
Migre tabelas geridas do Hive para o Google Cloud
Este documento mostra como migrar as suas tabelas geridas do Hive para o Google Cloud.
Pode usar o conetor de migração de tabelas geridas do Hive no Serviço de transferência de dados do BigQuery para migrar facilmente as suas tabelas geridas pelo metastore do Hive, suportando os formatos Hive e Iceberg de ambientes nas instalações e na nuvem para o Google Cloud. Suportamos o armazenamento de ficheiros no HDFS ou no Amazon S3.
Com o conetor de migração de tabelas geridas do Hive, pode registar as suas tabelas geridas do Hive com o Dataproc Metastore, o metastore do BigLake ou o catálogo REST do Iceberg do metastore do BigLake enquanto usa o Cloud Storage como armazenamento de ficheiros.
O diagrama seguinte apresenta uma vista geral do processo de migração de tabelas do cluster Hadoop.
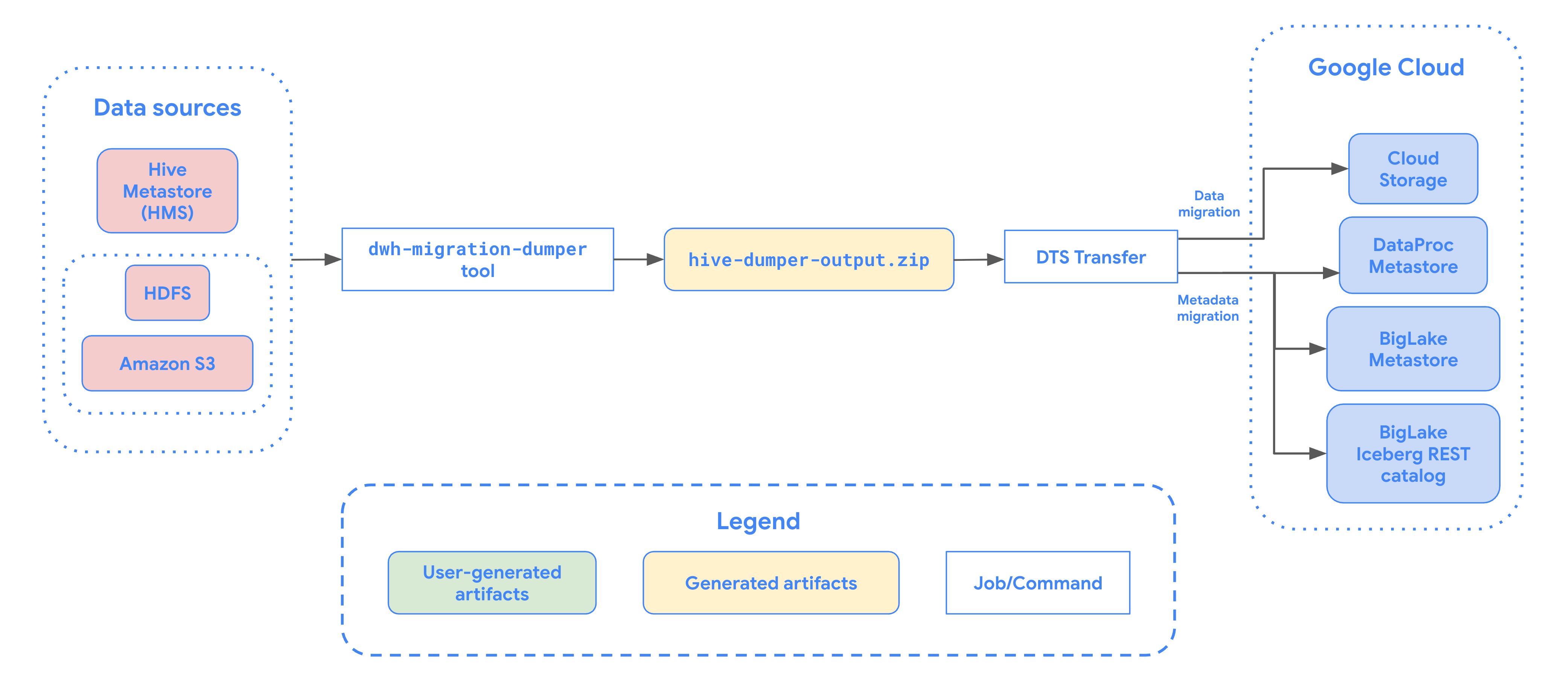
Limitações
As transferências de tabelas geridas do Hive estão sujeitas às seguintes limitações:
- Para migrar tabelas do Apache Iceberg, tem de registar as tabelas no metastore do BigLake para permitir o acesso de escrita para motores de código aberto (como o Apache Spark ou o Flink) e permitir o acesso de leitura para o BigQuery.
- Para migrar tabelas geridas do Hive, tem de registar as tabelas no Dataproc Metastore para permitir o acesso de escrita para motores de código aberto e o acesso de leitura para o BigQuery.
- Tem de usar a ferramenta de linha de comandos bq para migrar tabelas geridas do Hive para o BigQuery.
Antes de começar
Antes de agendar a transferência de tabelas geridas do Hive, tem de fazer o seguinte:
Gere um ficheiro de metadados para o Apache Hive
Execute a ferramenta dwh-migration-dumper para extrair metadados
para o Apache Hive. A ferramenta gera um ficheiro denominado hive-dumper-output.zip
num contentor do Cloud Storage, referido neste documento como DUMPER_BUCKET.
Ativar APIs
Ative as seguintes APIs no seu Google Cloud projeto:
- API da Transferência de dados
- API Storage Transfer
É criado um agente de serviço quando ativa a API Data Transfer.
Configure autorizações
- Crie uma conta de serviço e atribua-lhe a função de administrador do BigQuery (
roles/bigquery.admin). Esta conta de serviço é usada para criar a configuração de transferência. É criado um agente de serviço (P4SA) quando ativa a API Data Transfer. Conceda-lhe as seguintes funções:
roles/metastore.metadataOwnerroles/storagetransfer.adminroles/serviceusage.serviceUsageConsumerroles/storage.objectAdmin- Se estiver a migrar metadados para tabelas Iceberg do BigLake, também tem de conceder a função
roles/bigquery.admin. - Se estiver a migrar metadados para o catálogo REST do Iceberg do metastore do BigLake, também tem de conceder a função
roles/biglake.admin.
- Se estiver a migrar metadados para tabelas Iceberg do BigLake, também tem de conceder a função
Conceda à função do agente do serviço
roles/iam.serviceAccountTokenCreatorcom o seguinte comando:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Configure o Storage Transfer Service para lagos de dados HDFS
Obrigatório quando o ficheiro é armazenado no HDFS. Para configurar o agente de transferência de armazenamento necessário para uma transferência de lago de dados HDFS, faça o seguinte:
- Configure as autorizações para executar o agente de transferência de armazenamento no seu cluster Hadoop.
- Instale o Docker em máquinas de agentes no local.
- Crie um conjunto de agentes do serviço de transferência de armazenamento no seu Google Cloud projeto.
- Instale agentes nas suas máquinas de agentes no local.
Configure as autorizações do Serviço de transferência de armazenamento para o Amazon S3
Obrigatório quando o ficheiro está armazenado no Amazon S3. As transferências do Amazon S3 são transferências sem agente, que requerem autorizações específicas. Para configurar o Serviço de transferência de armazenamento para uma transferência do Amazon S3, faça o seguinte:
- Configure as autorizações de transferência sem agente.
- Configure as credenciais de acesso para o AWS Amazon S3.
- Anote o ID da chave de acesso e a chave de acesso secreta depois de configurar as credenciais de acesso.
- Adicione intervalos de IP usados pelos trabalhadores do serviço de transferência de armazenamento à sua lista de IPs permitidos se o seu projeto da AWS usar restrições de IP.
Agende a transferência de tabelas geridas do Hive
Selecione uma das seguintes opções:
Consola
Aceda à página Transferências de dados na Google Cloud consola.
Clique em Criar transferência.
Na secção Tipo de origem, selecione Tabelas geridas pelo Hive na lista Origem.
Para Localização, selecione um tipo de localização e, de seguida, selecione uma região.
Na secção Nome da configuração de transferência, em Nome a apresentar, introduza um nome para a transferência de dados.
Na secção Opções de agendamento, faça o seguinte:
- Na lista Frequência de repetição, selecione uma opção para especificar a frequência com que esta transferência de dados é executada. Para especificar uma frequência de repetição personalizada, selecione Personalizado. Se selecionar A pedido, esta transferência é executada quando aciona manualmente a transferência.
- Se aplicável, selecione Começar agora ou Começar à hora definida e indique uma data de início e um tempo de execução.
Na secção Detalhes da origem de dados, faça o seguinte:
- Para Padrões de nomes de tabelas, especifique as tabelas do data lake do HDFS a transferir, indicando os nomes das tabelas ou os padrões que correspondem às tabelas na base de dados do HDFS. Tem de usar a sintaxe de expressões regulares Java para especificar padrões de tabelas. Por exemplo:
db1..*corresponde a todas as tabelas em db1.db1.table1;db2.table2corresponde a table1 em db1 e table2 em db2.
- Para BQMS discovery dump gcs path, introduza o caminho para o contentor que contém o ficheiro
hive-dumper-output.zipque gerou quando criou um ficheiro de metadados para o Apache Hive. - Escolha o tipo de metastore na lista pendente:
DATAPROC_METASTORE: selecione esta opção para armazenar os seus metadados no Dataproc Metastore. Tem de fornecer o URL do Dataproc Metastore em Dataproc metastore url.BIGLAKE_METASTORE: selecione esta opção para armazenar os seus metadados no metastore do BigLake. Tem de fornecer um conjunto de dados do BigQuery em Conjunto de dados do BigQuery.BIGLAKE_REST_CATALOG: selecione esta opção para armazenar os seus metadados no metastore Iceberg REST do BigLake.
Para Caminho do GCS de destino, introduza um caminho para um contentor do Cloud Storage para armazenar os seus dados migrados.
Opcional: para Conta de serviço, introduza uma conta de serviço a usar com esta transferência de dados. A conta de serviço deve pertencer ao mesmo projeto Google Cloud onde a configuração de transferência e o conjunto de dados de destino são criados.
Opcional: pode ativar a opção Usar resultado da tradução para configurar um caminho do Cloud Storage e uma base de dados únicos para cada tabela que está a ser migrada. Para o fazer, indique o caminho para a pasta do Cloud Storage que contém os resultados da tradução no campo BQMS translation output gcs path. Para mais informações, consulte o artigo Configure a saída da tradução.
- Se especificar um caminho do Cloud Storage de saída da tradução, o caminho do Cloud Storage de destino e o conjunto de dados do BigQuery são provenientes dos ficheiros nesse caminho.
Para Tipo de armazenamento, selecione uma das seguintes opções:
HDFS: selecione esta opção se o armazenamento de ficheiros forHDFS. No campo Nome do conjunto de agentes do STS, tem de indicar o nome do conjunto de agentes que criou quando configurou o Storage Transfer Agent.S3: selecione esta opção se o armazenamento de ficheiros forAmazon S3. Nos campos ID da chave de acesso e Chave de acesso secreta, tem de indicar o ID da chave de acesso e a chave de acesso secreta que criou quando configurou as suas credenciais de acesso.
- Para Padrões de nomes de tabelas, especifique as tabelas do data lake do HDFS a transferir, indicando os nomes das tabelas ou os padrões que correspondem às tabelas na base de dados do HDFS. Tem de usar a sintaxe de expressões regulares Java para especificar padrões de tabelas. Por exemplo:
bq
Para agendar a transferência de tabelas geridas do Hive, introduza o comando bq mk
e forneça a flag de criação de transferência --transfer_config:
bq mk --transfer_config --data_source=hadoop --display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' --location='REGION' --params='{"table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY" }'
Substitua o seguinte:
TRANSFER_NAME: o nome a apresentar da configuração de transferência. O nome da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde.SERVICE_ACCOUNT: o nome da conta de serviço usado para autenticar a sua transferência. A conta de serviço deve ser propriedade da mesma conta de gestor que foiproject_idusada para criar a transferência e deve ter todas as autorizações necessárias.PROJECT_ID: o ID do seu Google Cloud projeto. Se o--project_idnão for fornecido para especificar um projeto em particular, é usado o projeto predefinido.REGION: localização desta configuração de transferência.LIST_OF_TABLES: uma lista de entidades a transferir. Use uma especificação de nomenclatura hierárquica:database.table. Este campo suporta a expressão regular RE2 para especificar tabelas. Por exemplo:db1..*: especifica todas as tabelas na base de dadosdb1.table1;db2.table2: uma lista de tabelas
DUMPER_BUCKET: o contentor do Cloud Storage que contém o ficheirohive-dumper-output.zip.MIGRATION_BUCKET: caminho do GCS de destino para o qual todos os ficheiros subjacentes vão ser carregados.METASTORE: o tipo de metastore para o qual migrar. Defina este elemento para um dos seguintes valores:DATAPROC_METASTORE: para transferir metadados para o Dataproc Metastore.BIGLAKE_METASTORE: para transferir metadados para o metastore do BigLake.BIGLAKE_REST_CATALOG: para transferir metadados para o metastore BigLake Iceberg REST Catalog.
DATAPROC_METASTORE_URL: o URL do seu Dataproc Metastore. Obrigatório semetastoreforDATAPROC_METASTORE.BIGLAKE_METASTORE_DATASET: o conjunto de dados do BigQuery para o metastore do BigLake. Obrigatório semetastoreforBIGLAKE_METASTORE.TRANSLATION_OUTPUT_BUCKET: (Opcional) Especifique um contentor do Cloud Storage para o resultado da tradução. Para mais informações, consulte o artigo Usar o resultado da tradução.STORAGE_TYPE: especifique o armazenamento de ficheiros subjacente para as suas tabelas. Os tipos suportados sãoHDFSeS3.AGENT_POOL_NAME: o nome do conjunto de agentes usado para criar agentes. Obrigatório sestorage_typeforHDFS.AWS_ACCESS_KEY_ID: o ID da chave de acesso das credenciais de acesso. Obrigatório sestorage_typeforS3.AWS_SECRET_ACCESS_KEY: a chave de acesso secreta das credenciais de acesso. Obrigatório sestorage_typeforS3.
Execute este comando para criar a configuração de transferência e iniciar a transferência de tabelas geridas do Hive. As transferências são agendadas para serem executadas a cada 24 horas por predefinição, mas podem ser configuradas com opções de agendamento de transferências.
Quando a transferência estiver concluída, as suas tabelas no cluster Hadoop são migradas para o MIGRATION_BUCKET.
Opções de carregamento de dados
As secções seguintes fornecem mais informações sobre como pode configurar as transferências de tabelas geridas do Hive.
Transferências incrementais
Quando uma configuração de transferência é configurada com um agendamento recorrente, todas as transferências subsequentes atualizam a tabela no Google Cloud com as atualizações mais recentes feitas à tabela de origem. Por exemplo, todas as operações de inserção, eliminação ou atualização com alterações ao esquema são refletidas em Google Cloud com cada transferência.
Opções de agendamento de transferências
Por predefinição, as transferências são agendadas para serem executadas a cada 24 horas. Para configurar a frequência de execução das transferências,
adicione a flag --schedule à configuração de transferência e especifique um
agendamento de transferência com a sintaxe schedule.
As transferências de tabelas geridas do Hive têm de ter um mínimo de 24 horas entre execuções de transferências.
Para transferências únicas, pode adicionar a flag end_time à configuração de transferência para executar a transferência apenas uma vez.
Configure a saída da tradução
Pode configurar um caminho do Cloud Storage e uma base de dados únicos para cada tabela migrada. Para tal, siga os passos seguintes para gerar um ficheiro YAML de mapeamento de tabelas que pode usar na configuração de transferência.
Crie um ficheiro YAML de configuração (com o sufixo
config.yaml) na pastaDUMPER_BUCKETque contenha o seguinte:type: object_rewriter relation: - match: relationRegex: ".*" external: location_expression: "'gs://MIGRATION_BUCKET/' + table.schema + '/' + table.name"
- Substitua
MIGRATION_BUCKETpelo nome do contentor do Cloud Storage que é o destino dos ficheiros de tabelas migrados. O campolocation_expressioné uma expressão do idioma de expressão comum (IEC).
- Substitua
Crie outro ficheiro YAML de configuração (com o sufixo
config.yaml) no diretórioDUMPER_BUCKETque contenha o seguinte:type: experimental_object_rewriter relation: - match: schema: SOURCE_DATABASE outputName: database: null schema: TARGET_DATABASE
- Substitua
SOURCE_DATABASEeTARGET_DATABASEpelo nome da base de dados de origem e da base de dados do Dataproc Metastore ou do conjunto de dados do BigQuery, consoante o metastore escolhido. Certifique-se de que o conjunto de dados do BigQuery existe se estiver a configurar o metastore do BigLake.
Para mais informações sobre este YAML de configuração, consulte as diretrizes para criar um ficheiro YAML de configuração.
- Substitua
Gere o ficheiro YAML de mapeamento de tabelas através do seguinte comando:
curl -d '{ "tasks": { "string": { "type": "HiveQL2BigQuery_Translation", "translation_details": { "target_base_uri": "TRANSLATION_OUTPUT_BUCKET", "source_target_mapping": { "source_spec": { "base_uri": "DUMPER_BUCKET" } }, "target_types": ["metadata"] } } } }' \ -H "Content-Type:application/json" \ -H "Authorization: Bearer TOKEN" -X POST https://bigquerymigration.googleapis.com/v2alpha/projects/PROJECT_ID/locations/LOCATION/workflows
Substitua o seguinte:
TRANSLATION_OUTPUT_BUCKET: (Opcional) Especifique um contentor do Cloud Storage para o resultado da tradução. Para mais informações, consulte o artigo Usar o resultado da tradução.DUMPER_BUCKET: o URI base do contentor do Cloud Storage que contém o ficheiro YAML dehive-dumper-output.zipe configuração.TOKEN: o token OAuth. Pode gerar este ficheiro na linha de comandos com o comandogcloud auth print-access-token.PROJECT_ID: o projeto para processar a tradução.LOCATION: a localização onde o trabalho é processado. Por exemplo,euouus.
Monitorize o estado desta tarefa. Quando estiver concluído, é gerado um ficheiro de mapeamento para cada tabela na base de dados num caminho predefinido em
TRANSLATION_OUTPUT_BUCKET.
Orquestre a execução do dumper através do comando cron
Pode automatizar transferências incrementais através de uma tarefa cron para executar a ferramenta dwh-migration-dumper. Ao automatizar a extração de metadados, garante que está disponível um despejo atualizado do Hadoop para execuções de transferências incrementais subsequentes.
Antes de começar
Antes de usar este script de automatização, conclua os pré-requisitos de instalação do dumper. Para executar o script, tem de ter a ferramenta dwh-migration-dumper instalada e as autorizações de IAM necessárias configuradas.
Agendar a automatização
Guarde o seguinte script num ficheiro local. Este script foi concebido para ser configurado e executado por um daemon
cronpara automatizar o processo de extração e carregamento do resultado do dumper:#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided GCS path." echo "" echo "Options:" echo " --dumper-executable
The full path to the dumper executable. (Required)" echo " --gcs-base-pathThe base GCS path for output files. (Required)" echo " --local-base-dirThe local base directory for logs and temp files. (Required)" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="hive-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"} cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to GCS." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "GCS Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) log "Starting dumper tool execution..." log "COMMAND: ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to GCS gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to GCS successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Execute o seguinte comando para tornar o script executável:
chmod +x PATH_TO_SCRIPT
Agende o script com
crontab, substituindo as variáveis por valores adequados para a sua tarefa. Adicione uma entrada para agendar a tarefa. O exemplo seguinte executa o script todos os dias às 02:30:# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Quando criar a transferência, certifique-se de que o campo
table_metadata_pathestá definido para o mesmo caminho do Google Cloud Storage que configurou paraGCS_PATH_TO_UPLOAD_DUMPER_OUTPUT. Este é o caminho que contém os ficheiros ZIP de saída do dumper.
Considerações de agendamento
Para evitar a obsolescência dos dados, a exportação de metadados tem de estar pronta antes do início da transferência agendada. Configure a frequência da tarefa cron em conformidade.
Recomendamos que execute manualmente algumas execuções de teste do script para determinar o tempo médio que a ferramenta de descarga demora a gerar o respetivo resultado. Use esta sincronização para definir uma agenda cron que anteceda em segurança a execução da transferência do DTS e garanta a atualização.
Monitorize as transferências de tabelas geridas do Hive
Depois de agendar a transferência de tabelas geridas do Hive, pode monitorizar a tarefa de transferência com comandos da ferramenta de linhas de comando bq. Para obter informações sobre como monitorizar as tarefas de transferência, consulte o artigo Veja as suas transferências.
Monitorize o estado da migração de tabelas
Também pode executar a ferramenta
dwh-dts-status para monitorizar o estado de todas as tabelas transferidas numa configuração de transferência ou numa base de dados específica. Também pode usar a ferramenta dwh-dts-status
para listar todas as configurações de transferência num projeto.
Antes de começar
Antes de poder usar a ferramenta dwh-dts-status, faça o seguinte:
Obtenha a ferramenta
dwh-dts-statustransferindo o pacotedwh-migration-tooldodwh-migration-toolsrepositório do GitHub.Autentique a sua conta no Google Cloud com o seguinte comando:
gcloud auth application-default loginPara mais informações, consulte o artigo Como funcionam as Credenciais padrão da aplicação.
Verifique se o utilizador tem a função
bigquery.adminelogging.viewer. Para mais informações sobre as funções de IAM, consulte o artigo Referência de controlo de acesso.
Apresenta todas as configurações de transferência num projeto
Para apresentar uma lista de todas as configurações de transferência num projeto, use o seguinte comando:
./dwh-dts-status --list-transfer-configs --project-id=[PROJECT_ID] --location=[LOCATION]
Substitua o seguinte:
PROJECT_ID: o ID do projeto Google Cloud que está a executar as transferências.LOCATION: a localização onde a configuração de transferência foi criada.
Este comando gera uma tabela com uma lista de nomes e IDs de configuração de transferência.
Veja os estados de todas as tabelas numa configuração
Para ver o estado de todas as tabelas incluídas numa configuração de transferência, use o seguinte comando:
./dwh-dts-status --list-status-for-config --project-id=[PROJECT_ID] --config-id=[CONFIG_ID] --location=[LOCATION]
Substitua o seguinte:
PROJECT_ID: o ID do projeto Google Cloud que está a executar as transferências.LOCATION: a localização onde a configuração de transferência foi criada.CONFIG_ID: o ID da configuração de transferência especificada.
Este comando gera uma tabela com uma lista de tabelas e o respetivo estado de transferência,
na configuração de transferência especificada. O estado da transferência pode ser um dos seguintes valores: PENDING, RUNNING, SUCCEEDED, FAILED, CANCELLED.
Veja os estados de todas as tabelas numa base de dados
Para ver o estado de todas as tabelas transferidas de uma base de dados específica, use o seguinte comando:
./dwh-dts-status --list-status-for-database --project-id=[PROJECT_ID] --database=[DATABASE]
Substitua o seguinte:
PROJECT_ID: o ID do projeto Google Cloud que está a executar as transferências.DATABASE:o nome da base de dados especificada.
Este comando gera uma tabela com uma lista de tabelas e o respetivo estado de transferência na base de dados especificada. O estado da transferência pode ser um dos seguintes valores: PENDING, RUNNING, SUCCEEDED, FAILED, CANCELLED.