
הגדרת הרשאות לפונקציות של AI גנרטיבי שמפעילות מודלים גדולים של שפה (LLM) בפלטפורמת הסוכנים של Gemini Enterprise
במסמך הזה מוסבר איך מגדירים הרשאות להרצת שאילתות של AI גנרטיבי. שאילתות של AI גנרטיבי מכילות פונקציות AI.* שקוראות למודלים בסיסיים ב-Gemini Enterprise Agent Platform, לדוגמה, AI.GENERATE.
יש שתי דרכים להגדיר הרשאות להרצת שאילתות שמשתמשות בפונקציות AI.*:
- מריצים את השאילתה באמצעות פרטי הכניסה של משתמש הקצה
- יצירת חיבור ל-BigQuery כדי להריץ את השאילתה באמצעות חשבון שירות
ברוב המקרים אפשר להשתמש בפרטי הכניסה של משתמש הקצה ולהשאיר את הארגומנט CONNECTION ריק. אם אתם צופים ששאילתת העבודה תפעל במשך 48 שעות או יותר, אתם צריכים להשתמש בחיבור ל-BigQuery ולכלול אותו בארגומנט CONNECTION.
הפעלת שאילתות של AI גנרטיבי באמצעות פרטי כניסה של משתמשי קצה
כדי להריץ שאילתות של AI גנרטיבי באמצעות פרטי כניסה של משתמשי קצה, צריך להגדיר את ההרשאות הנדרשות באמצעות Google Cloud המסוף. הערה: אם אתם בעלי הפרויקט, כבר יש לכם את כל ההרשאות הנדרשות, כך שלא צריך לעשות שום דבר.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות להרצת שאילתה שקוראת למודל Vertex AI, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים בפרויקט:
-
הפעלת משימות של שאילתות:
BigQuery Job User (
roles/bigquery.jobUser) -
גישה למודל בסיסי ב-Gemini Enterprise Agent Platform:
משתמש Agent Platform (
roles/aiplatform.user)
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שאפשר לקבל את ההרשאות הנדרשות גם באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש.
הענקת התפקידים הנדרשים למשתמש או לקבוצה
אתם יכולים להשתמש במסוף Google Cloud או ב-SQL כדי להעניק את התפקידים הנדרשים לישות מורשית. הישות המורשית היא המשתמש או הקבוצה שמריצים את השאילתה שמשתמשת בפונקציות AI.* כדי לקרוא למודל בסיס של Gemini Enterprise Agent Platform.
המסוף
נכנסים לדף IAM במסוף Google Cloud .
בוחרים את הפרויקט הרצוי.
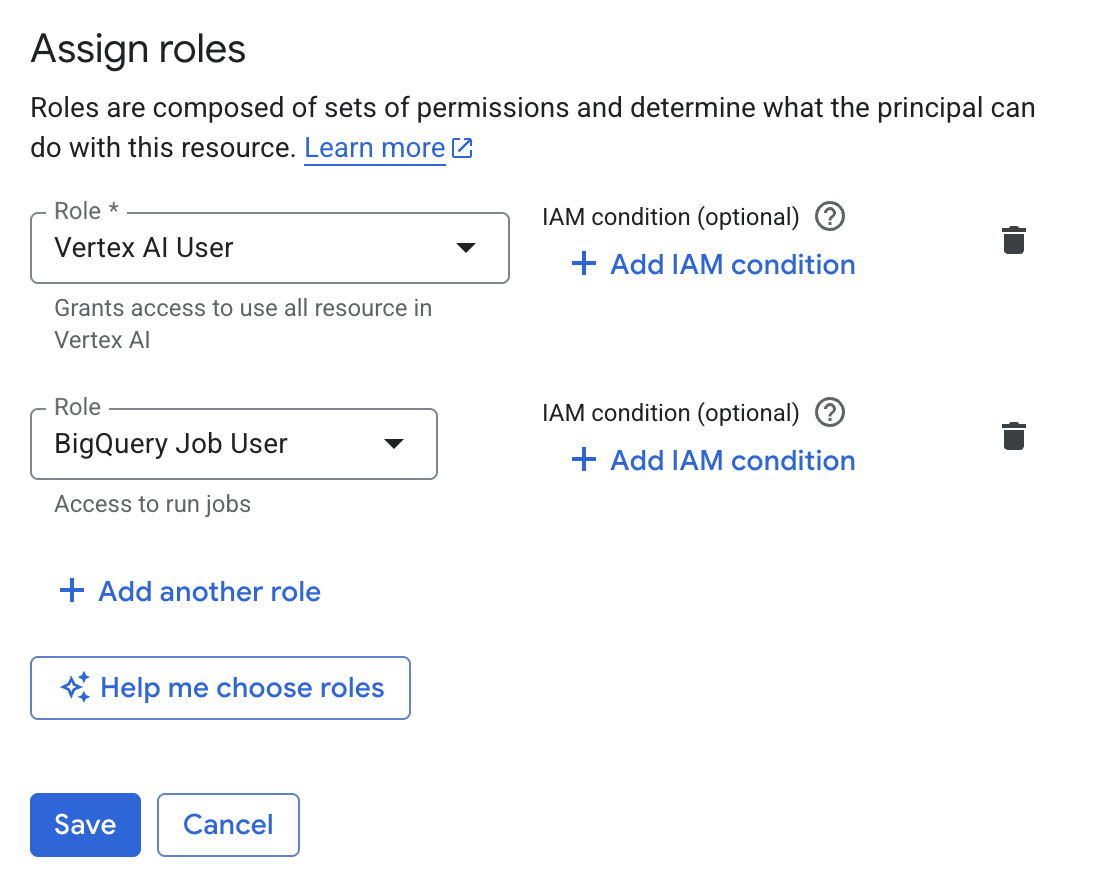
כדי להקצות תפקידים לחשבון משתמש, מבצעים את הפעולות הבאות:
עוברים לדף IAM & Admin.
לוחצים על Grant access.
תיבת הדו-שיח Add principals נפתחת.
בשדה New principals, מזינים את מזהה החשבון הראשי – לדוגמה,
my-user@example.comאו//iam.googleapis.com/locations/global/workforcePools/example-pool/group/example-group@example.com.בקטע Assign roles (הקצאת תפקידים), לוחצים על החץ של התפריט הנפתח Select a role (בחירת תפקיד).
מחפשים את התפקיד Agent Platform User ובוחרים אותו.
לוחצים על הוספת תפקיד נוסף.
בקטע Assign roles (הקצאת תפקידים), לוחצים על החץ של התפריט הנפתח Select a role (בחירת תפקיד).
מחפשים את התפקיד BigQuery Job User ובוחרים אותו.
לוחצים על Save.
SQL
משתמשים בהצהרה GRANT:
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
GRANT `roles/aiplatform.user`, `roles/bigquery.jobUser` ON PROJECT `PROJECT_ID` TO "USER_OR_GROUP";
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: הפרויקט שבו אתם מתכננים להשתמש בפונקציות שלAI.*. -
USER_OR_GROUP: המשתמש או הקבוצה שרוצים להעניק להם גישה, בפורמטuser:USER@DOMAINאוgroup:GROUP@DOMAIN.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
כדי לשנות את התפקידים של חשבון משתמש שכבר יש לו תפקידים בפרויקט, אפשר לעיין במאמר בנושא הקצאת תפקידים נוספים לאותו חשבון משתמש.
במאמר איך מקצים או מבטלים כמה תפקידי IAM באופן פרוגרמטי מוסבר על שיטות נוספות להקצאת תפקידים ברמת הפרויקט לחשבון משתמש.
הרצת שאילתות של AI גנרטיבי באמצעות חיבור ל-BigQuery
כדי להריץ שאילתות של AI גנרטיבי באמצעות חיבור, צריך ליצור את החיבור ואז להעניק גישה לחשבון השירות שנוצר על ידי החיבור.
יצירת חיבור
אתם יכולים להגדיר קישור למשאבים ב-Cloud כדי להריץ את כל השאילתות של AI גנרטיבי שמכילות פונקציות של AI.*. כשיוצרים חיבור, נותנים הרשאות להפעלת שאילתות לחשבון שירות.
המסוף
עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer מרחיבים את שם הפרויקט ואז לוחצים על Connections.
בדף Connections (חיבורים), לוחצים על Create connection (יצירת חיבור).
בשדה Connection type (סוג החיבור), בוחרים באפשרות Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) (מודלים מרוחקים של Vertex AI, פונקציות מרוחקות, BigLake ו-Spanner (משאב בענן)).
בשדה מזהה החיבור, מזינים שם לחיבור.
בקטע Location type, בוחרים מיקום לחיבור. החיבור צריך להיות ממוקם יחד עם משאבים אחרים, כמו מערכי נתונים.
לוחצים על יצירת קישור.
לוחצים על מעבר לחיבור.
בחלונית Connection info (פרטי התחברות), מעתיקים את מזהה חשבון השירות לשימוש בשלב מאוחר יותר.
SQL
משתמשים בהצהרה CREATE CONNECTION:
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
מחליפים את מה שכתוב בשדות הבאים:
-
CONNECTION_NAME: השם של החיבור בפורמטPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDאוCONNECTION_ID. אם לא מציינים את הפרויקט או המיקום, המערכת מסיקה אותם מהפרויקט והמיקום שבהם מופעלת ההצהרה. -
FRIENDLY_NAME(אופציונלי): שם תיאורי לחיבור. -
DESCRIPTION(אופציונלי): תיאור של הקישור.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
BQ
בסביבת שורת פקודה, יוצרים חיבור:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
הפרמטר
--project_idמבטל את פרויקט ברירת המחדל.מחליפים את מה שכתוב בשדות הבאים:
REGION: אזור החיבור-
PROJECT_ID: מזהה הפרויקט ב- Google Cloud -
CONNECTION_ID: מזהה לחיבור
כשיוצרים משאב חיבור, מערכת BigQuery יוצרת חשבון שירות ייחודי ומקשרת אותו לחיבור.
פתרון בעיות: אם מופיעה שגיאת החיבור הבאה, צריך לעדכן את Google Cloud SDK:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
מאחזרים ומעתיקים את מזהה חשבון השירות כדי להשתמש בו בשלב מאוחר יותר:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
הפלט אמור להיראות כך:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Terraform
משתמשים במשאב google_bigquery_connection.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
בדוגמה הבאה נוצר קישור למשאבים ב-Cloud בשם my_cloud_resource_connection באזור US:
כדי להחיל את הגדרות Terraform בפרויקט ב- Google Cloud , מבצעים את השלבים בקטעים הבאים.
הכנת Cloud Shell
- מפעילים את Cloud Shell.
-
מגדירים את פרויקט ברירת המחדל שבו רוצים להחיל את ההגדרות של Terraform. Google Cloud
תצטרכו להריץ את הפקודה הזו רק פעם אחת לכל פרויקט, ותוכלו לעשות זאת בכל ספרייה.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
אם תגדירו ערכים ספציפיים בקובץ התצורה של Terraform, הם יבטלו את ערכי ברירת המחדל של משתני הסביבה.
הכנת הספרייה
לכל קובץ תצורה של Terraform צריכה להיות ספרייה משלו (שנקראת גם מודול ברמה הבסיסית).
-
יוצרים ספרייה חדשה ב-Cloud Shell ובה יוצרים קובץ חדש. שם הקובץ חייב לכלול את הסיומת
.tf, למשלmain.tf. במדריך הזה, הקובץ נקראmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
אם אתם עוקבים אחרי המדריך, תוכלו להעתיק את הקוד לדוגמה בכל קטע או שלב.
מעתיקים את הקוד לדוגמה בקובץ
main.tfהחדש שיצרתם.לחלופין, אפשר גם להעתיק את הקוד מ-GitHub. כדאי לעשות את זה כשקטע הקוד של Terraform הוא חלק מפתרון מקצה לקצה.
- בודקים את הפרמטרים לדוגמה ומשנים אותם בהתאם לסביבה שלכם.
- שומרים את השינויים.
-
מפעילים את Terraform. צריך לעשות זאת רק פעם אחת לכל ספרייה.
terraform init
אופציונלי: תוכלו לכלול את האפשרות
-upgrade, כדי להשתמש בגרסה העדכנית ביותר של הספק של Google:terraform init -upgrade
החלה של השינויים
-
בודקים את ההגדרות ומוודאים שהמשאבים שמערכת Terraform תיצור או תעדכן תואמים לציפיות שלכם:
terraform plan
מתקנים את ההגדרות לפי הצורך.
-
מריצים את הפקודה הבאה ומזינים
yesבהודעה שמופיעה, כדי להחיל את הגדרות Terraform:terraform apply
ממתינים עד שב-Terraform תוצג ההודעה "Apply complete!".
- פותחים את Google Cloud הפרויקט כדי לראות את התוצאות. במסוף Google Cloud , נכנסים למשאבים בממשק המשתמש כדי לוודא שהם נוצרו או עודכנו ב-Terraform.
מידע נוסף מופיע במאמר בנושא יצירה והגדרה של קישור למשאבים ב-Cloud.
הענקת גישה לחשבון השירות
כדי להריץ שאילתות שמשתמשות בפונקציות גנרטיביות של AI.* שקוראות למודלים של Gemini Enterprise Agent Platform, צריך לתת הרשאות מתאימות לחשבון השירות שנוצר כשיוצרים את החיבור. כדי להריץ פונקציות שקוראות למודל בסיס של Gemini Enterprise Agent Platform, צריך את תפקיד המשתמש ב-Agent Platform (roles/aiplatform.user).
בוחרים באחת מהאפשרויות הבאות:
המסוף
עוברים לדף IAM & Admin.
לוחצים על Grant access.
תיבת הדו-שיח Add principals נפתחת.
בשדה New principals, מזינים את מזהה חשבון השירות שהעתקתם קודם.
בקטע הקצאת תפקידים, לוחצים על הוספת תפקידים.
מחפשים את התפקיד Agent Platform User, בוחרים אותו ולוחצים על Apply.
לוחצים על Save.
SQL
משתמשים בהצהרה GRANT:
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
GRANT `roles/aiplatform.user` ON PROJECT `PROJECT_ID` TO "connection:CONNECTION_NAME";
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: הפרויקט שבו אתם מתכננים להשתמש ב-Agent Platform. -
CONNECTION_NAME: השם של החיבור בפורמטPROJECT_ID.LOCATION.CONNECTION_IDאוLOCATION.CONNECTION_ID. אם לא מציינים פרויקט, המערכת מסיקה אותו מהפרויקט שבו מריצים את ההצהרה.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
gcloud
משתמשים בפקודה gcloud projects add-iam-policy-binding:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:$(bq show --format=prettyjson --connection $PROJECT_ID.$REGION.$CONNECTION_ID | jq -r .cloudResource.serviceAccountId)" --role=roles/aiplatform.user
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: שם הפרויקט. REGION: המיקום שבו נוצר החיבור.-
CONNECTION_ID: השם של החיבור שיצרתם.
Terraform
משתמשים במשאב google_bigquery_connection.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
בדוגמה הבאה מוקצית גישה לתפקיד IAM לחשבון השירות של חיבור משאב ה-Cloud:
כדי להחיל את הגדרות Terraform בפרויקט ב- Google Cloud , מבצעים את השלבים בקטעים הבאים.
הכנת Cloud Shell
- מפעילים את Cloud Shell.
-
מגדירים את פרויקט ברירת המחדל שבו רוצים להחיל את ההגדרות של Terraform. Google Cloud
תצטרכו להריץ את הפקודה הזו רק פעם אחת לכל פרויקט, ותוכלו לעשות זאת בכל ספרייה.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
אם תגדירו ערכים ספציפיים בקובץ התצורה של Terraform, הם יבטלו את ערכי ברירת המחדל של משתני הסביבה.
הכנת הספרייה
לכל קובץ תצורה של Terraform צריכה להיות ספרייה משלו (שנקראת גם מודול ברמה הבסיסית).
-
יוצרים ספרייה חדשה ב-Cloud Shell ובה יוצרים קובץ חדש. שם הקובץ חייב לכלול את הסיומת
.tf, למשלmain.tf. במדריך הזה, הקובץ נקראmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
אם אתם עוקבים אחרי המדריך, תוכלו להעתיק את הקוד לדוגמה בכל קטע או שלב.
מעתיקים את הקוד לדוגמה בקובץ
main.tfהחדש שיצרתם.לחלופין, אפשר גם להעתיק את הקוד מ-GitHub. כדאי לעשות את זה כשקטע הקוד של Terraform הוא חלק מפתרון מקצה לקצה.
- בודקים את הפרמטרים לדוגמה ומשנים אותם בהתאם לסביבה שלכם.
- שומרים את השינויים.
-
מפעילים את Terraform. צריך לעשות זאת רק פעם אחת לכל ספרייה.
terraform init
אופציונלי: תוכלו לכלול את האפשרות
-upgrade, כדי להשתמש בגרסה העדכנית ביותר של הספק של Google:terraform init -upgrade
החלה של השינויים
-
בודקים את ההגדרות ומוודאים שהמשאבים שמערכת Terraform תיצור או תעדכן תואמים לציפיות שלכם:
terraform plan
מתקנים את ההגדרות לפי הצורך.
-
מריצים את הפקודה הבאה ומזינים
yesבהודעה שמופיעה, כדי להחיל את הגדרות Terraform:terraform apply
ממתינים עד שב-Terraform תוצג ההודעה "Apply complete!".
- פותחים את Google Cloud הפרויקט כדי לראות את התוצאות. במסוף Google Cloud , נכנסים למשאבים בממשק המשתמש כדי לוודא שהם נוצרו או עודכנו ב-Terraform.