
Apache Hive Metastore 테이블을Google Cloud로 마이그레이션
이 문서에서는 Apache Hive Metastore에서 관리하는 Iceberg 및 Hive 테이블을Google Cloud 로 마이그레이션하는 방법을 BigQuery Data Transfer Service를 사용하여 설명합니다.
BigQuery Data Transfer Service의 Apache Hive Metastore 마이그레이션 커넥터를 사용하면 Hive Metastore 테이블을 Google Cloud 로 대규모로 원활하게 마이그레이션할 수 있습니다. 이 커넥터는 온프레미스 설치 및 클라우드 환경(Cloudera 설정 포함)의 Hive 및 Iceberg 테이블을 모두 지원합니다. Hive Metastore 이전 커넥터는 다음 데이터 소스에 저장된 파일을 지원합니다.
- Apache Hadoop 분산 파일 시스템(HDFS)
- Amazon Simple Storage Service(Amazon S3)
- Azure Blob Storage 또는 Azure Data Lake Storage Gen2
Hive Metastore 마이그레이션 커넥터를 사용하면 Cloud Storage를 파일 스토리지로 사용하고 다음 메타스토어 중 하나에 Hive Metastore 테이블을 등록할 수 있습니다.
Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그
모든 Iceberg 데이터에 Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그를 사용하는 것이 좋습니다.
Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그는 모든 Iceberg 데이터에 단일 소스를 제공하여 쿼리 엔진 간의 상호 운용성을 지원합니다. Apache Spark 및 기타 OSS 엔진 외에도 BigQuery를 사용하여 데이터를 쿼리할 수 있습니다. 레이크하우스 런타임 카탈로그 Iceberg REST 카탈로그는 Iceberg 테이블 형식만 지원합니다.
Lakehouse 런타임 카탈로그 Hive 카탈로그 (미리보기)
모든 Hive 테이블에 Lakehouse 런타임 카탈로그 Hive 카탈로그를 사용하는 것이 좋습니다.
Lakehouse 런타임 카탈로그 Hive 카탈로그를 사용하면 Hive 카탈로그를 사용하여 이전된 Hive 테이블을 Lakehouse 런타임 카탈로그에 등록할 수 있습니다. 이렇게 하면 Apache Hive 테이블에 서버리스 metastore가 제공됩니다. Apache Spark 및 기타 OSS 엔진 외에도 BigQuery를 사용하여 데이터 (형식 제한 적용)를 쿼리할 수 있습니다.
-
Dataproc Metastore는 Hive 및 Iceberg 테이블 형식을 모두 지원합니다. Apache Spark 및 기타 OSS 엔진만 사용하여 Dataproc Metastore에서 데이터를 읽고 쓸 수 있습니다.
이 커넥터는 전체 전송과 메타데이터 전용 전송을 모두 지원합니다. 전체 전송은 소스 테이블의 데이터와 메타데이터를 모두 대상 메타스토어로 전송합니다. Cloud Storage에 이미 데이터가 있고 대상 메타스토어에 데이터만 등록하려는 경우 메타데이터 전용 전송을 만들 수 있습니다.
다음 다이어그램은 마이그레이션 프로세스를 간략하게 보여줍니다.
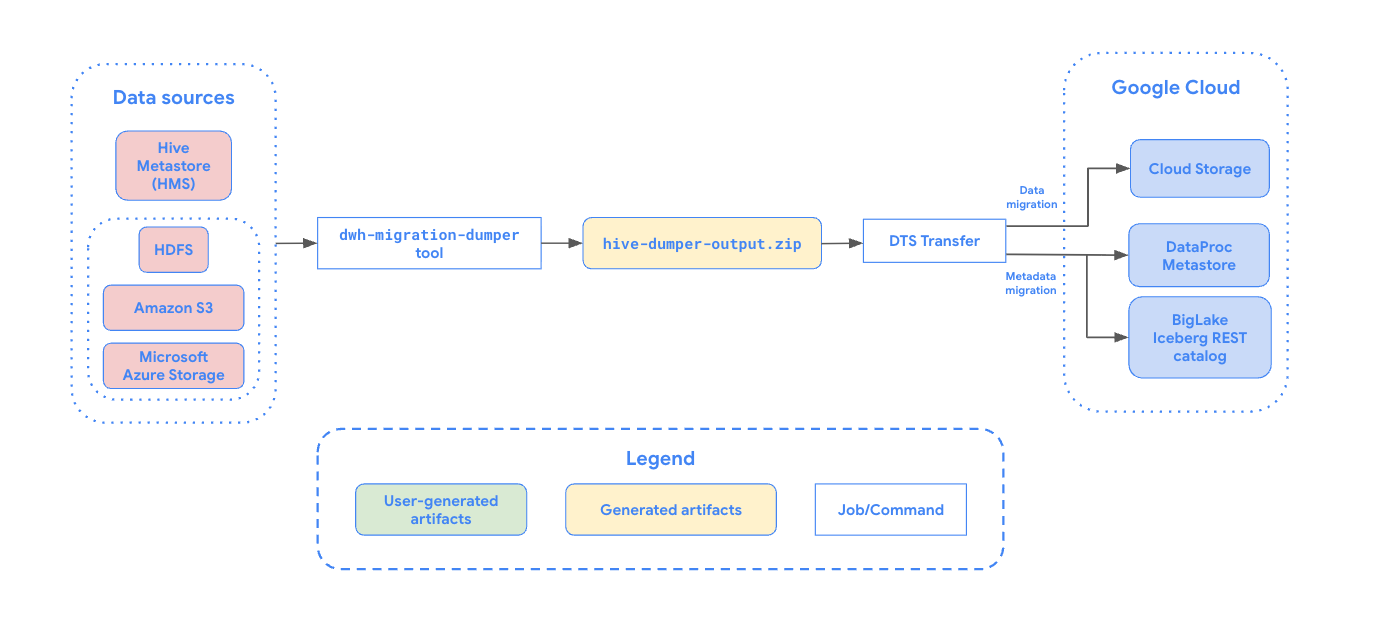
제한사항
Hive Metastore 테이블 전송에는 다음과 같은 제한사항이 적용됩니다.
- Hive Metastore 전송은 예약된 실행 간에 최소 30분이 필요합니다. 주문형 실행은 여전히 모든 간격으로 트리거할 수 있습니다.
- 파일 이름은 Cloud Storage 객체 이름 지정 요구사항을 준수해야 합니다.
- Cloud Storage의 단일 객체에는 5TiB 한도가 적용됩니다. Hive Metastore 테이블 내의 파일이 5TiB보다 크면 전송이 실패합니다.
- 전송이 진행되는 동안 소스에서 데이터가 변경되면 Storage Transfer Service에 특정 동작이 적용됩니다. 테이블이 활발하게 이전되는 동안 테이블에 쓰는 것은 권장되지 않습니다. 다른 Storage Transfer Service 제한사항 목록은 알려진 제한사항을 참고하세요.
Lakehouse 런타임 카탈로그 Hive 카탈로그 제한사항
Lakehouse 런타임 카탈로그 Hive 카탈로그 (BIGLAKE_HIVE_CATALOG)를 대상 메타스토어로 사용하는 경우 다음 제한사항과 고려사항이 적용됩니다.
- Lakehouse 런타임 카탈로그 Hive 카탈로그 ID에는 소문자, 숫자, 밑줄 (
_)만 포함해야 합니다. 대시 (-)나 대문자는 포함하면 안 됩니다. - Google Cloud 콘솔에서는 Lakehouse 런타임 카탈로그 Hive 카탈로그를 보거나 관리할 수 없습니다. 하지만 이전된 테이블은 대상 BigQuery 데이터 세트에서 표시되고 쿼리할 수 있습니다.
- 오픈소스 메타데이터 형식 및 데이터 유형에 대한 모든 Lakehouse 런타임 카탈로그 Hive 카탈로그 제한사항이 적용됩니다.
- CSV, JSON과 같은 형식과의 호환성에 대한 자세한 내용은 지원되는 저장 형식을 참고하세요.
- 지원되지 않는 데이터 유형 (예:
UNION또는 중첩 배열) 및 열 통계에 대한 자세한 내용은 메타 스토어 제한사항 및 파티션 제한사항을 참고하세요.
데이터 수집 옵션
다음 섹션에서는 Hive Metastore 전송을 구성하는 방법을 자세히 설명합니다.
증분 전송
반복 일정으로 전송 구성을 설정하면 후속 전송마다 소스 테이블에 적용된 최신 업데이트로 Google Cloud 의 테이블이 업데이트됩니다. 예를 들어 모든 데이터 업데이트와 스키마가 변경되는 모든 삽입, 삭제 또는 업데이트 작업은 전송될 때마다 Google Cloud 에 반영됩니다.
파티션 필터링
Cloud Storage에 저장된 맞춤 필터 JSON 파일을 제공하여 Hive 테이블에서 파티션의 하위 집합을 전송할 수 있습니다. 전송을 예약할 때 partition_filter_gcs_path 매개변수를 사용하여 이 JSON 파일의 전체 Cloud Storage 경로를 제공합니다.
다음은 필터 JSON 파일 구조의 예입니다.
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
필터 조건
JSON 파일의 condition 필드는 다음 값을 지원하며 각 값에는 partitions 배열의 특정 형식이 있습니다.
IN: 포함할 정확한 파티션 경로를 지정합니다.partitions배열에는 테이블 기본 경로 (예:["partition_key1=value1/partition_key2=value2"])를 기준으로 파티션의 정확한 디렉터리 구조를 나타내는 문자열이 포함됩니다. 배열에 여러 경로를 지정할 수 있습니다.LESS_THAN: 기본 파티션 키 값이 지정된 값보다 작거나 같은 파티션을 포함합니다.partitions배열에는["<partition_key>;<value>"]형식의 문자열이 하나 포함되어야 합니다.GREATER_THAN: 기본 파티션 키 값이 지정된 값보다 크거나 같은 파티션을 포함합니다.partitions배열에는["<partition_key>;<value>"]형식의 문자열이 하나만 포함되어야 합니다.RANGE: 기본 파티션 키 값이 지정된 범위 내에 있는 파티션을 포함합니다 (해당 값 포함).partitions배열에는["<partition_key>;<start_value>;<end_value>"]형식의 단일 문자열이 포함되어야 합니다.
필터 조건에는 다음과 같은 규칙과 제한사항이 적용됩니다.
- 포함 값:
GREATER_THAN,LESS_THAN,RANGE의 필터 조건에는 제공된 값이 포함됩니다. 예를 들어 값이2023인LESS_THAN필터에는2023까지의 파티션이 포함됩니다. - 파티션 삭제: 기존 대상 파티션이 파티션 필터를 충족하고 더 이상 소스에 없으면 대상 메타스토어에서 삭제됩니다. 하지만 해당 파티션의 기본 데이터 파일은 Cloud Storage 대상 버킷에서 삭제되지 않습니다.
- 단일 표 제한사항:
- 동일한 표에 여러 필터를 사용할 수는 없습니다.
- 동일한 표에서 서로 다른 조건 유형 (예:
GREATER_THAN및IN)을 혼합할 수 없습니다.
- 타겟 파티션 열:
GREATER_THAN,LESS_THAN,RANGE과 같은 필터 조건은 기본 파티션 열을 타겟팅해야 합니다. - 접두사 제한: 지정된 필터 조합이 테이블당 1,000개를 초과하는 접두사로 해석되면 안 됩니다. 예를 들어
year/month/day로 파티션을 나눈 테이블에서year>2020와 같은 필터를 사용하면 고유한year=접두사가 1, 000개 미만이어야 합니다.
시작하기 전에
Hive Metastore 전송을 예약하기 전에 이 섹션의 단계를 수행하세요.
API 사용 설정
Google Cloud 프로젝트에서 다음 API를 사용 설정합니다.
- Data Transfer API
- Storage Transfer API
- BigLake API
Data Transfer API를 사용 설정하면 서비스 에이전트가 생성됩니다.
권한 구성
Hive Metastore 전송 권한을 구성하려면 다음 섹션의 단계를 따르세요.
- 전송을 만드는 사용자 또는 서비스 계정에는 BigQuery 관리자 역할 (
roles/bigquery.admin)이 부여되어야 합니다. 서비스 계정을 사용하는 경우 전송을 만드는 데만 사용됩니다. Data Transfer API를 사용 설정하면 서비스 에이전트(P4SA)가 생성됩니다.
서비스 에이전트에 Hive Metastore 전송을 실행하는 데 필요한 권한이 있는지 확인하려면 관리자에게 프로젝트의 서비스 에이전트에 다음 IAM 역할을 부여해 달라고 요청하세요.
- 스토리지 전송 관리자 (
roles/storagetransfer.admin) - 서비스 사용량 소비자(
roles/serviceusage.serviceUsageConsumer) - 스토리지 관리자 (
roles/storage.admin) -
메타데이터를 Lakehouse 런타임 카탈로그 (Iceberg REST 카탈로그 또는 Hive 카탈로그)로 이전하려면 다음 권한이 필요합니다.
BigLake 관리자 (
roles/biglake.admin) -
Dataproc Metastore로 메타데이터를 마이그레이션하려면 Dataproc Metastore 데이터 소유자 (
roles/metastore.metadataOwner)가 필요합니다.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
관리자는 커스텀 역할이나 다른 사전 정의된 역할을 통해 서비스 에이전트에 필요한 권한을 부여할 수도 있습니다.
- 스토리지 전송 관리자 (
서비스 계정을 사용하는 경우 다음 명령어를 사용하여 서비스 에이전트에
roles/iam.serviceAccountTokenCreator역할을 부여합니다.gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
프로젝트에서 Storage Transfer Service 서비스 에이전트(
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com)에 다음 역할을 부여합니다.roles/storage.admin- 온프레미스/HDFS에서 이전하는 경우
roles/storagetransfer.serviceAgent역할도 부여해야 합니다.
더 세분화된 권한을 구성할 수도 있습니다. 자세한 내용은 다음 가이드를 참고하세요.
Apache Hive용 메타데이터 파일 생성
dwh-migration-dumper 도구를 실행하여 Apache Hive의 메타데이터를 추출합니다.
이 도구는 Cloud Storage 버킷에 업로드할 수 있는 hive-dumper-output.zip이라는 파일을 생성합니다. 이 Cloud Storage 버킷은 이 문서에서 DUMPER_BUCKET으로 참조됩니다.
스크립트를 사용하여 주기적인 업로드를 예약할 수도 있습니다. 자세한 내용은 cron 작업을 사용하여 덤퍼 도구 실행 자동화를 참고하세요.
Storage Transfer Service 구성
다음 옵션 중 하나를 선택합니다.
HDFS
온프레미스 또는 HDFS 전송에는 스토리지 전송 에이전트가 필요합니다.
에이전트를 설정하려면 다음 단계를 따르세요.
- 온프레미스 에이전트 머신에 Docker를 설치합니다.
- Google Cloud 프로젝트에서 Storage Transfer Service 에이전트 풀을 만듭니다.
- 온프레미스 에이전트 머신에 에이전트를 설치합니다.
Amazon S3
Amazon S3에서 전송은 에이전트 없는 전송입니다.
Amazon S3 전송을 위해 Storage Transfer Service를 구성하려면 다음 단계를 따르세요.
- AWS Amazon S3의 액세스 사용자 인증 정보 설정
- 액세스 사용자 인증 정보를 설정한 후 액세스 키 ID와 보안 비밀 액세스 키를 기록해 둡니다.
- AWS 프로젝트에서 IP 제한을 사용하는 경우 Storage Transfer Service 작업자가 사용하는 IP 범위를 허용된 IP 목록에 추가합니다.
Microsoft Azure
Microsoft Azure Storage에서의 전송은 에이전트리스 전송입니다.
Microsoft Azure Storage 전송을 위해 Storage Transfer Service를 구성하려면 다음 단계를 따르세요.
- Microsoft Azure 스토리지 계정의 공유 액세스 서명 (SAS) 토큰을 생성합니다.
- SAS 토큰을 생성한 후 기록해 둡니다.
- Microsoft Azure 스토리지 계정에서 IP 제한을 사용하는 경우 Storage Transfer Service 작업자가 사용하는 IP 범위를 허용된 IP 목록에 추가합니다.
Hive Metastore 전송 예약
다음 옵션 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 데이터 전송 페이지로 이동합니다.
전송 만들기를 클릭합니다.
소스 유형 섹션의 소스 목록에서 Hive Metastore를 선택합니다.
위치에서 위치 유형을 선택한 다음 리전을 선택합니다.
전송 구성 이름 섹션의 표시 이름에 데이터 전송 이름을 입력합니다.
일정 옵션 섹션에서 다음을 수행합니다.
- 반복 빈도 목록에서 이 데이터 전송 실행 빈도를 지정하는 옵션을 선택합니다. 커스텀 반복 빈도를 지정하려면 커스텀을 선택합니다. 주문형을 선택하면 수동으로 전송을 트리거할 때 이 전송이 실행됩니다.
- 해당하는 경우 지금 시작 또는 설정 시간에 시작을 선택하고 시작 날짜와 실행 시간을 입력합니다.
데이터 소스 세부정보 섹션에서 다음을 수행합니다.
- 전송 전략에서 다음 중 하나를 선택합니다.
FULL_TRANSFER: 모든 데이터를 전송하고 대상 메타 스토어에 메타데이터를 등록합니다. 기본 옵션입니다.METADATA_ONLY: 메타데이터만 등록합니다. 메타데이터에서 참조하는 올바른 Cloud Storage 위치에 데이터가 이미 있어야 합니다.
- 테이블 이름 패턴에 HDFS 데이터베이스의 테이블과 일치하는 테이블 이름이나 패턴을 입력하여 전송할 HDFS 데이터 레이크 테이블을 지정합니다. Java 정규 표현식 구문을 사용하여 테이블 패턴을 지정해야 합니다. 예를 들면 다음과 같습니다.
db1..*은 db1의 모든 테이블과 일치합니다.db1.table1;db2.table2은 db1의 table1과 db2의 table2를 찾습니다.
- BQMS 검색 덤프 GCS 경로의 경우 Apache Hive의 메타데이터 파일을 만들 때 생성한
hive-dumper-output.zip파일의 경로를 입력합니다.cron를 사용하여 덤퍼 출력 자동화를 사용하는 경우--gcs-base-path에 구성된 Cloud Storage 폴더 경로를 제공합니다. 이 폴더에는 덤퍼 출력 ZIP 파일이 포함되어 있습니다.- 스토리지 유형에서 다음 옵션 중 하나를 선택합니다. 이 필드는 전송 전략이
FULL_TRANSFER로 설정된 경우에만 사용할 수 있습니다. HDFS: 파일 스토리지가HDFS인 경우 이 옵션을 선택합니다. STS 에이전트 풀 이름 필드에 Storage Transfer Agent를 구성할 때 만든 에이전트 풀의 이름을 제공해야 합니다.S3: 파일 스토리지가Amazon S3인 경우 이 옵션을 선택합니다. 액세스 키 ID 및 보안 비밀 액세스 키 필드에 액세스 사용자 인증 정보를 설정할 때 만든 액세스 키 ID와 보안 비밀 액세스 키를 입력해야 합니다.AZURE: 파일 스토리지가Azure Blob Storage인 경우 이 옵션을 선택합니다. SAS 토큰 필드에 액세스 사용자 인증 정보를 설정할 때 만든 SAS 토큰을 제공해야 합니다.
- 스토리지 유형에서 다음 옵션 중 하나를 선택합니다. 이 필드는 전송 전략이
- 선택사항: 파티션 필터 gcs 경로에 소스 테이블에서 파티션을 필터링할 맞춤 필터 JSON 파일의 전체 Cloud Storage 경로를 입력합니다.
- 대상 GCS 경로에 이전된 데이터를 저장할 Cloud Storage 버킷의 경로를 입력합니다.
- 드롭다운 목록에서 대상 메타스토어 유형을 선택합니다.
DATAPROC_METASTORE: Dataproc Metastore에 메타데이터를 저장하려면 이 옵션을 선택합니다. Dataproc metastore url에 Dataproc Metastore의 URL을 제공해야 합니다.BIGLAKE_REST_CATALOG: Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그에 메타데이터를 저장하려면 이 옵션을 선택합니다. 카탈로그는 대상 Cloud Storage 버킷을 기반으로 생성됩니다.BIGLAKE_HIVE_CATALOG(미리보기): 레이크하우스 런타임 카탈로그 Hive 카탈로그에 메타데이터를 저장하려면 이 옵션을 선택합니다. BigLake Metastore Hive 카탈로그 ID에 카탈로그 이름을 제공해야 합니다. 카탈로그가 없으면 자동으로 생성됩니다.
- 선택사항: 서비스 계정에 이 데이터 전송에 사용할 서비스 계정을 입력합니다. 서비스 계정은 전송 구성과 대상 데이터 세트가 생성된 동일한Google Cloud 프로젝트에 속해야 합니다.
- 전송 전략에서 다음 중 하나를 선택합니다.
bq
Hive Metastore 전송을 예약하려면 bq mk 명령어를 입력하고 전송 생성 플래그 --transfer_config를 지정합니다.
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
다음을 바꿉니다.
TRANSFER_NAME: 전송 구성의 표시 이름. 전송 이름은 나중에 수정해야 할 경우를 대비해 전송을 식별할 수 있는 값이면 됩니다.SERVICE_ACCOUNT: 전송을 만드는 데 사용되는 서비스 계정 이름입니다.서비스 계정은 전송 구성과 대상 데이터 세트가 생성된 동일한Google Cloud 프로젝트에 속해야 합니다.PROJECT_ID: Google Cloud 프로젝트 ID입니다. 특정 프로젝트를 지정하는--project_id가 입력되지 않으면 기본 프로젝트가 사용됩니다.REGION: 이 전송 구성의 위치입니다.TRANSFER_STRATEGY: (선택사항) 다음 값 중 하나를 지정합니다.FULL_TRANSFER: 모든 데이터를 전송하고 대상 메타 스토어에 메타데이터를 등록합니다. 기본값입니다.METADATA_ONLY: 메타데이터만 등록합니다. 메타데이터에서 참조하는 올바른 Cloud Storage 위치에 데이터가 이미 있어야 합니다.
LIST_OF_TABLES: 전송할 항목 목록입니다. 계층적 이름 지정 사양(database.table)을 사용합니다. 이 필드는 테이블을 지정하기 위해 RE2 정규 표현식을 지원합니다. 예를 들면 다음과 같습니다.db1..*: 데이터베이스의 모든 테이블을 지정합니다.db1.table1;db2.table2: 테이블 목록입니다.
DUMPER_BUCKET:hive-dumper-output.zip파일이 포함된 Cloud Storage 버킷입니다.cron를 사용하여 덤퍼 출력 자동화를 사용하는 경우table_metadata_path을 cron 설정에서--gcs-base-path로 구성된 Cloud Storage 폴더 경로로 변경합니다(예:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>").MIGRATION_BUCKET: 모든 기본 파일이 로드될 대상 GCS 경로입니다.transfer_strategy이FULL_TRANSFER인 경우에만 사용할 수 있습니다.METASTORE: 이전할 메타스토어의 유형입니다. 다음 값 중 하나로 설정합니다.DATAPROC_METASTORE: Dataproc Metastore로 메타데이터를 전송합니다.BIGLAKE_REST_CATALOG: 메타데이터를 Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그로 전송합니다 (Iceberg 테이블에 권장).BIGLAKE_HIVE_CATALOG: 메타데이터를 Lakehouse 런타임 카탈로그 Hive 카탈로그로 전송합니다 (Apache Hive 테이블에 권장) (미리보기).
DATAPROC_METASTORE_URL: Dataproc Metastore의 URL입니다.metastore이DATAPROC_METASTORE인 경우 필수입니다.HIVE_CATALOG_ID: Lakehouse 런타임 카탈로그 Hive 카탈로그의 ID입니다.metastore이BIGLAKE_HIVE_CATALOG인 경우에 필요합니다. 카탈로그가 없으면 자동으로 생성됩니다.STORAGE_TYPE: 테이블의 기본 파일 저장소를 지정합니다. 지원되는 유형은HDFS,S3,AZURE입니다.transfer_strategy이FULL_TRANSFER인 경우 필수입니다.AGENT_POOL_NAME: 에이전트 생성에 사용되는 에이전트 풀의 이름입니다.storage_type이HDFS인 경우에 필요합니다.AWS_ACCESS_KEY_ID: 액세스 사용자 인증 정보의 액세스 키 ID입니다.storage_type이S3인 경우에 필요합니다.AWS_SECRET_ACCESS_KEY: 액세스 사용자 인증 정보의 보안 액세스 키입니다.storage_type이S3인 경우 필수입니다.AZURE_SAS_TOKEN: 액세스 사용자 인증 정보의 SAS 토큰입니다.storage_type이AZURE인 경우 필수입니다.FILTER_GCS_PATH: (선택사항) 파티션을 필터링하는 맞춤 필터 JSON 파일의 전체 Cloud Storage 경로입니다.
이 명령어를 실행하여 전송 구성을 만들고 Hive 관리 테이블 전송을 시작합니다. 전송은 기본적으로 24시간마다 실행되도록 예약되지만 전송 예약 옵션을 사용하여 구성할 수 있습니다.
전송이 완료되면 Hadoop 클러스터의 테이블이 MIGRATION_BUCKET으로 마이그레이션됩니다.
cron 작업으로 덤퍼 도구 실행 자동화
dwh-migration-dumper 도구를 실행하는 cron 작업을 사용하여 증분 전송을 자동화할 수 있습니다. 메타데이터 추출을 자동화하여 후속 증분 전송 실행에 데이터 소스의 최신 덤프를 사용할 수 있습니다.
시작하기 전에
이 자동화 스크립트를 사용하기 전에 다음을 수행해야 합니다.
dumper 도구의 모든 기본 요건을 완료합니다.
Google Cloud CLI를 설치합니다. 스크립트는
gsutil명령줄 도구를 사용하여 덤퍼 출력을 Cloud Storage에 업로드합니다.gsutil가 Cloud Storage에 파일을 업로드할 수 있도록 Google Cloud 로 인증하려면 다음 명령어를 실행합니다.gcloud auth application-default login
자동화 예약
다음 스크립트를 로컬 파일에 저장합니다. 이 스크립트는
cron데몬이 구성하고 실행하여 덤퍼 출력의 추출 및 업로드 프로세스를 자동화하도록 설계되었습니다.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.스크립트를 실행 가능하게 만들려면 다음 명령어를 실행합니다.
chmod +x PATH_TO_SCRIPT
crontab를 사용하여 스크립트를 예약하고 변수를 작업에 적합한 값으로 바꿉니다. 작업을 예약하는 항목을 추가합니다. 다음 예에서는 매일 오전 2시 30분에 스크립트를 실행합니다.Hive Metastore에 직접 액세스할 수 있고 Kerberos 인증이 필요하지 않은 호스트에서 실행하는 경우 다음 명령어를 실행합니다.
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Hive Metastore 인스턴스에 Kerberos 인증이 필요한 경우 다음 명령어를 실행합니다.
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
예약 고려사항
데이터가 오래되지 않도록 하려면 예약된 데이터 전송 전에 덤퍼 도구를 실행하세요.
스크립트를 수동으로 몇 번 실행하여 덤퍼 도구가 출력을 생성하는 데 걸리는 평균 시간을 확인하는 것이 좋습니다. 이 타이밍을 사용하여 전송 실행 전에 cron 작업 일정을 설정하여 데이터 최신 상태를 유지합니다.
전송 상태 모니터링 및 확인
개별 테이블의 리소스 수준 전송을 모니터링하여 진행 상황을 추적하고, 세부적인 오류 세부정보를 확인하고, 이전 중인 특정 리소스의 상태를 쿼리할 수 있습니다.
리소스의 진행 상황과 상태를 보려면 다음 옵션 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 데이터 전송 페이지로 이동합니다.
목록에서 전송 구성을 클릭합니다.
전송 세부정보 페이지에서 전송된 테이블 탭을 클릭합니다.
전송되는 리소스 목록을 확인합니다. 다음과 같은 세부정보를 확인할 수 있습니다.
- 마지막 전송 상태: 완료 진행률을 포함하여 최신 리소스 전송을 기반으로 하는 리소스의 현재 상태입니다.
- 표 이름: 전송 중인 리소스의 이름입니다. 리소스 이름을 클릭하여 리소스의 세부정보를 확인합니다.
- 최신 실행: 리소스를 업데이트한 마지막 전송 실행입니다.
- 상태 요약: 전송이 실패한 경우 상세 진행률 측정항목 또는 오류 메시지
- 마지막으로 완료한 실행: 리소스가 성공적으로 전송된 마지막 실행입니다.
필터 표시줄을 사용하여 이름으로 특정 리소스를 검색하거나 현재 상태(예: 실패한 전송)로 필터링합니다. 테이블 이름 필터는 와일드 카드 일치(예: * 사용)를 지원하지만 다른 필터 필드에서는 와일드 카드 일치가 지원되지 않습니다.
API
BigQuery Data Transfer Service API를 사용하여 전송 리소스의 상태를 쿼리할 수 있습니다.
모든 리소스와 상태 나열
모든 리소스와 해당 상태를 나열하려면 projects.locations.transferConfigs.transferResources.list 메서드를 사용합니다.
다음 정보를 사용하여 API 요청을 실행합니다.
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
curl 명령어:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
리소스 이름 또는 상태별로 결과를 필터링할 수 있습니다. 예를 들어 실패한 전송을 모두 찾으려면 요청 URL에 ?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED"를 추가합니다.
다음을 바꿉니다.
CONFIG_ID: 전송 구성의 ID입니다.LOCATION: 전송 구성이 생성된 위치입니다.PROJECT_ID: 전송을 실행하는 Google Cloud 프로젝트의 ID입니다.
특정 리소스 가져오기
특정 테이블 또는 파티션의 상태를 가져오려면 projects.locations.transferConfigs.transferResources.get 메서드를 사용합니다.
다음 정보를 사용하여 API 요청을 실행합니다.
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
curl 명령어:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
다음을 바꿉니다.
CONFIG_ID: 전송 구성의 ID입니다.LOCATION: 전송 구성이 생성된 위치입니다.PROJECT_ID: 전송을 실행하는 Google Cloud 프로젝트의 ID입니다.RESOURCE_ID: 리소스의 ID입니다(예: 테이블 이름).
할당량 및 동시 실행 제한
모든 BigQuery Data Transfer Service 실행에 대해 Hive Metastore 커넥터는 테이블당 하나의 Storage Transfer Service 작업을 실행합니다.
할당량에 도달하면 할당량이 추가로 제공될 때까지 전송이 대기합니다. Storage Transfer Service 작업은 고객 프로젝트에서 생성되며 Storage Transfer Service 할당량 및 한도가 적용됩니다.
가격 책정
Apache Hive Metastore 커넥터를 사용하여 데이터를 전송하는 데는 비용이 들지 않습니다. 데이터가 전송된 후 대상에 데이터를 저장하는 데는 요금이 청구됩니다. 자세한 내용은 다음을 참조하세요.