
התאוששות מאסון (DR) מנוהלת
במאמר הזה מוסבר על התאוששות מאסון מנוהלת ב-BigQuery ואיך להטמיע אותה בנתונים ובעומסי העבודה שלכם.
סקירה כללית
BigQuery תומך בתרחישי התאוששות מאסון במקרה של הפסקת שירות אזורית מוחלטת. התאוששות מאסון ב-BigQuery מתבססת על שכפול של מערכי נתונים בין אזורים כדי לנהל מעבר לגיבוי במקרה של כשל באחסון. אחרי שיוצרים רפליקה של מערך נתונים באזור משני, אפשר לשלוט בהתנהגות של יתירות כשל בחישוב ובאחסון, כדי לשמור על המשכיות עסקית במהלך הפסקה זמנית בשירות. אחרי יתירות כשל, אפשר לגשת לקיבולת מחשוב (משבצות) ולמערכי נתונים משוכפלים באזור המקודם. תוכנית התאוששות מאסון (DR) נתמכת רק במהדורת Enterprise Plus.
התאוששות מאסון מנוהלת מציעה שתי אפשרויות למעבר לגיבוי כשל: מעבר לגיבוי כשל קשיח ומעבר לגיבוי כשל רך. במעבר גיבוי (failover) קשיח, הרפליקות של ההזמנה ושל מערך הנתונים באזור המשני מקודמות באופן מיידי והופכות לרפליקות הראשיות. הפעולה הזו תתבצע גם אם האזור הראשי הנוכחי במצב אופליין, והיא לא תמתין לשכפול של נתונים שלא שוכפלו. לכן, עלול להתרחש אובדן נתונים במהלך מעבר גיבוי לשחזור.
ייתכן שיהיה צורך להפעיל מחדש באזור היעד משרות שביצעו פעולות על נתונים באזור המקור לפני שהערך של replication_time של הרפליקה הגיע ל-0 לאחר יתירות כשל.
בניגוד למעבר גיבוי אוטומטי קשיח, במעבר גיבוי אוטומטי רך המערכת ממתינה עד שכל השינויים בהזמנה ובמערך הנתונים שבוצעו באזור הראשי ישוכפלו לאזור המשני לפני השלמת תהליך מעבר הגיבוי האוטומטי. מעבר גיבוי אוטומטי רך מחייב שהאזור הראשי והאזור המשני יהיו זמינים.
הפעלת מעבר גיבוי אוטומטי רך מגדירה את הערך softFailoverStartTime להזמנה. הערך softFailoverStartTime
נמחק בסיום מעבר הגיבוי האוטומטי.
כדי להפעיל תוכנית התאוששות מאסון (DR), צריך ליצור הזמנה של מהדורת Enterprise Plus באזור הראשי, שהוא האזור שבו נמצא מערך הנתונים לפני יתירות כשל. קיבולת מחשוב במצב המתנה באזור המותאם כלולה בהזמנה של Enterprise Plus. לאחר מכן, מצמידים מערך נתונים להזמנה כדי להפעיל יתירות כשל עבור מערך הנתונים הזה. אפשר לצרף מערך נתונים להזמנה רק אם בוצע מילוי חוזר של מערך הנתונים, ואם יש בו את אותם מיקומים ראשיים ומשניים שמשויכים להזמנה. אחרי שמצרפים מערך נתונים להזמנת משאבים ליתירות כשל, רק הזמנות משאבים של Enterprise Plus יכולות לכתוב למערכי הנתונים האלה, ואי אפשר לבצע קידום של רפליקציה בין אזורים במערך הנתונים. אפשר לקרוא ממערכי נתונים שמצורפים להזמנת מעבר לגיבוי עם כל מודל קיבולת. מידע נוסף על הזמנות זמין במאמר מבוא לניהול עומסי עבודה.
קיבולת החישוב של האזור הראשי זמינה באזור המשני מיד אחרי מעבר לגיבוי. הזמינות הזו חלה על ערך הבסיס של ההזמנה, בין אם נעשה בו שימוש ובין אם לא.
צריך לבחור באופן פעיל לעבור לגיבוי כחלק מהבדיקה או בתגובה לאסון אמיתי. אסור לבצע יותר ממעבר גיבוי אוטומטי אחד בחלון של 10 דקות. בתרחישים של רפליקציה של נתונים, השלמה עם מסמכים קודמים מתייחסת לתהליך של אכלוס רפליקה של מערך נתונים בנתונים היסטוריים שהיו קיימים לפני שהרפליקה נוצרה או הופעלה. צריך להשלים את האכלת הנתונים של מערכי הנתונים לפני שניתן לבצע מעבר לגיבוי למערך הנתונים.
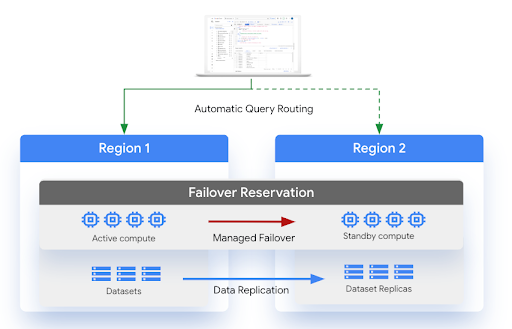
התרשים הבא מציג את הארכיטקטורה של תוכנית התאוששות מנוהלת מאסון (DR):
מגבלות
המגבלות הבאות חלות על תוכנית התאוששות מאסון (DR) ב-BigQuery:
אחרי שמצרפים מערך נתונים להזמנת יתירות כשל, רק הזמנות של Enterprise Plus יכולות לכתוב למערך הנתונים הזה. עם זאת, אפשר לקרוא ממערכי נתונים שמצורפים להזמנת יתירות כשל באמצעות כל מודל קיבולת.
תוכנית התאוששות מאסון (DR) ב-BigQuery כפופה לאותן מגבלות כמו שכפול של מערך נתונים בין אזורים.
התאמה אוטומטית לעומס אחרי יתירות כשל תלויה בזמינות של קיבולת מחשוב באזור המשני. רק נתוני הבסיס של ההזמנה זמינים באזור המשני.
INFORMATION_SCHEMA.RESERVATIONSבתצוגה אין פרטים על מעבר לגיבוי.הנתונים של האזור הראשי בתצוגה
INFORMATION_SCHEMA.JOBSלא משוכפלים לאזור המשני. התצוגה הזו מכילה רק את היסטוריית העבודות באזור הספציפי שבו העבודות בוצעו. במקרה של יתירות כשל, היסטוריית העבודות מהאזור הראשי לא מוצגת באזור המשני באמצעות התצוגהINFORMATION_SCHEMA.JOBS.אם יש לכם כמה מקומות שמורים ליתירות כשל עם אותו פרויקט ניהול, אבל מערכי הנתונים שמצורפים אליהם משתמשים במיקומים משניים שונים, אל תשתמשו במקום שמור אחד ליתירות כשל עם מערכי הנתונים שמצורפים למקום שמור אחר ליתירות כשל.
אם רוצים להמיר הזמנה קיימת להזמנה עם יתירות כשל, בהזמנה הקיימת לא יכולות להיות יותר מ-1,000 הקצאות של הזמנות.
אי אפשר לצרף יותר מ-1,000 מערכי נתונים להזמנת מעבר לגיבוי.
אפשר להפעיל מעבר גיבוי אוטומטי רך רק אם אזור המקור ואזור היעד זמינים.
לא ניתן להפעיל מעבר גיבוי אוטומטי רך אם יש שגיאות זמניות או אחרות במהלך שכפול ההזמנה. לדוגמה, אם אין מספיק מכסת משבצות באזור המשני לעדכון ההזמנה.
אי אפשר לעדכן את ההזמנה ואת מערכי הנתונים המצורפים במהלך מעבר גיבוי אוטומטי פעיל, אבל עדיין אפשר לקרוא מהם.
יכול להיות שמשימות שפועלות בהזמנה של מעבר לגיבוי בעת מעבר לגיבוי רך פעיל לא יפעלו בהזמנה בגלל שינויים זמניים בנתוני המערך ובניתוב ההזמנה במהלך פעולת המעבר לגיבוי. עם זאת, המשימות האלה ישתמשו במשבצות ההזמנה לפני שיופעל מעבר גיבוי אוטומטי, ואחרי שהוא יושלם.
במערכי נתונים שמשתמשים בתוכנית התאוששות מאסון (DR) ב-BigQuery, אי אפשר להשתמש במאגר המשותף של משבצות זמן פנויות לעבודות טעינה וחילוץ. צריך ליצור הקצאת הזמנה מסוג
PIPELINE, כי רק מהדורת Enterprise Plus תומכת בכתיבה למערכי נתונים שהוגדרו ב-MDR. הדרישה הזו מבטיחה שכל הטמעת הנתונים תתבצע באמצעות התשתית הייעודית שנדרשת לתמיכה בשכפול בין אזורים של MDR ובנקודת היעד לשחזור (RPO).שאילתות מתוזמנות לא מופנות אוטומטית למיקום הראשי החדש אחרי מעבר לגיבוי, כי הן קשורות למיקום שצוין במהלך היצירה שלהן. כדי להפעיל מחדש את השאילתות המתוזמנות במיקום הראשי החדש, צריך ליצור אותן מחדש באופן ידני במיקום הזה.
מיקומים
האזורים הבאים זמינים כשיוצרים הזמנה ליתירות כשל:
| קוד מיקום | שם האזור | תיאור האזור |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
טייוואן | |
ASIA-SOUTHEAST1 |
סינגפור | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
סידני | |
AUSTRALIA-SOUTHEAST2 |
מלבורן | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
מונטריאול | |
NORTHAMERICA-NORTHEAST2 |
טורונטו | |
DE |
||
EUROPE-WEST3 |
פרנקפורט | |
EUROPE-WEST10 |
ברלין | |
EU |
||
EU |
מספר אזורים באיחוד האירופי | |
EUROPE-CENTRAL2 |
ורשה | |
EUROPE-NORTH1 |
פינלנד | |
EUROPE-SOUTHWEST1 |
מדריד | |
EUROPE-WEST1 |
בלגיה | |
EUROPE-WEST3 |
פרנקפורט | |
EUROPE-WEST4 |
הולנד | |
EUROPE-WEST8 |
מילאנו | |
EUROPE-WEST9 |
פריז | |
IN |
||
ASIA-SOUTH1 |
מומבאי | |
ASIA-SOUTH2 |
דלהי | |
US |
||
US |
ארה"ב במספר אזורים | |
US-CENTRAL1 |
איווה | |
US-EAST1 |
דרום קרוליינה | |
US-EAST4 |
צפון וירג'יניה | |
US-EAST5 |
קולומבוס | |
US-SOUTH1 |
דאלאס | |
US-WEST1 |
אורגון | |
US-WEST2 |
לוס-אנג׳לס | |
US-WEST3 |
סולט לייק סיטי | |
US-WEST4 |
לאס וגאס |
צריך לבחור זוגות של אזורים בתוך ASIA, AU, CA, DE, EU, IN או US. לדוגמה, אי אפשר לשייך אזור ב-US לאזור ב-EU.
אם מערך הנתונים ב-BigQuery נמצא במיקום במספר אזורים, אי אפשר להשתמש בצמדי האזורים הבאים. המגבלה הזו נדרשת כדי לוודא שההקצאה ליתירות כשל והנתונים שלכם מופרדים גיאוגרפית אחרי הרפליקציה. מידע נוסף על אזורים שנכללים באזורים מרובים זמין במאמר בנושא אזורים מרובים.
-
us-central1–usמספר אזורים -
us-west1–usמספר אזורים -
eu-west1–euמספר אזורים -
eu-west4–euמספר אזורים
לפני שמתחילים
- מוודאים שיש לכם הרשאה לניהול זהויות והרשאות גישה (IAM)
bigquery.reservations.updateלעדכון הזמנות. - מוודאים שיש לכם מערכי נתונים קיימים שהוגדרו לשכפול. מידע נוסף מופיע במאמר בנושא שכפול של מערך נתונים.
רפליקציית טורבו
במסגרת התאוששות מאסון נעשה שימוש ברפליקציית טורבו כדי לבצע רפליקציה מהירה יותר של נתונים בין אזורים, וכך מפחיתים את הסיכון לחשיפה לאובדן נתונים, ממזערים את זמן ההשבתה של השירות ועוזרים בתמיכה בשירות ללא הפסקות בעקבות הפסקה זמנית בשירות באזור.
רפליקציה בקצב טורבו לא חלה על פעולת המילוי הראשוני. אחרי השלמת פעולת המילוי הראשוני, רפליקציה בקצב טורבו נועדה לבצע רפליקציה של מערכי נתונים לזוג אזורים יחיד למעבר לגיבוי בשעת כשל, עם רפליקה משנית תוך 15 דקות, כל עוד לא חרגתם ממכסת רוחב הפס ואין שגיאות משתמש.
היעד למשך ההתאוששות (RTO)
יעד משך ההתאוששות (RTO) הוא משך הזמן המקסימלי שמוקצב להתאוששות ב-BigQuery במקרה של אסון. מידע נוסף על RTO זמין במאמר היסודות של תכנון התאוששות מאסון.זמן ה-RTO של התאוששות מאסון מנוהלת הוא חמש דקות אחרי שמפעילים מעבר לגיבוי. בגלל ה-RTO, הקיבולת זמינה באזור המשני תוך חמש דקות מתחילת תהליך המעבר לגיבוי.
יעד להתאוששות מאסון (RPO)
יעד להתאוששות מאסון (RPO) הוא הנקודה העדכנית ביותר בזמן שממנה אפשר לשחזר נתונים. מידע נוסף על RPO זמין במאמר מושגי יסוד בתכנון DR. תוכנית התאוששות מאסון מנוהלת כוללת RPO שמוגדר לכל מערך נתונים. מטרת ה-RPO היא לשמור על הרפליקה המשנית בטווח של 15 דקות מהרפליקה הראשית. כדי לעמוד בדרישה הזו של RPO, אסור לחרוג ממיכסת רוחב הפס, ואסור שיהיו שגיאות מצד המשתמש.
מכסה
כדי להגדיר הזמנה למעבר אוטומטי לגיבוי, צריך לוודא שיש לכם את קיבולת המחשוב שבחרתם באזור המשני. אם אין מכסת זמינות באזור המשני, לא תוכלו להגדיר או לעדכן את ההזמנה. מידע נוסף זמין במאמר מכסות ומגבלות.
לרפליקציה בקצב טורבו יש מכסת רוחב פס. מידע נוסף זמין במאמר מכסות ומגבלות.
תמחור
כדי להגדיר התאוששות מאסון מנוהלת, צריך להשתמש בתוכניות התמחור הבאות:
קיבולת מחשוב: צריך לרכוש את מהדורת Enterprise Plus.
רפליקציה בקצב טורבו: תוכנית התאוששות מאסון (DR) מסתמכת על רפליקציה בקצב טורבו במהלך הרפליקציה. החיוב מתבצע על בסיס בייטים פיזיים ועל בסיס גיגה-בייט פיזי משוכפל. מידע נוסף מופיע במאמר תמחור של העברת נתונים לצורך שכפול נתונים של רפליקציה בקצב טורבו.
אחסון: החיוב על בייטים של אחסון באזור המשני זהה לחיוב על בייטים של אחסון באזור הראשי. מידע נוסף זמין במאמר בנושא תמחור של אחסון.
הלקוחות נדרשים לשלם רק על קיבולת המחשוב באזור הראשי. קיבולת מחשוב משנית (על סמך בסיס ההזמנה) זמינה באזור המשני ללא עלות נוספת. משבצות זמן פנויות לא יכולות להשתמש בקיבולת המשנית של המחשוב, אלא אם חל מעבר לגיבוי בעקבות כשל בהזמנה.
אם אתם צריכים לבצע קריאות לא עדכניות באזור המשני, אתם צריכים לרכוש קיבולת מחשוב נוספת.
יצירה או שינוי של הזמנה ב-Enterprise Plus
לפני שמצרפים קבוצת נתונים להזמנה, צריך ליצור הזמנת Enterprise Plus או לשנות הזמנה קיימת ולהגדיר אותה לתוכנית התאוששות מאסון.
יצירת בקשה לשמירת מקום
צריך לבחור אחת מהאפשרויות האלה:
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, לוחצים על ניהול קיבולת ואז על יצירת בקשה לשמירת מקום.
בשדה Reservation name, מזינים שם להזמנה.
ברשימה מיקום, בוחרים את המיקום.
ברשימה Edition בוחרים במהדורת Enterprise Plus.
ברשימה Max reservation size selector, בוחרים את הגודל המקסימלי של ההזמנה.
אופציונלי: בשדה Baseline slots, מזינים את מספר המשבצות הבסיסיות להזמנה.
כדי לקבוע את מספר המשבצות הזמינות להתאמה אוטומטית לעומס, מפחיתים את הערך של Baseline slots מהערך של Max reservation size. לדוגמה, אם יוצרים הזמנה עם 100 משבצות זמן בסיסיות וגודל הזמנה מקסימלי של 400, ההזמנה כוללת 300 משבצות זמן עם שינוי גודל אוטומטי. מידע נוסף על משבצות בסיסיות זמין במאמר בנושא שימוש בהזמנות עם משבצות בסיסיות ומשבצות של שינוי גודל אוטומטי.
ברשימה מיקום משני, בוחרים את המיקום המשני.
כדי להשבית את השיתוף של משבצות זמן פנויות ולהשתמש רק בקיבולת המשבצות שצוינה, לוחצים על המתג התעלמות ממשבצות זמן פנויות.
כדי להרחיב את הקטע הגדרות מתקדמות, לוחצים על החץ להרחבה .
אופציונלי: כדי להגדיר את יעד הבו-זמניות של משימות, לוחצים על המתג החלפת יעד הבו-זמניות של משימות אוטומטית כדי להפעיל אותו, ואז מזינים ערך בשדה יעד הבו-זמניות של משימות. פירוט המשבצות מוצג בטבלה Cost estimate. סיכום של שמירת המקום מוצג בטבלה Capacity summary.
לוחצים על Save.
ההזמנה החדשה מופיעה בכרטיסייה הזמנות למשבצות זמן.
SQL
כדי ליצור בקשה לשמירת מקום, משתמשים בהצהרה של שפת הגדרת נתונים (DDL) CREATE RESERVATION.
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
מחליפים את מה שכתוב בשדות הבאים:
-
ADMIN_PROJECT_ID: מזהה הפרויקט של פרויקט הניהול שבבעלותו משאב ההזמנה. -
LOCATION: המיקום של ההזמנה. אם בוחרים מיקום ב-BigQuery Omni, אפשר לבחור רק במהדורת Enterprise.
RESERVATION_NAME: השם של השמירה.השם צריך להתחיל ולהסתיים באות קטנה או במספר, ולהכיל רק אותיות קטנות, מספרים ומקפים.
-
NUMBER_OF_BASELINE_SLOTS: מספר המשבצות של תוכנית הבסיס להקצאה להזמנה. אי אפשר להגדיר את האפשרותslot_capacityואת האפשרותeditionבאותה הזמנה. -
SECONDARY_LOCATION: המיקום המשני של ההזמנה. במקרה של הפסקה זמנית בשירות, כל מערכי הנתונים שמצורפים להזמנה הזו יועברו למיקום הזה.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
שינוי הזמנה קיימת
צריך לבחור אחת מהאפשרויות האלה:
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, לוחצים על ניהול קיבולת.
לוחצים על הכרטיסייה Slot reservations.
מאתרים את ההזמנה שרוצים לעדכן.
לוחצים על פעולות בנושא הזמנות ואז על עריכה.
בשדה מיקום משני, מזינים את המיקום המשני.
לוחצים על Save.
SQL
כדי להוסיף או לשנות מיקום משני בהזמנה, משתמשים בהצהרת DDL ALTER RESERVATION SET OPTIONS.
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
מחליפים את מה שכתוב בשדות הבאים:
-
ADMIN_PROJECT_ID: מזהה הפרויקט של פרויקט הניהול שבבעלותו משאב ההזמנה. -
LOCATION: המיקום של השמירה, לדוגמהeurope-west9.
RESERVATION_NAME: השם של השמירה. השם צריך להתחיל ולהסתיים באות קטנה או במספר, ולהכיל רק אותיות קטנות, מספרים ומקפים.-
SECONDARY_LOCATION: המיקום המשני של ההזמנה. במקרה של הפסקה זמנית בשירות, כל מערכי הנתונים שמצורפים להזמנה הזו יועברו למיקום הזה.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
צירוף קבוצת נתונים להזמנה
כדי להפעיל תוכנית התאוששות מאסון (DR) להזמנה שנוצרה קודם, מבצעים את השלבים הבאים. מערך הנתונים כבר צריך להיות מוגדר לרפליקציה באותם אזורים ראשיים ומשניים כמו ההזמנה. מידע נוסף מופיע במאמר בנושא שכפול של מערכי נתונים באזורים שונים.
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, לוחצים על ניהול קיבולת ואז על הכרטיסייה הזמנת משבצות.
לוחצים על ההזמנה שרוצים לצרף אליה קבוצת נתונים.
לוחצים על הכרטיסייה שחזור אחרי אסון.
לוחצים על הוספת קבוצת נתונים למעבר לגיבוי.
מזינים את השם של מערך הנתונים שרוצים לשייך להזמנה.
לוחצים על הוספה.
SQL
כדי לצרף קבוצת נתונים להזמנה, משתמשים בהצהרת DDL ALTER SCHEMA SET OPTIONS.
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
מחליפים את מה שכתוב בשדות הבאים:
DATASET_NAME: השם של מערך הנתונים.-
ADMIN_PROJECT_ID.RESERVATION_NAME: השם של ההזמנה שרוצים לשייך אליה את מערך הנתונים.
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
ניתוק קבוצת נתונים מהזמנה
כדי להפסיק לנהל את התנהגות יתירות הכשל של מערך נתונים באמצעות הזמנה, צריך לנתק את מערך הנתונים מההזמנה. הפעולה הזו לא משנה את העותק הראשי הנוכחי של מערך הנתונים, ולא מסירה עותקים קיימים של מערך הנתונים. מידע נוסף על הסרת רפליקות של מערכי נתונים אחרי ניתוק מערך נתונים זמין במאמר הסרת רפליקה של מערך נתונים.
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, לוחצים על ניהול קיבולת ואז על הכרטיסייה הזמנת משבצות.
לוחצים על ההזמנה שרוצים לנתק ממנה קבוצת נתונים.
לוחצים על הכרטיסייה שחזור אחרי אסון.
מרחיבים את האפשרות Actions (פעולות) בשביל הרפליקה הראשית של מערך הנתונים.
לוחצים על הסרה.
SQL
כדי לנתק מערך נתונים מהזמנה, משתמשים בהצהרת ALTER SCHEMA SET OPTIONS DDL.
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
מחליפים את מה שכתוב בשדות הבאים:
DATASET_NAME: השם של מערך הנתונים.
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
הפעלת מעבר לגיבוי (failover)
במקרה של הפסקה זמנית בשירות אזורית, צריך לבצע יתירות כשל ידנית של ההזמנה למיקום שבו נעשה שימוש ברפליקה. המעבר לגיבוי בעקבות כשל בהזמנה כולל גם מערכי נתונים משויכים. כדי לבצע מעבר ידני לגיבוי של הזמנה:
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, לוחצים על Disaster recovery (תוכנית התאוששות מאסון (DR)).
לוחצים על שם ההזמנה שרוצים לבצע אליה מעבר לגיבוי.
בוחרים באפשרות מצב מעבר קשיח לגיבוי (ברירת מחדל) או מצב מעבר רך לגיבוי.
לוחצים על מעבר לגיבוי בענן.
SQL
כדי להוסיף או לשנות מיקום משני בהזמנה, משתמשים בALTER RESERVATION SET OPTIONS הצהרת DDL ומגדירים את is_primary ל-TRUE.
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
מחליפים את מה שכתוב בשדות הבאים:
-
ADMIN_PROJECT_ID: מזהה הפרויקט של פרויקט הניהול שבבעלותו משאב ההזמנה. LOCATION: המיקום הראשי החדש של ההזמנה, כלומר המיקום המשני הנוכחי לפני המעבר לגיבוי – לדוגמה,europe-west9.
RESERVATION_NAME: השם של השמירה. השם צריך להתחיל ולהסתיים באות קטנה או במספר, ולהכיל רק אותיות קטנות, מספרים ומקפים.-
PRIMARY_STATUS: סטטוס בוליאני שמציין אם ההזמנה היא הרפליקה הראשית.
FAILOVER_MODE: פרמטר אופציונלי שמשמש לתיאור מצב היתירות כשל. אפשר להגדיר את הערך ל-HARDאו ל-SOFT. אם לא מציינים את הפרמטר הזה, המערכת משתמשת בערךHARDכברירת מחדל.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
מעקב אחרי רפליקציה
אפשר לעקוב אחרי הסטטוס של העתקים של מערכי נתונים באמצעות BigQuery, Cloud Monitoring או תצוגות INFORMATION_SCHEMA.
מידע על יצירת התראות לגבי המדדים האלה זמין במאמר יצירת לוחות בקרה, תרשימים והתראות.
צפייה בסטטוס השכפול באמצעות BigQuery
כדי לראות את סטטוס השכפול ואת זמן האחזור של מערך נתונים במסוףGoogle Cloud :
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית Explorer מרחיבים את הפרויקט.
לוחצים על מערך הנתונים שרוצים לעקוב אחריו.
בחלונית הפרטים של מערך הנתונים, לוחצים על הכרטיסייה פרטים.
בקטע Replicas (רפליקות), בודקים את Replication latency (זמן האחזור של השכפול) ואת Status (סטטוס). כדי לראות פרטים נוספים, כולל תרשים של זמן האחזור של השכפול, לוחצים על הצגת פרטים.
הצגת סטטוס הרפליקציה באמצעות Cloud Monitoring
BigQuery מספק את המדדים הבאים ב-Monitoring כדי לעזור לכם לעקוב אחרי סטטוס השכפול:
- זמן האחזור של הרפליקציה: מידת העדכניות של הנתונים באזור המשני שמשוכפלים כחלק מרפליקציה חוצת-אזורים או מתוכנית התאוששות מאסון מנוהלת. המדד הזה מייצג את היעד להתאוששות מאסון (RPO).
- בייטים של תעבורת נתונים יוצאת מהרשת: נפח הנתונים (בבייטים) שחויב עליו ושוכפל מהאזור הראשי לאזור המשני. המדד הזה עוזר לכם לעקוב אחרי ניצול המכסה של רוחב הפס.
כדי לראות את המדדים האלה ב-Monitoring:
נכנסים לדף Monitoring במסוף Google Cloud .
לוחצים על Metrics explorer.
בשדה בחירת מדד, מחפשים את האפשרות מערך נתונים ב-BigQuery ובוחרים אותה.
בוחרים באפשרות Replication latency (
bigquery.googleapis.com/storage/replication/dataset_staleness) או באפשרות Network egress bytes (bigquery.googleapis.com/storage/replication/network_egress_bytes_count).לוחצים על אישור.
בקטע צבירה, בוחרים שיטת צבירה. למדד זמן האחזור של השכפול, מומלץ לבחור באפשרות האחוזון ה-99. הצבירה הזו מציגה בצורה טובה יותר את הביצועים במקרה הגרוע, בהשוואה לממוצע או לצבירות אחרות.
אופציונלי: כדי לראות מדדים של מערך נתונים ספציפי או אזור משני, לוחצים על הוספת מסנן, בוחרים באפשרות dataset_id או location ואז מזינים ערך. אם משכפלים נתונים לכמה אזורים משניים, אפשר לקבץ לפי מיקום כדי לראות את המדדים של כל אזור.
הצגת סטטוס הרפליקציה באמצעות INFORMATION_SCHEMA
כדי לקבוע את הסטטוס של העותקים, שולחים שאילתה לתצוגה INFORMATION_SCHEMA.SCHEMATA_REPLICAS. לדוגמה:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
השאילתה הבאה מחזירה את העבודות מ-7 הימים האחרונים שייכשלו אם מערכי הנתונים שלהן הם מערכי נתונים של מעבר לגיבוי בעת כשל:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: מזהה הפרויקט. -
DATASET_ID: מזהה קבוצת הנתונים. -
LOCATION: המיקום.