
הערכת המיגרציה
הכלי להערכת מיגרציה ל-BigQuery מאפשר לתכנן ולבדוק את המיגרציה של מחסן הנתונים הקיים ל-BigQuery. אתם יכולים להריץ את כלי ההערכה של ההעברה ל-BigQuery כדי ליצור דוח שמעריך את העלות של אחסון הנתונים ב-BigQuery, כדי לראות איך BigQuery יכול לבצע אופטימיזציה של עומס העבודה הקיים כדי לחסוך בעלויות, וכדי להכין תוכנית העברה שמפרטת את הזמן והמאמץ שנדרשים להשלמת ההעברה של מחסן הנתונים ל-BigQuery.
במאמר הזה מוסבר איך להשתמש בכלי להערכת מיגרציה של BigQuery ואיך לבדוק את תוצאות ההערכה. המסמך הזה מיועד למשתמשים שמכירים את מסוףGoogle Cloud ואת כלי התרגום של SQL בכמות גדולה.
לפני שמתחילים
כדי להכין ולהריץ הערכה של מיגרציה ל-BigQuery, פועלים לפי השלבים הבאים:
שליפת מטא נתונים ויומני שאילתות ממחסן הנתונים.
מעלים את המטא-נתונים ואת יומני השאילתות לקטגוריה של Cloud Storage.
אופציונלי: מריצים שאילתה על תוצאות ההערכה כדי למצוא מידע מפורט או ספציפי על ההערכה.
שליפת מטא נתונים ויומני שאילתות ממחסן הנתונים
כדי להכין את ההערכה עם ההמלצות, צריך גם מטא-נתונים וגם יומני שאילתות.
כדי לחלץ את המטא-נתונים ואת יומני השאילתות שנדרשים להרצת ההערכה, בוחרים את מחסן הנתונים:
Databricks
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
תהליך חילוץ המטא-נתונים לצורך הערכת Databricks מתחיל בהורדה של כלי החילוץ והרצתו בסביבת Databricks.
כלי החילוץ הוא מחברת שיוצרת ארכיון ZIP עם קבצים שמכילים ייצוג של מספר תצוגות של Databricks. התצוגות המפורטות מכילות את הנתונים שנדרשים להערכה.
הורדת כלי החילוץ
קישור להורדת המחברת מופיע בקטע 'הערכה' במסוףGoogle Cloud . הקבצים זמינים כארכיון ZIP, שמכיל את הפריטים הבאים:
- הנוטבוק לחילוץ
- סקריפטים של Python לכלי השירות שה-notebook מריץ במהלך תהליך החילוץ.
ייבוא והגדרה של כלי החילוץ
- מייבאים את קובץ ה-ZIP מהשלב הקודם באמצעות ממשק המשתמש של Databricks.
- אחרי הייבוא, פותחים את ה-notebook של החילוץ ומשלימים את כל השלבים שמסומנים בתווית Configuration (הגדרה).
האימות של המחברת הוא חלק משלבי ההגדרה. המחברת תומכת בשתי שיטות אימות של Databricks:
תצטרכו להשתמש באחת מהשיטות האלה כדי להמשיך לסעיף הבא. מומלץ להשתמש בחשבון שירות במקום ב-PAT אם האפשרות הזו זמינה, כי Databricks מחשיבה את אפשרות ה-PAT כמיושנת.
קבלת הנתונים לצורך הערכה
אחרי שמשלימים את כל שלבי ההגדרה, מחברת ה-Notebook מוכנה להרצה. כשהמחברת לחילוץ פעילה, משתמשים באפשרות 'הפעלת הכול' כדי להריץ את המחברת.
אם מדובר במערכות גדולות מאוד, הפעלת המחברת עשויה להימשך עד יום. במערכת טיפוסית עם כ-50,000 טבלאות, החילוץ נמשך פחות משעה.
אופציונלי: מעקב אחר ההתקדמות של מחברת החילוץ
מחברת החילוץ מספקת יומנים שמכילים מידע על ההתקדמות ועל שגיאות למטרות מעקב. הודעות היומן האחרונות של הפעלת מחברת נתונה מכילות מידע על מה שנשלף.
הביצוע של מחברת לא נעצר בשגיאה הראשונה, ולכן צריך לבדוק את השגיאות בשני שלבים:
- אחרי החילוץ, כדאי לבדוק את הסיכום כדי לראות את מספר השגיאות או אינדיקטורים אחרים לשגיאות. לדוגמה, אם נמצאו פחות נתונים מהצפוי. אם התוצאות נראות תקינות, אפשר לדלג על השלב הבא.
- מעתיקים את פלט היומן ושומרים אותו בקובץ טקסט.
השלמת תהליך החילוץ
אחרי שתהליך החילוץ במחברת יסתיים, תוכלו להוריד את התוצאות בלחיצה על לחצן ההורדה בקטע האחרון של המחברת.
פתית שלג
דרישות
כדי לחלץ מ-Snowflake מטא-נתונים ויומני שאילתות, צריך לעמוד בדרישות הבאות:
- מכונה שיכולה להתחבר למופעי Snowflake שלכם.
- חשבון Google Cloud עם קטגוריה של Cloud Storage לאחסון הנתונים.
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות. לחלופין, אפשר ליצור מערך נתונים של BigQuery כשיוצרים את משימת ההערכה באמצעות ממשק המשתמש של Google Cloud המסוף.
- משתמש Snowflake עם גישת
IMPORTED PRIVILEGESלמסד הנתוניםSnowflake. מומלץ ליצור משתמש עם אימות שמבוסס על צמד מפתחות.SERVICEכך אפשר לגשת לפלטפורמת הנתונים של Snowflake בצורה מאובטחת בלי ליצור אסימוני MFA.- כדי ליצור משתמש שירות חדש, פועלים לפי המדריך הרשמי של Snowflake. תצטרכו ליצור את זוג מפתחות ה-RSA ולהקצות את המפתח הציבורי למשתמש Snowflake.
- למשתמש השירות צריך להיות תפקיד
ACCOUNTADMIN, או שאדמין בחשבון צריך להקצות לו תפקיד עם הרשאותIMPORTED PRIVILEGESבמסד הנתוניםSnowflake. - במקום אימות באמצעות זוג מפתחות, אפשר להשתמש באימות שמבוסס על סיסמה. עם זאת, החל מאוגוסט 2025, Snowflake תדרוש אימות דו-שלבי מכל המשתמשים שמבוסס על סיסמה. כדי להשתמש בכלי החילוץ שלנו, צריך לאשר את ההתראה בדחיפה של MFA.
הפעלת הכלי dwh-migration-dumper
מורידים את כלי החילוץ של שורת הפקודה dwh-migration-dumper.
מורידים את קובץ SHA256SUMS.txt ומריצים את הפקודה הבאה כדי לוודא שקובץ ה-ZIP תקין:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
מחליפים את RELEASE_ZIP_FILENAME בשם קובץ ה-ZIP שהורדתם של מהדורת כלי החילוץ של שורת הפקודה dwh-migration-dumper – לדוגמה, dwh-migration-tools-v1.0.52.zip
התוצאה True מאשרת שהאימות של סכום הביקורת הצליח.
התוצאה False מציינת שגיאת אימות. מוודאים שקובצי ה-checksum וה-ZIP הורדו מאותה גרסת הפצה והוצבו באותה ספרייה.
לפרטים על השימוש בכלי dwh-migration-dumper, אפשר לעיין בדף יצירת מטא-נתונים.
אפשר להשתמש בכלי dwh-migration-dumper כדי לחלץ יומנים ומטא-נתונים ממחסן הנתונים של Snowflake כשני קובצי zip. מריצים את הפקודות הבאות במחשב עם גישה למחסן הנתונים של המקור כדי ליצור את הקבצים.
יוצרים את קובץ ה-ZIP של המטא-נתונים:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
יוצרים את קובץ ה-ZIP שמכיל את יומני השאילתות:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
מחליפים את מה שכתוב בשדות הבאים:
-
HOST_NAME: שם המארח של מופע Snowflake. -
USER_NAME: שם המשתמש שמשמש לחיבור למסד הנתונים, שצריכות להיות לו הרשאות גישה כמו שמפורט בקטע הדרישות. -
PRIVATE_KEY_PATH: הנתיב למפתח הפרטי של RSA שמשמש לאימות. -
PRIVATE_KEY_PASSWORD: (אופציונלי) הסיסמה שבה השתמשתם כשנוצר המפתח הפרטי של RSA. המאפיין הזה נדרש רק אם המפתח הפרטי מוצפן. -
ROLE_NAME: (אופציונלי, אבל מומלץ מאוד) תפקיד המשתמש בהרצת הכליdwh-migration-dumper– לדוגמה,ACCOUNTADMIN. למרות שבאופן טכני זה לא חובה אם לתפקיד ברירת המחדל יש הרשאות מספיקות, הגדרת תפקיד מבטיחה שלסשן תהיה גישה לסכימהSNOWFLAKE.ACCOUNT_USAGE. -
WAREHOUSE: המחסן ששימש להפעלת פעולות הגיבוי. אם יש לכם כמה מחסנים וירטואליים, אתם יכולים לציין כל מחסן להרצת השאילתה הזו. הפעלת השאילתה הזו עם הרשאות הגישה שמפורטות בקטע הדרישות מחלצת את כל הארטיפקטים של מחסן הנתונים בחשבון הזה. -
STARTING_DATE: (אופציונלי) משמש לציון תאריך ההתחלה בטווח תאריכים של יומני שאילתות, בפורמטYYYY-MM-DD. -
ENDING_DATE: (אופציונלי) משמש לציון תאריך הסיום בטווח התאריכים של יומני השאילתות, בפורמטYYYY-MM-DD.
אפשר גם ליצור כמה קובצי ZIP שמכילים יומני שאילתות שמתייחסים לתקופות לא חופפות, ולספק את כולם לצורך הערכה.
Hadoop / Cloudera
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
דרישות
כדי לחלץ מטא-נתונים מ-Cloudera, צריך את הדברים הבאים:
- מחשב שיכול להתחבר ל-Cloudera Manager API.
- חשבון Google Cloud עם קטגוריה של Cloud Storage לאחסון הנתונים.
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות. לחלופין, אפשר ליצור מערך נתונים ב-BigQuery כשיוצרים את משימת ההערכה.
הפעלת הכלי dwh-migration-dumper
מורידים את כלי החילוץ של שורת הפקודה
dwh-migration-dumper.מורידים את קובץ
SHA256SUMS.txt.בסביבת שורת הפקודה, בודקים שהמיקוד נכון:
sha256sum --check SHA256SUMS.txt
לפרטים על השימוש בכלי
dwh-migration-dumper, אפשר לעיין במאמר בנושא יצירת מטא-נתונים לתרגום ולבדיקה.משתמשים בכלי
dwh-migration-dumperכדי לחלץ מטא-נתונים ונתוני ביצועים לקובץ ה-ZIP:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --spark-history-service-names "SPARK_HISTORY_SERVICE_NAMES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
מחליפים את מה שכתוב בשדות הבאים:
-
USER_NAME: השם של המשתמש שמתחבר למופע Cloudera Manager. -
PASSWORD: הסיסמה למופע Cloudera Manager. -
URL_PATH: נתיב כתובת ה-URL אל Cloudera Manager API, לדוגמה,https://localhost:7183/api/v55/. -
APP_TYPES(אופציונלי): סוגי האפליקציות של YARN שמוצאים מהאשכול, מופרדים בפסיקים. ערך ברירת המחדל הואMAPREDUCE,SPARK,Oozie Launcher. -
SPARK_HISTORY_SERVICE_NAMES(אופציונלי): רשימת שמות השירותים של Spark History Server, מופרדים בפסיקים. הרשימה משמשת לשליחת שאילתות ליומני האירועים של Spark דרך Apache Knox כדי לחלץ מטא-נתונים של אפליקציות. אם לא מציינים ערך, ערך ברירת המחדל הואsparkhistory,spark3history. -
PAGE_SIZE(אופציונלי): מספר הרשומות בכל תגובה של Cloudera. ערך ברירת המחדל הוא1000. -
START_DATE(אופציונלי): תאריך ההתחלה של היסטוריית הנתונים בפורמט ISO 8601, לדוגמה2025-05-29. ערך ברירת המחדל הוא 90 ימים לפני התאריך הנוכחי. -
END_DATE(אופציונלי): תאריך הסיום של גיבוי היסטוריית השיחות בפורמט ISO 8601, לדוגמה2025-05-30. ערך ברירת המחדל הוא התאריך הנוכחי.
-
שימוש ב-Oozie באשכול Cloudera
אם אתם משתמשים ב-Oozie באשכול Cloudera, אתם יכולים להשתמש במחבר Oozie כדי לייצא את היסטוריית העבודות של Oozie. אפשר להשתמש ב-Oozie עם אימות Kerberos או עם אימות בסיסי.
כדי לבצע אימות Kerberos, מריצים את הפקודה הבאה:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
מחליפים את מה שכתוב בשדות הבאים:
-
URL_PATH(אופציונלי): נתיב כתובת ה-URL של שרת Oozie. אם לא מציינים את נתיב כתובת ה-URL, הוא נלקח ממשתנה הסביבהOOZIE_URL.
כדי להשתמש באימות בסיסי, מריצים את הפקודה הבאה:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
מחליפים את מה שכתוב בשדות הבאים:
-
USER_NAME: השם של משתמש Oozie. -
PASSWORD: סיסמת המשתמש. -
URL_PATH(אופציונלי): נתיב כתובת ה-URL של שרת Oozie. אם לא מציינים את נתיב כתובת ה-URL, הוא נלקח ממשתנה הסביבהOOZIE_URL.
שימוש ב-Airflow באשכול Cloudera
אם אתם משתמשים ב-Airflow באשכול Cloudera, אתם יכולים להשתמש במחבר Airflow כדי לייצא את היסטוריית ה-DAG:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
מחליפים את מה שכתוב בשדות הבאים:
-
USER_NAME: השם של משתמש Airflow -
PASSWORD: סיסמת המשתמש -
URL: מחרוזת ה-JDBC למסד הנתונים של Airflow -
DRIVER_PATH: הנתיב לדרייבר של JDBC -
START_DATE(אופציונלי): תאריך ההתחלה של גיבוי ההיסטוריה בפורמט ISO 8601 -
END_DATE(אופציונלי): תאריך הסיום של היסטוריית הנתונים בפורמט ISO 8601
שימוש ב-Hive באשכול Cloudera
כדי להשתמש ב-Hive connector, אפשר לעבור לכרטיסייה Apache Hive.
Teradata
דרישות
- מכונה שמחוברת למחסן נתונים של Teradata (גרסה 15 ואילך נתמכות)
- Google Cloud חשבון עם קטגוריה של Cloud Storage לאחסון הנתונים
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות
- הרשאות קריאה במערך הנתונים כדי להציג את התוצאות
- מומלץ: הרשאות גישה ברמת האדמין למסד הנתונים של המקור כשמשתמשים בכלי החילוץ כדי לגשת לטבלאות מערכת
דרישה: הפעלת רישום ביומן
הכלי dwh-migration-dumper מחלץ שלושה סוגים של יומנים: יומני שאילתות, יומני כלי עזר ויומני שימוש במשאבים. כדי לקבל תובנות מקיפות יותר, צריך להפעיל את רישום היומנים לסוגי היומנים הבאים:
- יומני שאילתות: נשלפים מהתצוגה
dbc.QryLogVומהטבלהdbc.DBQLSqlTbl. מפעילים את הרישום ביומן על ידי ציון האפשרותWITH SQL. - יומני כלי עזר: נשלפים מהטבלה
dbc.DBQLUtilityTbl. מפעילים את הרישום ביומן על ידי ציון האפשרותWITH UTILITYINFO. - יומני שימוש במשאבים: נשלפים מהטבלאות
dbc.ResUsageScpuו-dbc.ResUsageSpma. הפעלת רישום ביומן של RSS לשתי הטבלאות האלה.
הפעלת הכלי dwh-migration-dumper
מורידים את הכלי dwh-migration-dumper.
מורידים את קובץ SHA256SUMS.txt ומריצים את הפקודה הבאה כדי לוודא שקובץ ה-ZIP תקין:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
מחליפים את RELEASE_ZIP_FILENAME בשם קובץ ה-ZIP שהורדתם של מהדורת כלי החילוץ של שורת הפקודה dwh-migration-dumper – לדוגמה, dwh-migration-tools-v1.0.52.zip
התוצאה True מאשרת שהאימות של סכום הביקורת הצליח.
התוצאה False מציינת שגיאת אימות. מוודאים שקובצי ה-checksum וה-ZIP הורדו מאותה גרסת הפצה והוצבו באותה ספרייה.
במאמר יצירת מטא-נתונים לתרגום ולבדיקה מוסבר איך מגדירים את כלי החילוץ ואיך משתמשים בו.
משתמשים בכלי החילוץ כדי לחלץ יומנים ומטא-נתונים ממחסן הנתונים של Teradata כשני קובצי ZIP. מריצים את הפקודות הבאות במחשב עם גישה למחסן הנתונים של המקור כדי ליצור את הקבצים.
יוצרים את קובץ ה-ZIP של המטא-נתונים:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
הערה: השימוש בדגל --database הוא אופציונלי במחבר teradata. אם לא מציינים מסד נתונים, המטא-נתונים של כל מסדי הנתונים מחולצים. הדגל הזה תקף רק למחבר teradata ואי אפשר להשתמש בו עם teradata-logs.
יוצרים את קובץ ה-ZIP שמכיל את יומני השאילתות:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
הערה: לא משתמשים בדגל --database כשמחלצים יומני שאילתות באמצעות המחבר teradata-logs. יומני השאילתות תמיד מחולצים עבור כל מסדי הנתונים.
מחליפים את מה שכתוב בשדות הבאים:
-
PATH: הנתיב המוחלט או היחסי לקובץ ה-JAR של מנהל ההתקן שבו רוצים להשתמש לחיבור הזה -
VERSION: הגרסה של מנהל ההתקן -
HOST: כתובת המארח USER: שם המשתמש שמשמש לחיבור למסד הנתונים-
DATABASES: (אופציונלי) רשימה מופרדת בפסיקים של שמות מסדי הנתונים לחילוץ. אם לא מציינים מסד נתונים, המערכת מחלצת את כל מסדי הנתונים. -
PASSWORD: (אופציונלי) הסיסמה לשימוש בחיבור למסד הנתונים. אם השדה יישאר ריק, המשתמשים יתבקשו להזין את הסיסמה שלהם.
כברירת מחדל, יומני השאילתות מחולצים מהתצוגה המפורטת dbc.QryLogV ומהטבלה dbc.DBQLSqlTbl. אם אתם צריכים לחלץ את יומני השאילתות ממיקום חלופי, אתם יכולים לציין את השמות של הטבלאות או התצוגות באמצעות הדגלים -Dteradata-logs.query-logs-table ו--Dteradata-logs.sql-logs-table.
כברירת מחדל, יומני השירותים מחולצים מהטבלה dbc.DBQLUtilityTbl. אם אתם צריכים לחלץ את יומני השירות ממיקום חלופי, אתם יכולים לציין את שם הטבלה באמצעות הדגל -Dteradata-logs.utility-logs-table.
כברירת מחדל, יומני השימוש במשאבים מחולצים מהטבלאות dbc.ResUsageScpu ו-dbc.ResUsageSpma. אם אתם צריכים לחלץ את יומני השימוש במשאבים ממיקום חלופי, אתם יכולים לציין את שמות הטבלאות באמצעות הדגלים -Dteradata-logs.res-usage-scpu-table ו--Dteradata-logs.res-usage-spma-table.
לדוגמה:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
כברירת מחדל, הכלי dwh-migration-dumper מחלץ את יומני השאילתות מ-7 הימים האחרונים.
Google ממליצה לספק יומני שאילתות של שבועיים לפחות כדי לקבל תובנות מקיפות יותר. אפשר להגדיר טווח זמן מותאם אישית באמצעות הדגלים --query-log-start ו---query-log-end. לדוגמה:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
אפשר גם ליצור כמה קובצי ZIP שמכילים יומני שאילתות שמתייחסים לתקופות שונות, ולספק את כולם לצורך הערכה.
Redshift
דרישות
- מכונה שמחוברת למחסן הנתונים של Amazon Redshift
- Google Cloud חשבון עם קטגוריה של Cloud Storage לאחסון הנתונים
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות
- הרשאות קריאה במערך הנתונים כדי להציג את התוצאות
- מומלץ: גישת משתמש-על למסד הנתונים כשמשתמשים בכלי החילוץ כדי לגשת לטבלאות מערכת
הפעלת הכלי dwh-migration-dumper
מורידים את כלי החילוץ של שורת הפקודה dwh-migration-dumper.
מורידים את קובץ SHA256SUMS.txt ומריצים את הפקודה הבאה כדי לוודא שקובץ ה-ZIP תקין:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
מחליפים את RELEASE_ZIP_FILENAME בשם קובץ ה-ZIP שהורדתם של מהדורת כלי החילוץ של שורת הפקודה dwh-migration-dumper – לדוגמה, dwh-migration-tools-v1.0.52.zip
התוצאה True מאשרת שהאימות של סכום הביקורת הצליח.
התוצאה False מציינת שגיאת אימות. מוודאים שקובצי ה-checksum וה-ZIP הורדו מאותה גרסת הפצה והוצבו באותה ספרייה.
לפרטים על השימוש בכלי dwh-migration-dumper, אפשר לעיין בדף יצירת מטא-נתונים.
אפשר להשתמש בכלי dwh-migration-dumper כדי לחלץ יומנים ומטא-נתונים ממחסן הנתונים של Amazon Redshift כשני קובצי zip.
מריצים את הפקודות הבאות במחשב עם גישה למחסן הנתונים של המקור כדי ליצור את הקבצים.
יוצרים את קובץ ה-ZIP של המטא-נתונים:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
יוצרים את קובץ ה-ZIP שמכיל את יומני השאילתות:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
מחליפים את מה שכתוב בשדות הבאים:
-
DATABASE: השם של מסד הנתונים שאליו רוצים להתחבר -
PATH: הנתיב המוחלט או היחסי לקובץ ה-JAR של מנהל ההתקן שבו רוצים להשתמש לחיבור הזה -
VERSION: הגרסה של מנהל ההתקן USER: שם המשתמש שמשמש לחיבור למסד הנתונים-
IAM_PROFILE_NAME: שם פרופיל IAM ב-Amazon Redshift. נדרש לאימות ב-Amazon Redshift ולגישה ל-AWS API. כדי לקבל את התיאור של אשכולות Amazon Redshift, צריך להשתמש ב-AWS API.
כברירת מחדל, ב-Amazon Redshift נשמרים יומני שאילתות של שלושה עד חמישה ימים.
כברירת מחדל, הכלי dwh-migration-dumper מחלץ את יומני השאילתות של שבעת הימים האחרונים.
Google ממליצה לספק יומני שאילתות של שבועיים לפחות כדי לקבל תובנות מקיפות יותר. כדי לקבל את התוצאות הכי טובות, יכול להיות שתצטרכו להפעיל את כלי החילוץ כמה פעמים במהלך שבועיים. אפשר לציין טווח מותאם אישית באמצעות הדגלים --query-log-start ו---query-log-end.
לדוגמה:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
אפשר גם ליצור כמה קובצי ZIP שמכילים יומני שאילתות שמתייחסים לתקופות שונות, ולספק את כולם לצורך הערכה.
Redshift Serverless
דרישות
- מכונה שמחוברת למקור נתונים של מחסן נתונים בלי שרת ב-Amazon Redshift
- Google Cloud חשבון עם קטגוריה של Cloud Storage לאחסון הנתונים
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות
- הרשאות קריאה במערך הנתונים כדי להציג את התוצאות
- מומלץ: גישת משתמש-על למסד הנתונים כשמשתמשים בכלי החילוץ כדי לגשת לטבלאות מערכת
הפעלת הכלי dwh-migration-dumper
מורידים את כלי החילוץ של שורת הפקודה dwh-migration-dumper.
לפרטים על השימוש בכלי dwh-migration-dumper, אפשר לעיין בדף יצירת מטא-נתונים.
אפשר להשתמש בכלי dwh-migration-dumper כדי לחלץ יומני שימוש ומטא-נתונים ממרחב השמות של Amazon Redshift Serverless כשני קובצי ZIP. מריצים את הפקודות הבאות במחשב עם גישה למחסן הנתונים של המקור כדי ליצור את הקבצים.
יוצרים את קובץ ה-ZIP של המטא-נתונים:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
יוצרים את קובץ ה-ZIP שמכיל את יומני השאילתות:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
מחליפים את מה שכתוב בשדות הבאים:
-
DATABASE: השם של מסד הנתונים שאליו רוצים להתחבר -
PATH: הנתיב המוחלט או היחסי לקובץ ה-JAR של מנהל ההתקן שבו רוצים להשתמש לחיבור הזה -
VERSION: הגרסה של מנהל ההתקן USER: שם המשתמש שמשמש לחיבור למסד הנתונים-
IAM_PROFILE_NAME: שם פרופיל IAM ב-Amazon Redshift. נדרש לאימות ב-Amazon Redshift ולגישה ל-AWS API. כדי לקבל את התיאור של אשכולות Amazon Redshift, צריך להשתמש ב-AWS API.
ב-Amazon Redshift Serverless, יומני השימוש נשמרים למשך שבעה ימים. אם נדרש טווח רחב יותר, Google ממליצה לחלץ נתונים כמה פעמים לאורך תקופה ארוכה יותר.
Oracle / Oracle Exadata
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
דרישות
כדי לחלץ מ-Oracle ומ-Oracle Exadata מטא-נתונים ויומני שאילתות, צריך לעמוד בדרישות הבאות:
- מסד הנתונים של Oracle צריך להיות מגרסה 11g R1 ואילך.
- מכונה שיכולה להתחבר למופעים של Oracle.
- Java מגרסה 8 ואילך.
- חשבון Google Cloud עם קטגוריה של Cloud Storage לאחסון הנתונים.
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות. לחלופין, אפשר ליצור מערך נתונים של BigQuery כשיוצרים את משימת ההערכה באמצעות ממשק המשתמש של Google Cloud המסוף.
- משתמש Oracle רגיל עם הרשאות SYSDBA.
הפעלת הכלי dwh-migration-dumper
מורידים את כלי החילוץ של שורת הפקודה dwh-migration-dumper.
מורידים את קובץ SHA256SUMS.txt ומריצים את הפקודה הבאה כדי לוודא שקובץ ה-ZIP תקין:
sha256sum --check SHA256SUMS.txt
לפרטים על השימוש בכלי dwh-migration-dumper, אפשר לעיין בדף יצירת מטא-נתונים.
משתמשים בכלי dwh-migration-dumper כדי לחלץ מטא-נתונים ונתוני ביצועים לקובץ ה-ZIP. כברירת מחדל, הנתונים הסטטיסטיים מחולצים מ-Oracle AWR, שנדרש עבורו Oracle Tuning and Diagnostics Pack. אם הנתונים האלה לא זמינים, dwh-migration-dumper משתמש ב-STATSPACK במקום זאת. מחבר oracle-stats תומך גם ב-Oracle Exadata.
במסדי נתונים עם מספר דיירים, צריך להריץ את dwh-migration-dumper הכלי במאגר הבסיס. הפעלת הפקודה באחד ממסדי הנתונים הניתנים לחיבור מובילה לחוסר בנתוני ביצועים ובמטא-נתונים לגבי מסדי נתונים אחרים שניתנים לחיבור.
יוצרים את קובץ ה-ZIP של המטא-נתונים:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
מחליפים את מה שכתוב בשדות הבאים:
-
HOST_NAME: שם המארח של מופע Oracle. -
PORT: מספר יציאת החיבור. ערך ברירת המחדל הוא 1521. -
SERVICE_NAME: שם שירות Oracle שבו רוצים להשתמש לחיבור. -
JDBC_DRIVER_PATH: הנתיב המוחלט או היחסי לקובץ ה-JAR של הדרייבר. אפשר להוריד את הקובץ הזה מהדף Oracle JDBC driver downloads. צריך לבחור את גרסת הדרייבר שתואמת לגרסת מסד הנתונים. -
USER_NAME: השם של המשתמש שמשמש להתחברות למופע Oracle. למשתמש צריכות להיות הרשאות הגישה שמפורטות בקטע הדרישות.
Apache Hive
דרישות
- מכונה שמחוברת למחסן הנתונים של Apache Hive (הערכת ההעברה ל-BigQuery תומכת ב-Hive ב-Tez וב-MapReduce, ותומכת בגרסאות של Apache Hive בין 2.2 ל-3.1, כולל)
- Google Cloud חשבון עם קטגוריה של Cloud Storage לאחסון הנתונים
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות
- הרשאות קריאה במערך הנתונים כדי להציג את התוצאות
- גישה למחסן הנתונים של Apache Hive כדי להגדיר חילוץ של יומני שאילתות
- נתונים סטטיסטיים עדכניים לגבי טבלאות, מחיצות ועמודות
ההערכה של המיגרציה ל-BigQuery מתבססת על נתונים סטטיסטיים של טבלאות, מחיצות ועמודות כדי להבין טוב יותר את מחסן הנתונים של Apache Hive ולספק תובנות מקיפות. אם הגדרת hive.stats.autogather מוגדרת לערך false במחסן הנתונים של Apache Hive, מומלץ להפעיל אותה או לעדכן את הנתונים הסטטיסטיים באופן ידני לפני שמריצים את הכלי dwh-migration-dumper.
הפעלת הכלי dwh-migration-dumper
מורידים את כלי החילוץ של שורת הפקודה dwh-migration-dumper.
מורידים את קובץ SHA256SUMS.txt ומריצים את הפקודה הבאה כדי לוודא שקובץ ה-ZIP תקין:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
מחליפים את RELEASE_ZIP_FILENAME בשם קובץ ה-ZIP שהורדתם של מהדורת כלי החילוץ של שורת הפקודה dwh-migration-dumper – לדוגמה, dwh-migration-tools-v1.0.52.zip
התוצאה True מאשרת שהאימות של סכום הביקורת הצליח.
התוצאה False מציינת שגיאת אימות. מוודאים שקובצי ה-checksum וה-ZIP הורדו מאותה גרסת הפצה והוצבו באותה ספרייה.
לפרטים על השימוש בכלי dwh-migration-dumper, אפשר לעיין במאמר בנושא יצירת מטא-נתונים לתרגום ולבדיקה.
אפשר להשתמש בכלי dwh-migration-dumper כדי ליצור מטא-נתונים ממחסן הנתונים של Hive כקובץ zip.
ללא אימות
כדי ליצור את קובץ ה-zip של המטא-נתונים, מריצים את הפקודה הבאה במחשב שיש לו גישה למחסן הנתונים של המקור:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
עם אימות Kerberos
כדי לבצע אימות למאגר המטא-נתונים, צריך להיכנס בתור משתמש שיש לו גישה למאגר המטא-נתונים של Apache Hive וליצור כרטיס Kerberos. לאחר מכן, מריצים את הפקודה הבאה כדי ליצור את קובץ ה-ZIP של המטא-נתונים:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
מחליפים את מה שכתוב בשדות הבאים:
-
DATABASES: רשימה מופרדת בפסיקים של שמות מסדי הנתונים לחילוץ. אם לא מציינים מסד נתונים, המערכת מחלצת את כל מסדי הנתונים. -
PRINCIPAL: חשבון המשתמש ב-Kerberos שהטיקט הונפק לו -
HOST: שם המארח של Kerberos שהכרטיס מונפק לו -
hadoop.rpc.protection: איכות ההגנה (QOP) של רמת ההגדרה של שכבת האבטחה והאימות הפשוטים (SASL), ששווה לערך של הפרמטרhadoop.rpc.protectionבקובץ/etc/hadoop/conf/core-site.xml, עם אחד מהערכים הבאים:authenticationintegrityprivacy
חילוץ יומני שאילתות באמצעות וו הרישום hadoop-migration-assessment
כדי לחלץ יומני שאילתות, פועלים לפי השלבים הבאים:
- מעלים את
hadoop-migration-assessmentlogging hook. - הגדרת המאפיינים של וו רישום היומן.
- אימות ה-hook של הרישום ביומן.
העלאת ה-hook של רישום ביומן hadoop-migration-assessment
מורידים את
hadoop-migration-assessmentquery logs extraction logging hook שמכיל את קובץ ה-JAR של Hive logging hook.מחלצים את קובץ ה-JAR.
אם אתם צריכים לבדוק את הכלי כדי לוודא שהוא עומד בדרישות התאימות, תוכלו לעיין בקוד המקור ממאגר ה-GitHub של ווֹבּינג לרישום ביומן
hadoop-migration-assessment, ולקמפל בינארי משלכם.מעתיקים את קובץ ה-JAR לתיקיית הספרייה העזר בכל האשכולות שבהם מתכננים להפעיל את רישום השאילתות. בהתאם לספק, צריך לאתר את תיקיית הספרייה העזר בהגדרות האשכול ולהעביר את קובץ ה-JAR לתיקיית הספרייה העזר באשכול Hive.
הגדרת מאפייני תצורה ל-
hadoop-migration-assessmentlogging hook. בהתאם לספק Hadoop שלכם, תצטרכו להשתמש במסוף ממשק המשתמש כדי לערוך את הגדרות האשכול. משנים את קובץ/etc/hive/conf/hive-site.xmlאו משתמשים במנהל התצורה כדי להחיל את התצורה.
הגדרת מאפיינים
אם כבר יש לכם ערכים אחרים למפתחות ההגדרה הבאים, צריך להוסיף את ההגדרות באמצעות פסיק (,). כדי להגדיר את וו הרישום ביומן hadoop-migration-assessment, נדרשות הגדרות התצורה הבאות:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHook-
hive.aux.jars.path: כוללים את הנתיב לקובץ ה-JAR של ה-hook לרישום ביומן, לדוגמהfile://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar -
dwhassessment.hook.base-directory: הנתיב לתיקיית הפלט של יומני השאילתות. לדוגמה,hdfs://tmp/logs/. אפשר גם להגדיר את ההגדרות האופציונליות הבאות:
-
dwhassessment.hook.queue.capacity: קיבולת התור של השרשורים לרישום ביומן של אירועי השאילתות. ערך ברירת המחדל הוא64. -
dwhassessment.hook.rollover-interval: התדירות שבה צריך לבצע את החלפת הקובץ. לדוגמה,600s. ערך ברירת המחדל הוא 3,600 שניות (שעה אחת). -
dwhassessment.hook.rollover-eligibility-check-interval: התדירות שבה מופעלת ברקע בדיקת הזכאות להחלפת הקובץ. לדוגמה,600s. ערך ברירת המחדל הוא 600 שניות (10 דקות).
-
אימות של ה-hook לרישום ביומן
אחרי שמפעילים מחדש את התהליך של hive-server2, מריצים שאילתת בדיקה ומנתחים את יומני הניפוי באגים. תוצג לכם ההודעה הבאה:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
ה-hook של הרישום ביומן יוצר תיקיית משנה עם חלוקה לפי תאריכים בתיקייה שהוגדרה. קובץ ה-Avro עם אירועי השאילתה מופיע בתיקייה הזו אחרי dwhassessment.hook.rollover-interval המרווח
או סיום התהליך hive-server2. אפשר לחפש הודעות דומות ביומני הניפוי באגים כדי לראות את הסטטוס של פעולת ההחלפה:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
ההחלפה מתרחשת במרווחי הזמן שצוינו או כשהיום מתחלף. כשמתחלף התאריך, ווֹקִינג הלוג יוצר גם תיקיית משנה חדשה לתאריך הזה.
Google ממליצה לספק יומני שאילתות של שבועיים לפחות כדי לקבל תובנות מקיפות יותר.
אפשר גם ליצור תיקיות שמכילות יומני שאילתות מאשכולות Hive שונים ולספק את כולם להערכה אחת.
Informatica
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
דרישות
- גישה ללקוח Informatica PowerCenter Repository Manager
- חשבון Google Cloud עם קטגוריה של Cloud Storage לאחסון הנתונים.
- מערך נתונים ריק ב-BigQuery לאחסון התוצאות. לחלופין, אפשר ליצור מערך נתונים של BigQuery כשיוצרים את משימת ההערכה באמצעות Google Cloud המסוף.
דרישה: ייצוא קובצי אובייקטים
אפשר להשתמש בממשק המשתמש הגרפי של Informatica PowerCenter Repository Manager כדי לייצא את קובצי האובייקטים. מידע נוסף זמין במאמר שלבים לייצוא אובייקטים
אפשר גם להריץ את הפקודה pmrep כדי לייצא את קובצי האובייקט באופן הבא:
- מריצים את הפקודה
pmrep connectכדי להתחבר למאגר:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
מחליפים את מה שכתוב בשדות הבאים:
-
REPOSITORY_NAME: שם המאגר שאליו רוצים להתחבר -
DOMAIN_NAME: שם הדומיין של המאגר -
USERNAME: שם המשתמש להתחברות למאגר -
PASSWORD: הסיסמה של שם המשתמש
- אחרי שמתחברים למאגר, משתמשים בפקודה
pmrep objectexportכדי לייצא את האובייקטים הנדרשים:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
מחליפים את מה שכתוב בשדות הבאים:
-
OBJECT_NAME: השם של אובייקט ספציפי לייצוא -
OBJECT_TYPE: סוג האובייקט של האובייקט שצוין -
FOLDER_NAME: שם התיקייה שמכילה את האובייקט שמיועד לייצוא OUTPUT_FILE_NAME: שם קובץ ה-XML שיכיל את פרטי האובייקט
העלאת מטא-נתונים ויומני שאילתות ל-Cloud Storage
אחרי שמחלצים את המטא-נתונים ואת יומני השאילתות ממחסן הנתונים, אפשר להעלות את הקבצים לקטגוריה של Cloud Storage כדי להמשיך בהערכת המיגרציה.
Databricks
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
מעלים את קובץ ה-ZIP לקטגוריה של Cloud Storage. מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
פתית שלג
מעלים את המטא-נתונים ואת קובצי ה-ZIP שמכילים את יומני השאילתות והיסטוריית השימוש לקטגוריה ב-Cloud Storage. כשמעלים את הקבצים האלה ל-Cloud Storage, צריך לעמוד בדרישות הבאות:
- הגודל הכולל של כל הקבצים הלא דחוסים בקובץ ה-ZIP של המטא-נתונים צריך להיות קטן מ-50GB.
- צריך להעלות לתיקייה ב-Cloud Storage את קובץ ה-ZIP של המטא-נתונים ואת קובץ ה-ZIP שמכיל את יומני השאילתות. אם יש לכם כמה קובצי ZIP שמכילים יומני שאילתות לא חופפים, אתם יכולים להעלות את כולם.
- צריך להעלות את כל הקבצים לאותה תיקייה ב-Cloud Storage.
- צריך להעלות את כל קובצי ה-ZIP של המטא-נתונים ויומני השאילתות בדיוק כמו שהם מופקים על ידי הכלי
dwh-migration-dumper. אסור לחלץ, לשלב או לשנות אותם בדרך אחרת. - הגודל הכולל של כל קובצי היסטוריית השאילתות ללא דחיסה צריך להיות קטן מ-5TB.
מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
Hadoop / Cloudera
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
מעלים את קובץ ה-ZIP שמכיל מטא-נתונים ונתוני ביצועים לקטגוריה של Cloud Storage. כברירת מחדל, שם קובץ ה-ZIP הוא dwh-migration-cloudera-manager-RUN_DATE.zip (לדוגמה, dwh-migration-cloudera-manager-20250312T145808.zip), אבל אפשר להתאים אותו אישית באמצעות הדגל --output. הגודל הכולל של כל הקבצים בקובץ ה-ZIP אחרי פתיחת הדחיסה לא יכול להיות יותר מ-50GB.
מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריה והעלאת אובייקטים ממערכת קבצים.
Teradata
מעלים את המטא-נתונים ואת קובץ ה-ZIP או קובצי ה-ZIP שמכילים את יומני השאילתות לקטגוריה של Cloud Storage. מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים. הגודל הכולל של כל הקבצים בתוך קובץ ה-ZIP של המטא-נתונים לא יכול להיות גדול מ-50GB.
הערכים בכל קובצי ה-ZIP שמכילים יומני שאילתות מחולקים לקטגוריות הבאות:
- קבצים של היסטוריית שאילתות עם הקידומת
query_history_. - קבצים של סדרות זמנים עם הקידומות
utility_logs_,dbc.ResUsageScpu_ו-dbc.ResUsageSpma_.
הגודל הכולל המקסימלי של כל קובצי היסטוריית השאילתות הוא 5TB. הגודל הכולל המקסימלי של כל קובצי סדרות הזמן הוא 1TB.
אם יומני השאילתות מאוחסנים בארכיון במסד נתונים אחר, אפשר לעיין בתיאור של הדגלים -Dteradata-logs.query-logs-table ו--Dteradata-logs.sql-logs-table שמופיע בהמשך הקטע הזה. שם מוסבר איך לספק מיקום חלופי ליומני השאילתות.
Redshift
מעלים את המטא-נתונים ואת קובץ ה-ZIP או קובצי ה-ZIP שמכילים את יומני השאילתות לקטגוריה של Cloud Storage. מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים. הגודל הכולל של כל הקבצים בתוך קובץ ה-ZIP של המטא-נתונים לא יכול להיות גדול מ-50GB.
הערכים בכל קובצי ה-ZIP שמכילים יומני שאילתות מחולקים לקטגוריות הבאות:
- אפשר להשתמש בקידומות
querytext_ו-ddltext_כדי לחפש קבצים בהיסטוריית השאילתות. - קבצים של סדרות זמנים עם הקידומות
query_queue_info_,wlm_query_ו-querymetrics_.
הגודל הכולל המקסימלי של כל קובצי היסטוריית השאילתות הוא 5TB. הגודל הכולל המקסימלי של כל קובצי סדרות הזמן הוא 1TB.
Redshift Serverless
מעלים את המטא-נתונים ואת קובץ ה-ZIP או קובצי ה-ZIP שמכילים את יומני השאילתות לקטגוריה של Cloud Storage. מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
Oracle / Oracle Exadata
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
מעלים את קובץ ה-ZIP שמכיל מטא-נתונים ונתוני ביצועים לקטגוריה של Cloud Storage. כברירת מחדל, שם קובץ ה-ZIP הוא dwh-migration-oracle-stats.zip, אבל אפשר לשנות את זה באמצעות ציון שם הקובץ בדגל --output. הגודל הכולל של כל הקבצים בתוך קובץ ה-ZIP, כשהם לא דחוסים, לא יכול להיות גדול מ-50GB.
מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
Apache Hive
מעלים את המטא-נתונים ואת התיקיות שמכילות את יומני השאילתות מאשכול Hive אחד או יותר לקטגוריה ב-Cloud Storage. מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
הגודל הכולל של כל הקבצים בתוך קובץ ה-ZIP של המטא-נתונים לא יכול להיות גדול מ-50GB.
אפשר להשתמש במחבר Cloud Storage כדי להעתיק את יומני השאילתות ישירות לתיקיית Cloud Storage. צריך להעלות את התיקיות שמכילות תיקיות משנה עם יומני שאילתות לאותה תיקייה ב-Cloud Storage שאליה מעלים את קובץ ה-ZIP של המטא-נתונים.
בתיקיות של יומני השאילתות יש קבצים של היסטוריית השאילתות עם הקידומת dwhassessment_. הגודל הכולל המקסימלי של כל הקבצים של היסטוריית השאילתות הוא 5TB.
Informatica
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
מעלים קובץ zip שמכיל את אובייקטי המאגר של Informatica XML לקטגוריה של Cloud Storage. קובץ ה-ZIP צריך לכלול גם קובץ compilerworks-metadata.yaml שמכיל את הפרטים הבאים:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
הגודל הכולל של כל הקבצים בתוך קובץ ה-ZIP, כשהם לא דחוסים, לא יכול להיות גדול מ-50GB.
מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
הפעלת הערכה של העברה ל-BigQuery
כדי להריץ את ההערכה של המעבר ל-BigQuery, פועלים לפי השלבים הבאים. השלבים האלה מניחים שהעליתם את קובצי המטא-נתונים לקטגוריה של Cloud Storage, כמו שמתואר בקטע הקודם.
ההרשאות הנדרשות
כדי להפעיל את BigQuery Migration Service, צריך את ההרשאות הבאות לניהול זהויות והרשאות גישה (IAM):
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
כדי לגשת אל BigQuery Migration Service ולהשתמש בו, אתם צריכים את ההרשאות הבאות בפרויקט:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
כדי להריץ את שירות ההעברה ל-BigQuery, אתם צריכים את ההרשאות הנוספות הבאות.
הרשאה לגשת לקטגוריות של Cloud Storage לקבצי קלט ופלט:
-
storage.objects.getבקטגוריית המקור של Cloud Storage -
storage.objects.listבקטגוריית המקור של Cloud Storage -
storage.objects.createבקטגוריית היעד של Cloud Storage -
storage.objects.deleteבקטגוריית היעד של Cloud Storage -
storage.objects.updateבקטגוריית היעד של Cloud Storage storage.buckets.getstorage.buckets.list
-
הרשאה לקרוא ולעדכן את מערך הנתונים ב-BigQuery שבו שירות ההעברה ל-BigQuery כותב את התוצאות:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
כדי לשתף את הדוח ב-Data Studio עם משתמש, צריך להקצות לו את התפקידים הבאים:
roles/bigquery.dataViewerroles/bigquery.jobUser
בדוגמה הבאה מוצגות ההרשאות שצריך להעניק למשתמש שאיתו רוצים לשתף את הדוח:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:REPORT_VIEWER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:REPORT_VIEWER_EMAIL \ --role=roles/bigquery.jobUser
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT: הפרויקט שבו נמצא המשתמש -
REPORT_VIEWER_EMAIL: כתובת האימייל של המשתמש שאיתו רוצים לשתף את הדוח
יצירת פרויקט להערכה
מומלץ ליצור ולהגדיר פרויקט חדש כדי להריץ את הערכת המוכנות להעברה. אתם יכולים להשתמש בסקריפט הבא כדי ליצור פרויקט חדש Google Cloud עם כל ההרשאות הנדרשות והקצאות התפקידים להרצת ההערכה:
#!/bin/bash # --- Configuration --- # Replace with your desired project ID, the email of the user that runs # the assessment, and your organization ID. export PROJECT_ID="PROJECT_ID" export ASSESSMENT_RUNNER_EMAIL="RUNNER_EMAIL" export ORGANIZATION_ID="ORGANIZATION_ID" # --- Project Creation --- echo "Creating project: $PROJECT_ID" gcloud projects create $PROJECT_ID --organization=$ORGANIZATION_ID # Set the new project as the default for subsequent gcloud commands gcloud config set project $PROJECT_ID # --- IAM Role Creation --- echo "Creating custom role 'BQMSrole' in project $PROJECT_ID" gcloud iam roles create BQMSrole \ --project=$PROJECT_ID \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get # --- IAM Policy Binding for Assessment Runner --- echo "Granting IAM roles to the assessment runner: $ASSESSMENT_RUNNER_EMAIL" # Grant the custom BQMSrole to the assessment runner user gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member=user:$ASSESSMENT_RUNNER_EMAIL \ --role=projects/$PROJECT_ID/roles/BQMSrole # Grant the BigQuery Data Viewer role to the assessment runner user gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member=user:$ASSESSMENT_RUNNER_EMAIL \ --role=roles/bigquery.dataViewer # Grant the BigQuery Job User role to the assessment runner user gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member=user:$ASSESSMENT_RUNNER_EMAIL \ --role=roles/bigquery.jobUser echo "Project $PROJECT_ID created and configured for BigQuery Migration Assessment." echo "Assessment Runner: $ASSESSMENT_RUNNER_EMAIL"
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: השם של מזהה פרויקט חדש RUNNER_EMAIL: כתובת האימייל של המשתמש שמריץ את הערכת ההעברה-
ORGANIZATION_ID: מזהה הארגון. לדוגמה,123456789012.
מיקומים נתמכים
התכונה להערכת העברה ב-BigQuery נתמכת בכל המיקומים של BigQuery. רשימת המיקומים ב-BigQuery זמינה במאמר בנושא מיקומים נתמכים.
לפני שמתחילים
לפני שמריצים את ההערכה, צריך להפעיל את BigQuery Migration API וליצור מערך נתונים ב-BigQuery כדי לאחסן את תוצאות ההערכה.
הפעלת BigQuery Migration API
כדי להפעיל את BigQuery Migration API:
במסוף Google Cloud , עוברים לדף BigQuery Migration API.
לוחצים על Enable.
יצירת מערך נתונים לתוצאות ההערכה
הכלי להערכת מיגרציה ל-BigQuery כותב את תוצאות ההערכה לטבלאות ב-BigQuery. לפני שמתחילים, יוצרים מערך נתונים שיכיל את הטבלאות האלה. כשמשתפים את הדוח ב-Data Studio, צריך גם לתת למשתמשים הרשאה לקרוא את מערך הנתונים הזה. מידע נוסף זמין במאמר בנושא הפיכת הדוח לזמין למשתמשים.
הפעלת הערכת ההעברה
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, בקטע
Migration, לוחצים על שירותים.לוחצים על התחלת ההערכה.
ממלאים את תיבת הדו-שיח של הגדרת המבדק.
- בשדה שם מוצג מזינים את השם שיכול להכיל אותיות, מספרים או קווים תחתונים. השם הזה הוא רק למטרות תצוגה ולא חייב להיות ייחודי.
- בקטע מקור נתוני ההערכה, בוחרים את מחסן הנתונים.
- בשדה נתיב לקובצי קלט, מזינים את הנתיב לקטגוריה ב-Cloud Storage שמכילה את הקבצים שחולצו.
כדי לבחור איך לאחסן את תוצאות ההערכה, מבצעים אחת מהפעולות הבאות:
- משאירים את תיבת הסימון יצירה אוטומטית של מערך נתונים חדש ב-BigQuery מסומנת כדי שמערך הנתונים ב-BigQuery ייצור באופן אוטומטי. השם של מערך הנתונים נוצר באופן אוטומטי.
- מבטלים את הסימון בתיבת הסימון יצירה אוטומטית של מערך הנתונים החדש ב-BigQuery, ובוחרים את מערך הנתונים הקיים הריק ב-BigQuery באמצעות הפורמט
projectId.datasetId, או יוצרים שם חדש למערך הנתונים. באפשרות הזו אפשר לבחור את השם של מערך הנתונים ב-BigQuery.
אפשרות 1 – יצירה אוטומטית של מערך נתונים ב-BigQuery (ברירת מחדל)
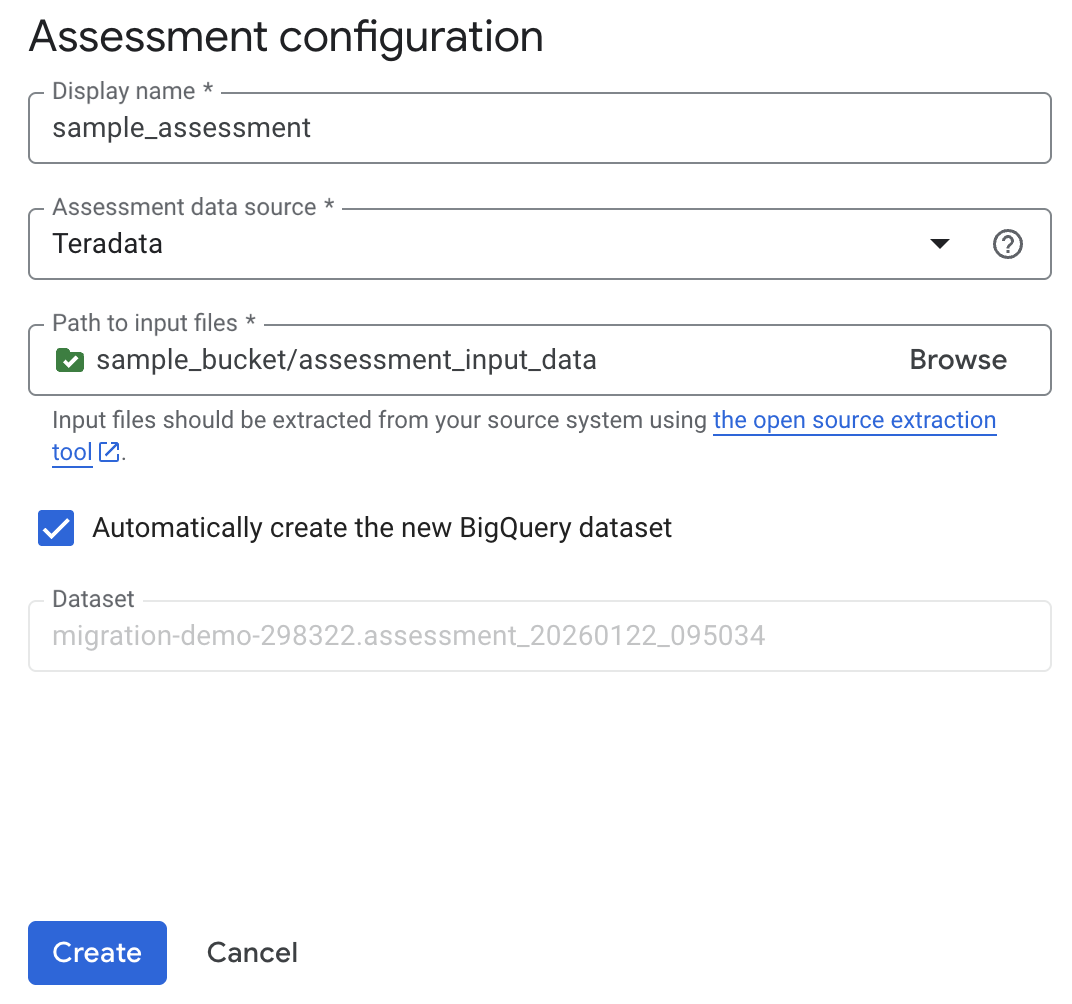
אפשרות 2 – יצירה ידנית של מערך נתונים ב-BigQuery:
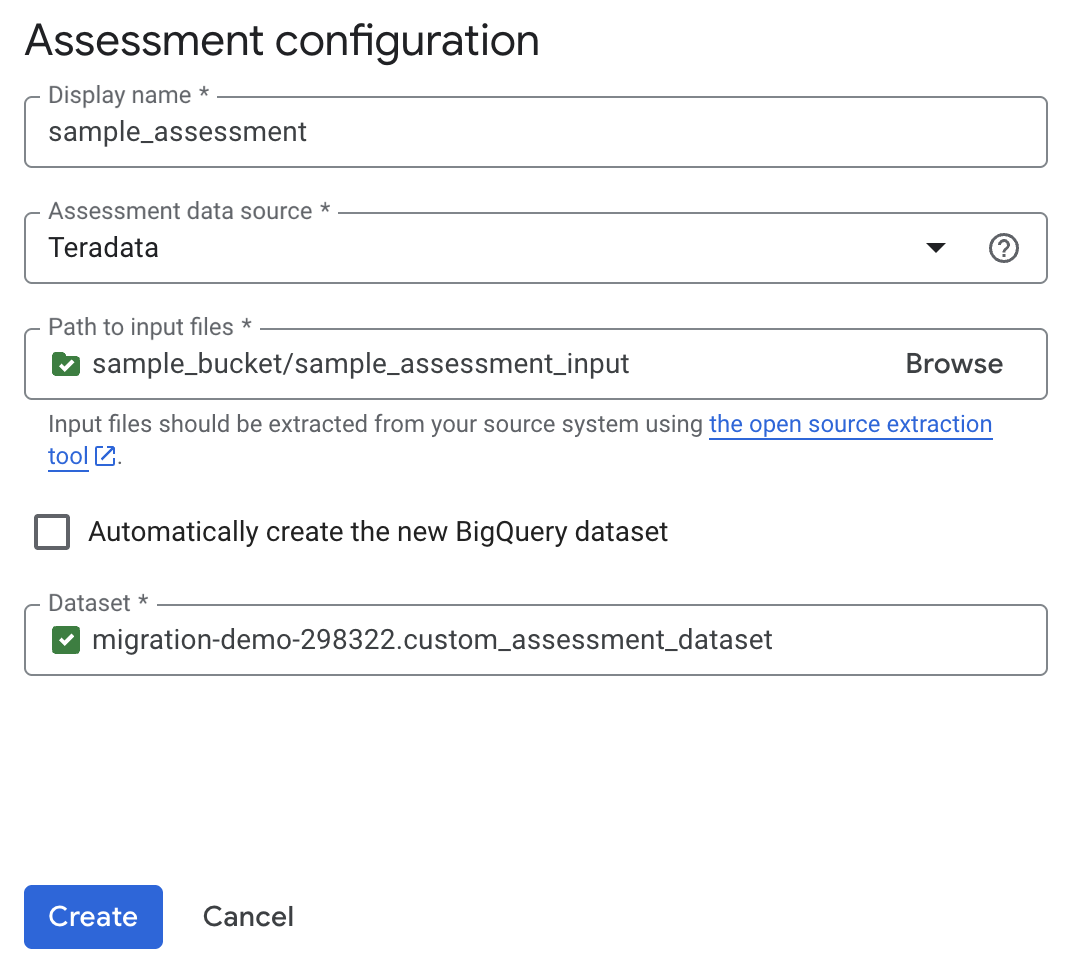
לוחצים על יצירה. אפשר לראות את הסטטוס של המשרה ברשימת משרות ההערכה.
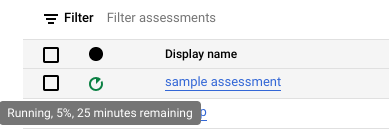
בזמן שההערכה פועלת, אפשר לבדוק את ההתקדמות שלה ואת הזמן המשוער לסיום בכלי הטיפ של סמל הסטטוס.
בזמן שההערכה פועלת, אפשר ללחוץ על הקישור View report ברשימת משימות ההערכה כדי לראות את דוח ההערכה עם נתונים חלקיים ב-Data Studio. יכול להיות שיעבור זמן מה עד שהקישור View report יופיע בזמן שההערכה פועלת. הדוח ייפתח בכרטיסייה חדשה.
הדוח מתעדכן בנתונים חדשים כשהם עוברים עיבוד. מרעננים את הכרטיסייה עם הדוח או לוחצים שוב על הצגת הדוח כדי לראות את הדוח המעודכן.
אחרי שההערכה תסתיים, לוחצים על View report (עיון בדוח) כדי לראות את דוח ההערכה המלא ב-Data Studio. הדוח ייפתח בכרטיסייה חדשה.
API
מבצעים קריאה ל-method create עם workflow מוגדר.
לאחר מכן קוראים לשיטה start
כדי להתחיל את תהליך העבודה של ההערכה.
ההערכה יוצרת טבלאות במערך הנתונים ב-BigQuery שיצרתם קודם. אתם יכולים לשלוח שאילתות לגבי הטבלאות והשאילתות שמשמשות במחסן הנתונים הקיים. מידע על קובצי הפלט של התרגום זמין במאמר בנושא כלי לתרגום SQL בכמות גדולה.
תוצאה נצברת של הערכה שאפשר לשתף
במקרה של הערכות של Amazon Redshift, Teradata ו-Snowflake, בנוסף למערך הנתונים ב-BigQuery שנוצר קודם, תהליך העבודה יוצר עוד מערך נתונים קל משקל עם אותו שם, בתוספת הסיומת _shareableRedactedAggregate. מערך הנתונים הזה מכיל נתונים מצטברים מאוד שנגזרים ממערך הנתונים של הפלט, ולא מכיל פרטים אישיים מזהים (PII).
כדי למצוא את מערך הנתונים, לבדוק אותו ולשתף אותו בצורה מאובטחת עם משתמשים אחרים, אפשר לעיין במאמר בנושא שאילתות על טבלאות הפלט של הערכת ההעברה.
התכונה מופעלת כברירת מחדל, אבל אפשר לבטל את ההסכמה לשימוש בה באמצעות ה-API הציבורי.
פרטי ההערכה
כדי להציג את דף הפרטים של ההערכה, לוחצים על השם לתצוגה ברשימת משימות ההערכה.

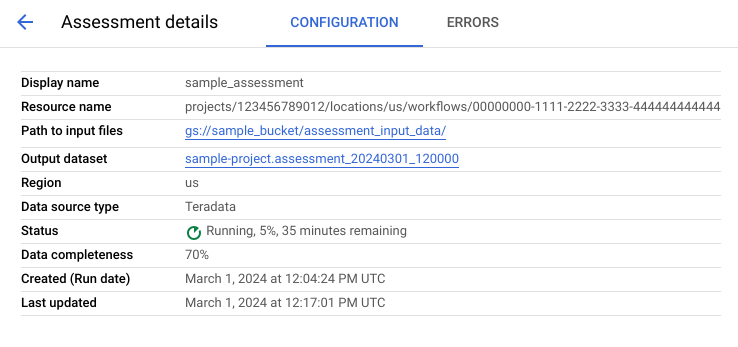
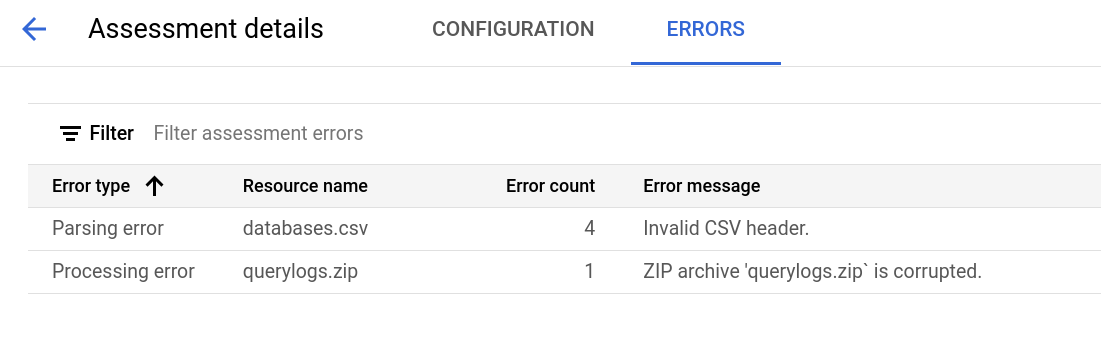
בדף הפרטים של ההערכה יש כרטיסייה בשם הגדרה, שבה אפשר לראות מידע נוסף על עבודת ההערכה, וכרטיסייה בשם שגיאות, שבה אפשר לבדוק אם היו שגיאות במהלך העיבוד של ההערכה.
בכרטיסייה Configuration (הגדרה) אפשר לראות את המאפיינים של ההערכה.
בכרטיסייה שגיאות אפשר לראות את השגיאות שהתרחשו במהלך עיבוד ההערכה.
בדיקה ושיתוף של הדוח ב-Data Studio
אחרי שמסיימים את משימת ההערכה, אפשר ליצור ולשתף דוח של התוצאות ב-Data Studio.
בדיקת הדוח
לוחצים על הקישור View report (הצגת הדוח) שמופיע לצד משימת ההערכה הרצויה. דוח Data Studio ייפתח בכרטיסייה חדשה במצב תצוגה מקדימה. אתם יכולים להשתמש במצב תצוגה מקדימה כדי לבדוק את תוכן הדוח לפני שמשתפים אותו.
הדוח אמור להיראות כמו בצילום המסך הבא:
כדי לראות אילו תצוגות כלולות בדוח, בוחרים במחסן הנתונים:
פתית שלג
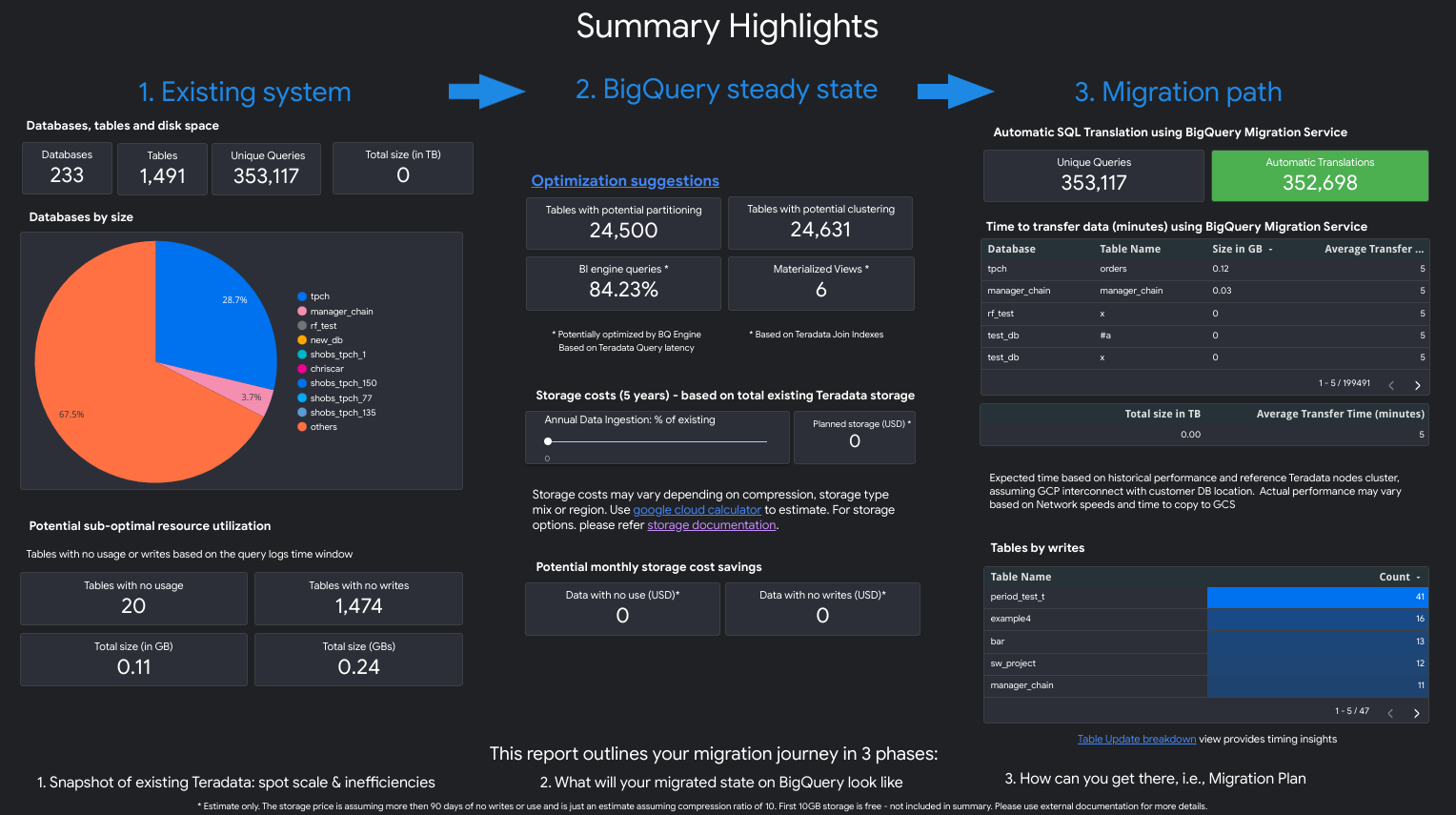
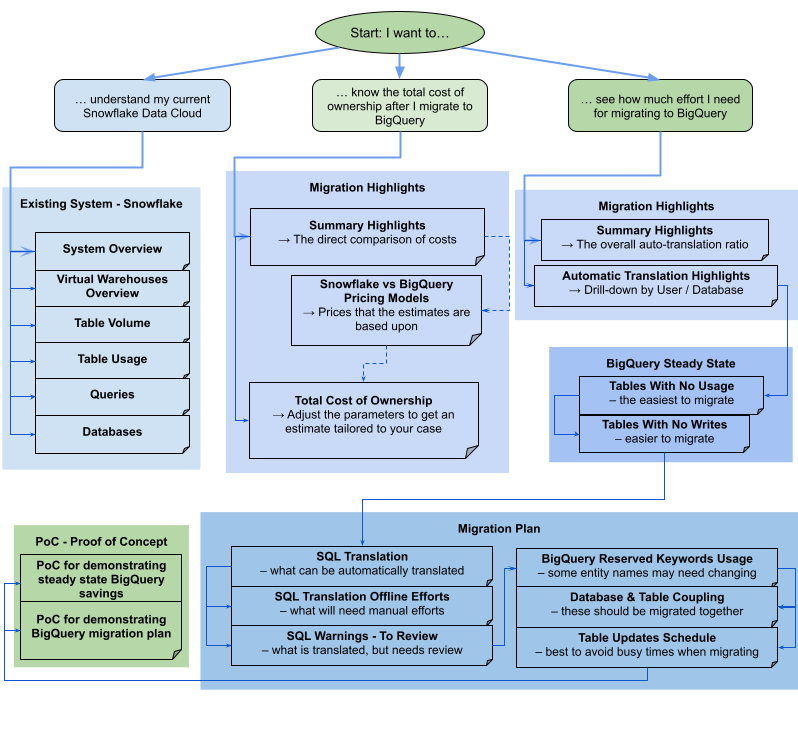
הדוח מורכב מקטעים שונים שאפשר להשתמש בהם בנפרד או ביחד. בתרשים הבא מוצגים שלושה יעדים נפוצים של משתמשים, כדי לעזור לכם להעריך את הצרכים שלכם בתהליך ההעברה:
תצוגות של נקודות מרכזיות בהעברה
הקטע נקודות חשובות בהעברה כולל את התצוגות הבאות:
- מודלים לתמחור ב-Snowflake לעומת BigQuery
- רשימה של התמחור עם רמות או מהדורות שונות. המסמך כולל גם איור שמראה איך התאמה אוטומטית לעומס ב-BigQuery יכולה לעזור לחסוך יותר בעלויות בהשוואה ל-Snowflake.
- עלות הבעלות הכוללת (TCO)
- טבלה אינטראקטיבית שמאפשרת למשתמש להגדיר: מהדורת BigQuery, התחייבות, התחייבות בסיסית ליחידות קיבולת, אחוז האחסון הפעיל ואחוז הנתונים שנטענו או שונו. כך אפשר להעריך טוב יותר את העלות של נרתיקים בהתאמה אישית.
- הדגשים של התרגום האוטומטי
- יחס התרגום המצטבר, מקובץ לפי משתמש או מסד נתונים, מסודר בסדר עולה או יורד. היא כוללת גם את הודעת השגיאה הנפוצה ביותר לגבי תרגום אוטומטי שנכשל.
תצוגות מערכת קיימות
הקטע מערכת קיימת מכיל את התצוגות הבאות:
- סקירה כללית של המערכת
- בתצוגה System Overview (סקירה כללית של המערכת) מוצגים מדדי הנפח ברמה גבוהה של הרכיבים העיקריים במערכת הקיימת, לתקופה מסוימת. ציר הזמן שנבדק תלוי ביומנים שנותחו על ידי כלי ההערכה להעברה של BigQuery. בתצוגה הזו אפשר לקבל תובנות מהירות לגבי השימוש במחסן הנתונים של המקור, שאפשר להשתמש בהן לתכנון ההעברה.
- סקירה כללית של מחסנים וירטואליים
- העלות של Snowflake לפי מחסן, וגם שינוי קנה המידה מחדש על בסיס צומת במהלך התקופה.
- נפח הטבלה
- בתצוגה Table Volume (נפח הטבלה) מוצגים נתונים סטטיסטיים על הטבלאות ומסדי הנתונים הגדולים ביותר שנמצאו על ידי כלי ההערכה של BigQuery לצורך מיגרציה. יכול להיות שייקח יותר זמן לחלץ טבלאות גדולות ממערכת מחסן הנתונים של מקור הנתונים, ולכן התצוגה הזו יכולה לעזור בתכנון ובסדר הפעולות של ההעברה.
- שימוש בטבלה
- בתצוגה 'שימוש בטבלה' מוצגים נתונים סטטיסטיים לגבי הטבלאות שנעשה בהן שימוש רב במערכת של מחסן הנתונים של המקור. טבלאות שנמצאות בשימוש רב יכולות לעזור לכם להבין אילו טבלאות עשויות להכיל הרבה תלויות ולדרוש תכנון נוסף במהלך תהליך ההעברה.
- שאילתות
- בתצוגה 'שאילתות' מוצג פירוט של סוגי הצהרות ה-SQL שבוצעו ונתונים סטטיסטיים על השימוש בהן. אפשר להשתמש בהיסטוגרמה של סוג השאילתה והזמן כדי לזהות תקופות של ניצול נמוך של המערכת וזמנים אופטימליים במהלך היום להעברת נתונים. אפשר גם להשתמש בתצוגה הזו כדי לזהות שאילתות שמופעלות לעיתים קרובות ואת המשתמשים שמפעילים את ההרצות האלה.
- מסדי נתונים
- בתצוגה 'מסדי נתונים' מוצגים מדדים לגבי הגודל, הטבלאות, התצוגות והפרוצדורות שמוגדרים במערכת של מחסן הנתונים של מקור הנתונים. בתצוגה הזו אפשר לקבל תובנות לגבי נפח האובייקטים שצריך להעביר.
BigQuery steady state views
הקטע BigQuery steady state כולל את התצוגות הבאות:
- טבלאות ללא שימוש
- בתצוגה 'טבלאות ללא שימוש' מוצגות טבלאות שבהן לא נמצא שימוש במהלך התקופה שצוינה ביומנים שנותחו במסגרת ההערכה של ההעברה ל-BigQuery. הנתונים האלה יכולים להצביע על טבלאות שאולי לא צריך להעביר ל-BigQuery במהלך ההעברה, או שהעלויות של אחסון הנתונים ב-BigQuery יכולות להיות נמוכות יותר. חשוב לאמת את רשימת הטבלאות שלא נעשה בהן שימוש, כי יכול להיות שהשימוש בהן לא נכלל בתקופת היומנים שנותחו, למשל טבלה שנעשה בה שימוש רק פעם ברבעון או במחצית השנה.
- טבלאות ללא פעולות כתיבה
- בתצוגה 'טבלאות ללא פעולות כתיבה' מוצגות טבלאות שבהן כלי ההערכה של ההעברה ל-BigQuery לא מצא עדכונים במהלך התקופה שבה נותחו היומנים. זה יכול להצביע על כך שהעלויות של אחסון נתונים ב-BigQuery יכולות להיות נמוכות יותר.
תצוגות של תוכנית ההעברה
הקטע תוכנית ההעברה בדוח מכיל את התצוגות הבאות:
- תרגום SQL
- בתצוגה 'תרגום SQL' מפורטים מספר השאילתות שהומרו אוטומטית על ידי כלי ההערכה של BigQuery Migration, ופרטים לגביהן. לא נדרשת התערבות ידנית לגבי השאילתות האלה. בדרך כלל, אם מספקים מטא-נתונים, שיעורי התרגום של תרגום אוטומטי של SQL הם גבוהים. התצוגה הזו אינטראקטיבית ומאפשרת ניתוח של שאילתות נפוצות ושל האופן שבו הן מתורגמות.
- תרגום SQL ללא חיבור לאינטרנט
- בתצוגה Offline Effort אפשר לראות את האזורים שבהם נדרבת התערבות ידנית, כולל UDF ספציפיות והפרות פוטנציאליות של מבנה לקסיקלי ותחביר בטבלאות או בעמודות.
- אזהרות SQL – לבדיקה
- בתצוגה 'אזהרות לבדיקה' מוצגים האזורים שתורגמו ברובם, אבל נדרשת בדיקה אנושית.
- מילות מפתח שמורות ב-BigQuery
- בתצוגה BigQuery Reserved Keywords מוצג השימוש במילות מפתח שזוהו, שיש להן משמעות מיוחדת בשפת GoogleSQL, ואי אפשר להשתמש בהן כמזהים אלא אם הן מוקפות בתווי גרש הפוך (
`). - צימוד של מסד נתונים וטבלה
- בתצוגה Database Coupling מוצגת סקירה כללית של מסדי נתונים וטבלאות שמתבצעת אליהם גישה יחד בשאילתה אחת. בתצוגה הזו אפשר לראות אילו טבלאות ומסדי נתונים מוזכרים לעיתים קרובות, ואילו אפשר להשתמש בהם לתכנון העברה.
- לוח הזמנים לעדכוני הטבלאות
- בתצוגה 'לוח הזמנים לעדכוני הטבלאות' אפשר לראות מתי הטבלאות מתעדכנות ובאיזו תדירות, כדי לתכנן איך ומתי להעביר אותן.
צפיות בהוכחת היתכנות
הקטע PoC (הוכחת היתכנות) מכיל את התצוגות הבאות:
- הוכחת היתכנות (PoC) להדגמת חיסכון במצב יציב ב-BigQuery
- כולל את השאילתות הכי תדירות, השאילתות שקוראות הכי הרבה נתונים, השאילתות הכי איטיות והטבלאות שהושפעו מהשאילתות האלה.
- הוכחת היתכנות להדגמת תוכנית העברה ל-BigQuery
- הסבר על האופן שבו BigQuery מתרגם את השאילתות המורכבות ביותר ועל הטבלאות שהן משפיעות עליהן.
Teradata
הדוח הוא סיפור בן שלושה חלקים, שמתחיל בדף סיכום עם נקודות חשובות. הדף הזה כולל את הקטעים הבאים:
- מערכת קיימת. הקטע הזה הוא תמונת מצב של מערכת Teradata הקיימת והשימוש בה, כולל מספר מסדי הנתונים, הסכימות, הטבלאות והגודל הכולל ב-TB. הוא גם מפרט את הסכימות לפי גודל ומצביע על ניצול משאבים פוטנציאלי לא אופטימלי (טבלאות ללא פעולות כתיבה או עם מעט פעולות קריאה).
- טרנספורמציות של מצב יציב ב-BigQuery (הצעות). בקטע הזה מוצג איך המערכת תיראה ב-BigQuery אחרי ההעברה. הוא כולל הצעות לאופטימיזציה של עומסי עבודה ב-BigQuery (ולמניעת בזבוז).
- תוכנית מיגרציה בקטע הזה מפורט מידע על מאמצי המיגרציה עצמה – למשל, המעבר מהמערכת הקיימת למצב היציב של BigQuery. בקטע הזה מופיע מספר השאילתות שתורגמו באופן אוטומטי, והזמן הצפוי להעברת כל טבלה ל-BigQuery.
הפרטים של כל קטע כוללים את המידע הבא:
מערכת קיימת
- חישובים ושאילתות
- ניצול המעבד (CPU):
- מפת חום של ממוצע ניצול המעבד לפי שעה (תצוגת ניצול משאבי המערכת הכוללת)
- שאילתות לפי שעה ויום עם ניצול CPU
- שאילתות לפי סוג (קריאה/כתיבה) עם ניצול יחידת העיבוד המרכזית (CPU)
- אפליקציות עם ניצול CPU
- שכבת-על של ניצול ה-CPU לפי שעה עם ביצועי שאילתות ממוצעים לפי שעה וביצועי אפליקציות ממוצעים לפי שעה
- היסטוגרמה של שאילתות לפי סוג ומשך שאילתות
- תצוגת פרטי האפליקציות (אפליקציה, משתמש, שאילתות ייחודיות, פירוט של דיווח לעומת ETL)
- ניצול המעבד (CPU):
- סקירה כללית של האחסון
- מסדי נתונים לפי נפח, צפיות ושיעורי גישה
- טבלאות עם שיעורי גישה לפי משתמשים, שאילתות, פעולות כתיבה ויצירות של טבלאות זמניות
- אפליקציות: שיעורי גישה וכתובות IP
טרנספורמציות של מצב יציב ב-BigQuery (הצעות)
- אינדקסים של הצטרפות שהומרו לתצוגות מהותיות
- אשכולות וחלוקה למחיצות של מועמדים על סמך מטא-נתונים ושימוש
- שאילתות עם זמן אחזור נמוך שזוהו כמועמדות לשימוש ב-BigQuery BI Engine
- עמודות שהוגדרו להן ערכי ברירת מחדל באמצעות התכונה של תיאור העמודה לאחסון ערכי ברירת מחדל
- אינדקסים ייחודיים ב-Teradata (כדי למנוע שורות עם מפתחות לא ייחודיים בטבלה) משתמשים בטבלאות זמניות ובמשפט
MERGEכדי להוסיף רק רשומות ייחודיות לטבלאות היעד, ואז למחוק את הכפילויות. - שאילתות וסכימה שנותרו מתורגמות כמו שהן
תוכנית העברה
- תצוגה מפורטת עם שאילתות שתורגמו אוטומטית
- מספר השאילתות הכולל עם אפשרות סינון לפי משתמש, אפליקציה, טבלאות מושפעות, טבלאות שנשאלו עליהן שאלות וסוג השאילתה
- שאילתות עם דפוסים דומים מקובצות ומוצגות יחד, כדי שהמשתמש יוכל לראות את עקרונות התרגום לפי סוגי שאילתות
- שאילתות שנדרשת לגביהן התערבות אנושית
- שאילתות עם הפרות של המבנה הלקסיקלי של BigQuery
- פונקציות ונהלים שמוגדרים על ידי המשתמש
- מילות מפתח שמורות ב-BigQuery
- טבלאות של לוחות זמנים לפי פעולות כתיבה וקריאה (כדי לקבץ אותן להעברה)
- העברת נתונים באמצעות שירות העברת הנתונים ל-BigQuery: הזמן המשוער להעברה לפי טבלה
הקטע מערכת קיימת מכיל את התצוגות הבאות:
- סקירה כללית של המערכת
- בתצוגה System Overview (סקירה כללית של המערכת) מוצגים מדדי הנפח ברמה גבוהה של הרכיבים העיקריים במערכת הקיימת לתקופה מסוימת. ציר הזמן שנבדק תלוי ביומנים שנותחו על ידי כלי ההערכה של המיגרציה ל-BigQuery. בתצוגה הזו אפשר לקבל במהירות תובנות לגבי השימוש במחסן נתונים של מקור, שאפשר להשתמש בהן לתכנון העברה.
- נפח הטבלה
- בתצוגה Table Volume (נפח הטבלה) מוצגים נתונים סטטיסטיים על הטבלאות ומסדי הנתונים הגדולים ביותר שנמצאו על ידי הערכת ההעברה של BigQuery. יכול להיות שייקח יותר זמן לחלץ טבלאות גדולות ממערכת מחסן נתונים של מקור, ולכן התצוגה הזו יכולה לעזור בתכנון ובסדר הפעולות של ההעברה.
- שימוש בטבלה
- בתצוגה 'שימוש בטבלה' מוצגים נתונים סטטיסטיים לגבי הטבלאות שנעשה בהן שימוש רב במערכת של מחסן הנתונים של המקור. טבלאות שנמצאות בשימוש רב יכולות לעזור לכם להבין אילו טבלאות עשויות להכיל הרבה תלויות ולדרוש תכנון נוסף במהלך תהליך ההעברה.
- אפליקציות
- בתצוגה Applications Usage (שימוש באפליקציות) ובתצוגה Applications Patterns (דפוסי שימוש באפליקציות) מוצגים נתונים סטטיסטיים על אפליקציות שנמצאו במהלך עיבוד היומנים. בתצוגות האלה המשתמשים יכולים להבין את השימוש באפליקציות ספציפיות לאורך זמן ואת ההשפעה על השימוש במשאבים. במהלך ההעברה, חשוב להמחיש את ההטמעה והצריכה של הנתונים כדי להבין טוב יותר את התלות של מחסן הנתונים, ולנתח את ההשפעה של העברת אפליקציות שונות שתלויות זו בזו יחד. טבלת כתובות ה-IP יכולה לעזור לכם לזהות את האפליקציה המדויקת שמשתמשת במחסן הנתונים דרך חיבורי JDBC.
- שאילתות
- בתצוגה Queries (שאילתות) מוצג פירוט של סוגי הצהרות SQL שהופעלו וסטטיסטיקות של השימוש בהן. אתם יכולים להשתמש בהיסטוגרמה של סוג השאילתה והזמן כדי לזהות תקופות של ניצול נמוך של המערכת, ואת השעות האופטימליות ביום להעברת נתונים. אפשר גם להשתמש בתצוגה הזו כדי לזהות שאילתות שמופעלות לעיתים קרובות ואת המשתמשים שמפעילים את ההרצות האלה.
- מסדי נתונים
- בתצוגה 'מסדי נתונים' מוצגים מדדים לגבי הגודל, הטבלאות, התצוגות והפרוצדורות שמוגדרים במערכת של מחסן הנתונים של מקור הנתונים. התצוגה הזו יכולה לספק תובנות לגבי נפח האובייקטים שצריך להעביר.
- צימוד מסד נתונים
- בתצוגה Database Coupling מוצגת סקירה כללית של מסדי נתונים וטבלאות שמתבצעת אליהם גישה יחד בשאילתה אחת. בתצוגה הזו אפשר לראות אילו טבלאות ומסדי נתונים מוזכרים לעיתים קרובות, ואילו אפשר להשתמש בהם לתכנון העברה.
הקטע BigQuery steady state כולל את התצוגות הבאות:
- טבלאות ללא שימוש
- בתצוגה 'טבלאות ללא שימוש' מוצגות טבלאות שבהן לא נמצא שימוש במהלך התקופה שצוינה ביומנים שנותחו במסגרת ההערכה של המיגרציה ל-BigQuery. אם אין שימוש בטבלה מסוימת, יכול להיות שלא צריך להעביר אותה ל-BigQuery במהלך ההעברה, או שהעלויות של אחסון הנתונים ב-BigQuery יכולות להיות נמוכות יותר. כדאי לאמת את רשימת הטבלאות שלא נעשה בהן שימוש, כי יכול להיות שהיה בהן שימוש מחוץ לתקופת היומנים, למשל טבלה שנעשה בה שימוש רק פעם בשלושה או שישה חודשים.
- טבלאות ללא פעולות כתיבה
- בתצוגה 'טבלאות ללא פעולות כתיבה' מוצגות טבלאות שבהן כלי ההערכה של ההעברה ל-BigQuery לא מצא עדכונים במהלך התקופה שבה נותחו היומנים. היעדר כתיבות יכול להצביע על מקומות שבהם אפשר להקטין את עלויות האחסון ב-BigQuery.
- שאילתות עם זמן אחזור נמוך
- בתצוגה 'שאילתות עם זמן אחזור נמוך' מוצגת התפלגות של זמני הריצה של השאילתות על סמך נתוני היומן שנותחו. אם בתרשים של התפלגות משך השאילתה מוצג מספר גדול של שאילתות עם זמן ריצה של פחות משנייה, כדאי להפעיל את BigQuery BI Engine כדי להאיץ את ה-BI ועומסי עבודה אחרים עם חביון נמוך.
- תצוגות מהותיות
- התצוגה הממומשת מספקת הצעות נוספות לאופטימיזציה כדי לשפר את הביצועים ב-BigQuery.
- חלוקה למחיצות (partitioning) וסידור באשכולות
בתצוגה 'חלוקה למחיצות (partitioning) ואשכולות' מוצגות טבלאות שיכולות להפיק תועלת מחלוקה למחיצות, מקיבוץ לאשכולות או משניהם.
ההצעות למטא-נתונים מתקבלות על ידי ניתוח הסכימה של מחסן הנתונים של המקור (כמו חלוקה למחיצות ומפתח ראשי בטבלת המקור) ומציאת המקבילה הקרובה ביותר ב-BigQuery כדי להשיג מאפייני אופטימיזציה דומים.
ההצעות לעומסי עבודה מתקבלות על ידי ניתוח של יומני השאילתות של המקור. ההמלצה נקבעת על סמך ניתוח של עומסי העבודה, במיוחד סעיפים של
WHEREאוJOINביומני השאילתות המנותחים.- המלצה על אשכול
בתצוגה 'חלוקה למחיצות' מוצגות טבלאות שעשויות להכיל יותר מ-10,000 מחיצות, בהתאם להגדרת אילוץ החלוקה למחיצות. הטבלאות האלה מתאימות בדרך כלל לאשכולות BigQuery, שמאפשרים חלוקה מפורטת של הטבלאות למחיצות.
- מגבלות ייחודיות
בתצוגה Unique Constraints (אילוצי ייחודיות) מוצגות גם טבלאות
SETוגם אינדקסים ייחודיים שהוגדרו במחסן נתוני המקור. ב-BigQuery, מומלץ להשתמש בטבלאות זמניות ובמשפטMERGEכדי להוסיף רק רשומות ייחודיות לטבלת היעד. התוכן בתצוגה הזו יכול לעזור לכם להבין אילו טבלאות צריך לשנות ב-ETL במהלך ההעברה.- ערכי ברירת מחדל / אילוצי בדיקה
בתצוגה הזו מוצגות טבלאות שמשתמשות באילוצי בדיקה כדי להגדיר ערכי ברירת מחדל של עמודות. ב-BigQuery, אפשר לעיין במאמר בנושא הגדרת ערכי ברירת מחדל לעמודות.
הקטע נתיב ההעברה בדוח כולל את התצוגות הבאות:
- תרגום SQL
- בתצוגה 'תרגום SQL' מפורטים מספר השאילתות שהומרו אוטומטית על ידי כלי ההערכה של BigQuery Migration, ופרטים לגביהן. לא נדרשת התערבות ידנית לגבי השאילתות האלה. בדרך כלל, אם מספקים מטא-נתונים, שיעורי התרגום של תרגום אוטומטי של SQL הם גבוהים. התצוגה הזו אינטראקטיבית ומאפשרת ניתוח של שאילתות נפוצות ושל האופן שבו הן מתורגמות.
- מאמץ אופליין
- בתצוגה Offline Effort אפשר לראות את האזורים שבהם נדרבת התערבות ידנית, כולל UDF ספציפיות והפרות פוטנציאליות של מבנה לקסיקלי ותחביר בטבלאות או בעמודות.
- מילות מפתח שמורות ב-BigQuery
- בתצוגה BigQuery Reserved Keywords מוצג השימוש במילות מפתח שזוהו, שיש להן משמעות מיוחדת בשפת GoogleSQL, ואי אפשר להשתמש בהן כמזהים אלא אם הן מוקפות בתווי גרש הפוך (
`). - לוח הזמנים לעדכוני הטבלאות
- בתצוגה 'לוח הזמנים לעדכוני הטבלאות' אפשר לראות מתי הטבלאות מתעדכנות וכל כמה זמן, כדי שתוכלו לתכנן איך ומתי להעביר אותן.
- העברת נתונים ל-BigQuery
- בתצוגה 'העברת נתונים ל-BigQuery' מפורט מסלול ההעברה עם הזמן המשוער להעברת הנתונים באמצעות שירות העברת הנתונים ל-BigQuery. מידע נוסף זמין במדריך בנושא שירות העברת נתונים ל-BigQuery עבור Teradata.
הקטע 'נספח' כולל את התצוגות הבאות:
- תלות באותיות רישיות
- בתצוגה Case Sensitivity מוצגות טבלאות במחסן נתונים של מקור שהוגדרו לבצע השוואות שלא תלויות באותיות רישיות. כברירת מחדל, השוואות של מחרוזות ב-BigQuery הן תלויות אותיות רישיות. מידע נוסף זמין במאמר בנושא השוואה.
Redshift
- נקודות חשובות בהעברה
- בתצוגה 'עיקרי המעבר' מוצג סיכום מנהלים של שלושת הקטעים בדוח:
- בחלונית מערכת קיימת מופיע מידע על מספר מסדי הנתונים, הסכימות והטבלאות, ועל הגודל הכולל של מערכת Redshift הקיימת. בנוסף, מוצגות רשימות של הסכימות לפי גודל וניצול פוטנציאלי לא אופטימלי של משאבים. אתם יכולים להשתמש במידע הזה כדי לבצע אופטימיזציה של הנתונים על ידי הסרה, חלוקה למחיצות או קיבוץ לאשכולות של הטבלאות.
- בחלונית BigQuery Steady State מוצג מידע על האופן שבו הנתונים ייראו אחרי ההעברה ב-BigQuery, כולל מספר השאילתות שאפשר לתרגם באופן אוטומטי באמצעות שירות ההעברה ל-BigQuery. בקטע הזה מוצגות גם העלויות של אחסון הנתונים ב-BigQuery על סמך קצב הטמעת הנתונים השנתי, וגם הצעות לאופטימיזציה של טבלאות, הקצאת משאבים ושטח אחסון.
- בחלונית נתיב ההעברה מוצג מידע על מאמצי ההעברה עצמם. בכל טבלה מוצגים הזמן הצפוי להעברה, מספר השורות בטבלה והגודל שלה.
הקטע מערכת קיימת מכיל את התצוגות הבאות:
- שאילתות לפי סוג ותזמון
- בתצוגה 'שאילתות לפי סוג ולוח זמנים' השאילתות מסווגות לקטגוריות ETL/Write ו-Reporting/Aggregation. הצגת תמהיל השאילתות לאורך זמן עוזרת להבין את דפוסי השימוש הקיימים, לזהות שימוש לא רציף וניצול יתר פוטנציאלי של משאבים שיכולים להשפיע על העלות והביצועים.
- הוספת שאילתות לתור
- בתצוגה Query Queuing (הוספת שאילתות לתור) אפשר לראות פרטים נוספים על עומס המערכת, כולל נפח השאילתות, השילוב שלהן וההשפעות על הביצועים כתוצאה מהוספה לתור, כמו משאבים לא מספיקים.
- שאילתות והתאמה לעומס (scaling) של WLM
- בתצוגה Queries and WLM Scaling (שאילתות והתאמת קנה מידה של WLM) מזוהה התאמת קנה מידה של concurrency כעלות נוספת ומורכבות בהגדרות. הוא מראה איך המערכת שלכם ב-Redshift מנתבת שאילתות על סמך הכללים שציינתם, ומה ההשפעות על הביצועים בגלל תורים, שינוי גודל של מספר הפעולות שמתבצעות בו-זמנית ושאילתות שהוצאו מהתור.
- הוספה לרשימת הבאים בתור והמתנה
- התצוגה 'המתנה בתור' מאפשרת לראות את זמני ההמתנה בתור של שאילתות לאורך זמן.
- סיווגים וביצועים של WLM
- התצוגה 'סיווגים של WLM וביצועים' מספקת דרך אופציונלית למפות את הכללים ל-BigQuery. עם זאת, מומלץ לאפשר ל-BigQuery לנתב את השאילתות באופן אוטומטי.
- תובנות לגבי נפח השאילתות והטבלאות
- בתצוגה 'תובנות לגבי נפח השאילתות והטבלאות' מוצגות שאילתות לפי גודל, תדירות ומשתמשים מובילים. הנתונים האלה עוזרים לסווג את מקורות העומס במערכת ולתכנן את העברת עומסי העבודה.
- מסדי נתונים וסכימות
- בתצוגה 'מסדי נתונים וסכימות' מוצגים מדדים לגבי הגודל, הטבלאות, התצוגות והפרוצדורות שמוגדרים במערכת של מחסן נתוני המקור. הנתונים האלה מאפשרים להבין את נפח האובייקטים שצריך להעביר.
- נפח הטבלה
- התצוגה 'נפח הטבלה' מספקת נתונים סטטיסטיים על הטבלאות ומסדי הנתונים הגדולים ביותר, ומראה איך ניגשים אליהם. יכול להיות שייקח יותר זמן לחלץ טבלאות גדולות ממערכת מחסן הנתונים של המקור, ולכן התצוגה הזו עוזרת לתכנן את ההעברה ואת סדר הפעולות.
- שימוש בטבלה
- בתצוגה 'שימוש בטבלה' מוצגים נתונים סטטיסטיים לגבי הטבלאות שנעשה בהן שימוש רב במערכת של מחסן הנתונים של המקור. אפשר להשתמש בטבלאות שנמצאות בשימוש רב כדי להבין אילו טבלאות עשויות להכיל הרבה תלויות, וכדאי לתכנן את ההעברה שלהן בצורה מיוחדת.
- יבואנים ויצואנים
- בתצוגה 'ייבוא וייצוא' אפשר לראות מידע על נתונים ומשתמשים שקשורים לייבוא נתונים (באמצעות שאילתות
COPY) ולייצוא נתונים (באמצעות שאילתותUNLOAD). התצוגה הזו עוזרת לזהות את שכבת הביניים ואת התהליכים שקשורים להעברה ולייצוא. - ניצול האשכול
- בתצוגה Cluster Utilization (ניצול אשכולות) מוצג מידע כללי על כל האשכולות הזמינים ומוצג השימוש ביחידת העיבוד המרכזית (CPU) של כל אשכול. התצוגה הזו יכולה לעזור לכם להבין את רזרבת הקיבולת של המערכת.
הקטע BigQuery steady state כולל את התצוגות הבאות:
- חלוקה למחיצות (partitioning) ואשכולות
בתצוגה 'חלוקה למחיצות (partitioning) ואשכולות' מוצגות טבלאות שיכולות להפיק תועלת מחלוקה למחיצות, מקיבוץ לאשכולות או משניהם.
ההצעות למטא-נתונים מתקבלות על ידי ניתוח הסכימה של מחסן הנתונים של המקור (כמו Sort Key ו-Dist Key בטבלת המקור) ומציאת המקבילה הקרובה ביותר ב-BigQuery כדי להשיג מאפייני אופטימיזציה דומים.
ההצעות לעומס העבודה מתקבלות מניתוח של יומני השאילתות של המקור. ההמלצה נקבעת על סמך ניתוח של עומסי העבודה, במיוחד סעיפים של
WHEREאוJOINביומני השאילתות המנותחים.בתחתית הדף מופיעה הצהרה מתורגמת ליצירת טבלה עם כל האופטימיזציות שסופקו. אפשר גם לחלץ מקבוצת הנתונים את כל הצהרות ה-DDL המתורגמות. הוראות DDL מתורגמות ונשמרות בטבלה
SchemaConversionבעמודהCreateTableDDL.ההמלצות בדוח מוצגות רק לגבי טבלאות גדולות מ-1GB, כי טבלאות קטנות לא יפיקו תועלת מקיבוץ ומחלוקה למחיצות. עם זאת, DDL לכל הטבלאות (כולל טבלאות קטנות מ-1GB) זמין בטבלת
SchemaConversion.- טבלאות ללא שימוש
בתצוגה 'טבלאות ללא שימוש' מוצגות טבלאות שבהן לא זוהה שימוש במהלך התקופה של היומנים המנותחים, במסגרת הערכת ההעברה של BigQuery. אם אין שימוש בטבלה, יכול להיות שלא צריך להעביר אותה ל-BigQuery במהלך ההעברה, או שהעלויות של אחסון הנתונים ב-BigQuery יכולות להיות נמוכות יותר (החיוב הוא על אחסון לטווח ארוך). מומלץ לאמת את רשימת הטבלאות שלא נעשה בהן שימוש, כי יכול להיות שיש בהן שימוש מחוץ לתקופת היומנים, למשל טבלה שנעשה בה שימוש רק פעם אחת כל שלושה או שישה חודשים.
- טבלאות ללא פעולות כתיבה
בתצוגה 'טבלאות ללא פעולות כתיבה' מוצגות טבלאות שבהן לא זוהו עדכונים במהלך תקופת היומנים שנותחו במסגרת הערכת המיגרציה של BigQuery. אם אין פעולות כתיבה, יכול להיות שתוכלו להפחית את עלויות האחסון ב-BigQuery (שמפורטות כאחסון לטווח ארוך).
- BigQuery BI Engine ותצוגות חומריות
הכלי BigQuery BI Engine ותצוגות חומריות מספקים הצעות נוספות לאופטימיזציה כדי לשפר את הביצועים ב-BigQuery.
הקטע נתיב ההעברה כולל את התצוגות הבאות:
- תרגום SQL
- בתצוגה 'תרגום SQL' מפורטים מספר השאילתות שהומרו אוטומטית על ידי כלי ההערכה של BigQuery Migration, ופרטים לגביהן. לא נדרשת התערבות ידנית לגבי השאילתות האלה. בדרך כלל, אם מספקים מטא-נתונים, שיעורי התרגום של תרגום אוטומטי של SQL הם גבוהים.
- תרגום SQL ללא חיבור לאינטרנט
- בתצוגה 'מאמץ תרגום SQL במצב אופליין' מפורטים התחומים שבהם נדרבת התערבות ידנית, כולל פונקציות ספציפיות להגדרת משתמש (UDF) ושאילתות עם אי בהירות פוטנציאלית בתרגום.
- תמיכה ב-Alter Table Append
- The Alter Table Append Support view (תצוגת התמיכה ב-Alter Table Append) מציגה פרטים על מבני SQL נפוצים ב-Redshift שאין להם מקבילה ישירה ב-BigQuery.
- תמיכה בהעתקת פקודות
- בתצוגה 'תמיכה בפקודת העתקה' מוצגים פרטים על מבנים נפוצים של Redshift SQL שאין להם מקבילה ישירה ב-BigQuery.
- אזהרות SQL
- בתצוגה 'אזהרות SQL' מוצגים אזורים שתורגמו בהצלחה, אבל דורשים בדיקה.
- הפרות של תחביר ומבנה לקסיקלי
- בתצוגה Lexical Structure & Syntax Violations (מבנה לקסיקלי והפרות תחביר) מוצגים שמות של עמודות, טבלאות, פונקציות ופרוצדורות שמפירים את התחביר של BigQuery.
- מילות מפתח שמורות ב-BigQuery
- בתצוגה BigQuery Reserved Keywords מוצג השימוש במילות מפתח שזוהו, שיש להן משמעות מיוחדת בשפת GoogleSQL, ואי אפשר להשתמש בהן כמזהים אלא אם הן מוקפות בתווי גרש הפוך (
`). - צימוד סכימה
- בתצוגה Schema Coupling (צימוד סכימה) מוצגת סקירה כללית של מסדי נתונים, סכימות וטבלאות שמתבצעת אליהם גישה יחד בשאילתה אחת. בתצוגה הזו אפשר לראות אילו טבלאות, סכימות ומסדי נתונים מוזכרים לעיתים קרובות, ומה אפשר להשתמש בהם לתכנון העברה.
- לוח הזמנים לעדכוני הטבלאות
- בתצוגה 'לוח הזמנים לעדכוני הטבלאות' אפשר לראות מתי הטבלאות מתעדכנות ומה תדירות העדכון שלהן, כדי שתוכלו לתכנן איך ומתי להעביר אותן.
- קנה מידה של טבלה
- בתצוגה 'קנה מידה של טבלה' מפורטות הטבלאות עם הכי הרבה עמודות.
- העברת נתונים ל-BigQuery
- בתצוגה 'העברת נתונים ל-BigQuery' מפורט נתיב ההעברה עם הזמן הצפוי להעברת הנתונים באמצעות שירות העברת הנתונים ל-BigQuery. מידע נוסף זמין במדריך בנושא שירות העברת נתונים ל-BigQuery עבור Redshift.
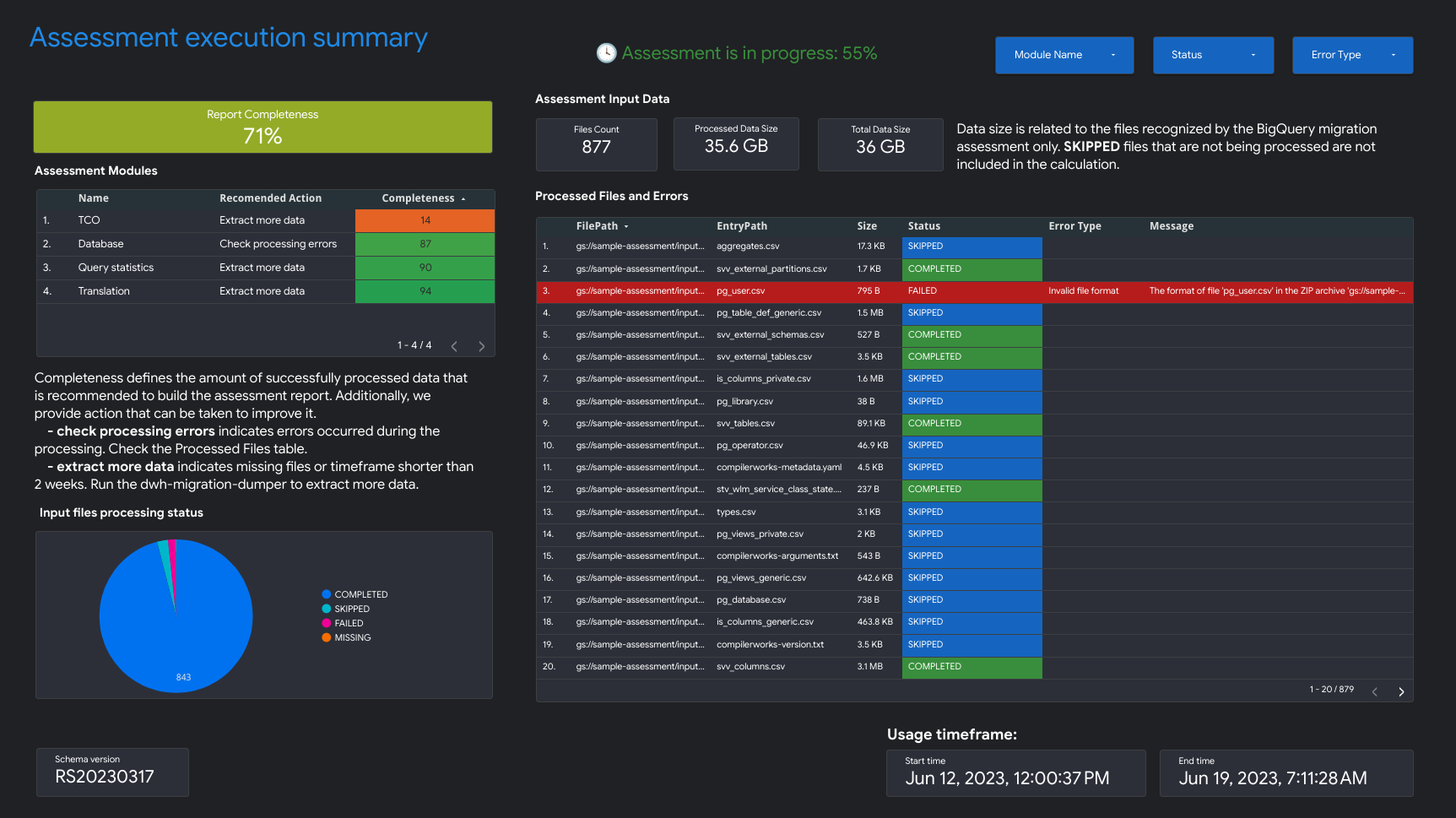
- סיכום של הרצת ההערכה
סיכום הביצוע של ההערכה מכיל את מידת השלמות של הדוח, את התקדמות ההערכה המתבצעת ואת הסטטוס של הקבצים המעובדים והשגיאות.
המדד 'שלמות הדוח' מייצג את אחוז הנתונים שעברו עיבוד בהצלחה, שמומלץ להציג בדוח ההערכה כדי לקבל תובנות משמעותיות. אם חסרים נתונים בקטע מסוים בדוח, המידע הזה יופיע בטבלה Assessment Modules (מודולים להערכה) לצד האינדיקטור Report Completeness (מידת השלמות של הדוח).
מדד ההתקדמות מציין את אחוז הנתונים שעברו עיבוד עד כה, וגם את הזמן שנותר עד לעיבוד כל הנתונים. אחרי שהעיבוד מסתיים, מדד ההתקדמות לא מוצג.
Redshift Serverless
- נקודות חשובות בהעברה
- בדף הדוח הזה מוצג סיכום של מסדי נתונים קיימים של Amazon Redshift Serverless, כולל הגודל ומספר הטבלאות. בנוסף, הוא מספק אומדן ברמה גבוהה של ערך החוזה השנתי (ACV) – העלות של מחשוב ואחסון ב-BigQuery. בתצוגה 'נקודות מרכזיות בהעברה' מוצג תקציר מנהלים של שלושת החלקים בדוח.
בקטע מערכת קיימת יש את התצוגות הבאות:
- מסדי נתונים וסכימות
- פירוט של גודל האחסון הכולל ב-GB לכל מסד נתונים, סכימה או טבלה.
- מסדי נתונים וסכימות חיצוניים
- פירוט של גודל האחסון הכולל ב-GB לכל מסד נתונים חיצוני, סכימה או טבלה.
- ניצול המערכת
- מידע כללי על השימוש ההיסטורי במערכת. בתצוגה הזו מוצג השימוש ההיסטורי ב-RPU (יחידות עיבוד של Amazon Redshift) וצריכת האחסון היומית. התצוגה הזו יכולה לעזור לכם להבין את הקיבולת של המערכת.
בקטע BigQuery Steady State (מצב יציב של BigQuery) מוסבר איך הנתונים ייראו אחרי ההעברה ל-BigQuery, כולל מספר השאילתות שאפשר לתרגם באופן אוטומטי באמצעות שירות ההעברה ל-BigQuery. בקטע הזה מוצגות גם העלויות של אחסון הנתונים ב-BigQuery על סמך קצב הטמעת הנתונים השנתי, יחד עם הצעות לאופטימיזציה של טבלאות, הקצאת משאבים ושטח אחסון. בקטע 'מצב יציב' יש את התצוגות הבאות:
- תמחור ב-Amazon Redshift Serverless לעומת תמחור ב-BigQuery
- השוואה בין מודלים של תמחור ב-Amazon Redshift Serverless וב-BigQuery, כדי להבין את היתרונות ואת החיסכון הפוטנציאלי בעלויות אחרי המעבר ל-BigQuery.
- עלות מחשוב ב-BigQuery (עלות כוללת)
- מאפשרת להעריך את עלות המחשוב ב-BigQuery. יש ארבעה נתונים שצריך להזין ידנית במחשבון: מהדורת BigQuery, אזור, תקופת התחייבות ונתוני בסיס. כברירת מחדל, המחשבון מספק התחייבויות בסיסיות אופטימליות וחסכוניות שאפשר לשנות ידנית.
- עלות הבעלות הכוללת (TCO)
- מאפשרת לכם להעריך את ערך החוזה השנתי (ACV) – העלות של מחשוב ואחסון ב-BigQuery. המחשבון מאפשר גם לחשב את עלות האחסון, שמשתנה בין אחסון פעיל לבין אחסון לטווח ארוך, בהתאם לשינויים בטבלה במהלך התקופה שנותחה. מידע נוסף זמין במאמר בנושא תמחור של אחסון.
התצוגה הזו מופיעה בקטע נספח:
- סיכום הרצת ההערכה
- פרטים על ביצוע ההערכה, כולל רשימת הקבצים שעברו עיבוד, השגיאות ומידת השלמות של הדוח. בדף הזה אפשר לבדוק למה חסרים נתונים בדוח, ולהבין טוב יותר את מידת השלמות של הדוח.
Oracle / Oracle Exadata
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bq-edw-migration-support@google.com.
נקודות חשובות בהעברה
הקטע נקודות חשובות בהעברה כולל את התצוגות הבאות:
- מערכת קיימת: תמונת מצב של מערכת Oracle הקיימת והשימוש בה, כולל מספר מסדי הנתונים, הסכימות, הטבלאות והגודל הכולל ב-GB. הכלי גם מספק סיכום של סיווג עומסי העבודה לכל מסד נתונים, כדי לעזור לכם להחליט אם BigQuery הוא יעד ההעברה הנכון.
- תאימות: מספק מידע על מאמץ ההעברה עצמו. לכל מסד נתונים שמנותח, מוצג משך הזמן הצפוי להעברה ומספר האובייקטים במסד הנתונים שאפשר להעביר באופן אוטומטי באמצעות כלים שסופקו על ידי Google.
- מצב יציב של BigQuery: מכיל מידע על האופן שבו הנתונים ייראו אחרי ההעברה ל-BigQuery, כולל העלויות של אחסון הנתונים ב-BigQuery על סמך קצב הטמעת הנתונים השנתי והערכת עלות החישוב. בנוסף, הוא מספק תובנות לגבי טבלאות שלא נעשה בהן שימוש מספיק.
מערכת קיימת
הקטע מערכת קיימת מכיל את התצוגות הבאות:
- מאפיין עומסי העבודה: מתאר את סוג עומס העבודה של כל מסד נתונים על סמך מדדי הביצועים שנותחו. כל מסד נתונים מסווג כ-OLAP, Mixed או OLTP. המידע הזה יכול לעזור לכם להחליט אילו מסדי נתונים אפשר להעביר ל-BigQuery.
- מסדי נתונים וסכימות: פירוט של גודל האחסון הכולל ב-GB לכל מסד נתונים, סכימה או טבלה. בנוסף, אפשר להשתמש בתצוגה הזו כדי לזהות תצוגות חומריות וטבלאות חיצוניות.
- תכונות וקישורים של מסד הנתונים: מציג את רשימת התכונות של Oracle שנעשה בהן שימוש במסד הנתונים, יחד עם התכונות או השירותים המקבילים של BigQuery שאפשר להשתמש בהם אחרי ההעברה. בנוסף, אפשר לעיין בקישורי מסד הנתונים כדי להבין טוב יותר את הקשרים בין מסדי הנתונים.
- חיבורים למסד נתונים: מספק תובנות לגבי סשנים במסד הנתונים שהתחילו על ידי המשתמש או האפליקציה. ניתוח הנתונים האלה יכול לעזור לכם לזהות אפליקציות חיצוניות שעשויות לדרוש מאמץ נוסף במהלך ההעברה.
- סוגי שאילתות: פירוט של סוגי הצהרות ה-SQL שהופעלו ונתונים סטטיסטיים על השימוש בהן. אתם יכולים להשתמש בהיסטוגרמה השעתית של Query Executions (ביצועי שאילתות) או Query CPU Time (זמן מעבד של שאילתות) כדי לזהות תקופות של ניצול נמוך של המערכת ואת השעות האופטימליות ביום להעברת נתונים.
- קוד מקור של PL/SQL: מספק תובנות לגבי אובייקטים של PL/SQL, כמו פונקציות או פרוצדורות, והגודל שלהם לכל מסד נתונים וסכימה. בנוסף, אפשר להשתמש בהיסטוגרמה של ההרצות השעתיות כדי לזהות את שעות השיא עם הכי הרבה הרצות של PL/SQL.
- ניצול המערכת: מידע כללי על ניצול המערכת לאורך זמן. בתצוגה הזו מוצג השימוש במעבד לפי שעה וצריכת נפח האחסון לפי יום. התצוגה הזו יכולה לעזור להבין את רזרבת הקיבולת של המערכת.
מצב יציב ב-BigQuery
הקטע BigQuery Steady State מכיל את התצוגות הבאות:
- תמחור של Exadata לעומת BigQuery: השוואה כללית של מודלים לתמחור של Exadata ו-BigQuery, כדי להבין את היתרונות ואת החיסכון הפוטנציאלי בעלויות אחרי המעבר ל-BigQuery.
- קריאות וכתיבות במסד נתונים של BigQuery: מספק תובנות לגבי פעולות הדיסק הפיזי של מסד הנתונים. ניתוח הנתונים האלה יכול לעזור לכם למצוא את הזמן הכי טוב להעברת נתונים מ-Oracle ל-BigQuery.
- עלות מחשוב ב-BigQuery: מאפשרת להעריך את עלות המחשוב ב-BigQuery. יש ארבעה נתונים שצריך להזין ידנית במחשבון: מהדורת BigQuery, אזור, תקופת התחייבות ונתוני בסיס. כברירת מחדל, המחשבון מספק התחייבות בסיסית אופטימלית ומשתלמת שאפשר לשנות באופן ידני. הערך של Annual Autoscaling Slot Hours (שעות שימוש שנתיות בהקצאת משאבים דינמית) מציין את מספר שעות השימוש בהקצאת משאבים דינמית שלא נכללות בהתחייבות. הערך הזה מחושב לפי ניצול המערכת. הסבר ויזואלי על הקשר בין נתוני הבסיס, התאמה אוטומטית לעומס והניצול מופיע בסוף הדף. בכל הערכה מוצג המספר הסביר וטווח הערכה.
- עלות הבעלות הכוללת (TCO): מאפשרת להעריך את ערך החוזה השנתי (ACV) – העלות של מחשוב ואחסון ב-BigQuery. במחשבון אפשר גם לחשב את עלות האחסון. המחשבון מאפשר גם לחשב את עלות האחסון, שמשתנה בין אחסון פעיל לבין אחסון לטווח ארוך, בהתאם לשינויים בטבלה במהלך תקופת הניתוח. מידע נוסף על תמחור האחסון
- טבלאות שלא נעשה בהן שימוש מספיק: מספק מידע על טבלאות שלא נעשה בהן שימוש ועל טבלאות לקריאה בלבד, על סמך מדדי השימוש מתקופת הזמן שנותחה. אם אין שימוש בטבלה, יכול להיות שלא צריך להעביר אותה ל-BigQuery במהלך ההעברה, או שהעלויות של אחסון הנתונים ב-BigQuery יכולות להיות נמוכות יותר (חיוב על אחסון לטווח ארוך). מומלץ לאמת את רשימת הטבלאות שלא נעשה בהן שימוש, למקרה שהן בשימוש מחוץ לתקופת הזמן שנותחה.
הצעות להעברה
הקטע הצעות להעברה כולל את התצוגות הבאות:
- תאימות של אובייקטים במסד נתונים: סקירה כללית של התאימות של אובייקטים במסד נתונים ל-BigQuery, כולל מספר האובייקטים שאפשר להעביר באופן אוטומטי באמצעות כלים שסופקו על ידי Google או שנדרשת פעולה ידנית כדי להעביר אותם. המידע הזה מוצג לכל מסד נתונים, סכימה וסוג של אובייקט במסד הנתונים.
- מאמץ להעברת אובייקטים של מסד נתונים: מוצגת הערכה של מאמץ ההעברה בשעות לכל מסד נתונים, סכימה או סוג אובייקט של מסד נתונים. בנוסף, מוצג אחוז האובייקטים הקטנים, הבינוניים והגדולים על סמך מאמץ ההעברה.
- מאמץ להעברת סכימת מסד הנתונים: מספק את הרשימה של כל סוגי האובייקטים במסד הנתונים שזוהו, את המספר שלהם, את התאימות שלהם ל-BigQuery ואת מאמץ ההעברה המשוער בשעות.
- פירוט מאמץ ההעברה של סכימת מסד הנתונים: מספק מידע מעמיק יותר לגבי מאמץ ההעברה של סכימת מסד הנתונים, כולל המידע על כל אובייקט בודד.
צפיות בהוכחת היתכנות
הקטע תצוגות הוכחת היתכנות כולל את התצוגות הבאות:
- העברה של הוכחת היתכנות: מציגה את רשימת מסדי הנתונים המוצעים עם מאמץ ההעברה הנמוך ביותר, שהם מועמדים טובים להעברה ראשונית. בנוסף, מוצגות השאילתות המובילות שיכולות לעזור להדגים את החיסכון בזמן ובעלויות, ואת הערך של BigQuery באמצעות הוכחת היתכנות.
נספח
הקטע נספח מכיל את התצוגות הבאות:
- סיכום הביצוע של ההערכה: מספק את פרטי הביצוע של ההערכה, כולל רשימת הקבצים שעברו עיבוד, השגיאות ומידת השלמות של הדוח. בדף הזה אפשר לבדוק נתונים חסרים בדוח ולהבין טוב יותר את מידת השלמות של הדוח.
Apache Hive
הדוח מורכב מסיפור בן שלושה חלקים, ולפניו דף סיכום עם נקודות מרכזיות שכולל את הקטעים הבאים:
מערכת קיימת – Apache Hive. בקטע הזה מוצג צילום מצב של מערכת Apache Hive ושל השימוש בה, כולל מספר מסדי הנתונים, הטבלאות, הגודל הכולל שלהם ב-GB ומספר יומני השאילתות שעברו עיבוד. בקטע הזה מפורטים גם מסדי הנתונים לפי גודל, ומוצגות נקודות שבהן יכול להיות שהשימוש במשאבים לא אופטימלי (טבלאות ללא פעולות כתיבה או עם מעט פעולות קריאה) והקצאת משאבים. הפרטים בקטע הזה כוללים את המידע הבא:
- חישובים ושאילתות
- ניצול המעבד (CPU):
- שאילתות לפי שעה ויום עם ניצול CPU
- שאילתות לפי סוג (קריאה/כתיבה)
- תורים ואפליקציות
- שכבת-על של ניצול ה-CPU לפי שעה עם ביצועי שאילתות ממוצעים לפי שעה וביצועי אפליקציות ממוצעים לפי שעה
- היסטוגרמה של שאילתות לפי סוג ומשך השאילתה
- דף ההמתנה וההוספה לרשימת ההמתנה
- תצוגה מפורטת של תורים (תור, משתמש, שאילתות ייחודיות, פירוט של דיווח לעומת ETL, לפי מדדים)
- ניצול המעבד (CPU):
- סקירה כללית בנושא אחסון
- מסדי נתונים לפי נפח, צפיות ושיעורי גישה
- טבלאות עם שיעורי גישה לפי משתמשים, שאילתות, פעולות כתיבה ויצירות של טבלאות זמניות
- תורים ואפליקציות: שיעורי גישה וכתובות IP של לקוחות
- חישובים ושאילתות
BigQuery Steady State בקטע הזה מוצג איך המערכת תיראה ב-BigQuery אחרי ההעברה. הוא כולל הצעות לאופטימיזציה של עומסי עבודה ב-BigQuery (ולמניעת בזבוז). הפרטים בקטע הזה כוללים את המידע הבא:
- טבלאות שמזוהות כמועמדות לתצוגות חומריות.
- אשכולות וחלוקה למחיצות של מועמדים על סמך מטא-נתונים ושימוש.
- שאילתות עם זמן אחזור נמוך שזוהו כמועמדות לשימוש ב-BigQuery BI Engine.
- טבלאות ללא שימוש בקריאה או בכתיבה.
- טבלאות מחולקות למחיצות עם חלוקת נתונים לא מאוזנת (partition skew).
תוכנית העברה בקטע הזה מפורט מידע על מאמצי ההעברה עצמם. לדוגמה, המעבר מהמערכת הקיימת למצב יציב ב-BigQuery. בקטע הזה מפורטים יעדי האחסון שזוהו לכל טבלה, טבלאות שזוהו כחשובות להעברה ומספר השאילתות שתורגמו באופן אוטומטי. הפרטים בקטע הזה כוללים את המידע הבא:
- תצוגה מפורטת עם שאילתות שתורגמו אוטומטית
- מספר השאילתות הכולל, עם אפשרות סינון לפי משתמש, אפליקציה, טבלאות מושפעות, טבלאות שנשאלו עליהן שאילתות וסוג השאילתה.
- דליים של שאילתות עם דפוסים דומים מקובצים יחד, כדי לאפשר למשתמשים לראות את פילוסופיית התרגום לפי סוגי שאילתות.
- שאילתות שנדרשת לגביהן התערבות אנושית
- שאילתות עם הפרות של המבנה הלקסיקלי של BigQuery
- פונקציות ונהלים שמוגדרים על ידי המשתמש
- מילות מפתח שמורות ב-BigQuery
- שאילתה שנדרשת לגביה בדיקה
- טבלאות של לוחות זמנים לפי פעולות כתיבה וקריאה (כדי לקבץ אותן להעברה)
- יעד אחסון מזוהה לטבלאות חיצוניות ולטבלאות מנוהלות
- תצוגה מפורטת עם שאילתות שתורגמו אוטומטית
הקטע מערכת קיימת – Hive כולל את התצוגות הבאות:
- סקירה כללית של המערכת
- בתצוגה הזו מוצגים מדדי הנפח ברמה גבוהה של הרכיבים העיקריים במערכת הקיימת לתקופה מוגדרת. ציר הזמן שנבדק תלוי ביומנים שנותחו על ידי כלי ההערכה של המיגרציה ל-BigQuery. בתצוגה הזו אפשר לקבל במהירות תובנות לגבי השימוש במחסן נתונים של מקור, שאפשר להשתמש בהן לתכנון העברה.
- נפח הטבלה
- בתצוגה הזו מוצגים נתונים סטטיסטיים על הטבלאות ומסדי הנתונים הגדולים ביותר שנמצאו על ידי כלי ההערכה של BigQuery לצורך מיגרציה. יכול להיות שייקח יותר זמן לחלץ טבלאות גדולות ממערכת מחסן נתונים של מקור, ולכן התצוגה הזו יכולה לעזור בתכנון ובסדר הפעולות של ההעברה.
- שימוש בטבלה
- בתצוגה הזו מוצגים נתונים סטטיסטיים לגבי הטבלאות שנמצאות בשימוש רב במערכת מחסן הנתונים של מקור הנתונים. טבלאות שנמצאות בשימוש רב יכולות לעזור לכם להבין אילו טבלאות עשויות להכיל הרבה תלויות ולדרוש תכנון נוסף במהלך תהליך ההעברה.
- ניצול של תורים
- בתצוגה הזו מוצגים נתונים סטטיסטיים על השימוש בתורים של YARN שנמצאו במהלך עיבוד היומנים. התצוגות האלה מאפשרות למשתמשים להבין את השימוש בתורים ובאפליקציות ספציפיים לאורך זמן, ואת ההשפעה על השימוש במשאבים. התצוגות האלה גם עוזרות לזהות ולתעדף עומסי עבודה להעברה. במהלך ההעברה, חשוב להמחיש את ההטמעה והצריכה של הנתונים כדי להבין טוב יותר את התלות של מחסן הנתונים, ולנתח את ההשפעה של העברת אפליקציות שונות שתלויות זו בזו יחד. טבלת כתובות ה-IP יכולה להיות שימושית לזיהוי מדויק של האפליקציה באמצעות מחסן הנתונים דרך חיבורי JDBC.
- מדדי תורים
- בתצוגה הזו מוצג פירוט של המדדים השונים בתורי YARN שנמצאו במהלך עיבוד היומנים. התצוגה הזו מאפשרת למשתמשים להבין את דפוסי השימוש בתורים ספציפיים ואת ההשפעה על המיגרציה. אתם יכולים להשתמש בתצוגה הזו גם כדי לזהות קשרים בין טבלאות שמתבצעת אליהן גישה בשאילתות לבין תורים שבהם השאילתה בוצעה.
- הוספה לרשימת הבאים בתור והמתנה
- בתצוגה הזו אפשר לקבל תובנה לגבי זמן ההמתנה בתור של השאילתה במחסן הנתונים של המקור. זמני ההמתנה בתור מצביעים על ירידה בביצועים בגלל הקצאת משאבים לא מספקת, והקצאת משאבים נוספת מחייבת הגדלה של עלויות החומרה והתחזוקה.
- שאילתות
- בתצוגה הזו מוצג פירוט של סוגי הצהרות ה-SQL שהופעלו וסטטיסטיקות של השימוש בהן. אתם יכולים להשתמש בהיסטוגרמה של סוג השאילתה והזמן כדי לזהות תקופות של ניצול נמוך של המערכת, ואת השעות האופטימליות ביום להעברת נתונים. אפשר גם להשתמש בתצוגה הזו כדי לזהות את מנועי ההפעלה של Hive שהכי הרבה משתמשים בהם ואת השאילתות שמופעלות בתדירות גבוהה, יחד עם פרטי המשתמשים.
- מסדי נתונים
- בתצוגה הזו מוצגים מדדים לגבי הגודל, הטבלאות, התצוגות והפרוצדורות שמוגדרים במערכת מחסן הנתונים של מקור הנתונים. התצוגה הזו יכולה לספק תובנות לגבי נפח האובייקטים שצריך להעביר.
- צימוד של מסד נתונים וטבלה
- בתצוגה הזו אפשר לראות סקירה כללית של מסדי נתונים וטבלאות שאליהם ניגשים יחד בשאילתה אחת. בתצוגה הזו אפשר לראות אילו טבלאות ומסדי נתונים מוזכרים לעיתים קרובות, ואילו אפשר להשתמש בהם לתכנון העברה.
הקטע BigQuery Steady State מכיל את התצוגות הבאות:
- טבלאות ללא שימוש
- בתצוגה 'טבלאות ללא שימוש' מוצגות טבלאות שבהן לא נמצא שימוש במהלך התקופה שצוינה ביומנים שנותחו במסגרת ההערכה של המיגרציה ל-BigQuery. אם אין שימוש בטבלה מסוימת, יכול להיות שלא צריך להעביר אותה ל-BigQuery במהלך ההעברה, או שהעלויות של אחסון הנתונים ב-BigQuery יכולות להיות נמוכות יותר. צריך לאמת את רשימת הטבלאות שלא נעשה בהן שימוש, כי יכול להיות שיש בהן שימוש מחוץ לתקופת היומנים, למשל טבלה שנעשה בה שימוש רק פעם אחת כל שלושה או שישה חודשים.
- טבלאות ללא פעולות כתיבה
- בתצוגה 'טבלאות ללא פעולות כתיבה' מוצגות טבלאות שבהן כלי ההערכה של ההעברה ל-BigQuery לא מצא עדכונים במהלך התקופה שבה נותחו היומנים. היעדר כתיבות יכול להצביע על מקומות שבהם אפשר להקטין את עלויות האחסון ב-BigQuery.
- המלצות בנושא קיבוץ לאשכולות (clustering) וחלוקה למחיצות (partitioning)
בתצוגה הזו מוצגות טבלאות שיכולות להפיק תועלת מחלוקה למחיצות, מאשכולות או משניהם.
ההצעות למטא-נתונים מתקבלות על ידי ניתוח הסכימה של מחסן הנתונים של המקור (כמו חלוקה למחיצות ומפתח ראשי בטבלת המקור) ומציאת המקבילה הקרובה ביותר ב-BigQuery כדי להשיג מאפייני אופטימיזציה דומים.
ההצעות לעומסי עבודה מתקבלות מניתוח של יומני השאילתות של המקור. ההמלצה נקבעת על סמך ניתוח של עומסי העבודה, במיוחד סעיפים של
WHEREאוJOINביומני השאילתות המנותחים.- מחיצות שהומרו לאשכולות
בתצוגה הזו מוצגות טבלאות עם יותר מ-10,000 מחיצות, על סמך הגדרת אילוצי החלוקה שלהן. הטבלאות האלה מתאימות בדרך כלל לאשכולות BigQuery, שמאפשרים חלוקה מפורטת של הטבלאות למחיצות.
- מחיצות לא מאוזנות
בתצוגה 'מחיצות עם חלוקת נתונים לא מאוזנת' מוצגות טבלאות שמבוססות על ניתוח המטא-נתונים וכוללות חלוקת נתונים לא מאוזנת במחיצה אחת או יותר. הטבלאות האלה הן מועמדות טובות לשינוי סכימה, כי יכול להיות שהביצועים של שאילתות במחיצות מוטות לא יהיו טובים.
- BI Engine ותצוגות מהותיות
בתצוגה 'שאילתות עם זמן אחזור נמוך ותצוגות חומריות' מוצג פיזור של זמני הריצה של השאילתות על סמך נתוני היומן שנותחו, ומוצעות הצעות נוספות לאופטימיזציה כדי לשפר את הביצועים ב-BigQuery. אם בתרשים של התפלגות משך השאילתה מוצג מספר גדול של שאילתות עם זמן ריצה של פחות משנייה אחת, כדאי להפעיל את BI Engine כדי להאיץ את ה-BI ועומסי עבודה אחרים עם זמן אחזור נמוך.
הקטע תוכנית ההעברה בדוח מכיל את התצוגות הבאות:
- תרגום SQL
- בתצוגה 'תרגום SQL' מפורטים מספר השאילתות שהומרו אוטומטית על ידי כלי ההערכה של BigQuery Migration, ופרטים לגביהן. לא נדרשת התערבות ידנית לגבי השאילתות האלה. בדרך כלל, אם מספקים מטא-נתונים, שיעורי התרגום של תרגום אוטומטי של SQL הם גבוהים. התצוגה הזו אינטראקטיבית ומאפשרת ניתוח של שאילתות נפוצות ושל האופן שבו הן מתורגמות.
- תרגום SQL ללא חיבור לאינטרנט
- בתצוגה Offline Effort אפשר לראות את האזורים שבהם נדרבת התערבות ידנית, כולל UDF ספציפיות והפרות פוטנציאליות של מבנה לקסיקלי ותחביר בטבלאות או בעמודות.
- אזהרות SQL
- בתצוגה 'אזהרות SQL' מוצגים אזורים שתורגמו בהצלחה, אבל דורשים בדיקה.
- מילות מפתח שמורות ב-BigQuery
- בתצוגה של מילות מפתח שמורות ב-BigQuery מוצג השימוש שזוהה במילות מפתח שיש להן משמעות מיוחדת בשפת GoogleSQL.
אי אפשר להשתמש במילות המפתח האלה כמזהים אלא אם הן מוקפות בתווי גרש הפוך (
`). - לוח הזמנים לעדכוני הטבלאות
- בתצוגה 'לוח הזמנים לעדכוני הטבלאות' אפשר לראות מתי הטבלאות מתעדכנות וכל כמה זמן, כדי שתוכלו לתכנן איך ומתי להעביר אותן.
- טבלאות חיצוניות של BigLake
- בתצוגה BigLake External Tables מפורטות טבלאות שמזוהות כיעדים להעברה ל-BigLake במקום ל-BigQuery.
הקטע נספח בדוח מכיל את התצוגות הבאות:
- ניתוח מפורט של מאמצי תרגום SQL אופליין
- בתצוגה 'ניתוח מפורט של מאמץ אופליין' אפשר לקבל תובנה נוספת לגבי אזורי ה-SQL שנדרשת בהם התערבות ידנית.
- ניתוח מפורט של אזהרות SQL
- התצוגה 'ניתוח מפורט של אזהרות' מספקת תובנה נוספת לגבי אזורי ה-SQL שתורגמו בהצלחה, אבל דורשים בדיקה.
שיתוף הדוח
דוח Data Studio הוא לוח בקרה של קצה קדמי למטרת הערכת המיגרציה. היא מסתמכת על הרשאות הגישה למערך הנתונים הבסיסי. כדי לשתף את הדוח, הנמען צריך לקבל גישה לדוח עצמו ב-Data Studio ולמערך הנתונים ב-BigQuery שמכיל את תוצאות ההערכה.
כשפותחים את הדוח ממסוף Google Cloud , הוא מוצג במצב תצוגה מקדימה. כדי ליצור את הדוח ולשתף אותו עם משתמשים אחרים:
- לוחצים על עריכה ושיתוף. מערכת Data Studio תציג הנחיה לצרף את מחברי Data Studio החדשים שנוצרו לדוח החדש.
- לוחצים על הוספה לדוח. הדוח מקבל מזהה דוח ייחודי, שבאמצעותו אפשר לגשת לדוח.
- כדי לשתף את הדוח ב-Data Studio עם משתמשים אחרים, פועלים לפי השלבים שמפורטים במאמר בנושא שיתוף דוחות עם משתמשים בעלי הרשאת צפייה ועריכה.
- נותנים למשתמשים הרשאה לצפייה במערך הנתונים ב-BigQuery ששימש להרצת משימת ההערכה. מידע נוסף מופיע במאמר בנושא הענקת גישה למערך נתונים.
הרצת שאילתות על טבלאות הפלט של הערכת ההעברה
הדוחות ב-Data Studio הם הדרך הנוחה ביותר לראות את תוצאות ההערכה, אבל אפשר גם לראות את נתוני הבסיס ולהריץ עליהם שאילתות במערך הנתונים של BigQuery.
שאילתה לדוגמה
בדוגמה הבאה מקבלים את המספר הכולל של שאילתות ייחודיות, את מספר השאילתות שנכשלו בתרגום ואת אחוז השאילתות הייחודיות שנכשלו בתרגום.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
שיתוף מערך הנתונים עם משתמשים בפרויקטים אחרים
אחרי שבודקים את מערך הנתונים, אם רוצים לשתף אותו עם משתמש שלא נמצא בפרויקט, אפשר לעשות זאת באמצעות תהליך העבודה של BigQuery sharing (לשעבר Analytics Hub).
במסוף Google Cloud , עוברים לדף BigQuery.
לוחצים על מערך הנתונים כדי לראות את הפרטים שלו.
לוחצים על שיתוף > פרסום ככרטיס מוצר.
בתיבת הדו-שיח שנפתחת, יוצרים כרטיס מידע בהתאם להנחיות.
אם כבר יש לכם שיתוף נתונים, אפשר לדלג על שלב 5.
יצירת אוסף נתונים לשיתוף והגדרת הרשאות כדי לאפשר למשתמש לצפות בכרטיסי המוצר שלכם בבורסת הפרסום הזו, צריך להוסיף אותו לרשימת המשתמשים הרשומים.
מזינים את פרטי הכרטיס.
השם המוצג הוא השם של כרטיס המוצר הזה והוא שדה חובה. שאר השדות הם אופציונליים.
לוחצים על פרסום.
נוצר כרטיס מוצר פרטי.
בכרטיס המוצר, לוחצים על פעולות נוספות בקטע פעולות.
לוחצים על העתקת הקישור לשיתוף.
אפשר לשתף את הקישור עם משתמשים שיש להם מינוי לאוסף נתונים לשיתוף או לכרטיסי מוצר.
פתרון בעיות
בקטע הזה מוסברות כמה בעיות נפוצות וטכניקות לפתרון בעיות שקשורות להעברת מחסן הנתונים ל-BigQuery.
dwh-migration-dumper שגיאות בכלי
כדי לפתור בעיות שקשורות לשגיאות ואזהרות בפלט של מסוף הכלי dwh-migration-dumper שהתרחשו במהלך חילוץ מטא-נתונים או יומני שאילתות, אפשר לעיין במאמר בנושא פתרון בעיות שקשורות ליצירת מטא-נתונים.
שגיאות בהעברה של Hive
בקטע הזה מתוארות בעיות נפוצות שיכולות לקרות כשמתכננים להעביר את מחסן הנתונים מ-Hive ל-BigQuery.
ה-hook של הרישום ביומן כותב הודעות של יומן ניפוי הבאגים ביומנים שלכם hive-server2. אם נתקלים בבעיות, כדאי לעיין ביומני ניפוי הבאגים של ה-hook של הרישום ביומן, שמכילים את המחרוזת MigrationAssessmentLoggingHook.
טיפול בשגיאה ClassNotFoundException
יכול להיות שהשגיאה נגרמת בגלל מיקום שגוי של קובץ ה-JAR של ה-logging hook. מוודאים שהוספתם את קובץ ה-JAR לתיקיית auxlib באשכול Hive. לחלופין, אפשר לציין את הנתיב המלא לקובץ ה-JAR במאפיין hive.aux.jars.path, לדוגמה, file://.
תיקיות משנה לא מופיעות בתיקייה שהוגדרה
יכול להיות שהבעיה הזו נגרמת בגלל הגדרה שגויה או בגלל בעיות במהלך האתחול של וו התחברות.
מחפשים בhive-server2 יומני ניפוי הבאגים את ההודעות הבאות של וו התיוג:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
בודקים את פרטי הבעיה כדי לראות אם יש משהו שצריך לתקן כדי לפתור את הבעיה.
הקבצים לא מופיעים בתיקייה
הבעיה הזו יכולה להיגרם בגלל בעיות שנתקלו בהן במהלך עיבוד אירוע או בזמן כתיבה לקובץ.
מחפשים ביומני ניפוי הבאגים hive-server2 את ההודעות הבאות של וו התחברות לרישום ביומן:
Failed to close writer for file
Got exception while processing event
Error writing record for query
בודקים את פרטי הבעיה כדי לראות אם יש משהו שצריך לתקן כדי לפתור את הבעיה.
חלק מהאירועים של השאילתות לא נרשמים
יכול להיות שהבעיה הזו נגרמת בגלל גלישת תור של שרשור וו של רישום ביומן.
מחפשים בhive-server2 יומני ניפוי הבאגים את ההודעה הבאה של וו התחברות ליומן:
Writer queue is full. Ignoring event
אם יש הודעות כאלה, כדאי להגדיל את הפרמטר dwhassessment.hook.queue.capacity.
המאמרים הבאים
מידע נוסף על הכלי dwh-migration-dumper זמין במאמר dwh-migration-tools.
אפשר גם לקרוא מידע נוסף על השלבים הבאים בהעברה של מחסן נתונים:
- סקירה כללית על מיגרציה
- סקירה כללית של סכימה והעברת נתונים
- צינורות עיבוד נתונים
- תרגום SQL באצווה
- תרגום אינטראקטיבי של SQL
- אבטחה ומשילות מידע
- כלי לאימות נתונים