
העברה מ-Amazon Redshift ל-BigQuery: סקירה כללית
במסמך הזה מוסבר איך לבצע מיגרציה מ-Amazon Redshift ל-BigQuery, עם דגש על הנושאים הבאים:
- אסטרטגיות להעברה
- שיטות מומלצות לאופטימיזציה של שאילתות ולמידול נתונים
- טיפים לפתרון בעיות
- הנחיות לאימוץ על ידי משתמשים
המטרות של המסמך הזה הן:
- אני רוצה לקבל הנחיות כלליות לארגונים שעוברים מ-Amazon Redshift ל-BigQuery, כולל עזרה בשינוי הגישה לצינורות הנתונים הקיימים כדי להפיק את המרב מ-BigQuery.
- לעזור לך להשוות בין הארכיטקטורות של BigQuery ו-Amazon Redshift כדי שתוכל לקבוע איך להטמיע תכונות ויכולות קיימות במהלך המיגרציה. המטרה היא להציג לכם יכולות חדשות שזמינות לארגון שלכם דרך BigQuery, ולא למפות תכונות אחת לאחת עם Amazon Redshift.
המסמך הזה מיועד לאדריכלים ארגוניים, לאדמינים של מסדי נתונים, למפתחי אפליקציות ולמומחי אבטחת IT. המאמר מיועד למי שמכיר את Amazon Redshift.
אפשר גם להשתמש בתרגום SQL באצווה כדי להעביר את סקריפטים של SQL בכמות גדולה, או בתרגום SQL אינטראקטיבי כדי לתרגם שאילתות אד-הוק. שירותי התרגום של SQL תומכים באופן מלא ב-Amazon Redshift SQL.
משימות לפני ההעברה
כדי להבטיח שההעברה של מחסן הנתונים תצליח, מומלץ להתחיל לתכנן את אסטרטגיית ההעברה בשלב מוקדם בציר הזמן של הפרויקט. הגישה הזו מאפשרת לכם להעריך את התכונות שמתאימות לצרכים שלכם. Google Cloud
תכנון קיבולת
ב-BigQuery משתמשים במשבצות זמן כדי למדוד את תפוקת הניתוח. יחידת קיבולת של BigQuery היא יחידה קניינית של Google לקיבולת חישובית שנדרשת להרצת שאילתות SQL. מערכת BigQuery מחשבת באופן רציף כמה משבצות נדרשות לשאילתות בזמן שהן מופעלות, אבל היא מקצה משבצות לשאילתות על סמך מתזמן הוגן.
כשמתכננים את הקיבולת של משבצות BigQuery, אפשר לבחור בין מודלים התמחור הבאים:
- תמחור על פי דרישה: בשיטת התמחור הזו, BigQuery מחייב על מספר הבייטים שעברו עיבוד (גודל הנתונים), כך שאתם משלמים רק על השאילתות שאתם מריצים. למידע נוסף על האופן שבו BigQuery קובע את גודל הנתונים, אפשר לעיין במאמר בנושא חישוב גודל הנתונים. יחידות הקיבולת (Slot) קובעות את יכולת החישוב הבסיסית, ולכן אתם יכולים לשלם על השימוש ב-BigQuery בהתאם למספר יחידות הקיבולת שאתם צריכים (במקום לפי בייטים שעברו עיבוד). כברירת מחדל, כלGoogle Cloud הפרויקטים מוגבלים ל-2,000 משבצות לכל היותר. יכול להיות ש-BigQuery יחרוג מהמגבלה הזו כדי להאיץ את השאילתות, אבל אין הבטחה לכך.
- תמחור לפי קיבולת: בתמחור לפי קיבולת, אתם רוכשים מקומות שמורים של יחידות קיבולת של BigQuery (מינימום 100) במקום לשלם על בייטים שעוברים עיבוד בשאילתות שאתם מריצים. אנחנו ממליצים על תמחור לפי קיבולת לעומסי עבודה של מחסני נתונים ארגוניים, שבדרך כלל כוללים הרבה שאילתות מקבילות של דיווח ושל extract-load-transform (ELT) עם צריכה צפויה.
כדי להעריך את מספר הסלוטים, מומלץ להגדיר מעקב אחרי BigQuery באמצעות Cloud Monitoring ולנתח את יומני הביקורת באמצעות BigQuery. אתם יכולים להשתמש ב-Data Studio (כאן מופיעה דוגמה של קוד פתוח למרכז בקרה של Data Studio) או ב-Looker כדי להציג בתרשימים את נתוני יומן הביקורת של BigQuery, במיוחד את השימוש במשבצות (slots) בשאילתות ובפרויקטים. אפשר גם להשתמש בנתונים של טבלאות המערכת של BigQuery כדי לעקוב אחרי ניצול משבצות בכל המשימות וההזמנות (כאן אפשר לראות דוגמה של מרכז בקרה ב-Data Studio בקוד פתוח). מעקב וניתוח קבועים של ניצול המשבצות עוזרים להעריך כמה משבצות בסך הכול הארגון צריך ככל שהוא מתפתח ב- Google Cloud.
לדוגמה, נניח שבהתחלה שריינתם 4,000 משבצות זמן ב-BigQuery כדי להריץ 100 שאילתות ברמת מורכבות בינונית בו-זמנית. אם אתם מבחינים בזמני המתנה ארוכים בתוכניות הביצוע של השאילתות, ובמכשירי הבקרה מוצג ניצול גבוה של משבצות, יכול להיות שאתם צריכים משבצות נוספות ב-BigQuery כדי לתמוך בעומסי העבודה. אם אתם רוצים לרכוש בעצמכם חריצי אחסון באמצעות התחייבויות שנתיות או תלת-שנתיות, אתם יכולים להתחיל להשתמש בהזמנות של BigQuery באמצעותGoogle Cloud המסוף או כלי שורת הפקודה bq. לפרטים נוספים על ניהול עומסי עבודה, הפעלת שאילתות וארכיטקטורת BigQuery, אפשר לעיין במאמר Migration to Google Cloud: An in-depth view.
אבטחה ב Google Cloud
בקטעים הבאים מתוארים אמצעי אבטחה נפוצים ב-Amazon Redshift ומוסבר איך אפשר לוודא שמחסן הנתונים שלכם יישאר מוגן בסביבתGoogle Cloud .
ניהול זהויות והרשאות גישה
הגדרת בקרת גישה ב-Amazon Redshift כוללת כתיבה של כללי מדיניות להרשאות ב-Amazon Redshift API וצירוף שלהם לזהויות בניהול הזהויות והרשאות הגישה (IAM). ההרשאות של Amazon Redshift API מספקות גישה ברמת האשכול, אבל לא מספקות רמות גישה פרטניות יותר מהאשכול. אם אתם רוצים גישה מפורטת יותר למשאבים כמו טבלאות או תצוגות, אתם יכולים להשתמש בחשבונות משתמשים במסד הנתונים של Amazon Redshift.
ב-BigQuery נעשה שימוש ב-IAM כדי לנהל את הגישה למשאבים ברמה פרטנית יותר. סוגי המשאבים שזמינים ב-BigQuery הם ארגונים, פרויקטים, מערכי נתונים, טבלאות, עמודות ותצוגות. בהיררכיית מדיניות IAM, מערכי נתונים הם משאבי צאצא של פרויקטים. טבלה מקבלת הרשאות בירושה ממערך הנתונים שמכיל אותה.
כדי להעניק גישה למשאב, מקצים תפקיד אחד או יותר ב-IAM למשתמש, לקבוצה או לחשבון שירות. תפקידים בארגון ופרויקט משפיעים על היכולת להריץ משימות או לנהל את הפרויקט, בעוד שתפקידים במערך נתונים משפיעים על היכולת לגשת לנתונים בתוך פרויקט או לשנות אותם.
ב-IAM יש את סוגי התפקידים הבאים:
- תפקידים מוגדרים מראש, שמיועדים לתמיכה בתרחישים נפוצים ובדפוסי בקרת גישה.
- תפקידים בהתאמה אישית, שמאפשרים גישה פרטנית בהתאם לרשימת ההרשאות שנבחרו.
ב-IAM, BigQuery מספק בקרת גישה ברמת הטבלה. ההרשאות ברמת הטבלה קובעות אילו משתמשים, קבוצות וחשבונות שירות יכולים לגשת לטבלה או לתצוגה. אתם יכולים לתת למשתמש גישה לטבלאות או לתצוגות ספציפיות בלי לתת לו גישה למערך הנתונים המלא. כדי להגדיר גישה מפורטת יותר, אפשר גם להטמיע אחד או יותר ממנגנוני האבטחה הבאים:
- בקרת גישה ברמת העמודה, שמאפשרת גישה מדויקת לעמודות עם נתונים רגישים באמצעות תגי מדיניות, או סיווג מבוסס-נתונים.
- הסתרת נתונים דינמית ברמת העמודה, שמאפשרת להסתיר באופן סלקטיבי נתונים בעמודה עבור קבוצות של משתמשים, תוך שמירה על הגישה לעמודה.
- אבטחה ברמת השורה, שמאפשרת לסנן נתונים ולגשת לשורות ספציפיות בטבלה על סמך תנאים של משתמשים שעומדים בדרישות.
הצפנה מלאה של הדיסק
בנוסף לניהול זהויות וגישה, הצפנת נתונים מוסיפה שכבת הגנה נוספת על הנתונים. במקרה של חשיפת נתונים, אי אפשר לקרוא נתונים מוצפנים.
ב-Amazon Redshift, ההצפנה של נתונים במנוחה ושל נתונים במעבר לא מופעלת כברירת מחדל. צריך להפעיל באופן מפורש את ההצפנה של נתונים במצב מנוחה כשמפעילים אשכול או כשמשנים אשכול קיים כדי להשתמש בהצפנה של AWS Key Management Service. צריך גם להפעיל באופן מפורש את ההצפנה של נתונים במעבר.
כל הנתונים ב-BigQuery מוצפנים כברירת מחדל במצב מנוחה ובזמן העברה, ללא קשר למקור או לכל תנאי אחר, ואי אפשר להשבית את ההצפנה. בנוסף, BigQuery תומך במפתחות הצפנה בניהול הלקוח (CMEK) אם רוצים לשלוט במפתחות הצפנה ולנהל אותם ב-Cloud Key Management Service.
מידע נוסף על הצפנה ב- Google Cloudזמין במסמכים טכניים בנושא הצפנת נתונים במנוחה והצפנת נתונים במעבר.
נתונים במעבר ב- Google Cloud מוצפנים ומאומתים כשהם מועברים אל מחוץ לגבולות הפיזיים שבשליטת Google או מטעמה. בתוך הגבולות האלה, הנתונים במעבר מאומתים בדרך כלל אבל לא בהכרח מוצפנים.
מניעת אובדן נתונים
דרישות התאימות עשויות להגביל את הנתונים שאפשר לאחסן ב-Google Cloud. אפשר להשתמש ב-Sensitive Data Protection כדי לסרוק את טבלאות BigQuery ולזהות ולסווג מידע אישי רגיש. אם המערכת מזהה מידע אישי רגיש, אפשר להשתמש בשיטות להסרת פרטים מזהים של Sensitive Data Protection כדי להסתיר, למחוק או להצפין את הנתונים האלה.
העברה אל Google Cloud: העקרונות הבסיסיים
בקטע הזה מוסבר איך להשתמש בכלים ובצינורות כדי להקל על ההעברה.
כלים להעברה
שירות העברת הנתונים ל-BigQuery מספק כלי אוטומטי להעברת סכימה ונתונים מ-Amazon Redshift ל-BigQuery באופן ישיר. בטבלה הבאה מפורטים כלים נוספים שיעזרו לכם לבצע מיגרציה מ-Amazon Redshift ל-BigQuery:
| כלי | מטרה |
|---|---|
| שירות העברת נתונים ל-BigQuery | השירות המנוהל במלואו הזה מאפשר לבצע העברה אוטומטית של נתונים מ-Amazon Redshift ל-BigQuery. |
| Storage Transfer Service | שירות מנוהל מלא שמאפשר לייבא במהירות נתונים מ-Amazon S3 ל-Cloud Storage ולהגדיר לוח זמנים חוזר להעברת נתונים. |
gcloud |
העתקת קבצים מ-Amazon S3 ל-Cloud Storage באמצעות כלי שורת הפקודה הזה. |
| כלי שורת הפקודה של BigQuery | אפשר לקיים אינטראקציה עם BigQuery באמצעות כלי שורת הפקודה הזה. אינטראקציות נפוצות כוללות יצירת סכימות של טבלאות ב-BigQuery, טעינת נתונים מ-Cloud Storage לטבלאות והרצת שאילתות. |
| ספריות לקוח של Cloud Storage | העתקת קבצים מ-Amazon S3 ל-Cloud Storage באמצעות כלי בהתאמה אישית שבניתם על בסיס ספריית הלקוח של Cloud Storage. |
| ספריות לקוח של BigQuery | אינטראקציה עם BigQuery באמצעות כלי מותאם אישית שנוצר על בסיס ספריית הלקוח של BigQuery. |
| מתזמן השאילתות של BigQuery | אפשר לתזמן שאילתות SQL חוזרות באמצעות התכונה המובנית הזו של BigQuery. |
| Managed Service for Apache Airflow | תזמור טרנספורמציות ומשימות טעינה ב-BigQuery באמצעות סביבת Apache Airflow מנוהלת. |
| Apache Sqoop | שליחת משימות Hadoop באמצעות Sqoop ומנהל התקן JDBC של Amazon Redshift כדי לחלץ נתונים מ-Amazon Redshift ל-HDFS או ל-Cloud Storage. Sqoop פועל בסביבת Managed Service for Apache Spark. |
מידע נוסף על השימוש בשירות העברת הנתונים ל-BigQuery זמין במאמר בנושא העברת סכימה ונתונים מ-Amazon Redshift.
העברה באמצעות צינורות עיבוד נתונים
העברת הנתונים מ-Amazon Redshift ל-BigQuery יכולה להתבצע בדרכים שונות, בהתאם לכלים הזמינים להעברה. הרשימה בקטע הזה היא לא רשימה מלאה, אבל היא נותנת מושג לגבי דפוסי צינורות הנתונים השונים שזמינים כשמעבירים את הנתונים.
למידע נוסף על העברת נתונים ל-BigQuery באמצעות צינורות נתונים, אפשר לקרוא את המאמר בנושא העברת צינורות נתונים.
חילוץ וטעינה (EL)
אפשר לבצע אוטומציה מלאה של צינור EL באמצעות שירות העברת הנתונים ל-BigQuery, שיכול להעתיק באופן אוטומטי את הסכימות והנתונים של הטבלאות מאשכול Amazon Redshift ל-BigQuery. אם אתם רוצים יותר שליטה בשלבים של צינור הנתונים, אתם יכולים ליצור צינור באמצעות האפשרויות שמתוארות בקטעים הבאים.
שימוש בחילוצי קבצים של Amazon Redshift
- ייצוא נתונים מ-Amazon Redshift אל Amazon S3
כדי להעתיק נתונים מ-Amazon S3 ל-Cloud Storage, אפשר להשתמש באחת מהאפשרויות הבאות:
כדי לטעון נתונים מ-Cloud Storage ל-BigQuery, אפשר להשתמש באחת מהאפשרויות הבאות:
שימוש בחיבור JDBC של Amazon Redshift
אפשר להשתמש בכל אחד מהמוצרים הבאים Google Cloud כדי לייצא נתונים מ-Amazon Redshift באמצעות מנהל התקן Amazon Redshift JDBC:
-
- תבנית שסופקה על ידי Google: JDBC ל-BigQuery
Managed Service for Apache Spark
משתמשים ב-Sqoop ובמנהל התקן Amazon Redshift JDBC כדי לחלץ נתונים מ-Amazon Redshift ל-Cloud Storage
חילוץ, טרנספורמציה וטעינה (ETL)
אם רוצים לבצע טרנספורמציה של חלק מהנתונים לפני הטעינה שלהם ל-BigQuery, צריך לפעול לפי אותן המלצות לגבי צינורות שמתוארות בקטע שליפה וטעינה (EL), ולהוסיף שלב נוסף לטרנספורמציה של הנתונים לפני הטעינה שלהם ל-BigQuery.
שימוש בחילוצי קבצים של Amazon Redshift
כדי להעתיק נתונים מ-Amazon S3 ל-Cloud Storage, אפשר להשתמש באחת מהאפשרויות הבאות:
אפשר להשתמש באחת מהאפשרויות הבאות כדי להמיר את הנתונים ואז לטעון אותם ל-BigQuery:
-
- קריאה מ-Cloud Storage
- כתיבה ל-BigQuery
- תבנית שסופקה על ידי Google: Cloud Storage Text to BigQuery
שימוש בחיבור JDBC של Amazon Redshift
אפשר להשתמש בכל אחד מהמוצרים שמתוארים בקטע חילוץ וטעינה (EL), ולהוסיף שלב נוסף כדי לבצע טרנספורמציה של הנתונים לפני הטעינה ל-BigQuery. משנים את צינור הנתונים כדי להוסיף שלב אחד או יותר להמרת הנתונים לפני הכתיבה ל-BigQuery.
-
- משכפלים את קוד התבנית JDBC to BigQuery ומשנים את התבנית כדי להוסיף Apache Beam transforms.
-
- לבצע טרנספורמציה של הנתונים באמצעות אחד מתוספי CDAP.
חילוץ, טעינה וטרנספורמציה (ELT)
אפשר להשתמש ב-BigQuery כדי לשנות את הנתונים, באמצעות אחת מהאפשרויות של Extract and Load (EL) כדי לטעון את הנתונים לטבלת ביניים. לאחר מכן, משנים את הנתונים בטבלת הביניים באמצעות שאילתות SQL שכותבות את הפלט שלהן לטבלת הייצור הסופית.
סימון נתונים שהשתנו (CDC)
לכידת שינויים בנתונים היא אחת מכמה תבניות עיצוב תוכנה שמשמשות למעקב אחרי שינויים בנתונים. היא משמשת לעיתים קרובות במחסני נתונים, כי מחסן הנתונים משמש לאיסוף ולמעקב אחרי נתונים ושינויים שלהם ממערכות מקור שונות לאורך זמן.
כלים של שותפים להעברת נתונים
יש כמה ספקים בתחום החילוץ, הטרנספורמציה והטעינה (ETL). באתר השותפים של BigQuery אפשר למצוא רשימה של שותפים מרכזיים והפתרונות שהם מספקים.
מיגרציה אל Google Cloud: מבט מעמיק
בקטע הזה מוסבר איך הארכיטקטורה, הסכימה והניב של SQL במחסן הנתונים משפיעים על ההעברה.
השוואה בין ארכיטקטורות
גם BigQuery וגם Amazon Redshift מבוססים על ארכיטקטורה של עיבוד מקבילי מסיבי (MPP). השאילתות מפוזרות בין כמה שרתים כדי להאיץ את הביצוע שלהן. בנוגע לארכיטקטורת המערכת, ההבדל העיקרי בין Amazon Redshift לבין BigQuery הוא באופן שבו הנתונים מאוחסנים ובאופן שבו השאילתות מבוצעות. ב-BigQuery, החומרה וההגדרות הבסיסיות מופשטות, והאחסון והמחשוב מאפשרים למחסן הנתונים שלכם לגדול בלי שתצטרכו להתערב.
מחשוב, זיכרון ואחסון
ב-Amazon Redshift, המעבד (CPU), הזיכרון והאחסון בדיסק קשורים זה לזה באמצעות צמתי מחשוב, כמו שמוצג בתרשים הזה מתוך מסמכי התיעוד של Amazon Redshift. הביצועים של האשכול וקיבולת האחסון נקבעים לפי הסוג והכמות של צמתי החישוב, ושניהם צריכים להיות מוגדרים. כדי לשנות את נפח האחסון או את כוח המחשוב, צריך לשנות את הגודל של האשכול בתהליך (שנמשך כמה שעות, או עד יומיים או יותר) שיוצר אשכול חדש לגמרי ומעתיק את הנתונים. ב-Amazon Redshift יש גם צמתים מסוג RA3 עם אחסון מנוהל שעוזרים להפריד בין מחשוב לאחסון. הצומת הגדול ביותר בקטגוריה RA3 מוגבל ל-64TB של אחסון מנוהל לכל צומת.
מראש, BigQuery לא משלב בין מחשוב, זיכרון ואחסון, אלא מתייחס לכל אחד מהם בנפרד.
החישוב ב-BigQuery מוגדר על ידי יחידות קיבולת, שהן יחידות של יכולת חישובית שנדרשות להרצת שאילתות. Google מנהלת את כל התשתית שמשבצת מאגדת, כך שכל מה שצריך לעשות הוא לבחור את מספר המשבצות המתאים לעומסי העבודה שלכם ב-BigQuery. כדי להחליט כמה משבצות תקנו למחסן הנתונים, תוכלו להיעזר בתכנון הקיבולת. הזיכרון של BigQuery מסופק על ידי שירות מבוזר מרוחק שמחובר למשבצות חישוב באמצעות רשת פטה-ביט של Google, והכול מנוהל על ידי Google.
גם BigQuery וגם Amazon Redshift משתמשים באחסון עמודות, אבל ב-BigQuery נעשה שימוש בוריאציות ובשיפורים של אחסון עמודות. בזמן שהעמודות מוצפנות, נשמרים נתונים סטטיסטיים שונים לגבי הנתונים, והמערכת משתמשת בהם מאוחר יותר במהלך ביצוע השאילתה כדי ליצור תוכניות אופטימליות ולבחור את האלגוריתם היעיל ביותר בזמן הריצה. ב-BigQuery, הנתונים מאוחסנים במערכת הקבצים המבוזרת של Google, שבה הם נדחסים, מוצפנים, משוכפלים ומפוזרים באופן אוטומטי. כל זה קורה בלי להשפיע על כוח המחשוב שזמין לשאילתות שלכם. הפרדה בין האחסון לבין המחשוב מאפשרת להגדיל את נפח האחסון עד לעשרות פטה-בייט בצורה חלקה, בלי שיידרשו משאבי מחשוב יקרים נוספים. יש גם מספר יתרונות נוספים להפרדה בין מחשוב לאחסון.
הגדלה או הקטנה של הקיבולת
כשנפח האחסון או כוח החישוב מוגבלים, צריך לשנות את הגודל של אשכולות Amazon Redshift על ידי שינוי הכמות או הסוגים של הצמתים באשכול.
כשמשנים את הגודל של אשכול Amazon Redshift, יש שתי גישות:
- שינוי גודל קלאסי: Amazon Redshift יוצר אשכול שאליו מועתקים הנתונים. התהליך הזה יכול להימשך כמה שעות, או עד יומיים או יותר אם מדובר בכמויות גדולות של נתונים.
- שינוי גודל דינמי: אם משנים רק את מספר הצמתים, השאילתות מושהות באופן זמני והחיבורים נשארים פתוחים אם אפשר. במהלך פעולת השינוי של הגודל, האשכול הוא לקריאה בלבד. בדרך כלל שינוי הגודל הגמיש נמשך 10 עד 15 דקות, אבל יכול להיות שהוא לא יהיה זמין לכל ההגדרות.
מכיוון ש-BigQuery היא פלטפורמה כשירות (PaaS), אתם צריכים לדאוג רק למספר המשבצות ב-BigQuery שאתם רוצים לשריין לארגון שלכם. אתם שומרים יחידות קיבולת (slot) ב-BigQuery בהזמנות, ואז מקצים פרויקטים להזמנות האלה. הוראות להגדרת השמירה הזו מופיעות במאמר תכנון הקיבולת.
ביצוע שאילתה
מנוע הביצוע של BigQuery דומה לזה של Amazon Redshift בכך ששניהם מתזמנים את השאילתה על ידי פירוק שלה לשלבים (תוכנית שאילתה), ביצוע השלבים (במקביל, אם אפשר) ואז הרכבת התוצאות. Amazon Redshift יוצר תוכנית שאילתה סטטית, אבל BigQuery לא עושה זאת כי הוא מבצע אופטימיזציה דינמית של תוכניות שאילתה בזמן שהשאילתה מופעלת. ב-BigQuery, ערבוב הנתונים מתבצע באמצעות שירות הזיכרון המרוחק, ואילו ב-Amazon Redshift, ערבוב הנתונים מתבצע באמצעות הזיכרון של צומת המחשוב המקומי. למידע נוסף על אחסון נתונים זמניים משלבים שונים בתוכנית השאילתות ב-BigQuery, אפשר לעיין במאמר ביצוע שאילתות בזיכרון ב-Google BigQuery.
ניהול עומסי עבודה (workload) ב-BigQuery
BigQuery מציע את האמצעים הבאים לניהול עומסי עבודה (WLM):
- שאילתות אינטראקטיביות, שמופעלות בהקדם האפשרי (זו הגדרת ברירת המחדל).
- שאילתות באצווה, שמוכנסות לתור בשמכם ומתחילות לפעול ברגע שמשאבים פנויים זמינים במאגר המשאבים המשותפים של BigQuery.
הזמנות של יחידות קיבולת (Slot) באמצעות תמחור לפי קיבולת. במקום לשלם על שאילתות על פי דרישה, אתם יכולים ליצור ולנהל באופן דינמי קבוצות של משבצות שנקראות reservations ולהקצות פרויקטים, תיקיות או ארגונים ל-reservations האלה. כדי לצמצם את העלויות, אפשר לרכוש התחייבויות לשימוש במשבצות זמן ב-BigQuery (החל מ-100 משבצות זמן) בהתחייבות גמישה, חודשית או שנתית. כברירת מחדל, שאילתות שמופעלות בהזמנה משתמשות אוטומטית במשבצות פנויות מהזמנות אחרות.
בדוגמה הבאה, נניח שרכשתם קיבולת התחייבות כוללת של 1,000 משבצות שמשותפות בין שלושה סוגים של עומסי עבודה: מדעי הנתונים, ELT ובינה עסקית (BI). כדי לתמוך בעומסי העבודה האלה, אפשר ליצור את ההזמנות הבאות:
- אפשר ליצור את ההזמנה ds עם 500 משבצות, ולהקצות את כל הפרויקטים שלGoogle Cloud data science להזמנה הזו.
- אפשר ליצור את ההזמנה elt עם 300 משבצות, ולהקצות לה את הפרויקטים שבהם אתם משתמשים לעומסי עבודה של ELT.
- אתם יכולים ליצור את ההזמנה bi עם 200 משבצות, ולהקצות לה פרויקטים שמחוברים לכלי ה-BI שלכם.
ההגדרה הזו מוצגת בתרשים הבא:
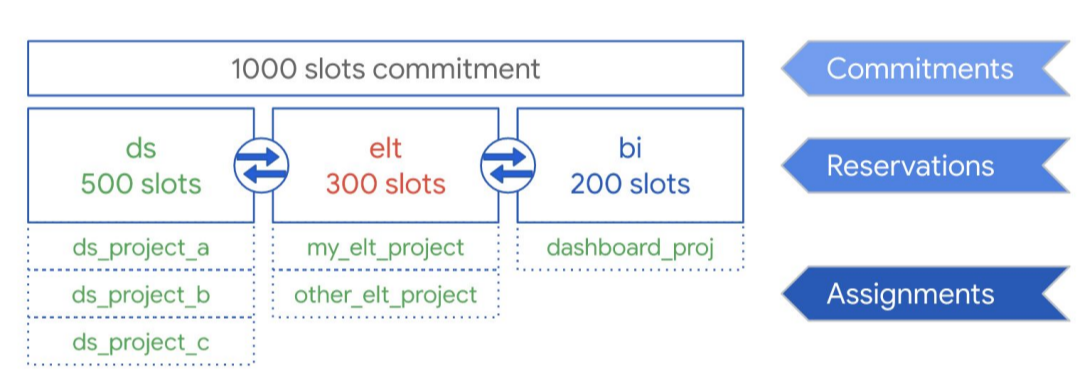
במקום להקצות את ההזמנות לעומסי העבודה של הארגון, למשל לייצור ולבדיקות, אתם יכולים להקצות את ההזמנות לצוותים או למחלקות ספציפיים, בהתאם לתרחיש השימוש.
מידע נוסף זמין במאמר ניהול עומסי עבודה באמצעות הזמנות.
ניהול עומסי עבודה (workload) ב-Amazon Redshift
ב-Amazon Redshift יש שני סוגים של ניהול עומסי עבודה (WLM):
- אוטומטי: עם WLM אוטומטי, Amazon Redshift מנהל את מספר השאילתות המקבילות ואת הקצאת הזיכרון. נוצרות עד שמונה תורים עם מזהי מחלקת השירות 100 עד 107. התכונה 'ניהול עומסי עבודה אוטומטי' קובעת את כמות המשאבים שנדרשת לשאילתות ומשנה את מספר הפעולות המקבילות על סמך עומס העבודה. מידע נוסף זמין במאמר בנושא עדיפות של שאילתות.
- ידני: לעומת זאת, ב-WLM ידני צריך לציין ערכים של מקבילות שאילתות והקצאת זיכרון. ברירת המחדל של WLM ידני היא חמש שאילתות בו-זמניות, והזיכרון מחולק באופן שווה בין כל חמש השאילתות.
כשמפעילים את התכונה התאמת נפח אחסון דינמית, מערכת Amazon Redshift מוסיפה באופן אוטומטי נפח אחסון נוסף לאשכול כשצריך לעבד עלייה במספר השאילתות המקבילות לקריאה. יש שיקולים אזוריים ושיקולים שקשורים לשאילתות לגבי שינוי גודל של מספר הפעולות שמתבצעות בו-זמנית. מידע נוסף זמין במאמר בנושא מועמדים להרחבת מספר הפעולות בו-זמנית.
הגדרות של מערכי נתונים וטבלאות
ב-BigQuery יש כמה דרכים להגדיר את הנתונים והטבלאות, כמו חלוקה למחיצות, אשכולות ומיקום נתונים. ההגדרות האלה יכולות לעזור לכם לתחזק טבלאות גדולות, לצמצם את נפח הנתונים הכולל ואת זמן התגובה של השאילתות, וכך לשפר את היעילות התפעולית של עומסי העבודה של הנתונים.
חלוקה למחיצות
טבלה מחולקת למחיצות (Partitions) היא טבלה שמחולקת לפלחים, שנקראים מחיצות, כדי להקל על הניהול והשאילתות של הנתונים. בדרך כלל, המשתמשים מפצלים טבלאות גדולות למחיצות קטנות יותר, כשכל מחיצה מכילה נתונים של יום אחד. ניהול המחיצות הוא גורם חשוב שמשפיע על הביצועים והעלויות של BigQuery כשמריצים שאילתות על טווח תאריכים ספציפי, כי הוא עוזר ל-BigQuery לסרוק פחות נתונים לכל שאילתה.
יש שלושה סוגים של חלוקה למחיצות ב-BigQuery:
- טבלאות שמחולקות למחיצות לפי זמני הטמעת הנתונים: הטבלאות מחולקות למחיצות על סמך זמני הטמעת הנתונים.
- טבלאות עם חלוקה למחיצות לפי עמודה:
הטבלאות מחולקות למחיצות על סמך עמודה מסוג
TIMESTAMPאוDATE. - טבלאות שמחולקות למחיצות לפי טווח של מספרים שלמים: הטבלאות מחולקות למחיצות על סמך עמודה של מספרים שלמים.
טבלה עם חלוקה למחיצות לפי עמודה מבטלת את הצורך לשמור על מודעות למחיצות בנפרד מהסינון הקיים של הנתונים בעמודה המקושרת. נתונים שנכתבים בטבלה מבוססת-עמודות עם חלוקה למחיצות לפי זמן מועברים אוטומטית למחיצה המתאימה על סמך ערך הנתונים. באופן דומה, שאילתות שמבטאות מסננים בעמודת החלוקה למחיצות יכולות להקטין את כמות הנתונים הכוללת שנסרקת, וכך לשפר את הביצועים ולהקטין את עלות השאילתה בשאילתות לפי דרישה.
חלוקה למחיצות (partitioning) ב-BigQuery שמבוססת על עמודות דומה לחלוקה למחיצות שמבוססת על עמודות ב-Amazon Redshift, אבל יש הבדל קל בסיבה לשימוש בה. ב-Amazon Redshift נעשה שימוש בהפצת מפתחות מבוססת-עמודות כדי לנסות לשמור נתונים קשורים יחד בתוך אותו צומת חישוב, ובסופו של דבר למזער את ערבוב הנתונים שמתרחש במהלך הצטרפות וצבירה. ב-BigQuery, האחסון מופרד מהמחשוב, ולכן נעשה שימוש בחלוקה למחיצות לפי עמודות כדי לצמצם את כמות הנתונים שהמשבצות קוראות מהדיסק.
אחרי שעובדי המשבצות קוראים את הנתונים שלהם מהדיסק, מערכת BigQuery יכולה לקבוע באופן אוטומטי פיצול נתונים אופטימלי יותר ולבצע במהירות חלוקה מחדש של הנתונים באמצעות שירות ה-Shuffle בזיכרון של BigQuery.
מידע נוסף זמין במאמר מבוא לטבלאות עם מחיצות.
מפתחות לאשכולות ולמיון
ב-Amazon Redshift אפשר לציין עמודות בטבלה כמפתחות מיון מורכבים או משולבים. ב-BigQuery, אפשר לציין מפתחות מיון מורכבים על ידי אשכול של הטבלה. טבלאות מקובצות ב-BigQuery משפרות את הביצועים של השאילתות כי נתוני הטבלה ממוינים אוטומטית על סמך התוכן של עד ארבע עמודות שצוינו בסכימה של הטבלה. העמודות האלה משמשות למיקום משותף של נתונים קשורים. סדר העמודות לאשכולות שאתם מציינים חשוב כי הוא קובע את סדר המיון של הנתונים.
האשכולות יכולים לשפר את הביצועים של סוגים מסוימים של שאילתות, כמו שאילתות שמשתמשות בתנאי סינון ושאילתות שמצטברות נתונים. כשמשימת שאילתה או משימת טעינה כותבות נתונים לטבלה מסודרת באשכולות, BigQuery ממיין את הנתונים באופן אוטומטי באמצעות הערכים בעמודות האשכולות. הערכים האלה משמשים לארגון הנתונים למספר בלוקים באחסון של BigQuery. כששולחים שאילתה שמכילה פסקה שמסננת נתונים על סמך עמודות האשכול, BigQuery משתמש בבלוקים הממוינים כדי למנוע סריקות של נתונים מיותרים.
באופן דומה, כששולחים שאילתה שמצטברת נתונים על סמך הערכים בעמודות האשכול, הביצועים משתפרים כי הבלוקים הממוינים ממקמים שורות עם ערכים דומים.
כדאי להשתמש באשכולות בנסיבות הבאות:
- מפתחות מיון מורכבים מוגדרים בטבלאות של Amazon Redshift.
- הסינון או הצבירה מוגדרים לעמודות מסוימות בשאילתות.
כשמשתמשים גם באשכולות וגם בחלוקה למחיצות, אפשר לחלק את הנתונים למחיצות לפי עמודה של תאריך, חותמת זמן או מספר שלם, ואז ליצור אשכולות לפי קבוצה אחרת של עמודות (עד ארבע עמודות בסך הכול). במקרה כזה, הנתונים בכל מחיצה מקובצים על סמך הערכים של עמודות האשכול.
כשמציינים מפתחות מיון בטבלאות ב-Amazon Redshift, המערכת מפעילה את המיון באופן אוטומטי באמצעות יכולת החישוב של האשכול שלכם, בהתאם לעומס על המערכת. יכול להיות שתצטרכו להריץ את הפקודה VACUUM באופן ידני אם אתם רוצים למיין את נתוני הטבלה באופן מלא בהקדם האפשרי, למשל אחרי טעינה של כמות גדולה של נתונים. BigQuery מטפל במיון הזה באופן אוטומטי ולא משתמש במשבצות שהוקצו לכם ב-BigQuery, ולכן הוא לא משפיע על הביצועים של אף אחת מהשאילתות שלכם.
מידע נוסף על עבודה עם טבלאות מקובצות זמין במאמר מבוא לטבלאות מקובצות.
מפתחות הפצה
מערכת Amazon Redshift משתמשת במפתחות חלוקה כדי לבצע אופטימיזציה של המיקום של בלוקי נתונים, במטרה להריץ את השאילתות. ב-BigQuery לא משתמשים במפתחות חלוקה כי המערכת קובעת ומוסיפה שלבים באופן אוטומטי בתוכנית השאילתות (בזמן שהשאילתה פועלת) כדי לשפר את חלוקת הנתונים בין העובדים של השאילתה.
מקורות חיצוניים
אם אתם משתמשים ב-Amazon Redshift Spectrum כדי לשלוח שאילתות לנתונים ב-Amazon S3, אתם יכולים להשתמש באופן דומה בתכונת מקור הנתונים החיצוני של BigQuery כדי לשלוח שאילתות לנתונים ישירות מקבצים ב-Cloud Storage.
בנוסף להרצת שאילתות על נתונים ב-Cloud Storage, BigQuery מציע פונקציות של שאילתות מאוחדות להרצת שאילתות ישירות מהמוצרים הבאים:
- Cloud SQL (מערכת מנוהלת לחלוטין של MySQL או PostgreSQL)
- Bigtable (מערכת NoSQL מנוהלת)
- Google Drive (CSV, JSON, Avro, Sheets)
אחסון ועיבוד נתונים באופן מקומי
אפשר ליצור מערכי נתונים ב-BigQuery במיקומים אזוריים ובמיקומים במספר אזורים, בעוד שב-Amazon Redshift יש רק מיקומים אזוריים. מערכת BigQuery קובעת את המיקום להרצת עבודות הטעינה, השאילתות או החילוץ על סמך מערכי הנתונים שאליהם מתייחסת הבקשה. במאמר בנושא שיקולים לגבי מיקום ב-BigQuery יש טיפים לעבודה עם מערכי נתונים אזוריים ומערכי נתונים במספר אזורים.
מיפוי סוגי נתונים ב-BigQuery
סוגי הנתונים ב-Amazon Redshift שונים מסוגי הנתונים ב-BigQuery. פרטים נוספים על סוגי הנתונים ב-BigQuery זמינים במסמכי העזרה הרשמיים.
BigQuery תומך גם בסוגי הנתונים הבאים, שאין להם מקבילה ישירה ב-Amazon Redshift:
השוואת SQL
GoogleSQL תומך בתאימות לתקן SQL 2011 ויש לו הרחבות שתומכות בשאילתות של נתונים מקוננים וחוזרים. Amazon Redshift SQL מבוסס על PostgreSQL, אבל יש כמה הבדלים שמפורטים במסמכי התיעוד של Amazon Redshift. השוואה מפורטת בין התחביר והפונקציות של Amazon Redshift לבין אלה של GoogleSQL זמינה במדריך לתרגום SQL של Amazon Redshift.
אתם יכולים להשתמש בכלי לתרגום SQL באצווה כדי להמיר סקריפטים וקוד SQL אחר מהפלטפורמה הנוכחית שלכם ל-BigQuery.
אחרי ההעברה
מכיוון שהעברתם סקריפטים שלא תוכננו לשימוש ב-BigQuery, אתם יכולים ליישם טכניקות לאופטימיזציה של ביצועי השאילתות ב-BigQuery. מידע נוסף זמין במאמר מבוא לאופטימיזציה של ביצועי שאילתות.
המאמרים הבאים
- הוראות מפורטות להעברת סכימה ונתונים מ-Amazon Redshift
- הוראות שלב אחרי שלב להעברת נתונים מ-Amazon Redshift ל-BigQuery באמצעות VPC