
סקירה כללית: העברת מחסני נתונים ל-BigQuery
במאמר הזה נסביר על מושגים כלליים שרלוונטיים לכל טכנולוגיה של מחסן נתונים, ונתאר מסגרת שאפשר להשתמש בה כדי לארגן ולבנות את ההעברה ל-BigQuery.
הסברים על המונחים
אנחנו משתמשים במינוח הבא כשדנים בהעברה של מחסן נתונים:
- תרחיש שימוש
-
תרחיש לדוגמה כולל את כל מערכי הנתונים, עיבוד הנתונים והאינטראקציות של המערכת והמשתמשים שנדרשים כדי להשיג ערך עסקי, כמו מעקב אחר נפחי המכירות של מוצר לאורך זמן. במחסני נתונים, תרחיש השימוש כולל בדרך כלל:
- צינורות נתונים שמבצעים המרה של נתונים גולמיים ממקורות נתונים שונים, כמו מסד נתונים של מערכת לניהול קשרי לקוחות (CRM).
- הנתונים שמאוחסנים במחסן הנתונים.
- סקריפטים ופרוצדורות לעיבוד נוסף של הנתונים ולניתוח שלהם.
- אפליקציה עסקית שקוראת את הנתונים או מבצעת פעולות שקשורות לנתונים.
- עומס עבודה
-
קבוצה של תרחישי שימוש שמחוברים זה לזה ויש להם תלות משותפת. For
example, a use case might have the following relationships and dependencies:
- דוחות על רכישות יכולים לעמוד בפני עצמם, והם שימושיים להבנת ההוצאות ולבקשת הנחות.
- הדיווח על מכירות יכול לעמוד בפני עצמו והוא שימושי לתכנון קמפיינים שיווקיים.
- עם זאת, הדיווח על רווח והפסד תלוי ברכישות ובמכירות, והוא שימושי לקביעת הערך של החברה.
- אפליקציה עסקית
- מערכת שמשתמשי הקצה יוצרים איתה אינטראקציה – לדוגמה, דוח חזותי או מרכז בקרה. אפליקציה עסקית יכולה להיות גם צינור עיבוד נתונים תפעולי או לולאת משוב. לדוגמה, אחרי שמחשבים או חוזים שינויים במחירי המוצרים, צינור נתונים תפעולי יכול לעדכן את מחירי המוצרים החדשים במסד נתונים טרנזקציוני.
- תהליך Upstream
- מערכות המקור וצינורות הנתונים שמעלים נתונים למחסן הנתונים.
- תהליך downstream
- הסקריפטים, הפרוצדורות והאפליקציות העסקיות שמשמשים לעיבוד הנתונים במחסן הנתונים, להרצת שאילתות עליהם ולהצגתם בצורה ויזואלית.
- העברה של נתונים לארכיון
-
אסטרטגיית מיגרציה שמטרתה להפעיל את תרחיש השימוש עבור
משתמש הקצה בסביבה החדשה במהירות האפשרית, או לנצל את הקיבולת
הנוספת שזמינה בסביבה החדשה. כדי להעביר את תרחישי השימוש ל-Offload:
- העתקה ואז סנכרון של הסכימה והנתונים ממחסן הנתונים מדור קודם.
- העברת הסקריפטים, הפרוצדורות והאפליקציות העסקיות במורד הזרם.
העברת נתונים יכולה להגדיל את המורכבות ואת העבודה שנדרשת להעברת צינורות נתונים.
- העברה מלאה
- גישה להעברה שדומה להעברה של נתונים לאחסון זמני, אבל במקום להעתיק את הסכימה והנתונים ואז לסנכרן אותם, מגדירים את ההעברה כך שהנתונים ייקלטו ישירות במחסן הנתונים החדש בענן ממערכות המקור במעלה הזרם. במילים אחרות, גם צינורות הנתונים שנדרשים לתרחיש השימוש מועברים.
- מחסן נתונים ארגוני (EDW)
- מחסן נתונים שלא כולל רק מסד נתונים לצורכי ניתוח, אלא גם רכיבים ונהלים אנליטיים קריטיים רבים. הם כוללים צינורות נתונים, שאילתות ואפליקציות עסקיות שנדרשים כדי לבצע את עומסי העבודה של הארגון.
- מחסן נתונים בענן (CDW)
- מחסן נתונים (data warehouse) עם מאפיינים זהים לאלה של EDW, אבל הוא פועל בשירות מנוהל מלא בענן – במקרה הזה, BigQuery.
- פייפליין
- תהליך שמקשר בין מערכות נתונים באמצעות סדרה של פונקציות ומשימות שמבצעות סוגים שונים של טרנספורמציה של נתונים. לפרטים נוספים, אפשר לעיין במאמר בנושא מהו צינור נתונים? בסדרה הזו.
למה כדאי לעבור ל-BigQuery?
בעשורים האחרונים, ארגונים התמקצעו בתחום של מחסני נתונים. הם משתמשים יותר ויותר בניתוח נתונים תיאוריים כדי להפיק תובנות מנתונים רבים שנשמרים, וכך מקבלים תובנות לגבי הפעילות העסקית העיקרית שלהם. בעבר, בינה עסקית (BI) קונבנציונלית, שהתמקדה בשאילתות, בדיווח ובעיבוד אנליטי אונליין, הייתה יכולה להיות גורם מבדיל, שיכול היה להוביל להצלחה או לכישלון של חברה. אבל היום היא כבר לא מספיקה.
כיום, ארגונים לא צריכים רק להבין אירועים מהעבר באמצעות ניתוח תיאורי, אלא גם ניתוח חיזוי, שלרוב משתמש בלמידת מכונה (ML) כדי לחלץ דפוסי נתונים ולספק טענות הסתברותיות לגבי העתיד. המטרה הסופית היא לפתח ניתוח נתונים תומך החלטות שמשלב לקחים מהעבר עם תחזיות לגבי העתיד, כדי להנחות באופן אוטומטי פעולות בזמן אמת.
בשיטות מסורתיות של מחסני נתונים, הנתונים הגולמיים נאספים ממקורות שונים, שלרוב הם מערכות עיבוד טרנזקציות אונליין (OLTP). לאחר מכן, קבוצת משנה של נתונים מחולצת באצוות, עוברת טרנספורמציה על סמך סכימה מוגדרת ונטענת למחסן הנתונים. מחסני נתונים מסורתיים מתעדים קבוצת משנה של נתונים באצוות ושומרים נתונים על סמך סכימות נוקשות, ולכן הם לא מתאימים לניתוח בזמן אמת או למענה על שאילתות ספונטניות. Google תכננה את BigQuery בין היתר כדי לתת מענה למגבלות המובנות האלה.
לעתים קרובות, רעיונות חדשניים מתעכבים בגלל הגודל והמורכבות של מחלקת ה-IT שמיישמת ומנהלת את מחסני הנתונים המסורתיים האלה. יכולות לעבור שנים עד שיוצרים ארכיטקטורה של מחסן נתונים (data warehouse) שניתנת להתאמה, עם זמינות גבוהה ומאובטחת. BigQuery מציע טכנולוגיה מתקדמת של תוכנה כשירות (SaaS) שאפשר להשתמש בה לפעולות של מחסן נתונים ללא שרת. כך תוכלו להתמקד בקידום העסק העיקרי שלכם ולהעביר את האחריות לתחזוקת התשתית ולפיתוח הפלטפורמה אל Google Cloud.
BigQuery מאפשר גישה לאחסון, לעיבוד ולניתוח של נתונים מובנים, והוא ניתן להתאמה, גמיש וחסכוני. המאפיינים האלה חיוניים כשנפחי הנתונים גדלים באופן אקספוננציאלי – כדי להקצות משאבי אחסון ועיבוד לפי הצורך, וגם כדי להפיק ערך מהנתונים האלה. בנוסף, לארגונים שרק מתחילים בניתוח Big Data ובלמידת מכונה, ורוצים להימנע מהמורכבות הפוטנציאלית של מערכות Big Data מקומיות, BigQuery מציע דרך של תשלום לפי שימוש להתנסות בשירותים מנוהלים.
בעזרת BigQuery, אפשר למצוא פתרונות לבעיות שהיו בלתי פתירות בעבר, להשתמש בלמידת מכונה כדי לגלות דפוסי נתונים חדשים ולבדוק השערות חדשות. כתוצאה מכך, אתם מקבלים תובנות בזמן אמת לגבי ביצועי העסק, ויכולים לשנות תהליכים כדי לשפר את התוצאות. בנוסף, חוויית המשתמש של משתמש הקצה מתעשרת לעיתים קרובות בתובנות רלוונטיות שנאספו מניתוח של נתונים גדולים, כפי שנסביר בהמשך הסדרה הזו.
מה מעבירים ואיך: מסגרת ההעברה
ביצוע מיגרציה יכול להיות תהליך מורכב וארוך. לכן מומלץ לפעול לפי מסגרת לארגון ולבנייה של עבודת ההעברה בשלבים:
- הכנה וגילוי: הכנה להעברה באמצעות גילוי עומסי עבודה ותרחישי שימוש.
- תכנון: קובעים סדר עדיפויות לתרחישים לדוגמה, מגדירים מדדים להצלחה ומתכננים את ההעברה.
- ביצוע: חוזרים על השלבים של ההעברה, מהערכה ועד לאימות.
הכנה וגילוי
בשלב הראשוני, המיקוד הוא בהכנה ובגילוי. המטרה היא לתת לכם ולבעלי העניין הזדמנות מוקדמת לגלות את תרחישי השימוש הקיימים ולהעלות חששות ראשוניים. חשוב גם לבצע ניתוח ראשוני של היתרונות הצפויים. היתרונות כוללים שיפורים בביצועים (למשל, שיפור במקביליות) והפחתה בעלות הבעלות הכוללת (TCO). השלב הזה חשוב מאוד כי הוא עוזר לכם להבין את הערך של המעבר.
מחסן נתונים בדרך כלל תומך במגוון רחב של תרחישי שימוש, ויש לו מספר רב של בעלי עניין, החל ממנתחי נתונים ועד מקבלי החלטות עסקיות. מומלץ לערב נציגים מהקבוצות האלה כדי להבין אילו תרחישי שימוש קיימים, אם תרחישי השימוש האלה פועלים בצורה טובה ואם בעלי העניין מתכננים תרחישי שימוש חדשים.
תהליך שלב הגילוי כולל את המשימות הבאות:
- בדיקת הצעת הערך של BigQuery והשוואה שלה לזו של מחסן הנתונים מדור קודם.
- ביצוע ניתוח ראשוני של עלות הבעלות הכוללת.
- לזהות את התרחישים לדוגמה שמושפעים מההעברה.
- יצירת מודל של המאפיינים של מערכי הנתונים וצינורות הנתונים הבסיסיים שרוצים להעביר כדי לזהות יחסי תלות.
כדי לקבל תובנות לגבי תרחישי השימוש, אפשר לפתח שאלון לאיסוף מידע ממומחים בתחום, ממשתמשי קצה ומבעלי עניין. השאלון צריך לכלול את הפרטים הבאים:
- מה המטרה של תרחיש השימוש? מהו הערך העסקי?
- מהן הדרישות הלא-פונקציונליות? עדכניות הנתונים, שימוש בו-זמני וכו'.
- האם תרחיש השימוש הוא חלק מעומס עבודה גדול יותר? האם זה תלוי בתרחישי שימוש אחרים?
- אילו מערכי נתונים, טבלאות וסכימות עומדים בבסיס תרחיש השימוש?
- מה ידוע לך על צינורות הנתונים שמזינים את מערכי הנתונים האלה?
- אילו כלים, דוחות ומרכזי בקרה של BI נמצאים בשימוש כרגע?
- מהן הדרישות הטכניות הנוכחיות בנוגע לצרכים תפעוליים, לביצועים, לאימות ולרוחב פס ברשת?
התרשים הבא מציג ארכיטקטורה כללית מדור קודם לפני ההעברה. התרשים מציג את קטלוג מקורות הנתונים הזמינים, צינורות נתונים מדור קודם, צינורות נתונים תפעוליים מדור קודם, לולאות משוב, דוחות BI מדור קודם ומרכזי בקרה מדור קודם שהמשתמשי קצה שלכם ניגשים אליהם.

תוכנית
בשלב התכנון, לוקחים את הקלט משלב ההכנה והגילוי, מעריכים אותו ואז משתמשים בו כדי לתכנן את ההעברה. אפשר לחלק את השלב הזה למשימות הבאות:
רישום תרחישי שימוש ותעדוף שלהם
מומלץ לחלק את תהליך ההעברה לחלקים קטנים. אתם יכולים לקטלג תרחישי שימוש קיימים וחדשים ולהקצות להם עדיפות. פרטים נוספים זמינים בקטעים מעבר ל-Google Workspace באמצעות גישה איטרטיבית וקביעת סדר עדיפויות לתרחישי שימוש במסמך הזה.
הגדרת מדדי הצלחה
מומלץ להגדיר מדדים ברורים להצלחה, כמו מדדי ביצועים מרכזיים (KPI), לפני המעבר. המדדים יאפשרו לכם להעריך את הצלחת המיגרציה בכל איטרציה. כך תוכלו לשפר את תהליך ההעברה באיטרציות הבאות.
יצירת הגדרה של 'סיום'
בהעברות מורכבות, לא תמיד ברור מתי מסיימים להעביר תרחיש שימוש מסוים. לכן, כדאי להגדיר באופן רשמי את המצב הסופי הרצוי. ההגדרה הזו צריכה להיות כללית מספיק כדי שאפשר יהיה להחיל אותה על כל תרחישי השימוש שרוצים להעביר. ההגדרה צריכה לשמש כקבוצה של קריטריונים מינימליים כדי שתוכלו להחשיב את תרחיש השימוש כהעברה מלאה. ההגדרה הזו בדרך כלל כוללת נקודות ביקורת כדי לוודא שתהליך השימוש שולב, נבדק ותועד.
עיצוב והצעה של הוכחת היתכנות (POC), מצב לטווח קצר ומצב סופי אידיאלי
אחרי שקובעים את סדר העדיפויות של תרחישי השימוש, אפשר להתחיל לחשוב עליהם לאורך כל תקופת ההעברה. כדאי להתייחס להעברה הראשונה של תרחיש שימוש כהוכחת היתכנות (PoC) כדי לאמת את הגישה הראשונית להעברה. כדאי לחשוב מה אפשר להשיג במהלך השבועות או החודשים הראשונים, ולראות בכך את המצב לטווח הקצר. איך תוכניות ההעברה ישפיעו על המשתמשים? האם הם יקבלו פתרון היברידי, או שתוכלו להעביר קודם עומס עבודה שלם עבור קבוצת משנה של משתמשים?
יצירת אומדנים של זמן ועלות
כדי להבטיח שהפרויקט להעברה יצליח, חשוב ליצור הערכות זמן ריאליות. כדי לעשות את זה, צריך לנהל שיחה עם כל בעלי העניין הרלוונטיים כדי לדון בזמינות שלהם ולהסכים על רמת המעורבות שלהם לאורך הפרויקט. כך תוכלו להעריך את עלויות העבודה בצורה מדויקת יותר. כדי לחשב אומדנים של עלויות שקשורות לצריכה הצפויה של משאבי ענן, אפשר לעיין במאמרים חישוב אומדנים של עלויות האחסון והשאילתות ומבוא לניהול העלויות ב-BigQuery במסמכי BigQuery.
זיהוי שותף להעברה ויצירת קשר איתו
במסמכי BigQuery מפורטים כלים ומשאבים רבים שאפשר להשתמש בהם כדי לבצע את ההעברה. עם זאת, יכול להיות שיהיה לכם קשה לבצע מיגרציה גדולה ומורכבת בעצמכם אם אין לכם ניסיון קודם או את כל המומחיות הטכנית הנדרשת בארגון. לכן מומלץ לזהות שותף להעברה ולפנות אליו כבר בהתחלה. פרטים נוספים זמינים בתוכניות השותפים הגלובליים ושירותי הייעוץ שלנו.
העברה באמצעות גישה איטרטיבית
כשמעבירים פעולה גדולה של מחסן נתונים לענן, מומלץ להשתמש בגישה איטרטיבית. לכן מומלץ לעבור ל-BigQuery בשלבים. חלוקת מאמץ ההעברה לאיטרציות מקלה על התהליך הכולל, מפחיתה את הסיכון ומספקת הזדמנויות ללמידה ולשיפור אחרי כל איטרציה.
איטרציה כוללת את כל העבודה שנדרשת להפחתת עומס או להעברה מלאה של תרחישי שימוש קשורים אחד או יותר בפרק זמן מוגבל. אפשר לחשוב על איטרציה כעל מחזור ספרינט במתודולוגיה אג'ילית, שמורכב מסיפור משתמש אחד או יותר.
כדי שיהיה לכם נוח לעקוב אחרי תרחישי שימוש, כדאי לשייך כל תרחיש שימוש לסיפור משתמש אחד או יותר. לדוגמה, נניח שיש את סיפור המשתמש הבא: "כאנליסט תמחור, אני רוצה לנתח שינויים במחירי מוצרים בשנה האחרונה כדי שאוכל לחשב מחירים עתידיים".
תרחיש השימוש המתאים יכול להיות:
- הטמעה של הנתונים ממסד נתונים טרנזקציוני שבו מאוחסנים מוצרים ומחירים.
- המרת הנתונים לסדרת זמן אחת לכל מוצר והזנת ערכים חסרים.
- אחסון התוצאות בטבלה אחת או יותר במחסן הנתונים.
- התוצאות זמינות דרך קובץ notebook של Python (האפליקציה העסקית).
הערך העסקי של תרחיש השימוש הזה הוא תמיכה בניתוח תמחור.
כמו ברוב התרחישים לדוגמה, התרחיש הזה כנראה יתמוך בכמה סיפורי משתמשים.
סביר להניח שתרחיש שימוש שהועבר ילווה באיטרציה נוספת כדי להעביר את תרחיש השימוש באופן מלא. אחרת, יכול להיות שעדיין תהיה לכם תלות במחסן הנתונים הקיים מדור קודם, כי הנתונים מועתקים משם. המיגרציה המלאה הבאה היא הדלתא בין ההעברה לבין מיגרציה מלאה שלא קדמה לה העברה – במילים אחרות, המיגרציה של צינורות הנתונים לחילוץ, לשינוי ולטעינה של הנתונים למחסן הנתונים.
קביעת סדר עדיפויות לתרחישי שימוש
הנקודה שבה מתחילים את המיגרציה והנקודה שבה מסיימים אותה תלויות בצרכים הספציפיים של העסק. חשוב להחליט באיזה סדר להעביר את תרחישי השימוש, כי הצלחה מוקדמת במהלך ההעברה היא חיונית להמשך התהליך של אימוץ הענן. אם ההעברה נכשלת בשלב מוקדם, זה עלול לפגוע באופן משמעותי במאמצי ההעברה הכוללים. יכול להיות שאתם מבינים את היתרונות שלGoogle Cloud ו-BigQuery, אבל עיבוד כל מערכי הנתונים וצינורות הנתונים שנוצרו או שמנוהלים במחסן הנתונים מדור קודם שלכם לתרחישי שימוש שונים יכול להיות מסובך ולגזול זמן רב.
אין תשובה אחת שמתאימה לכולם, אבל יש שיטות מומלצות שאפשר להשתמש בהן כשמעריכים את תרחישי השימוש ואת האפליקציות העסקיות המקומיות. תכנון מוקדם כזה יכול להקל על תהליך ההעברה ולשפר את המעבר ל-BigQuery.
בקטעים הבאים מפורטות גישות אפשריות לקביעת סדר עדיפויות לתרחישי שימוש.
גישה: ניצול הזדמנויות קיימות
כדאי לבדוק אילו הזדמנויות קיימות שיכולות לעזור לכם למקסם את ההחזר על ההשקעה שלכם בתרחיש שימוש ספציפי. הגישה הזו שימושית במיוחד אם אתם צריכים להצדיק את הערך העסקי של המעבר לענן. היא גם מאפשרת לאסוף נקודות נתונים נוספות שיעזרו להעריך את העלות הכוללת של המעבר.
הנה כמה שאלות לדוגמה שיעזרו לכם לזהות אילו תרחישי שימוש כדאי לתעדף:
- האם תרחיש השימוש כולל מערכי נתונים או צינורות נתונים שמוגבלים כרגע על ידי Enterprise Data Warehouse מדור קודם?
- האם מחסן הנתונים הארגוני הקיים שלכם דורש רענון חומרה, או שאתם צופים שתצטרכו להרחיב את החומרה? אם זה המצב, כדאי להעביר את תרחישי השימוש ל-BigQuery מוקדם ככל האפשר.
זיהוי הזדמנויות להעברה יכול להניב הצלחות מהירות שיוצרות יתרונות מוחשיים ומיידיים למשתמשים ולעסק.
גישה: העברת עומסי עבודה אנליטיים קודם
כדאי להעביר עומסי עבודה (workloads) של עיבוד אנליטי אונליין (OLAP) לפני עומסי עבודה של עיבוד טרנזקציות אונליין (OLTP). מחסן נתונים הוא לרוב המקום היחיד בארגון שבו יש את כל הנתונים ליצירת תצוגה גלובלית אחת של הפעולות בארגון. לכן, נפוץ בארגונים שיהיו צינורות נתונים מסוימים שמזינים נתונים בחזרה למערכות העסקאות כדי לעדכן את הסטטוס או להפעיל תהליכים – לדוגמה, כדי לקנות עוד מלאי כשמלאי המוצרים נמוך. עומסי עבודה של OLTP הם בדרך כלל מורכבים יותר, ויש להם דרישות תפעוליות מחמירות יותר והסכמי רמת שירות (SLA) מחמירים יותר מעומסי עבודה של OLAP. לכן, בדרך כלל קל יותר להעביר קודם עומסי עבודה של OLAP.
גישה: התמקדות בחוויית המשתמש
לזהות הזדמנויות לשיפור חוויית המשתמש על ידי העברה של מערכי נתונים ספציפיים והפעלה של סוגים חדשים של ניתוחים מתקדמים. לדוגמה, אחת הדרכים לשפר את חוויית המשתמש היא באמצעות ניתוח בזמן אמת. אפשר ליצור חוויות משתמש מתוחכמות על סמך זרם נתונים בזמן אמת בשילוב עם נתונים היסטוריים. לדוגמה:
- עובד במשרד האחורי שמקבל התראה באפליקציה לנייד על מלאי נמוך.
- לקוח באינטרנט שיכול להרוויח ממידע על כך שאם הוא יוסיף עוד דולר להוצאה שלו הוא יעבור לרמת תגמול הבאה.
- אחות שמקבלת התראה על הסימנים החיוניים של מטופל בשעון החכם שלה, ויכולה לנקוט את הפעולה הטובה ביותר על ידי הצגת היסטוריית הטיפול של המטופל בטאבלט שלה.
אתם יכולים גם לשפר את חוויית המשתמש באמצעות ניתוח נתונים חיזויים וניתוח נתונים שמציע המלצות. לשם כך, אפשר להשתמש ב-BigQuery ML, ב-Gemini Enterprise Agent Platform AutoML tabular או במודלים שאומנו מראש של Google לניתוח תמונות, ניתוח סרטונים, זיהוי דיבור, שפה טבעית ותרגום. לחלופין, אפשר להכניס לשימוש בסביבת הייצור את המודל שאומן בהתאמה אישית באמצעות Gemini Enterprise Agent Platform לתרחישי שימוש שמותאמים לצרכים העסקיים שלכם. לדוגמה:
- המלצה על מוצר על סמך מגמות בשוק והתנהגות רכישה של משתמשים.
- חיזוי של עיכוב בטיסה.
- זיהוי פעילויות שמקורן בתרמיות.
- דיווח על תוכן בלתי הולם.
- רעיונות חדשניים אחרים שיכולים לייחד את האפליקציה שלכם מהמתחרים.
גישה: מתן עדיפות לתרחישי שימוש עם הסיכון הנמוך ביותר
יש מספר שאלות שאנשי ה-IT יכולים לשאול כדי להעריך אילו תרחישי שימוש הם הכי פחות מסוכנים להעברה, ולכן הכי כדאי להעביר אותם בשלבים הראשונים של ההעברה. לדוגמה:
- מה רמת הקריטיות העסקית של תרחיש השימוש הזה?
- האם מספר גדול של עובדים או לקוחות תלוי בתרחיש השימוש?
- מהי סביבת היעד (לדוגמה, פיתוח או ייצור) של מקרה השימוש?
- מה ההבנה של צוות ה-IT שלנו לגבי תרחיש השימוש?
- כמה תלויות ושילובים יש בתרחיש לדוגמה?
- האם לצוות ה-IT שלנו יש תיעוד מתאים, עדכני ומקיף לתרחיש השימוש?
- מהן הדרישות התפעוליות (הסכמי רמת שירות) לתרחיש השימוש?
- מהן דרישות הציות לחוק או לדרישות ממשלתיות בתרחיש השימוש?
- מהי הרגישות לזמן השבתה ולזמן אחזור כשניגשים למערך הנתונים הבסיסי?
- האם יש בעלי עסקים שרוצים להעביר את תרחיש השימוש שלהם מוקדם יותר?
העיון ברשימת השאלות הזו יכול לעזור לכם לדרג מערכי נתונים וצינורות נתונים מהסיכון הנמוך ביותר לסיכון הגבוה ביותר. מומלץ להעביר קודם נכסים עם סיכון נמוך, ואחר כך נכסים עם סיכון גבוה יותר.
ביצוע
אחרי שאוספים מידע על המערכות מדור קודם ויוצרים רשימה של תרחישי שימוש לפי סדר עדיפויות, אפשר לקבץ את תרחישי השימוש בעומסי עבודה ולהמשיך בהעברה בשלבים.
איטרציה יכולה לכלול תרחיש שימוש יחיד, כמה תרחישי שימוש נפרדים או מספר תרחישי שימוש שקשורים לעומס עבודה יחיד. האפשרות שתבחרו עבור האיטרציה תלויה בקישוריות בין תרחישי השימוש, בתלות משותפת ובמשאבים שזמינים לכם לביצוע העבודה.
העברה בדרך כלל כוללת את השלבים הבאים:
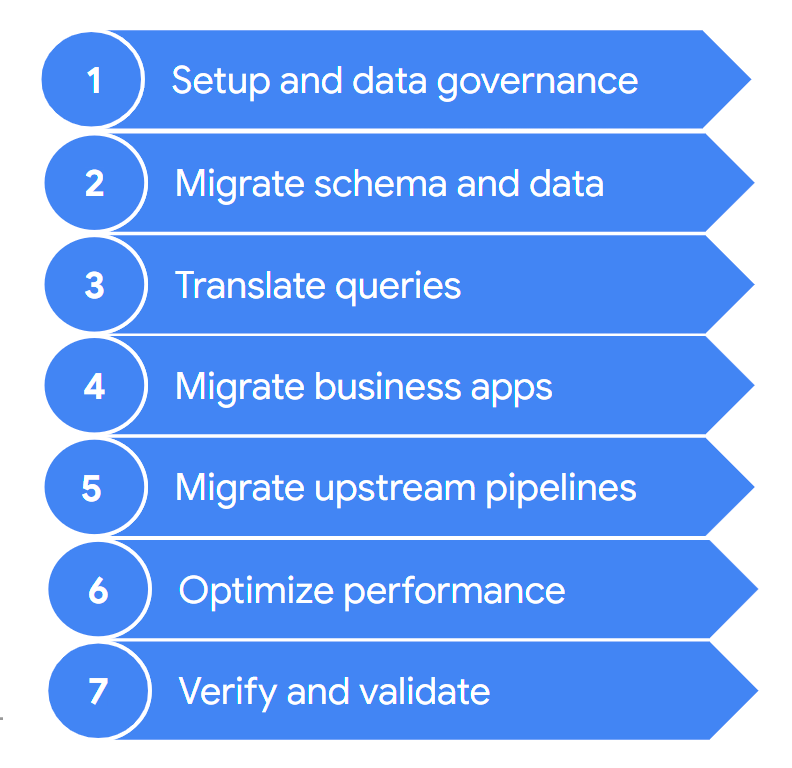
השלבים האלה מוסברים בפירוט בקטעים הבאים. יכול להיות שלא תצטרכו לבצע את כל השלבים האלה בכל איטרציה. לדוגמה, יכול להיות שבאיטרציה אחת תחליטו להתמקד בהעתקת חלק מהנתונים ממחסן הנתונים מדור קודם ל-BigQuery. לעומת זאת, באיטרציה הבאה תוכלו להתמקד בשינוי צינור ההטמעה ממקור נתונים מקורי ישירות ל-BigQuery.
1. הגדרה ומשילות מידע (data governance)
ההגדרה היא העבודה הבסיסית שנדרשת כדי להפעיל את תרחישי השימוש ב- Google Cloud. ההגדרה יכולה לכלול את הפרויקטים, הרשת, הענן הווירטואלי הפרטי (VPC) וניהול הנתונים שלכם.Google Cloud התהליך כולל גם פיתוח הבנה טובה של המצב הנוכחי – מה עובד ומה לא. כך תוכלו להבין מהן הדרישות למאמצי ההעברה. כדי לקבל עזרה בשלב הזה, אפשר להשתמש בתכונת הערכת ההעברה של BigQuery.
פיקוח על נתונים הוא גישה מבוססת-עקרונות לניהול נתונים במהלך מחזור החיים שלהם, מרגע הרכישה ועד לשימוש ולסילוק. בתוכנית שלכם לניהול נתונים מפורטים בבירור סעיפי המדיניות, הנהלים, האחריות ואמצעי הבקרה שקשורים לפעילויות שקשורות לנתונים. התוכנית הזו עוזרת לוודא שהמידע נאסף, נשמר, נמצא בשימוש ומופץ באופן שעומד בדרישות של הארגון לגבי תקינות נתונים וצרכי האבטחה שלו. בנוסף, הוא עוזר לעובדים שלכם לגלות את הנתונים ולהשתמש בהם כדי לממש את הפוטנציאל המלא שלהם.
מסמכי התיעוד בנושא ניהול נתונים עוזרים להבין מהו ניהול נתונים ואילו אמצעי בקרה צריך להפעיל כשמעבירים את מחסן הנתונים המקומי ל-BigQuery.
2. העברת סכימה ונתונים
הסכימה של מחסן הנתונים מגדירה את מבנה הנתונים ואת הקשרים בין ישויות הנתונים. הסכימה היא הבסיס של עיצוב הנתונים, והיא משפיעה על תהליכים רבים, גם במעלה הזרם וגם במורד הזרם.
במסמכי התיעוד בנושא סכימה והעברת נתונים יש מידע מפורט על האופן שבו אפשר להעביר את הנתונים ל-BigQuery והמלצות לעדכון הסכימה כדי לנצל את כל היתרונות של התכונות של BigQuery.
3. תרגום שאילתות
אפשר להשתמש בתרגום SQL באצווה כדי להעביר את קוד ה-SQL בכמות גדולה, או בתרגום SQL אינטראקטיבי כדי לתרגם שאילתות אד-הוק.
חלק ממחסני הנתונים מדור קודם כוללים הרחבות לתקן SQL כדי להפעיל פונקציונליות למוצר שלהם. BigQuery לא תומך בתוספים הקנייניים האלה, אלא פועל בהתאם לתקן ANSI/ISO SQL:2011. המשמעות היא שאולי עדיין תצטרכו לבצע שינויים ידניים בחלק מהשאילתות, אם מתרגמי ה-SQL לא יוכלו לפרש אותן.
4. העברה של אפליקציות עסקיות
אפליקציות עסקיות יכולות להיות מסוגים שונים – מלוחות בקרה ועד אפליקציות בהתאמה אישית וצינורות עיבוד נתונים תפעוליים שמספקים לולאות משוב למערכות טרנזקציות.
מידע נוסף על אפשרויות הניתוח כשעובדים עם BigQuery זמין במאמר סקירה כללית על ניתוח הנתונים ב-BigQuery. במאמר הזה נספק סקירה כללית של כלי הדיווח והניתוח שבהם אפשר להשתמש כדי להפיק תובנות משמעותיות מהנתונים.
בקטע על לולאות משוב במסמכי התיעוד של צינור הנתונים מוסבר איך אפשר להשתמש בצינור נתונים כדי ליצור לולאת משוב להקצאת משאבים במערכות במעלה הזרם.
5. העברת צינורות נתונים
במסמכי התיעוד בנושא צינורות עיבוד נתונים מפורטים תהליכים, דפוסים וטכנולוגיות להעברת צינורות עיבוד נתונים מדור קודם אל Google Cloud. הוא עוזר להבין מהו צינור נתונים, אילו נהלים ודפוסים אפשר להשתמש בו, ואילו אפשרויות וטכנולוגיות להעברה זמינות בהקשר של העברה גדולה יותר של מחסן נתונים.
6. אופטימיזציה של הביצועים
BigQuery מעבד נתונים ביעילות גם במערכי נתונים קטנים וגם במערכי נתונים גדולים מאוד (בסדר גודל של פטה-בייט). בעזרת BigQuery, עבודות ניתוח הנתונים שלכם אמורות לפעול בצורה טובה בלי שתצטרכו לבצע שינויים במחסן הנתונים החדש שהועבר. אם אתם מגלים שבנסיבות מסוימות ביצועי השאילתות לא עומדים בציפיות שלכם, תוכלו לקרוא את המאמר מבוא לאופטימיזציה של ביצועי שאילתות כדי לקבל הנחיות.
7. אימות ואישור
בסוף כל איטרציה, מאמתים שההעברה של תרחיש השימוש הצליחה על ידי בדיקה של הדברים הבאים:
- הנתונים והסכימה הועברו במלואם.
- הדרישות בנושא משילות מידע (data governance) נבדקו ועומדות בכל הקריטריונים.
- הוגדרו נהלים לאוטומציה של תחזוקה ומעקב.
- השאילתות תורגמו בצורה נכונה.
- פייפליינים של נתונים שהועברו פועלים כמצופה.
- האפליקציות העסקיות מוגדרות בצורה נכונה כדי לגשת לנתונים ולשאילתות שהועברו.
אפשר להתחיל להשתמש בכלי לאימות נתונים, כלי Python CLI בקוד פתוח שמשווה נתונים מסביבות מקור ויעד כדי לוודא שהם זהים. הוא תומך בכמה סוגי חיבורים וכולל פונקציונליות של אימות בכמה רמות.
כדאי גם למדוד את ההשפעה של המיגרציה של תרחיש השימוש – למשל, במונחים של שיפור הביצועים, צמצום העלויות או ניצול הזדמנויות טכניות או עסקיות חדשות. כך תוכלו לכמת בצורה מדויקת יותר את ערך ההחזר על ההשקעה ולהשוות את הערך לקריטריונים להצלחה שהגדרתם לאיטרציה.
אחרי שמאמתים את האיטרציה, אפשר להשיק את תרחיש השימוש שהועבר לסביבת הייצור ולתת למשתמשים גישה למערכי נתונים ולאפליקציות עסקיות שהועברו.
לבסוף, כדאי לסכם את מה שלמדתם מהאיטרציה הזו כדי שתוכלו ליישם את המסקנות באיטרציה הבאה ולזרז את ההעברה.
סיכום מאמצי ההעברה
במהלך ההעברה, מפעילים גם את מחסן הנתונים מדור קודם וגם את BigQuery, כמו שמפורט במסמך הזה. הארכיטקטורה לדוגמה בתרשים הבא מדגישה ששני מחסני הנתונים מציעים פונקציונליות ונתיבים דומים – שניהם יכולים לקלוט נתונים ממערכות המקור, להשתלב עם האפליקציות העסקיות ולספק את גישת המשתמש הנדרשת. חשוב לציין שהדיאגרמה גם מדגישה שהנתונים מסונכרנים ממחסן הנתונים אל BigQuery. כך אפשר להעביר תרחישי שימוש במהלך כל משך ההעברה.

בהנחה שאתם רוצים לבצע מיגרציה מלאה ממחסן הנתונים ל-BigQuery, המצב הסופי של המיגרציה ייראה כך:

המאמרים הבאים
אפשר לבצע העברה ל-BigQuery באמצעות הכלים הבאים:
- מריצים הערכת מיגרציה כדי להעריך את ההיתכנות והיתרונות הפוטנציאליים של העברת מחסן הנתונים ל-BigQuery.
- אפשר להשתמש בכלי התרגום של SQL, כמו כלי ה-SQL האינטראקטיבי לתרגום, Translation API וכלי ה-SQL לתרגום באצווה, כדי להפוך את שאילתות ה-SQL שלכם ל-GoogleSQL באופן אוטומטי, כולל התאמה אישית של SQL באמצעות Gemini.
- אחרי שמבצעים מיגרציה של מחסן הנתונים ל-BigQuery, מריצים את כלי אימות הנתונים כדי לאמת את הנתונים החדשים שעברו מיגרציה.
כדי לקבל מידע נוסף על העברת מחסן נתונים, אפשר לעיין במקורות המידע הבאים:
- במרכז הארכיטקטורה של Cloud יש משאבים למיגרציה שיעזרו לכם לתכנן ולבצע את המיגרציה אל Google Cloud
- איך מעבירים סכימה ונתונים ממחסן הנתונים
- איך מעבירים צינורות נתונים ממחסן הנתונים
- מידע על משילות מידע ב-BigQuery
עובדים עם צוות השירותים המקצועיים כדי לתכנן ולפרוס את Google Cloud ההעברה. מידע נוסף זמין במאמר בנושא שירותים מקצועיים של Google Cloud
מידע נוסף על מעבר ממחסני נתונים ספציפיים ל-BigQuery: