
Las devoluciones de llamada son una función avanzada que proporciona un mecanismo potente para conectarse al proceso de ejecución de un agente específico con código de Python. Te permiten observar, personalizar y hasta controlar el comportamiento del agente en puntos específicos predefinidos.
Existen varios tipos de devoluciones de llamada que puedes utilizar, y cada tipo se ejecuta en un punto específico del turno de conversación. Estos tipos se describen en las siguientes secciones.
Clases y entorno de ejecución de Python
En el código de devolución de llamada de Python, tienes acceso a ciertas clases y funciones que te ayudan a escribir el código. Para obtener más información, consulta la referencia del entorno de ejecución de Python.
Tipos de devolución de llamada
Según el tipo de devolución de llamada, tu función de devolución de llamada principal debe tener un nombre específico. Esto te permite definir funciones auxiliares con cualquier nombre dentro del código de devolución de llamada.
Cada tipo de devolución de llamada se ejecuta en un punto específico del turno de conversación:
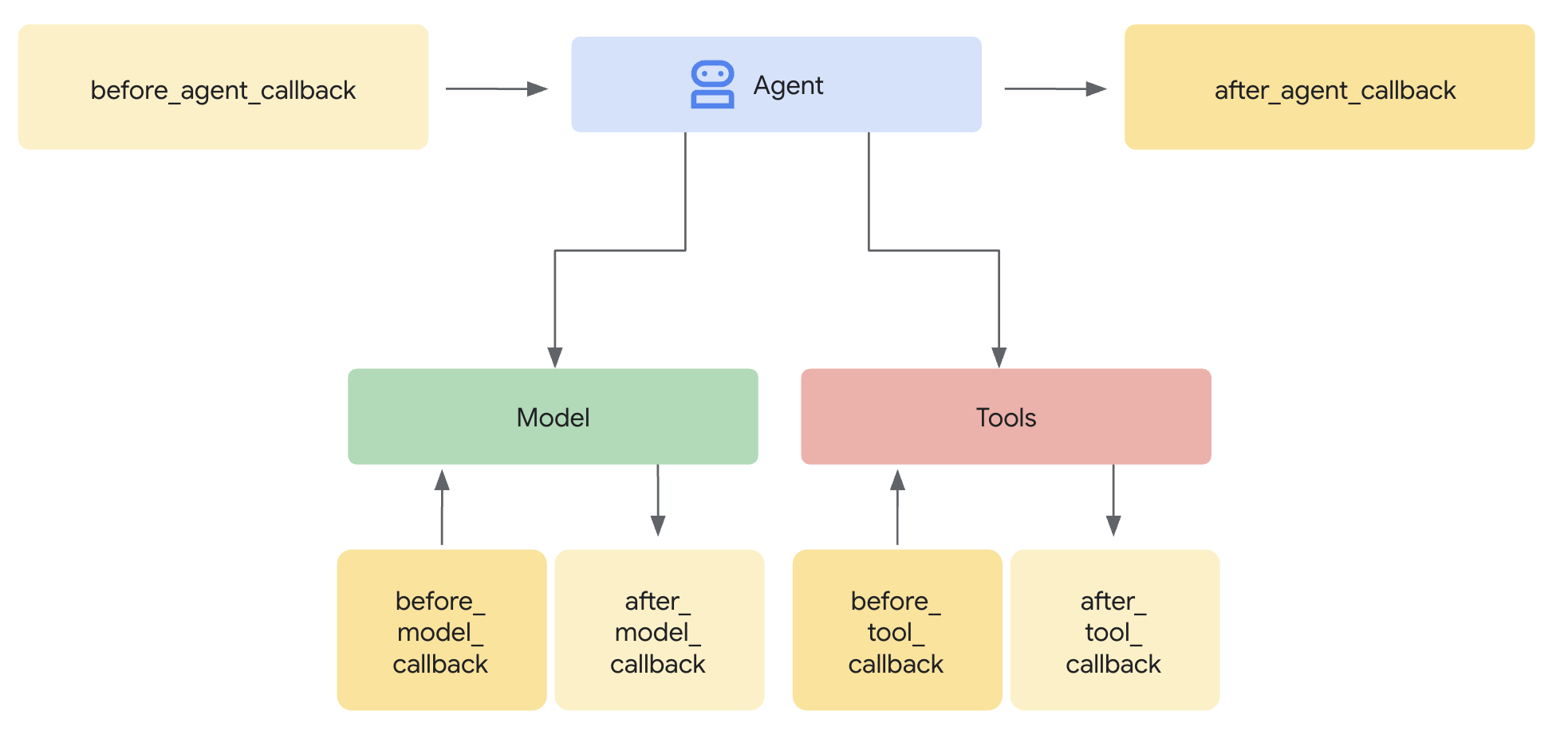
Si defines varias devoluciones de llamada de un tipo específico, se ejecutarán en el orden en que las definas.
En las siguientes secciones, se describe cada tipo de devolución de llamada, y se incluye la siguiente información para cada tipo:
| X | X |
|---|---|
| Nombre | Nombre de la función de devolución de llamada obligatoria |
| Ejecución | Es el punto de ejecución dentro del turno de conversación. |
| Objetivo | Situaciones útiles para usar la devolución de llamada. |
| Argumentos | Son los argumentos de entrada para la función. |
| Volver | Es el valor de retorno de la función. |
| Devolución de llamada del ADK | Vínculo a la documentación de devolución de llamada del ADK correspondiente. |
Antes de que se inicie el agente (before_agent_callback)
| X | X |
|---|---|
| Nombre | before_agent_callback |
| Ejecución | Se llama antes de invocar al agente. |
| Objetivo | Es útil para configurar el estado o los recursos necesarios para el agente, realizar verificaciones de validación en el estado de la sesión o evitar la invocación del agente. |
| Argumentos | CallbackContext |
| Volver | Content(opcional): Si se configura, no se invoca al agente y se usa la respuesta proporcionada. |
| Devolución de llamada del ADK | before agent callback |
Muestra de código:
import random
def before_agent_callback(
callback_context: CallbackContext
) -> Optional[Content]:
username = callback_context.variables.get("username", None)
if not username:
# default user
final_name = "Default Name"
else:
# add a random integer to the username
final_name = f"{username} {random.randint(1,10)}"
# update the username variable
callback_context.variables["username"] = final_name
Después de que el agente finaliza (after_agent_callback)
| X | X |
|---|---|
| Nombre | after_agent_callback |
| Ejecución | Se llama después de que el agente completa su tarea. |
| Objetivo | Es útil para realizar tareas de limpieza, validar datos después de la ejecución, modificar el estado final o actualizar la respuesta del agente. |
| Argumentos | CallbackContext |
| Volver | Content(opcional): Si se configura, reemplaza el resultado del agente por el resultado proporcionado. |
| Devolución de llamada del ADK | after agent callback |
Muestra de código:
def after_agent_callback(
callback_context: CallbackContext
) -> Optional[Content]:
if callback_context.agent_name == "Routing Agent":
counter = callback_context.variables.get("counter", 0)
counter += 1
# increment the invoked counter for this agent
callback_context.variables["counter"] = int(counter)
Antes de la llamada al LLM (before_model_callback)
| X | X |
|---|---|
| Nombre | before_model_callback |
| Ejecución | Se llama antes de la solicitud del modelo. |
| Objetivo | Es útil para inspeccionar o modificar la solicitud del modelo, o para evitar el uso del modelo. |
| Argumentos | CallbackContext, LlmRequest |
| Volver | LlmResponse: Si se configura, se omite la llamada al modelo y se usa la respuesta como si proviniera del modelo. |
| Devolución de llamada del ADK | before model callback |
Muestra de código:
def before_model_callback(
callback_context: CallbackContext,
llm_request: LlmRequest
) -> Optional[LlmResponse]:
"""
This callback executes *before* a request is sent to the LLM.
By returning an `LlmResponse` object, we are intercepting the call to the
LLM. The LLM will *not* be called, and the framework will instead use the
`LlmResponse` we provide as if it came from the model.
This is the core mechanism for implementing input guardrails, prompt
validation, or serving responses from a cache. Here, we force the agent to
call a function instead of thinking with the LLM.
"""
# Modify the shared session state.
callback_context.variables['foo'] = 'baz'
# Skip the LLM call and return a custom response telling the agent to
# execute a specific function.
return LlmResponse(
content=Content(parts=[Part(
function_call=FunctionCall(
name="function_name", args={"arg_name": "arg_value"}))],
role="model"))
Después de la llamada al LLM (after_model_callback)
| X | X |
|---|---|
| Nombre | after_model_callback |
| Ejecución | Se llama después de que se recibe una respuesta del modelo. |
| Objetivo | Es útil para cambiar el formato de las respuestas del modelo, censurar la información sensible generada por el modelo, analizar los datos estructurados del modelo para usarlos en variables y manejo de errores del modelo. |
| Argumentos | CallbackContext, LlmResponse |
| Volver | LlmResponse: Si se configura, reemplaza la respuesta del modelo por la respuesta proporcionada. |
| Devolución de llamada del ADK | Devolución de llamada posterior al modelo |
Muestra de código:
def after_model_callback(
callback_context: CallbackContext,
llm_response: LlmResponse
) -> Optional[LlmResponse]:
"""
This callback executes *after* a response has been received from the LLM,
but before the agent processes it.
The `llm_response` parameter contains the actual data from the LLM.
By returning `None`, we are approving this response and allowing the agent
to use it as-is.
If we returned a new `LlmResponse` object, it would *replace* the original,
which is useful for redacting sensitive information, enforcing output
formatting, or adding disclaimers.
"""
# Returning None allows the LLM's actual response to be used.
return None
Antes de la llamada a la herramienta (before_tool_callback)
| X | X |
|---|---|
| Nombre | before_tool_callback |
| Ejecución | Se llama antes de las llamadas a herramientas. |
| Objetivo | Es útil para inspeccionar y modificar los argumentos de las herramientas, realizar verificaciones de autorización antes de la ejecución de las herramientas o implementar el almacenamiento en caché a nivel de las herramientas. |
| Argumentos | Tool, Dict[str,Any]: Entradas de la herramienta, CallbackContext |
| Volver | Dict[str,Any] : Si se configura, se omite la ejecución de la herramienta y se proporciona este resultado al modelo. |
| Devolución de llamada del ADK | before tool callback |
Muestra de código:
def before_tool_callback(
tool: Tool,
input: dict[str, Any],
callback_context: CallbackContext
) -> Optional[dict[str, Any]]:
"""
This callback executes *before* a specific tool is called by the agent.
Here, we modify the input arguments intended for the tool and then return
a dictionary. By returning a dictionary instead of `None`, we are
overriding the default behavior. The actual tool function will *not* be
executed. Instead, the dictionary we return will be treated as the
llm.tool's result and passed back to the LLM for the next step.
This is ideal for validating tool inputs, applying policies, or returning
mocked/cached data for testing.
"""
# Modify the shared session state.
callback_context.variables['foo'] = 'baz'
# Modify the arguments for the tool call in-place.
input['input_arg'] = 'updated_val1'
input['additional_arg'] = 'updated_val2'
# Override the tool call and return a mocked result.
return {"result": "ok"}
Después de la llamada a la herramienta (after_tool_callback)
| X | X |
|---|---|
| Nombre | after_tool_callback |
| Ejecución | Se llama después de que se completa la herramienta. |
| Objetivo | Es útil para inspeccionar y modificar la respuesta de la herramienta antes de enviarla al modelo, procesar los resultados de la herramienta de forma posterior o guardar partes específicas de una respuesta de la herramienta en variables. |
| Argumentos | Tool, Dict[str,Any]: Entradas de la herramienta, CallbackContext, Dict[str,Any]: Respuesta de la herramienta |
| Volver | Dict[str,Any]: Si se configura, anula la respuesta de la herramienta que se proporciona al modelo. |
| Devolución de llamada del ADK | después de la devolución de llamada de la herramienta |
Muestra de código:
# Previous tool was named `get_user_info`
# Previous tool returned the payload:
# {"username": "Patrick", "fave_food": ["pizza"]}
def after_tool_callback(
tool: Tool,
input: dict[str, Any],
callback_context: CallbackContext,
tool_response: dict
) -> Optional[dict]:
if tool.name == "get_user_info":
tool_response["username"] = "Gary"
tool_response["pet"] = "dog"
# Override tool response
return tool_response
Crea una devolución de llamada
Para crear una devolución de llamada, haz lo siguiente:
- Abre la configuración del agente.
- Haz clic en Agregar código.
- Selecciona un tipo de devolución de llamada.
- Proporciona código de Python.
- Haz clic en Guardar.
Cargas útiles personalizadas (custom_payloads)
Las cargas útiles personalizadas facilitan la inclusión de datos estructurados complementarios y no textuales (por lo general, con formato JSON) en la respuesta de un agente. Esta carga útil es fundamental para dirigir o aumentar la interacción del agente con sistemas externos o aplicaciones cliente.
El modelo de lenguaje grande (LLM) no puede ver el valor de la carga útil, ya que solo se usa para generar la respuesta final.
Las cargas útiles personalizadas se generan y configuran con devoluciones de llamada, específicamente before_model_callback o after_model_callback.
La carga útil personalizada se puede usar para varios propósitos, generalmente centrados en habilitar interacciones enriquecidas y estructuradas:
- Transferencia o derivación al agente: Se usa con frecuencia para transferir una interacción a un agente humano proporcionando instrucciones de enrutamiento (por ejemplo, la cola específica a la que se debe enrutar).
- Contenido enriquecido y acciones del cliente:
Permite incorporar widgets enriquecidos y otro contenido enriquecido directamente en las experiencias de chat, lo que resulta especialmente útil para las integraciones de chat personalizadas.
- Por ejemplo, mostrar URLs de imágenes o chips y opciones de respuesta rápida para un cliente que usa una interfaz como Call Companion.
- Composición de la respuesta:
Las cargas útiles personalizadas se pueden configurar para que se muestren de varias maneras:
- Devuelve solo la carga útil explícita de forma determinística.
- Devuelve la carga útil junto con una respuesta de texto generada por un LLM.
- Devuelve la carga útil con una respuesta de texto estático
Configuración del agente
Las cargas útiles personalizadas solo se pueden generar y establecer con devoluciones de llamada.
La carga útil se establece como un Blob con un mime_type de application/json.
Part.from_json(data=payload_string)
Ejemplo de after_model_callback
Este es un ejemplo de after_model_callback que devuelve la respuesta del modelo junto con una respuesta de carga útil personalizada adicional.
import json
def after_model_callback(callback_context: CallbackContext, llm_response: LlmResponse) -> Optional[LlmResponse]:
"""
Adds a custom payload to every model response which is a text
"""
if (llm_response.content.parts[0].text is not None):
# construct payload
payload_dict = { "custom_payload_key": "custom_payload_value"}
payload_json_string = json.dumps(payload_dict)
new_parts = []
# Keep the origial agent response part, as model only sees text in the historical context.
new_parts.append(Part(text=llm_response.content.parts[0].text))
# Append custom payload
new_parts.append(Part.from_json(data=payload_string))
return LlmResponse(content=Content(parts=new_parts))
Ejemplo de before_model_callback
Este es un ejemplo de before_model_callback que devuelve una carga útil personalizada adicional después de que se activa una herramienta determinada.
import json
def has_escalate(llm_request: LlmRequest) -> bool:
for content in llm_request.contents:
for part in content.parts:
if part.function_call and part.function_call.name == 'escalate':
return True
return False
def before_model_callback(callback_context: CallbackContext, llm_request: LlmRequest) -> Optional[LlmResponse]:
# checks if `escalate` tool is being called
if not has_escalate(llm_request):
return None
payload_dict = { "escalate": "user ask for escalation"}
payload_json_string = json.dumps(payload_dict)
return LlmResponse(content=Content(parts=[Part(text="ESCALATE!!!"), Part.from_json(data=payload_json_string)]))
Verifica la carga útil en la respuesta durante el tiempo de ejecución
La carga útil se completa como un Struct en el campo payload para RunSession y BidiRunSession.
El LLM no puede ver el valor de la carga útil.