
אפשר להשתמש במטמון נתונים רק עם אשכולות GKE Standard. במדריך הזה מוסבר איך להפעיל את GKE Data Cache כשיוצרים אשכול GKE Standard חדש או מאגר צמתים, ואיך להקצות דיסקים שמצורפים ל-GKE עם האצת Data Cache.
מידע על GKE Data Cache
באמצעות GKE Data Cache, אתם יכולים להשתמש בכונני SSD מקומיים בצמתי GKE כשכבת מטמון לאחסון הקבוע שלכם, כמו Persistent Disks או Hyperdisks. שימוש בכונני SSD מקומיים מקטין את זמן האחזור של קריאת הדיסק ומגדיל את מספר השאילתות לשנייה (QPS) עבור עומסי העבודה עם שמירת מצב, תוך מזעור דרישות הזיכרון. GKE Data Cache תומך בכל הסוגים של Persistent Disk או Hyperdisk כדיסקים לגיבוי.
כדי להשתמש ב-GKE Data Cache באפליקציה, צריך להגדיר את מאגר הצמתים של GKE עם כונני SSD מקומיים שמצורפים אליו. אתם יכולים להגדיר את GKE Data Cache כך שישתמש בכל או בחלק מה-SSD המקומי המצורף. כונני SSD מקומיים שמשמשים את פתרון GKE Data Cache מוצפנים במצב מנוחה באמצעות הצפנה רגילה Google Cloud .
יתרונות
היתרונות של GKE Data Cache:
- שיעור גבוה יותר של שאילתות שמטופלות בשנייה במסדי נתונים רגילים, כמו MySQL או Postgres, ובמסדי נתונים וקטוריים.
- שיפור ביצועי הקריאה באפליקציות עם שמירת מצב על ידי צמצום זמן האחזור של הדיסק.
- הנתונים נטענים מהר יותר כי כונני ה-SSD נמצאים באופן מקומי בצומת. העברת נתונים היא התהליך הראשוני של טעינת הנתונים הדרושים מאחסון קבוע ל-SSD המקומי. החזרת נתונים למצב פעיל היא תהליך שבו משחזרים את הנתונים בכונני ה-SSD המקומיים אחרי שמבצעים מיחזור של צומת.
ארכיטקטורת פריסה
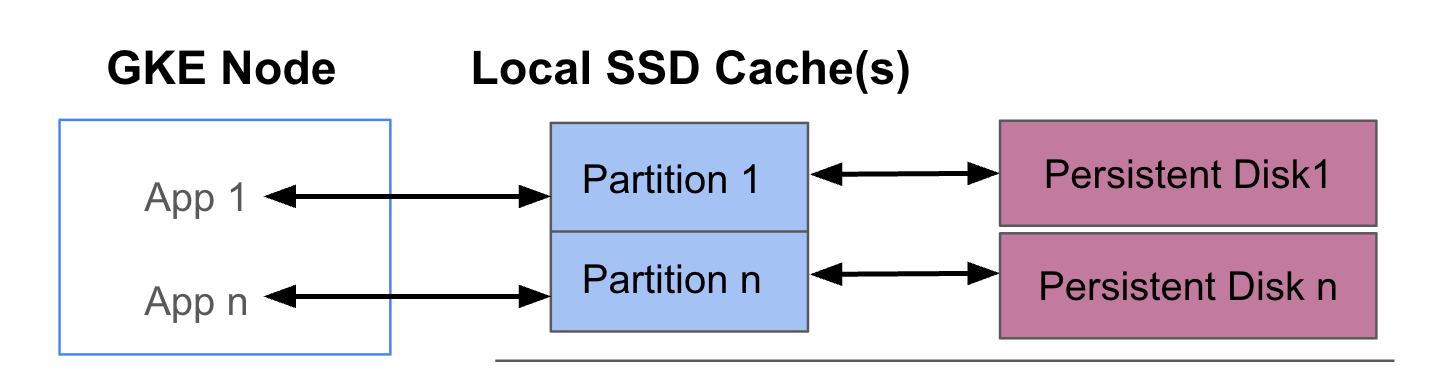
בתרשים הבא מוצגת דוגמה להגדרה של GKE Data Cache עם שני פודים, שכל אחד מהם מריץ אפליקציה. הפודים רצים באותו צומת GKE. כל Pod משתמש ב-SSD מקומי נפרד ובדיסק קבוע שמשמש כגיבוי.
מצבי פריסה
אפשר להגדיר את GKE Data Cache באחד משני מצבים:
- Writethrough (מומלץ): כשהאפליקציה כותבת נתונים, הנתונים נכתבים באופן סינכרוני גם למטמון וגם לדיסק הבסיסי הקבוע. המצב
writethroughמונע אובדן נתונים ומתאים לרוב עומסי העבודה של הייצור. - כתיבה חוזרת (Writeback): כשהאפליקציה כותבת נתונים, הנתונים נכתבים רק במטמון. לאחר מכן, הנתונים נכתבים בדיסק המתמיד באופן אסינכרוני (ברקע). מצב
writebackמשפר את ביצועי הכתיבה ומתאים לעומסי עבודה שמסתמכים על מהירות. עם זאת, המצב הזה משפיע על האמינות. אם הצומת נסגר באופן לא צפוי, נתוני מטמון שלא נמחקו יאבדו.
מטרות
במדריך הזה תלמדו איך:
- יצירת תשתית בסיסית של GKE כדי להשתמש ב-GKE Data Cache.
- יוצרים מאגר צמתים ייעודי עם כונני SSD מקומיים מצורפים.
- יוצרים StorageClass להקצאה דינמית של PersistentVolume (PV) כש-Pod מבקש אותו דרך PersistentVolumeClaim (PVC).
- יוצרים PVC כדי לבקש PV.
- יוצרים Deployment שמשתמש ב-PVC כדי להבטיח שלאפליקציה תהיה גישה לאחסון מתמיד גם אחרי הפעלה מחדש של Pod, ובמהלך תזמון מחדש.
דרישות ותכנון
כדי להשתמש ב-GKE Data Cache, צריך לוודא שאתם עומדים בדרישות הבאות:
- באשכול GKE צריכה לפעול גרסה 1.32.3-gke.1440000 ומעלה.
- במאגרי הצמתים צריך להשתמש בסוגי מכונות שתומכים ב-SSD מקומי. מידע נוסף זמין במאמר בנושא תמיכה בסדרות של מכונות.
תכנון
כשמתכננים את קיבולת האחסון של GKE Data Cache, כדאי לקחת בחשבון את ההיבטים הבאים:
- מספר ה-Pods המקסימלי לכל צומת שישתמש במטמון הנתונים של GKE בו-זמנית.
- דרישות הגודל הצפויות של המטמון של ה-Pods שישתמשו ב-GKE Data Cache.
- הקיבולת הכוללת של כונני SSD מקומיים שזמינים בצמתי GKE. למידע על סוגי המכונות שבהם מצורפים כברירת מחדל התקני SSD מקומיים ועל סוגי המכונות שבהם צריך לצרף התקני SSD מקומיים, אפשר לקרוא את המאמר בחירת מספר תקין של דיסקים מקומיים מסוג SSD.
- בסוגי מכונות מהדור השלישי ואילך (שמצורף אליהם מספר ברירת מחדל של כונני SSD מקומיים), כדאי לשים לב שכונני ה-SSD המקומיים של מטמון הנתונים שמורים מתוך המספר הכולל של כונני ה-SSD המקומיים שזמינים במכונה.
- התקורה של מערכת הקבצים, שיכולה להקטין את השטח שניתן לשימוש בכונני SSD מקומיים. לדוגמה, גם אם יש לכם צומת עם שני כונני SSD מקומיים עם קיבולת כוללת של 750 GiB, יכול להיות שהשטח הפנוי לכל נפחי מטמון הנתונים יהיה קטן יותר בגלל תקורה של מערכת הקבצים. חלק מהקיבולת של כונן ה-SSD המקומי שמור לשימוש המערכת.
מגבלות
אי-תאימות לגיבוי ל-GKE
כדי לשמור על תקינות הנתונים בתרחישים כמו התאוששות מאסון או העברת אפליקציות, יכול להיות שתצטרכו לגבות ולשחזר את הנתונים. אם משתמשים ב-Backup for GKE כדי לשחזר PVC שהוגדר לשימוש במטמון נתונים, תהליך השחזור נכשל. הכשל הזה מתרחש כי תהליך השחזור לא מעביר בצורה נכונה את הפרמטרים הדרושים של מטמון הנתונים מ-StorageClass המקורי.
תמחור
החיוב מתבצע על סך הקיבולת שהוקצתה ל-SSD המקומי ולדיסקים הקשיחים הקבועים שמצורפים אליו. החיוב הוא לפי GiB לחודש.
מידע נוסף מופיע במאמר בנושא תמחור של דיסקים במסמכי התיעוד של Compute Engine.
לפני שמתחילים
לפני שמתחילים, חשוב לוודא שביצעתם את הפעולות הבאות:
- מפעילים את ממשק Google Kubernetes Engine API. הפעלת Google Kubernetes Engine API
- כדי להשתמש ב-CLI של Google Cloud למשימה הזו, צריך להתקין ואז להפעיל את gcloud CLI. אם התקנתם בעבר את ה-CLI של gcloud, מריצים את הפקודה
gcloud components updateכדי לקבל את הגרסה העדכנית. יכול להיות שגרסאות קודמות של ה-CLI של gcloud לא יתמכו בהרצת הפקודות שמופיעות במסמך הזה.
- בודקים את סוגי המכונות שתומכים בכונני SSD מקומיים במאגר הצמתים.
הגדרת צמתים של GKE לשימוש במטמון נתונים
כדי להתחיל להשתמש ב-GKE Data Cache לאחסון מהיר, בצמתים שלכם צריכים להיות משאבי SSD מקומיים נדרשים. בקטע הזה מוצגות פקודות להקצאת כונני SSD מקומיים ולהפעלת GKE Data Cache כשיוצרים אשכול GKE חדש או כשמוסיפים מאגר צמתים חדש לאשכול קיים. אי אפשר לעדכן מאגר צמתים קיים כדי להשתמש במטמון נתונים. אם רוצים להשתמש במטמון נתונים באשכול קיים, צריך להוסיף מאגר צמתים חדש לאשכול.
באשכול חדש
כדי ליצור אשכול GKE עם הגדרות של Data Cache, משתמשים בפקודה הבאה:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
מחליפים את מה שכתוב בשדות הבאים:
-
CLUSTER_NAME: שם האשכול. מזינים שם ייחודי לאשכול GKE שיוצרים. -
LOCATION: Google Cloud האזור או התחום של האשכול החדש. -
MACHINE_TYPE: סוג המכונה לשימוש מסדרת מכונות מהדור השני, השלישי או דורות מאוחרים יותר עבור האשכול, כמוn2-standard-2אוc3-standard-4-lssd. זהו שדה חובה כי אי אפשר להשתמש ב-SSD מקומי עם סוג ברירת המחדלe2-medium. מידע נוסף מופיע במאמר בנושא סדרות מכונות. -
DATA_CACHE_COUNT: מספר הכרכים של SSD מקומי שיוקדשו באופן בלעדי למטמון נתונים בכל צומת במאגר הצמתים שמוגדר כברירת מחדל. לכל אחד מה-SSD המקומיים האלה יש קיבולת של 375 GiB. המספר המקסימלי של אמצעי אחסון משתנה בהתאם לסוג המכונה ולאזור. שימו לב: חלק מהקיבולת של ה-SSD המקומי שמור לשימוש המערכת. (Optional)
LOCAL_SSD_COUNT: מספר נפחי ה-Local SSD שצריך להקצות לצרכים אחרים של אחסון זמני. משתמשים בדגל--ephemeral-storage-local-ssd countאם רוצים להקצות עוד כונני SSD מקומיים שלא משמשים למטמון נתונים.הערות לגבי סוגי מכונות מהדור השלישי ואילך:
- לסוגי מכונות מהדור השלישי ואילך יש מספר מסוים של כונני SSD מקומיים שמצורפים כברירת מחדל. מספר כונני ה-SSD המקומיים שמצורפים לכל צומת תלוי בסוג המכונה שאתם מציינים.
- אם אתם מתכננים להשתמש בדגל
--ephemeral-storage-local-ssd countלאחסון זמני נוסף, הקפידו להגדיר את הערך שלDATA_CACHE_COUNTלמספר שהוא נמוך מהכמות הכוללת הזמינה של דיסקים מקומיים מסוג SSD במחשב. המספר הכולל של כונני SSD מקומיים שזמינים כולל את הדיסקים המצורפים שמוגדרים כברירת מחדל ואת כל הדיסקים החדשים שמוסיפים באמצעות הדגל--ephemeral-storage-local-ssd count.
הפקודה הזו יוצרת אשכול GKE שפועל בסוג מכונה מהדור השני, השלישי או דורות מאוחרים יותר עבור מאגר הצמתים שמוגדר כברירת מחדל, מקצה כונני SSD מקומיים למטמון נתונים, ומקצה כונני SSD מקומיים נוספים לצרכים אחרים של אחסון זמני, אם מצוין.
ההגדרות האלה חלות רק על מאגר הצמתים שמוגדר כברירת מחדל.
באשכול קיים
כדי להשתמש במטמון נתונים באשכול קיים, צריך ליצור מאגר צמתים חדש עם מטמון נתונים מוגדר.
כדי ליצור מאגר צמתים ב-GKE עם הגדרת מטמון נתונים, משתמשים בפקודה הבאה:
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
מחליפים את מה שכתוב בשדות הבאים:
-
NODE_POOL_NAME: שם מאגר הצמתים. מזינים שם ייחודי למאגר הצמתים שיוצרים. -
CLUSTER_NAME: השם של אשכול GKE קיים שבו רוצים ליצור את מאגר הצמתים. -
LOCATION: אותו אזור או תחום כמו האשכול. Google Cloud -
MACHINE_TYPE: סוג המכונה לשימוש מסדרת מכונות מהדור השני, השלישי או דורות מאוחרים יותר עבור האשכול, כמוn2-standard-2אוc3-standard-4-lssd. השדה הזה הוא חובה, כי אי אפשר להשתמש ב-SSD מקומי עם סוג ברירת המחדלe2-medium. מידע נוסף מופיע במאמר בנושא סדרות מכונות. -
DATA_CACHE_COUNT: מספר נפחי ה-SSD המקומי שיוקדשו באופן בלעדי למטמון נתונים בכל צומת במאגר הצמתים. לכל אחד מה-SSD המקומיים האלה יש קיבולת של 375 GiB. המספר המקסימלי של אמצעי אחסון משתנה בהתאם לסוג המכונה ולאזור. שימו לב: חלק מהקיבולת של ה-SSD המקומי שמור לשימוש המערכת. (Optional)
LOCAL_SSD_COUNT: מספר נפחי ה-Local SSD שצריך להקצות לצרכים אחרים של אחסון זמני. משתמשים בדגל--ephemeral-storage-local-ssd countאם רוצים להקצות עוד כונני SSD מקומיים שלא משמשים למטמון נתונים.הערות לגבי סוגי מכונות מהדור השלישי ואילך:
- לסוגי מכונות מהדור השלישי ואילך יש מספר מסוים של כונני SSD מקומיים שמצורפים כברירת מחדל. מספר כונני ה-SSD המקומיים שמצורפים לכל צומת תלוי בסוג המכונה שאתם מציינים.
- אם אתם מתכננים להשתמש בדגל
--ephemeral-storage-local-ssd countלאחסון זמני נוסף, הקפידו להגדיר אתDATA_CACHE_COUNTלערך נמוך מהערך הכולל הזמין של דיסקים מקומיים מסוג SSD במכונה. המספר הכולל של כונני SSD מקומיים שזמינים כולל את הדיסקים המצורפים שמוגדרים כברירת מחדל ואת כל הדיסקים החדשים שמוסיפים באמצעות הדגל--ephemeral-storage-local-ssd count.
הפקודה הזו יוצרת מאגר צמתים של GKE שפועל בסוג מכונה מהדור השני, השלישי או דורות מאוחרים יותר, מקצה כונני SSD מקומיים למטמון נתונים, ואם מציינים זאת, מקצה כונני SSD מקומיים נוספים לצרכים אחרים של אחסון זמני.
הקצאת Data Cache לאחסון מתמיד ב-GKE
בקטע הזה מופיעה דוגמה להפעלה של היתרונות של GKE Data Cache בביצועים של אפליקציות עם שמירת מצב.
יצירת מאגר צמתים עם כונני SSD מקומיים למטמון נתונים
כדי להתחיל, יוצרים מאגר צמתים חדש עם כונני SSD מקומיים שמצורפים לאשכול GKE. GKE Data Cache משתמש ב-SSD מקומי כדי לשפר את הביצועים של דיסקים מתמידים שמצורפים.
הפקודה הבאה יוצרת מאגר צמתים שמשתמש במכונה מהדור השני, n2-standard-2:
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
מחליפים את מה שכתוב בשדות הבאים:
-
CLUSTER_NAME: שם האשכול. מציינים את אשכול GKE שבו יוצרים את מאגר הצמתים החדש. -
LOCATION: אותו אזור Google Cloud או תחום כמו האשכול שלכם.
הפקודה הזו יוצרת מאגר צמתים עם המפרט הבא:
-
--num-nodes=2: מגדיר את המספר הראשוני של הצמתים במאגר הזה לשניים. -
--data-cache-count=1: מציין SSD מקומי אחד לכל צומת שמוקדש ל-GKE Data Cache.
המספר הכולל של כונני SSD מקומיים שהוקצו למאגר הצמתים הזה הוא שניים, כי לכל צומת הוקצה כונן SSD מקומי אחד.
יצירת Data Cache StorageClass
יוצרים StorageClass Kubernetes שמגדיר ל-GKE איך להקצות באופן דינמי נפח אחסון קבוע שמשתמש במטמון נתונים.
משתמשים במניפסט הבא כדי ליצור ולהחיל StorageClass בשם pd-balanced-data-cache-sc:
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
StorageClass הפרמטרים של מטמון הנתונים כוללים את הפרטים הבאים:
-
type: מציין את סוג הדיסק הבסיסי של נפח האחסון המתמיד. אפשרויות נוספות זמינות במאמרים בנושא סוגי Persistent Disk נתמכים או סוגי Hyperdisk. -
data-cache-mode: משתמש במצבwritethroughהמומלץ. מידע נוסף זמין במאמר בנושא מצבי פריסה. -
data-cache-size: מגדיר את הקיבולת של ה-SSD המקומי ל-100 GiB, שמשמש כמטמון לקריאה לכל PVC.
בקשה לנפח אחסון באמצעות PersistentVolumeClaim (PVC)
יוצרים PVC שמפנה אל pd-balanced-data-cache-sc StorageClass שיצרתם. ה-PVC מבקש נפח אחסון מתמיד עם Data Cache מופעל.
משתמשים במניפסט הבא כדי ליצור PVC בשם pvc-data-cache שמבקש נפח אחסון קבוע של לפחות 300 GiB עם גישת ReadWriteOnce.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
יצירת פריסה שמשתמשת ב-PVC
יוצרים פריסה בשם postgres-data-cache שמפעילה Pod שמשתמש ב-PVC pvc-data-cache שיצרתם קודם. הכלי cloud.google.com/gke-data-cache-countnode selector מוודא שה-Pod מתוזמן לצומת שיש בו את משאבי ה-SSD המקומי שנדרשים לשימוש ב-GKE Data Cache.
יוצרים את המניפסט הבא ומחילים אותו כדי להגדיר Pod שפורס שרת אינטרנט של Postgres באמצעות ה-PVC:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
מוודאים שהפריסה נוצרה בהצלחה:
kubectl get deployment
יכול להיות שיחלפו כמה דקות עד שהקצאת המשאבים של מאגר Postgres תסתיים ויוצג סטטוס READY.
אימות ההקצאה של מטמון הנתונים
אחרי שיוצרים את הפריסה, מוודאים שהקצאת האחסון הקבוע עם מטמון הנתונים מתבצעת בצורה נכונה.
כדי לוודא ש-
pvc-data-cacheקשור בהצלחה לנפח אחסון מתמשך, מריצים את הפקודה הבאה:kubectl get pvc pvc-data-cacheהפלט אמור להיראות כך:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10mכדי לוודא שקבוצת Logical Volume Manager (LVM) של מטמון הנתונים נוצרה בצומת, פועלים לפי השלבים הבאים:
מקבלים את שם ה-Pod של מנהל ההתקן PDCSI בצומת הזה:
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAMEמעתיקים את השם של
pdcsi-nodeה-Pod מהפלט.צפייה ביומני מנהלי התקנים של PDCSI ליצירת קבוצת LVM:
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"מחליפים את
PDCSI-NODE_POD_NAMEבשם ה-Pod בפועל שהעתקתם בשלב הקודם.הפלט אמור להיראות כך:
Volume group creation succeeded for LVM_GROUP_NAME
ההודעה הזו מאשרת שהגדרת ה-LVM של מטמון הנתונים מוגדרת בצורה נכונה בצומת.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud , מוחקים את משאבי האחסון שיצרתם במדריך הזה.
מוחקים את הפריסה.
kubectl delete deployment postgres-data-cacheמוחקים את PersistentVolumeClaim.
kubectl delete pvc pvc-data-cacheמוחקים את מאגר הצמתים.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMEמחליפים את
CLUSTER_NAMEבשם האשכול שבו יצרתם את מאגר הצמתים שמשתמש במטמון נתונים.
המאמרים הבאים
- אפשר לעיין במאמר בנושא פתרון בעיות באחסון ב-GKE.
- מידע נוסף על מנהל התקן Persistent Disk CSI ב-GitHub