
空間分析的格狀系統
本文說明如何在 BigQuery 中使用地理空間格線系統 (例如 S2 和 H3) 整理標準化地理區域的空間資料,並介紹相關用途和方法。並說明如何為應用程式選擇合適的格線系統。如果您在 BigQuery 中處理空間資料並執行空間分析,這份文件會很有幫助。
使用空間分析的總覽和挑戰
空間分析有助於顯示實體空間中實體 (商店或房屋) 和事件之間的關係。以地球表面做為實體空間的空間分析稱為「地理空間分析」。BigQuery 內建地理空間功能和函式,可讓您大規模執行地理空間分析。
許多地理空間用途都涉及匯總特定區域內的資料,並比較這些區域的統計匯總資料。這些本地化區域在空間資料庫表格中以多邊形表示。在某些情況下,這種方法稱為「統計地理」。為提升報表、分析和空間索引的品質,判斷地理區域範圍的方法必須標準化。舉例來說,零售商可能會想分析商店所在區域或考慮新建商店區域的客層變化。或者,保險公司可能會想分析特定區域的現有天然災害風險,進一步瞭解財產風險。
由於許多地區都有嚴格的資料隱私權法規,含有位置資訊的資料集必須去識別化或部分匿名化,才能保護資料中代表的個人隱私。舉例來說,您可能需要對包含未償還抵押貸款資料的資料集,執行地理信用集中風險分析。如要對資料集去識別化,使其符合法規要求,請保留資源位置的相關資訊,但避免使用特定地址或經緯度座標。
在上述範例中,這些分析的設計人員面臨下列挑戰:
- 如何繪製區域邊界,以便分析一段時間內的變化?
- 如何使用現有的行政界線,例如普查區或多解析度格線系統?
本文將說明各個選項、最佳做法,以及如何避免常見陷阱,協助您解答上述問題。
選擇統計區域時的常見陷阱
房地產銷售、行銷活動、電子商務出貨和保險單等業務資料集,都適合進行空間分析。這些資料集通常包含看似方便的空間彙整索引鍵,例如人口普查區、郵遞區號或城市名稱。包含人口普查區、郵遞區號和城市代表的公開資料集隨手可得,因此很適合用來做為統計匯總的行政界線。
雖然這些和其他行政界線在名義上很方便,但也有缺點。此外,這些界線在分析專案的早期階段可能運作良好,但缺點會在後期階段顯現。
郵遞區號
全球各國都會使用郵遞區號遞送郵件,因此郵遞區號十分普及,經常用於參照空間和非空間資料集中的位置和區域。以前述房貸為例,資料集通常需要先去識別化,才能進行後續分析。由於每個房地產地址都包含郵遞區號,因此可存取郵遞區號參照表,方便做為空間分析的彙整索引鍵。
使用郵遞區號的缺點是,郵遞區號並非以多邊形表示,且郵遞區號區域沒有單一正確的可靠來源。此外,郵遞區號無法準確反映真實的人類行為。美國最常用的郵遞區號資料來自 US Census Bureau TIGER/Line Shapefiles,其中包含名為 ZCTA5 (郵遞區號統計區域) 的資料集。這項資料集代表郵遞區號邊界的近似值,是從郵件遞送路線衍生而來。不過,代表個別建築物的某些郵遞區號完全沒有邊界。其他國家/地區也有這個問題,因此難以建立單一全球事實資料表,其中包含可在系統和資料集之間使用的權威郵遞區號界線集。
此外,全球沒有統一的郵遞區號格式。 有些是數字 (三到十位數),有些是英數字元。 此外,國家/地區之間也有重疊,因此必須將原產地國家/地區與郵遞區號儲存在不同的資料欄中。部分國家/地區不使用郵遞區號,這會使分析更加複雜。
人口普查區、城市和郡
部分行政單位 (例如人口普查區、城市和郡) 不會因缺乏權威邊界而受到影響。舉例來說,城市界線通常是由政府機關劃定。美國人口普查局和其他國家/地區的類似機構,都對人口普查區有明確定義。
使用這些和其他行政邊界的一項缺點是,這些邊界會隨時間變更,且彼此在地理位置上並不一致。縣市可能會合併或分開,有時也會更名。美國每十年更新一次普查區,其他國家/地區的更新時間則不盡相同。令人困惑的是,有時地理界線可能會變更,但其專屬 ID 仍維持不變,導致難以分析及瞭解一段時間內的變化。
部分行政區界線的另一個常見缺點是,這些區域各自獨立,沒有地理階層。除了比較個別區域,常見的需求是比較區域的匯總與其他匯總。舉例來說,實作 Huff 模型的零售商可能想使用多個距離執行這項分析,而這些距離可能與商家其他地方使用的行政區不符。
單一和多重解析度格線
單一解析度格線是由不與包含這些單位的較大區域有地理關係的離散單位組成。舉例來說,郵遞區號與較大行政單位的界線 (例如可能包含郵遞區號的城市或郡) 之間,地理關係並不一致。進行空間分析時,瞭解不同區域之間的關係非常重要,不必深入瞭解定義區域多邊形的歷史和立法。
多重解析度格線有時也稱為階層式格線,因為每個縮放等級的儲存格,都會在較高的縮放等級細分成較小的儲存格。多重解析度格線是由明確定義的單元階層組成,這些單元包含在較大的單元中。舉例來說,普查區包含街區群組,而街區群組又包含街區。這種一致的階層式關係有助於統計匯總。舉例來說,您可以計算某個人口普查區內所有街區群組的平均收入,然後顯示該人口普查區內街區群組的平均收入。郵遞區號無法做到這一點,因為所有郵遞區號區域都位於單一解析度。由於沒有定義相鄰的標準方式,也無法比較不同國家/地區的收入,因此很難比較某個地塊與周圍地塊的收入。
S2 和 H3 格線系統
本節將概略介紹 S2 和 H3 格線系統。
S2
S2 幾何是 Google 開發的開放原始碼階層式格線系統,於 2011 年公開發布。您可以使用 S2 格線系統,為每個儲存格指派專屬的 64 位元整數,藉此整理空間資料並建立索引。解析度共有 31 個等級。每個儲存格都以正方形表示,專為球體幾何圖形 (有時稱為「地理位置」) 的運算而設計。每個方格又細分為四個較小的方格。相鄰遍歷 (可識別相鄰 S2 儲存格) 的定義較不明確,因為正方形可能會有四個或八個相關鄰項,視分析類型而定。以下是多重解析度 S2 格線儲存格的範例:
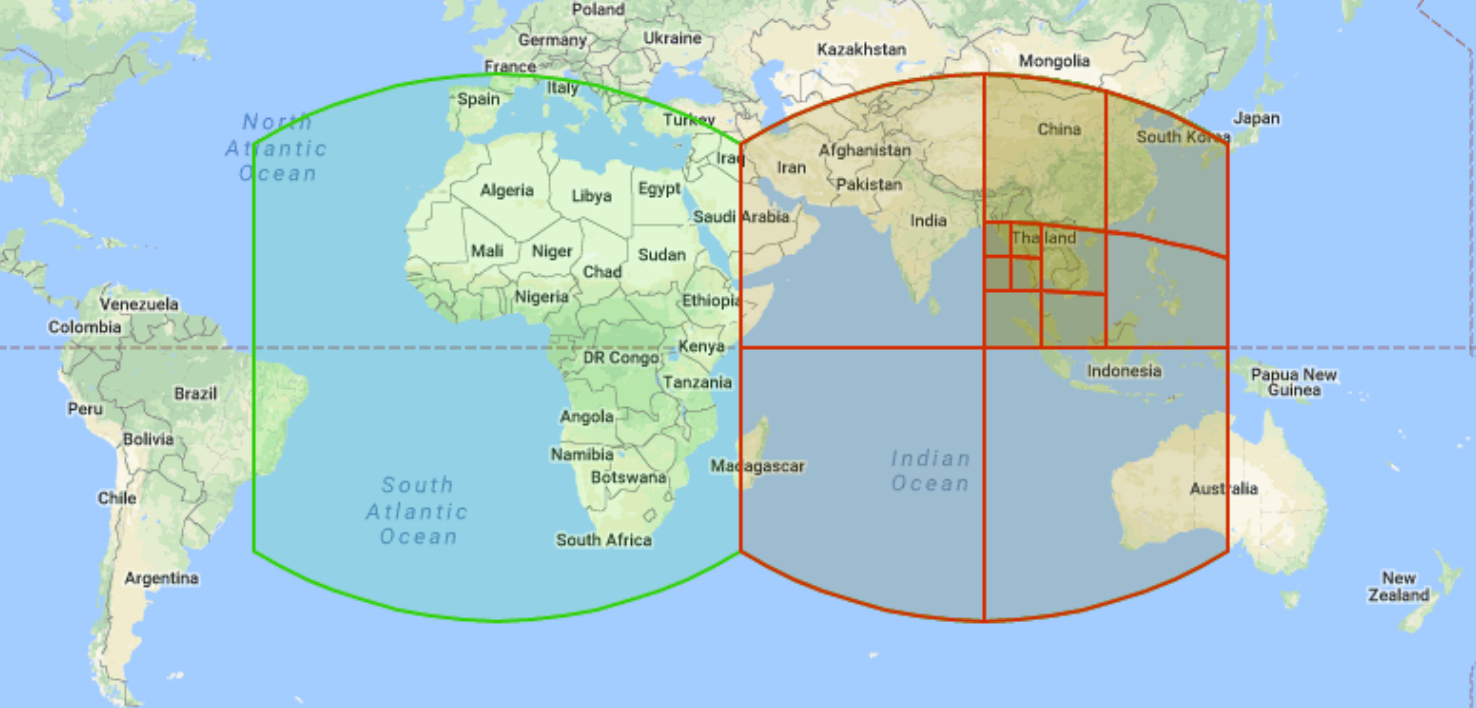
BigQuery 會使用 S2 儲存格為空間資料建立索引,並公開多項函式。舉例來說,S2_CELLIDFROMPOINT 會傳回 S2 儲存格 ID,其中包含地球表面上特定層級的點。
H3
H3 是 Uber 開發的開放原始碼階層式格線系統,Overture Maps 也使用這個系統。解析度分為 16 個等級。每個儲存格都以六邊形表示,且與 S2 相同,每個儲存格都會獲派專屬的 64 位元整數。在涵蓋墨西哥灣的 H3 儲存格視覺化範例中,較小的 H3 儲存格並未完全包含在較大的儲存格中。
每個蜂巢單元又細分為七個較小的六邊形。雖然並非精確的細分,但已足夠用於許多用途。每個儲存格都與六個相鄰儲存格共用邊緣,簡化了鄰項遍歷。舉例來說,每個層級都有 12 個五邊形,但這些五邊形與五個相鄰五邊形共用邊緣,而非六個。雖然 BigQuery 不支援 H3,但您可以使用 Carto Analytics Toolbox for BigQuery,在 BigQuery 中新增 H3 支援。
S2 和 H3 程式庫都是開放原始碼,並依阿帕契 2 授權提供,但 H3 程式庫的說明文件更詳細。
HEALPix
天文領域常用的球體格線額外架構,稱為「階層式等面積等緯度像素化」(HEALPix)。HEALPix 與階層式像素深度無關,但運算時間維持不變。
HEALPix 是球體的階層式等面積像素化配置。天球圖用於呈現和分析天體 (或其他) 球體上的資料。除了運算時間固定不變,HEALPix 格線還具有下列特徵:
- 格線儲存格具有階層式結構,可維持上層和下層關係。
- 在特定階層中,儲存格的面積相等。
- 這些儲存格遵循 iso-latitude 分布,可提升光譜方法的效能。
BigQuery 不支援 HEALPix,但有許多語言 (包括 JavaScript) 實作了這項功能,因此方便在 BigQuery 使用者定義函式 (UDF) 中使用。
各索引策略的實務應用範例
本節提供一些範例,協助您評估哪種格線系統最適合您的用途。
許多分析和報表使用案例都涉及視覺化,無論是分析本身的一部分,還是向業務利害關係人匯報時使用,這些視覺化內容通常會以 Web Mercator 呈現,這是 Google 地圖和許多其他網路地圖應用程式使用的平面投影。如果視覺化效果至關重要,H3 格狀單元可提供主觀上更優質的視覺化體驗。S2 儲存格 (尤其是在較高緯度) 往往比 H3 更容易出現扭曲,且以平面投影呈現時,與較低緯度的儲存格不一致。
H3 儲存格可簡化實作程序,在分析中,鄰近比較扮演重要角色。舉例來說,比較城市各區的資料,有助於決定適合開設新零售商店或配送中心的地點。分析時,需要針對特定儲存格的屬性進行統計計算,並與相鄰儲存格比較。
S2 儲存格更適合用於全球性質的分析,例如涉及距離和角度測量的分析。Niantic 的 Pokemon Go 會使用 S2 儲存格,判斷遊戲資產的放置位置和發布方式。S2 格子的確切細分屬性可確保遊戲素材平均分布在全球各地。
後續步驟
- 如需空間分群的最佳做法,請參閱「BigQuery 空間分群 - 最佳做法」。
- 瞭解如何根據不完美的資料建立空間階層。
- 如要瞭解 S2 幾何,請前往 GitHub。
- 在 GitHub 上瞭解 H3 幾何。
- 請參閱使用 H3、BigQuery 和 Earth Engine 的範例。