
סקירה כללית על BigQuery
BigQuery היא פלטפורמת נתונים מנוהלת לחלוטין שמוכנה לשימוש ב-AI. היא עוזרת לכם לנהל ולנתח את הנתונים שלכם באמצעות תכונות מובנות כמו למידת מכונה, חיפוש, ניתוח גיאוספציאלי ובינה עסקית. הארכיטקטורה ללא שרת (serverless) של BigQuery מאפשרת לכם להשתמש בשפות כמו SQL ו-Python כדי לענות על השאלות הכי חשובות של הארגון, בלי שתצטרכו לנהל את התשתית.
BigQuery מספק דרך אחידה לעבודה עם נתונים מובנים ולא מובנים, ותומך בפורמטים פתוחים של טבלאות כמו Apache Iceberg, Delta ו-Apache Hudi. הזרמת נתונים ב-BigQuery תומכת בהטמעה ובניתוח רציפים של נתונים, ומנוע הניתוח המבוזר והניתן להרחבה של BigQuery מאפשר לכם להריץ שאילתות על טרה-בייט של נתונים בשניות ועל פטה-בייט של נתונים בדקות.
ל-BigQuery יש יכולות מובנות של ניהול נתונים שמאפשרות לכם לגלות ולסדר נתונים, ולנהל מטא-נתונים ואיכות נתונים. באמצעות תכונות כמו חיפוש סמנטי ושיוך נתונים למקור, אתם יכולים למצוא ולאמת נתונים רלוונטיים לניתוח. אתם יכולים לשתף נתונים ונכסי AI בארגון שלכם וליהנות מיתרונות בקרת הגישה. התכונות האלה מבוססות על Dataplex Universal Catalog, שהוא פתרון מאוחד וחכם למשילות נתונים ולנכסי AI ב- Google Cloud.הארכיטקטורה של BigQuery מורכבת משני חלקים: שכבת אחסון שמטמיעה, מאחסנת ומבצעת אופטימיזציה של נתונים, ושכבת מחשוב שמספקת יכולות ניתוח. שכבות המחשוב והאחסון האלה פועלות ביעילות באופן עצמאי זו מזו, הודות לרשת של Google בקנה מידה של פטה-ביט, שמאפשרת את התקשורת הנדרשת ביניהן.
בדרך כלל, מסדי נתונים מדור קודם צריכים לחלוק משאבים בין פעולות קריאה וכתיבה לבין פעולות ניתוח. זה עלול לגרום לקונפליקטים במשאבים ולהאט את השאילתות בזמן כתיבת נתונים לאחסון או קריאת נתונים מהאחסון. העומס על מאגרי משאבים משותפים יכול לגדול עוד יותר כשנדרשים משאבים למשימות ניהול מסדי נתונים, כמו הקצאה או ביטול של הרשאות. ההפרדה בין שכבות החישוב והאחסון ב-BigQuery מאפשרת לכל שכבה להקצות משאבים באופן דינמי בלי להשפיע על הביצועים או על הזמינות של השכבה השנייה.
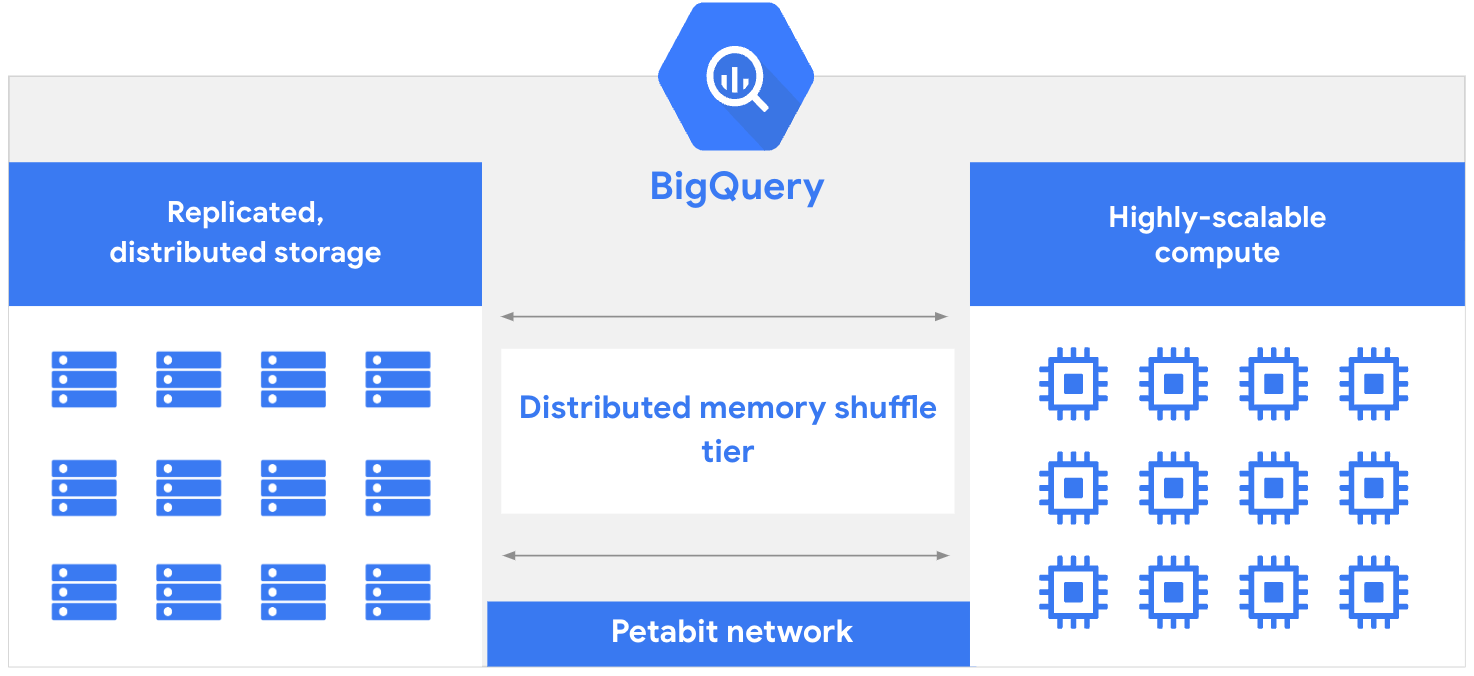
העיקרון הזה מאפשר ל-BigQuery לחדש מהר יותר כי אפשר לפרוס שיפורים באחסון ובחישוב באופן עצמאי, בלי השבתה או השפעה שלילית על ביצועי המערכת. בנוסף, חשוב להציע מחסן נתונים (data warehouse) ללא שרתים שמנוהל באופן מלא, שבו צוות ההנדסה של BigQuery מטפל בעדכונים ובתחזוקה. התוצאה היא שלא צריך להקצות משאבים או לשנות את גודלם באופן ידני, כך שתוכלו להתמקד בהעברת ערך במקום במשימות ניהול מסדי נתונים מסורתיות.
ממשקי BigQuery כוללים את ממשק Google Cloud המסוף ואת כלי שורת הפקודה של BigQuery. מפתחים ומדעני נתונים יכולים להשתמש בספריות לקוח עם תכנות מוכר, כולל Python, Java, JavaScript ו-Go, וגם ב-API בארכיטקטורת REST וב-RPC API של BigQuery כדי לשנות ולנהל נתונים. דרייברים של ODBC ו-JDBC מאפשרים אינטראקציה עם אפליקציות קיימות, כולל כלים וכלי עזר של צד שלישי.
אם אתם עובדים כנתוני אנליטיקה, מהנדסי מערכות מידע, מנהלי מחסני נתונים או מדעני נתונים, BigQuery יכול לעזור לכם לטעון, לעבד ולנתח נתונים כדי לקבל החלטות עסקיות חשובות.
איך מתחילים לעבוד עם BigQuery
אפשר להתחיל להתנסות ב-BigQuery תוך דקות. כדי להתחיל לטעון נתונים ולהריץ עליהם שאילתות, אפשר להשתמש בתוכנית השימוש החינמית של BigQuery או בארגז החול ללא עלות.
- ארגז החול של BigQuery: אפשר להתחיל להשתמש בארגז החול של BigQuery ללא סיכון וללא עלות.
- מערכי נתונים ציבוריים: תוכלו לבדוק את הביצועים של BigQuery באמצעות נתונים גדולים מהעולם האמיתי מתוכנית מערכי הנתונים הציבוריים.
- Google Cloud מדריך למתחילים לשימוש במסוף: כדאי להכיר את היכולות של BigQuery Studio.
עיון ב-BigQuery
התשתית ללא שרת (serverless) של BigQuery מאפשרת לכם להתמקד בנתונים במקום בניהול משאבים. BigQuery משלב מחסן נתונים בענן עם כלי ניתוח מתקדמים.
אחסון BigQuery
BigQuery מאחסן נתונים בפורמט אחסון עמודתי שעבר אופטימיזציה לשאילתות ניתוחיות. הנתונים ב-BigQuery מוצגים בטבלאות, בשורות ובעמודות, ויש תמיכה מלאה בסמנטיקה של טרנזקציות במסד נתונים (ACID). האחסון ב-BigQuery משוכפל באופן אוטומטי בכמה מיקומים כדי לספק זמינות גבוהה.
- מידע על דפוסים נפוצים לארגון משאבי BigQuery במחסן הנתונים ובשווקי הנתונים.
- מידע על מערכי נתונים, המאגר ברמה העליונה של טבלאות ותצוגות ב-BigQuery.
- שירות העברת נתונים ל-BigQuery מבצע אוטומציה של הטמעת נתונים.
- טעינת נתונים ל-BigQuery באמצעות:
- הזרמת נתונים באמצעות Storage Write API.
- טעינת נתונים באצווה מקבצים מקומיים או מ-Cloud Storage באמצעות פורמטים שכוללים: Avro, Parquet, ORC, CSV, JSON, Datastoreו-Firestore.
מידע נוסף זמין במאמר סקירה כללית של האחסון ב-BigQuery.
ניתוח נתונים ב-BigQuery
ניתוח תיאורי וניתוח פרסקריפטיבי משמשים בין היתר לבינה עסקית, לניתוח אד-הוק, לניתוח גיאו-מרחבי וללמידת מכונה. אפשר להריץ שאילתות על נתונים שמאוחסנים ב-BigQuery או על נתונים שמאוחסנים במקום אחר באמצעות טבלאות חיצוניות או שאילתות מאוחדות, כולל נתונים ב-Cloud Storage, ב-Bigtable, ב-Spanner או ב-Google Sheets שמאוחסנים ב-Google Drive.
- שאילתות SQL בתקן ANSI (תמיכה ב-ISO/IEC 9075) כולל תמיכה בצירופים, בשדות מקוננים וחוזרים, בפונקציות ניתוח וצבירה, בשאילתות מרובות הצהרות ובמגוון פונקציות מרחביות עם ניתוח גיאוגרפי – מערכות מידע גיאוגרפיות.
- יוצרים תצוגות כדי לשתף את הניתוח.
- תמיכה בכלי בינה עסקית, כולל BI Engine עם Looker Studio, Looker, Google Sheets וכלים של צד שלישי כמו Tableau ו-Power BI.
- BigQuery ML מספק למידת מכונה וחיזוי אנליטי.
- BigQuery Studio מציע תכונות כמו מחברות Python ובקרת גרסאות למחברות ולשאילתות שמורות. התכונות האלה מקלות על השלמת תהליכי העבודה של ניתוח הנתונים ולמידת המכונה (ML) ב-BigQuery.
- הפעלת שאילתות על נתונים מחוץ ל-BigQuery באמצעות שאילתות מאוחדות וטבלאות חיצוניות.
מידע נוסף זמין במאמר סקירה כללית על ניתוח הנתונים ב-BigQuery.
ניהול BigQuery
BigQuery מספק ניהול מרכזי של נתונים ומשאבי מחשוב, וניהול זהויות וגישה (IAM) עוזר לאבטח את המשאבים האלה באמצעות מודל הגישה שמשמש בכל Google Cloud.השיטות המומלצות לאבטחה מספקות גישה מוצקה אך גמישה שיכולה לכלול אבטחה היקפית או גישה מורכבת ומפורטת יותר של הגנה לעומק.Google Cloud
- מבוא לאבטחת נתונים ולניהול נתונים עוזר להבין מהו ניהול נתונים, ואילו אמצעי בקרה עשויים להידרש כדי לאבטח משאבי BigQuery.
- משימות הן פעולות ש-BigQuery מריץ בשמכם כדי לטעון, לייצא, לשלוח שאילתות או להעתיק נתונים.
- הזמנות מאפשרות לכם לעבור בין תמחור על פי דרישה לבין תמחור על בסיס קיבולת.
מידע נוסף זמין במאמר מבוא לניהול BigQuery.
משאבים ב-BigQuery
עיון במשאבים של BigQuery:
- בנתוני הגרסה מפורטים יומני שינויים של תכונות, שינויים והוצאות משימוש.
- תמחור לניתוח ולאחסון. ראו גם: תמחור של BigQuery ML, תמחור של BI Engine ותמחור של שירות העברת נתונים.
- מיקומים מגדירים איפה יוצרים ומאחסנים מערכי נתונים (מיקומים אזוריים ומיקומים במספר אזורים).
- ב-Stack Overflow יש קהילה פעילה של מפתחים ומנתחים שעובדים עם BigQuery.
- צוות התמיכה של BigQuery מספק עזרה בנושא BigQuery.
- Google BigQuery: The Definitive Guide: Data Warehousing, Analytics, and Machine Learning at Scale מאת Valliappa Lakshmanan ו-Jordan Tigani, מסביר איך BigQuery פועל ומספק הדרכה מקיפה על השימוש בשירות.
ממשקי API, כלים וחומרי עזר
חומרי עזר למפתחים ולמנתחים של BigQuery:
- BigQuery API וספריות לקוח מספקים סקירות כלליות של התכונות של BigQuery והשימוש בהן.
- תחביר של שאילתות SQL לפרטים על השימוש ב-GoogleSQL.
- דוגמאות קוד של BigQuery מספקות מאות קטעי קוד לספריות לקוח ב-C#, Go, Java, Node.js, Python ו-Ruby. אפשר גם לעיין בדפדפן לדוגמה.
- תחביר של DML, DDL ופונקציות מוגדרות על ידי המשתמש (UDF)מאפשר לכם לנהל את הנתונים ב-BigQuery ולבצע בהם טרנספורמציה.
- מאמרי עזרה בנושא כלי שורת הפקודה של BigQuery מוסבר על התחביר, הפקודות, הדגלים והארגומנטים של ממשק ה-CLI
bq. - שילוב של ODBC / JDBC חיבור של BigQuery לכלים ולתשתית הקיימים.
תכונות של Gemini ב-BigQuery
Gemini ב-BigQuery הוא חלק מחבילת המוצרים Gemini for Google Cloud, שמספקת עזרה מבוססת-AI בעבודה עם הנתונים.
Gemini ב-BigQuery מספק תמיכה מבוססת-AI שתעזור לכם:
- איך בודקים את הנתונים ומבינים אותם באמצעות תובנות מנתונים תובנות לגבי נתונים מספקות דרך אוטומטית ואינטואיטיבית לגלות דפוסים ולבצע ניתוח סטטיסטי באמצעות שאילתות שמספקות תובנות, שנוצרות מהמטא נתונים של הטבלאות. התכונה הזו שימושית במיוחד כשמנסים להתמודד עם אתגרי ההתנעה הקרה של ניתוח נתונים בשלב מוקדם. מידע נוסף זמין במאמר בנושא יצירת תובנות לגבי נתונים ב-BigQuery.
- גילוי, שינוי, שאילתה והמחשה של נתונים באמצעות קנבס נתונים ב-BigQuery. אתם יכולים להשתמש בשפה טבעית עם Gemini ב-BigQuery כדי למצוא נכסי טבלה, לצרף אותם ולבצע עליהם שאילתות, להציג את התוצאות באופן ויזואלי ולשתף פעולה עם אחרים בצורה חלקה לאורך כל התהליך. מידע נוסף זמין במאמר ניתוח באמצעות קנבס נתונים.
- קבלת עזרה בניתוח נתונים באמצעות SQL ו-Python אתם יכולים להשתמש ב-Gemini ב-BigQuery כדי ליצור או להציע קוד ב-SQL או ב-Python, וכדי לקבל הסבר על שאילתת SQL קיימת. אפשר גם להשתמש בשאילתות בשפה טבעית כדי להתחיל בניתוח הנתונים. כדי ללמוד איך ליצור, להשלים ולסכם קוד, אפשר לעיין במסמכים הבאים:
- עזרה בכתיבת קוד SQL
- עזרה בכתיבת קוד Python
- הכנת נתונים לניתוח. הכנת נתונים ב-BigQuery מספקת המלצות להמרת נתונים שנוצרו על ידי AI, עם מודעות להקשר, כדי לנקות את הנתונים לצורך ניתוח. מידע נוסף מופיע במאמר הכנת נתונים באמצעות Gemini.
- התאמה אישית של תרגומי SQL באמצעות כללי תרגום (Preview) יצירת כללי תרגום משופרים של Gemini כדי להתאים אישית את תרגומי ה-SQL כשמשתמשים בכלי האינטראקטיבי לתרגום SQL. אפשר לתאר שינויים בפלט של תרגום ה-SQL באמצעות הנחיות בשפה טבעית, או לציין תבניות SQL כדי למצוא ולהחליף. מידע נוסף מופיע במאמר יצירת כלל תרגום.
איך מגדירים את Gemini ב-BigQuery
תפקידים ומשאבים ב-BigQuery
BigQuery נותן מענה לצרכים של אנשי מקצוע בתחום הנתונים בתפקידים ובתחומי האחריות הבאים.
מנתח/ת נתונים
הנחיות לביצוע משימות שיעזרו לכם אם תצטרכו:
- שליחת שאילתות לנתוני BigQuery באמצעות שאילתות אינטראקטיביות או שאילתות אצווה באמצעות תחביר של שאילתות SQL
- אפשר לעיין בפונקציות, באופרטורים ובביטויים מותנים של SQL כדי לשלוח שאילתות לנתונים
- שימוש בכלים לניתוח ולהצגה חזותית של נתוני BigQuery, כולל: Looker, Looker Studio ו-Google Sheets.
שימוש בניתוח נתונים גיאו-מרחביים כדי לנתח נתונים גיאו-מרחביים ולהציג אותם באמצעות מערכות מידע גיאוגרפיות (GIS) של BigQuery
אופטימיזציה של ביצועי שאילתות באמצעות:
- טבלאות מחולקות למחיצות: אפשר לצמצם טבלאות גדולות על סמך טווחי זמן או טווחי מספרים שלמים.
- תצוגות מהותיות: הגדרת תצוגות שנשמרו במטמון כדי לבצע אופטימיזציה של שאילתות או לספק תוצאות קבועות.
- BI Engine: שירות ניתוח נתונים מהיר בזיכרון של BigQuery.
אדמין של נתונים
הנחיות לביצוע משימות שיעזרו לכם אם תצטרכו:
- ניהול עלויות באמצעות מקומות שמורים כדי לאזן בין תמחור על פי דרישה לתמחור מבוסס-קיבולת.
- הסבר על אבטחת מידע ומשילות נתונים כדי לאבטח נתונים לפי מערך נתונים, טבלה, עמודה, שורה, או תצוגה
- גיבוי נתונים באמצעות תמונות מצב של טבלאות כדי לשמור את התוכן של טבלה בנקודת זמן מסוימת.
- אפשר לעיין ב-INFORMATION_SCHEMA של BigQuery כדי להבין את המטא-נתונים של מערכי נתונים, עבודות, בקרת גישה, הזמנות, טבלאות ועוד.
- שימוש בעבודות כדי לבצע פעולות בשמכם ב-BigQuery, כמו טעינה, ייצוא, שליחת שאילתות או העתקה של נתונים.
- מעקב אחרי יומנים ומשאבים כדי להבין את BigQuery ואת עומסי העבודה.
מידע נוסף זמין במאמר מבוא לניהול BigQuery.
כדי לראות את התכונות לניהול נתונים ב-BigQuery Google Cloud ישירות במסוף, לוחצים על Take the tour.
מדען/ית נתונים
הנחיות לביצוע משימות שיעזרו לכם להשתמש בלמידת מכונה של BigQuery ML כדי לבצע את הפעולות הבאות:
- הבנת התהליך מקצה לקצה שעובר משתמש הקצה במודלים של למידת מכונה
- ניהול אמצעי בקרת הגישה ל-BigQuery ML
- יצירה ואימון של מודלים של BigQuery ML
כולל:
- תחזיות רגרסיה לינארית
- סיווגים של רגרסיה לוגיסטית בינארית ושל רגרסיה לוגיסטית רב-סיווגית
- K-means clustering לפילוח נתונים
- תחזיות של סדרות זמנים באמצעות מודלים של Arima+
מפתחים של נתונים
הנחיות לביצוע משימות שיעזרו לכם אם תצטרכו:
- טעינת נתונים ל-BigQuery
באמצעות:
- טעינת נתונים באצווה בפורמטים הבאים: Avro, Parquet, ORC, CSV, JSON , Datastore , ו-Firestore
- שירות העברת נתונים ל-BigQuery
- BigQuery Storage Write API
שימוש בספרייה של דוגמת קוד, כולל:
Google Cloud דפדפן לדוגמאות (במסגרת BigQuery)
המאמרים הבאים
- סקירה כללית על אחסון ב-BigQuery זמינה במאמר סקירה כללית על אחסון ב-BigQuery.
- סקירה כללית על שאילתות BigQuery זמינה במאמר סקירה כללית על ניתוח הנתונים ב-BigQuery.
- סקירה כללית של ניהול BigQuery זמינה במאמר מבוא לניהול BigQuery.
- סקירה כללית על האבטחה ב-BigQuery זמינה במאמר סקירה כללית על אבטחת מידע וניהול נתונים.