
העברת טבלאות של Apache Hive Metastore אל Google Cloud
במאמר הזה מוסבר איך להעביר טבלאות Iceberg ו-Hive שמנוהלות על ידי Apache Hive Metastore אלGoogle Cloud באמצעות שירות העברת הנתונים ל-BigQuery.
מחבר ההעברה של Apache Hive Metastore בשירות העברת הנתונים ל-BigQuery מאפשר להעביר בצורה חלקה את טבלאות Hive Metastore ל- Google Cloud בהיקף גדול. המחבר הזה תומך בטבלאות Hive ו-Iceberg מהתקנות מקומיות ומסביבות ענן, כולל הגדרות Cloudera. מחבר ההעברה של Hive Metastore תומך בקבצים שמאוחסנים במקורות הנתונים הבאים:
- Apache Hadoop Distributed File System (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage או Azure Data Lake Storage Gen2
בעזרת מחבר ההעברה של Hive Metastore, אתם יכולים להשתמש ב-Cloud Storage כאחסון הקבצים ולרשום את הטבלאות של Hive Metastore באחד ממאגרי המטא-נתונים הבאים:
קטלוג זמן הריצה של Lakehouse Iceberg REST Catalog
מומלץ להשתמש בקטלוג Iceberg REST של Lakehouse runtime לכל נתוני Iceberg.
קטלוג ה-REST של Iceberg, שנוצר על ידי קטלוג זמן הריצה של Lakehouse, מאפשר יכולת פעולה הדדית בין מנועי השאילתות שלכם על ידי הצעת מקור יחיד של נתונים מהימנים לכל נתוני Iceberg. אתם יכולים להשתמש ב-BigQuery כדי להריץ שאילתות על הנתונים, בנוסף ל-Apache Spark ולמנועי OSS אחרים. קטלוג Iceberg REST של Lakehouse runtime תומך רק בפורמטים של טבלאות Iceberg.
Lakehouse runtime catalog Hive Catalog (תצוגה מקדימה)
מומלץ להשתמש ב-Hive Catalog של Lakehouse runtime לכל טבלאות ה-Hive.
הקטלוג של Lakehouse runtime (זמן ריצה של Lakehouse) מאפשר לכם לרשום את טבלאות Hive שהועברו באמצעות קטלוג Hive. השירות הזה מציע metastore ללא שרת לטבלאות Apache Hive. אתם יכולים להשתמש ב-BigQuery כדי לשלוח שאילתות לנתונים (בכפוף למגבלות הפורמט), בנוסף ל-Apache Spark ולמנועי OSS אחרים.
-
Dataproc Metastore תומך בפורמטים של טבלאות Hive ו-Iceberg. אפשר להשתמש רק ב-Apache Spark ובמנועי OSS אחרים כדי לקרוא ולכתוב נתונים ב-Dataproc Metastore.
המחבר הזה תומך בהעברות מלאות ובהעברות של מטא-נתונים בלבד. העברות מלאות יעבירו גם את הנתונים וגם את המטא-נתונים מטבלאות המקור אל מאגר המטא-נתונים של היעד. אתם יכולים ליצור העברה של מטא-נתונים בלבד אם הנתונים שלכם כבר נמצאים ב-Cloud Storage ואם אתם רוצים רק לרשום את הנתונים במאגר מטא-נתונים של יעד.
בתרשים הבא מוצגת סקירה כללית של תהליך ההעברה.
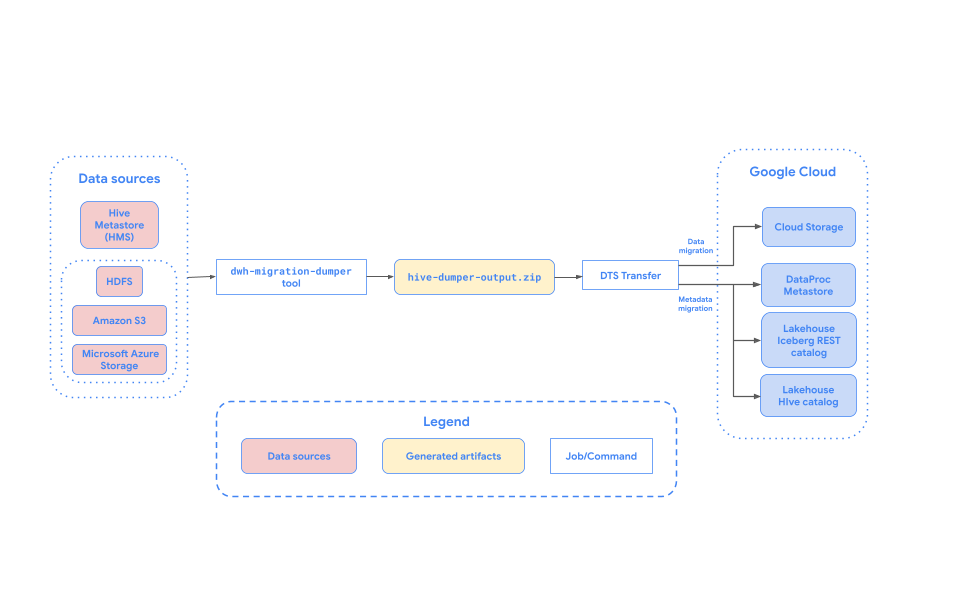
מגבלות
העברות של טבלאות Hive Metastore כפופות למגבלות הבאות:
- ההפרש בין שני מועדים מתוזמנים להרצת העברה של Hive Metastore צריך להיות לפחות 30 דקות. עדיין אפשר להפעיל ריצות על פי דרישה בכל מרווח זמן.
- שמות הקבצים צריכים לעמוד בדרישות של מתן שמות לאובייקטים ב-Cloud Storage.
- ב-Cloud Storage יש מגבלה של 5TiB לאובייקטים בודדים. העברה של קבצים בטבלאות Hive Metastore שגדולים מ-5TiB תיכשל.
- ל-Storage Transfer Service יש התנהגויות ספציפיות אם הנתונים משתנים במקור בזמן שההעברה מתבצעת. אנחנו לא ממליצים לכתוב לטבלאות בזמן שהטבלה עוברת העברה פעילה. רשימה של מגבלות נוספות של Storage Transfer Service זמינה במאמר מגבלות ידועות.
מגבלות של קטלוג Hive בזמן ריצה של Lakehouse
כשמשתמשים ב-Hive Catalog (BIGLAKE_HIVE_CATALOG) של Lakehouse runtime בתור מאגר המטא-נתונים של היעד, חלות ההגבלות וההערות הבאות:
- מזהה קטלוג Hive של זמן הריצה של Lakehouse חייב להכיל רק אותיות קטנות, מספרים וקווים תחתונים (
_). הוא לא יכול להכיל מקפים (-) או אותיות גדולות. - אי אפשר לראות או לנהל קטלוגים של Hive בזמן ריצה של Lakehouse במסוף Google Cloud . עם זאת, הטבלאות שהועברו גלויות וניתן להריץ עליהן שאילתות במערך הנתונים של BigQuery.
- כל המגבלות של קטלוג Hive בזמן הריצה של Lakehouse חלות על פורמטים של מטא-נתונים וסוגי נתונים בקוד פתוח.
- מידע על תאימות לפורמטים כמו CSV ו-JSON זמין במאמר בנושא פורמטים נתמכים לאחסון.
- מידע על סוגי נתונים שלא נתמכים (כמו
UNIONאו מערכים מקוננים) ועל נתונים סטטיסטיים של עמודות זמין במאמרים בנושא מגבלות של מאגר המטא-נתונים ומגבלות של מחיצות.
אפשרויות להטמעת נתונים
בקטעים הבאים מוסבר איך להגדיר העברות של Hive Metastore.
העברות מצטברות
כשמגדירים העברה עם לוח זמנים חוזר, כל העברה שמתבצעת לאחר מכן מעדכנת את הטבלה ב- Google Cloud עם העדכונים האחרונים שבוצעו בטבלת המקור. לדוגמה, כל עדכוני הנתונים וכל פעולות ההוספה, המחיקה או העדכון עם שינויים בסכימה משתקפים Google Cloud בכל העברה.
סינון מחיצות
אפשר להעביר קבוצת משנה של מחיצות מטבלאות Hive על ידי מתן קובץ JSON של מסנן מותאם אישית שמאוחסן ב-Cloud Storage. כשמתזמנים את ההעברה, צריך לספק את הנתיב המלא ב-Cloud Storage לקובץ ה-JSON הזה באמצעות הפרמטר partition_filter_gcs_path.
הנה דוגמה למבנה של קובץ JSON של מסנן:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
תנאי סינון
השדה condition בקובץ ה-JSON תומך בערכים הבאים, שלכל אחד מהם יש פורמט ספציפי למערך partitions:
-
IN: מציין את הנתיבים המדויקים של המחיצות שרוצים לכלול. המערךpartitionsכולל מחרוזות שמייצגות את מבנה הספריות המדויק של המחיצות ביחס לנתיב הבסיס של הטבלה (לדוגמה,["partition_key1=value1/partition_key2=value2"]). אפשר לציין כמה נתיבים במערך. -
LESS_THAN: כולל מחיצות שבהן הערך של מפתח המחיצה הראשי קטן מהערך שצוין או שווה לו. המערךpartitionsחייב להכיל מחרוזת אחת בפורמט["<partition_key>;<value>"]. -
GREATER_THAN: כולל מחיצות שבהן הערך של מפתח המחיצה הראשי גדול מהערך שצוין או שווה לו. המערךpartitionsחייב להכיל מחרוזת אחת בפורמט["<partition_key>;<value>"]. -
RANGE: כולל מחיצות שבהן הערך של מפתח המחיצה הראשי נמצא בטווח שצוין (כולל). המערךpartitionsחייב להכיל מחרוזת אחת בפורמט["<partition_key>;<start_value>;<end_value>"].
תנאי הסינון כפופים לכללים ולהגבלות הבאים:
- ערכים כוללים: תנאי הסינון של
GREATER_THAN,LESS_THANו-RANGEכוללים את הערכים שצוינו. לדוגמה, מסנןLESS_THANעם ערך של2023כולל מחיצות עד2023כולל. - מחיקת מחיצה: אם מחיצת יעד קיימת עומדת בדרישות של מסנן המחיצה ולא קיימת יותר במקור, היא תוסר ממאגר המטא-נתונים של היעד. עם זאת, קובצי הנתונים הבסיסיים של המחיצה הזו לא נמחקים מקטגוריית היעד ב-Cloud Storage.
- הגבלות על טבלה אחת:
- אסור להשתמש בכמה מסננים באותה טבלה.
- אי אפשר לשלב סוגים שונים של תנאים (לדוגמה:
GREATER_THANו-IN) באותה טבלה.
- עמודת מחיצה של יעד: תנאי סינון כמו
GREATER_THAN,LESS_THANו-RANGEצריכים להיות מכוונים לעמודת המחיצה הראשית. - מגבלות על קידומות: שילוב המסננים שצוין לא יכול להניב יותר מ-1,000 קידומות לכל טבלה. לדוגמה, מסנן כמו
year>2020בטבלה שמחולקת למחיצות לפיyear/month/dayצריך להניב פחות מ-1,000 קידומות ייחודיות שלyear=.
לפני שמתחילים
לפני שתזמנו העברה של Hive Metastore, תצטרכו לבצע את השלבים שבקטע הזה.
הפעלת ממשקי ה-API
מפעילים את ממשקי ה-API הבאים בפרויקט ב-Google Cloud :
- Data Transfer API
- Storage Transfer API
- BigLake API
סוכן שירות נוצר כשמפעילים את Data Transfer API.
הגדרת ההרשאות
כדי להגדיר הרשאות להעברה של Hive Metastore, צריך לבצע את השלבים בקטעים הבאים.
- למשתמש או לחשבון השירות שיוצרים את ההעברה צריכה להיות הרשאת אדמין ב-BigQuery (
roles/bigquery.admin). אם משתמשים בחשבון שירות, הוא משמש רק ליצירת ההעברה. סוכן שירות (P4SA) נוצר כשמפעילים את Data Transfer API.
כדי לוודא שלסוכן השירות יש את ההרשאות הנדרשות להפעלת העברה של Hive Metastore, צריך לבקש מהאדמין להקצות לסוכן השירות את תפקידי ה-IAM הבאים בפרויקט:
- אדמין של העברת נתונים באחסון (
roles/storagetransfer.admin) - צרכן שימוש בשירות (
roles/serviceusage.serviceUsageConsumer) - אדמין באחסון (
roles/storage.admin) -
כדי להעביר מטא-נתונים לקטלוג של זמן הריצה של Lakehouse (קטלוג REST של Iceberg או קטלוג Hive):
BigLake Admin (
roles/biglake.admin) -
כדי להעביר מטא נתונים אל Dataproc Metastore:
בעל נתונים ב-Dataproc Metastore (
roles/metastore.metadataOwner)
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שהאדמין גם יוכל לתת לסוכן השירות את ההרשאות שנדרשות באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
- אדמין של העברת נתונים באחסון (
אם משתמשים בחשבון שירות, מקצים לסוכן השירות את התפקיד
roles/iam.serviceAccountTokenCreatorבאמצעות הפקודה הבאה:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
מקצים לסוכן השירות של Storage Transfer Service (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) את התפקידים הבאים בפרויקט:roles/storage.admin- אם אתם מבצעים העברה מ-on-prem או מ-HDFS, אתם צריכים גם להקצות את התפקיד
roles/storagetransfer.serviceAgent.
אפשר גם להגדיר הרשאות מפורטות יותר. מידע נוסף זמין במדריך הבא:
יצירת קובץ מטא-נתונים ל-Apache Hive
מריצים את dwh-migration-dumper הכלי כדי לחלץ מטא-נתונים עבור Apache Hive.
הכלי יוצר קובץ בשם hive-dumper-output.zip שאפשר להעלות אותו לקטגוריה של Cloud Storage. במסמך הזה, קטגוריית Cloud Storage הזו נקראת DUMPER_BUCKET.
אפשר גם לתזמן העלאות תקופתיות באמצעות סקריפט. מידע נוסף מופיע במאמר בנושא אוטומציה של הפעלת כלי ה-dumper באמצעות משימת cron.
הגדרת Storage Transfer Service
בוחרים באחת מהאפשרויות הבאות:
HDFS
נדרש סוכן להעברת אחסון להעברות מקומיות או להעברות HDFS.
כדי להגדיר את הסוכן:
- מתקינים את Docker במכונות של סוכנים מקומיים.
- יוצרים מאגר של סוכני שירות של Storage Transfer Service בפרויקט Google Cloud .
- מתקינים סוכנים במכונות הסוכנים המקומיות.
Amazon S3
העברות מ-Amazon S3 הן העברות ללא סוכן.
כדי להגדיר את Storage Transfer Service להעברה מ-Amazon S3, צריך לבצע את הפעולות הבאות:
- הגדרת פרטי גישה ל-AWS Amazon S3
- אחרי שמגדירים את פרטי הגישה, חשוב לזכור את המזהה של מפתח הגישה ואת מפתח הגישה הסודי.
- אם בפרויקט AWS שלכם יש הגבלות על כתובות IP, צריך להוסיף את טווחי כתובות ה-IP שמשמשים את העובדים של Storage Transfer Service לרשימת כתובות ה-IP המותרות.
Microsoft Azure
העברות מ-Microsoft Azure Storage הן העברות ללא סוכן.
כדי להגדיר את Storage Transfer Service להעברה של Microsoft Azure Storage, צריך לבצע את הפעולות הבאות:
- יוצרים אסימון של חתימת גישה משותפת (SAS) לחשבון האחסון שלכם ב-Microsoft Azure.
- אחרי שיוצרים את טוקן ה-SAS, חשוב לשים לב לטוקן.
- אם בחשבון האחסון שלכם ב-Microsoft Azure יש הגבלות על כתובות IP, צריך להוסיף לרשימת כתובות ה-IP המותרות את טווחי כתובות ה-IP שמשמשים את העובדים של שירות העברת הנתונים.
תזמון העברה של Hive Metastore
בוחרים באחת מהאפשרויות הבאות:
המסוף
עוברים לדף 'העברות נתונים' במסוף Google Cloud .
לוחצים על Create transfer (יצירת העברה).
בקטע Source type, בוחרים באפשרות Hive Metastore מהרשימה Source.
בקטע מיקום, בוחרים סוג מיקום ואז בוחרים אזור.
בקטע Transfer config name (שם הגדרת ההעברה), בשדה Display name (שם מוצג), מזינים שם להעברת הנתונים.
בקטע Schedule options:
- ברשימה תדירות החזרה, בוחרים אפשרות כדי לציין באיזו תדירות תתבצע העברת הנתונים הזו. כדי לציין תדירות חזרה מותאמת אישית, בוחרים באפשרות בהתאמה אישית. אם בוחרים באפשרות על פי דרישה, ההעברה תתבצע כשמפעילים אותה ידנית.
- אם רלוונטי, בוחרים באפשרות התחלה מיידית או התחלה בשעה שנקבעה, ומזינים תאריך התחלה ומשך זמן הפעלה.
בקטע Data source details (פרטים של מקור הנתונים), מבצעים את הפעולות הבאות:
- בקטע Transfer strategy (שיטת ההעברה), בוחרים באחת מהאפשרויות הבאות:
-
FULL_TRANSFER: העברת כל הנתונים ורישום המטא-נתונים במאגר המטא-נתונים של היעד. זו האפשרות שמוגדרת כברירת המחדל. -
METADATA_ONLY: רישום מטא-נתונים בלבד. הנתונים צריכים להיות כבר במיקום הנכון ב-Cloud Storage שאליו מתייחסים המטא-נתונים.
-
- בקטע Table name patterns (תבניות של שמות טבלאות), מציינים את הטבלאות של אגם הנתונים ב-HDFS שרוצים להעביר. אפשר לציין שמות של טבלאות או תבניות שמתאימות לטבלאות במסד הנתונים של HDFS. כדי לציין דפוסי טבלה, צריך להשתמש בתחביר של ביטויים רגולריים ב-Java. לדוגמה:
-
db1..*תואם לכל הטבלאות ב-db1. -
db1.table1;db2.table2תואם ל-table1 ב-db1 ול-table2 ב-db2.
-
- בשדה BQMS discovery dump gcs path (נתיב GCS של קובץ dump של גילוי BQMS), מזינים את הנתיב לקובץ
hive-dumper-output.zipשיצרתם כשיצרתם קובץ מטא נתונים עבור Apache Hive. אם אתם משתמשים באוטומציה של פלט dumper עםcron, צריך לציין את נתיב התיקייה ב-Cloud Storage שהוגדר ב---gcs-base-path, שמכילה קובצי ZIP של פלט dumper.- בקטע סוג אחסון, בוחרים אחת מהאפשרויות הבאות. השדה הזה זמין רק אם שיטת ההעברה מוגדרת לערך
FULL_TRANSFER: -
HDFS: בוחרים באפשרות הזו אם נפח האחסון של הקובץ הואHDFS. בשדה STS agent pool name (שם מאגר הסוכנים של STS), צריך לציין את השם של מאגר הסוכנים שיצרתם כשהגדרתם את Storage Transfer Agent. -
S3: בוחרים באפשרות הזו אם נפח האחסון של הקובץ הואAmazon S3. בשדות מזהה מפתח הגישה ומפתח הגישה הסודי, צריך לספק את מזהה מפתח הגישה ואת מפתח הגישה הסודי שיצרתם כשהגדרתם את פרטי הגישה. -
AZURE: בוחרים באפשרות הזו אם נפח האחסון של הקובץ הואAzure Blob Storage. בשדה SAS token, צריך לציין את טוקן ה-SAS שיצרתם כשהגדרתם את פרטי הגישה.
- בקטע סוג אחסון, בוחרים אחת מהאפשרויות הבאות. השדה הזה זמין רק אם שיטת ההעברה מוגדרת לערך
- אופציונלי: בשדה Partition Filter gcs path (נתיב GCS של מסנן מחיצות), מזינים נתיב מלא ב-Cloud Storage לקובץ JSON של מסנן בהתאמה אישית כדי לסנן מחיצות מטבלאות מקור.
- בשדה נתיב יעד ב-GCS, מזינים נתיב לקטגוריה של Cloud Storage שבה רוצים לאחסן את הנתונים שהועברו.
- בוחרים את סוג ה-Metastore של היעד מהרשימה הנפתחת:
-
DATAPROC_METASTORE: בוחרים באפשרות הזו כדי לאחסן את המטא-נתונים ב-Dataproc Metastore. חובה לספק את כתובת ה-URL של Dataproc Metastore בכתובת ה-URL של Dataproc Metastore. -
BIGLAKE_REST_CATALOG: בוחרים באפשרות הזו כדי לאחסן את המטא-נתונים בקטלוג זמן הריצה של Lakehouse, קטלוג REST של Iceberg. הקטלוג נוצר על סמך קטגוריית Cloud Storage של היעד. -
BIGLAKE_HIVE_CATALOG(תצוגה מקדימה): בוחרים באפשרות הזו כדי לאחסן את המטא-נתונים בקטלוג של זמן הריצה של Lakehouse, Hive Catalog. חובה לציין שם קטלוג במזהה קטלוג Hive של BigLake Metastore. אם הקטלוג לא קיים, הוא ייווצר באופן אוטומטי.
-
- אופציונלי: בשדה Service account, מזינים חשבון שירות לשימוש בהעברת הנתונים הזו. חשבון השירות צריך להיות שייך לאותוGoogle Cloud פרויקט שבו נוצרו הגדרות ההעברה ומערך נתוני היעד.
- בקטע Transfer strategy (שיטת ההעברה), בוחרים באחת מהאפשרויות הבאות:
BQ
כדי לתזמן העברה של Hive Metastore, מזינים את הפקודה bq mk
ומספקים את דגל יצירת ההעברה --transfer_config:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
מחליפים את מה שכתוב בשדות הבאים:
-
TRANSFER_NAME: השם המוצג של הגדרות ההעברה. שם ההעברה יכול להיות כל ערך שיעזור לכם לזהות את ההעברה אם תצטרכו לשנות אותה בהמשך. -
SERVICE_ACCOUNT: השם של חשבון השירות שמשמש ליצירת ההעברה.חשבון השירות צריך להיות שייך לאותוGoogle Cloud פרויקט שבו נוצרו הגדרות ההעברה ומערך נתוני היעד. -
PROJECT_ID: מזהה הפרויקט ב- Google Cloud . אם לא מציינים את--project_idכדי לציין פרויקט מסוים, המערכת משתמשת בפרויקט שמוגדר כברירת מחדל. -
REGION: המיקום של הגדרות ההעברה. -
TRANSFER_STRATEGY: (אופציונלי) מציינים אחד מהערכים הבאים:-
FULL_TRANSFER: העברת כל הנתונים ורישום המטא-נתונים במאגר המטא-נתונים של היעד. זה ערך ברירת המחדל. -
METADATA_ONLY: רישום מטא-נתונים בלבד. הנתונים צריכים להיות כבר במיקום הנכון ב-Cloud Storage שאליו מתייחסים המטא-נתונים.
-
-
LIST_OF_TABLES: רשימה של ישויות להעברה. משתמשים במפרט שמות היררכי –database.table. השדה הזה תומך בביטויים רגולריים של RE2 כדי לציין טבלאות. לדוגמה:-
db1..*: מציין את כל הטבלאות במסד הנתונים -
db1.table1;db2.table2: רשימה של טבלאות
-
-
DUMPER_BUCKET: קטגוריה של Cloud Storage שמכילה את קובץhive-dumper-output.zip. אם אתם משתמשים באוטומציה של פלט dumper עםcron, אתם צריכים לשנות אתtable_metadata_pathלנתיב התיקייה ב-Cloud Storage שהוגדר עם--gcs-base-pathבהגדרת cron – לדוגמה:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>". -
MIGRATION_BUCKET: נתיב היעד ב-GCS שאליו ייטענו כל הקבצים הבסיסיים. זמין רק אםtransfer_strategyהואFULL_TRANSFER. -
METASTORE: סוג חנות המטא-נתונים שאליה רוצים להעביר את הנתונים. מגדירים את הערך הזה לאחד מהערכים הבאים:-
DATAPROC_METASTORE: להעברת מטא-נתונים אל Dataproc Metastore. -
BIGLAKE_REST_CATALOG: להעברת מטא-נתונים לקטלוג של זמן הריצה של Lakehouse, קטלוג REST של Iceberg (מומלץ לטבלאות Iceberg). -
BIGLAKE_HIVE_CATALOG: להעברת מטא-נתונים לקטלוג של Lakehouse runtime Hive Catalog (מומלץ לטבלאות של Apache Hive) (גרסת Preview).
-
-
DATAPROC_METASTORE_URL: כתובת ה-URL של Dataproc Metastore. חובה אם הערך שלmetastoreהואDATAPROC_METASTORE. -
HIVE_CATALOG_ID: המזהה של קטלוג Hive של זמן הריצה של Lakehouse. חובה אם הערך שלmetastoreהואBIGLAKE_HIVE_CATALOG. אם הקטלוג לא קיים, הוא ייווצר באופן אוטומטי. -
STORAGE_TYPE: ציון האחסון הבסיסי של הקבצים לטבלאות. הסוגים הנתמכים הםHDFS,S3ו-AZURE. חובה אם הערך שלtransfer_strategyהואFULL_TRANSFER. -
AGENT_POOL_NAME: השם של מאגר הסוכנים שמשמש ליצירת סוכנים. חובה אם הערך שלstorage_typeהואHDFS. -
AWS_ACCESS_KEY_ID: מזהה מפתח הגישה מתוך פרטי הגישה. חובה אם הערך שלstorage_typeהואS3. -
AWS_SECRET_ACCESS_KEY: מפתח הגישה הסודי מפרטי הכניסה לגישה. חובה אם הערך שלstorage_typeהואS3. -
AZURE_SAS_TOKEN: טוקן ה-SAS מפרטי הגישה. חובה אם הערך שלstorage_typeהואAZURE. -
FILTER_GCS_PATH: (אופציונלי) נתיב מלא ב-Cloud Storage לקובץ JSON של מסנן מותאם אישית לסינון מחיצות.
מריצים את הפקודה הזו כדי ליצור את הגדרת ההעברה ולהתחיל בהעברת טבלאות מנוהלות של Hive. ההעברות מתוזמנות להפעלה כל 24 שעות כברירת מחדל, אבל אפשר להגדיר אותן באמצעות אפשרויות תזמון העברה.
בסיום ההעברה, הטבלאות שלכם באשכול Hadoop יועברו אל MIGRATION_BUCKET.
אוטומציה של הפעלת כלי ה-dumper באמצעות cron job
אפשר להשתמש במשימה של cron כדי להריץ את הכלי dwh-migration-dumper ולהפוך את ההעברות המצטברות לאוטומטיות. אוטומציה של חילוץ המטא-נתונים כדי להבטיח שיהיה זמין dump עדכני ממקור הנתונים להפעלות הבאות של העברה מצטברת.
לפני שמתחילים
לפני שמשתמשים בסקריפט האוטומציה הזה, צריך לבצע את הפעולות הבאות:
מבצעים את כל הפעולות הנדרשות לשימוש בכלי ליצירת קובץ dump.
מתקינים את Google Cloud CLI. הסקריפט משתמש בכלי שורת הפקודה
gsutilכדי להעלות את הפלט של הכלי dumper ל-Cloud Storage.כדי לבצע אימות באמצעות Google Cloud כדי לאפשר ל-
gsutilלהעלות קבצים ל-Cloud Storage, מריצים את הפקודה הבאה:gcloud auth application-default login
תזמון הפעולה האוטומטית
שומרים את הסקריפט הבא בקובץ מקומי. הסקריפט הזה מיועד להגדרה ולהפעלה על ידי דמון
cronכדי לבצע אוטומטית את תהליך החילוץ וההעלאה של פלט הכלי dumper.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.כדי להפוך את הסקריפט לניתן להרצה, מריצים את הפקודה הבאה:
chmod +x PATH_TO_SCRIPT
מתזמנים את הסקריפט באמצעות
crontab, ומחליפים את המשתנים בערכים המתאימים לעבודה. מוסיפים רשומה כדי לתזמן את העבודה. בדוגמאות הבאות, הסקריפט מופעל כל יום בשעה 2:30:אם אתם מריצים את המערכת במארח שיש לו גישה ישירה ל-Hive Metastore ולא נדרש אימות Kerberos, מריצים את הפקודה הבאה:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
אם נדרשת אימות Kerberos במופע Hive Metastore, מריצים את הפקודה הבאה:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
שיקולים לתזמון
כדי למנוע נתונים לא עדכניים, מומלץ להריץ את כלי ה-dumper לפני העברת הנתונים המתוזמנת.
מומלץ להריץ את הסקריפט כמה פעמים באופן ידני כדי לקבוע את הזמן הממוצע שנדרש לכלי ליצירת הפלט. אפשר להשתמש בתזמון הזה כדי להגדיר cron תזמון של משימה שתקדים את ההרצה של ההעברה, כדי לוודא את עדכניות הנתונים.
בדיקה של סטטוס ההעברה
אתם יכולים לעקוב אחרי ההתקדמות של העברות ברמת המשאב של טבלאות ספציפיות, לראות פרטים מדויקים על שגיאות ולשאול על הסטטוס של משאבים ספציפיים שמועברים.
כדי לראות את ההתקדמות והסטטוס של המשאבים, בוחרים באחת מהאפשרויות הבאות:
המסוף
נכנסים לדף Data transfers במסוף Google Cloud .
לוחצים על הגדרת ההעברה מהרשימה.
בדף פרטי ההעברה, לוחצים על הכרטיסייה טבלאות שהועברו.
צפייה ברשימת המשאבים שמועברים. אפשר לראות פרטים כמו:
- סטטוס ההעברה האחרונה: המצב הנוכחי של המשאב על סמך העברת המשאב האחרונה, כולל התקדמות ההשלמה.
- שם הטבלה: השם של המשאב שמועבר. לוחצים על שם המשאב כדי לראות תצוגה מפורטת של המשאב.
- ההרצה האחרונה: ההרצה האחרונה של ההעברה שעדכנה את המשאב.
- סיכום הסטטוס: מדדי התקדמות מפורטים או הודעות שגיאה אם ההעברה נכשלה.
- ההפעלה המוצלחת האחרונה: ההפעלה האחרונה שבה הועבר המשאב בהצלחה.
אפשר להשתמש בסרגל הסינון כדי לחפש משאבים ספציפיים לפי שם או לסנן לפי הסטטוס הנוכחי שלהם, לדוגמה, העברות שנכשלו. המסנן שם הטבלה תומך בהתאמה של תווים כלליים לחיפוש – לדוגמה, באמצעות * – אבל אין תמיכה בהתאמה של תווים כלליים לחיפוש בשדות מסנן אחרים.
API
אפשר להריץ שאילתות על סטטוס של משאבי העברה באמצעות BigQuery Data Transfer Service API.
הצגת רשימה של כל המשאבים והסטטוסים שלהם
כדי להציג רשימה של כל המשאבים והסטטוסים שלהם, משתמשים בשיטה projects.locations.transferConfigs.transferResources.list.
מריצים את בקשת ה-API עם הפרטים הבאים:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
פקודה curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
אפשר לסנן את התוצאות לפי שם המשאב או הסטטוס. לדוגמה, כדי למצוא את כל ההעברות שנכשלו, מוסיפים את המחרוזת ?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED" לכתובת ה-URL של הבקשה.
מחליפים את מה שכתוב בשדות הבאים:
-
CONFIG_ID: המזהה של הגדרות ההעברה. -
LOCATION: המיקום שבו נוצרה הגדרת ההעברה. -
PROJECT_ID: המזהה של Google Cloud הפרויקט שבו מתבצעות ההעברות.
קבלת משאב ספציפי
כדי לקבל את הסטטוס של טבלה או מחיצה ספציפית, משתמשים בשיטה projects.locations.transferConfigs.transferResources.get.
מריצים את בקשת ה-API עם הפרטים הבאים:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
פקודה curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
מחליפים את מה שכתוב בשדות הבאים:
-
CONFIG_ID: המזהה של הגדרות ההעברה. -
LOCATION: המיקום שבו נוצרה הגדרת ההעברה. -
PROJECT_ID: המזהה של Google Cloud הפרויקט שבו מתבצעות ההעברות. -
RESOURCE_ID: המזהה של המשאב, לדוגמה, שם הטבלה.
מכסות ומגבלות על מספר הפעולות שאפשר לבצע בו-זמנית
לכל הפעלה של שירות העברת הנתונים ל-BigQuery, מחבר Hive Metastore מפעיל משימה אחת של Storage Transfer Service לכל טבלה.
כשמגיעים למכסה, ההעברה ממתינה עד שתהיה מכסה נוספת. המשימות של Storage Transfer Service נוצרות בפרויקט של הלקוח, והן כפופות למכסות ולמגבלות של Storage Transfer Service.
תמחור
השימוש במחבר Apache Hive Metastore להעברת הנתונים לא כרוך בתשלום. אחרי העברת הנתונים, תחוייבו על אחסון הנתונים ביעד. למידע נוסף, קראו את המאמרים הבאים: