
העברה מ-IBM Netezza
במאמר הזה מוסבר איך לבצע מיגרציה מ-IBM Netezza ל-BigQuery. במאמר הזה נסביר על ההבדלים הבסיסיים בארכיטקטורה בין Netezza לבין BigQuery, וגם על היכולות הנוספות ש-BigQuery מציע. בנוסף, הוא מסביר איך אפשר לשנות את מודל הנתונים הקיים ולבצע תהליכי חילוץ, טרנספורמציה וטעינה (ETL) כדי למקסם את היתרונות של BigQuery.
המסמך הזה מיועד לאדריכלים ארגוניים, לאדמיניסטרטורים של מסדי נתונים, למפתחי אפליקציות ולמומחי אבטחת IT שרוצים להעביר נתונים מ-Netezza ל-BigQuery ולפתור בעיות טכניות בתהליך ההעברה. במסמך הזה מפורטים השלבים הבאים בתהליך ההעברה:
- ייצוא נתונים
- הטמעת נתונים
- שימוש בכלים של צד שלישי
אפשר גם להשתמש בתרגום SQL באצווה כדי להעביר את סקריפטים של SQL בכמות גדולה, או בתרגום SQL אינטראקטיבי כדי לתרגם שאילתות אד-הוק. שני הכלים תומכים ב-Netezza SQL/NZPLSQL בגרסת Preview.
השוואה בין ארכיטקטורות
Netezza היא מערכת עוצמתית שיכולה לעזור לכם לאחסן ולנתח כמויות גדולות של נתונים. עם זאת, מערכת כמו Netezza דורשת השקעות גדולות בחומרה, בתחזוקה וברשיונות. קשה להרחיב את הפתרון הזה בגלל בעיות בניהול הצמתים, בנפח הנתונים לכל מקור ובעלויות הארכיון. ב-Netezza, קיבולת האחסון והעיבוד מוגבלת על ידי מכשירי חומרה. כשמגיעים לניצול המקסימלי, תהליך הרחבת הקיבולת של המכשיר מורכב ולפעמים הוא אפילו לא אפשרי.
עם BigQuery, אתם לא צריכים לנהל תשתית, ולא צריך אדמין של מסד נתונים. BigQuery הוא מחסן נתונים (data warehouse) מנוהל, ללא שרתים, בקנה מידה של פטה-בייט, שיכול לסרוק מיליארדי שורות בלי אינדקס תוך עשרות שניות. מכיוון ש-BigQuery חולק את התשתית של Google, הוא יכול להריץ כל שאילתה במקביל על עשרות אלפי שרתים. הטכנולוגיות הבאות מבדילות את BigQuery מפתרונות אחרים:
- אחסון עמודות. הנתונים מאוחסנים בעמודות ולא בשורות, ולכן אפשר להשיג יחס דחיסה גבוה מאוד וקצב העברה גבוה של נתונים.
- ארכיטקטורת עץ. השאילתות נשלחות והתוצאות מצטברות באלפי מחשבים תוך כמה שניות.
ארכיטקטורת Netezza
Netezza הוא מכשיר עם האצת חומרה שמגיע עם שכבת הפשטה של נתונים בתוכנה. שכבת הפשטת הנתונים מנהלת את חלוקת הנתונים במכשיר ומבצעת אופטימיזציה של השאילתות על ידי חלוקת עיבוד הנתונים בין המעבדים וה-FPGAs הבסיסיים.
התמיכה במודלים Netezza TwinFin ו-Striper הסתיימה ביוני 2019.
התרשים הבא ממחיש את שכבות הפשטת הנתונים ב-Netezza:
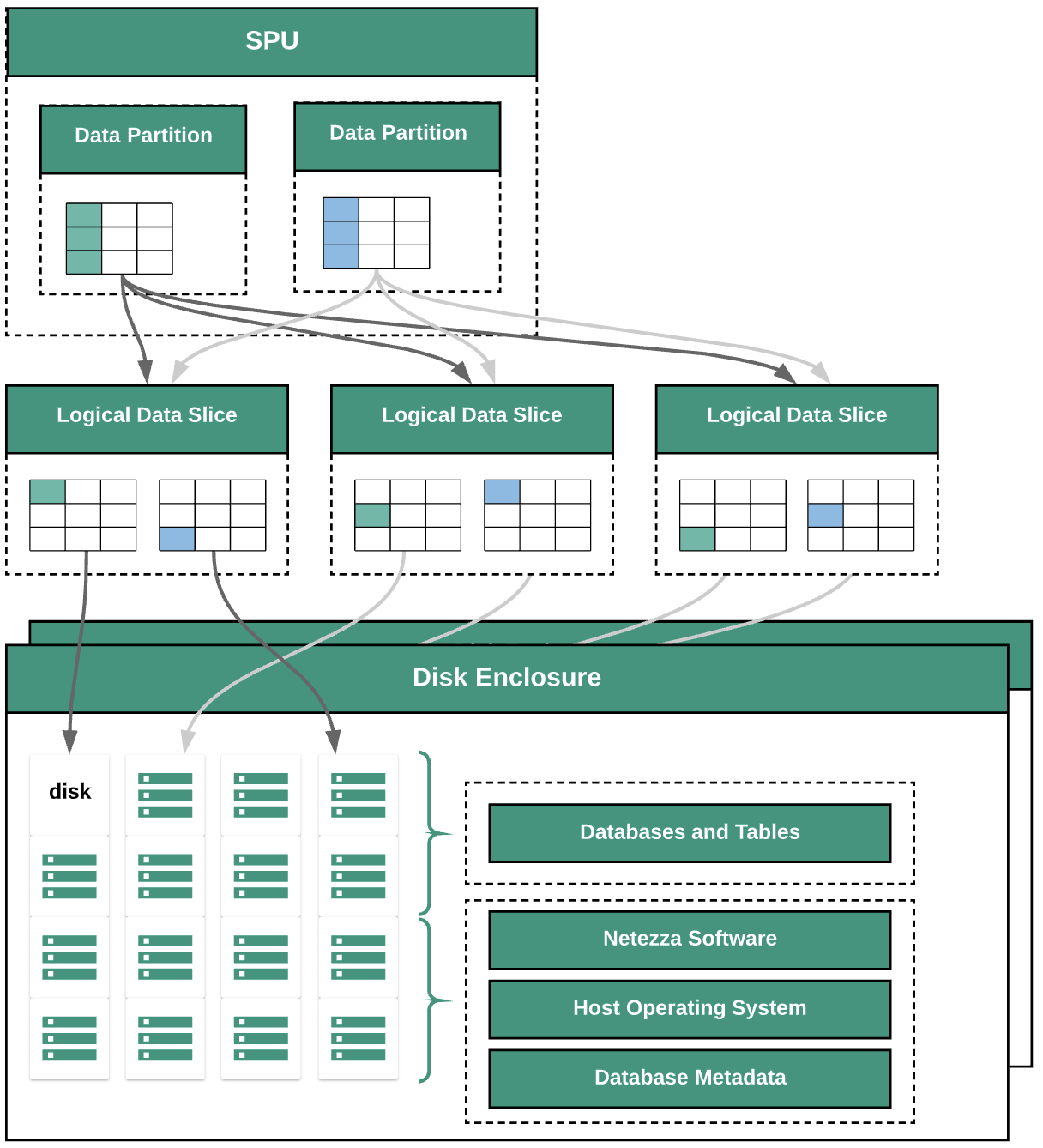
בתרשים מוצגות שכבות ההפשטה הבאות של הנתונים:
- מארז דיסק. המרחב הפיזי בתוך המכשיר שבו הדיסקים מותקנים.
- Disks כוננים פיזיים בתוך מארזי הדיסקים מאחסנים את מסדי הנתונים והטבלאות.
- פרוסות נתונים. ייצוג לוגי של הנתונים שנשמרים בדיסק.
הנתונים מופצים בין פרוסות הנתונים באמצעות מפתח הפצה. אפשר לעקוב אחרי הסטטוס של פרוסות הנתונים באמצעות פקודות
nzds. - מחיצות נתונים. ייצוג לוגי של פרוסת נתונים שמנוהלת על ידי יחידות עיבוד של קטעי קוד (SPU) ספציפיות. כל יחידת SPU היא הבעלים של מחיצת נתונים אחת או יותר שמכילה את נתוני המשתמש שהיחידה אחראית לעיבוד שלהם במהלך שאילתות.
כל רכיבי המערכת מחוברים באמצעות רשת. מכשיר Netezza מריץ פרוטוקול מותאם אישית שמבוסס על כתובות IP.
ארכיטקטורת BigQuery
BigQuery הוא מחסן נתונים ארגוני מנוהל שמאפשר לכם לנהל ולנתח את הנתונים שלכם באמצעות תכונות מובנות כמו למידת מכונה, ניתוח גיאוגרפי ובינה עסקית. מידע נוסף זמין במאמר סקירה כללית של BigQuery.
BigQuery מטפל באחסון ובחישובים כדי לספק אחסון נתונים עמיד ותגובות מהירות לשאילתות ניתוח. מידע נוסף זמין במאמר הסבר על BigQuery.
מידע על התמחור של BigQuery זמין במאמר הסבר על ההתאמה המהירה של BigQuery והתמחור הפשוט שלו.
לפני ההעברה
כדי להבטיח שהעברת מחסן הנתונים תהיה מוצלחת, מומלץ להתחיל לתכנן את אסטרטגיית ההעברה בשלב מוקדם בציר הזמן של הפרויקט. מידע על תכנון שיטתי של עבודת ההעברה זמין במאמר מה מעבירים ואיך מעבירים: מסגרת ההעברה.
תכנון הקיבולת ב-BigQuery
התפוקה של Analytics ב-BigQuery נמדדת במשבצות. יחידת קיבולת של BigQuery היא יחידת מחשוב קניינית של Google, שכוללת זיכרון RAM וקצב העברת נתונים ברשת, שנדרשים להרצת שאילתות SQL. BigQuery מחשב באופן אוטומטי כמה משבצות נדרשות לכל שאילתה, בהתאם לגודל ולמורכבות של השאילתה.
כדי להריץ שאילתות ב-BigQuery, צריך לבחור אחד ממודלי התמחור הבאים:
- על פי דרישה. מודל התמחור שמוגדר כברירת מחדל, שבו אתם מחויבים על מספר הבייטים שעובדו על ידי כל שאילתה.
- תמחור מבוסס-קיבולת. אתם רוכשים משבצות, שהן מעבדים וירטואליים (CPU). כשקונים יחידות קיבולת, קונים קיבולת עיבוד ייעודית שאפשר להשתמש בה כדי להריץ שאילתות. יחידות הקיבולת (Slots) זמינות בתוכניות הבאות עם התחייבות:
- שנתי. אתם מתחייבים ל-365 ימים.
- שלוש שנים. אתם מתחייבים ל-365*3 ימים.
יש כמה דברים דומים בין יחידת קיבולת של BigQuery לבין יחידות עיבוד סימטריות (SPU) ב-Netezza, כמו מעבד, זיכרון ועיבוד נתונים. עם זאת, הן לא מייצגות את אותה יחידת מידה. ל-SPU ב-Netezza יש מיפוי קבוע לרכיבי החומרה הבסיסיים, בעוד שיחידת קיבולת של BigQuery מייצגת מעבד וירטואלי שמשמש להרצת שאילתות. כדי לעזור לכם להעריך את מספר המשבצות, מומלץ להגדיר מעקב אחרי BigQuery באמצעות Cloud Monitoring ולנתח את יומני הביקורת באמצעות BigQuery. כדי להציג את נתוני השימוש ביחידות קיבולת של BigQuery, אפשר גם להשתמש בכלים כמו Data Studio או Looker. מעקב וניתוח קבועים של השימוש במשבצות עוזרים להעריך כמה משבצות סך הכול הארגון צריך ככל שהוא מתפתח ב- Google Cloud.
לדוגמה, נניח שבהתחלה שריינתם 2,000 יחידות קיבולת (Slot) ב-BigQuery כדי להריץ 50 שאילתות ברמת מורכבות בינונית בו-זמנית. אם השאילתות נמשכות באופן עקבי יותר מכמה שעות והשימוש במשבצות בלוחות הבקרה גבוה, יכול להיות שהשאילתות לא מותאמות או שאתם צריכים משבצות נוספות ב-BigQuery כדי לתמוך בעומסי העבודה. כדי לרכוש בעצמכם יחידות קיבולת (Slots) בהתחייבות לשימוש לשנה או לשלוש שנים, אתם יכולים ליצור הזמנות של BigQuery באמצעות המסוף Google Cloud או כלי שורת הפקודה של BigQuery. אם חתמתם על הסכם אופליין לרכישה לפי נפח אחסון, יכול להיות שהתוכנית שלכם שונה מהפרטים שמתוארים כאן.
מידע על ניהול העלויות של אחסון ועיבוד שאילתות ב-BigQuery זמין במאמר אופטימיזציה של עומסי עבודה.
אבטחה ב Google Cloud
בקטעים הבאים מתוארים אמצעי אבטחה נפוצים ב-Netezza ומוסבר איך אפשר לעזור בהגנה על מחסן הנתונים בסביבת Google Cloud .
ניהול זהויות והרשאות גישה
מסד הנתונים של Netezza מכיל קבוצה של יכולות בקרת גישה משולבות באופן מלא במערכת, שמאפשרות למשתמשים לגשת למשאבים שהם מורשים לגשת אליהם.
הגישה ל-Netezza נשלטת דרך הרשת למכשיר Netezza על ידי ניהול חשבונות המשתמשים ב-Linux שיכולים להיכנס למערכת ההפעלה. הגישה למסד הנתונים, לאובייקטים ולמשימות של Netezza מנוהלת באמצעות חשבונות משתמשים במסד הנתונים של Netezza, שיכולים ליצור חיבורי SQL למערכת.
ב-BigQuery נעשה שימוש בשירות ניהול הזהויות והרשאות הגישה (IAM) של Google כדי לנהל את הגישה למשאבים. סוגי המשאבים שזמינים ב-BigQuery הם ארגונים, פרויקטים, מערכי נתונים, טבלאות ותצוגות. בהיררכיית מדיניות IAM, מערכי נתונים הם משאבי צאצא של פרויקטים. טבלה מקבלת את ההרשאות ממערך הנתונים שהיא כלולה בו.
כדי להעניק גישה למשאב, מקצים תפקיד אחד או יותר למשתמש, לקבוצה או לחשבון שירות. תפקידים בארגון ובפרויקט שולטים בגישה להרצת משימות או לניהול הפרויקט, בעוד שתפקידים במערך נתונים שולטים בגישה לצפייה בנתונים בתוך פרויקט או לשינוי שלהם.
IAM מספק את סוגי התפקידים הבאים:
- תפקידים מוגדרים מראש. כדי לתמוך בתרחישי שימוש נפוצים ובדפוסי בקרת גישה.
- תפקידים בסיסיים. כוללים את התפקידים 'בעלים', 'עריכה' ו'צפייה'. תפקידים בסיסיים מאפשרים גישה פרטנית לשירותים ספציפיים ומנוהלים על ידי Google Cloud.
- תפקידים בהתאמה אישית. גישה פרטנית בהתאם לרשימת ההרשאות שנבחרו.
כשמקצים למשתמש תפקידים מוגדרים מראש ותפקידים בסיסיים, ההרשאות שניתנות לו הן איחוד של ההרשאות של כל תפקיד בנפרד.
אבטחה ברמת השורה
אבטחה רב-שכבתית היא מודל אבטחה מופשט שמשמש את Netezza להגדרת כללים לשליטה בגישת המשתמשים אל טבלאות מאובטחות ברמת השורה (RST). טבלה עם אבטחה ברמת השורה היא טבלת מסד נתונים עם תוויות אבטחה בשורות, שמסננות משתמשים שאין להם את ההרשאות המתאימות. התוצאות שמוחזרות בשאילתות שונות בהתאם להרשאות של המשתמש שמבצע את השאילתה.
כדי להשיג אבטחה ברמת השורה ב-BigQuery, אפשר להשתמש בתצוגות מורשות ובמדיניות גישה ברמת השורה. מידע נוסף על תכנון והטמעה של המדיניות הזו זמין במאמר מבוא לאבטחה ברמת השורה ב-BigQuery.
הצפנת נתונים
מכשירי Netezza משתמשים בכוננים עם הצפנה עצמית (SED) כדי לשפר את האבטחה וההגנה של הנתונים שמאוחסנים במכשיר. מכשירי SED מצפינים את הנתונים כשהם נכתבים בדיסק. לכל דיסק יש מפתח להצפנת דיסק (DEK) שמוגדר במפעל ומאוחסן בדיסק. הדיסק משתמש ב-DEK כדי להצפין את הנתונים בזמן הכתיבה, ואז כדי לפענח את הנתונים בזמן הקריאה מהדיסק. הפעולה של הדיסק, ההצפנה והפענוח שלו, שקופים למשתמשים שקוראים וכותבים נתונים. מצב ברירת המחדל הזה של הצפנה ופענוח נקרא מצב מחיקה מאובטחת.
במצב מחיקה מאובטחת, לא צריך מפתח אימות או סיסמה כדי לפענח ולקרוא נתונים. כונני SED מציעים יכולות משופרות למחיקה מאובטחת מהירה ויעילה במצבים שבהם צריך להשתמש בדיסקים למטרה אחרת או להחזיר אותם לצורך תמיכה או במסגרת אחריות.
Netezza משתמשת בהצפנה סימטרית. אם הנתונים שלכם מוצפנים ברמת השדה, פונקציית הפענוח הבאה יכולה לעזור לכם לקרוא ולייצא את הנתונים:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
כל הנתונים שמאוחסנים ב-BigQuery מוצפנים במצב מנוחה. אם אתם רוצים לשלוט בהצפנה בעצמכם, אתם יכולים להשתמש במפתחות הצפנה בניהול הלקוח (CMEK) ב-BigQuery. ב-CMEK, במקום ש-Google תנהל את מפתחות הצפנת המפתחות שמגנים על הנתונים שלכם, אתם שולטים במפתחות הצפנת המפתחות ומנהלים אותם ב-Cloud Key Management Service. מידע נוסף זמין במאמר בנושא הצפנה במנוחה.
השוואת ביצועים
כדי לעקוב אחרי ההתקדמות והשיפורים במהלך תהליך ההעברה, חשוב לקבוע את רמת הביצועים הבסיסית של סביבת Netezza הנוכחית. כדי לקבוע את נקודת הבסיס, בוחרים קבוצה של שאילתות מייצגות שנאספו מהאפליקציות שצורכות את הנתונים (כמו Tableau או Cognos).
| סביבה | Netezza | BigQuery |
|---|---|---|
| גודל הנתונים | size TB | - |
| שאילתה 1: name (סריקה מלאה של הטבלה) | mm:ss.ms | - |
| שאילתה 2: name | mm:ss.ms | - |
| שאילתה 3: name | mm:ss.ms | - |
| סה"כ | mm:ss.ms | - |
הגדרת פרויקט בסיסית
לפני שמקצים משאבי אחסון להעברת נתונים, צריך להשלים את הגדרת הפרויקט.
- הוראות להגדרת פרויקטים ולהפעלת IAM ברמת הפרויקט מופיעות במאמר Google Cloud Well-Architected Framework.
- במאמר עיצוב אזור נחיתה ב- Google Cloud מוסבר איך לעצב משאבים בסיסיים כדי שהפריסה בענן תהיה מוכנה לשימוש בארגון.
- מידע על ניהול נתונים ואמצעי הבקרה שצריך להשתמש בהם כשמעבירים מחסן נתונים מקומי ל-BigQuery זמין במאמר סקירה כללית על אבטחת נתונים וניהול נתונים.
קישוריות רשת
צריך חיבור רשת אמין ומאובטח בין מרכז הנתונים המקומי (שבו פועל מופע Netezza) לבין סביבת Google Cloud. מידע על אבטחת החיבור זמין במאמר מבוא למשילות מידע ב-BigQuery. כשמעלים תמציות נתונים, רוחב הפס של הרשת יכול להיות גורם מגביל. מידע על עמידה בדרישות להעברת נתונים זמין במאמר הגדלת רוחב הפס ברשת.
סוגי נתונים ומאפיינים נתמכים
סוגי הנתונים ב-Netezza שונים מסוגי הנתונים ב-BigQuery. מידע על סוגי נתונים ב-BigQuery זמין במאמר בנושא סוגי נתונים. השוואה מפורטת בין סוגי הנתונים ב-Netezza וב-BigQuery זמינה במדריך לתרגום SQL של IBM Netezza.
השוואת SQL
נתוני SQL של Netezza מורכבים מ-DDL, DML ושפת בקרת נתונים (DCL) שייחודית ל-Netezza, ושונה מ-GoogleSQL. GoogleSQL תואם לתקן SQL 2011 ויש לו הרחבות שתומכות בשאילתות של נתונים מקוננים וחוזרים. אם אתם משתמשים ב-SQL מדור קודם ב-BigQuery, תוכלו לעיין במאמר בנושא פונקציות ואופרטורים של SQL מדור קודם. למידע מפורט על ההבדלים בין Netezza SQL לבין SQL ופונקציות של BigQuery, אפשר לעיין במדריך לתרגום SQL של IBM Netezza.
כדי לעזור לכם בהעברת קוד SQL, אתם יכולים להשתמש בתרגום SQL באצווה כדי להעביר את קוד ה-SQL בכמות גדולה, או בתרגום SQL אינטראקטיבי כדי לתרגם שאילתות אד-הוק.
השוואה בין פונקציות
חשוב להבין איך פונקציות Netezza ממופות לפונקציות BigQuery. לדוגמה, הפונקציה Months_Between
ב-Netezza מחזירה ערך עשרוני, בעוד שהפונקציה DateDiff
ב-BigQuery מחזירה מספר שלם. לכן, צריך להשתמש בפונקציית UDF מותאמת אישית כדי להפיק את סוג הנתונים הנכון. במדריך לתרגום של IBM Netezza SQL יש השוואה מפורטת בין פונקציות של Netezza SQL ושל GoogleSQL.
העברת נתונים
כדי להעביר נתונים מ-Netezza ל-BigQuery, צריך לייצא את הנתונים מ-Netezza, להעביר אותם ל- Google Cloudולשמור אותם שם, ואז לטעון את הנתונים ל-BigQuery. בקטע הזה יש סקירה כללית של תהליך העברת הנתונים. תיאור מפורט של תהליך העברת הנתונים מופיע במאמר סכימה ותהליך העברת נתונים. השוואה מפורטת בין סוגי הנתונים הנתמכים ב-Netezza וב-BigQuery מופיעה במדריך לתרגום SQL של IBM Netezza.
ייצוא נתונים מ-Netezza
כדי לייצא נתונים מטבלאות של מסד נתונים ב-Netezza, מומלץ לייצא לטבלה חיצונית בפורמט CSV. מידע נוסף זמין במאמר בנושא העברת נתונים למערכת לקוח מרוחקת. אפשר גם לקרוא נתונים באמצעות מערכות של צד שלישי כמו Informatica (או ETL בהתאמה אישית) באמצעות מחברי JDBC/ODBC כדי ליצור קובצי CSV.
מערכת Netezza תומכת רק בייצוא של קבצים שטוחים לא דחוסים (CSV) לכל טבלה.
עם זאת, אם מייצאים טבלאות גדולות, קובץ ה-CSV הלא דחוס יכול להיות גדול מאוד. אם אפשר, כדאי להמיר את קובץ ה-CSV לפורמט עם סכימה, כמו Parquet, Avro או ORC. כך תקבלו קובצי ייצוא קטנים יותר עם מהימנות גבוהה יותר. אם CSV הוא הפורמט הזמין היחיד, מומלץ לדחוס את קובצי הייצוא כדי להקטין את גודל הקובץ לפני ההעלאה אל Google Cloud.
הקטנת גודל הקובץ עוזרת להעלות אותו מהר יותר ומשפרת את מהימנות ההעברה. אם מעבירים קבצים ל-Cloud Storage, אפשר להשתמש בדגל --gzip-local בפקודה gcloud storage cp, שדוחסת את הקבצים לפני ההעלאה.
העברה והכנה של נתונים
אחרי ייצוא הנתונים, צריך להעביר אותם ולשמור אותם ב-Google Cloud. יש כמה אפשרויות להעברת הנתונים, בהתאם לכמות הנתונים שאתם מעבירים ולרוחב הפס הזמין ברשת. מידע נוסף זמין במאמר סקירה כללית על סכימה והעברת נתונים.
כשמשתמשים ב-Google Cloud CLI, אפשר להפוך את העברת הקבצים ל-Cloud Storage לאוטומטית ולבצע אותה במקביל. כדי לטעון את הקבצים מהר יותר ל-BigQuery, מומלץ להגביל את גודל הקבצים ל-4TB (לא דחוסים). עם זאת, צריך לייצא את הסכימה מראש. זו הזדמנות טובה לבצע אופטימיזציה של BigQuery באמצעות חלוקה למחיצות (partitioning) וקיבוץ לאשכולות (clustering).
משתמשים ב-gcloud storage bucket create כדי ליצור את קטגוריות הביניים לאחסון הנתונים המיוצאים, וב-gcloud storage cp כדי להעביר את קובצי ייצוא הנתונים לקטגוריות של Cloud Storage.
ה-CLI של gcloud מבצע את פעולת ההעתקה באופן אוטומטי באמצעות שילוב של ריבוי שרשורים ועיבוד מרובה.
טעינת נתונים ל-BigQuery
אחרי שהנתונים מוכנים ב- Google Cloud, יש כמה אפשרויות לטעינת הנתונים ב-BigQuery. מידע נוסף זמין במאמר בנושא טעינת הסכימה והנתונים ל-BigQuery.
כלים ותמיכה לשותפים
אתם יכולים לקבל תמיכה משותף במהלך תהליך המעבר. כדי לעזור לכם בהעברת קוד SQL, אתם יכולים להשתמש בתרגום SQL בכמות גדולה כדי להעביר את קוד ה-SQL שלכם בכמות גדולה.
הרבה Google Cloud שותפים מציעים גם שירותים להעברת מחסני נתונים. רשימת השותפים והפתרונות שהם מספקים זמינה במאמר עבודה עם שותף בעל מומחיות ב-BigQuery.
אחרי ההעברה
אחרי שמעבירים את הנתונים, אפשר להתחיל לייעל את השימוש ב-Google Cloud כדי לפתור בעיות שקשורות לצרכים העסקיים. לדוגמה, שימוש בכלי החיפוש וההדמיה שלGoogle Cloudכדי להפיק תובנות עבור בעלי עניין עסקיים, ביצוע אופטימיזציה של שאילתות עם ביצועים נמוכים או פיתוח תוכנית שתעזור למשתמשים לאמץ את המוצר.
התחברות ל-BigQuery APIs דרך האינטרנט
בתרשים הבא אפשר לראות איך אפליקציה חיצונית יכולה להתחבר ל-BigQuery באמצעות ה-API:
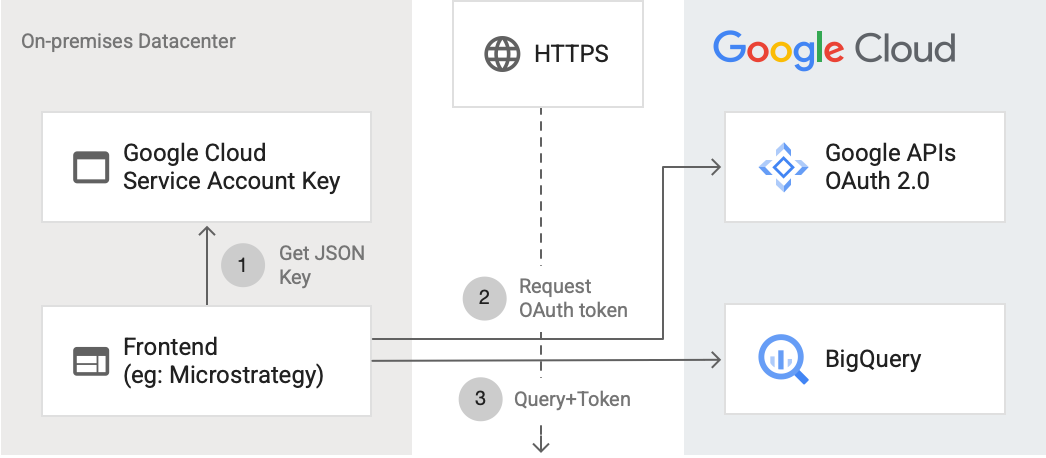
בתרשים מוצגים השלבים הבאים:
- ב- Google Cloud, נוצר חשבון שירות עם הרשאות IAM. מפתח חשבון השירות נוצר בפורמט JSON ומועתק לשרת הקצה הקדמי (לדוגמה, MicroStrategy).
- הקצה הקדמי קורא את המפתח ומבקש אסימון OAuth מ-Google APIs ב-HTTPS.
- לאחר מכן, ממשק הקצה שולח בקשות ל-BigQuery יחד עם הטוקן.
מידע נוסף מופיע במאמר בנושא אישור בקשות API.
אופטימיזציה ל-BigQuery
GoogleSQL תומך בתאימות לתקן SQL 2011 ויש לו תוספים שתומכים בשאילתות של נתונים מקוננים וחוזרים. אופטימיזציה של שאילתות ל-BigQuery היא חיונית לשיפור הביצועים וזמן התגובה.
החלפת הפונקציה Months_Between ב-BigQuery באמצעות UDF
ב-Netezza, מספר הימים בחודש הוא 31. הפונקציה המותאמת אישית הבאה של UDF יוצרת מחדש את הפונקציה של Netezza עם רמת דיוק גבוהה, ואפשר להפעיל אותה מהשאילתות:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
העברת תהליכים מאוחסנים ב-Netezza
אם אתם משתמשים בפרוצדורות מאוחסנות של Netezza בעומסי עבודה של ETL כדי ליצור טבלאות עובדות, אתם צריכים להעביר את הפרוצדורות המאוחסנות האלה לשאילתות SQL שתואמות ל-BigQuery. ב-Netezza משתמשים בשפת הסקריפטים NZPLSQL כדי לעבוד עם נהלים מאוחסנים. NZPLSQL מבוססת על השפה Postgres PL/pgSQL. מידע נוסף אפשר למצוא במדריך לתרגום SQL של IBM Netezza.
פונקציה מוגדרת על ידי המשתמש (UDF) בהתאמה אישית כדי לדמות ASCII של Netezza
הפונקציה המותאמת אישית הבאה של BigQuery מתקנת שגיאות קידוד בעמודות:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
המאמרים הבאים
- איך מבצעים אופטימיזציה של עומסי עבודה כדי לשפר את הביצועים הכוללים ולהפחית את העלויות.
- איך מייעלים את האחסון ב-BigQuery
- מומלץ לעיין במדריך לתרגום SQL של IBM Netezza.