
Migra tablas de Apache Hive Metastore aGoogle Cloud
En este documento, se muestra cómo migrar tus tablas de Iceberg y Hive administradas por Apache Hive Metastore aGoogle Cloud con el Servicio de transferencia de datos de BigQuery.
El conector de migración de Apache Hive Metastore en el Servicio de transferencia de datos de BigQuery te permite migrar sin problemas tus tablas de Hive Metastore a Google Cloud a gran escala. Este conector admite tablas de Hive y de Iceberg desde instalaciones locales y entornos de nube, incluidas las configuraciones de Cloudera. El conector de migración de Hive Metastore admite archivos almacenados en las siguientes fuentes de datos:
- Sistema de archivos distribuidos de Apache Hadoop (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage o Azure Data Lake Storage Gen2
Con el conector de migración de Hive Metastore, puedes usar Cloud Storage como almacenamiento de archivos y registrar tus tablas de Hive Metastore con uno de los siguientes almacenes de metadatos:
Catálogo de entorno de ejecución de Lakehouse (catálogo de REST de Iceberg)
Te recomendamos que uses el catálogo de REST de Iceberg del catálogo de entorno de ejecución de Lakehouse para todos tus datos de Iceberg.
El catálogo de REST de Iceberg del catálogo de entorno de ejecución de Lakehouse crea interoperabilidad entre tus motores de consultas, ya que ofrece una única fuente de información para todos tus datos de Iceberg. Puedes usar BigQuery para consultar los datos, además de Apache Spark y otros motores de OSS. El catálogo de REST de Iceberg del catálogo de entorno de ejecución de Lakehouse solo admite formatos de tablas de Iceberg.
Catálogo de Hive del catálogo de entorno de ejecución de Lakehouse (vista previa)
Te recomendamos que uses el catálogo de Hive del catálogo de entorno de ejecución de Lakehouse para todas tus tablas de Hive.
El catálogo de Hive del catálogo de entorno de ejecución de Lakehouse te permite registrar tus tablas de Hive migradas con el catálogo de entorno de ejecución de Lakehouse a través de un catálogo de Hive. Esto ofrece un almacén de metadatos sin servidores para las tablas de Apache Hive. Puedes usar BigQuery para consultar los datos (sujeto a limitaciones de formato), además de Apache Spark y otros motores de OSS.
-
Dataproc Metastore admite los formatos de tablas Hive y Iceberg. Solo puedes usar Apache Spark y otros motores de OSS para leer y escribir datos en Dataproc Metastore.
Este conector admite transferencias completas y solo de metadatos. Las transferencias completas transferirán tus datos y metadatos de las tablas de origen al metastore de destino. Puedes crear una transferencia solo de metadatos si ya tienes tus datos en Cloud Storage y solo deseas registrarlos en un metastore de destino.
En el siguiente diagrama, se proporciona una descripción general del proceso de migración.
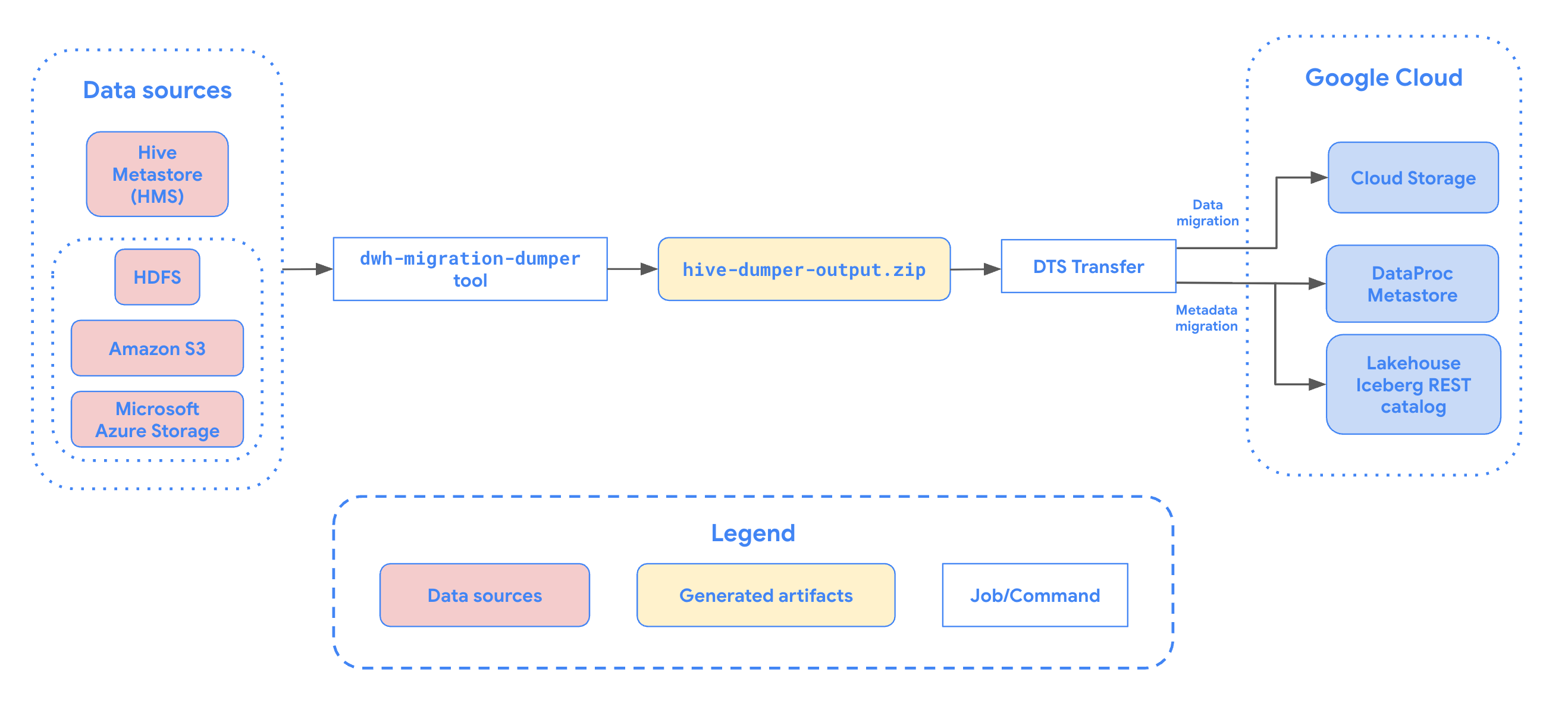
Limitaciones
Las transferencias de tablas de Hive Metastore están sujetas a las siguientes limitaciones:
- Las transferencias de Hive Metastore deben tener un mínimo de 30 minutos entre 2 ejecuciones programadas. Las ejecuciones a pedido se pueden seguir activando en cualquier intervalo.
- Los nombres de archivo deben cumplir con los requisitos para nombrar objetos de Cloud Storage.
- Cloud Storage tiene un límite de 5 TiB para objetos individuales. No se podrán transferir los archivos de las tablas de Hive Metastore que superen los 5 TiB.
- El Servicio de transferencia de almacenamiento tiene comportamientos específicos si los datos cambian en la fuente mientras se realiza una transferencia. No recomendamos escribir en las tablas mientras se migran de forma activa. Para obtener una lista de otras limitaciones del Servicio de transferencia de almacenamiento, consulta las limitaciones conocidas.
Limitaciones del catálogo de Hive del catálogo de entorno de ejecución de Lakehouse
Cuando usas el catálogo de Hive del catálogo de Lakehouse Runtime (BIGLAKE_HIVE_CATALOG) como tu metastore de destino, se aplican las siguientes limitaciones y consideraciones:
- El ID del catálogo de Hive del catálogo del entorno de ejecución de Lakehouse solo debe contener letras minúsculas, números y guiones bajos (
_). No debe contener guiones (-) ni letras mayúsculas. - No puedes ver ni administrar los catálogos de Hive del catálogo del entorno de ejecución de Lakehouse en la consola de Google Cloud . Sin embargo, las tablas migradas son visibles y se pueden consultar en el conjunto de datos de destino de BigQuery.
- Se aplican todas las limitaciones del catálogo de Hive del catálogo de entornos de ejecución de Lakehouse para los formatos de metadatos y los tipos de datos de código abierto.
- Para obtener información sobre la compatibilidad con formatos como CSV y JSON, consulta Formatos de almacenamiento compatibles.
- Para obtener información sobre los tipos de datos no admitidos (como
UNIONo arrays anidados) y las estadísticas de columnas, consulta las limitaciones del metastore y las limitaciones de las particiones.
Opciones de transferencia de datos
En las siguientes secciones, se proporciona más información sobre cómo puedes configurar tus transferencias de Hive Metastore.
Transferencias incrementales
Cuando se configura una transferencia con un programa recurrente, cada transferencia posterior actualiza la tabla en Google Cloud con las actualizaciones más recientes realizadas en la tabla de origen. Por ejemplo, todas las actualizaciones de datos y todas las operaciones de inserción, eliminación o actualización con cambios de esquema se reflejan en Google Cloud con cada transferencia.
Filtrar particiones
Puedes transferir un subconjunto de particiones de tus tablas de Hive si proporcionas un archivo JSON de filtro personalizado almacenado en Cloud Storage. Cuando programes la transferencia, proporciona la ruta de acceso completa de Cloud Storage a este archivo JSON con el parámetro partition_filter_gcs_path.
A continuación, se muestra un ejemplo de la estructura del archivo JSON de filtro:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
Condiciones de filtro
El campo condition del archivo JSON admite los siguientes valores, cada uno con un formato específico para el array partitions:
IN: Especifica las rutas de acceso exactas de las particiones que se incluirán. El arraypartitionscontiene cadenas que representan la estructura de directorios exacta de las particiones en relación con la ruta base de la tabla (por ejemplo,["partition_key1=value1/partition_key2=value2"]). Puedes especificar varias rutas de acceso en el array.LESS_THAN: Incluye las particiones en las que el valor de la clave de partición principal es menor o igual que el valor especificado. El arraypartitionsdebe contener una sola cadena en el formato["<partition_key>;<value>"].GREATER_THAN: Incluye particiones en las que el valor de la clave de partición principal es mayor o igual que el valor especificado. El arraypartitionsdebe contener una sola cadena en el formato["<partition_key>;<value>"].RANGE: Incluye las particiones en las que el valor de la clave de partición principal se encuentra dentro del rango especificado (inclusivo). El arraypartitionsdebe contener una sola cadena en el formato["<partition_key>;<start_value>;<end_value>"].
Las condiciones del filtro están sujetas a las siguientes reglas y restricciones:
- Valores inclusivos: Las condiciones de filtro para
GREATER_THAN,LESS_THANyRANGEincluyen los valores proporcionados. Por ejemplo, un filtroLESS_THANcon un valor de2023incluye particiones hasta2023inclusive. - Borrado de particiones: Si una partición de destino existente satisface el filtro de partición y ya no está presente en la fuente, se quita del metastore de destino. Sin embargo, los archivos de datos subyacentes de esa partición no se borran del bucket de destino de Cloud Storage.
- Restricciones de una sola tabla:
- No se permiten varios filtros en la misma tabla.
- No puedes combinar diferentes tipos de condiciones (por ejemplo,
GREATER_THANyIN) en la misma tabla.
- Columna de partición de destino: Las condiciones de filtro como
GREATER_THAN,LESS_THANyRANGEdeben segmentarse para la columna de partición principal. - Limitaciones de prefijos: La combinación de filtros especificada no debe resolverse en más de 1,000 prefijos por tabla. Por ejemplo, un filtro como
year>2020en una tabla particionada poryear/month/daydebe generar menos de 1,000 prefijosyear=únicos.
Antes de comenzar
Antes de programar la transferencia de Hive Metastore, realiza los pasos que se indican en esta sección.
Habilita las APIs
Habilita las siguientes APIs en tu proyecto deGoogle Cloud :
- API de Data Transfer
- API de Storage Transfer
- API de BigLake
Cuando habilitas la API de Data Transfer, se crea un agente de servicio.
Configura permisos
Para configurar los permisos de una transferencia de Hive Metastore, sigue los pasos que se indican en las siguientes secciones.
- El usuario o la cuenta de servicio que crea la transferencia debe tener el rol de administrador de BigQuery (
roles/bigquery.admin). Si usas una cuenta de servicio, solo se usa para crear la transferencia. Cuando se habilita la API de Data Transfer, se crea un agente de servicio (P4SA).
Para garantizar que el agente de servicio tenga los permisos necesarios para ejecutar una transferencia de Hive Metastore, pídele a tu administrador que le otorgue al agente de servicio los siguientes roles de IAM en el proyecto:
- Administrador de transferencia de almacenamiento (
roles/storagetransfer.admin) - Consumidor de Service Usage (
roles/serviceusage.serviceUsageConsumer) - Administrador de almacenamiento (
roles/storage.admin) -
Para migrar metadatos al catálogo de entorno de ejecución de Lakehouse (catálogo de REST de Iceberg o catálogo de Hive), necesitas el rol de administrador de BigLake (
roles/biglake.admin). -
Para migrar metadatos a Dataproc Metastore, debes tener el rol de Propietario de datos de Dataproc Metastore (
roles/metastore.metadataOwner).
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Es posible que tu administrador también pueda otorgar los permisos necesarios al agente de servicio a través de roles personalizados o de otros roles predefinidos.
- Administrador de transferencia de almacenamiento (
Si usas una cuenta de servicio, otorga al agente de servicio el rol
roles/iam.serviceAccountTokenCreatorcon el siguiente comando:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Otorga al agente de servicio del Servicio de transferencia de almacenamiento (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) los siguientes roles en el proyecto:roles/storage.admin- Si migras desde HDFS o un entorno local, también debes otorgar el rol
roles/storagetransfer.serviceAgent.
También puedes configurar permisos más detallados. Para obtener más información, consulta la siguiente guía:
Genera un archivo de metadatos para Apache Hive
Ejecuta la herramienta dwh-migration-dumper para extraer metadatos para Apache Hive.
La herramienta genera un archivo llamado hive-dumper-output.zip que se puede subir a un bucket de Cloud Storage. En este documento, se hace referencia a este bucket de Cloud Storage como DUMPER_BUCKET.
También puedes programar cargas periódicas con una secuencia de comandos. Para obtener más información, consulta Automatiza la ejecución de la herramienta de volcado con un trabajo de cron.
Configura el Servicio de transferencia de almacenamiento
Selecciona una de las siguientes opciones:
HDFS
Se requiere un agente de transferencia de almacenamiento para las transferencias locales o de HDFS.
Para configurar el agente, haz lo siguiente:
- Instala Docker en las máquinas de agentes locales.
- Crea un grupo de agentes del Servicio de transferencia de almacenamiento en tu proyecto Google Cloud .
- Instala agentes en tus máquinas de agentes locales.
Amazon S3
Las transferencias de Amazon S3 son transferencias sin agente.
Para configurar el Servicio de transferencia de almacenamiento para una transferencia de Amazon S3, haz lo siguiente:
- Configura las credenciales de acceso para AWS Amazon S3.
- Toma nota del ID de clave de acceso y la clave de acceso secreta después de configurar tus credenciales de acceso.
- Agrega los rangos de IP que usan los trabajadores del Servicio de transferencia de almacenamiento a tu lista de IPs permitidas si tu proyecto de AWS usa restricciones de IP.
Microsoft Azure
Las transferencias desde Microsoft Azure Storage son transferencias sin agentes.
Para configurar el Servicio de transferencia de almacenamiento para una transferencia de Microsoft Azure Storage, haz lo siguiente:
- Genera un token de firma de acceso compartido (SAS) para tu cuenta de almacenamiento de Microsoft Azure.
- Toma nota del token SAS después de generarlo.
- Agrega los rangos de IP que usan los trabajadores del Servicio de transferencia de almacenamiento a tu lista de IPs permitidas si tu cuenta de almacenamiento de Microsoft Azure usa restricciones de IP.
Programa una transferencia de Hive Metastore
Selecciona una de las siguientes opciones:
Console
Ve a la página Transferencia de datos en la Google Cloud consola.
Haz clic en Crear transferencia.
En la sección Tipo de fuente, selecciona Hive Metastore en la lista Fuente.
En Ubicación, selecciona un tipo de ubicación y, luego, una región.
En la sección Nombre de configuración de la transferencia (Transfer config name), en Nombre visible (Display name), ingresa el nombre de la transferencia de datos.
En la sección Opciones de programación, haz lo siguiente:
- En la lista Frecuencia de repetición, selecciona una opción para especificar la frecuencia con la que se ejecuta esta transferencia de datos. Para especificar una frecuencia de repetición personalizada, selecciona Personalizada. Si seleccionas Según demanda, esta transferencia se ejecuta cuando activas la transferencia de forma manual.
- Si corresponde, selecciona Comenzar ahora o Comenzar a una hora determinada y proporciona una fecha de inicio y una hora de ejecución.
En la sección Detalles de fuente de datos, haz lo siguiente:
- En Estrategia de transferencia, selecciona una de las siguientes opciones:
FULL_TRANSFER: Transfiere todos los datos y registra los metadatos en el metastore de destino. Esta es la opción predeterminada.METADATA_ONLY: Registra solo los metadatos. Debes tener datos presentes en la ubicación correcta de Cloud Storage a la que se hace referencia en los metadatos.
- En Patrones de nombres de tablas, especifica las tablas del data lake de HDFS que se transferirán. Para ello, proporciona nombres de tablas o patrones que coincidan con las tablas de la base de datos de HDFS. Debes usar la sintaxis de expresiones regulares de Java para especificar patrones de tablas. Por ejemplo:
db1..*coincide con todas las tablas de db1.db1.table1;db2.table2coincide con table1 en db1 y table2 en db2.
- En BQMS discovery dump gcs path, ingresa la ruta de acceso al archivo
hive-dumper-output.zipque generaste cuando creaste un archivo de metadatos para Apache Hive. Si usas la automatización de la salida del volcado concron, proporciona la ruta de la carpeta de Cloud Storage configurada en--gcs-base-path, que contiene archivos ZIP de salida del volcado.- En Tipo de almacenamiento, selecciona una de las siguientes opciones. Este campo solo está disponible si Estrategia de transferencia está configurado como
FULL_TRANSFER: HDFS: Selecciona esta opción si tu almacenamiento de archivos esHDFS. En el campo Nombre del grupo de agentes de STS, debes proporcionar el nombre del grupo de agentes que creaste cuando configuraste tu agente de Storage Transfer.S3: Selecciona esta opción si tu almacenamiento de archivos esAmazon S3. En los campos ID de clave de acceso y Clave de acceso secreta, debes proporcionar el ID de clave de acceso y la clave de acceso secreta que creaste cuando configuraste tus credenciales de acceso.AZURE: Selecciona esta opción si tu almacenamiento de archivos esAzure Blob Storage. En el campo Token SAS, debes proporcionar el token SAS que creaste cuando configuraste tus credenciales de acceso.
- En Tipo de almacenamiento, selecciona una de las siguientes opciones. Este campo solo está disponible si Estrategia de transferencia está configurado como
- Opcional: En Ruta de acceso de GCS al filtro de partición, ingresa una ruta de acceso completa de Cloud Storage a un archivo JSON de filtro personalizado para filtrar particiones de las tablas de origen.
- En Ruta de acceso de GCS de destino, ingresa una ruta de acceso a un bucket de Cloud Storage para almacenar tus datos migrados.
- Elige el tipo de metastore de destino en la lista desplegable:
DATAPROC_METASTORE: Selecciona esta opción para almacenar tus metadatos en Dataproc Metastore. Debes proporcionar la URL de Dataproc Metastore en URL de Dataproc Metastore.BIGLAKE_REST_CATALOG: Selecciona esta opción para almacenar tus metadatos en el catálogo de REST de Iceberg del catálogo de entorno de ejecución de Lakehouse. El catálogo se crea en función del bucket de Cloud Storage de destino.BIGLAKE_HIVE_CATALOG(versión preliminar): Selecciona esta opción para almacenar tus metadatos en el catálogo de Hive del catálogo del entorno de ejecución de Lakehouse. Debes proporcionar un nombre de catálogo en ID del catálogo de Hive de BigLake Metastore. Si el catálogo no existe, se creará automáticamente.
- Opcional: En Cuenta de servicio, ingresa una cuenta de servicio para usar con esta transferencia de datos. La cuenta de servicio debe pertenecer al mismo proyecto deGoogle Cloud en el que se crean la configuración de transferencia y el conjunto de datos de destino.
- En Estrategia de transferencia, selecciona una de las siguientes opciones:
bq
Para programar la transferencia de Hive Metastore, ingresa el comando bq mk y proporciona la marca de creación de transferencias --transfer_config:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
Reemplaza lo siguiente:
TRANSFER_NAMEes el nombre visible de la configuración de transferencia. El nombre de la transferencia puede ser cualquier valor que te permita identificarla con facilidad si es necesario hacerle modificaciones más tarde.SERVICE_ACCOUNT: Es el nombre de la cuenta de servicio que se usa para crear tu transferencia.La cuenta de servicio debe pertenecer al mismo proyectoGoogle Cloud en el que se crean la configuración de transferencia y el conjunto de datos de destino.PROJECT_ID: Es el ID del proyecto de Google Cloud . Si no se proporciona--project_idpara especificar un proyecto en particular, se usa el proyecto predeterminado.REGION: Es la ubicación de esta configuración de transferencia.TRANSFER_STRATEGY: (Opcional) Especifica uno de los siguientes valores:FULL_TRANSFER: Transfiere todos los datos y registra los metadatos en el metastore de destino. Este es el valor predeterminado.METADATA_ONLY: Registra solo los metadatos. Debes tener datos presentes en la ubicación correcta de Cloud Storage a la que se hace referencia en los metadatos.
LIST_OF_TABLES: Es una lista de entidades que se transferirán. Usa una especificación de nombres jerárquica:database.table. Este campo admite expresiones regulares de RE2 para especificar tablas. Por ejemplo:db1..*: Especifica todas las tablas de la base de datos.db1.table1;db2.table2: Una lista de tablas
DUMPER_BUCKET: Es el bucket de Cloud Storage que contiene el archivohive-dumper-output.zip. Si usas la automatización de salida de volcado concron, cambiatable_metadata_pathpara que sea la ruta de acceso a la carpeta de Cloud Storage configurada con--gcs-base-pathen la configuración de cron, por ejemplo:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>".MIGRATION_BUCKET: Es la ruta de acceso de GCS de destino en la que se cargarán todos los archivos subyacentes. Solo está disponible sitransfer_strategyesFULL_TRANSFER.METASTORE: Es el tipo de metastore al que se migrará. Establece este parámetro en uno de los siguientes valores:DATAPROC_METASTORE: Para transferir metadatos a Dataproc Metastore.BIGLAKE_REST_CATALOG: Para transferir metadatos al catálogo de entorno de ejecución de Lakehouse, usa el catálogo de REST de Iceberg (recomendado para las tablas de Iceberg).BIGLAKE_HIVE_CATALOG: Para transferir metadatos al catálogo del entorno de ejecución de Lakehouse Hive Catalog (recomendado para tablas de Apache Hive) (vista previa).
DATAPROC_METASTORE_URL: Es la URL de tu Dataproc Metastore. Obligatorio simetastoreesDATAPROC_METASTORE.HIVE_CATALOG_ID: Es el ID del catálogo de Hive del catálogo del entorno de ejecución de Lakehouse. Obligatorio simetastoreesBIGLAKE_HIVE_CATALOG. Si el catálogo no existe, se creará automáticamente.STORAGE_TYPE: Especifica el almacenamiento de archivos subyacente para tus tablas. Los tipos admitidos sonHDFS,S3yAZURE. Obligatorio sitransfer_strategyesFULL_TRANSFER.AGENT_POOL_NAME: Es el nombre del grupo de agentes que se usa para crear agentes. Obligatorio sistorage_typeesHDFS.AWS_ACCESS_KEY_ID: Es el ID de la clave de acceso de las credenciales de acceso. Obligatorio sistorage_typeesS3.AWS_SECRET_ACCESS_KEY: Es la clave de acceso secreta de las credenciales de acceso. Se requiere sistorage_typeesS3.AZURE_SAS_TOKEN: Es el token de SAS de las credenciales de acceso. Obligatorio sistorage_typeesAZURE.FILTER_GCS_PATH: (Opcional) Ruta de acceso completa de Cloud Storage a un archivo JSON de filtro personalizado para filtrar particiones.
Ejecuta este comando para crear la configuración de transferencia y comenzar la transferencia de las tablas administradas de Hive. De forma predeterminada, las transferencias se programan para ejecutarse cada 24 horas, pero se pueden configurar con opciones de programación de transferencias.
Cuando se complete la transferencia, tus tablas del clúster de Hadoop se migrarán a MIGRATION_BUCKET.
Automatiza la ejecución de la herramienta de volcado con un trabajo de cron
Puedes automatizar las transferencias incrementales con un trabajo de cron para ejecutar la herramienta dwh-migration-dumper. Automatizar la extracción de metadatos para garantizar que haya disponible una volcado actualizado de la fuente de datos para las ejecuciones de transferencia incrementales posteriores
Antes de comenzar
Antes de usar esta secuencia de comandos de automatización, debes hacer lo siguiente:
Completa todos los requisitos previos para la herramienta de volcado.
Instala Google Cloud CLI. La secuencia de comandos usa la herramienta de línea de comandos
gsutilpara subir el resultado de volcado a Cloud Storage.Para autenticarte con Google Cloud y permitir que
gsutilsuba archivos a Cloud Storage, ejecuta el siguiente comando:gcloud auth application-default login
Cómo programar la automatización
Guarda la siguiente secuencia de comandos en un archivo local. Esta secuencia de comandos está diseñada para que un daemon
cronla configure y ejecute para automatizar el proceso de extracción y carga del resultado del volcado.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Para que se pueda ejecutar la secuencia de comandos, ejecuta el siguiente comando:
chmod +x PATH_TO_SCRIPT
Programa la secuencia de comandos con
crontaby reemplaza las variables por los valores adecuados para tu trabajo. Agrega una entrada para programar el trabajo. En los siguientes ejemplos, se ejecuta la secuencia de comandos todos los días a las 2:30 a.m.:Si ejecutas en un host que tiene acceso directo al almacén de metadatos de Hive y no requiere autenticación de Kerberos, ejecuta el siguiente comando:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Si tu instancia de Hive Metastore requiere autenticación de Kerberos, ejecuta el siguiente comando:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
Consideraciones de programación
Para evitar que los datos estén desactualizados, ejecuta la herramienta de volcado antes de la transferencia de datos programada.
Te recomendamos que ejecutes algunas pruebas del script de forma manual para determinar el tiempo promedio que tarda la herramienta de volcado en generar su resultado. Usa esta sincronización para establecer un programa de trabajos de cron que preceda a la ejecución de la transferencia y, así, garantizar la actualidad de los datos.
Supervisa y consulta el estado de la transferencia
Puedes supervisar las transferencias a nivel de recursos para tablas individuales y, así, hacer un seguimiento del progreso, ver detalles de errores específicos y consultar el estado de los recursos específicos que se están migrando.
Para ver el progreso y el estado de tus recursos, selecciona una de las siguientes opciones:
Console
En la consola de Google Cloud , ve a la página Transferencia de datos.
Haz clic en la configuración de transferencia en la lista.
En la página Detalles de la transferencia, haz clic en la pestaña Tablas transferidas.
Consulta la lista de recursos que se transfieren. Puedes ver detalles como los siguientes:
- Estado de la última transferencia: Es el estado actual del recurso según la transferencia de recursos más reciente, incluido el progreso de la finalización.
- Nombre de la tabla: Es el nombre del recurso que se está transfiriendo. Haz clic en el nombre del recurso para ver una vista detallada del recurso.
- Última ejecución: Es la última ejecución de transferencia que actualizó el recurso.
- Resumen del estado: Métricas de progreso detalladas o mensajes de error si falló la transferencia.
- Última ejecución exitosa: Es la última ejecución que transfirió correctamente el recurso.
Usa la barra de filtros para buscar recursos específicos por nombre o filtrar por su estado actual, por ejemplo, Transferencias fallidas. El filtro Nombre de la tabla admite la coincidencia con comodines (por ejemplo, con *), pero esta no se admite para otros campos de filtro.
API
Puedes consultar el estado de los recursos de transferencia con la API del Servicio de transferencia de datos de BigQuery.
Enumera todos los recursos y sus estados
Para enumerar todos los recursos y sus estados, usa el método projects.locations.transferConfigs.transferResources.list.
Ejecuta la solicitud a la API con la siguiente información:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
Comando curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Puedes filtrar los resultados por nombre o estado del recurso. Por ejemplo, para encontrar todas las transferencias fallidas, agrega ?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED" a la URL de la solicitud.
Reemplaza lo siguiente:
CONFIG_ID: Es el ID de la configuración de transferencia.LOCATION: Es la ubicación en la que se creó la configuración de transferencia.PROJECT_ID: Es el ID del proyecto de Google Cloud que ejecuta las transferencias.
Obtén un recurso específico
Para obtener el estado de una tabla o partición específica, usa el método projects.locations.transferConfigs.transferResources.get.
Ejecuta la solicitud a la API con la siguiente información:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
Comando curl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Reemplaza lo siguiente:
CONFIG_ID: Es el ID de la configuración de transferencia.LOCATION: Es la ubicación en la que se creó la configuración de transferencia.PROJECT_ID: Es el ID del proyecto de Google Cloud que ejecuta las transferencias.RESOURCE_ID: Es el ID del recurso, por ejemplo, el nombre de la tabla.
Cuotas y límites de simultaneidad
En cada ejecución del Servicio de transferencia de datos de BigQuery, el conector de Hive Metastore ejecuta un trabajo del Servicio de transferencia de almacenamiento por tabla.
Una vez que se alcanza la cuota, la transferencia espera hasta que haya más cuota disponible. Los trabajos del Servicio de transferencia de almacenamiento se crean en el proyecto del cliente y están sujetos a las cuotas y los límites del Servicio de transferencia de almacenamiento.
Precios
No se aplican cargos por usar el conector de Apache Hive Metastore para transferir tus datos. Una vez que se transfieren los datos, se te cobra por almacenarlos en tu destino. Para obtener más información, consulta lo siguiente: