
BigQuery DataFrames in dbt verwenden
dbt (data build tool) ist ein Open-Source-Befehlszeilen-Framework, das für die Datentransformation in modernen Data Warehouses entwickelt wurde. dbt ermöglicht modulare Datentransformationen durch die Erstellung von wiederverwendbaren SQL- und Python-basierten Modellen. Das Tool orchestriert die Ausführung dieser Transformationen im Zieldata-Warehouse und konzentriert sich dabei auf den Transformationsschritt der ELT-Pipeline. Weitere Informationen finden Sie in der dbt-Dokumentation.
In dbt ist ein Python-Modell eine Datentransformation, die mit Python-Code in Ihrem dbt-Projekt definiert und ausgeführt wird. Anstatt SQL für die Transformationslogik zu schreiben, schreiben Sie Python-Skripts, die von dbt orchestriert werden, um in der Data Warehouse-Umgebung ausgeführt zu werden. Mit einem Python-Modell können Sie Datentransformationen durchführen, die in SQL möglicherweise komplex oder ineffizient auszudrücken sind. So können Sie die Funktionen von Python nutzen und gleichzeitig von der Projektstruktur, Orchestrierung, Abhängigkeitsverwaltung, den Testfunktionen und der Dokumentation von dbt profitieren. Weitere Informationen finden Sie unter Python-Modelle.
Der dbt-bigquery-Adapter unterstützt die Ausführung von Python-Code, der in BigQuery DataFrames definiert ist. Dieses Feature ist in dbt Cloud und dbt Core verfügbar.
Sie können diese Funktion auch erhalten, indem Sie die aktuelle Version des dbt-bigquery-Adapters klonen.
Hinweis
Wenn Sie den dbt-bigquery-Adapter verwenden möchten, aktivieren Sie die folgenden APIs in Ihrem Projekt:
- BigQuery API (
bigquery.googleapis.com) - Cloud Storage API (
storage.googleapis.com) - Compute Engine API (
compute.googleapis.com) - Dataform API (
dataform.googleapis.com) - Identity and Access Management API (
iam.googleapis.com) - Vertex AI API (
aiplatform.googleapis.com)
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (roles/serviceusage.serviceUsageAdmin), die die Berechtigung serviceusage.services.enable enthält. Weitere Informationen zum Zuweisen von Rollen
Erforderliche Rollen
Der dbt-bigquery-Adapter unterstützt die OAuth-basierte und die dienstkontobasierte Authentifizierung. In den folgenden Abschnitten werden die erforderlichen Rollen je nach Authentifizierungsmethode beschrieben.
OAuth
Wenn Sie sich mit OAuth beim dbt-bigquery-Adapter authentifizieren möchten, bitten Sie Ihren Administrator, Ihnen die folgenden Rollen zuzuweisen:
- Rolle „BigQuery-Nutzer“ (
roles/bigquery.user) für das Projekt - Rolle „BigQuery-Datenbearbeiter“ (
roles/bigquery.dataEditor) für das Projekt oder das Dataset, in dem Tabellen gespeichert werden - Colab Enterprise-Nutzerrolle (
roles/colabEnterprise.user) für das Projekt - Rolle „Storage-Administrator“ (
roles/storage.admin) für den Cloud Storage-Staging-Bucket zum Stagen von Code und Logs
Dienstkonto
Wenn Sie sich mit einem Dienstkonto in Ihrem Projekt beim dbt-bigquery-Adapter authentifizieren möchten, bitten Sie Ihren Administrator, dem Dienstkonto, das Sie verwenden möchten, die folgenden Rollen zuzuweisen:
- Rolle „BigQuery-Nutzer“
(
roles/bigquery.user) - Rolle „BigQuery-Dateneditor“
(
roles/bigquery.dataEditor) - Colab Enterprise-Nutzerrolle
(
roles/colabEnterprise.user) - Storage-Administratorrolle
(
roles/storage.admin)
Wenn Sie die Authentifizierung mit einem Dienstkonto vornehmen, müssen Sie auch die Rolle Dienstkontonutzer (roles/iam.serviceAccountUser) für das Dienstkonto zuweisen, das Sie verwenden möchten.
Identitätsübernahme des Dienstkontos
Wenn Sie die Authentifizierung für den dbt-bigquery-Adapter mit OAuth planen, die Datenverarbeitung und die Notebook-Ausführung jedoch unter der Identität eines Dienstkontos im selben Projekt erfolgen sollen, in dem die Jobs ausgeführt werden, bitten Sie Ihren Administrator, Ihnen die folgenden Rollen zuzuweisen:
- Rolle „Dienstkonto-Token-Ersteller“
(
roles/iam.serviceAccountTokenCreator) - Dienstkontonutzer
(
roles/iam.serviceAccountUser)
Das übernommene Dienstkonto muss auch alle für die Authentifizierung erforderlichen Rollen haben.
Projektübergreifende Dienstkonten
Wenn Sie planen, sich mit einem Dienstkonto in einem anderen Projekt beim dbt-bigquery-Adapter zu authentifizieren, dem Anmeldedatenprojekt, aus dem die Jobs ausgeführt werden, dem Ausführungsprojekt, bitten Sie Ihren Administrator, Folgendes zu tun:
- Deaktivieren Sie die Einschränkung
constraints/iam.disableCrossProjectServiceAccountUsageim Anmeldedatenprojekt. Zusätzlich zu allen für die Dienstkontoauthentifizierung erforderlichen Rollen weisen Sie dem Dienstkonto im Anmeldedatenprojekt die folgenden Rollen zu:
- Vertex AI Service Agent-Rolle (roles/aiplatform.serviceAgent) für
service-PROJECT_NUMBER@gcp-sa-aiplatform.iam.gserviceaccount.com - Vertex AI Colab Service Agent-Rolle (roles/aiplatform.colabServiceAgent) für
service-PROJECT_NUMBER@gcp-sa-vertex-nb.iam.gserviceaccount.com - Weisen Sie dem
service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.comdie Compute Engine Service-Agent-Rolle (roles/compute.serviceAgent) zu.
- Vertex AI Service Agent-Rolle (roles/aiplatform.serviceAgent) für
Wenn Sie sich mit OAuth beim dbt-bigquery-Adapter authentifizieren möchten, die Datenverarbeitung und die Notebook-Ausführung jedoch unter der Identität eines Dienstkontos in einem anderen Projekt als dem, in dem die Jobs ausgeführt werden, erfolgen sollen, bitten Sie Ihren Administrator, Folgendes zu tun:
- Folgen Sie der zuvor beschriebenen Anleitung für Dienstkonten für mehrere Projekte für das Dienstkonto in einem anderen Projekt.
- Weisen Sie sich selbst und dem Dienstkonto die für die Identitätsübernahme des Dienstkontos erforderlichen Rollen zu.
Gemeinsam genutzte VPC
Wenn Sie Colab Enterprise in einer Umgebung mit freigegebene VPC verwenden, bitten Sie Ihren Administrator, die folgenden Rollen und Berechtigungen zu gewähren:
compute.subnetworks.use-Berechtigung: Gewähren Sie diese Berechtigung dem Dienstkonto, das von der Colab Enterprise-Laufzeit im Hostprojekt oder in bestimmten Subnetzen verwendet wird. Diese Berechtigung ist in der Rolle „Compute Network User“ (roles/compute.networkUser) enthalten.Berechtigung
compute.subnetworks.get:compute.subnetworks.getGewähren Sie diese Berechtigung dem Dienstkonto, das von der Colab Enterprise-Laufzeit im Hostprojekt oder in bestimmten Subnetzen verwendet wird. Diese Berechtigung ist in der Rolle „Compute-Netzwerkbetrachter“ (roles/compute.networkViewer) enthalten.Rolle „Compute Network User“ (
roles/compute.networkUser): Weisen Sie diese Rolle dem Dienst-Agenten der Gemini Enterprise Agent Platform,service-PROJECT_NUMBER@gcp-sa-aiplatform.iam.gserviceaccount.com, im Hostprojekt der freigegebene VPC zu.Rolle „Compute Network User“ (
roles/compute.networkUser): Wenn die Funktion für die Ausführung von Notebook-Jobs verwendet wird, weisen Sie dem Colab Enterprise-Dienst-Agenten (service-PROJECT_NUMBER@gcp-sa-vertex-nb.iam.gserviceaccount.com) im Hostprojekt der freigegebene VPC diese Rolle zu.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Python-Ausführungsumgebung
Der dbt-bigquery-Adapter verwendet den Colab Enterprise-Notebook-Ausführungsservice, um den BigQuery DataFrames-Python-Code auszuführen. Für jedes Python-Modell wird automatisch ein Colab Enterprise-Notebook erstellt und vom dbt-bigquery-Adapter ausgeführt. Sie können dasGoogle Cloud -Projekt auswählen, in dem das Notebook ausgeführt werden soll. Im Notebook wird der Python-Code aus dem Modell ausgeführt, der von der BigQuery DataFrames-Bibliothek in BigQuery-SQL umgewandelt wird. Die BigQuery-SQL wird dann im konfigurierten Projekt ausgeführt. Das folgende Diagramm zeigt den Kontrollfluss:
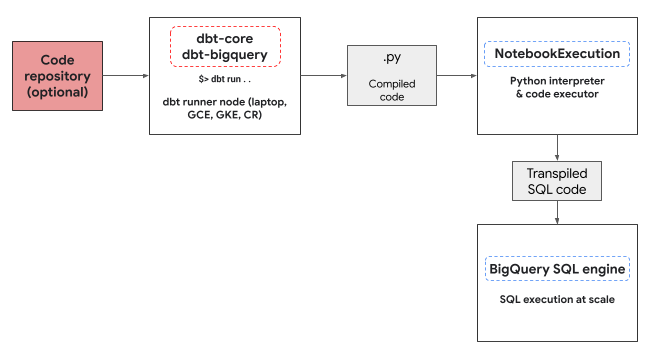
Wenn im Projekt noch keine Notebook-Vorlage verfügbar ist und der Nutzer, der den Code ausführt, die Berechtigungen zum Erstellen der Vorlage hat, wird die Standard-Notebook-Vorlage automatisch vom dbt-bigquery-Adapter erstellt und verwendet. Sie können auch eine andere Notebook-Vorlage mit einer dbt-Konfiguration angeben.
Für die Notebook-Ausführung ist ein Staging-Cloud Storage-Bucket zum Speichern des Codes und der Logs erforderlich. Der dbt-bigquery-Adapter kopiert die Logs jedoch in die dbt-Logs, sodass Sie nicht im Bucket suchen müssen.
Unterstützte Features
Der dbt-bigquery-Adapter unterstützt die folgenden Funktionen für dbt-Python-Modelle, die BigQuery DataFrames ausführen:
- Daten aus einer vorhandenen BigQuery-Tabelle mit dem Makro
dbt.source()laden - Daten aus anderen dbt-Modellen mit dem Makro
dbt.ref()laden, um Abhängigkeiten zu erstellen und gerichtete azyklische Graphen (DAGs) mit Python-Modellen zu erstellen. - Python-Pakete von PyPi angeben und verwenden, die mit der Ausführung von Python-Code verwendet werden können. Weitere Informationen finden Sie unter Konfigurationen.
- Geben Sie eine benutzerdefinierte Notebook-Laufzeitvorlage für Ihre BigQuery DataFrames-Modelle an.
Der dbt-bigquery-Adapter unterstützt die folgenden Materialisierungsstrategien:
- Tabellenmaterialisierung, bei der Daten bei jedem Lauf als Tabelle neu erstellt werden.
- Inkrementelle Materialisierung mit einer Zusammenführungsstrategie, bei der einer vorhandenen Tabelle neue oder aktualisierte Daten hinzugefügt werden. Änderungen werden oft mithilfe einer Zusammenführungsstrategie verarbeitet.
dbt für die Verwendung von BigQuery DataFrames einrichten
Wenn Sie dbt Core verwenden, müssen Sie eine profiles.yml-Datei für die Verwendung mit BigQuery DataFrames verwenden.
Im folgenden Beispiel wird die Methode oauth verwendet:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
Wenn Sie dbt Cloud verwenden, können Sie direkt über die dbt Cloud-Benutzeroberfläche eine Verbindung zu Ihrer Datenplattform herstellen. In diesem Fall benötigen Sie keine profiles.yml-Datei. Weitere Informationen finden Sie unter Informationen zu profiles.yml.
Dies ist ein Beispiel für eine Konfiguration auf Projektebene für die Datei dbt_project.yml:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Einige Parameter können auch mit der Methode dbt.config in Ihrem Python-Code konfiguriert werden. Wenn diese Einstellungen mit Ihrer dbt_project.yml-Datei in Konflikt stehen, haben die Konfigurationen mit dbt.config Vorrang.
Weitere Informationen finden Sie unter Modellkonfigurationen und dbt_project.yml.
Konfigurationen
Mit der dbt.config-Methode in Ihrem Python-Modell können Sie die folgenden Konfigurationen einrichten. Diese Konfigurationen überschreiben die Konfiguration auf Projektebene.
| Konfiguration | Erforderlich | Nutzung |
|---|---|---|
submission_method |
Ja | submission_method=bigframes |
notebook_template_id |
Nein | Wenn keine Angabe erfolgt, wird eine Standardvorlage erstellt und verwendet. |
packages |
Nein | Geben Sie bei Bedarf die zusätzliche Liste der Python-Pakete an. |
timeout |
Nein | Optional: Verlängern Sie das Zeitlimit für die Jobausführung. |
Python-Beispielmodelle
In den folgenden Abschnitten finden Sie Beispielszenarien und Python-Modelle.
Daten aus einer BigQuery-Tabelle laden
Wenn Sie Daten aus einer vorhandenen BigQuery-Tabelle als Quelle in Ihrem Python-Modell verwenden möchten, müssen Sie diese Quelle zuerst in einer YAML-Datei definieren. Das folgende Beispiel ist in einer source.yml-Datei definiert.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
Anschließend erstellen Sie Ihr Python-Modell, das die in dieser YAML-Datei konfigurierten Datenquellen verwenden kann:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
Auf ein anderes Modell verweisen
Sie können Modelle erstellen, die von der Ausgabe anderer dbt-Modelle abhängen, wie im folgenden Beispiel gezeigt. Dies ist nützlich, um modulare Datenpipelines zu erstellen.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
Paketabhängigkeit angeben
Wenn für Ihr Python-Modell bestimmte Drittanbieterbibliotheken wie MLflow oder Boto3 erforderlich sind, können Sie das Paket in der Konfiguration des Modells deklarieren, wie im folgenden Beispiel gezeigt. Diese Pakete werden in der Ausführungsumgebung installiert.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
Nicht standardmäßige Vorlage angeben
Wenn Sie mehr Kontrolle über die Ausführungsumgebung haben oder vorkonfigurierte Einstellungen verwenden möchten, können Sie eine nicht standardmäßige Notebook-Vorlage für Ihr BigQuery DataFrames-Modell angeben, wie im folgenden Beispiel gezeigt.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
Tabellen materialisieren
Wenn dbt Ihre Python-Modelle ausführt, muss es wissen, wie die Ergebnisse in Ihrem Data Warehouse gespeichert werden. Das wird als Materialisierung bezeichnet.
Bei der Standardtabellenmaterialisierung erstellt oder ersetzt dbt jedes Mal, wenn es ausgeführt wird, eine Tabelle in Ihrem Data Warehouse mit der Ausgabe Ihres Modells. Dies erfolgt standardmäßig oder durch explizites Festlegen des Attributs materialized='table', wie im folgenden Beispiel gezeigt.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
Durch die inkrementelle Materialisierung mit einer Merge-Strategie kann dbt Ihre Tabelle nur mit neuen oder geänderten Zeilen aktualisieren. Das ist bei großen Datasets nützlich, da das vollständige Neuerstellen einer Tabelle jedes Mal ineffizient sein kann. Die Zusammenführungsstrategie ist eine gängige Methode, um diese Aktualisierungen zu verarbeiten.
Bei diesem Ansatz werden Änderungen auf folgende Weise intelligent integriert:
- Vorhandene Zeilen aktualisieren, die sich geändert haben.
- Neue Zeilen hinzufügen
- Optional, je nach Konfiguration: Löschen von Zeilen, die in der Quelle nicht mehr vorhanden sind.
Wenn Sie die Zusammenführungsstrategie verwenden möchten, müssen Sie die Eigenschaft unique_key angeben, mit der dbt die übereinstimmenden Zeilen zwischen der Ausgabe Ihres Modells und der vorhandenen Tabelle identifizieren kann. Ein Beispiel finden Sie unten.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
Fehlerbehebung
Sie können die Python-Ausführung in den dbt-Logs beobachten.
Außerdem können Sie den Code und die Logs (einschließlich früherer Ausführungen) auf der Seite Colab Enterprise-Ausführungen ansehen.
Zu „Colab Enterprise-Ausführungen“
Abrechnung
Bei Verwendung des dbt-bigquery-Adapters mit BigQuery DataFrames Google Cloud fallen Gebühren für Folgendes an:
Notebook-Ausführung: Ihnen wird die Ausführung der Notebook-Laufzeit in Rechnung gestellt. Weitere Informationen finden Sie unter Preise für Notebook-Laufzeiten.
Ausführung von BigQuery-Abfragen: Im Notebook wandelt BigQuery DataFrames Python in SQL um und führt den Code in BigQuery aus. Die Abrechnung erfolgt gemäß Ihrer Projektkonfiguration und Ihrer Abfrage, wie unter Preise für BigQuery DataFrames beschrieben.
Sie können das folgende Abrechnungslabels in der BigQuery-Abrechnungskonsole verwenden, um den Abrechnungsbericht für die Notebook-Ausführung und für die BigQuery-Ausführungen herauszufiltern, die vom dbt-bigquery-Adapter ausgelöst werden:
- BigQuery-Ausführungslabels:
bigframes-dbt-api
Nächste Schritte
- Weitere Informationen zu dbt und BigQuery DataFrames finden Sie unter BigQuery DataFrames mit dbt-Python-Modellen verwenden.
- Weitere Informationen zu dbt-Python-Modellen finden Sie unter Python-Modelle und Konfiguration von Python-Modellen.
- Weitere Informationen zu Colab Enterprise-Notebooks finden Sie unter Colab Enterprise-Notebook mit der Google Cloud Console erstellen.
- Weitere Informationen zu Google Cloud -Partnern finden Sie unter Google Cloud Ready – BigQuery-Partner.