
Esegui la migrazione delle tabelle del metastore Apache Hive a Google Cloud
Questo documento mostra come eseguire la migrazione delle tabelle Iceberg e Hive gestite da Apache Hive Metastore aGoogle Cloud utilizzando BigQuery Data Transfer Service.
Il connettore di migrazione di Apache Hive Metastore in BigQuery Data Transfer Service consente di eseguire la migrazione senza problemi delle tabelle Hive Metastore a Google Cloud su larga scala. Questo connettore supporta le tabelle Hive e Iceberg da installazioni on-premise e ambienti cloud, incluse le configurazioni Cloudera. Il connettore di migrazione Hive Metastore supporta i file archiviati nelle seguenti origini dati:
- Apache Hadoop Distributed File System (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage o Azure Data Lake Storage Gen2
Con il connettore di migrazione del metastore Hive, puoi utilizzare Cloud Storage come spazio di archiviazione dei file e registrare le tabelle del metastore Hive con uno dei seguenti metastore:
Catalogo runtime Lakehouse Iceberg REST Catalog
Ti consigliamo di utilizzare il catalogo runtime Lakehouse Iceberg REST per tutti i tuoi dati Iceberg.
Il catalogo runtime Lakehouse Iceberg REST Catalog crea interoperabilità tra i motori di query offrendo un'unica fonte di verità per tutti i tuoi dati Iceberg. Puoi utilizzare BigQuery per eseguire query sui dati, oltre ad Apache Spark e altri motori OSS. Il catalogo runtime Lakehouse Iceberg REST Catalog supporta solo i formati di tabella Iceberg.
Catalogo Hive del catalogo runtime Lakehouse (anteprima)
Ti consigliamo di utilizzare il catalogo runtime Lakehouse Hive Catalog per tutte le tue tabelle Hive.
Il catalogo Hive del catalogo runtime Lakehouse consente di registrare le tabelle Hive migrate con il catalogo runtime Lakehouse utilizzando un catalogo Hive. Offre un metastore serverless per le tabelle Apache Hive. Puoi utilizzare BigQuery per eseguire query sui dati (soggetti a limitazioni di formato), oltre ad Apache Spark e altri motori OSS.
-
Dataproc Metastore supporta i formati di tabella Hive e Iceberg. Puoi utilizzare solo Apache Spark e altri motori OSS per leggere e scrivere dati in Dataproc Metastore.
Questo connettore supporta i trasferimenti completi e solo di metadati. I trasferimenti completi trasferiranno sia i dati che i metadati dalle tabelle di origine al metastore di destinazione. Puoi creare un trasferimento solo di metadati se hai già i dati in Cloud Storage e se vuoi solo registrarli in un metastore di destinazione.
Il seguente diagramma fornisce una panoramica della procedura di migrazione.
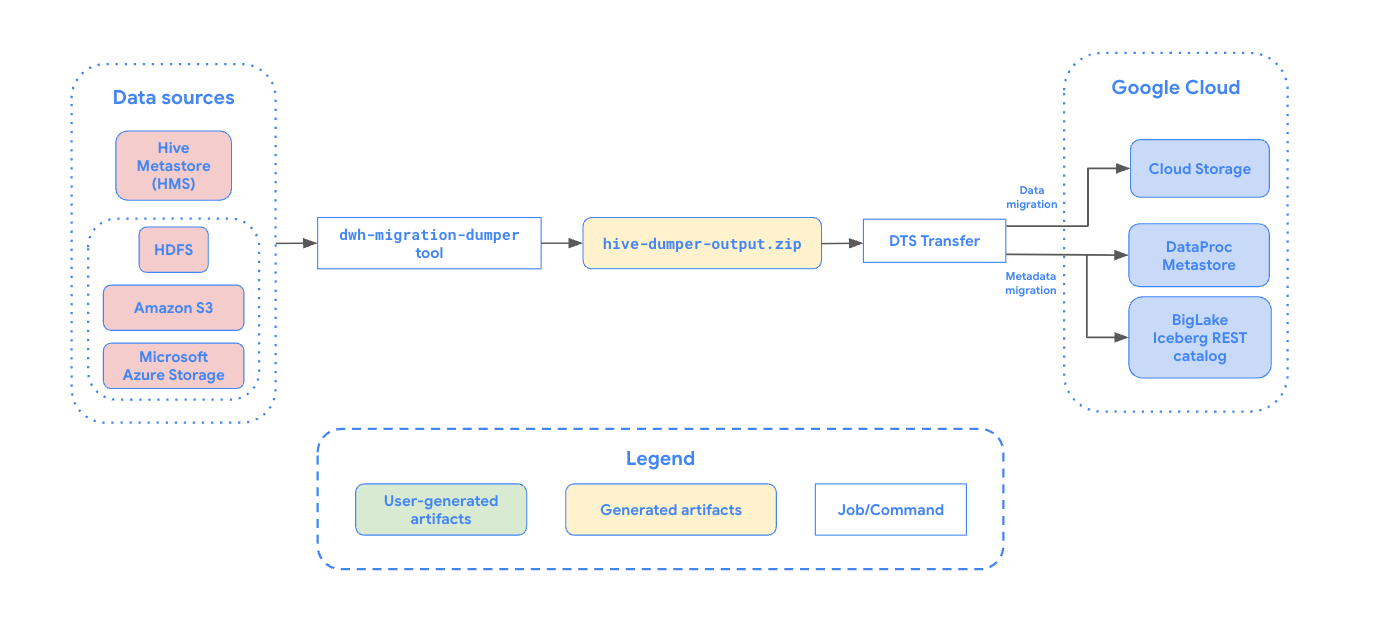
Limitazioni
I trasferimenti di tabelle Hive Metastore sono soggetti alle seguenti limitazioni:
- I trasferimenti di Hive Metastore devono avere un intervallo minimo di 30 minuti tra due esecuzioni pianificate. Le esecuzioni on demand possono comunque essere attivate a qualsiasi intervallo.
- I nomi dei file devono rispettare i requisiti di denominazione degli oggetti Cloud Storage.
- Cloud Storage ha un limite di 5 TiB per i singoli oggetti. Il trasferimento dei file all'interno delle tabelle Hive Metastore di dimensioni superiori a 5 TiB non andrà a buon fine.
- Storage Transfer Service ha comportamenti specifici se i dati vengono modificati nell'origine mentre è in corso un trasferimento. Sconsigliamo di scrivere nelle tabelle mentre la migrazione è in corso. Per un elenco di altre limitazioni di Storage Transfer Service, consulta le limitazioni note.
Limitazioni del catalogo Hive del catalogo runtime Lakehouse
Quando utilizzi il catalogo Hive (BIGLAKE_HIVE_CATALOG) del runtime Lakehouse come metastore di destinazione, si applicano le seguenti limitazioni e considerazioni:
- L'ID catalogo Hive del catalogo di runtime Lakehouse deve contenere solo lettere minuscole, numeri e trattini bassi (
_). Non deve contenere trattini (-) o lettere maiuscole. - Non puoi visualizzare o gestire i cataloghi Hive del catalogo runtime Lakehouse nella console Google Cloud . Tuttavia, le tabelle migrate sono visibili e interrogabili nel set di dati BigQuery di destinazione.
- Si applicano tutte le limitazioni del catalogo Hive del runtime Lakehouse per i formati e i tipi di dati dei metadati open source.
- Per informazioni sulla compatibilità con formati come CSV e JSON, consulta Formati di archiviazione supportati.
- Per informazioni sui tipi di dati non supportati (come
UNIONo array nidificati) e sulle statistiche delle colonne, consulta Limitazioni di Metastore e Limitazioni delle partizioni.
Opzioni di importazione dei dati
Le sezioni seguenti forniscono ulteriori informazioni su come configurare i trasferimenti di Hive Metastore.
Trasferimenti incrementali
Quando una configurazione del trasferimento viene impostata con una pianificazione ricorrente, ogni trasferimento successivo aggiorna la tabella su Google Cloud con gli ultimi aggiornamenti apportati alla tabella di origine. Ad esempio, tutti gli aggiornamenti dei dati e tutte le operazioni di inserimento, eliminazione o aggiornamento con modifiche dello schema vengono riflessi in Google Cloud con ogni trasferimento.
Filtra partizioni
Puoi trasferire un sottoinsieme di partizioni dalle tue tabelle Hive fornendo un file JSON di filtro personalizzato archiviato in Cloud Storage. Quando pianifichi il trasferimento, fornisci il percorso Cloud Storage completo a questo file JSON utilizzando il parametro partition_filter_gcs_path.
Di seguito è riportato un esempio della struttura del file JSON del filtro:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
Condizioni filtro
Il campo condition nel file JSON supporta i seguenti valori, ognuno con un formato specifico per l'array partitions:
IN: specifica i percorsi di partizione esatti da includere. L'arraypartitionscontiene stringhe che rappresentano la struttura di directory esatta delle partizioni rispetto al percorso di base della tabella (ad esempio,["partition_key1=value1/partition_key2=value2"]). Puoi specificare più percorsi nell'array.LESS_THAN: include le partizioni in cui il valore della chiave di partizione principale è minore o uguale al valore specificato. L'arraypartitionsdeve contenere una singola stringa nel formato["<partition_key>;<value>"].GREATER_THAN: include le partizioni in cui il valore della chiave di partizione principale è maggiore o uguale al valore specificato. L'arraypartitionsdeve contenere una singola stringa nel formato["<partition_key>;<value>"].RANGE: include le partizioni in cui il valore della chiave di partizionamento principale rientra nell'intervallo specificato (incluso). L'arraypartitionsdeve contenere una singola stringa nel formato["<partition_key>;<start_value>;<end_value>"].
Le condizioni del filtro sono soggette alle seguenti regole e limitazioni:
- Valori inclusivi:le condizioni di filtro per
GREATER_THAN,LESS_THANeRANGEincludono i valori forniti. Ad esempio, un filtroLESS_THANcon un valore di2023include le partizioni fino a2023inclusa. - Eliminazione delle partizioni:se una partizione di destinazione esistente soddisfa il filtro di partizionamento e non è più presente nell'origine, viene eliminata dal metastore di destinazione. Tuttavia, i file di dati sottostanti per quella partizione non vengono eliminati dal bucket di destinazione Cloud Storage.
- Limitazioni per una singola tabella:
- Non sono consentiti più filtri nella stessa tabella.
- Non puoi combinare diversi tipi di condizioni (ad esempio
GREATER_THANeIN) nella stessa tabella.
- Colonna di partizionamento di destinazione:le condizioni di filtro come
GREATER_THAN,LESS_THANeRANGEdevono avere come target la colonna di partizionamento principale. - Limitazioni dei prefissi:la combinazione di filtri specificata non deve restituire
più di 1000 prefissi per tabella. Ad esempio, un filtro come
year>2020su una tabella partizionata peryear/month/daydeve generare meno di 1000 prefissiyear=unici.
Prima di iniziare
Prima di pianificare il trasferimento di Hive Metastore, esegui i passaggi descritti in questa sezione.
Abilita API
Abilita le seguenti API nel tuo progettoGoogle Cloud :
- API Data Transfer
- API Storage Transfer
- API BigLake
Un agente di servizio viene creato quando abiliti l'API Data Transfer.
Configura autorizzazioni
Per configurare le autorizzazioni per un trasferimento di Hive Metastore, segui i passaggi nelle sezioni seguenti.
- All'utente o al account di servizio che crea il trasferimento deve essere concesso il ruolo
Amministratore BigQuery (
roles/bigquery.admin). Se utilizzi un account di servizio, questo viene utilizzato solo per creare il trasferimento. Un service agent (P4SA) viene creato quando viene abilitata l'API Data Transfer.
Per assicurarti che l'agente di servizio disponga delle autorizzazioni necessarie per eseguire un trasferimento di Hive Metastore, chiedi all'amministratore di concedere all'agente di servizio i seguenti ruoli IAM sul progetto:
- Amministratore Storage Transfer (
roles/storagetransfer.admin) - Consumer Service Usage (
roles/serviceusage.serviceUsageConsumer) - Storage Admin (
roles/storage.admin) -
Per eseguire la migrazione dei metadati al catalogo runtime Lakehouse (catalogo REST Iceberg o catalogo Hive):
BigLake Admin (
roles/biglake.admin) -
Per eseguire la migrazione dei metadati a Dataproc Metastore:
Dataproc Metastore Data Owner (
roles/metastore.metadataOwner)
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
L'amministratore potrebbe anche essere in grado di concedere all'agente di servizio le autorizzazioni richieste tramite ruoli personalizzati o altri ruoli predefiniti.
- Amministratore Storage Transfer (
Se utilizzi un account di servizio, concedi all'agente di servizio il ruolo
roles/iam.serviceAccountTokenCreatorcon il seguente comando:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Concedi al service agent Storage Transfer Service (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) i seguenti ruoli nel progetto:roles/storage.admin- Se esegui la migrazione da on-premise/HDFS, devi anche
concedere il ruolo
roles/storagetransfer.serviceAgent.
Puoi anche configurare autorizzazioni più granulari. Per saperne di più, consulta la seguente guida:
Genera il file di metadati per Apache Hive
Esegui lo strumento dwh-migration-dumper per estrarre
i metadati per Apache Hive.
Lo strumento genera un file denominato hive-dumper-output.zip che può essere caricato
in un bucket Cloud Storage. Questo bucket Cloud Storage viene indicato in
questo documento come DUMPER_BUCKET.
Puoi anche pianificare caricamenti periodici utilizzando uno script. Per saperne di più, consulta
Automatizzare l'esecuzione dello strumento di dump con un job cron.
Configura Storage Transfer Service
Seleziona una delle seguenti opzioni:
HDFS
È necessario un agente di trasferimento dello spazio di archiviazione per i trasferimenti on-premise o HDFS.
Per configurare l'agente:
- Installa Docker sulle macchine agenti on-premise.
- Crea un pool di agenti Storage Transfer Service nel tuo progetto Google Cloud .
- Installa gli agenti sulle macchine agenti on-premise.
Amazon S3
I trasferimenti da Amazon S3 sono trasferimenti senza agente.
Per configurare Storage Transfer Service per un trasferimento Amazon S3, procedi nel seguente modo:
- Configura le credenziali di accesso per AWS Amazon S3.
- Prendi nota dell'ID chiave di accesso e della chiave di accesso segreta dopo aver configurato le credenziali di accesso.
- Aggiungi intervalli IP utilizzati dai worker di Storage Transfer Service all'elenco degli IP consentiti se il tuo progetto AWS utilizza restrizioni IP.
Microsoft Azure
I trasferimenti da Microsoft Azure Storage sono trasferimenti senza agenti.
Per configurare Storage Transfer Service per un trasferimento di Microsoft Azure Storage, procedi nel seguente modo:
- Genera un token di firma di accesso condiviso (SAS) per il tuo account di archiviazione Microsoft Azure.
- Prendi nota del token SAS dopo averlo generato.
- Aggiungi intervalli IP utilizzati dai worker di Storage Transfer Service all'elenco degli IP consentiti se il tuo account di archiviazione Microsoft Azure utilizza restrizioni IP.
Pianificare un trasferimento del metastore Hive
Seleziona una delle seguenti opzioni:
Console
Vai alla pagina Trasferimenti di dati nella console Google Cloud .
Fai clic su Crea trasferimento.
Nella sezione Tipo di origine, seleziona Hive Metastore dall'elenco Origine.
Per Località, seleziona un tipo di località, quindi seleziona una regione.
Nella sezione Nome configurazione di trasferimento, per Nome visualizzato, inserisci un nome per il trasferimento di dati.
Nella sezione Opzioni di pianificazione, segui questi passaggi:
- Nell'elenco Frequenza di ripetizione, seleziona un'opzione per specificare la frequenza con cui viene eseguito questo trasferimento di dati. Per specificare una frequenza di ripetizione personalizzata, seleziona Personalizzata. Se selezioni On demand, questo trasferimento viene eseguito quando attivi manualmente il trasferimento.
- Se applicabile, seleziona Inizia ora o Inizia all'ora impostata e fornisci una data di inizio e un'ora di esecuzione.
Nella sezione Dettagli origine dati, segui questi passaggi:
- Per Strategia di trasferimento, seleziona una delle seguenti opzioni:
FULL_TRANSFER: trasferisci tutti i dati e registra i metadati con il metastore di destinazione. Questa è l'opzione predefinita.METADATA_ONLY: Registra solo i metadati. Devi disporre di dati già presenti nella posizione Cloud Storage corretta a cui viene fatto riferimento nei metadati.
- Per Pattern dei nomi delle tabelle, specifica le tabelle del data lake HDFS da trasferire fornendo nomi di tabelle o pattern che corrispondono alle tabelle nel database HDFS. Per specificare i pattern delle tabelle, devi utilizzare la sintassi delle espressioni regolari Java. Ad esempio:
db1..*corrisponde a tutte le tabelle in db1.db1.table1;db2.table2corrisponde a table1 in db1 e table2 in db2.
- Per BQMS discovery dump gcs path, inserisci il percorso del file
hive-dumper-output.zipche hai generato durante la creazione di un file di metadati per Apache Hive. Se utilizzi l'automazione dell'output di dumper concron, fornisci il percorso della cartella Cloud Storage configurato in--gcs-base-path, che contiene i file ZIP di output di dumper.- Per Tipo di archiviazione, seleziona una delle seguenti opzioni. Questo
campo è disponibile solo se Strategia di trasferimento è impostato su
FULL_TRANSFER: HDFS: seleziona questa opzione se l'archiviazione dei file èHDFS. Nel campo Nome pool di agenti STS, devi fornire il nome del pool di agenti che hai creato quando hai configurato Storage Transfer Agent.S3: seleziona questa opzione se l'archiviazione dei file èAmazon S3. Nei campi ID chiave di accesso e Chiave di accesso segreta, devi fornire l'ID chiave di accesso e la chiave di accesso segreta che hai creato quando hai configurato le credenziali di accesso.AZURE: seleziona questa opzione se l'archiviazione dei file èAzure Blob Storage. Nel campo Token SAS, devi fornire il token SAS che hai creato quando hai configurato le credenziali di accesso.
- Per Tipo di archiviazione, seleziona una delle seguenti opzioni. Questo
campo è disponibile solo se Strategia di trasferimento è impostato su
- (Facoltativo) Per Percorso GCS filtro partizione, inserisci un percorso Cloud Storage completo a un file JSON di filtro personalizzato per filtrare le partizioni dalle tabelle di origine.
- In Percorso GCS di destinazione, inserisci un percorso per un bucket Cloud Storage in cui archiviare i dati di cui è stata eseguita la migrazione.
- Scegli il tipo di metastore di destinazione dall'elenco a discesa:
DATAPROC_METASTORE: seleziona questa opzione per archiviare i metadati in Dataproc Metastore. Devi fornire l'URL di Dataproc Metastore in URL Dataproc Metastore.BIGLAKE_REST_CATALOG: seleziona questa opzione per archiviare i metadati nel catalogo runtime Lakehouse, ovvero il catalogo REST Iceberg. Il catalogo viene creato in base al bucket Cloud Storage di destinazione.BIGLAKE_HIVE_CATALOG(anteprima): seleziona questa opzione per archiviare i metadati nel catalogo Hive del runtime Lakehouse. Devi fornire un nome del catalogo in ID catalogo Hive di BigLake Metastore. Se il catalogo non esiste, verrà creato automaticamente.
- (Facoltativo) In Service account, inserisci un account di servizio da utilizzare con questo trasferimento di dati. Il account di servizio deve appartenere allo stesso progettoGoogle Cloud in cui vengono creati la configurazione del trasferimento e il set di dati di destinazione.
- Per Strategia di trasferimento, seleziona una delle seguenti opzioni:
bq
Per pianificare il trasferimento di Hive Metastore, inserisci il comando bq mk
e fornisci il flag di creazione del trasferimento --transfer_config:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
Sostituisci quanto segue:
TRANSFER_NAME: il nome visualizzato per la configurazione del trasferimento. Il nome del trasferimento può essere qualsiasi valore che ti consenta di identificare il trasferimento se devi modificarlo in un secondo momento.SERVICE_ACCOUNT: il nome del account di servizio utilizzato per creare il trasferimento.Il account di servizio deve appartenere allo stesso progettoGoogle Cloud in cui vengono creati la configurazione del trasferimento e il set di dati di destinazione.PROJECT_ID: il tuo ID progetto Google Cloud . Se--project_idnon viene fornito per specificare un progetto particolare, viene utilizzato il progetto predefinito.REGION: la posizione di questa configurazione di trasferimento.TRANSFER_STRATEGY: (facoltativo) specifica uno dei seguenti valori:FULL_TRANSFER: trasferisci tutti i dati e registra i metadati con il metastore di destinazione. Questo è il valore predefinito.METADATA_ONLY: Registra solo i metadati. Devi disporre di dati già presenti nella posizione Cloud Storage corretta a cui viene fatto riferimento nei metadati.
LIST_OF_TABLES: un elenco di entità da trasferire. Utilizza una specifica di denominazione gerarchica -database.table. Questo campo supporta l'espressione regolare RE2 per specificare le tabelle. Ad esempio:db1..*: specifica tutte le tabelle nel databasedb1.table1;db2.table2: un elenco di tabelle
DUMPER_BUCKET: il bucket Cloud Storage che contiene il filehive-dumper-output.zip. Se utilizzi l'automazione dell'output di dumper concron, modificatable_metadata_pathin modo che corrisponda al percorso della cartella Cloud Storage configurato con--gcs-base-pathnella configurazione di cron, ad esempio:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>".MIGRATION_BUCKET: il percorso GCS di destinazione in cui verranno caricati tutti i file sottostanti. Disponibile solo setransfer_strategyèFULL_TRANSFER.METASTORE: Il tipo di metastore a cui eseguire la migrazione. Imposta uno dei seguenti valori:DATAPROC_METASTORE: per trasferire i metadati a Dataproc Metastore.BIGLAKE_REST_CATALOG: per trasferire i metadati al catalogo runtime Lakehouse Catalogo REST Iceberg (consigliato per le tabelle Iceberg).BIGLAKE_HIVE_CATALOG: per trasferire i metadati al catalogo runtime Lakehouse Catalogo Hive (consigliato per le tabelle Apache Hive) (anteprima).
DATAPROC_METASTORE_URL: l'URL del tuo Dataproc Metastore. Obbligatorio semetastoreèDATAPROC_METASTORE.HIVE_CATALOG_ID: l'ID del catalogo Hive del catalogo runtime Lakehouse. Obbligatorio semetastoreèBIGLAKE_HIVE_CATALOG. Se il catalogo non esiste, verrà creato automaticamente.STORAGE_TYPE: specifica l'archiviazione dei file sottostanti per le tabelle. I tipi supportati sonoHDFS,S3eAZURE. Obbligatorio setransfer_strategyèFULL_TRANSFER.AGENT_POOL_NAME: il nome del pool di agenti utilizzato per la creazione di agenti. Obbligatorio sestorage_typeèHDFS.AWS_ACCESS_KEY_ID: l'ID chiave di accesso delle credenziali di accesso. Obbligatorio sestorage_typeèS3.AWS_SECRET_ACCESS_KEY: la chiave di accesso segreta delle credenziali di accesso. Obbligatorio sestorage_typeèS3.AZURE_SAS_TOKEN: il token SAS delle credenziali di accesso. Obbligatorio sestorage_typeèAZURE.FILTER_GCS_PATH: (facoltativo) un percorso Cloud Storage completo a un file JSON di filtro personalizzato per filtrare le partizioni.
Esegui questo comando per creare la configurazione del trasferimento e avviare il trasferimento delle tabelle gestite di Hive. Per impostazione predefinita, i trasferimenti vengono eseguiti ogni 24 ore, ma possono essere configurati con le opzioni di pianificazione del trasferimento.
Al termine del trasferimento, le tabelle nel cluster Hadoop verranno
migrate a MIGRATION_BUCKET.
Automatizza l'esecuzione dello strumento di dump con un job cron
Puoi automatizzare i trasferimenti incrementali utilizzando un job
cron per eseguire lo strumento
dwh-migration-dumper. Automatizzare l'estrazione dei metadati per garantire che
un dump aggiornato dell'origine dati sia disponibile per le successive esecuzioni di trasferimento
incrementale.
Prima di iniziare
Prima di utilizzare questo script di automazione, devi:
Completa tutti i prerequisiti per lo strumento di dump.
Installa Google Cloud CLI. Lo script utilizza lo strumento a riga di comando
gsutilper caricare l'output del dumper su Cloud Storage.Per eseguire l'autenticazione con Google Cloud per consentire a
gsutildi caricare file in Cloud Storage, esegui questo comando:gcloud auth application-default login
Pianificazione dell'automazione
Salva il seguente script in un file locale. Questo script è progettato per essere configurato ed eseguito da un daemon
cronper automatizzare il processo di estrazione e caricamento dell'output di dumper.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Per rendere eseguibile lo script, esegui il comando seguente:
chmod +x PATH_TO_SCRIPT
Pianifica lo script utilizzando
crontab, sostituendo le variabili con i valori appropriati per il tuo job. Aggiungi una voce per pianificare il job. Gli esempi seguenti eseguono lo script ogni giorno alle 2:30:Se esegui l'operazione su un host che ha accesso diretto a Hive Metastore e non richiede l'autenticazione Kerberos, esegui il seguente comando:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Se la tua istanza di Hive Metastore richiede l'autenticazione Kerberos, esegui questo comando:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
Considerazioni sulla programmazione
Per evitare l'obsolescenza dei dati, esegui lo strumento di dump prima del trasferimento dei dati pianificato.
Ti consigliamo di eseguire manualmente alcune prove dello script per determinare il
tempo medio necessario allo strumento di dump per generare l'output. Utilizza questa
tempistica per impostare una pianificazione dei job cron che precede l'esecuzione del trasferimento per
garantire l'aggiornamento dei dati.
Monitorare e visualizzare lo stato del trasferimento
Puoi monitorare i trasferimenti a livello di risorsa per le singole tabelle per tenere traccia dell'avanzamento, visualizzare i dettagli granulari degli errori ed eseguire query sullo stato di risorse specifiche di cui è in corso la migrazione.
Per visualizzare l'avanzamento e lo stato delle risorse, seleziona una delle seguenti opzioni:
Console
Nella console Google Cloud , vai alla pagina Trasferimenti di dati.
Fai clic sulla configurazione del trasferimento dall'elenco.
Nella pagina Dettagli trasferimento, fai clic sulla scheda Tabelle trasferite.
Visualizza l'elenco delle risorse da trasferire. Puoi visualizzare dettagli come:
- Stato ultimo trasferimento: lo stato attuale della risorsa in base all'ultimo trasferimento della risorsa, incluso l'avanzamento del completamento.
- Nome tabella: il nome della risorsa da trasferire. Fai clic sul nome della risorsa per visualizzarne una visualizzazione dettagliata.
- Ultima esecuzione: l'ultima esecuzione del trasferimento che ha aggiornato la risorsa.
- Riepilogo dello stato: metriche di avanzamento granulari o messaggi di errore se il trasferimento non è riuscito.
- Ultima esecuzione riuscita: l'ultima esecuzione che ha trasferito correttamente la risorsa.
Utilizza la barra dei filtri per cercare risorse specifiche per nome o filtrare in base
al loro stato attuale, ad esempio Trasferimenti non riusciti. Il filtro Nome tabella
supporta la corrispondenza con caratteri jolly, ad esempio utilizzando *, ma la corrispondenza con caratteri jolly non è supportata per altri campi filtro.
API
Puoi eseguire query sullo stato delle risorse di trasferimento utilizzando l'API BigQuery Data Transfer Service.
Elenca tutte le risorse e i relativi stati
Per elencare tutte le risorse e i relativi stati, utilizza il metodo projects.locations.transferConfigs.transferResources.list.
Esegui la richiesta API con le seguenti informazioni:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
comando curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Puoi filtrare i risultati in base al nome o allo stato della risorsa. Ad esempio, per trovare
tutti i trasferimenti non riusciti, aggiungi
?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED"
all'URL della richiesta.
Sostituisci quanto segue:
CONFIG_ID: l'ID della configurazione del trasferimento.LOCATION: la località in cui è stata creata la configurazione del trasferimento.PROJECT_ID: l'ID del progetto Google Cloud che esegue i trasferimenti.
Ottenere una risorsa specifica
Per ottenere lo stato di una tabella o di una partizione specifica, utilizza il metodo projects.locations.transferConfigs.transferResources.get.
Esegui la richiesta API con le seguenti informazioni:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
comando curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Sostituisci quanto segue:
CONFIG_ID: l'ID della configurazione del trasferimento.LOCATION: la località in cui è stata creata la configurazione del trasferimento.PROJECT_ID: l'ID del Google Cloud progetto che esegue i trasferimenti.RESOURCE_ID: l'ID della risorsa, ad esempio il nome della tabella.
Quote e limiti di concorrenza
Per ogni esecuzione di BigQuery Data Transfer Service, il connettore Hive Metastore esegue un job Storage Transfer Service per tabella.
Una volta raggiunta la quota, il trasferimento attende che sia disponibile una quota maggiore. I job Storage Transfer Service vengono creati nel progetto cliente e sono soggetti a quote e limiti di Storage Transfer Service.
Prezzi
Non sono previsti costi per l'utilizzo del connettore Apache Hive Metastore per trasferire i dati. Dopo il trasferimento dei dati, ti viene addebitato il costo di archiviazione dei dati nella destinazione. Per ulteriori informazioni, consulta le seguenti risorse: