
Memigrasikan tabel Apache Hive Metastore ke Google Cloud
Dokumen ini menunjukkan cara memigrasikan tabel Iceberg dan Hive yang dikelola oleh Apache Hive Metastore ke Google Cloud menggunakan BigQuery Data Transfer Service.
Konektor migrasi Apache Hive Metastore di BigQuery Data Transfer Service memungkinkan Anda memigrasikan tabel Hive Metastore dengan lancar ke Google Cloud dalam skala besar. Konektor ini mendukung tabel Hive dan Iceberg dari penginstalan lokal dan lingkungan cloud, termasuk penyiapan Cloudera. Konektor migrasi Hive Metastore mendukung file yang disimpan di sumber data berikut:
- Apache Hadoop Distributed File System (HDFS)
- Layanan Simple Storage Amazon (Amazon S3)
- Azure Blob Storage atau Azure Data Lake Storage Gen2
Dengan konektor migrasi Hive Metastore, Anda dapat menggunakan Cloud Storage sebagai penyimpanan file dan mendaftarkan tabel Hive Metastore dengan salah satu metastore berikut:
Katalog runtime Lakehouse Iceberg REST Catalog
Sebaiknya gunakan Katalog REST Iceberg katalog runtime Lakehouse untuk semua data Iceberg Anda.
Katalog runtime Lakehouse Iceberg REST Catalog menciptakan interoperabilitas antara mesin kueri Anda dengan menawarkan satu sumber tepercaya untuk semua data Iceberg Anda. Anda dapat menggunakan BigQuery untuk mengkueri data, selain Apache Spark dan mesin OSS lainnya. Katalog runtime Lakehouse Iceberg REST Catalog hanya mendukung format tabel Iceberg.
Katalog runtime Lakehouse Hive Catalog (Pratinjau)
Sebaiknya gunakan Hive Catalog Lakehouse runtime catalog untuk semua tabel Hive Anda.
Hive Catalog Lakehouse runtime catalog memungkinkan Anda mendaftarkan tabel Hive yang dimigrasikan dengan Lakehouse runtime catalog menggunakan Hive Catalog. Hal ini menawarkan metastore tanpa server untuk tabel Apache Hive. Anda dapat menggunakan BigQuery untuk membuat kueri data (tunduk pada batasan format), selain Apache Spark dan mesin OSS lainnya.
-
Dataproc Metastore mendukung format tabel Hive dan Iceberg. Anda hanya dapat menggunakan Apache Spark dan mesin OSS lainnya untuk membaca dan menulis data ke Dataproc Metastore.
Konektor ini mendukung transfer penuh dan hanya metadata. Transfer penuh akan mentransfer data dan metadata dari tabel sumber ke metastore target. Anda dapat membuat transfer hanya metadata jika sudah memiliki data di Cloud Storage dan jika hanya ingin mendaftarkan data ke metastore tujuan.
Diagram berikut memberikan ringkasan proses migrasi.
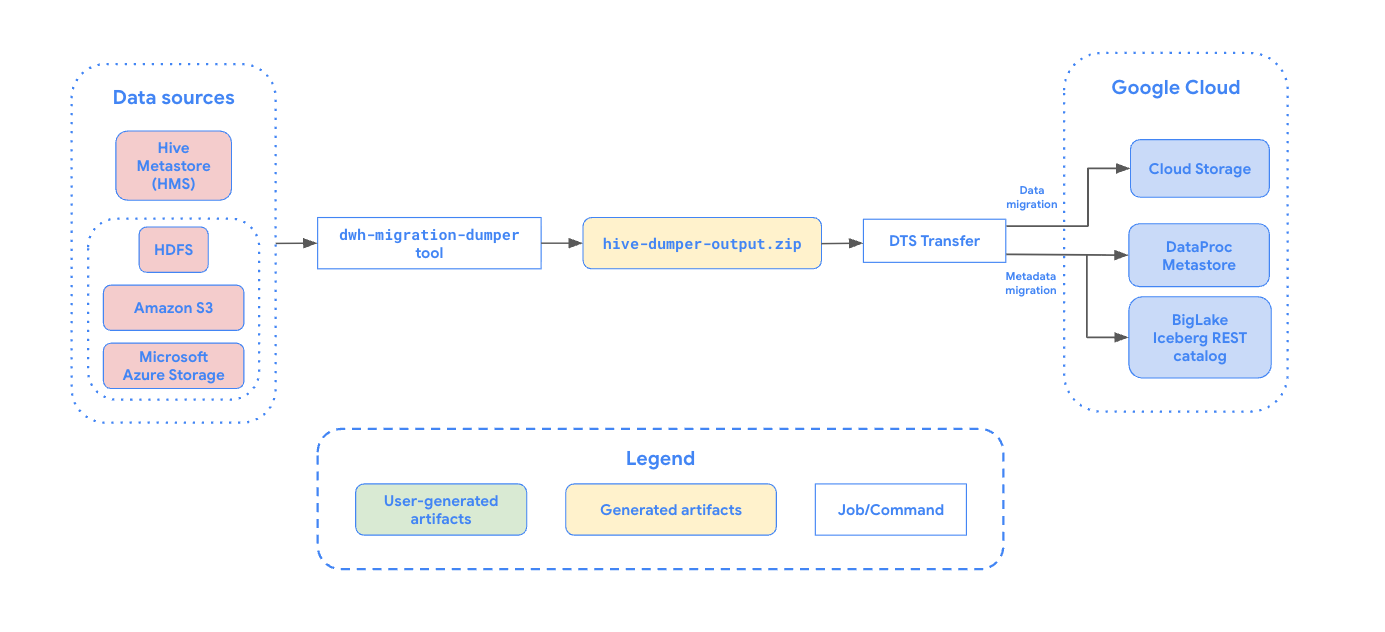
Batasan
Transfer tabel Hive Metastore tunduk pada batasan berikut:
- Transfer Hive Metastore harus memiliki jeda minimal 30 menit antara 2 proses terjadwal. Run sesuai permintaan masih dapat dipicu pada interval apa pun.
- Nama file harus mematuhi persyaratan penamaan objek Cloud Storage.
- Cloud Storage memiliki batas 5 TiB untuk objek tunggal. File dalam tabel Hive Metastore Anda yang berukuran lebih dari 5 TiB tidak akan ditransfer.
- Storage Transfer Service memiliki perilaku tertentu jika data diubah di sumber saat transfer sedang berlangsung. Sebaiknya jangan menulis ke tabel saat tabel sedang dimigrasikan secara aktif. Untuk mengetahui daftar batasan Storage Transfer Service lainnya, lihat batasan umum.
Batasan Katalog Hive Katalog runtime Lakehouse
Saat menggunakan Hive Catalog (BIGLAKE_HIVE_CATALOG) katalog runtime Lakehouse sebagai metastore tujuan, batasan dan pertimbangan berikut berlaku:
- ID Katalog Hive katalog runtime Lakehouse hanya boleh berisi huruf kecil, angka, dan garis bawah (
_). ID ini tidak boleh berisi tanda hubung (-) atau huruf besar. - Anda tidak dapat melihat atau mengelola Katalog Hive runtime Lakehouse di konsol Google Cloud . Namun, tabel yang dimigrasikan dapat dilihat dan dikueri di set data BigQuery target.
- Semua batasan Hive Catalog untuk format metadata dan jenis data open source berlaku untuk katalog runtime Lakehouse.
- Untuk mengetahui informasi tentang kompatibilitas dengan format seperti CSV dan JSON, lihat Format penyimpanan yang didukung.
- Untuk mengetahui informasi tentang jenis data yang tidak didukung (seperti
UNIONatau array bertingkat) dan statistik kolom, lihat batasan metastore dan batasan partisi.
Opsi penyerapan data
Bagian berikut memberikan informasi selengkapnya tentang cara mengonfigurasi transfer Hive Metastore.
Transfer inkremental
Jika konfigurasi transfer disiapkan dengan jadwal berulang, setiap transfer berikutnya akan memperbarui tabel di Google Cloud dengan pembaruan terbaru yang dilakukan pada tabel sumber. Misalnya, semua pembaruan data dan semua operasi penyisipan, penghapusan, atau pembaruan dengan perubahan skema tercermin di Google Cloud dengan setiap transfer.
Memfilter partisi
Anda dapat mentransfer subset partisi dari tabel Hive dengan memberikan file JSON filter kustom yang disimpan di Cloud Storage. Saat menjadwalkan transfer, berikan jalur Cloud Storage lengkap ke file JSON ini menggunakan parameter partition_filter_gcs_path.
Berikut adalah contoh struktur file JSON filter:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
Kondisi filter
Kolom condition dalam file JSON mendukung nilai berikut, yang masing-masing memiliki
format tertentu untuk array partitions:
IN: Menentukan jalur partisi persis yang akan disertakan. Arraypartitionsberisi string yang merepresentasikan struktur direktori persis dari partisi relatif terhadap jalur dasar tabel (misalnya,["partition_key1=value1/partition_key2=value2"]). Anda dapat menentukan beberapa jalur dalam array.LESS_THAN: Mencakup partisi dengan nilai kunci partisi utama yang kurang dari atau sama dengan nilai yang ditentukan. Arraypartitionsharus berisi satu string dalam format["<partition_key>;<value>"].GREATER_THAN: Menyertakan partisi dengan nilai kunci partisi utama lebih besar dari atau sama dengan nilai yang ditentukan. Arraypartitionsharus berisi satu string dalam format["<partition_key>;<value>"].RANGE: Mencakup partisi dengan nilai kunci partisi utama yang berada dalam rentang yang ditentukan (inklusif). Arraypartitionsharus berisi satu string dalam format["<partition_key>;<start_value>;<end_value>"].
Kondisi filter tunduk pada aturan dan batasan berikut:
- Nilai inklusif: Kondisi filter untuk
GREATER_THAN,LESS_THAN, danRANGEbersifat inklusif terhadap nilai yang diberikan. Misalnya, filterLESS_THANdengan nilai2023menyertakan partisi hingga dan termasuk2023. - Penghapusan partisi: Jika partisi tujuan yang ada memenuhi filter partisi dan tidak lagi ada di sumber, maka partisi tersebut akan dihapus dari metastore tujuan. Namun, file data pokok untuk partisi tersebut tidak dihapus dari bucket tujuan Cloud Storage.
- Batasan tabel tunggal:
- Beberapa filter pada tabel yang sama tidak diizinkan.
- Anda tidak dapat menggabungkan berbagai jenis kondisi (misalnya:
GREATER_THANdanIN) pada tabel yang sama.
- Kolom partisi target: Kondisi filter seperti
GREATER_THAN,LESS_THAN, danRANGEharus menargetkan kolom partisi utama. - Batasan awalan: Kombinasi filter yang ditentukan tidak boleh menghasilkan lebih dari 1.000 awalan per tabel. Misalnya, filter seperti
year>2020pada tabel yang dipartisi menurutyear/month/dayharus menghasilkan kurang dari 1.000 awalanyear=unik.
Sebelum memulai
Sebelum menjadwalkan transfer Hive Metastore, lakukan langkah-langkah di bagian ini.
Mengaktifkan API
Aktifkan API berikut di project Google Cloud Anda:
- Data Transfer API
- Storage Transfer API
- BigLake API
Agen layanan dibuat saat Anda mengaktifkan Data Transfer API.
Konfigurasikan izin
Untuk mengonfigurasi izin transfer Hive Metastore, lakukan langkah-langkah di bagian berikut.
- Pengguna atau akun layanan yang membuat transfer harus diberi peran BigQuery Admin (
roles/bigquery.admin). Jika Anda menggunakan akun layanan, akun tersebut hanya digunakan untuk membuat transfer. Agen layanan (P4SA) dibuat saat mengaktifkan Data Transfer API.
Untuk memastikan bahwa agen layanan memiliki izin yang diperlukan untuk menjalankan transfer Hive Metastore, minta administrator untuk memberikan peran IAM berikut kepada agen layanan di project:
- Storage Transfer Admin (
roles/storagetransfer.admin) - Service Usage Consumer (
roles/serviceusage.serviceUsageConsumer) - Storage Admin (
roles/storage.admin) -
Untuk memigrasikan metadata ke katalog runtime Lakehouse (Iceberg REST Catalog atau Hive Catalog):
Admin BigLake (
roles/biglake.admin) -
Untuk memigrasikan metadata ke Dataproc Metastore:
Pemilik Data Dataproc Metastore (
roles/metastore.metadataOwner)
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Administrator Anda mungkin juga dapat memberikan izin yang diperlukan kepada agen layanan melalui peran khusus atau peran bawaan lainnya.
- Storage Transfer Admin (
Jika Anda menggunakan akun layanan, berikan peran
roles/iam.serviceAccountTokenCreatorkepada agen layanan dengan perintah berikut:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Berikan peran berikut kepada agen layanan Storage Transfer Service (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) di project:roles/storage.admin- Jika Anda melakukan migrasi dari on-prem/HDFS, Anda juga harus memberikan peran
roles/storagetransfer.serviceAgent.
Anda juga dapat mengonfigurasi izin yang lebih terperinci. Untuk informasi selengkapnya, lihat panduan berikut:
Membuat file metadata untuk Apache Hive
Jalankan alat dwh-migration-dumper untuk mengekstraksi
metadata untuk Apache Hive.
Alat ini menghasilkan file bernama hive-dumper-output.zip yang dapat diupload ke bucket Cloud Storage. Bucket Cloud Storage ini disebut dalam dokumen ini sebagai DUMPER_BUCKET.
Anda juga dapat menjadwalkan upload berkala menggunakan skrip. Untuk mengetahui informasi selengkapnya, lihat
Mengotomatiskan eksekusi alat dumper dengan tugas cron.
Mengonfigurasi Storage Transfer Service
Pilih salah satu opsi berikut:
HDFS
Agen transfer penyimpanan diperlukan untuk transfer lokal atau HDFS.
Untuk menyiapkan agen, lakukan hal berikut:
- Instal Docker di mesin agen lokal.
- Buat kumpulan agen Storage Transfer Service di project Google Cloud Anda.
- Instal agen di komputer agen lokal Anda.
Amazon S3
Transfer dari Amazon S3 adalah transfer tanpa agen.
Untuk mengonfigurasi Storage Transfer Service untuk transfer Amazon S3, lakukan hal berikut:
- Siapkan kredensial akses untuk AWS Amazon S3.
- Catat ID kunci akses dan kunci akses rahasia setelah menyiapkan kredensial akses Anda.
- Tambahkan rentang IP yang digunakan oleh pekerja Storage Transfer Service ke daftar IP yang diizinkan jika project AWS Anda menggunakan pembatasan IP.
Microsoft Azure
Transfer dari Microsoft Azure Storage adalah transfer tanpa agen.
Untuk mengonfigurasi Storage Transfer Service untuk transfer Microsoft Azure Storage, lakukan hal berikut:
- Buat token Tanda Tangan Akses Bersama (SAS) untuk akun penyimpanan Microsoft Azure Anda.
- Catat token SAS setelah membuatnya.
- Tambahkan rentang IP yang digunakan oleh pekerja Storage Transfer Service ke daftar IP yang diizinkan jika akun penyimpanan Microsoft Azure Anda menggunakan batasan IP.
Menjadwalkan transfer Hive Metastore
Pilih salah satu opsi berikut:
Konsol
Buka halaman Transfer data di konsol Google Cloud .
Klik Create transfer.
Di bagian Jenis sumber, pilih Hive Metastore dari daftar Sumber.
Untuk Location, pilih jenis lokasi, lalu pilih wilayah.
Di bagian Transfer config name, untuk Display name, masukkan nama untuk transfer data.
Di bagian Opsi jadwal, lakukan tindakan berikut:
- Dalam daftar Frekuensi pengulangan, pilih opsi untuk menentukan seberapa sering transfer data ini dijalankan. Untuk menentukan frekuensi pengulangan kustom, pilih Kustom. Jika Anda memilih On-demand, transfer ini akan berjalan saat Anda memicu transfer secara manual.
- Jika berlaku, pilih Start now atau Start at set time, dan masukkan tanggal mulai dan waktu proses.
Di bagian Detail sumber data, lakukan hal berikut:
- Untuk Strategi transfer, pilih salah satu opsi berikut:
FULL_TRANSFER: Transfer semua data dan daftarkan metadata dengan metastore target. Opsi ini adalah opsi default.METADATA_ONLY: Hanya mendaftarkan metadata. Anda harus memiliki data yang sudah ada di lokasi Cloud Storage yang benar yang dirujuk dalam metadata.
- Untuk Pola nama tabel, tentukan tabel data lake HDFS yang akan ditransfer dengan memberikan nama tabel atau pola yang cocok dengan tabel di database HDFS. Anda harus menggunakan sintaksis ekspresi reguler Java untuk menentukan pola tabel. Misalnya:
db1..*cocok dengan semua tabel di db1.db1.table1;db2.table2cocok dengan table1 di db1 dan table2 di db2.
- Untuk BQMS discovery dump gcs path, masukkan jalur ke file
hive-dumper-output.zipyang Anda buat saat membuat file metadata untuk Apache Hive. Jika Anda menggunakan otomatisasi output dumper dengancron, berikan jalur folder Cloud Storage yang dikonfigurasi di--gcs-base-path, yang berisi file ZIP output dumper.- Untuk Jenis penyimpanan, pilih salah satu opsi berikut. Kolom
ini hanya tersedia jika Strategi transfer disetel ke
FULL_TRANSFER: HDFS: Pilih opsi ini jika penyimpanan file Anda adalahHDFS. Di kolom STS agent pool name, Anda harus memberikan nama agent pool yang Anda buat saat mengonfigurasi Storage Transfer Agent.S3: Pilih opsi ini jika penyimpanan file Anda adalahAmazon S3. Di kolom Access key ID dan Secret access key, Anda harus memberikan ID kunci akses dan kunci akses rahasia yang Anda buat saat menyiapkan kredensial akses.AZURE: Pilih opsi ini jika penyimpanan file Anda adalahAzure Blob Storage. Di kolom SAS token, Anda harus memberikan token SAS yang Anda buat saat menyiapkan kredensial akses.
- Untuk Jenis penyimpanan, pilih salah satu opsi berikut. Kolom
ini hanya tersedia jika Strategi transfer disetel ke
- Opsional: Untuk Partition Filter gcs path, masukkan jalur Cloud Storage lengkap ke file JSON filter kustom untuk memfilter partisi dari tabel sumber.
- Untuk Destination gcs path, masukkan jalur ke bucket Cloud Storage untuk menyimpan data yang dimigrasikan.
- Pilih jenis Metastore Tujuan dari menu drop-down:
DATAPROC_METASTORE: Pilih opsi ini untuk menyimpan metadata Anda di Dataproc Metastore. Anda harus memberikan URL untuk Dataproc Metastore di Dataproc metastore url.BIGLAKE_REST_CATALOG: Pilih opsi ini untuk menyimpan metadata di katalog REST Iceberg katalog runtime Lakehouse. Katalog dibuat berdasarkan bucket Cloud Storage tujuan.BIGLAKE_HIVE_CATALOG(Pratinjau): Pilih opsi ini untuk menyimpan metadata Anda di Hive Catalog runtime Lakehouse. Anda harus memberikan nama katalog di ID Katalog Hive BigLake Metastore. Jika katalog belum ada, katalog akan dibuat secara otomatis.
- Opsional: Untuk Akun layanan, masukkan akun layanan yang akan digunakan dengan transfer data ini. Akun layanan harus termasuk dalam projectGoogle Cloud yang sama dengan tempat konfigurasi transfer dan set data tujuan dibuat.
- Untuk Strategi transfer, pilih salah satu opsi berikut:
bq
Untuk menjadwalkan transfer Hive Metastore, masukkan perintah bq mk
dan berikan flag pembuatan transfer --transfer_config:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
Ganti kode berikut:
TRANSFER_NAME: nama tampilan untuk konfigurasi transfer. Nama transfer dapat berupa nilai apa pun yang memungkinkan Anda mengidentifikasi transfer jika perlu mengubahnya nanti.SERVICE_ACCOUNT: nama akun layanan yang digunakan untuk membuat transfer.Akun layanan harus termasuk dalam projectGoogle Cloud yang sama tempat konfigurasi transfer dan set data tujuan dibuat.PROJECT_ID: Google Cloud Project ID Anda. Jika--project_idtidak diberikan untuk menentukan project tertentu, project default akan digunakan.REGION: lokasi konfigurasi transfer ini.TRANSFER_STRATEGY: (Opsional) Tentukan salah satu nilai berikut:FULL_TRANSFER: Transfer semua data dan daftarkan metadata dengan metastore target. Ini adalah nilai defaultnya.METADATA_ONLY: Hanya mendaftarkan metadata. Anda harus memiliki data yang sudah ada di lokasi Cloud Storage yang benar yang dirujuk dalam metadata.
LIST_OF_TABLES: daftar entity yang akan ditransfer. Gunakan spesifikasi penamaan hierarkis -database.table. Kolom ini mendukung ekspresi reguler RE2 untuk menentukan tabel. Contoh:db1..*: menentukan semua tabel dalam databasedb1.table1;db2.table2: daftar tabel
DUMPER_BUCKET: bucket Cloud Storage yang berisi filehive-dumper-output.zip. Jika Anda menggunakan otomatisasi output dumper dengancron, maka ubahtable_metadata_pathmenjadi jalur folder Cloud Storage yang dikonfigurasi dengan--gcs-base-pathdalam penyiapan cron—misalnya:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>".MIGRATION_BUCKET: Jalur GCS tujuan tempat semua file pokok akan dimuat. Hanya tersedia jikatransfer_strategyadalahFULL_TRANSFER.METASTORE: Jenis metastore yang akan dimigrasikan. Tetapkan ini ke salah satu nilai berikut:DATAPROC_METASTORE: Untuk mentransfer metadata ke Dataproc Metastore.BIGLAKE_REST_CATALOG: Untuk mentransfer metadata ke Katalog REST Iceberg katalog runtime Lakehouse (direkomendasikan untuk tabel Iceberg).BIGLAKE_HIVE_CATALOG: Untuk mentransfer metadata ke katalog runtime Lakehouse Hive Catalog (direkomendasikan untuk tabel Apache Hive) (Pratinjau).
DATAPROC_METASTORE_URL: URL Dataproc Metastore Anda. Wajib jikametastoreadalahDATAPROC_METASTORE.HIVE_CATALOG_ID: ID Katalog Hive Katalog runtime Lakehouse. Wajib jikametastoreadalahBIGLAKE_HIVE_CATALOG. Jika belum ada, katalog akan dibuat secara otomatis.STORAGE_TYPE: Tentukan penyimpanan file pokok untuk tabel Anda. Jenis yang didukung adalahHDFS,S3, danAZURE. Wajib jikatransfer_strategyadalahFULL_TRANSFER.AGENT_POOL_NAME: nama kumpulan agen yang digunakan untuk membuat agen. Wajib jikastorage_typeadalahHDFS.AWS_ACCESS_KEY_ID: ID kunci akses dari kredensial akses. Wajib jikastorage_typeadalahS3.AWS_SECRET_ACCESS_KEY: kunci akses rahasia dari kredensial akses. Wajib jikastorage_typeadalahS3.AZURE_SAS_TOKEN: token SAS dari kredensial akses. Wajib jikastorage_typeadalahAZURE.FILTER_GCS_PATH: (Opsional) Jalur Cloud Storage lengkap ke file JSON filter kustom untuk memfilter partisi.
Jalankan perintah ini untuk membuat konfigurasi transfer dan memulai transfer tabel terkelola Hive. Transfer dijadwalkan untuk berjalan setiap 24 jam secara default, tetapi dapat dikonfigurasi dengan opsi penjadwalan transfer.
Setelah transfer selesai, tabel Anda di cluster Hadoop akan dimigrasikan ke MIGRATION_BUCKET.
Mengotomatiskan eksekusi alat dumper dengan tugas cron
Anda dapat mengotomatiskan transfer inkremental menggunakan tugas
cron untuk menjalankan alat
dwh-migration-dumper. Mengotomatiskan ekstraksi metadata untuk memastikan bahwa dump terbaru dari sumber data tersedia untuk menjalankan transfer inkremental berikutnya.
Sebelum memulai
Sebelum menggunakan skrip otomatisasi ini, Anda harus melakukan hal berikut:
Selesaikan semua prasyarat untuk alat dumper.
Menginstal Google Cloud CLI. Skrip menggunakan alat command line
gsutiluntuk mengupload output dumper ke Cloud Storage.Untuk mengautentikasi dengan Google Cloud agar dapat mengizinkan
gsutilmengupload file ke Cloud Storage, jalankan perintah berikut:gcloud auth application-default login
Menjadwalkan otomatisasi
Simpan skrip berikut ke file lokal. Skrip ini dirancang untuk dikonfigurasi dan dieksekusi oleh daemon
cronuntuk mengotomatiskan proses ekstraksi dan upload output dumper.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Agar skrip dapat dieksekusi, jalankan perintah berikut:
chmod +x PATH_TO_SCRIPT
Jadwalkan skrip menggunakan
crontab, dengan mengganti variabel dengan nilai yang sesuai untuk tugas Anda. Tambahkan entri untuk menjadwalkan pekerjaan. Contoh berikut menjalankan skrip setiap hari pada pukul 02.30:Jika Anda menjalankan host yang memiliki akses langsung ke Hive Metastore dan tidak memerlukan autentikasi Kerberos, jalankan perintah berikut:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Jika instance Hive Metastore Anda memerlukan autentikasi Kerberos, jalankan perintah berikut:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
Pertimbangan penjadwalan
Untuk menghindari data yang tidak valid, jalankan alat dumper sebelum transfer data terjadwal.
Sebaiknya lakukan beberapa uji coba skrip secara manual untuk menentukan
waktu rata-rata yang diperlukan alat dumper untuk menghasilkan outputnya. Gunakan waktu ini untuk menetapkan jadwal tugas cron yang mendahului proses transfer Anda untuk memastikan keaktualan data.
Memantau dan melihat status transfer
Anda dapat memantau transfer tingkat resource untuk setiap tabel guna melacak progres, melihat detail error terperinci, dan mengkueri status resource tertentu yang dimigrasikan.
Untuk melihat progres dan status resource Anda, pilih salah satu opsi berikut:
Konsol
Di konsol Google Cloud , buka halaman Transfer data.
Klik konfigurasi transfer Anda dari daftar.
Di halaman Detail transfer, klik tab Tabel yang ditransfer.
Lihat daftar resource yang sedang ditransfer. Anda dapat melihat detail seperti berikut:
- Status transfer terakhir: status resource saat ini berdasarkan transfer resource terbaru, termasuk progres penyelesaian.
- Nama tabel: nama resource yang ditransfer. Klik nama resource untuk melihat tampilan mendetail resource.
- Operasi terakhir: operasi transfer terakhir yang memperbarui resource.
- Ringkasan status: metrik progres terperinci atau pesan error jika transfer gagal.
- Last successful run: operasi terakhir yang berhasil mentransfer resource.
Gunakan kotak filter untuk menelusuri resource tertentu menurut nama atau memfilter menurut statusnya saat ini, misalnya, Transfer gagal. Filter Nama tabel
mendukung pencocokan karakter pengganti—misalnya, menggunakan *—tetapi pencocokan
karakter pengganti tidak didukung untuk kolom filter lainnya.
API
Anda dapat membuat kueri status resource transfer menggunakan BigQuery Data Transfer Service API.
Mencantumkan semua resource dan statusnya
Untuk mencantumkan semua resource dan statusnya, gunakan
metode projects.locations.transferConfigs.transferResources.list.
Jalankan permintaan API dengan informasi berikut:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
Perintah curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Anda dapat memfilter hasil menurut nama atau status resource. Misalnya, untuk menemukan semua transfer yang gagal, tambahkan
?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED"
ke URL permintaan.
Ganti kode berikut:
CONFIG_ID: ID konfigurasi transfer.LOCATION: lokasi tempat konfigurasi transfer dibuat.PROJECT_ID: ID Google Cloud project yang menjalankan transfer.
Mendapatkan resource tertentu
Untuk mendapatkan status tabel atau partisi tertentu, gunakan
metode projects.locations.transferConfigs.transferResources.get.
Jalankan permintaan API dengan informasi berikut:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
Perintah curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Ganti kode berikut:
CONFIG_ID: ID konfigurasi transfer.LOCATION: lokasi tempat konfigurasi transfer dibuat.PROJECT_ID: ID Google Cloud project yang menjalankan transfer.RESOURCE_ID: ID resource, misalnya, nama tabel.
Kuota dan batas konkurensi
Untuk setiap eksekusi BigQuery Data Transfer Service, konektor Hive Metastore menjalankan satu tugas Storage Transfer Service per tabel.
Setelah kuota tercapai, transfer akan menunggu hingga kuota lainnya tersedia. Tugas Storage Transfer Service dibuat di project pelanggan dan tunduk pada kuota dan batas Storage Transfer Service.
Harga
Tidak ada biaya untuk menggunakan konektor Apache Hive Metastore guna mentransfer data Anda. Setelah data ditransfer, Anda akan dikenai biaya penyimpanan data di tujuan. Untuk informasi selengkapnya, lihat referensi berikut: