACCOUNTADMIN in Snowflake, um diesen Befehl auszuführen.
ALTER ACCOUNT SET PREVENT_UNLOAD_TO_INLINE_URL = false;
Netzwerkrichtlinien hinzufügen
Für öffentliche Verbindungen ist im Snowflake-Konto standardmäßig eine öffentliche Verbindung mit Datenbankanmeldedaten zulässig. Möglicherweise haben Sie jedoch Netzwerkregeln oder ‑richtlinien konfiguriert, die verhindern, dass der Snowflake-Connector eine Verbindung zu Ihrem Konto herstellt. In diesem Fall müssen Sie die erforderlichen IP-Adressen der Zulassungsliste hinzufügen. Weitere Informationen finden Sie unter Netzwerkrichtlinien für Snowflake-Übertragungen konfigurieren.
Schemaerkennung und ‑zuordnung
Wenn Sie Ihr Schema definieren möchten, können Sie den BigQuery Data Transfer Service verwenden, um das Schema und die Datentypzuordnung automatisch zu erkennen, wenn Sie Daten von Snowflake zu BigQuery übertragen. Alternativ können Sie die Übersetzungs-Engine verwenden, um Ihr Schema und Ihre Datentypen manuell zu definieren.
Weitere Informationen finden Sie unter Schemaerkennung und ‑zuordnung für Snowflake.
Inkrementelle Übertragungen aktivieren
Informationen zum Einrichten einer inkrementellen Snowflake-Datenübertragung finden Sie unter Inkrementelle Übertragungen für Snowflake einrichten.
Private Verbindung aktivieren
Wenn Sie einen privaten Snowflake-Datenübertrag erstellen möchten, müssen Sie Ihr Netzwerk für private Verbindungen konfigurieren.
Übertragungsinformationen erfassen
Erfassen Sie die Informationen, die Sie zum Einrichten der Migration mit BigQuery Data Transfer Service benötigen:
- Ihre Snowflake-Konto-ID, das Präfix in Ihrer Snowflake-Konto-URL. Beispiel:
ACCOUNT_IDENTIFIER.snowflakecomputing.com. - Der Nutzername und der zugehörige private Schlüssel mit den entsprechenden Berechtigungen für Ihre Snowflake-Datenbank. Es kann nur die erforderlichen Berechtigungen zum Ausführen der Datenübertragung haben.
- Der URI des Staging-Buckets, der für die Übertragung verwendet werden soll. Wir empfehlen, für diesen Bucket eine Lebenszyklusrichtlinie einzurichten, um unnötige Gebühren zu vermeiden.
- Der URI des Cloud Storage-Bucket, in dem Sie die von der Übersetzungs-Engine abgerufenen Schemazuordnungsdateien gespeichert haben.
Snowflake-Übertragung einrichten
Wählen Sie eine der folgenden Optionen aus:
Console
Rufen Sie in der Google Cloud -Console die Seite „Datenübertragungen“ auf.
Klicken Sie auf Übertragung erstellen.
Wählen Sie im Abschnitt Quelltyp die Option Snowflake-Migration aus der Liste Quelle aus.
Geben Sie im Abschnitt Transfer config name (Konfigurationsname für Übertragung) im Feld Display name (Anzeigename) einen Namen für die Übertragung ein, z. B.
My migration. Der Anzeigename kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.Wählen Sie im Abschnitt Destination settings (Zieleinstellungen) das von Ihnen erstellte Dataset aus der Liste Dataset aus.
Führen Sie im Bereich Snowflake-Anmeldedaten folgende Schritte aus:
- Geben Sie für Account Identifier (Konto-ID) eine eindeutige ID für Ihr Snowflake-Konto ein. Diese besteht aus Ihrem Organisationsnamen und Ihrem Kontonamen. Die ID ist das Präfix der Snowflake-Konto-URL und nicht die vollständige URL. Beispiel:
ACCOUNT_IDENTIFIER.snowflakecomputing.com. - Geben Sie unter Nutzername den Nutzernamen des Snowflake-Nutzers ein, dessen Anmeldedaten und Autorisierung für den Zugriff auf Ihre Datenbank verwendet werden, um die Snowflake-Tabellen zu übertragen. Wir empfehlen, den Nutzer zu verwenden, den Sie für diese Übertragung erstellt haben.
- Wählen Sie unter Authentication Mechanism (Authentifizierungsmechanismus) eine Snowflake-Nutzerauthentifizierungsmethode aus:
PASSWORT
- Geben Sie unter Passwort das Passwort des Snowflake-Nutzers ein.
KEY_PAIR
- Geben Sie für Private Key den privaten Schlüssel ein, der mit dem öffentlichen Schlüssel des Snowflake-Nutzers verknüpft ist.
- Wählen Sie für Is Private Key Encrypted (Ist der private Schlüssel verschlüsselt?) dieses Feld aus, wenn der private Schlüssel mit einer Passphrase verschlüsselt ist.
- Geben Sie unter Passphrase für den privaten Schlüssel die Passphrase für den verschlüsselten privaten Schlüssel ein. Dieses Feld ist erforderlich, wenn Sie Is Private Key Encrypted (Ist der private Schlüssel verschlüsselt?) ausgewählt haben. Weitere Informationen finden Sie unter Schlüsselpaar für die Authentifizierung generieren.
- Geben Sie unter Warehouse ein Warehouse ein, das für die Ausführung dieses Datentransfers verwendet wird.
- Geben Sie unter Snowflake-Datenbank den Namen der Snowflake-Datenbank ein, die die in dieser Datenübertragung enthaltenen Tabellen enthält.
- Geben Sie unter Snowflake-Schema den Namen des Snowflake-Schemas ein, das die in dieser Datenübertragung enthaltenen Tabellen enthält.
- Geben Sie für Account Identifier (Konto-ID) eine eindeutige ID für Ihr Snowflake-Konto ein. Diese besteht aus Ihrem Organisationsnamen und Ihrem Kontonamen. Die ID ist das Präfix der Snowflake-Konto-URL und nicht die vollständige URL. Beispiel:
Führen Sie im Abschnitt Speicherkonfiguration die folgenden Schritte aus:
- Geben Sie unter Name des Speicherintegrationsobjekts den Namen des Snowflake-Speicherintegrationsobjekts ein.
- Optional: Geben Sie unter Maximale Dateigröße die maximale Größe jeder Datei an, die aus Snowflake an den Staging-Speicherort entladen wird (in MB).
Wählen Sie für Cloud Provider (Cloud-Anbieter) je nachdem, welcher Cloud-Anbieter Ihr Snowflake-Konto hostet,
AWS,AZUREoderGCPaus.- Geben Sie als GCS-URI den URI des Cloud Storage-Buckets ein, der als Staging-Bucket verwendet werden soll.
Führen Sie im Abschnitt Dienstkonto folgende Schritte aus:
- Geben Sie unter Dienstkonto ein Dienstkonto ein, das für diese Datenübertragung verwendet werden soll. Das Dienstkonto sollte zum selbenGoogle Cloud -Projekt gehören, in dem die Übertragungskonfiguration und das Ziel-Dataset erstellt werden. Das Dienstkonto muss die erforderlichen Berechtigungen
storage.objects.listundstorage.objects.gethaben.
- Geben Sie unter Dienstkonto ein Dienstkonto ein, das für diese Datenübertragung verwendet werden soll. Das Dienstkonto sollte zum selbenGoogle Cloud -Projekt gehören, in dem die Übertragungskonfiguration und das Ziel-Dataset erstellt werden. Das Dienstkonto muss die erforderlichen Berechtigungen
Führen Sie im Abschnitt Schemakonfiguration die folgenden Schritte aus:
- Wählen Sie für Aufnahmetyp die Option Vollständig oder Inkrementell aus. Weitere Informationen finden Sie unter Inkrementelle Übertragungen konfigurieren.
- Geben Sie bei Table name patterns (Tabellennamensmuster) eine zu übertragende Tabelle an, indem Sie einen Namen oder ein Muster eingeben, das mit dem Tabellennamen im Schema übereinstimmt. Sie können das Muster mit regulären Ausdrücken angeben, z. B.
table1_regex;table2_regex. Das Muster sollte der Java-Syntax für reguläre Ausdrücke folgen. Beispiel:lineitem;ordertbführt zu Übereinstimmungen mit Tabellen, dielineitemundordertbheißen..*führt zu Übereinstimmung mit allen Tabellen.
- Optional: Wählen Sie für BigQuery Translation Engine-Ausgabe verwenden dieses Feld aus, wenn Sie einen benutzerdefinierten Ausgabepfad für die Übersetzung angeben möchten.
- Optional: Geben Sie für GCS-Pfad für Übersetzungsausgabe einen Pfad zum Cloud Storage-Ordner an, der die Dateien für die Schemazuordnung der Übersetzungs-Engine enthält. Sie können dieses Feld leer lassen, damit das Schema automatisch vom Snowflake-Connector erkannt wird.
- Der Pfad muss dem Format
translation_target_base_uri/metadata/config/db/schema/entsprechen und mit/enden.
- Der Pfad muss dem Format
- Optional: Geben Sie unter Pfad zur benutzerdefinierten Schemadatei den Cloud Storage-Pfad zu einer benutzerdefinierten Schemadatei an.
- Optional: Wählen Sie für Snowflake-NUMBER mit Skalierung 0 BigQuery-INT64 zuordnen dieses Feld aus, wenn Sie möchten, dass Snowflake-
NUMBER(p, 0)-Typen BigQuery-INT64zugeordnet werden.
Führen Sie im Abschnitt Netzwerkverbindung die folgenden Schritte aus:
- Wählen Sie für Use Private Network (Privates Netzwerk verwenden) True aus, wenn Sie eine private Datenübertragung erstellen.
- Geben Sie für PSC-Dienstanhang den URI des Dienstanhangs ein, wenn Sie eine private Verbindung erstellen. Weitere Informationen finden Sie unter Private Snowflake-Übertragungskonfiguration erstellen.
- Wenn Sie einen privaten Datentransfer für Private Network Service erstellen, geben Sie den Self-Link des Service Directory ein. Weitere Informationen finden Sie unter Private Snowflake-Übertragungskonfiguration erstellen.
Optional: Gehen Sie im Abschnitt Benachrichtigungsoptionen so vor:
- Klicken Sie auf den Umschalter, um E-Mail-Benachrichtigungen zu aktivieren. Wenn Sie diese Option aktivieren, erhält der Übertragungsadministrator eine E-Mail-Benachrichtigung, wenn ein Übertragungsvorgang fehlschlägt.
- Wählen Sie unter Pub/Sub-Thema auswählen Ihr Thema aus oder klicken Sie auf Thema erstellen. Mit dieser Option werden Pub/Sub-Ausführungsbenachrichtigungen für Ihre Übertragung konfiguriert.
Wenn Sie CMEKs verwenden, wählen Sie im Abschnitt Erweiterte Optionen die Option Vom Kunden verwalteter Schlüssel aus. Es wird eine Liste der verfügbaren CMEKs angezeigt, aus denen Sie wählen können. Informationen zur Funktionsweise von CMEKs mit dem BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.
Klicken Sie auf Speichern.
In der Google Cloud Console werden alle Details zur Übertragungseinrichtung angezeigt, darunter ein Ressourcenname für diese Übertragung.
bq
Geben Sie den Befehl bq mk ein und geben Sie das Flag --transfer_config für die Übertragungserstellung an. Folgende Flags sind ebenfalls erforderlich:
--project_id--data_source--target_dataset--display_name--params
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters'
Ersetzen Sie Folgendes:
- project_id: Projekt-ID in Google Cloud . Wenn
--project_idnicht angegeben ist, wird das Standardprojekt verwendet. - data_source: die Datenquelle,
snowflake_migration. - dataset ist das BigQuery-Ziel-Dataset für die Übertragungskonfiguration.
- name: Der Anzeigename für die Übertragungskonfiguration. Der Übertragungsname kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.
- service_account: (Optional) der Name des Dienstkontos, der zur Authentifizierung der Übertragung verwendet wird. Das Dienstkonto sollte zum selben
project_idgehören, das für die Erstellung der Übertragung verwendet wurde, und sollte alle erforderlichen Rollen haben. - parameters: die Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel:
--params='{"param":"param_value"}'.
Sie können die folgenden Parameter für Ihre Snowflake-Übertragungskonfiguration konfigurieren:
account_identifier: Geben Sie eine eindeutige Kennung für Ihr Snowflake-Konto an, die eine Kombination aus Ihrem Organisationsnamen und Kontonamen ist. Die ID ist das Präfix der Snowflake-Konto-URL und nicht die vollständige URL. Beispiel:account_identifier.snowflakecomputing.com.username: Geben Sie den Nutzernamen des Snowflake-Nutzers an, dessen Anmeldedaten und Autorisierung für den Zugriff auf Ihre Datenbank zum Übertragen der Snowflake-Tabellen verwendet werden.auth_mechanism: Geben Sie die Authentifizierungsmethode für Snowflake-Nutzer an. Unterstützte Werte sindPASSWORDundKEY_PAIR. Weitere Informationen finden Sie unter Schlüsselpaar für die Authentifizierung generieren.password: Geben Sie das Passwort des Snowflake-Nutzers an. Dieses Feld ist erforderlich, wenn SiePASSWORDim Feldauth_mechanismangegeben haben.private_key: Geben Sie den privaten Schlüssel an, der mit dem öffentlichen Schlüssel verknüpft ist, der dem Snowflake-Nutzer zugeordnet ist. Dieses Feld ist erforderlich, wenn SieKEY_PAIRim Feldauth_mechanismangegeben haben.is_private_key_encrypted: Geben Sietruean, wenn der private Schlüssel mit einer Passphrase verschlüsselt ist.private_key_passphrase: Geben Sie die Passphrase für den verschlüsselten privaten Schlüssel an. Dieses Feld ist erforderlich, wenn SieKEY_PAIRim Feldauth_mechanismundtrueim Feldis_private_key_encryptedangegeben haben.warehouse: Geben Sie ein Warehouse an, das für die Ausführung dieser Datenübertragung verwendet wird.service_account: Geben Sie ein Dienstkonto an, das für diese Datenübertragung verwendet werden soll. Das Dienstkonto sollte zum selben Google Cloud -Projekt gehören, in dem die Übertragungskonfiguration und das Ziel-Dataset erstellt werden. Das Dienstkonto muss die erforderlichen Berechtigungenstorage.objects.listundstorage.objects.gethaben.database: Geben Sie den Namen der Snowflake-Datenbank an, die die in dieser Datenübertragung enthaltenen Tabellen enthält.schema: Geben Sie den Namen des Snowflake-Schemas an, das die in dieser Datenübertragung enthaltenen Tabellen enthält.table_name_patterns: Geben Sie eine zu übertragende Tabelle an, indem Sie einen Namen oder ein Muster eingeben, das mit dem Tabellennamen im Schema übereinstimmt. Sie können das Muster mit regulären Ausdrücken angeben, z. B.table1_regex;table2_regex. Das Muster sollte der Java-Syntax für reguläre Ausdrücke folgen. Beispiel:lineitem;ordertbführt zu Übereinstimmungen mit Tabellen, dielineitemundordertbheißen..*führt zu Übereinstimmung mit allen Tabellen.Sie können dieses Feld auch leer lassen, um alle Tabellen aus dem angegebenen Schema zu migrieren.
ingestion_mode: Gibt den Aufnahmemodus für die Übertragung an. Unterstützte Werte sindFULLundINCREMENTAL. Weitere Informationen finden Sie unter Inkrementelle Übertragungen konfigurieren.translation_output_gcs_path: (Optional) Geben Sie einen Pfad zum Cloud Storage-Ordner an, der die Schemazuordnungsdateien der Übersetzungs-Engine enthält. Sie können dieses Feld leer lassen, damit das Schema automatisch vom Snowflake-Connector erkannt wird.- Der Pfad muss dem Format
gs://translation_target_base_uri/metadata/config/db/schema/entsprechen und mit/enden.
- Der Pfad muss dem Format
storage_integration_object_name: Geben Sie den Namen des Snowflake-Speicherintegrationsobjekts an.max_file_size_mb: (Optional) Gibt die maximale Größe jeder Datei an, die von Snowflake an den Staging-Speicherort entladen wird (in MB). Der Wert muss zwischen16und5120liegen. Der Standardwert ist512.staging_gcs_uri: Geben Sie den URI des Cloud Storage-Buckets ein, der für das Staging Ihrer Daten verwendet werden soll.use_private_network: Wenn Sie eine Übertragung privater Daten erstellen, legen SieTRUEfest.service_attachment: Wenn Sie eine private Datenübertragung erstellen, geben Sie den URI des Dienstanhangs an. Weitere Informationen finden Sie unter Private Snowflake-Übertragungskonfiguration erstellen.private_network_service: Wenn Sie eine private Datenübertragung erstellen, geben Sie den Self-Link des NLB-Dienstes an. Weitere Informationen finden Sie unter Private Snowflake-Übertragungskonfiguration erstellen.
Mit dem folgenden Befehl wird beispielsweise für ein in AWS gehostetes Snowflake-Konto eine Snowflake-Übertragung mit dem Namen Snowflake transfer config, einem Ziel-Dataset namens your_bq_dataset und einem Projekt mit der ID your_project_id erstellt.
PARAMS='{ "account_identifier": "your_account_identifier", "auth_mechanism": "KEY_PAIR", "aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_aws_secret_access_key", "cloud_provider": "AWS", "database": "your_sf_database", "ingestion_mode": "INCREMENTAL", "private_key": "-----BEGIN PRIVATE KEY----- privatekey\nseparatedwith\nnewlinecharacters=-----END PRIVATE KEY-----", "schema": "your_snowflake_schema", "service_account": "your_service_account", "storage_integration_object_name": "your_storage_integration_object", "max_file_size_mb": "512", "staging_s3_uri": "s3://your/s3/bucket/uri", "table_name_patterns": ".*", "translation_output_gcs_path": "gs://sf_test_translation/output/metadata/config/database_name/schema_name/", "username": "your_sf_username", "warehouse": "your_warehouse" }' bq mk --transfer_config \ --project_id=your_project_id \ --target_dataset=your_bq_dataset \ --display_name='snowflake transfer config' \ --params="$PARAMS" \ --data_source=snowflake_migration
API
Verwenden Sie die Methode projects.locations.transferConfigs.create und geben Sie eine Instanz der Ressource TransferConfig an.
Verschlüsselungsschlüssel mit Übertragungen angeben
Sie können kundenverwaltete Verschlüsselungsschlüssel (CMEKs) angeben, um Daten für eine Übertragungsausführung zu verschlüsseln. Sie können einen CMEK verwenden, um Übertragungen von Snowflake zu unterstützen.Wenn Sie einen CMEK mit einer Übertragung angeben, wendet der BigQuery Data Transfer Service den CMEK auf einen zwischengeschalteten Festplatten-Cache von aufgenommenen Daten an, sodass der gesamte Datenübertragungsworkflow CMEK-konform ist.
Sie können eine vorhandene Übertragung nicht aktualisieren, um einen CMEK hinzuzufügen, wenn die Übertragung nicht ursprünglich mit einem CMEK erstellt wurde. Sie können beispielsweise keine Zieltabelle ändern, die ursprünglich standardmäßig verschlüsselt wurde, um jetzt mit CMEK zu verschlüsseln. Umgekehrt können Sie eine CMEK-verschlüsselte Zieltabelle auch nicht auf einen anderen Verschlüsselungstyp ändern.
Sie können einen CMEK für eine Übertragung aktualisieren, wenn die Übertragungskonfiguration ursprünglich mit einer CMEK-Verschlüsselung erstellt wurde. Wenn Sie einen CMEK für eine Übertragungskonfiguration aktualisieren, leitet der BigQuery Data Transfer Service den CMEK bei der nächsten Ausführung der Übertragung an die Zieltabellen weiter, wobei der BigQuery Data Transfer Service während der Übertragungsausführung alle veralteten CMEKs durch den neuen CMEK ersetzt. Weitere Informationen finden Sie unter Übertragung aktualisieren.
Sie können auch Standardschlüssel für Projekte verwenden. Wenn Sie einen Projektstandardschlüssel für eine Übertragung angeben, verwendet der BigQuery Data Transfer Service den Standardschlüssel des Projekts als Standardschlüssel für neue Übertragungskonfigurationen.
Kontingente und Limits
BigQuery hat standardmäßig ein Ladekontingent von 15 TB pro Ladejob und Tabelle. Snowflake komprimiert die Tabellendaten intern. Daher ist die exportierte Tabellengröße größer als die von Snowflake gemeldete Tabellengröße.
Um die Ladezeiten für größere Tabellen zu verkürzen und das BigQuery-Ladelimit von 15 TB zu entfernen, geben Sie für die Reservierungszuweisung den Jobtyp PIPELINE an.
Aufgrund des Konsistenzmodells von Amazon S3 kann es sein, dass einige Dateien nicht in die Übertragung nach BigQuery einbezogen werden.
Leistung der Datenübertragung optimieren
Sie können die Leistung Ihrer Datenübertragungen überwachen, indem Sie die Logs für die Datenübertragung aufrufen. Wir empfehlen Ihnen, die folgenden Optimierungsschritte auszuführen, um die Leistung Ihrer Datenübertragungen zu verbessern:
- Snowflake-Instanz, Staging-Bucket und BigQuery-Dataset in derselben Region belassen
- Sie können die Geschwindigkeit beim Entladen von Tabellen verbessern, indem Sie Folgendes tun:
- Erhöhen Sie die Größe Ihres virtuellen Snowflake-Warehouse, insbesondere wenn Sie große Snowflake-Tabellen (1 TiB oder mehr) übertragen.
- Passen Sie die Option
MAX_FILE_SIZEin der Übertragungskonfiguration an.- Kleinere Dateien können die Übertragungsgeschwindigkeit verbessern, aber wenn sie zu klein sind, kann das zu einer zu großen Anzahl von Dateien führen.
- Sie können die Ladegeschwindigkeit von Tabellen verbessern, indem Sie die Anzahl der BigQuery-Slotreservierungen für die Jobtypen
PIPELINEundQUERYerhöhen. - Vermeiden Sie beim vollständigen Übertragen von Daten Clustering und Partitionierung in der BigQuery-Zieltabelle.
- Wenn Sie eine inkrementelle Übertragung im Upsert-Modus vornehmen, sollten Sie Clustering und Partitionierung für Primärschlüsselspalten in Betracht ziehen, um die Übertragungsleistung zu verbessern.
- Vermeiden Sie jedoch das Clustern und Partitionieren von Spalten, die keine Primärschlüsselspalten sind, um langsamere Zusammenführungsvorgänge zu verhindern.
Preise
Die Preise für BigQuery Data Transfer Service finden Sie auf der Seite Preise.
- Wenn sich das Snowflake-Warehouse und der Amazon S3-Bucket in verschiedenen Regionen befinden, berechnet Snowflake Gebühren für ausgehenden Traffic, wenn Sie eine Snowflake-Datenübertragung ausführen. Für Snowflake-Datenübertragungen fallen keine Egress-Gebühren an, wenn sich sowohl das Snowflake-Warehouse als auch der Amazon S3-Bucket in derselben Region befinden.
- Wenn Daten von AWS zu Google Cloudübertragen werden, fallen Gebühren für ausgehenden Traffic zwischen Clouds an.
Nächste Schritte
- Weitere Informationen zum BigQuery Data Transfer Service
- Migrieren Sie SQL-Code mit der Batch-SQL-Übersetzung.