
BigQuery 데이터 캔버스를 사용한 분석
이 문서에서는 데이터 분석을 위해 데이터 캔버스를 사용하는 방법을 설명합니다. Knowledge Catalog를 사용하여 데이터 캔버스 메타데이터를 관리할 수도 있습니다.
BigQuery의 Gemini 기능인 BigQuery 데이터 캔버스를 사용하면 자연어 프롬프트와 분석 워크플로용 그래픽 인터페이스를 통해 데이터를 찾고, 변환하고, 쿼리하고, 시각화할 수 있습니다.
분석 워크플로의 경우 BigQuery 데이터 캔버스는 워크플로의 그래픽 뷰를 제공하는 방향성 비순환 그래프(DAG)를 사용합니다. BigQuery 데이터 캔버스에서는 쿼리 결과를 반복하고 한 곳에서 여러 문의 브랜치로 작업할 수 있습니다.
BigQuery 데이터 캔버스는 분석 작업을 가속화하고 데이터 분석가, 데이터 엔지니어 등의 데이터 전문가가 데이터에서 유용한 정보로 이동하는 여정을 지원하도록 설계되었습니다. 특정 도구에 대한 기술적 지식이 없어도 되며 SQL 읽기 및 쓰기에 대한 기본적인 지식만 있으면 됩니다. BigQuery 데이터 캔버스는 Knowledge Catalog 메타데이터와 함께 작동하여 자연어를 기반으로 적절한 테이블을 식별합니다.
BigQuery 데이터 캔버스는 비즈니스 사용자가 직접 사용하는 용도가 아닙니다.
BigQuery 데이터 캔버스는 BigQuery의 Gemini를 사용하여 데이터를 찾고, SQL을 만들고, 차트를 생성하고, 데이터 요약을 만듭니다.
Google Cloud 를 위한 Gemini에서 사용자 데이터를 사용하는 방법과 시점을 알아보세요.
기능
BigQuery 데이터 캔버스를 사용하면 다음 작업을 할 수 있습니다.
Knowledge Catalog 메타데이터와 함께 자연어 쿼리 또는 키워드 검색 구문을 사용하여 테이블, 뷰 또는 구체화된 뷰와 같은 애셋을 찾습니다.
다음과 같은 기본 SQL 쿼리에 자연어를 사용합니다.
FROM절, 수학 함수, 배열, 구조체가 포함된 쿼리- 두 테이블의
JOIN작업
원하는 내용을 자연어로 설명하여 커스텀 시각화를 만듭니다.
데이터 통계 자동화
제한사항
다음과 같은 경우에는 자연어 명령이 제대로 작동하지 않을 수 있습니다.
- BigQuery ML
- Apache Spark
- 객체 테이블
- BigLake
- 조회수
INFORMATION_SCHEMA회 - JSON
- 중첩되고 반복되는 필드
- 복잡한 함수 및 데이터 유형(예:
DATETIME및TIMEZONE)
데이터 시각화는 Geomap 차트에서 작동하지 않습니다.
프롬프트 권장사항
적절한 프롬프트 기법을 사용하면 복잡한 SQL 쿼리를 생성할 수 있습니다. 다음 제안은 BigQuery 데이터 캔버스에서 자연어 프롬프트를 미세 조정하여 쿼리의 정확성을 높이는 데 도움이 됩니다.
명확하게 작성합니다. 요청을 명확하게 서술하고 모호하게 표현하지 마세요.
직접적으로 질문하세요. 가장 정확한 답변을 얻으려면 한 번에 하나의 질문을 하고 프롬프트는 간결하게 유지하세요. 처음에 질문이 두 개 이상 포함된 프롬프트를 입력한 경우 Gemini가 명확하게 이해할 수 있도록 질문의 각 부분을 항목화하세요.
중점적으로 명확한 지침을 주세요. 프롬프트에서 주요 용어를 강조합니다.
작업 순서를 지정합니다. 명확하고 체계적인 방식으로 지침을 제공합니다. 작업을 집중적으로 수행할 수 있는 작은 단계로 나눕니다.
수정하고 반복하세요. 다양한 문구와 접근 방식을 시도하여 가장 좋은 결과를 얻는 방법을 알아보세요.
자세한 내용은 BigQuery 데이터 캔버스 프롬프트 권장사항을 참조하세요.
시작하기 전에
- BigQuery의 Gemini가 Google Cloud 프로젝트에 사용 설정되어 있는지 확인합니다. 일반적으로 관리자가 이 단계를 실행합니다.
- BigQuery 데이터 캔버스를 사용하기 위한 필요한 Identity and Access Management(IAM) 권한이 있는지 확인합니다.
- Knowledge Catalog에서 데이터 캔버스 메타데이터를 관리하려면 Google Cloud 프로젝트에서 Dataplex API가 사용 설정되어 있어야 합니다.
필요한 역할
BigQuery 데이터 캔버스를 사용하는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 다음 IAM 역할을 부여해 달라고 요청하세요.
- BigQuery Studio 사용자 (
roles/bigquery.studioUser) - Google Cloud를 위한 Gemini 사용자 (
roles/cloudaicompanion.user)
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
BigQuery에서 IAM 역할 및 권한에 대한 자세한 내용은 IAM 소개를 참조하세요.
Knowledge Catalog에서 데이터 캔버스 메타데이터를 관리하려면 필요한 Knowledge Catalog 역할과 dataform.repositories.get 권한이 있는지 확인합니다.
데이터 캔버스의 보안 고려사항
BigQuery의 코드 애셋은 Dataform으로 구동되므로 이러한 애셋에 액세스할 수 있는 사용자의 보안 영향을 고려해야 합니다.
- 코드 애셋의 공개 상태는 프로젝트 수준 Dataform 권한에 따라 관리됩니다.
dataform.repositories.list권한이 있는 사용자(BigQuery 작업 사용자, BigQuery Studio 사용자, BigQuery 사용자와 같은 표준 BigQuery 역할에 포함됨)는 이러한 애셋을 만들었는지 또는 이러한 애셋이 공유되었는지와 관계없이 Google Cloud 프로젝트의 탐색기 패널에서 모든 코드 애셋을 볼 수 있습니다. 표시 여부를 제한하려면dataform.repositories.list권한이 제외된 커스텀 역할을 만드세요. - Dataform 서비스 에이전트와 공유된 모든 보안 비밀은 이러한 애셋을 수정할 수 있는 사용자가 액세스할 수 있습니다. 인증 정보를 보호하려면 신뢰할 수 있는 사용자에 대한 생성 및 수정 액세스를 제한하고 Dataform 서비스 에이전트가 액세스할 수 있는 보안 비밀을 제한하세요. 자세한 내용은 패키지 설치 중 보안 비밀 액세스를 참고하세요.
자세한 내용은 Dataform 권한의 보안 고려사항을 참고하세요.
노드 유형
캔버스는 하나 이상의 노드 모음입니다. 노드는 순서에 관계없이 연결할 수 있습니다. BigQuery 데이터 캔버스에는 다음과 같은 노드 유형이 있습니다.
- 텍스트
- 검색
- 표
- SQL
- 대상 노드
- 시각화
- 통계
텍스트 노드
BigQuery 데이터 캔버스에서 텍스트 노드를 사용하면 캔버스에 서식 있는 텍스트 콘텐츠를 추가할 수 있습니다. 캔버스에 설명, 메모 또는 안내를 추가하여 나와 다른 사람이 분석의 맥락과 목적을 더 쉽게 이해할 수 있습니다. 서식을 위한 마크다운을 비롯해 원하는 텍스트 콘텐츠를 텍스트 노드 편집기에 입력할 수 있습니다. 이 기능을 사용하면 시각적으로 매력적이고 유용한 텍스트 블록을 만들 수 있습니다.
텍스트 노드에서 다음 작업을 할 수 있습니다.
- 노드를 삭제합니다.
- 노드를 디버그합니다.
- 노드를 복제합니다.
검색 노드
BigQuery 데이터 캔버스에서 검색 노드를 사용하면 데이터 애셋을 찾아 캔버스에 통합할 수 있습니다. 자연어 쿼리 또는 키워드 검색과 작업하려는 실제 데이터 간의 연결고리 역할을 합니다.
자연어 또는 키워드를 사용하여 검색어를 입력합니다. 검색 노드는 데이터 애셋을 검색합니다. Knowledge Catalog 메타데이터를 활용하여 컨텍스트 인지도를 향상합니다. BigQuery 데이터 캔버스에서는 최근에 사용한 테이블, 쿼리, 저장된 쿼리도 추천합니다.
검색 노드는 쿼리와 일치하는 관련 데이터 애셋 목록을 반환합니다. 열 이름과 테이블 설명을 고려합니다. 그런 다음 데이터 캔버스에 표 노드로 추가할 애셋을 선택하여 데이터를 추가로 분석하고 시각화할 수 있습니다.
검색 노드에서 다음 작업을 할 수 있습니다.
- 노드를 삭제합니다.
- 노드를 디버그합니다.
- 노드를 복제합니다.
테이블 노드
BigQuery 데이터 캔버스에서 테이블 노드는 분석 워크플로에 통합한 특정 테이블을 나타냅니다. 작업 중인 데이터를 나타내며 직접 상호작용할 수 있습니다.
표 노드에는 이름, 스키마, 데이터 미리보기와 같은 표에 관한 정보가 표시됩니다. 표 스키마, 표 세부정보, 표 미리보기와 같은 세부정보를 확인하여 표와 상호작용할 수 있습니다.
표 노드에서 다음 작업을 할 수 있습니다.
- 노드를 삭제합니다.
- 노드를 디버그합니다.
- 노드를 복제합니다.
- 노드를 실행합니다.
- 노드와 다음 노드를 실행합니다.
데이터 캔버스 내에서 다음 작업을 할 수 있습니다.
- 새 SQL 노드에서 결과를 쿼리합니다.
- 결과를 다른 테이블에 조인합니다.
SQL 노드
BigQuery 데이터 캔버스에서 SQL 노드를 사용하면 캔버스 내에서 직접 맞춤 SQL 쿼리를 실행할 수 있습니다. SQL 노드 편집기에서 직접 SQL 코드를 작성하거나 자연어 프롬프트를 사용하여 SQL을 생성할 수 있습니다.
SQL 노드는 지정된 데이터 소스에 대해 제공된 SQL 쿼리를 실행합니다. SQL 노드는 결과 테이블을 생성하며, 이 테이블은 캔버스에서 다른 노드에 연결하여 추가 분석 또는 시각화를 할 수 있습니다. SQL 노드 실행의 출력(쿼리 결과라고 함)은 대상 노드를 통해 자체 테이블에 유지될 수도 있습니다.
쿼리가 실행된 후 예약된 쿼리로 내보내거나, 쿼리 결과를 내보내거나, 대화형 쿼리를 실행하는 것과 마찬가지로 캔버스를 공유할 수 있습니다.
SQL 노드에서 다음 작업을 할 수 있습니다.
- SQL 문을 예약된 쿼리로 내보냅니다.
- 노드를 삭제합니다.
- 노드를 디버그합니다.
- 노드를 복제합니다.
- 노드를 실행합니다.
- 노드와 다음 노드를 실행합니다.
데이터 캔버스 내에서 다음 작업을 할 수 있습니다.
- 새 SQL 노드에서 결과를 쿼리합니다.
- 결과를 테이블에 저장합니다.
- 시각화 노드에서 결과를 시각화합니다.
- 통계 노드에서 결과에 대한 통계를 생성합니다.
- 결과를 다른 테이블에 조인합니다.
대상 노드
BigQuery 데이터 캔버스에서 대상 노드는 SQL 실행 결과를 전용 테이블에 유지하는 SQL 노드의 하위 요소입니다. 새 데이터 세트 또는 기존 데이터 세트에 테이블을 저장하거나 데이터 세트의 새 테이블 또는 기존 테이블로 저장할 수 있습니다. 대상 테이블을 만든 후 SQL 전환 버튼을 사용하여 상위 SQL 노드가 다시 실행될 때 테이블이 실시간으로 업데이트되도록 합니다.
대상 노드는 상위 노드에서 분리되고 테이블의 콘텐츠가 상위 SQL 노드의 업스트림 변경사항에 영향을 받지 않는 경우 테이블 노드가 될 수 있습니다.
대상 노드에서 다음 작업을 할 수 있습니다.
- 노드를 상위 요소에서 분리하여 독립형 테이블 노드로 만듭니다.
- 새 SQL 노드에서 테이블을 쿼리합니다.
- 결과를 다른 테이블에 조인합니다.
시각화 노드
BigQuery 데이터 캔버스에서 시각화 노드를 사용하면 데이터를 시각적으로 표시하여 추세, 패턴, 통계를 더 쉽게 이해할 수 있습니다. 다양한 차트 유형을 제공하므로 데이터에 가장 적합한 시각화를 선택하고 맞춤설정할 수 있습니다.
시각화 노드는 테이블을 입력으로 사용하며, 이는 SQL 쿼리 또는 테이블 노드의 결과일 수 있습니다. 선택한 차트 유형과 입력 테이블의 데이터를 기반으로 시각화 노드가 차트를 생성합니다. 자동 차트를 선택하여 BigQuery에서 데이터에 가장 적합한 차트 유형을 선택하도록 할 수 있습니다. 그러면 시각화 노드에 생성된 차트가 표시됩니다.
시각화 노드를 사용하면 색상, 라벨, 데이터 소스를 변경하는 등 차트를 맞춤설정할 수 있습니다. 차트를 PNG 파일로 내보낼 수도 있습니다.
다음 그래픽 유형을 사용하여 데이터를 시각화합니다.
- 막대 차트
- 히트맵
- 선 그래프
- 원형 차트
- 분산형 차트
시각화 노드에서 다음 작업을 수행할 수 있습니다.
- 차트를 PNG 파일로 내보냅니다.
- 노드를 디버그합니다.
- 노드를 복제합니다.
- 노드를 실행합니다.
- 노드와 다음 노드를 실행합니다.
데이터 캔버스 내에서 다음 작업을 할 수 있습니다.
- 통계 노드에서 결과에 대한 통계를 생성합니다.
- 시각화를 수정합니다.
통계 노드
BigQuery 데이터 캔버스에서 인사이트 노드를 사용하면 데이터 캔버스 내의 데이터에서 인사이트와 요약을 생성할 수 있습니다. 이를 통해 캔버스에서 패턴을 파악하고, 데이터 품질을 평가하고, 통계 분석을 수행할 수 있습니다. 데이터 내에서 추세, 패턴, 이상치, 상관관계를 식별하고 데이터 분석 결과에 대한 간결하고 명확한 요약을 생성합니다.
데이터 통계에 대한 자세한 내용은 BigQuery에서 데이터 통계 생성을 참고하세요.
통계 노드에서 다음 작업을 수행할 수 있습니다.
- 노드를 삭제합니다.
- 노드를 복제합니다.
- 노드를 실행합니다.
BigQuery 데이터 캔버스 사용
Google Cloud 콘솔, 쿼리 또는 테이블에서 BigQuery 데이터 캔버스를 사용할 수 있습니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 SQL 쿼리 옆에 있는 새로 만들기를 클릭하고 AI 및 지식을 선택한 다음 데이터 캔버스를 클릭합니다.
자연어 프롬프트 필드에 자연어 프롬프트를 입력합니다.
예를 들어
Find me tables related to trees를 입력하면 BigQuery 데이터 캔버스는bigquery-public-data.usfs_fia.plot_tree또는bigquery-public-data.new_york_trees.tree_species와 같은 공개 데이터 세트를 포함하여 가능한 테이블 목록을 반환합니다.테이블을 선택하세요.
선택한 테이블의 테이블 노드가 BigQuery 데이터 캔버스에 추가됩니다. 스키마 정보를 보거나 테이블 세부정보를 보거나 데이터를 미리 보려면 테이블 노드에서 다양한 탭을 선택하세요.
선택사항: 데이터 캔버스를 저장한 후 다음 툴바를 사용하여 데이터 캔버스 세부정보나 버전 기록을 보거나 새 댓글을 추가하거나 기존 댓글에 답글을 달거나 링크를 가져옵니다.
댓글 툴바 기능은 프리뷰 버전으로 제공됩니다. 이 기능에 대한 의견을 제공하거나 지원을 요청하려면 bqui-workspace-pod@google.com으로 이메일을 보내세요.
캔버스 제어
데이터 캔버스 툴바는 노드를 추가하고 캔버스 뷰를 관리하기 위한 다음 컨트롤을 제공합니다.
- 검색: 캔버스에 검색 노드를 추가합니다.
- SQL: 캔버스에 SQL 노드를 추가합니다.
- 텍스트: 댓글에 마크다운 또는 텍스트 노드를 추가합니다.
- 확대/축소 컨트롤: 특정 확대/축소 수준을 설정할 수 있습니다.
- 맞춤 확대/축소: 캔버스에 모든 콘텐츠가 표시되도록 확대/축소를 자동으로 조정합니다.
- 선택 항목으로 확대/축소: 선택한 노드에 초점을 맞추도록 확대/축소를 자동으로 조정합니다.
- 확대: 캔버스 뷰를 확대합니다. Control을 누른 상태에서 마우스 휠을 사용하여 스크롤하여 확대할 수도 있습니다.
- 축소: 캔버스 보기를 줄입니다. Control을 누른 상태에서 마우스 휠을 사용하여 스크롤하여 축소할 수도 있습니다.
- 전체 화면: 캔버스의 전체 화면 모드로 전환합니다.
- 캔버스 정리: 캔버스의 노드를 자동으로 정렬합니다.
- 캔버스 새로고침: 실행 가능한 모든 노드를 단일 버튼으로 실행합니다.
- 작업 더보기: 캔버스 지우기와 같은 추가 옵션을 엽니다.
다음 예에서는 분석 워크플로에서 BigQuery 데이터 캔버스를 사용하는 다양한 방법을 보여줍니다.
워크플로 예시: 데이터 찾기, 쿼리, 시각화
이 예시에서는 BigQuery 데이터 캔버스의 자연어 프롬프트를 사용하여 데이터를 찾고, 쿼리를 생성하고, 쿼리를 수정합니다. 그런 다음 차트를 만듭니다.
프롬프트 1: 데이터 찾기
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 SQL 쿼리 옆에 있는 새로 만들기를 클릭하고 AI 및 지식을 선택한 다음 데이터 캔버스를 클릭합니다.
데이터 검색을 클릭합니다.
filter_list 검색 필터 수정을 클릭한 다음 검색 필터링 창에서 BigQuery 공개 데이터 세트 전환 버튼을 사용 설정으로 클릭합니다.
자연어 프롬프트 필드에 다음 자연어 프롬프트를 입력합니다.
Chicago taxi tripsBigQuery 데이터 캔버스는 Knowledge Catalog 메타데이터를 기반으로 가능한 테이블 목록을 생성합니다. 여러 테이블을 선택할 수 있습니다.
bigquery-public-data.chicago_taxi_trips.taxi_trips테이블을 선택한 다음 캔버스에 추가를 클릭합니다.taxi_trips의 테이블 노드가 BigQuery 데이터 캔버스에 추가됩니다. 스키마 정보를 보거나 테이블 세부정보를 보거나 데이터를 미리 보려면 테이블 노드에서 다양한 탭을 선택하세요.
프롬프트 2: 선택한 테이블에서 SQL 쿼리 생성
bigquery-public-data.chicago_taxi_trips.taxi_trips 테이블의 SQL 쿼리를 생성하려면 다음을 수행합니다.
데이터 캔버스에서 쿼리를 클릭합니다.
자연어 프롬프트 필드에 다음을 입력합니다.
Get me the 100 longest tripsBigQuery 데이터 캔버스는 다음과 유사한 SQL 쿼리를 생성합니다.
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` ORDER BY trip_miles DESC LIMIT 100;
프롬프트 3: 쿼리 수정
생성한 쿼리를 수정하려면 쿼리를 수동으로 수정하거나 자연어 프롬프트를 변경하고 쿼리를 다시 생성하면 됩니다. 이 예시에서는 자연어 프롬프트를 사용하여 고객이 현금으로 결제한 이동만 선택하도록 쿼리를 수정합니다.
자연어 프롬프트 필드에 다음을 입력합니다.
Get me the 100 longest trips where the payment type is cashBigQuery 데이터 캔버스는 다음과 유사한 SQL 쿼리를 생성합니다.
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `PROJECT_ID.chicago_taxi_trips_123123.taxi_trips` WHERE payment_type = 'Cash' ORDER BY trip_miles DESC LIMIT 100;
위 예시에서
PROJECT_ID는 Google Cloud 프로젝트의 ID입니다.쿼리 결과를 보려면 실행을 클릭합니다.
차트 만들기
- 데이터 캔버스에서 시각화를 클릭합니다.
막대 그래프 만들기를 클릭합니다.
BigQuery 데이터 캔버스는 이동 ID별로 가장 많은 이동 거리를 보여주는 막대 그래프를 만듭니다. BigQuery 데이터 캔버스는 차트를 제공하는 것 외에도 시각화를 뒷받침하는 데이터의 일부 주요 세부정보를 요약합니다.
선택사항: 다음 중 하나 이상을 수행합니다.
- 차트를 수정하려면 수정을 클릭한 다음 시각화 수정 창에서 차트를 수정합니다.
- 데이터 캔버스를 공유하려면 공유를 클릭한 다음 링크 공유를 클릭하여 BigQuery 데이터 캔버스 링크를 복사합니다.
- 데이터 캔버스를 정리하려면 작업 더보기를 선택한 다음 캔버스 지우기를 선택합니다. 이 단계를 완료하면 빈 캔버스가 표시됩니다.
워크플로 예시: 테이블 조인
이 예시에서는 BigQuery 데이터 캔버스의 자연어 프롬프트를 사용하여 데이터를 찾고 테이블을 조인합니다. 그런 다음 쿼리를 노트북으로 내보냅니다.
프롬프트 1: 데이터 찾기
자연어 프롬프트 필드에 다음 프롬프트를 입력합니다.
Information about treesBigQuery 데이터 캔버스에는 나무에 관한 정보가 포함된 여러 테이블이 표시됩니다.
이 예시에서는
bigquery-public-data.new_york_trees.tree_census_1995테이블을 선택한 다음 캔버스에 추가를 클릭합니다.테이블이 캔버스에 표시됩니다.
프롬프트 2: 주소에 따라 테이블 조인
데이터 캔버스에서 조인을 클릭합니다.
BigQuery 데이터 캔버스에서 조인할 테이블을 추천합니다.
새 자연어 프롬프트 필드를 열려면 테이블 검색을 클릭합니다.
자연어 프롬프트 필드에 다음 프롬프트를 입력합니다.
Information about treesbigquery-public-data.new_york_trees.tree_census_2005테이블을 선택한 다음 캔버스에 추가를 클릭합니다.테이블이 캔버스에 표시됩니다.
데이터 캔버스에서 조인을 클릭합니다.
이 캔버스 섹션에서 테이블 셀 체크박스를 선택한 다음 확인을 클릭합니다.
자연어 프롬프트 필드에 다음 프롬프트를 입력합니다.
Join on addressBigQuery 데이터 캔버스는 주소를 기준으로 두 테이블을 조인하는 SQL 쿼리를 제안합니다.
SELECT * FROM `bigquery-public-data.new_york_trees.tree_census_2015` AS t2015 JOIN `bigquery-public-data.new_york_trees.tree_census_1995` AS t1995 ON t2015.address = t1995.address;
쿼리를 실행하고 결과를 보려면 실행을 클릭합니다.
쿼리를 노트북으로 내보내기
BigQuery 데이터 캔버스를 사용하면 쿼리를 노트북으로 내보낼 수 있습니다.
- 데이터 캔버스에서 노트북으로 내보내기를 클릭합니다.
- 노트북 저장 창에서 노트북의 이름과 저장할 리전을 입력합니다.
- 저장을 클릭합니다. 노트북이 생성됩니다.
- 선택사항: 만든 노트북을 보려면 열기를 클릭합니다.
워크플로 예시: 프롬프트를 사용하여 차트 수정
이 예시에서는 BigQuery 데이터 캔버스의 자연어 프롬프트를 사용하여 데이터를 찾고, 쿼리하고, 필터링한 다음 시각화 세부정보를 수정합니다.
프롬프트 1: 데이터 찾기
미국 이름에 관한 데이터를 찾으려면 다음 프롬프트를 입력합니다.
Find data about USA namesBigQuery 데이터 캔버스에서 테이블 목록이 생성됩니다.
이 예시에서는
bigquery-public-data.usa_names.usa_1910_current테이블을 선택한 다음 캔버스에 추가를 클릭합니다.
프롬프트 2: 데이터 쿼리
데이터를 쿼리하려면 데이터 캔버스에서 쿼리를 클릭하고 다음 프롬프트를 입력합니다.
Summarize this dataBigQuery 데이터 캔버스는 다음과 유사한 쿼리를 생성합니다.
SELECT state, gender, year, name, number FROM `bigquery-public-data.usa_names.usa_1910_current`
실행을 클릭합니다. 쿼리 결과가 표시됩니다.
프롬프트 3: 데이터 필터링
- 데이터 캔버스에서 결과 쿼리를 클릭합니다.
데이터를 필터링하려면 SQL 프롬프트 필드에 다음 프롬프트를 입력합니다.
Get me the top 10 most popular names in 1980BigQuery 데이터 캔버스는 다음과 유사한 쿼리를 생성합니다.
SELECT name, SUM(number) AS total_count FROM `bigquery-public-data`.usa_names.usa_1910_current WHERE year = 1980 GROUP BY name ORDER BY total_count DESC LIMIT 10;
쿼리를 실행하면 1980년에 태어난 아이의 가장 흔한 이름 10개가 포함된 테이블이 표시됩니다.
차트 만들기 및 수정
데이터 캔버스에서 시각화를 클릭합니다.
BigQuery 데이터 캔버스에서는 막대 그래프, 원형 차트, 선 그래프, 커스텀 시각화 등 여러 시각화 옵션을 제안합니다.
이 예시에서는 막대 그래프 만들기를 클릭합니다.
BigQuery 데이터 캔버스는 다음과 유사한 막대 그래프를 만듭니다.
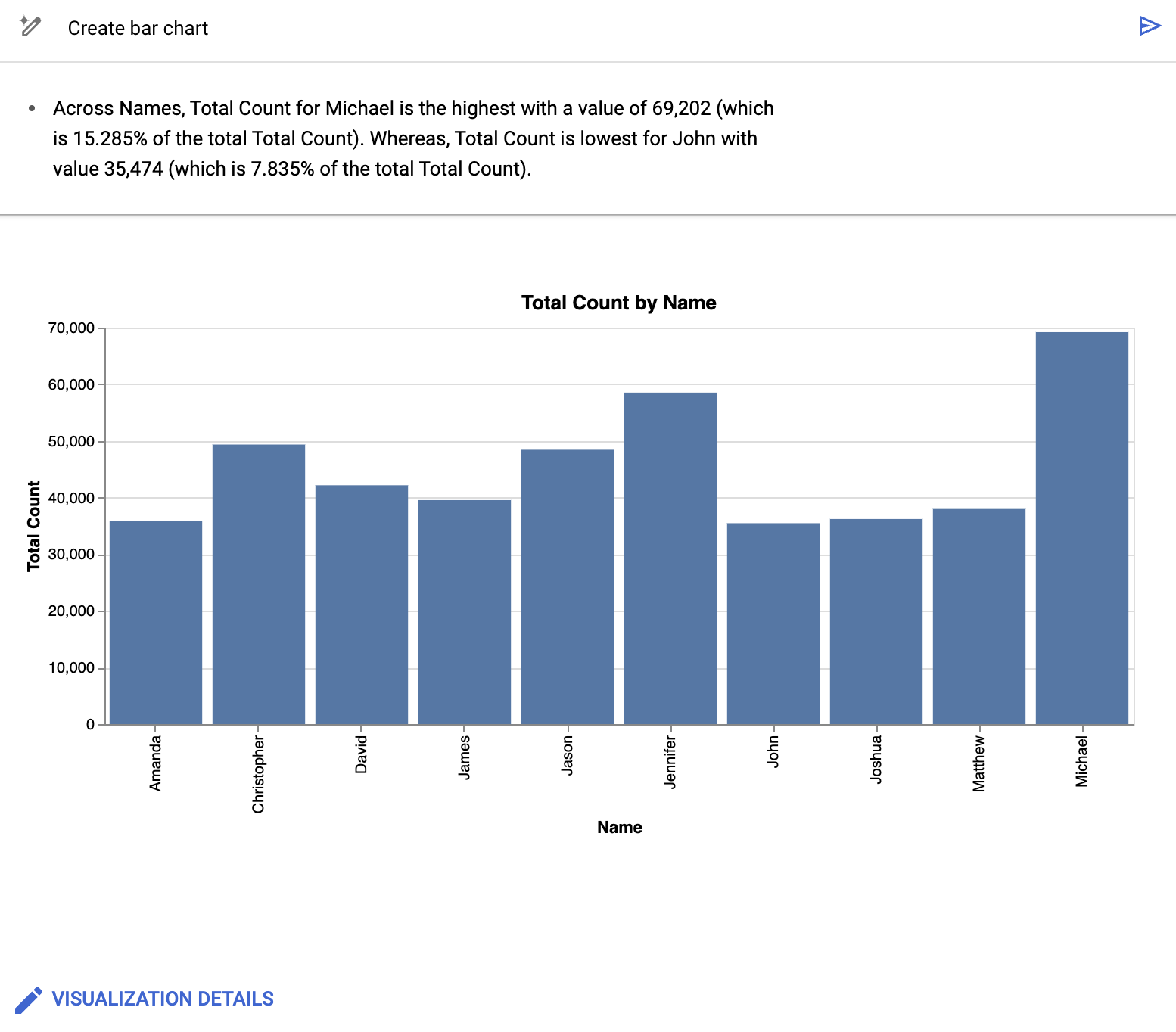
BigQuery 데이터 캔버스는 차트를 제공하는 것 외에도 시각화를 뒷받침하는 데이터의 일부 주요 세부정보를 요약합니다. 시각화 세부정보를 클릭하고 측면 패널에서 차트를 수정하여 차트를 수정할 수 있습니다.
프롬프트 4: 시각화 세부정보 수정
시각화 프롬프트 필드에 다음을 입력합니다.
Create a bar chart sorted high to low, with a gradientBigQuery 데이터 캔버스는 다음과 유사한 막대 그래프를 만듭니다.
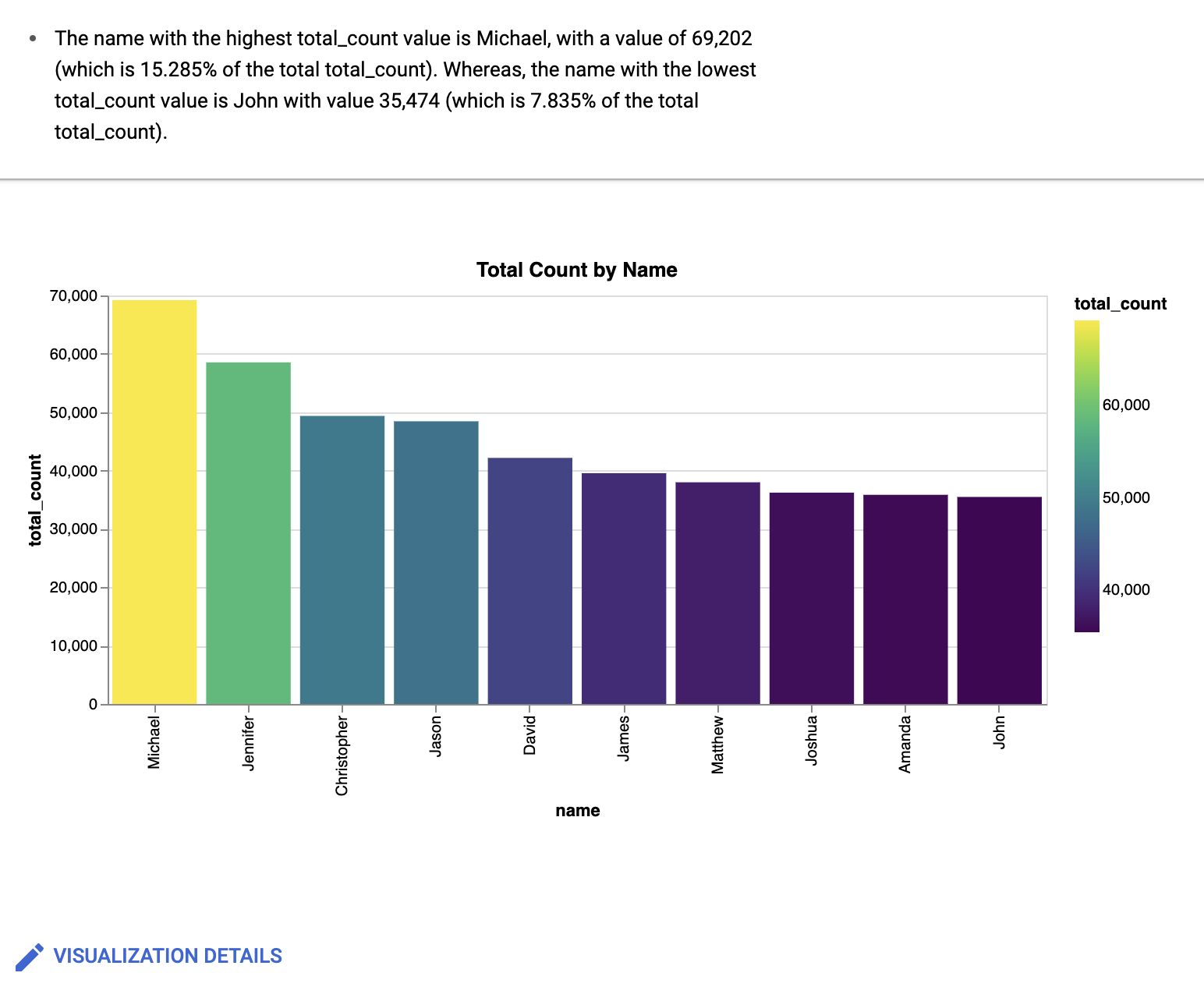
선택사항: 추가로 변경하려면 수정을 클릭합니다.
시각화 수정 창이 표시됩니다. 차트 제목, x축 이름, y축 이름과 같은 세부정보를 수정할 수 있습니다. 또한 JSON 편집기 탭을 클릭하면 JSON 값을 기반으로 차트를 직접 수정할 수 있습니다.
Gemini 어시스턴트 사용하기
Gemini 기반 채팅 환경을 사용하여 BigQuery 데이터 캔버스를 사용할 수 있습니다. 채팅 어시스턴트는 요청에 따라 노드를 만들고, 쿼리를 실행하고, 시각화를 만들 수 있습니다. 어시스턴트가 사용할 테이블을 선택할 수 있으며, 어시스턴트의 동작을 지시하는 안내를 추가할 수 있습니다. 어시스턴트는 신규 또는 기존 데이터 캔버스와 함께 작동합니다.
Gemini 어시스턴트를 사용하려면 다음 단계를 따르세요.
- 어시스턴트를 열려면 데이터 캔버스에서 스파크 데이터 캔버스 어시스턴트 열기를 클릭합니다.
데이터 질문하기 필드에 자연어 프롬프트를 입력합니다(예: 다음 중 하나).
Show me interesting statistics of my data.Make a chart based on my data, sorted high to low.I want to see sample data from my table.
대답에는 요청에 기반한 노드가 포함됩니다. 예를 들어 어시스턴트에게 데이터 차트를 만들어 달라고 요청하면 데이터 캔버스에 시각화 노드가 생성됩니다.
데이터 질문하기 필드를 클릭하면 다음 작업도 할 수 있습니다.
- 데이터를 추가하려면 설정을 클릭합니다.
- 요청 사항을 추가하려면 설정을 클릭합니다.
어시스턴트와 계속 작업하려면 자연어 프롬프트를 추가하세요.
데이터 캔버스로 작업하면서 자연어 프롬프트를 계속 만들 수 있습니다.
데이터 추가
Gemini 채팅 인터페이스를 사용할 때 어시스턴트가 참조할 데이터 세트를 알 수 있도록 데이터를 추가할 수 있습니다. 프롬프트를 실행하기 전에 어시스턴트가 테이블을 선택하라는 메시지를 표시합니다. 어시스턴트 내에서 데이터를 검색할 때 검색 가능한 데이터의 범위를 모든 프로젝트, 별표표시된 프로젝트 또는 현재 프로젝트로 제한할 수 있습니다. 검색에 공개 데이터 세트를 포함할지 여부도 결정할 수 있습니다.
Gemini 어시스턴트에 데이터를 추가하려면 다음 단계를 따르세요.
- 어시스턴트를 열려면 데이터 캔버스에서 스파크 데이터 캔버스 어시스턴트 열기를 클릭합니다.
- 설정을 클릭한 다음 데이터 추가를 클릭합니다.
- 선택사항: 검색 결과를 펼쳐 공개 데이터 세트를 포함하려면 공개 데이터 세트 전환 버튼을 사용 설정으로 클릭합니다.
- 선택사항: 검색 결과의 범위를 다른 프로젝트로 변경하려면 범위 메뉴에서 적절한 프로젝트 옵션을 선택합니다.
- 어시스턴트에 추가할 각 표의 체크박스를 선택합니다.
- 어시스턴트에서 추천하지 않는 테이블을 검색하려면 테이블 검색을 클릭합니다.
- 자연어 프롬프트 필드에 찾고 있는 테이블을 설명하는 프롬프트를 입력한 후 Enter 키를 누릅니다.
- 어시스턴트에 추가할 각 표의 체크박스를 선택한 다음 확인을 클릭합니다.
- 캔버스 어시스턴트 설정 창을 닫습니다.
어시스턴트는 사용자가 선택한 데이터를 기반으로 분석합니다.
안내 설명 추가
Gemini 채팅 인터페이스를 사용할 때 어시스턴트가 어떻게 작동해야 하는지 알 수 있도록 요청 사항을 추가할 수 있습니다. 이러한 안내는 데이터 캔버스 내의 모든 프롬프트에 적용됩니다. 잠재적 지침의 예는 다음과 같습니다.
Visualize trends over time.Chart colors: Red (negative), Green (positive)Domain: USA
어시스턴트에 안내를 추가하려면 다음 단계를 따르세요.
- 어시스턴트를 열려면 데이터 캔버스에서 스파크 데이터 캔버스 어시스턴트 열기를 클릭합니다.
- 설정을 클릭합니다.
- 요청 사항 필드에 어시스턴트의 요청 사항 목록을 추가한 다음 캔버스 어시스턴트 설정 창을 닫습니다.
어시스턴트는 안내를 기억하고 향후 프롬프트에 적용합니다.
Gemini 어시스턴트 권장사항
BigQuery 데이터 캔버스 어시스턴트를 사용할 때 최상의 결과를 얻으려면 다음 권장사항을 따르세요.
구체적이고 명확해야 합니다. 계산, 분석 또는 시각화하려는 내용을 명확하게 설명하세요. 예를 들어
Analyze trip data대신Calculate the average trip duration for trips starting in council district eight라고 말합니다.정확한 데이터 컨텍스트를 보장합니다. 어시스턴트는 사용자가 제공한 데이터로만 작동할 수 있습니다. 관련 테이블과 열이 모두 캔버스에 추가되었는지 확인합니다.
간단하게 시작한 다음 반복하세요. 어시스턴트가 기본 구조와 데이터를 이해할 수 있도록 간단한 질문으로 시작하세요. 예를 들어 먼저
Show total trips by라고 말한 다음subscriber_typeShow total trips by라고 말합니다.subscriber_typeand break down the result bycouncil_district복잡한 질문을 세분화합니다. 여러 단계로 구성된 프로세스의 경우 명확한 부분으로 프롬프트를 명확하게 표현하거나 주요 단계별로 별도의 프롬프트를 사용하는 것이 좋습니다. 예를 들어
First, find the top five busiest stations by trip count. Second, calculate the average trip duration for trips starting from only those top five stations라고 말합니다.계산을 명확하게 명시합니다. 선택한 계산(예:
SUM,MAX,AVERAGE)을 지정합니다. 예를 들어Find the라고 말합니다.MAXtrip duration perbike_id지속적인 컨텍스트와 환경설정을 위해 시스템 안내를 사용하세요. 시스템 안내를 사용하여 모든 프롬프트에 적용되는 정보 규칙과 환경설정을 명시합니다.
캔버스 검토하기 생성된 노드를 항상 검토하여 로직이 요청과 일치하고 결과가 정확한지 확인하세요.
실험 다양한 표현, 세부정보 수준, 프롬프트 구조를 시도하여 어시스턴트가 특정 데이터와 분석 요구사항에 어떻게 반응하는지 알아보세요.
참조 열 이름 가능하면 선택한 데이터의 실제 열 이름을 사용하세요. 예를 들어
Show trips by subscriber type대신Show the count of trips grouped by라고 말합니다.subscriber_typeandstart_station_name
워크플로 예시: Gemini 어시스턴트와 함께 작업하기
이 예시에서는 Gemini 어시스턴트와 함께 자연어 프롬프트를 사용하여 데이터를 찾고, 쿼리하고, 시각화합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 SQL 쿼리 옆에 있는 새로 만들기를 클릭하고 AI 및 지식을 선택한 다음 데이터 캔버스를 클릭합니다.
데이터 검색을 클릭합니다.
filter_list 검색 필터 수정을 클릭한 다음 검색 필터링 창에서 BigQuery 공개 데이터 세트 전환 버튼을 사용 설정으로 클릭합니다.
자연어 프롬프트 필드에 다음 자연어 프롬프트를 입력합니다.
bikeshareBigQuery 데이터 캔버스는 Knowledge Catalog 메타데이터를 기반으로 가능한 테이블 목록을 생성합니다. 여러 테이블을 선택할 수 있습니다.
bigquery-public-data.austin_bikeshare.bikeshare_stations테이블과bigquery-public-data.austin_bikeshare.bikeshare_trips을 선택한 다음 캔버스에 추가를 클릭합니다.선택한 각 테이블의 테이블 노드가 BigQuery 데이터 캔버스에 추가됩니다. 스키마 정보를 보거나 테이블 세부정보를 보거나 데이터를 미리 보려면 테이블 노드에서 다양한 탭을 선택하세요.
어시스턴트를 열려면 데이터 캔버스에서 스파크 데이터 캔버스 어시스턴트 열기를 클릭합니다.
설정을 클릭합니다.
안내 필드에 어시스턴트를 위한 다음 안내를 추가합니다.
Tasks: - Visualize findings with charts - Show many charts per question - Make sure to cover each part via a separate line of reasoning캔버스 어시스턴트 설정 창을 닫습니다.
데이터 질문하기 필드에 다음 자연어 프롬프트를 입력합니다.
Show the number of trips by council district and subscriber type데이터 질문하기 필드에 프롬프트를 계속 입력할 수 있습니다. 다음 자연어 프롬프트를 입력합니다.
What are most popular stations among the top 5 subscriber types최종 프롬프트를 입력합니다.
What station is least used to start and end a trip관련된 프롬프트를 모두 요청하면 캔버스에 어시스턴트에게 제공한 프롬프트와 지침에 따라 관련 질문과 시각화 노드가 채워집니다. 원하는 결과를 얻을 때까지 프롬프트를 계속 입력하거나 기존 프롬프트를 수정합니다.
모든 데이터 캔버스 보기
프로젝트의 모든 데이터 캔버스 목록을 보려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.

왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
탐색기 창에서 데이터 캔버스 옆에 있는 작업 보기를 클릭한 후 다음 중 하나를 수행합니다.
- 현재 탭에서 목록을 열려면 모두 표시를 클릭합니다.
- 목록을 새 탭에서 열려면 모두 표시 > 새 탭을 클릭합니다.
- 분할 탭에서 목록을 열려면 모두 표시 > 분할 탭을 클릭합니다.
데이터 캔버스 메타데이터 보기
데이터 캔버스 메타데이터를 보려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.
탐색기 창에서 프로젝트를 펼치고 데이터 캔버스를 클릭합니다.
메타데이터를 보려는 데이터 캔버스의 이름을 클릭합니다.
세부정보를 클릭하여 사용되는 리전 및 마지막으로 수정된 날짜 등 데이터 캔버스에 대한 정보를 확인합니다.
데이터 캔버스 버전 지원
저장소 내부 또는 외부에서 데이터 캔버스를 만들 수 있습니다. 데이터 캔버스 버전 관리는 데이터 캔버스의 위치에 따라 다르게 처리됩니다.
저장소의 데이터 캔버스 버전 관리
저장소는 BigQuery 또는 서드 파티 제공업체에 있는 Git 저장소입니다. 저장소의 작업공간을 사용하여 데이터 캔버스에서 버전 제어를 실행할 수 있습니다. 자세한 내용은 파일에 버전 제어 사용을 참고하세요.
저장소 외부의 데이터 캔버스 버전 관리
데이터 캔버스의 버전을 보고, 비교하고, 복원할 수 있습니다.
데이터 캔버스 버전 보기 및 비교
데이터 캔버스의 여러 버전을 보고 현재 버전과 비교하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.
탐색기 창에서 프로젝트를 펼치고 데이터 캔버스를 클릭합니다.
버전 기록을 보려는 데이터 캔버스의 이름을 클릭합니다.
버전 기록을 클릭하여 날짜 기준 내림차순으로 정렬된 데이터 캔버스 버전 목록을 확인합니다.
데이터 캔버스 버전 옆에 있는 작업 보기를 클릭한 다음 비교를 클릭합니다. 선택한 데이터 캔버스 버전을 현재 데이터 캔버스 버전과 비교하는 비교 창이 열립니다.
(선택사항): 별도의 창 대신 버전을 인라인 비교하려면 비교를 클릭한 다음 인라인을 클릭합니다.
데이터 캔버스 버전 복원
비교 창에서 복원하면 복원 여부를 선택하기 전에 데이터 캔버스의 이전 버전을 현재 버전과 비교할 수 있습니다.
왼쪽 창에서 탐색기를 클릭합니다.
탐색기 창에서 프로젝트를 펼치고 데이터 캔버스를 클릭합니다.
이전 버전을 복원할 데이터 캔버스의 이름을 클릭합니다.
버전 기록을 클릭합니다.
복원할 데이터 캔버스 버전 옆에 있는 작업 보기를 클릭한 다음 비교를 클릭합니다.
선택한 데이터 캔버스 버전을 가장 최근 데이터 캔버스 버전과 비교하는 비교 창이 열립니다.
비교한 후 이전 데이터 캔버스 버전을 복원하려면 복원을 클릭합니다.
확인을 클릭합니다.
Knowledge Catalog에서 메타데이터 관리
Knowledge Catalog를 사용하면 데이터 캔버스의 메타데이터를 보고 관리할 수 있습니다. 데이터 캔버스는 추가 구성 없이 기본적으로 Knowledge Catalog에서 사용할 수 있습니다.
Knowledge Catalog를 사용하여 모든 BigQuery 위치의 데이터 캔버스를 관리할 수 있습니다. Knowledge Catalog에서 데이터 캔버스를 관리하는 경우 Knowledge Catalog 할당량 및 한도와 Knowledge Catalog 가격 책정이 적용됩니다.
Knowledge Catalog는 데이터 캔버스에서 다음 메타데이터를 자동으로 검색합니다.
- 데이터 애셋 이름
- 데이터 애셋 상위 항목
- 데이터 애셋 위치
- 데이터 애셋 유형
- 해당 Google Cloud 프로젝트
Knowledge Catalog는 데이터 캔버스를 다음 항목 값을 사용해 항목으로 로깅합니다.
- 시스템 항목 그룹
- 데이터 캔버스의 시스템 항목 그룹은
@dataform입니다. Knowledge Catalog에서 데이터 캔버스 항목의 세부정보를 보려면dataform시스템 항목 그룹을 확인해야 합니다. 항목 그룹의 모든 항목 목록을 보는 방법에 관한 안내는 Knowledge Catalog 문서의 항목 그룹 세부정보 보기를 참고하세요. - 시스템 항목 유형
- 데이터 캔버스의 시스템 항목 유형은
dataform-code-asset입니다. 데이터 캔버스의 세부정보를 보려면dataform-code-asset시스템 항목 유형을 확인하고, 관점 기반 필터로 결과를 필터링하고,dataform-code-asset관점 내의type필드를DATA_CANVAS로 설정해야 합니다. 그런 다음 선택한 데이터 캔버스의 항목을 선택합니다. 선택한 항목 유형의 세부정보를 보는 방법에 관한 안내는 Knowledge Catalog 문서의 항목 유형의 세부정보 보기를 참고하세요. 선택한 항목의 세부정보를 보는 방법에 관한 안내는 Knowledge Catalog 문서의 항목 세부정보 보기를 참고하세요. - 시스템 관점 유형
- 데이터 캔버스의 시스템 관점 유형은
dataform-code-asset입니다. 관점으로 데이터 캔버스 항목에 주석을 추가하여 Knowledge Catalog의 데이터 캔버스에 추가 컨텍스트를 제공하려면dataform-code-asset관점 유형을 확인하고 관점 기반 필터로 결과를 필터링한 다음dataform-code-asset관점 내의type필드를DATA_CANVAS로 설정합니다. 관점으로 항목에 주석을 추가하는 방법에 관한 안내는 Knowledge Catalog 문서의 관점 관리 및 메타데이터 보강을 참고하세요. - 유형
- 데이터 캔버스의 유형은
DATA_CANVAS입니다. 이 유형을 사용하면 관점 기반 필터에서aspect:dataplex-types.global.dataform-code-asset.type=DATA_CANVAS쿼리를 사용하여dataform-code-asset시스템 항목 유형 및dataform-code-asset관점 유형의 데이터 캠버스를 필터링할 수 있습니다.
Knowledge Catalog에서 애셋을 검색하는 방법에 관한 안내는 Knowledge Catalog 문서의 Knowledge Catalog에서 데이터 애셋 검색을 참고하세요.
가격 책정
이 기능의 가격 책정에 대한 상세 설명은 BigQuery의 Gemini 가격 책정 개요를 참조하세요.
위치
모든 BigQuery 위치에서 BigQuery 데이터 캔버스를 사용할 수 있습니다. BigQuery의 Gemini에서 데이터를 처리하는 위치에 대해 알아보려면 BigQuery의 Gemini에서 데이터를 처리하는 위치를 참고하세요.
의견 보내기
Google에 의견을 제출하여 BigQuery 데이터 캔버스 제안을 개선할 수 있습니다. 의견을 제공하려면 다음 단계를 따르세요.
- BigQuery 데이터 캔버스 툴바에서 작업 더보기를 클릭한 다음 의견 제출을 클릭합니다.
- 의견이 적용되는 카테고리를 클릭합니다.
- 의견 설명 (필수) 필드에 의견을 입력합니다.
- 선택사항: BigQuery에 데이터 캔버스의 스크린샷을 제공하려면 screenshot_monitor 스크린샷 캡처를 클릭합니다.
- 선택사항: 생성 기록을 제공하려면 Google이 내 생성 기록을 수집하고 내 의견과 함께 제출하도록 허용을 선택합니다.
- 보내기를 클릭합니다.
데이터 공유 설정은 전체 프로젝트에 적용되며 serviceusage.services.enable 및 serviceusage.services.list IAM 권한이 있는 프로젝트 관리자만 이 설정을 설정할 수 있습니다.
이 기능에 대한 직접적인 의견을 제공하려면 datacanvas-feedback@google.com으로 문의하세요.
다음 단계
Gemini 지원으로 쿼리를 작성하는 방법을 알아보세요.
노트북을 만드는 방법 알아보기
데이터 통계를 사용하여 데이터에 대한 자연어 쿼리를 생성하는 방법을 알아보세요.