
העברה של עדכונים בטבלה בזמן אמת באמצעות סימון נתונים שהשתנו (CDC)
הטמעה של נתוני שינוי (CDC) ב-BigQuery מעדכנת את הטבלאות ב-BigQuery על ידי עיבוד של שינויים שהועברו בסטרימינג והחלתם על נתונים קיימים. הסנכרון הזה מתבצע באמצעות פעולות של הכנסה או עדכון (upsert) ומחיקה של שורות, שמוזרמות בזמן אמת על ידי BigQuery Storage Write API. מומלץ להכיר את ה-API הזה לפני שממשיכים.
לפני שמתחילים
מקצים תפקידים של ניהול זהויות והרשאות גישה (IAM) שמעניקים למשתמשים את ההרשאות הנדרשות לביצוע כל משימה במאמר הזה, ומוודאים שהתהליך שלכם עומד בכל הדרישות המוקדמות.
ההרשאות הנדרשות
כדי לקבל את ההרשאה שנדרשת לשימוש ב-Storage Write API, צריך לבקש מהאדמין להקצות לכם את תפקיד ה-IAM BigQuery Data Editor (roles/bigquery.dataEditor).
כדי לקרוא הסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
התפקיד שמוגדר מראש מכיל את ההרשאה bigquery.tables.updateData, שנדרשת כדי להשתמש ב-Storage Write API.
יכול להיות שתוכלו לקבל את ההרשאה הזו גם בתפקידים בהתאמה אישית או בתפקידים אחרים שמוגדרים מראש.
במאמר מבוא ל-IAM יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery.
דרישות מוקדמות
כדי להשתמש בהטמעה של CDC ב-BigQuery, תהליך העבודה צריך לעמוד בתנאים הבאים:
- חובה להשתמש ב-Storage Write API בזרם ברירת המחדל.
- חובה להשתמש בפורמט protobuf כפורמט ההעלאה. הפורמט Apache Arrow לא נתמך.
- צריך להגדיר מפתחות ראשיים לטבלת היעד ב-BigQuery. יש תמיכה במפתחות ראשיים מורכבים שמכילים עד 16 עמודות.
- צריכים להיות זמינים מספיק משאבי מחשוב של BigQuery כדי לבצע את פעולות השורות של CDC. חשוב לדעת שאם פעולות של שינוי שורות ב-CDC נכשלות, יכול להיות שיישארו נתונים שלא התכוונתם למחוק. מידע נוסף מופיע במאמר שיקולים לגבי נתונים שנמחקו.
מציינים שינויים ברשומות קיימות
בייבוא של נתוני CDC ב-BigQuery, עמודת ה-pseudocolumn _CHANGE_TYPE מציינת את סוג השינוי שצריך לעבד בכל שורה. כדי להשתמש ב-CDC, צריך להגדיר את _CHANGE_TYPE כשמעבירים בסטרימינג שינויים בשורות באמצעות Storage Write API. בעמודה הווירטואלית _CHANGE_TYPE אפשר להזין רק את הערכים UPSERT ו-DELETE. טבלה נחשבת פעילה עם CDC בזמן ש-Storage Write API מעביר בסטרימינג שינויים בשורות לטבלה באופן הזה.
דוגמה עם הערכים UPSERT ו-DELETE
נניח שיש לכם את הטבלה הבאה ב-BigQuery:
| מזהה | שם | שכר |
|---|---|---|
| 100 | צ'רלי | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5,000 |
השינויים הבאים בשורות מועברים בסטרימינג על ידי Storage Write API:
| מזהה | שם | שכר | _CHANGE_TYPE |
|---|---|---|---|
| 100 | מחיקה | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
הטבלה המעודכנת היא:
| מזהה | שם | שכר |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5,000 |
| 105 | Izumi | 6000 |
ניהול של נתונים לא עדכניים בטבלה
כברירת מחדל, בכל פעם שמריצים שאילתה, BigQuery מחזיר את התוצאות העדכניות ביותר. כדי לספק את התוצאות העדכניות ביותר כשמריצים שאילתה בטבלה עם CDC פעיל, מערכת BigQuery צריכה להחיל כל שינוי בשורה שמועבר בסטרימינג עד לזמן תחילת השאילתה, כדי שהשאילתה תתבצע על הגרסה העדכנית ביותר של הטבלה. החלת השינויים האלה בשורות בזמן הריצה של השאילתה מגדילה את זמן האחזור ואת העלות של השאילתה. עם זאת, אם אתם לא צריכים תוצאות של שאילתות שמתעדכנות באופן מלא, אתם יכולים להגדיר את האפשרות max_staleness בטבלה כדי להפחית את העלות ואת זמן האחזור של השאילתות. כשמגדירים את האפשרות הזו, BigQuery מחיל שינויים בשורות לפחות פעם אחת בפרק הזמן שמוגדר בערך max_staleness. כך אפשר להריץ שאילתות בלי לחכות להחלת העדכונים, אבל הנתונים לא יהיו עדכניים לגמרי.
ההתנהגות הזו שימושית במיוחד ללוחות בקרה ולדוחות שבהם עדכניות הנתונים לא חיונית. התכונה הזו גם עוזרת לנהל את העלויות, כי היא מאפשרת לכם לשלוט בתדירות שבה BigQuery מבצע שינויים בשורות.
הרצת שאילתות על טבלאות עם האפשרות max_staleness
כששולחים שאילתה לטבלה עם האפשרות max_staleness, BigQuery מחזיר את התוצאה על סמך הערך של max_staleness והשעה שבה התרחשה פעולת ההחלה האחרונה, שמיוצגת על ידי חותמת הזמן upsert_stream_apply_watermark של הטבלה.
בדוגמה הבאה, האפשרות max_staleness בטבלה מוגדרת ל-10 דקות, והפעולה האחרונה של החלת העבודה התרחשה בשעה T20:
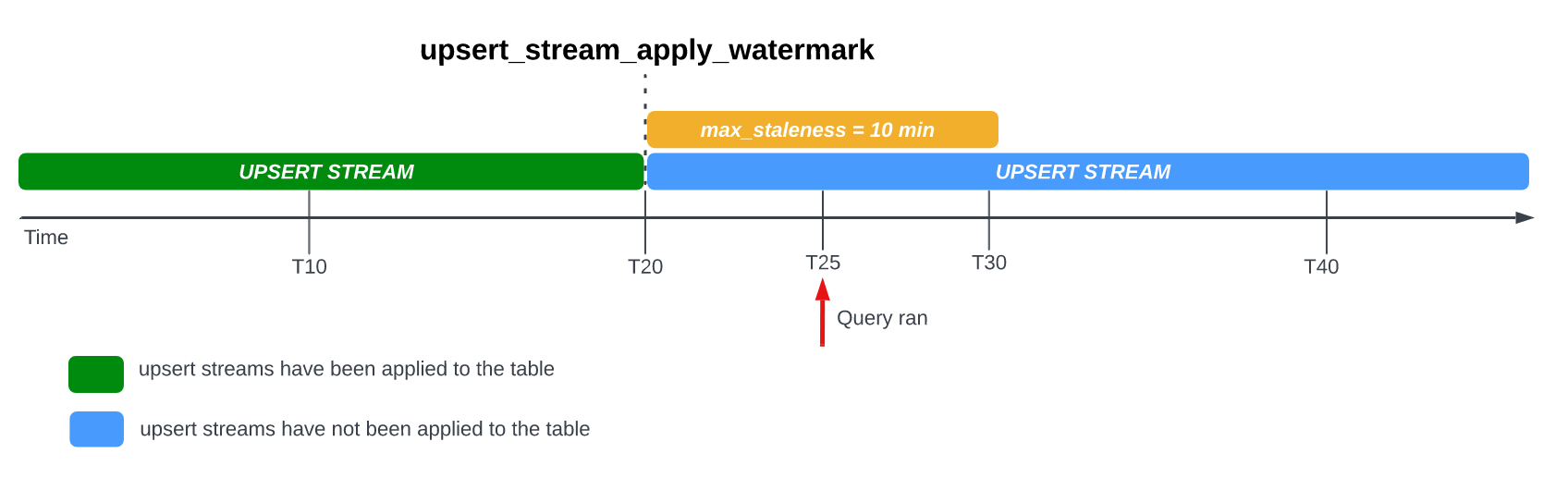
אם תשאלו את הטבלה בשעה T25, הגרסה הנוכחית של הטבלה תהיה ישנה ב-5 דקות, שזה פחות מmax_staleness המרווח של 10 דקות. במקרה הזה, BigQuery מחזיר את גרסת הבסיס של הטבלה בשעה T20, כלומר הנתונים שמוחזרים גם הם בני 5 דקות.
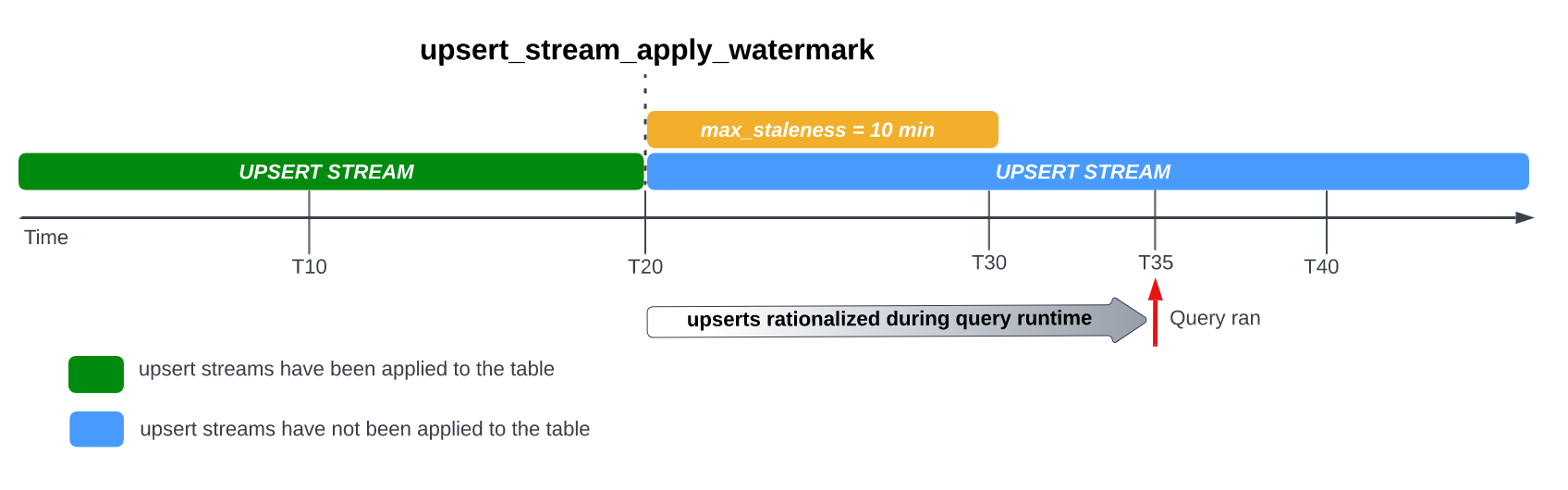
כשמגדירים את האפשרות max_staleness בטבלה, BigQuery מחיל את השינויים בהמתנה בשורות לפחות פעם אחת בתוך המרווח max_staleness. עם זאת, במקרים מסוימים, יכול להיות ש-BigQuery לא ישלים את התהליך של החלת השינויים האלה בשורות בהמתנה בתוך המרווח.
לדוגמה, אם שולחים שאילתה לטבלה בזמן T35, ותהליך החלת השינויים בשורות בהמתנה לא הסתיים, הגרסה הנוכחית של הטבלה לא עדכנית כבר 15 דקות, שזה יותר ממרווח הזמן של 10 דקות max_staleness.
במקרה הזה, בזמן ההרצה של השאילתה, BigQuery מחיל את כל השינויים בשורות בין T20 ל-T35 על השאילתה הנוכחית, כלומר הנתונים שנכללים בשאילתה עדכניים לחלוטין, אבל יש עלות של השהיה נוספת בשאילתה.
זה נחשב לתהליך מיזוג בזמן ריצה.
ערך מומלץ max_staleness
הערך של max_staleness בטבלה צריך להיות בדרך כלל הגבוה מבין שני הערכים הבאים:
- הזמן המקסימלי שבו הנתונים יכולים להיות לא עדכניים בתהליך העבודה.
- כפול מהזמן המקסימלי שנדרש להחלת שינויי upsert בטבלה, בתוספת מאגר זמני נוסף.
כדי לחשב את הזמן שנדרש להחלת שינויים שבוצעו בפעולת upsert על טבלה קיימת, משתמשים בשאילתת ה-SQL הבאה כדי לקבוע את משך הזמן של 95% מהמשימות להחלת שינויים ברקע, בתוספת מרווח ביטחון של שבע דקות כדי לאפשר את ההמרה של האחסון שעבר אופטימיזציה לכתיבה ב-BigQuery (מאגר זמני לנתונים זורמים).
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
מחליפים את מה שכתוב בשדות הבאים:
-
REGION: שם האזור שבו נמצא הפרויקט. לדוגמה,us. -
PROJECT_ID: המזהה של הפרויקט שמכיל את הטבלאות ב-BigQuery שמשתנות על ידי הטמעה של CDC ב-BigQuery.
משך הזמן של משימות הפעלה ברקע מושפע מכמה גורמים, כולל מספר הפעולות של CDC ומורכבותן שמונפקות בתוך מרווח הזמן של הנתונים המיושנים, גודל הטבלה והזמינות של משאבי BigQuery. מידע נוסף על זמינות משאבים זמין במאמר שינוי הגודל של הזמנות ברקע ומעקב אחריהן.
יצירת טבלה באמצעות האפשרות max_staleness
כדי ליצור טבלה באמצעות האפשרות max_staleness, משתמשים במשפט CREATE TABLE.
בדוגמה הבאה נוצרת הטבלה employees עם מגבלה של max_staleness דקות:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
שינוי האפשרות max_staleness בטבלה קיימת
כדי להוסיף או לשנות מגבלת max_staleness בטבלה קיימת, משתמשים בהצהרה ALTER TABLE.
בדוגמה הבאה משנים את המגבלה max_staleness של הטבלה employees ל-15 דקות:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
קביעת הערך הנוכחי של טבלה max_staleness
כדי לקבוע את הערך הנוכחי של max_staleness בטבלה, מריצים שאילתה בתצוגה INFORMATION_SCHEMA.TABLE_OPTIONS.
בדוגמה הבאה נבדק הערך הנוכחי של max_staleness בטבלה
mytable:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
מחליפים את מה שכתוב בשדות הבאים:
-
DATASET_NAME: השם של מערך הנתונים שבו נמצאת הטבלה. -
TABLE_NAME: שם הטבלה.
התוצאות מראות שהערך של max_staleness הוא 10 דקות:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
מעקב אחרי ההתקדמות של פעולת upsert בטבלה
כדי לעקוב אחרי מצב הטבלה ולבדוק מתי בוצעו לאחרונה שינויים בשורות, שולחים שאילתה אל התצוגה INFORMATION_SCHEMA.TABLES כדי לקבל את חותמת הזמן upsert_stream_apply_watermark.
בדוגמה הבאה נבדק הערך upsert_stream_apply_watermark של הטבלה mytable:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
מחליפים את מה שכתוב בשדות הבאים:
-
DATASET_NAME: השם של מערך הנתונים שבו נמצאת הטבלה. -
TABLE_NAME: שם הטבלה.
התוצאה אמורה להיראות כך:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
פעולות upsert מבוצעות על ידי חשבון השירות bigquery-adminbot@system.gserviceaccount.com ומופיעות בהיסטוריית העבודות של הפרויקט שמכיל את הטבלה עם CDC פעיל.
ניהול סדר מותאם אישית
כשמבצעים הוספה או עדכון של רשומות בסטרימינג ל-BigQuery, התנהגות ברירת המחדל של סידור רשומות עם מפתחות ראשיים זהים נקבעת לפי זמן המערכת ב-BigQuery שבו הרשומה נקלטה ב-BigQuery. במילים אחרות, לרשומה שהוכנסה לאחרונה עם חותמת הזמן העדכנית ביותר יש עדיפות על פני רשומה שהוכנסה קודם לכן עם חותמת זמן ישנה יותר. במקרים מסוימים, כמו מקרים שבהם מתבצעים עדכונים והוספות (upserts) מאוד תכופים לאותו מפתח ראשי בחלון זמן קצר מאוד, או מקרים שבהם סדר העדכונים וההוספות לא מובטח, יכול להיות שהפתרון הזה לא יספיק. במקרים כאלה, יכול להיות שיהיה צורך במפתח הזמנה שסופק על ידי המשתמש.
כדי להגדיר מפתחות סידור שסופקו על ידי המשתמש, משתמשים בעמודה הווירטואלית _CHANGE_SEQUENCE_NUMBER כדי לציין את הסדר שבו BigQuery צריך להחיל רשומות, על סמך הערך הגדול יותר של _CHANGE_SEQUENCE_NUMBER בין שתי רשומות תואמות עם אותו מפתח ראשי. העמודה הווירטואלית _CHANGE_SEQUENCE_NUMBER היא עמודה אופציונלית שמקבלת רק ערכים בפורמט קבוע STRING.
פורמט _CHANGE_SEQUENCE_NUMBER
בעמודה הווירטואלית _CHANGE_SEQUENCE_NUMBER אפשר להזין רק ערכים של STRING, שנכתבים בפורמט קבוע. הפורמט הקבוע הזה משתמש בערכים STRING שנכתבים בפורמט הקסדצימלי, ומחולקים לקטעים באמצעות קו נטוי /. כל מקטע יכול לכלול עד 16 תווים הקסדצימליים, ומותרים עד ארבעה מקטעים לכל _CHANGE_SEQUENCE_NUMBER. הטווח המותר של
_CHANGE_SEQUENCE_NUMBER תומך בערכים בין 0/0/0/0 לבין
FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
הערכים של _CHANGE_SEQUENCE_NUMBER יכולים לכלול אותיות קטנות וגדולות.
אפשר להשתמש בקטע אחד כדי להגדיר מפתחות בסיסיים למיון. לדוגמה, כדי להזמין מפתחות רק על סמך חותמת הזמן של עיבוד רשומה משרת אפליקציות, אפשר להשתמש בקטע אחד: '2024-04-30 11:19:44 UTC', שמוצג כהקסדצימלי על ידי המרת חותמת הזמן למילישניות מ-Epoch, '18F2EBB6480' במקרה הזה. הלוגיקה להמרת נתונים לפורמט הקסדצימלי היא באחריות הלקוח שמבצע את הפעולה ב-BigQuery באמצעות Storage Write API.
התמיכה בכמה קטעים מאפשרת לשלב כמה ערכים של לוגיקת עיבוד במפתח אחד, כדי להתאים לתרחישי שימוש מורכבים יותר. לדוגמה, כדי להזמין מפתחות על סמך חותמת הזמן של עיבוד רשומה משרת אפליקציות, מספר רצף ביומן והסטטוס של הרשומה, אפשר להשתמש בשלושה קטעים: '2024-04-30 11:19:44 UTC' / '123' / 'complete', כל אחד מהם מבוטא כהקסדצימלי.
סדר הקטעים הוא שיקול חשוב לדירוג של לוגיקת העיבוד. מערכת BigQuery משווה את הערכים של _CHANGE_SEQUENCE_NUMBER על ידי השוואה של החלק הראשון, ואז השוואה של החלק הבא רק אם החלקים הקודמים היו שווים.
BigQuery משתמש ב-_CHANGE_SEQUENCE_NUMBER כדי לבצע מיון על ידי השוואה בין שני שדות _CHANGE_SEQUENCE_NUMBER או יותר כערכים מספריים לא חתומים.
כדאי לעיין בדוגמאות הבאות להשוואה ובתוצאות העדיפות שלהן:_CHANGE_SEQUENCE_NUMBER
דוגמה 1:
- רשומה מס' 1:
_CHANGE_SEQUENCE_NUMBER= '77' - רשומה מס' 2:
_CHANGE_SEQUENCE_NUMBER= '7B'
תוצאה: רשומה מס' 2 נחשבת לרשומה העדכנית ביותר כי '7B' > '77' (כלומר, '123' > '119')
- רשומה מס' 1:
דוגמה 2:
- רשומה מס' 1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - הקלטה מס' 2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
תוצאה: רשומה מס' 2 נחשבת לרשומה האחרונה כי FFF/ABC > FFF/B (כלומר, 4095/2748 > 4095/11)
- רשומה מס' 1:
דוגמה 3:
- רשומה מס' 1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - רשומה מס' 2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
תוצאה: רשומה מספר 2 נחשבת לרשומה העדכנית ביותר כי 'ABC' > 'BA/FFFFFFFF' (כלומר, '2748' > '186/4294967295')
- רשומה מס' 1:
דוגמה 4:
- הקלטה מס' 1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - רשומה מס' 2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
תוצאה: רשומה מספר 1 נחשבת לרשומה העדכנית ביותר כי 'FFF/ABC' > 'ABC' (כלומר '4095/2748' > '2748')
- הקלטה מס' 1:
אם שני ערכים של _CHANGE_SEQUENCE_NUMBER זהים, הרשומה עם זמן ההטמעה האחרון במערכת BigQuery מקבלת עדיפות על פני רשומות שהוטמעו קודם.
כשמשתמשים בסדר מותאם אישית של טבלה, צריך תמיד לספק את הערך _CHANGE_SEQUENCE_NUMBER. כל בקשות הכתיבה שלא מציינות את הערך _CHANGE_SEQUENCE_NUMBER, שמובילות לשילוב של שורות עם ערכים של _CHANGE_SEQUENCE_NUMBER ושורות ללא ערכים כאלה, יגרמו לסידור בלתי צפוי.
הגדרת הזמנה ב-BigQuery לשימוש בהטמעה של CDC
אתם יכולים להשתמש בהזמנות של BigQuery כדי להקצות משאבי מחשוב ייעודיים של BigQuery לפעולות של שינוי שורות ב-CDC. הזמנות מאפשרות לכם להגדיר מכסה לעלות של הפעולות האלה. הגישה הזו שימושית במיוחד בתהליכי עבודה עם פעולות CDC תכופות על טבלאות גדולות, שעלולות להיות יקרות כי הן כרוכות בעיבוד של מספר גדול של בייטים בכל פעולה.
משימות הטמעה של BigQuery CDC שמחילות שינויים בשורות בהמתנה במרווח max_staleness נחשבות למשימות ברקע ומשתמשות בסוג ההקצאה BACKGROUND או BACKGROUND_CHANGE_DATA_CAPTURE, ולא בסוג ההקצאה QUERY.
לעומת זאת, שאילתות מחוץ לטווח max_staleness שדורשות שינויים בשורות שיוחלו בזמן הריצה של השאילתה משתמשות בסוג ההקצאה QUERY. בטבלאות ללא הגדרה של max_staleness או בטבלאות שבהן max_staleness מוגדר כ-0, נעשה שימוש גם בסוג ההקצאה QUERY.
משימות רקע של הטמעת נתונים ב-CDC ב-BigQuery שמתבצעות ללא הקצאה של BACKGROUND או BACKGROUND_CHANGE_DATA_CAPTURE, מחויבות לפי תמחור על פי דרישה.
השיקול הזה חשוב כשמתכננים את אסטרטגיית ניהול עומסי העבודה (workload) להטמעה של CDC ב-BigQuery.
כדי להגדיר הזמנה ב-BigQuery לשימוש ב-CDC, מתחילים בהגדרת הזמנה באזור שבו נמצאים הטבלאות ב-BigQuery. למידע על גודל ההזמנה, אפשר לעיין במאמר גודל ההזמנה ומעקב אחרי הזמנות BACKGROUND.
אחרי שיוצרים הזמנה, מקצים את פרויקט BigQuery להזמנה ומגדירים את האפשרות job_type לערך BACKGROUND על ידי הפעלת ההצהרה הבאה: CREATE ASSIGNMENT
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
מחליפים את מה שכתוב בשדות הבאים:
-
ADMIN_PROJECT_ID: המזהה של פרויקט הניהול שבבעלותו נמצאת ההזמנה. -
REGION: שם האזור שבו נמצא הפרויקט. לדוגמה,us. -
RESERVATION_NAME: השם של ההזמנה. -
ASSIGNMENT_ID: המזהה של ההקצאה. המזהה צריך להיות ייחודי לפרויקט ולמיקום, להתחיל ולהסתיים באות קטנה או במספר, ולהכיל רק אותיות קטנות, מספרים ומקפים. -
PROJECT_ID: המזהה של הפרויקט שמכיל את הטבלאות ב-BigQuery שמשתנות על ידי הטמעת CDC ב-BigQuery. הפרויקט הזה משויך להזמנה.
גודל והזמנות של BACKGROUND צגים
הזמנות קובעות את כמות משאבי המחשוב שזמינים לביצוע פעולות מחשוב ב-BigQuery. הזמנת משאבים קטנה מדי עלולה להאריך את זמן העיבוד של פעולות שינוי שורות ב-CDC. כדי לקבוע את הגודל של הזמנה בצורה מדויקת, צריך לעקוב אחרי צריכת המשבצות ההיסטורית של הפרויקט שמבצע את פעולות ה-CDC באמצעות שאילתה בתצוגה INFORMATION_SCHEMA.JOBS_TIMELINE:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
מחליפים את REGION בשם האזור שבו נמצא הפרויקט. לדוגמה,
us.
שיקולים לגבי נתונים שנמחקו
- פעולות הטמעה של CDC ב-BigQuery משתמשות במשאבי מחשוב של BigQuery. אם פעולות ה-CDC מוגדרות לשימוש בחיוב על פי דרישה, הן מתבצעות באופן קבוע באמצעות משאבים פנימיים של BigQuery. אם פעולות ה-CDC מוגדרות עם הזמנה של
BACKGROUNDאוBACKGROUND_CHANGE_DATA_CAPTURE, הזמינות של המשאבים בפעולות ה-CDC תהיה בהתאם להזמנה שהוגדרה. אם אין מספיק משאבים זמינים בהזמנה שהוגדרה, יכול להיות שייקח יותר זמן מהצפוי לעבד פעולות CDC, כולל מחיקה. - פעולת CDC
DELETEנחשבת כפעולה שהוחלה רק אחרי שחותמת הזמןupsert_stream_apply_watermarkחלפה את חותמת הזמן שבה Storage Write API העביר את הפעולה בסטרימינג. מידע נוסף על חותמת הזמןupsert_stream_apply_watermarkזמין במאמר מעקב אחרי התקדמות של פעולת upsert בטבלה. - כדי להחיל פעולות CDC
DELETEשמגיעות לא לפי הסדר, מערכת BigQuery שומרת חלון שימור של מחיקות למשך יומיים. פעולות בטבלהDELETEמאוחסנות למשך התקופה הזו לפני שמתחיל Google Cloud תהליך מחיקת הנתונים הרגיל. פעולותDELETEשמתבצעות במסגרת חלון השמירה למחיקה מחויבות לפי תמחור האחסון הרגיל ב-BigQuery.
מגבלות
- תהליך ההטמעה של CDC ב-BigQuery לא מבצע אכיפה של מפתחות, ולכן חשוב לוודא שהמפתחות הראשיים שלכם הם ייחודיים.
- מספר העמודות במפתחות ראשיים לא יכול להיות גדול מ-16.
- בטבלאות עם CDC פעיל לא יכולות להיות יותר מ-2,000 עמודות ברמה העליונה שמוגדרות על ידי הסכימה של הטבלה.
- בטבלאות עם CDC פעיל אי אפשר לבצע את הפעולות הבאות:
- שינוי של פקודות שפת טיפול בנתונים (DML) כמו
DELETE,UPDATEו-MERGE - הרצת שאילתות על טבלאות עם תווים כלליים לחיפוש
- אינדקסים של חיפוש
- שינוי של פקודות שפת טיפול בנתונים (DML) כמו
- בטבלאות עם CDC פעיל שמבצעות מיזוג בזמן ריצה כי הערך
max_stalenessשל הטבלה נמוך מדי, אי אפשר לבצע את הפעולות הבאות: - פעולות ייצוא של BigQuery בטבלאות עם CDC פעיל לא מייצאות שינויים בשורות שהועברו לאחרונה בסטרימינג ושעדיין לא הוחלו על ידי עבודת רקע. כדי לייצא את הטבלה המלאה, צריך להשתמש בדף חשבון
EXPORT DATA. - אם השאילתה מפעילה מיזוג בזמן ריצה בטבלה עם חלוקה למחיצות, כל הטבלה נסרקת, גם אם השאילתה מוגבלת לקבוצת משנה של המחיצות.
- אם אתם משתמשים ב-Standard edition,
BACKGROUNDהזמנות לא זמינות, ולכן כשמחילים שינויים בשורות בהמתנה נעשה שימוש במודל התמחור על פי דרישה. עם זאת, אתם יכולים לשלוח שאילתות לטבלאות עם CDC פעיל, בלי קשר למהדורה שלכם. - אי אפשר להריץ שאילתות על העמודות הפסאודו
_CHANGE_TYPEו-_CHANGE_SEQUENCE_NUMBERכשמבצעים קריאה של טבלה. - אין תמיכה בשילוב של שורות עם ערכים
UPSERTאוDELETEבעמודה_CHANGE_TYPEעם שורות שכוללות ערכיםINSERTאו ערכים לא מוגדרים בעמודה_CHANGE_TYPEבאותו חיבור, והפעולה הזו גורמת לשגיאת האימות הבאה:The given value is not a valid CHANGE_TYPE.
תמחור של הטמעה של CDC ב-BigQuery
הטמעת נתונים ב-BigQuery CDC מתבצעת באמצעות Storage Write API, אחסון הנתונים מתבצע ב-BigQuery, ופעולות השינוי בשורות מתבצעות באמצעות מחשוב ב-BigQuery. כל הפעולות האלה כרוכות בעלויות. מידע על תמחור זמין במאמר בנושא תמחור ב-BigQuery.
חישוב אומדנים של עלויות ההטמעה של CDC ב-BigQuery
בנוסף לשיטות מומלצות כלליות להערכת עלויות ב-BigQuery, חשוב להעריך את העלויות של הטמעת CDC ב-BigQuery בתהליכי עבודה שכוללים כמויות גדולות של נתונים, הגדרת max_staleness נמוכה או נתונים שמשתנים לעיתים קרובות.
התמחור של הכנסת נתונים ל-BigQuery והתמחור של אחסון ב-BigQuery מחושבים ישירות לפי כמות הנתונים שאתם מכניסים ומאחסנים, כולל עמודות פסאודו. עם זאת, יכול להיות שיהיה קשה יותר להעריך את התמחור של מחשוב ב-BigQuery, כי הוא קשור לשימוש במשאבי מחשוב שמשמשים להפעלת משימות של הטמעת נתונים ב-CDC ב-BigQuery.
משימות ההטמעה של BigQuery CDC מחולקות לשלוש קטגוריות:
- משימות להחלת שינויים ברקע: משימות שפועלות ברקע במרווחי זמן קבועים שמוגדרים על ידי הערך
max_stalenessבטבלה. העבודות האלה מחילות שינויים בשורות שהועברו בסטרימינג לאחרונה על טבלאות עם CDC פעיל. - Query jobs: שאילתות GoogleSQL שמופעלות בחלון
max_stalenessוקוראות רק מהבסיס של טבלה עם CDC פעיל. - מיזוג בזמן ריצה: מיזוג שמופעל על ידי שאילתות GoogleSQL אד-הוק שמופעלות מחוץ לחלון
max_staleness. העבודות האלה צריכות לבצע מיזוג דינמי של נתוני הבסיס של טבלה עם CDC פעיל, ושל השינויים בשורות ששודרו לאחרונה בזמן הריצה של השאילתה. סוג העבודה הזה לא מקדם את חותמת הזמןupsert_stream_apply_watermark.
רק משימות של שאילתות מנצלות את החלוקה למחיצות ב-BigQuery. אי אפשר להשתמש בחלוקה למחיצות בעבודות של החלת שינויים ברקע ובעבודות של מיזוג בזמן ריצה, כי כשמחילים שינויים בשורות שהועברו לאחרונה בסטרימינג, אין ערובה לכך שהעדכונים שהועברו בסטרימינג יחולו על מחיצת הטבלה הנכונה. במילים אחרות, טבלת הבסיס המלאה נקראת במהלך משימות של החלת הגדרות ברקע ומשימות של מיזוג בזמן ריצה. מאותה סיבה, רק משימות של שאילתות יכולות להפיק תועלת מסינון בעמודות של אשכולות BigQuery. הבנת כמות הנתונים שנקראים כדי לבצע פעולות CDC עוזרת להעריך את העלות הכוללת.
אם כמות הנתונים שנקראים מטבלת הבסיס גבוהה, כדאי להשתמש במודל התמחור לפי קיבולת של BigQuery, שלא מבוסס על כמות הנתונים שעברו עיבוד.
שיטות מומלצות להטמעת נתונים ב-BigQuery CDC
בנוסף לשיטות המומלצות הכלליות לניהול העלויות ב-BigQuery, אפשר להשתמש בטכניקות הבאות כדי לייעל את העלויות של פעולות הטמעת נתונים ב-BigQuery CDC:
- אלא אם יש צורך בכך, מומלץ להימנע מהגדרת האפשרות
max_stalenessשל טבלה עם ערך נמוך מאוד. הערךmax_stalenessיכול להגדיל את מספר המקרים של משימות החלה ברקע ומשימות מיזוג בזמן ריצה, שהן יקרות יותר ואיטיות יותר ממשימות של שאילתות. הנחיות מפורטות מופיעות במאמר בנושא ערך מומלץ של טבלתmax_staleness. - מומלץ להגדיר הזמנה ב-BigQuery לשימוש עם טבלאות CDC.
אחרת, עבודות של החלת כללים ברקע ועבודות של מיזוג בזמן ריצה משתמשות בתמחור על פי דרישה,
שיכול להיות יקר יותר בגלל עיבוד נתונים רב יותר. פרטים נוספים זמינים במאמרים בנושא הזמנות ב-BigQuery ואיך קובעים את הגודל של הזמנה ב-
BACKGROUNDועוקבים אחרי השימוש בה.
המאמרים הבאים
- איך מטמיעים את זרם ברירת המחדל של Storage Write API
- שיטות מומלצות לשימוש ב-Storage Write API
- איך משתמשים ב-Datastream כדי לשכפל מסדי נתונים של טרנזקציות ל-BigQuery באמצעות הטמעה של BigQuery CDC.