
Migrazione da Oracle a BigQuery
Questo documento fornisce indicazioni di alto livello su come eseguire la migrazione da Oracle a BigQuery. Descrive le differenze architetturali fondamentali e suggerisce modi per eseguire la migrazione da data warehouse e data mart in esecuzione su Oracle RDBMS (incluso Exadata) a BigQuery. Questo documento fornisce dettagli che possono essere applicati anche a Exadata, ExaCC e Oracle Autonomous Data Warehouse, in quanto utilizzano software Oracle compatibile.
Questo documento è destinato ad architetti aziendali, DBA, sviluppatori di applicazioni e professionisti della sicurezza IT che vogliono eseguire la migrazione da Oracle a BigQuery e risolvere le sfide tecniche nel processo di migrazione.
Puoi anche utilizzare la traduzione SQL batch per eseguire la migrazione degli script SQL in blocco oppure la traduzione SQL interattiva per tradurre query ad hoc. Oracle SQL, PL/SQL ed Exadata sono supportati da entrambi gli strumenti in anteprima.
Pre-migrazione
Per garantire una migrazione del data warehouse riuscita, inizia a pianificare la strategia di migrazione all'inizio della cronologia del progetto. Per informazioni su come pianificare sistematicamente il lavoro di migrazione, vedi Cosa e come eseguire la migrazione: il framework di migrazione.
Pianificazione della capacità di BigQuery
Dietro le quinte, la velocità effettiva delle analisi in BigQuery viene misurata in termini di slot. Uno slot BigQuery è un'unità proprietaria di Google di capacità di calcolo richiesta per eseguire le query SQL.
BigQuery calcola continuamente il numero di slot richiesti dalle query durante l'esecuzione, ma li assegna alle query in base a uno scheduler equo.
Quando pianifichi la capacità per gli slot BigQuery, puoi scegliere tra i seguenti modelli di determinazione dei prezzi:
Prezzi on demand: con i prezzi on demand, BigQuery addebita i costi in base al numero di byte elaborati (dimensioni dei dati), quindi paghi solo per le query che esegui. Per ulteriori informazioni su come BigQuery determina le dimensioni dei dati, vedi Calcolo delle dimensioni dei dati. Poiché gli slot determinano la capacità di calcolo sottostante, puoi pagare l'utilizzo di BigQuery in base al numero di slot necessari (anziché ai byte elaborati). Per impostazione predefinita, Google Cloud i progetti sono limitati a un massimo di 2000 slot.
Prezzi basati sulla capacità: Con i prezzi basati sulla capacità, acquisti prenotazioni di slot BigQuery (un minimo di 100) anziché pagare per i byte elaborati dalle query che esegui. Consigliamo i prezzi basati sulla capacità per i carichi di lavoro del data warehouse aziendale, che in genere vedono molte query di report e di estrazione, caricamento e trasformazione (ELT) simultanee con un consumo prevedibile.
Per facilitare la stima degli slot, ti consigliamo di configurare il monitoraggio di BigQuery utilizzando Cloud Monitoring e di analizzare gli audit log utilizzando BigQuery. Molti clienti utilizzano Looker Studio (ad esempio, vedi un esempio open source di una dashboard di Looker Studio), Looker o Tableau come frontend per visualizzare i dati dei log di controllo di BigQuery, in particolare per l'utilizzo degli slot in query e progetti. Puoi anche utilizzare i dati delle tabelle di sistema BigQuery per monitorare l'utilizzo degli slot in job e prenotazioni. Per un esempio, consulta un esempio open source di una dashboard di Looker Studio.
Il monitoraggio e l'analisi regolari dell'utilizzo degli slot ti aiutano a stimare il numero totale di slot necessari alla tua organizzazione man mano che cresce su Google Cloud.
Ad esempio, supponiamo di prenotare inizialmente 4000 slot BigQuery per eseguire 100 query di media complessità contemporaneamente. Se noti tempi di attesa elevati nei piani di esecuzione delle query e le dashboard mostrano un utilizzo elevato degli slot, ciò potrebbe indicare che hai bisogno di slot BigQuery aggiuntivi per supportare i tuoi carichi di lavoro. Se vuoi acquistare slot autonomamente tramite impegni annuali o triennali, puoi iniziare a utilizzare le prenotazioni BigQuery utilizzando la console Google Cloud o lo strumento a riga di comando bq.
Per qualsiasi domanda relativa al tuo piano attuale e alle opzioni precedenti, contatta il tuo rappresentante di vendita.
Sicurezza a Google Cloud
Le sezioni riportate di seguito descrivono i controlli di sicurezza Oracle comuni e come puoi assicurarti che il tuo data warehouse rimanga protetto in un ambiente Google Cloud.
Identity and Access Management (IAM)
Oracle fornisce utenti, privilegi, ruoli e profili per gestire l'accesso alle risorse.
BigQuery utilizza IAM per gestire l'accesso alle risorse e fornisce una gestione dell'accesso centralizzata a risorse e azioni. I tipi di risorse disponibili in BigQuery includono organizzazioni, progetti, set di dati, tabelle e viste. Nella gerarchia dei criteri IAM, i set di dati sono risorse secondarie dei progetti. Una tabella eredita le autorizzazioni dal set di dati che la contiene.
Per concedere l'accesso a una risorsa, assegna uno o più ruoli a un utente, un gruppo o un account di serviziot. I ruoli dell'organizzazione e del progetto influiscono sulla capacità di eseguire job o gestire il progetto, mentre i ruoli del set di dati influiscono sulla capacità di accedere ai dati all'interno di un progetto o di modificarli.
IAM fornisce i seguenti tipi di ruoli:
- I ruoli predefiniti sono pensati per supportare casi d'uso comuni e patterncontrollo dell'accessoo. I ruoli predefiniti forniscono un accesso granulare per un servizio specifico e sono gestiti da Google Cloud.
I ruoli di base includono i ruoli Proprietario, Editor e Visualizzatore.
I ruoli personalizzati forniscono un accesso granulare in base a un elenco di autorizzazioni specificato dall'utente.
Quando assegni a un utente ruoli di base e predefiniti, le autorizzazioni concesse sono l'unione delle autorizzazioni di ogni singolo ruolo.
Sicurezza a livello di riga
Oracle Label Security (OLS) consente di limitare l'accesso ai dati riga per riga. Un caso d'uso tipico per la sicurezza a livello di riga è la limitazione dell'accesso di un venditore agli account che gestisce. Implementando la sicurezza a livello di riga, ottieni un controllo granulare degli accessi.
Per ottenere la sicurezza a livello di riga in BigQuery, puoi utilizzare le viste autorizzate e i criteri di accesso a livello di riga. Per ulteriori informazioni su come progettare e implementare queste norme, consulta Introduzione alla sicurezza a livello di riga di BigQuery.
Crittografia completa del disco
Oracle offre la crittografia TDE (Transparent Data Encryption) e la crittografia di rete per la crittografia dei dati at-rest e in transito. TDE richiede l'opzione Protezione avanzata, che viene concessa in licenza separatamente.
BigQuery cripta tutti i dati at-rest e in transito per impostazione predefinita, indipendentemente dall'origine o da qualsiasi altra condizione, e questa funzionalità non può essere disattivata. BigQuery supporta anche le chiavi di crittografia gestite dal cliente (CMEK) per gli utenti che vogliono controllare e gestire le chiavi di crittografia delle chiavi in Cloud Key Management Service. Per saperne di più sulla crittografia at- Google Cloud, consulta Crittografia at-rest predefinita e Crittografia in transito.
Mascheramento e oscuramento dei dati
Oracle utilizza la mascheratura dei dati in Real Application Testing e l'oscuramento dei dati, che consente di mascherare (oscurare) i dati restituiti dalle query emesse dalle applicazioni.
BigQuery supporta il mascheramento dinamico dei dati a livello di colonna. Puoi utilizzare il mascheramento dei dati per oscurare selettivamente i dati della colonna per gruppi di utenti, consentendo loro comunque di accedere alla colonna.
Puoi utilizzare Sensitive Data Protection per identificare e oscurare le informazioni che consentono l'identificazione personale (PII) sensibili su BigQuery.
Confronto tra BigQuery e Oracle
Questa sezione descrive le principali differenze tra BigQuery e Oracle. Questi punti salienti ti aiutano a identificare gli ostacoli alla migrazione e a pianificare le modifiche necessarie.
Architettura di sistema
Una delle principali differenze tra Oracle e BigQuery è che BigQuery è un EDW cloud serverless con livelli di archiviazione e di calcolo separati che possono essere scalati in base alle esigenze della query. Data la natura dell'offerta serverless di BigQuery, non sei limitato dalle decisioni hardware. Puoi invece richiedere più risorse per le tue query e i tuoi utenti tramite le prenotazioni. BigQuery non richiede inoltre la configurazione del software e dell'infrastruttura sottostanti, come sistema operativo, sistemi di rete e sistemi di archiviazione, inclusi scalabilità e alta disponibilità. BigQuery si occupa di scalabilità, gestione e operazioni amministrative. Il seguente diagramma illustra la gerarchia di archiviazione di BigQuery.
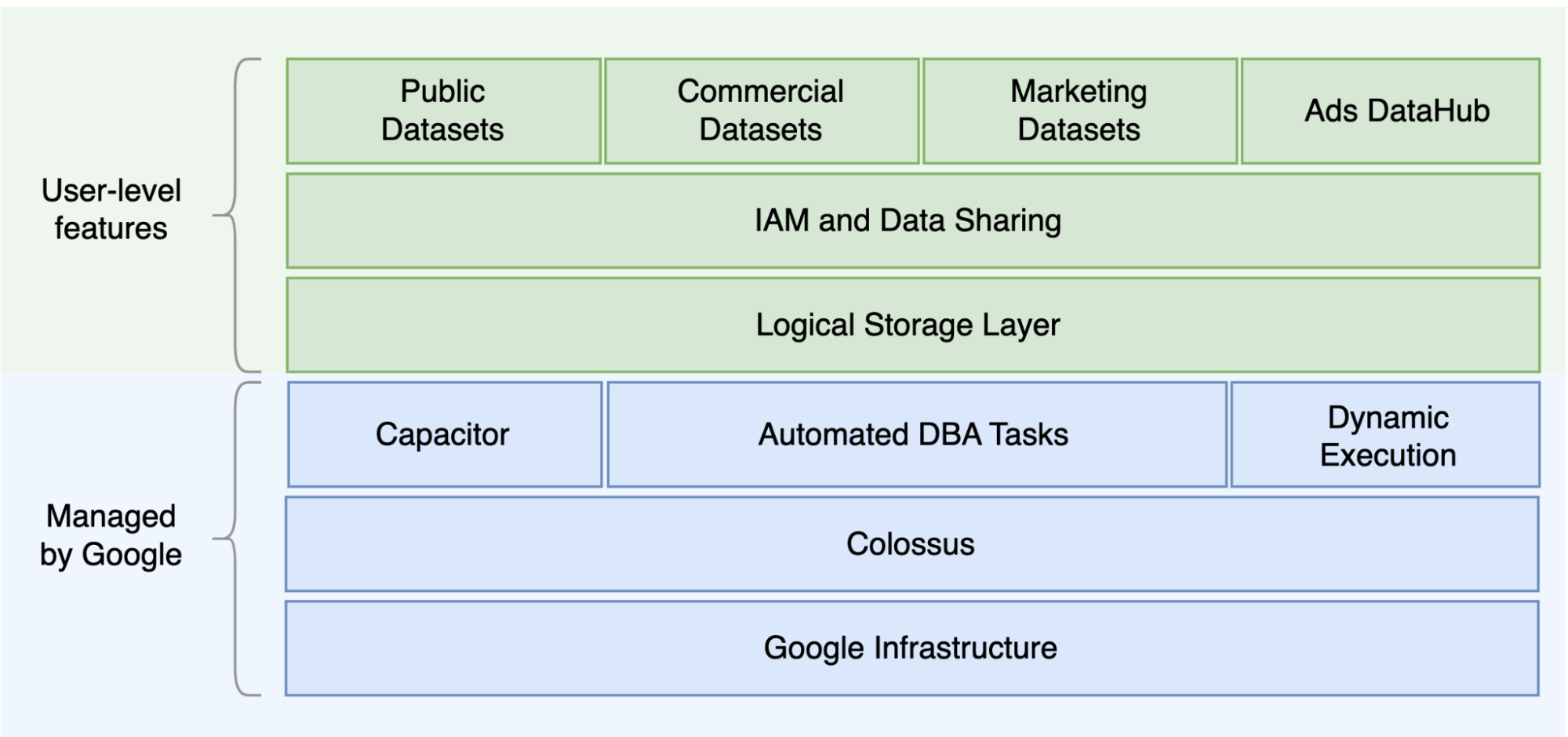
La conoscenza dell'architettura di archiviazione ed elaborazione delle query sottostante, ad esempio la separazione tra archiviazione (Colossus) ed esecuzione delle query (Dremel) e il modo in cui Google Cloud alloca le risorse (Borg) può essere utile per comprendere le differenze comportamentali e ottimizzare le prestazioni e l'efficacia in termini di costi delle query. Per i dettagli, consulta le architetture di sistema di riferimento per BigQuery, Oracle ed Exadata.
Architettura di dati e spazio di archiviazione
La struttura dei dati e dell'archiviazione è una parte importante di qualsiasi sistema di analisi dei dati perché influisce su prestazioni, costi, scalabilità ed efficienza delle query.
BigQuery disaccoppia l'archiviazione e il calcolo dei dati e li archivia in Colossus, dove vengono compressi e memorizzati in un formato colonnare chiamato Capacitor.
BigQuery opera direttamente sui dati compressi senza decomprimerli utilizzando Capacitor. BigQuery fornisce set di dati come astrazione di livello più alto per organizzare l'accesso alle tabelle, come mostrato nel diagramma precedente. Schemi ed etichette possono essere utilizzati per organizzare ulteriormente le tabelle. BigQuery offre il partizionamento per migliorare le prestazioni e i costi delle query e per gestire il ciclo di vita delle informazioni. Le risorse di archiviazione sono allocate man mano che le consumi e l'allocazione viene annullata quando rimuovi i dati o elimini le tabelle.
Oracle archivia i dati in formato riga utilizzando il formato di blocco Oracle organizzato in segmenti. Gli schemi (di proprietà degli utenti) vengono utilizzati per organizzare tabelle e altri oggetti del database. A partire da Oracle 12c, multitenant viene utilizzato per creare database pluggable all'interno di un'istanza di database per un ulteriore isolamento. Il partizionamento può essere utilizzato per migliorare le prestazioni delle query e le operazioni del ciclo di vita delle informazioni. Oracle offre diverse opzioni di archiviazione per database autonomi e Real Application Clusters (RAC), come ASM, un file system del sistema operativo e un file system cluster.
Exadata fornisce un'infrastruttura di archiviazione ottimizzata nei server delle celle di archiviazione e consente ai server Oracle di accedere a questi dati in modo trasparente utilizzando ASM. Exadata offre opzioni di Hybrid Columnar Compression (HCC) in modo che gli utenti possano comprimere tabelle e partizioni.
Oracle richiede una capacità di archiviazione pre-provisioning, un dimensionamento accurato e configurazioni di incremento automatico su segmenti, file di dati e tablespace.
Esecuzione e prestazioni delle query
BigQuery gestisce le prestazioni e la scalabilità a livello di query per massimizzare le prestazioni in base al costo. BigQuery utilizza molte ottimizzazioni, ad esempio:
- Esecuzione in memoria delle query
- Architettura ad albero multilivello basata sul motore di esecuzione Dremel
- Ottimizzazione automatica dello spazio di archiviazione in Capacitor
- Larghezza di banda bisezionale totale di 1 petabit al secondo con Jupiter
- Gestione delle risorse di scalabilità automatica per fornire query rapide su scala petabyte
BigQuery raccoglie le statistiche sulle colonne durante il caricamento dei dati e include informazioni diagnostiche sul piano di query e sui tempi. Le risorse di query sono allocate in base al tipo di query e alla complessità. Ogni query utilizza un certo numero di slot, che sono unità di calcolo che includono una determinata quantità di CPU e RAM.
Oracle fornisce job di raccolta delle statistiche sui dati. L'ottimizzatore del database utilizza le statistiche per fornire piani di esecuzione ottimali. Potrebbero essere necessari indici per ricerche rapide di righe e operazioni di unione. Oracle fornisce anche un archivio colonne in memoria per l'analisi in memoria. Exadata offre diversi miglioramenti delle prestazioni, come la scansione intelligente delle celle, gli indici di archiviazione, la cache flash e le connessioni InfiniBand tra i server di archiviazione e i server di database. Real Application Clusters (RAC) può essere utilizzato per ottenere un'alta disponibilità del server e scalare le applicazioni che richiedono un utilizzo intensivo della CPU del database utilizzando lo stesso spazio di archiviazione sottostante.
L'ottimizzazione delle prestazioni delle query con Oracle richiede un'attenta valutazione di queste opzioni e dei parametri del database. Oracle fornisce diversi strumenti, ad esempio Active Session History (ASH), Automatic Database Diagnostic Monitor (ADDM), report Automatic Workload Repository (AWR), SQL Monitoring and Tuning Advisor e Undo and Memory Tuning Advisors per l'ottimizzazione delle prestazioni.
Analisi agile
In BigQuery puoi consentire a diversi progetti, utenti e gruppi di eseguire query sui set di dati in progetti diversi. La separazione dell'esecuzione delle query consente ai team autonomi di lavorare all'interno dei propri progetti senza influire su altri utenti e progetti separando le quote di slot e la fatturazione delle query da altri progetti e dai progetti che ospitano i set di dati.
Alta disponibilità, backup e ripristino di emergenza
Oracle fornisce Data Guard come soluzione diripristino di emergenzay e replica del database. Real Application Clusters (RAC) possono essere configurati per la disponibilità del server. I backup di Recovery Manager (RMAN) possono essere configurati per i backup di database e archivelog e utilizzati anche per le operazioni di ripristino e recupero. La funzionalità Flashback database può essere utilizzata per i flashback del database per riavvolgere il database fino a un punto specifico nel tempo. Annulla gli snapshot della tabella dei blocchi dello spazio delle tabelle. È possibile eseguire query su snapshot precedenti con le clausole di query flashback e "as of" a seconda delle operazioni DML/DDL eseguite in precedenza e delle impostazioni di conservazione dell'annullamento. In Oracle, l'intera integrità del database deve essere gestita all'interno di tablespace che dipendono dai metadati di sistema, dall'annullamento e dai tablespace corrispondenti, perché elevata coerenza è importante per il backup di Oracle e le procedure di ripristino devono includere tutti i dati primari. Puoi pianificare le esportazioni a livello di schema della tabella se il recupero point-in-time non è necessario in Oracle.
BigQuery è completamente gestito e diverso dai sistemi di database tradizionali per la sua funzionalità di backup completa. Non devi preoccuparti di server, guasti di archiviazione, bug di sistema e danneggiamenti fisici dei dati. BigQuery replica i dati in diversi data center a seconda della posizione del set di dati per massimizzare l'affidabilità e la disponibilità. La funzionalità multiregionale di BigQuery replica i dati in diverse regioni e protegge dall'indisponibilità di una singola zona all'interno della regione. La funzionalità di BigQuery a singola regione replica i dati in diverse zone all'interno della stessa regione.
BigQuery ti consente di eseguire query sugli snapshot storici delle tabelle fino a sette giorni e di ripristinare le tabelle eliminate entro due giorni utilizzando il time travel.
Puoi copiare una tabella eliminata (per ripristinarla) utilizzando la sintassi
dello snapshot (dataset.table@timestamp).
Puoi esportare i dati dalle
tabelle BigQuery per esigenze di backup aggiuntive, ad esempio per il recupero
da operazioni utente accidentali. Per i backup possono essere utilizzate strategie e pianificazioni di backup comprovate utilizzate per i sistemi di data warehouse (DWH) esistenti.
Le operazioni batch e la tecnica di creazione di snapshot consentono diverse strategie di backup per BigQuery, quindi non è necessario esportare frequentemente tabelle e partizioni invariate. Un backup dell'esportazione della partizione o della tabella è sufficiente al termine dell'operazione di caricamento o ETL. Per ridurre i costi di backup, puoi archiviare i file di esportazione in Cloud Storage Nearline Storage o Coldline Storage e definire un criterio del ciclo di vita per eliminare i file dopo un determinato periodo di tempo, a seconda dei requisiti di conservazione dei dati.
Memorizzazione nella cache
BigQuery offre una cache per utente e, se i dati non cambiano, i risultati delle query vengono memorizzati nella cache per circa 24 ore. Se i risultati vengono recuperati dalla cache, la query non costa nulla.
Oracle offre diverse cache per i dati e i risultati delle query, come la cache del buffer, la cache dei risultati, la cache flash Exadata e l'archivio colonne in memoria.
Connessioni
BigQuery gestisce la gestione delle connessioni e non richiede
alcuna configurazione lato server. BigQuery fornisce driver JDBC e
ODBC. Puoi utilizzare la
consoleGoogle Cloud o
bq command-line tool per le query
interattive. Puoi utilizzare le API REST e le librerie
client per interagire
in modo programmatico con BigQuery. Puoi connettere
Google Fogli
direttamente a BigQuery e utilizzare i driver ODBC e JDBC
per connetterti a Excel. Se cerchi un client desktop, esistono strumenti senza costi
come DBeaver.
Oracle fornisce listener, servizi, gestori di servizi, diversi parametri di configurazione e ottimizzazione e server condivisi e dedicati per gestire le connessioni al database. Oracle fornisce driver JDBC, JDBC Thin, ODBC, connessioni Oracle Client e TNS. Listener di scansione, indirizzi IP di scansione e nome di scansione sono necessari per le configurazioni RAC.
Prezzi e licenze
Oracle richiede licenze e tariffe di assistenza in base al numero di core per le edizioni del database e le opzioni del database come RAC, multitenant, Active Data Guard, partizionamento, in-memory, Real Application Testing, GoldenGate e Spatial and Graph.
BigQuery offre opzioni di prezzi flessibili in base all'utilizzo di archiviazione, query e inserimenti di flussi di dati. BigQuery offre prezzi basati sulla capacità per i clienti che necessitano di costi e capacità degli slot prevedibili in regioni specifiche. Gli slot utilizzati per gli inserimenti di flussi di dati e i caricamenti non vengono conteggiati nella capacità degli slot del progetto. Per decidere quanti slot acquistare per il tuo data warehouse, consulta la sezione Pianificazione della capacità di BigQuery.
BigQuery inoltre riduce automaticamente i costi di archiviazione della metà per i dati non modificati archiviati per più di 90 giorni.
Etichettatura
Set di dati, tabelle e viste BigQuery possono essere etichettati con coppie chiave-valore. Le etichette possono essere utilizzate per differenziare i costi di archiviazione e i riaddebiti interni.
Monitoraggio e audit log
Oracle offre diversi livelli e tipi di opzioni di controllo del database e funzionalità di audit vault e firewall del database, che sono concesse in licenza separatamente. Oracle fornisce Enterprise Manager per il monitoraggio del database.
Per BigQuery, Cloud Audit Logs viene utilizzato sia per i log di accesso ai dati sia per gli audit log, che sono abilitati per impostazione predefinita. I log di accesso ai dati sono disponibili per 30 giorni, mentre gli altri eventi di sistema e i log delle attività amministrative sono disponibili per 400 giorni. Se hai bisogno di un periodo di conservazione più lungo, puoi esportare i log in BigQuery, Cloud Storage o Pub/Sub come descritto in Analisi dei log di sicurezza in Google Cloud. Se è necessaria l'integrazione con uno strumento di monitoraggio degli incidenti esistente, Pub/Sub può essere utilizzato per le esportazioni e lo sviluppo personalizzato deve essere eseguito sullo strumento esistente per leggere i log da Pub/Sub.
Gli audit log includono tutte le chiamate API, le istruzioni di query e gli stati dei job. Puoi utilizzare Cloud Monitoring per monitorare l'allocazione degli slot, i byte analizzati nelle query e archiviati e altre metriche di BigQuery. Il piano di query e la sequenza temporale di BigQuery possono essere utilizzati per analizzare le fasi e le prestazioni delle query.

Puoi utilizzare la tabella dei messaggi di errore per risolvere i problemi relativi ai job di query e agli errori API. Per distinguere le allocazioni di slot per query o job, puoi utilizzare questa utilità, utile per i clienti che utilizzano i prezzi basati sulla capacità e hanno molti progetti distribuiti in diversi team.
Manutenzione, upgrade e versioni
BigQuery è un servizio completamente gestito e non richiede manutenzione o aggiornamenti. BigQuery non offre versioni diverse. Gli upgrade sono continui e non comportano tempi di inattività e non compromettono le prestazioni del sistema. Per saperne di più, consulta le note di rilascio.
Oracle ed Exadata richiedono l'applicazione di patch, aggiornamenti e manutenzione a livello di database e infrastruttura sottostante. Esistono molte versioni di Oracle e ogni anno è prevista la release di una nuova versione principale. Sebbene le nuove versioni siano compatibili con le versioni precedenti, le prestazioni delle query, il contesto e le funzionalità possono cambiare.
Esistono applicazioni che richiedono versioni specifiche come 10g, 11g, o 12c. Per gli aggiornamenti principali del database sono necessari un'attenta pianificazione e test. La migrazione da versioni diverse potrebbe includere esigenze di conversione tecnica diverse per le clausole di query e gli oggetti di database.
Workload
Oracle Exadata supporta carichi di lavoro misti, inclusi i carichi di lavoro OLTP. BigQuery è progettato per l'analisi e non per gestire carichi di lavoro OLTP. I carichi di lavoro OLTP che utilizzano lo stesso Oracle devono essere migrati in Cloud SQL, Spanner o Firestore in Google Cloud. Oracle offre opzioni aggiuntive come Advanced Analytics e Spatial and Graph. Questi carichi di lavoro potrebbero dover essere riscritti per la migrazione a BigQuery. Per saperne di più, consulta la sezione Migrazione delle opzioni Oracle.
Parametri e impostazioni
Oracle offre e richiede la configurazione e l'ottimizzazione di molti parametri a livello di sistema operativo, database, RAC, ASM e listener per diversi workload e applicazioni. BigQuery è un servizio completamente gestito e non richiede la configurazione di parametri di inizializzazione.
Limiti e quote
Oracle ha limiti rigidi e flessibili in base a infrastruttura, capacità hardware, parametri, versioni software e licenze. BigQuery ha quote e limiti per azioni e oggetti specifici.
Provisioning di BigQuery
BigQuery è una piattaforma come servizio (PaaS) e un data warehouse di elaborazione massivamente parallela del cloud. La sua capacità aumenta e diminuisce senza alcun intervento da parte dell'utente, poiché Google gestisce il backend. Di conseguenza, a differenza di molti sistemi RDBMS, BigQuery non richiede il provisioning delle risorse prima dell'uso. BigQuery alloca in modo dinamico le risorse di archiviazione e query in base ai tuoi pattern di utilizzo. Le risorse di archiviazione sono allocate man mano che le consumi e l'allocazione viene annullata quando rimuovi i dati o elimini le tabelle. Le risorse di query sono allocate in base al tipo di query e alla complessità. Ogni query utilizza slot. Viene utilizzato uno scheduler di equità finale, quindi potrebbero esserci brevi periodi in cui alcune query ottengono una quota maggiore di slot, ma lo scheduler alla fine corregge questo problema.
In termini di VM tradizionali, BigQuery ti offre l'equivalente di entrambi:
- Fatturazione al secondo
- Scalabilità al secondo
Per svolgere questa attività, BigQuery esegue le seguenti operazioni:
- Mantiene distribuite vaste risorse per evitare di doverle scalare rapidamente.
- Utilizza risorse multitenant per allocare istantaneamente grandi blocchi per secondi alla volta.
- Alloca in modo efficiente le risorse tra gli utenti con economie di scala.
- Ti addebita solo i job che esegui, anziché le risorse di cui è stato eseguito il deployment, quindi paghi solo le risorse che utilizzi.
Per ulteriori informazioni sui prezzi, consulta la sezione Informazioni su scalabilità rapida e prezzi semplici di BigQuery.
Migrazione dello schema
Per eseguire la migrazione dei dati da Oracle a BigQuery, devi conoscere i tipi di dati Oracle e i mapping BigQuery.
Tipi di dati Oracle e mappature BigQuery
I tipi di dati Oracle sono diversi da quelli di BigQuery. Per ulteriori informazioni sui tipi di dati BigQuery, consulta la documentazione ufficiale.
Per un confronto dettagliato tra i tipi di dati Oracle e BigQuery, consulta la guida alla traduzione di Oracle SQL.
Indici
In molti carichi di lavoro analitici, vengono utilizzate tabelle a colonne anziché archivi di righe. Ciò aumenta notevolmente le operazioni basate sulle colonne ed elimina l'utilizzo di indici per l'analisi batch. BigQuery archivia i dati anche in un formato colonnare, quindi gli indici non sono necessari in BigQuery. Se il carico di lavoro di analisi richiede un singolo e piccolo insieme di accessi basati sulle righe, Bigtable può essere un'alternativa migliore. Se un carico di lavoro richiede l'elaborazione delle transazioni con coerenze relazionali forti, Spanner o Cloud SQL possono essere alternative migliori.
In sintesi, in BigQuery non sono necessari e non vengono offerti indici per l'analisi batch. È possibile utilizzare il partizionamento o il clustering. Per saperne di più su come ottimizzare e migliorare le prestazioni delle query in BigQuery, consulta la pagina Introduzione all'ottimizzazione delle prestazioni delle query.
Visualizzazioni
Analogamente a Oracle, BigQuery consente di creare viste personalizzate. Tuttavia, le viste in BigQuery non supportano le istruzioni DML.
Viste materializzate
Le viste materializzate vengono utilizzate comunemente per migliorare il tempo di rendering dei report nei tipi di report e carichi di lavoro di tipo write-once, read-many.
Le viste materializzate vengono offerte in Oracle per aumentare le prestazioni delle viste semplicemente creando e gestendo una tabella per contenere il set di dati dei risultati della query. Esistono due modi per aggiornare le viste materializzate in Oracle: on-commit e on-demand.
Anche in BigQuery è disponibile la funzionalità di vista materializzata. BigQuery sfrutta i risultati precalcolati dalle viste materializzate e ogni volta che è possibile legge solo le modifiche delta dalla tabella base per calcolare i risultati aggiornati.
Le funzionalità di memorizzazione nella cache in Looker Studio o in altri strumenti di BI moderni possono anche migliorare il rendimento ed eliminare la necessità di eseguire di nuovo la stessa query, risparmiando costi.
Partizionamento delle tabelle
Il partizionamento delle tabelle è ampiamente utilizzato nei data warehouse Oracle. A differenza di Oracle, BigQuery non supporta il partizionamento gerarchico.
BigQuery implementa tre tipi di partizionamento delle tabelle che consentono alle query di specificare filtri di predicato in base alla colonna di partizionamento per ridurre la quantità di dati analizzati.
- Tabelle partizionate per data di importazione: Le tabelle vengono partizionate in base alla data di importazione dei dati.
- Tabelle partizionate per colonna:
le tabelle sono partizionate in base a una colonna
TIMESTAMPoDATE. - Tabelle partizionate per intervallo di numeri interi: Le tabelle sono partizionate in base a una colonna di numeri interi.
Per saperne di più su limiti e quote applicati alle tabelle partizionate in BigQuery, consulta Introduzione alle tabelle partizionate.
Se le limitazioni di BigQuery influiscono sulla funzionalità del database di cui è stata eseguita la migrazione, valuta la possibilità di utilizzare lo sharding anziché il partizionamento.
Inoltre, BigQuery non supporta EXCHANGE PARTITION,
SPLIT PARTITION o la conversione di una tabella non partizionata in una partizionata.
Clustering
Il clustering consente di organizzare e recuperare in modo efficiente i dati archiviati in più colonne a cui si accede spesso insieme. Tuttavia, Oracle e BigQuery hanno circostanze diverse in cui il clustering funziona meglio. In BigQuery, se una tabella viene filtrata e aggregata comunemente con colonne specifiche, utilizza il clustering. Il clustering può essere preso in considerazione per la migrazione di tabelle partizionate per elenco o organizzate per indice da Oracle.
Tabelle temporanee
Le tabelle temporanee vengono spesso utilizzate nelle pipeline ETL Oracle. Una tabella temporanea contiene i dati durante una sessione utente. Questi dati vengono eliminati automaticamente al termine della sessione.
BigQuery utilizza tabelle temporanee per memorizzare nella cache i risultati delle query che non vengono scritti in una tabella permanente. Al termine di una query, le tabelle temporanee esistono per un massimo di 24 ore. Le tabelle vengono create in un set di dati speciale e denominate in modo casuale. Puoi anche creare tabelle temporanee per uso personale. Per ulteriori informazioni, vedi Tabelle temporanee.
Tabelle esterne
Come Oracle, BigQuery consente di eseguire query su origini dati esterne. BigQuery supporta l'esecuzione di query sui dati direttamente dalle origini dati esterne, tra cui:
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Modellazione dei dati
I modelli di dati a stella o a fiocco di neve possono essere efficienti per l'archiviazione di analisi e vengono comunemente utilizzati per i data warehouse su Oracle Exadata.
Le tabelle denormalizzate eliminano le costose operazioni di join e nella maggior parte dei casi offrono prestazioni migliori per l'analisi in BigQuery. BigQuery supporta anche i modelli di dati a stella e a fiocco di neve. Per ulteriori dettagli sulla progettazione del data warehouse in BigQuery, consulta Progettazione dello schema.
Formato riga e formato colonna e limiti del server e serverless
Oracle utilizza un formato di riga in cui la riga della tabella viene archiviata in blocchi di dati, quindi le colonne non necessarie vengono recuperate all'interno del blocco per le query analitiche, in base al filtraggio e all'aggregazione di colonne specifiche.
Oracle ha un'architettura di tipo shared-everything, con dipendenze fisse dalle risorse hardware, come memoria e spazio di archiviazione, assegnate al server. Queste sono le due forze principali alla base di molte tecniche di modellazione dei dati che si sono evolute per migliorare l'efficienza dell'archiviazione e il rendimento delle query analitiche. Alcuni esempi sono gli schemi a stella e a fiocco di neve e la modellazione del data vault.
BigQuery utilizza un formato a colonne per archiviare i dati e non ha limiti fissi di archiviazione e memoria. Questa architettura consente di denormalizzare ulteriormente e progettare schemi in base alle letture e alle esigenze aziendali, riducendo la complessità e migliorando flessibilità, scalabilità e prestazioni.
Denormalizzazione
Uno degli obiettivi principali della normalizzazione dei database relazionali è ridurre la ridondanza dei dati. Sebbene questo modello sia più adatto a un database relazionale che utilizza un formato di riga, la denormalizzazione dei dati è preferibile per i database orientati alle colonne. Per ulteriori informazioni sui vantaggi della denormalizzazione dei dati e su altre strategie di ottimizzazione delle query in BigQuery, consulta Denormalizzazione.
Tecniche per appiattire lo schema esistente
La tecnologia BigQuery sfrutta una combinazione di accesso e elaborazione dei dati colonnari, archiviazione in memoria ed elaborazione distribuita per fornire prestazioni di query di qualità.
Quando progetti uno schema DWH BigQuery, la creazione di una tabella dei fatti in una
struttura di tabella piatta (consolidando tutte le tabelle delle dimensioni in un unico
record nella tabella dei fatti) è migliore per l'utilizzo dello spazio di archiviazione rispetto all'utilizzo di più
tabelle delle dimensioni del DWH. Oltre a un minore utilizzo dello spazio di archiviazione, una tabella piatta
in BigQuery comporta un minore utilizzo di JOIN. Il seguente diagramma
illustra un esempio di appiattimento dello schema.
Esempio di appiattimento di uno schema a stella
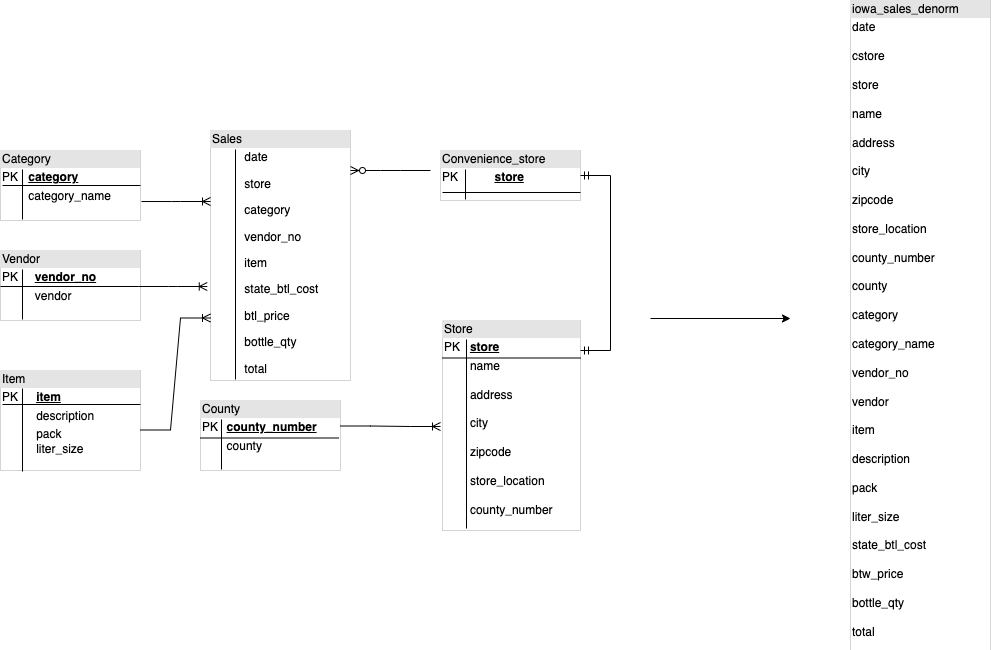
La Figura 1 mostra un database fittizio di gestione delle vendite che include quattro tabelle:
- Tabella degli ordini/vendite (tabella dei fatti)
- Tabella Dipendenti
- Tabella delle località
- Tabella clienti
La chiave primaria della tabella delle vendite è OrderNum, che contiene anche
chiavi esterne per le altre tre tabelle.
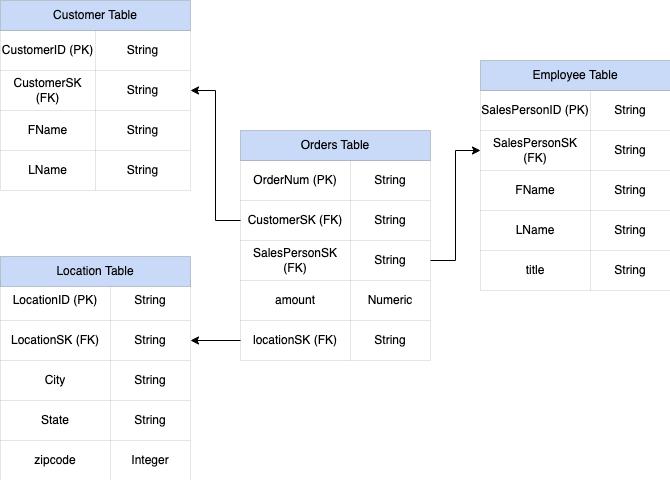
Figura 1: dati di vendita di esempio in uno schema a stella
Dati di esempio
Contenuti della tabella degli ordini/dei fatti
| OrderNum | CustomerID | SalesPersonID | quantità | Località |
|---|---|---|---|---|
| O-1 | 1234 | 12 | 234,22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14,66 | 18 | |
| O-4 | 4567 | 4 | 182,00 | 26 |
Contenuti della tabella dei dipendenti
| SalesPersonID | FName | LName | titolo |
|---|---|---|---|
| 1 | Alex | Smith | Persona addetta alle vendite |
| 4 | Lisa | Rossi | Persona addetta alle vendite |
| 12 | Mario | Rossi | Persona addetta alle vendite |
Contenuti della tabella dei clienti
| CustomerID | FName | LName |
|---|---|---|
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Contenuti della tabella delle località
| Località | city | state | codice postale |
|---|---|---|---|
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Query per appiattire i dati utilizzando LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Output dei dati resi bidimensionali
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | quantità | Località | city | state | codice postale |
|---|---|---|---|---|---|---|---|---|---|---|---|
| O-1 | 1234 | Amanda | Lee | 12 | Mario | Rossi | 234,22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | Mario | Rossi | 14,66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Rossi | 182,00 | 26 | Montagna
Visualizza |
CA | 90210 |
Campi nidificati e ripetuti
Per progettare e creare uno schema DWH da uno schema relazionale (ad esempio, schemi a stella e a fiocco di neve contenenti tabelle delle dimensioni e dei fatti), BigQuery presenta la funzionalità dei campi nidificati e ripetuti. Pertanto, le relazioni possono essere mantenute in modo simile a uno schema DWH relazionale normalizzato (o parzialmente normalizzato) senza influire sulle prestazioni. Per saperne di più, consulta le best practice per le prestazioni.
Per comprendere meglio l'implementazione dei campi nidificati e ripetuti, esamina uno schema relazionale semplice di una tabella CUSTOMERS e di una tabella ORDER/SALES. Sono due tabelle diverse, una per ogni entità, e le relazioni sono definite utilizzando una chiave come una chiave primaria e una chiave esterna come collegamento tra le tabelle durante l'esecuzione di query utilizzando JOIN. I campi nidificati e ripetuti di BigQuery consentono di mantenere la stessa relazione tra le entità in una singola tabella. Ciò può essere implementato disponendo di tutti i dati dei clienti, mentre i dati degli ordini
sono nidificati per ciascun cliente. Per saperne di più, consulta Specificare
colonne nidificate e ripetute.
Per convertire la struttura flat in uno schema nidificato o ripetuto, nidifica i campi nel seguente modo:
CustomerID,FName,LNamenidificati in un nuovo campo chiamatoCustomer.SalesPersonID,FName,LNamenidificati in un nuovo campo chiamatoSalesperson.LocationID,city,state,zip codenidificati in un nuovo campo chiamatoLocation.
I campi OrderNum e amount non sono nidificati, in quanto rappresentano elementi unici.
Vuoi rendere il tuo schema abbastanza flessibile da consentire a ogni ordine di avere più di un cliente: uno principale e uno secondario. Il campo cliente è contrassegnato come ripetuto. Lo schema risultante è mostrato nella Figura 2, che illustra i campi nidificati e ripetuti.
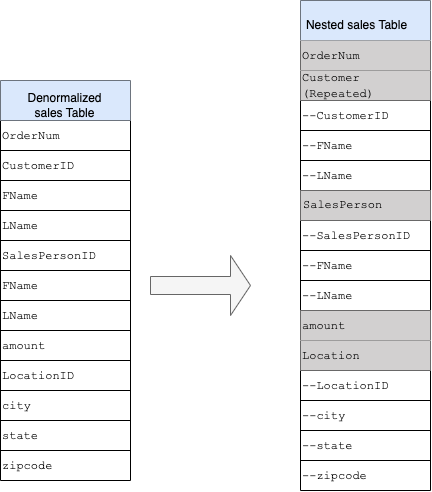
Figura 2: rappresentazione logica di una struttura nidificata
In alcuni casi, la denormalizzazione tramite campi nidificati e ripetuti non comporta miglioramenti delle prestazioni. Per ulteriori informazioni su limitazioni e restrizioni, consulta Specificare colonne nidificate e ripetute negli schemi delle tabelle.
Chiavi surrogate
È comune identificare le righe con chiavi univoche all'interno delle tabelle. Le sequenze vengono
comunemente utilizzate in Oracle per creare queste chiavi. In
BigQuery puoi creare chiavi surrogate utilizzando le funzioni row_number e
partition by. Per saperne di più, consulta BigQuery e
chiavi surrogate: un approccio
pratico.
Tenere traccia delle modifiche e della cronologia
Quando pianifichi una migrazione del DWH BigQuery, considera il concetto di dimensioni che cambiano lentamente (SCD). In generale, il termine SCD descrive il processo di apportare modifiche (operazioni DML) nelle tabelle delle dimensioni.
Per diversi motivi, i data warehouse tradizionali utilizzano tipi diversi per gestire le modifiche ai dati e conservare i dati storici nelle dimensioni a variazione lenta. Questi tipi di utilizzo sono necessari a causa delle limitazioni hardware e dei requisiti di efficienza descritti in precedenza. Poiché l'archiviazione è molto più economica del calcolo e infinitamente scalabile, la ridondanza e la duplicazione dei dati sono incoraggiate se comportano query più veloci in BigQuery. Puoi utilizzare tecniche di snapshot dei dati in cui tutti i dati vengono caricati in nuove partizioni giornaliere.
Viste specifiche per ruolo e per utente
Utilizza visualizzazioni specifiche per ruolo e utente quando gli utenti appartengono a team diversi e devono visualizzare solo i record e i risultati di cui hanno bisogno.
BigQuery supporta la column- e la sicurezza a livello di riga. La sicurezza a livello di colonna fornisce un accesso granulare alle colonne sensibili utilizzando i tag di criteri o la classificazione basata sui tipi di dati. Sicurezza a livello di riga che consente di filtrare i dati e di accedere a righe specifiche di una tabella in base alle condizioni dell'utente idoneo.
Migrazione dei dati
Questa sezione fornisce informazioni sulla migrazione dei dati da Oracle a BigQuery, inclusi il caricamento iniziale, Change Data Capture (CDC) e strumenti e approcci ETL/ELT.
Attività di migrazione
Ti consigliamo di eseguire la migrazione in fasi identificando i casi d'uso appropriati per la migrazione. Esistono diversi strumenti e servizi disponibili per migrare i dati da Oracle a Google Cloud. Sebbene questo elenco non sia esaustivo, fornisce un'idea delle dimensioni e dell'ambito dell'impegno di migrazione.
Esportazione dei dati da Oracle:per ulteriori informazioni, vedi Caricamento iniziale e Inserimento di CDC e streaming da Oracle a BigQuery. Per il caricamento iniziale possono essere utilizzati strumenti ETL.
Staging dei dati (in Cloud Storage): Cloud Storage è la posizione di destinazione (area di staging) consigliata per i dati esportati da Oracle. Cloud Storage è progettato per l'importazione rapida e flessibile di dati strutturati o non strutturati.
Processo ETL:per ulteriori informazioni, vedi Migrazione ETL/ELT.
Caricamento dei dati direttamente in BigQuery: puoi caricare i dati in BigQuery direttamente da Cloud Storage, tramite Dataflow o tramite lo streaming in tempo reale. Utilizza Dataflow quando è necessaria la trasformazione dei dati.
Caricamento iniziale
La migrazione dei dati iniziali dal data warehouse Oracle esistente a BigQuery potrebbe essere diversa dalle pipeline ETL/ELT incrementali a seconda delle dimensioni dei dati e della larghezza di banda della rete. Le stesse pipeline ETL/ELT possono essere utilizzate se le dimensioni dei dati sono di un paio di terabyte.
Se i dati raggiungono alcuni terabyte, il dump dei dati e l'utilizzo di gcloud storage
per il trasferimento possono essere molto più efficienti rispetto all'utilizzo di una metodologia di estrazione programmatica del database simile a JdbcIO, perché gli approcci programmatici potrebbero richiedere una messa a punto delle prestazioni molto più granulare. Se le dimensioni dei dati superano alcuni terabyte e
i dati sono archiviati in un archivio cloud o online (come Amazon Simple Storage Service (Amazon S3)), valuta la possibilità di
utilizzare BigQuery Data Transfer Service. Per i trasferimenti su larga scala
(soprattutto quelli con larghezza di banda di rete limitata), Transfer
Appliance è un'opzione utile.
Vincoli per il caricamento iniziale
Quando pianifichi la migrazione dei dati, considera quanto segue:
- Dimensioni dei dati del DWH Oracle: le dimensioni dell'origine dello schema hanno un peso significativo sul metodo di trasferimento dei dati scelto, soprattutto quando le dimensioni dei dati sono grandi (terabyte e superiori). Quando le dimensioni dei dati sono relativamente ridotte, la procedura di trasferimento dei dati può essere completata in meno passaggi. La gestione di dati su larga scala rende l'intero processo più complesso.
Tempo di inattività:è importante decidere se il tempo di inattività è un'opzione per la migrazione a BigQuery. Per ridurre i tempi di inattività, puoi caricare in blocco i dati storici stabili e disporre di una soluzione CDC per recuperare le modifiche che si verificano durante il processo di trasferimento.
Prezzi:in alcuni scenari, potresti aver bisogno di strumenti di integrazione di terze parti (ad esempio strumenti ETL o di replica) che richiedono licenze aggiuntive.
Trasferimento iniziale dei dati (batch)
Il trasferimento dei dati utilizzando un metodo batch indica che i dati verranno esportati in modo coerente in un unico processo (ad esempio, l'esportazione dei dati dello schema Oracle DWH in file CSV, Avro o Parquet o l'importazione in Cloud Storage per creare set di dati su BigQuery. Tutti gli strumenti e i concetti ETL spiegati in Migrazione ETL/ELT possono essere utilizzati per il caricamento iniziale.
Se non vuoi utilizzare uno strumento ETL/ELT per il caricamento iniziale, puoi scrivere
script personalizzati per esportare i dati in file (CSV, Avro o Parquet) e caricarli
in Cloud Storage utilizzando gcloud storage, BigQuery Data Transfer Service o
Transfer Appliance. Per ulteriori informazioni sull'ottimizzazione delle prestazioni dei trasferimenti di grandi quantità di dati e sulle opzioni di trasferimento, consulta Trasferimento di set di dati di grandi dimensioni. Poi carica i dati da
Cloud Storage a BigQuery.
Cloud Storage è ideale per la gestione dell'inserimento iniziale dei dati. Cloud Storage è un servizio di archiviazione di oggetti durevole e ad alta disponibilità senza limitazioni al numero di file e paghi solo per lo spazio di archiviazione che utilizzi. Il servizio è ottimizzato per funzionare con altri servizi Google Cloud come BigQuery e Dataflow.
CDC e importazione di flussi di dati da Oracle a BigQuery
Esistono diversi modi per acquisire i dati modificati da Oracle. Ogni opzione presenta compromessi, principalmente in termini di impatto sulle prestazioni del sistema di origine, requisiti di sviluppo e configurazione, nonché prezzi e licenze.
CDC basato su log
Oracle GoldenGate è lo strumento consigliato da Oracle per estrarre i log di ripristino e puoi utilizzare GoldenGate for Big Data per lo streaming dei log in BigQuery. GoldenGate richiede licenze per CPU. Per informazioni sul prezzo, consulta il listino prezzi globale della tecnologia Oracle. Se Oracle GoldenGate for Big Data è disponibile (nel caso in cui siano già state acquisite le licenze), l'utilizzo di GoldenGate può essere una buona scelta per creare pipeline di dati per trasferire i dati (caricamento iniziale) e poi sincronizzare tutte le modifiche ai dati.
Oracle XStream
Oracle archivia ogni commit nei file di log di ripetizione e questi file possono essere utilizzati per CDC. Oracle XStream Out è basato su LogMiner e fornito da strumenti di terze parti come Debezium (a partire dalla versione 0.8) o commercialmente utilizzando strumenti come Striim. L'utilizzo delle API XStream richiede l'acquisto di una licenza per Oracle GoldenGate anche se GoldenGate non è installato e utilizzato. XStream consente di propagare i messaggi di Streams tra Oracle e altri software in modo efficiente.
Oracle LogMiner
Per LogMiner non è necessaria alcuna licenza speciale. Puoi utilizzare l'opzione LogMiner nel connettore della community Debezium. È disponibile anche in commercio utilizzando strumenti come Attunity, Striim o StreamSets. LogMiner potrebbe avere un impatto sulle prestazioni di un database di origine molto attivo e deve essere utilizzato con attenzione nei casi in cui il volume delle modifiche (la dimensione del redo) è superiore a 10 GB all'ora, a seconda della capacità e dell'utilizzo di CPU, memoria e I/O del server.
CDC basata su SQL
Si tratta dell'approccio ETL incrementale in cui le query SQL eseguono il polling continuo delle tabelle di origine per rilevare eventuali modifiche a seconda di una chiave crescente in modo monotono e di una colonna timestamp che contiene la data dell'ultima modifica o inserimento. Se non è presente una chiave
in aumento monotono, l'utilizzo della colonna timestamp (data di modifica) con una
precisione ridotta (secondi) può causare record duplicati o dati mancanti a seconda
del volume e dell'operatore di confronto, ad esempio > o >=.
Per superare questi problemi, puoi utilizzare una precisione maggiore nelle colonne timestamp, ad esempio sei cifre frazionarie (microsecondi, che è la precisione massima supportata in BigQuery) oppure puoi aggiungere attività di deduplicazione nella pipeline ETL/ELT, a seconda delle chiavi aziendali e delle caratteristiche dei dati.
Per migliorare le prestazioni dell'estrazione e ridurre l'impatto sul database di origine, deve essere presente un indice nella colonna della chiave o del timestamp. Le operazioni di eliminazione sono una
sfida per questa metodologia perché devono essere gestite nell'applicazione
di origine in modo da eliminare temporaneamente, ad esempio inserendo un flag di eliminazione e aggiornando
last_modified_date. Una soluzione alternativa può essere la registrazione di queste operazioni in
un'altra tabella utilizzando un trigger.
Trigger
I trigger di database possono essere creati nelle tabelle di origine per registrare le modifiche nelle tabelle
journal shadow. Le tabelle di log possono contenere intere righe per tenere traccia di ogni
modifica della colonna oppure possono contenere solo la chiave primaria con il tipo di operazione
(inserimento, aggiornamento o eliminazione). I dati modificati possono quindi essere acquisiti con un approccio basato su SQL descritto in CDC basato su SQL. L'utilizzo dei trigger può influire sulle prestazioni delle transazioni e raddoppiare la latenza dell'operazione DML su una singola riga se viene memorizzata una riga completa. L'archiviazione della sola chiave primaria può ridurre questo
overhead, ma in questo caso è necessaria un'operazione JOIN con la tabella originale
nell'estrazione basata su SQL, che non tiene conto della modifica intermedia.
Migrazione ETL/ELT
Esistono molte possibilità per gestire ETL/ELT su Google Cloud. Le indicazioni tecniche sulle conversioni di carichi di lavoro ETL specifici non rientrano nell'ambito di questo documento. Puoi prendere in considerazione un approccio lift and shift o riprogettare la piattaforma di integrazione dei dati a seconda di vincoli come costi e tempi. Per ulteriori informazioni su come eseguire la migrazione delle pipeline di dati a Google Cloud e su molti altri concetti di migrazione, consulta Eseguire la migrazione delle pipeline di dati.
Approccio lift and shift
Se la tua piattaforma esistente supporta BigQuery e vuoi continuare a utilizzare lo strumento di integrazione dei dati esistente:
- Puoi mantenere la piattaforma ETL/ELT così com'è e modificare le fasi di archiviazione necessarie con BigQuery nei tuoi job ETL/ELT.
- Se vuoi eseguire la migrazione anche della piattaforma ETL/ELT a Google Cloud , puoi chiedere al fornitore se il suo strumento è concesso in licenza su Google Cloude, se lo è, puoi installarlo su Compute Engine o controllare Google Cloud Marketplace.
Per informazioni sui fornitori di soluzioni di integrazione dei dati, consulta Partner BigQuery.
Riprogettazione della piattaforma ETL/ELT
Se vuoi riprogettare le pipeline di dati, ti consigliamo vivamente di valutare l'utilizzo dei servizi Google Cloud .
Cloud Data Fusion
Cloud Data Fusion è un CDAP gestito su Google Cloud che offre un'interfaccia visiva con molti plug-in per attività come trascinamento e sviluppo di pipeline. Cloud Data Fusion può essere utilizzato per acquisire dati da molti tipi diversi di sistemi di origine e offre funzionalità di replica batch e in streaming. È possibile utilizzare i plug-in Cloud Data Fusion o Oracle per acquisire i dati da Oracle. Un plug-in BigQuery può essere utilizzato per caricare i dati in BigQuery e gestire gli aggiornamenti dello schema.
Nessuno schema di output è definito nei plug-in di origine e sink e
select * from viene utilizzato nel plug-in di origine anche per replicare nuove colonne.
Puoi utilizzare la funzionalità Wrangle di Cloud Data Fusion per la pulizia e la preparazione dei dati.
Dataflow
Dataflow è una piattaforma di elaborazione dei dati serverless in grado di scalare automaticamente ed eseguire l'elaborazione dei dati in batch e in streaming. Dataflow può essere una buona scelta per gli sviluppatori Python e Java che vogliono programmare le proprie pipeline di dati e utilizzare lo stesso codice sia per i carichi di lavoro di streaming che batch. Utilizza il modello JDBC to BigQuery per estrarre i dati dai tuoi database relazionali Oracle o di altro tipo e caricarli in BigQuery.
Cloud Composer
Cloud Composer è un servizio di orchestrazione del flusso di lavoro completamente gestito basato su Apache Airflow. Google Cloud Consente di creare, pianificare e monitorare pipeline distribuite in ambienti cloud e data center on-premise. Cloud Composer fornisce operatori e contributi che possono eseguire tecnologie multicloud per casi d'uso tra cui estrazione e caricamenti, trasformazioni ELT e chiamate API REST.
Cloud Composer utilizza grafici aciclici diretti (DAG) per la pianificazione e l'orchestrazione dei flussi di lavoro. Per comprendere i concetti generali di Airflow, consulta Concetti di Apache Airflow. Per saperne di più sui DAG, vedi Scrittura di DAG (flussi di lavoro). Per esempi di best practice ETL con Apache Airflow, consulta Best practice ETL con il sito di documentazione di Airflow¶. Puoi sostituire l'operatore Hive nell'esempio con l'operatore BigQuery e gli stessi concetti sarebbero applicabili.
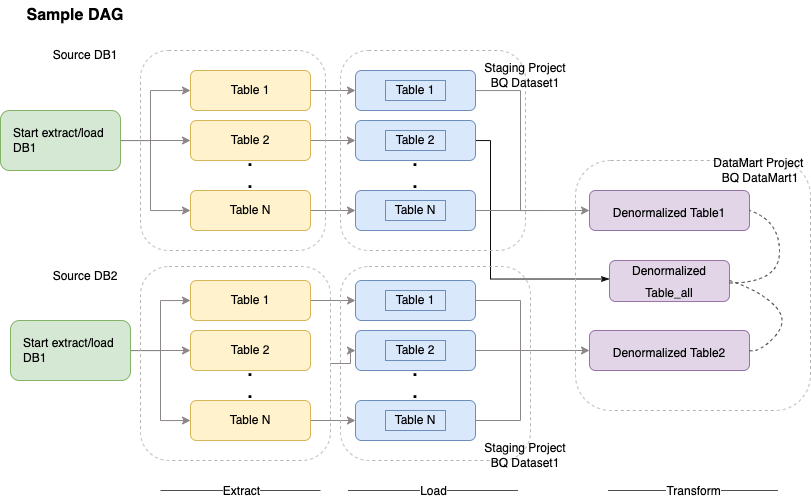
Il seguente codice campione è una parte di alto livello di un DAG di esempio per il diagramma precedente:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
Il codice precedente viene fornito a scopo dimostrativo e non può essere utilizzato così com'è.
Dataprep di Trifacta
Dataprep è un servizio dati che consente di esplorare in modo visivo, pulire e preparare dati strutturati e non strutturati per l'analisi, il reporting e il machine learning. Esporta i dati di origine in file JSON o CSV, trasformali utilizzando Dataprep e caricali utilizzando Dataflow. Per un esempio, consulta Dati Oracle (ETL) in BigQuery utilizzando Dataflow e Dataprep.
Dataproc
Dataproc è un servizio Hadoop gestito da Google. Puoi utilizzare Sqoop per esportare i dati da Oracle e da molti database relazionali in Cloud Storage come file Avro, quindi puoi caricare i file Avro in BigQuery utilizzando bq tool. È
molto comune installare strumenti ETL come CDAP su Hadoop che utilizzano JDBC per estrarre
i dati e Apache Spark o MapReduce per le trasformazioni dei dati.
Strumenti dei partner per la migrazione dei dati
Esistono diversi fornitori nel campo dell'estrazione, della trasformazione e del caricamento (ETL). I leader di mercato ETL come Informatica, Talend, Matillion, Infoworks, Stitch, Fivetran e Striim sono profondamente integrati con BigQuery e Oracle e possono aiutarti a estrarre, trasformare, caricare i dati e gestire i flussi di lavoro di elaborazione.
Gli strumenti ETL esistono da molti anni. Per alcune organizzazioni potrebbe essere più conveniente sfruttare un investimento esistente in script ETL attendibili. Alcune delle nostre soluzioni partner chiave sono incluse nel sito web dei partner BigQuery. Sapere quando scegliere gli strumenti partner rispetto alle utilità integrate dipende dall'infrastruttura attuale e dalla familiarità del tuo team IT con lo sviluppo di pipeline di dati in codice Java o Python.Google Cloud
Migrazione dello strumento di Business Intelligence (BI)
BigQuery supporta una suite flessibile di soluzioni di business intelligence (BI) per la generazione di report e l'analisi che puoi sfruttare. Per saperne di più sulla migrazione degli strumenti di BI e sull'integrazione di BigQuery, consulta Panoramica dell'analisi di BigQuery.
Traduzione delle query (SQL)
GoogleSQL di BigQuery supporta la conformità allo standard SQL 2011 e dispone di estensioni che supportano l'esecuzione di query su dati nidificati e ripetuti. Tutte le funzioni e gli operatori SQL conformi allo standard ANSI possono essere utilizzati con modifiche minime. Per un confronto dettagliato tra la sintassi e le funzioni SQL di Oracle e BigQuery, consulta Riferimento alla traduzione da Oracle a BigQuery SQL.
Utilizza la traduzione SQL batch per migrare il codice SQL in blocco oppure la traduzione SQL interattiva per tradurre query ad hoc.
Opzioni di migrazione di Oracle
Questa sezione presenta consigli e riferimenti architetturali per la conversione di applicazioni che utilizzano le funzionalità Oracle Data Mining, R e Spatial and Graph.
Opzione Oracle Advanced Analytics
Oracle offre opzioni di analisi avanzata per il data mining, algoritmi di machine learning (ML) fondamentali e l'utilizzo di R. L'opzione Advanced Analytics richiede una licenza. Puoi scegliere da un elenco completo di prodotti Google AI/ML a seconda delle tue esigenze, dallo sviluppo alla produzione su larga scala.
Oracle R Enterprise
Oracle R Enterprise (ORE), un componente dell'opzione Oracle Advanced Analytics, consente di integrare il linguaggio di programmazione statistica R open source con Oracle Database. Nelle implementazioni ORE standard, R è installato su un server Oracle.
Per scale di dati o approcci al data warehousing molto grandi, l'integrazione di R con BigQuery è la scelta ideale. Puoi utilizzare la libreria R bigrquery open source per integrare R con BigQuery.
Google ha collaborato con RStudio per rendere disponibili agli utenti gli strumenti all'avanguardia del settore. RStudio può essere utilizzato per accedere a terabyte di dati in BigQuery, adattare modelli in TensorFlow ed eseguire modelli di machine learning su larga scala con AI Platform. In Google Cloud, R può essere installato su Compute Engine su larga scala.
Oracle Data Mining
Oracle Data Mining (ODM), un componente dell'opzione Oracle Advanced Analytics, consente agli sviluppatori di creare modelli di machine learning utilizzando Oracle PL/SQL Developer su Oracle.
BigQuery ML consente agli sviluppatori di eseguire molti tipi diversi di modelli, come regressione lineare, regressione logistica binaria, regressione logistica multiclasse, clustering k-means e importazioni di modelli TensorFlow. Per ulteriori informazioni, vedi Introduzione a BigQuery ML.
La conversione dei job ODM potrebbe richiedere la riscrittura del codice. Puoi scegliere tra offerte complete di prodotti Google AI come BigQuery ML, API AI (Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, API Cloud Natural Language, Cloud Vision, API Timeseries Insights e altro ancora) o Vertex AI.
Vertex AI Workbench può essere utilizzato come ambiente di sviluppo per i data scientist e Vertex AI Training può essere utilizzato per eseguire carichi di lavoro di addestramento e valutazione su larga scala.
Opzione Spaziale e grafico
Oracle offre l'opzione Spatial and Graph per eseguire query su geometrie e grafici e richiede una licenza per questa opzione. Puoi utilizzare le funzioni di geometria in BigQuery senza costi o licenze aggiuntivi e utilizzare altri database grafici in Google Cloud.
Spaziale
BigQuery offre funzioni e tipi di dati di analisi geospaziale. Per saperne di più, consulta Utilizzare i dati di analisi geospaziale. I tipi di dati e le funzioni Oracle Spatial possono essere convertiti in funzioni geografiche in BigQuery Standard SQL. Le funzioni geografiche non aggiungono costi aggiuntivi ai prezzi standard di BigQuery.
Grafico
JanusGraph è una soluzione di database a grafo open source che può utilizzare Bigtable come backend di archiviazione. Per maggiori informazioni, consulta Esecuzione di JanusGraph su GKE con Bigtable.
Neo4j è un'altra soluzione di database a grafo fornita come Google Cloud servizio eseguito su Google Kubernetes Engine (GKE).
Oracle Application Express
Le applicazioni Oracle Application Express (APEX) sono specifiche di Oracle e devono essere riscritte. Le funzionalità di reporting e visualizzazione dei dati possono essere sviluppate utilizzando Looker Studio o BI Engine, mentre le funzionalità a livello di applicazione, come la creazione e la modifica delle righe, possono essere sviluppate senza programmazione su AppSheet utilizzando Cloud SQL.
Passaggi successivi
- Scopri come ottimizzare i workload per l'ottimizzazione complessiva delle prestazioni e la riduzione dei costi.
- Scopri come ottimizzare l'archiviazione in BigQuery.
- Per gli aggiornamenti di BigQuery, consulta le note di rilascio.
- Consulta la guida alla traduzione SQL di Oracle.