
במאמר הזה מוסבר איך להעביר את מסד הנתונים ממערכות Oracle® Online Transaction Processing (OLTP) אל Spanner.
ב-Spanner יש מושגים מסוימים ששונים מאלה שבכלי ניהול אחרים של מסדי נתונים לארגונים, ולכן יכול להיות שתצטרכו לשנות את האפליקציה כדי לנצל את כל היכולות של Spanner. יכול להיות שתצטרכו להשתמש בשירותים נוספים של Google Cloud כדי להשלים את Spanner ולענות על הצרכים שלכם.
מגבלות על העברה
כשמעבירים את האפליקציה ל-Spanner, צריך לקחת בחשבון את התכונות השונות שזמינות. כנראה שתצטרכו לתכנן מחדש את ארכיטקטורת האפליקציה כדי שתתאים למערך התכונות של Spanner וכדי לשלב אותה עם Google Cloud שירותים נוספים.
תהליכים מאוחסנים וטריגרים
Spanner לא תומך בהרצת קוד משתמש ברמת מסד הנתונים, ולכן כחלק מההעברה, צריך להעביר את הלוגיקה העסקית שמיושמת על ידי פרוצדורות מאוחסנות וטריגרים ברמת מסד הנתונים אל האפליקציה.
רצפים
מומלץ להשתמש בגרסה 4 של UUID כשיטה שמוגדרת כברירת מחדל ליצירת ערכים של מפתח ראשי.
הפונקציה GENERATE_UUID() (GoogleSQL, PostgreSQL)
מחזירה ערכים של UUID בגרסה 4 כסוג STRING.
אם אתם צריכים ליצור ערכים של מספרים שלמים של 64 ביט, Spanner תומך ברצפים חיוביים של היפוך ביטים (GoogleSQL, PostgreSQL), שמפיקים ערכים שמתפלגים באופן שווה על פני מרחב המספרים החיוביים של 64 ביט. אתם יכולים להשתמש במספרים האלה כדי להימנע מבעיות בשימוש בנקודות גישה אישיות.
מידע נוסף מופיע במאמר בנושא אסטרטגיות של ערכי ברירת מחדל למפתח ראשי.
בקרות גישה
בעזרת הפלטפורמה לניהול זהויות והרשאות גישה (IAM) תוכלו לקבוע את הגישה של משתמשים וקבוצות למשאבי Spanner ברמת הפרויקט, ברמת מופע Spanner וברמת מסד נתונים של Spanner. מידע נוסף זמין במאמר סקירה כללית על IAM.
כדאי לבדוק את מדיניות IAM וליישם אותה בהתאם לעיקרון של מתן ההרשאות המינימליות לכל המשתמשים וחשבונות השירות שיש להם גישה למסד הנתונים. אם האפליקציה דורשת גישה מוגבלת לטבלאות, לעמודות, לתצוגות או לסנכרון שינויים בזרמי נתונים ספציפיים, צריך להטמיע בקרת גישה פרטנית (FGAC). מידע נוסף זמין במאמר סקירה כללית על בקרת גישה ברמת פירוט גבוהה.
מגבלות של אימות נתונים
Spanner יכול לתמוך בקבוצה מוגבלת של אילוצי אימות נתונים בשכבת מסד הנתונים.
אם אתם צריכים אילוצים מורכבים יותר על הנתונים, אתם יכולים להטמיע אותם בשכבת האפליקציה.
בטבלה הבאה מפורטים סוגי האילוצים שנפוצים במסדי נתונים של Oracle®, ואיך מטמיעים אותם ב-Spanner.
| מגבלה | הטמעה באמצעות Spanner |
|---|---|
| לא Null | NOT NULLמגבלת עמודה |
| ייחודי | אינדקס משני עם אילוץ UNIQUE |
| מפתח זר (לטבלאות רגילות) | איך יוצרים ומנהלים קשרים של מפתח זר |
פעולות של מפתח זר ON DELETE/ON UPDATE |
אפשרות זו קיימת רק בטבלאות משולבות, אחרת היא מיושמת בשכבת האפליקציה |
בדיקות ואימות של ערכים באמצעות אילוצים או טריגרים של CHECK
|
ההטמעה מתבצעת בשכבת האפליקציות |
סוגי נתונים נתמכים
מסדי נתונים של Oracle® ו-Spanner תומכים בקבוצות שונות של סוגי נתונים. בטבלה הבאה מפורטים סוגי הנתונים של Oracle והמקבילים שלהם ב-Spanner. הגדרות מפורטות של כל סוג נתונים ב-Spanner זמינות במאמר סוגי נתונים.
יכול להיות שתצטרכו לבצע טרנספורמציות נוספות בנתונים שלכם, כמו שמתואר בעמודה Notes, כדי שהנתונים של Oracle יתאימו למסד הנתונים של Spanner.
לדוגמה, אפשר לאחסן BLOB גדול כאובייקט בקטגוריה של Cloud Storage במקום במסד הנתונים, ואז לאחסן במסד הנתונים את הפניה ל-URI של אובייקט Cloud Storage כ-STRING.
| סוג הנתונים של Oracle | מקבילה ב-Spanner | הערות |
|---|---|---|
סוגי תווים (CHAR, VARCHAR, NCHAR,
NVARCHAR)
|
STRING
|
הערה: ב-Spanner נעשה שימוש במחרוזות Unicode בכל מקום. Oracle תומך באורך מקסימלי של 32,000 בייטים או תווים (בהתאם לסוג), בעוד ש-Spanner תומך בעד 2,621,440 תווים. |
BLOB, LONG RAW, BFILE
|
BYTES או STRING שמכיל את ה-URI של האובייקט.
|
אפשר לאחסן אובייקטים קטנים (פחות מ-10MiB) כ-BYTES.כדאי לשקול להשתמש במוצרים חלופיים Google Cloud כמו Cloud Storage כדי לאחסן אובייקטים גדולים יותר. |
CLOB, NCLOB, LONG
|
STRING (מכיל נתונים או URI לאובייקט חיצוני)
|
אפשר לאחסן אובייקטים קטנים (פחות מ-2,621,440 תווים) בתור STRING. כדאי להשתמש במוצרים חלופיים כמו Cloud Storage כדי לאחסן אובייקטים גדולים יותר. Google Cloud
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
סוג הנתונים NUMBER של Oracle שווה לסוג הנתונים NUMERIC של GoogleSQL. כל אחד מהם תומך ב-38 ספרות של דיוק ובתשע ספרות של קנה מידה: (P,S) = (38,9). סוג הנתונים NUMERIC ב-PostgreSQL מאחסן נתונים מספריים עם דיוק שרירותי.
סוג הנתונים FLOAT64 GoogleSQL תומך בדיוק של עד 16 ספרות. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
ייצוג ברירת המחדל של סוג STRING ב-Spanner DATE הוא yyyy-mm-dd, ששונה מזה של Oracle, לכן צריך להיזהר כשמבצעים המרה אוטומטית לייצוגים של תאריכים ב-STRING ומייצוגים של תאריכים ב-STRING. יש פונקציות SQL להמרת תאריכים למחרוזת בפורמט מסוים.
|
DATETIME
|
TIMESTAMP
|
ב-Spanner, השעה נשמרת בלי קשר לאזור הזמן. אם אתם צריכים לאחסן אזור זמן, אתם צריכים להשתמש בעמודה נפרדת STRING.
יש פונקציות SQL להמרת חותמות זמן למחרוזת מפורמטת באמצעות אזורי זמן.
|
XML
|
STRING (מכיל נתונים או URI לאובייקט חיצוני)
|
אפשר לאחסן אובייקטים קטנים של XML (פחות מ-2,621,440 תווים) בתור STRING. כדאי להשתמש במוצרים חלופיים כמו Cloud Storage כדי לאחסן אובייקטים גדולים יותר. Google Cloud |
URI, DBURI, XDBURI,
HTTPURI
|
STRING
|
|
ROWID
|
PRIMARY KEY
|
מערכת Spanner משתמשת במפתח הראשי של הטבלה כדי למיין שורות ולעיין בהן באופן פנימי, ולכן ב-Spanner הוא זהה למעשה לROWID סוג הנתונים. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
Spanner לא תומך בסוגי נתונים גיאו-מרחביים. תצטרכו לאחסן את הנתונים האלה באמצעות סוגי נתונים רגילים, ולהטמיע את כל הלוגיקה של החיפוש והסינון בשכבת האפליקציה. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
ב-Spanner אין תמיכה בסוגי נתונים של מדיה. כדאי להשתמש ב-Cloud Storage לאחסון נתוני מדיה. |
תהליך ההעברה
ציר זמן כללי של תהליך ההעברה:
- ממירים את הסכימה ואת מודל הנתונים.
- תרגום של שאילתות SQL.
- העברת האפליקציה לשימוש ב-Spanner בנוסף ל-Oracle.
- ייצוא נתונים בכמות גדולה מ-Oracle וייבוא שלהם ל-Spanner באמצעות Dataflow.
- חשוב לשמור על עקביות בין שני מסדי הנתונים במהלך ההעברה.
- להעביר את האפליקציה מ-Oracle.
שלב 1: המרת מסד הנתונים והסכימה
אתם ממירים את הסכימה הקיימת לסכימה של Spanner כדי לאחסן את הנתונים. הסכימה הזו צריכה להיות דומה ככל האפשר לסכימת Oracle הקיימת, כדי לפשט את השינויים באפליקציה. עם זאת, בגלל ההבדלים בתכונות, יהיה צורך לבצע כמה שינויים.
שימוש בשיטות מומלצות לעיצוב סכימה יכול לעזור לכם להגדיל את קצב העברת הנתונים ולצמצם את הנקודות החמות במסד הנתונים של Spanner.
מקש במקלדת הראשית
ב-Spanner, לכל טבלה שצריכה לאחסן יותר משורה אחת צריך להיות מפתח ראשי שמורכב מעמודה אחת או יותר של הטבלה. המפתח הראשי של הטבלה מזהה באופן ייחודי כל שורה בטבלה, והשורות בטבלה ממוינות לפי המפתח הראשי. מכיוון ש-Spanner מבוזר מאוד, חשוב לבחור שיטה ליצירת מפתח ראשי שניתן להרחבה בהתאם לגידול בנתונים. מידע נוסף מופיע במאמר בנושא אסטרטגיות מומלצות להעברת מפתחות ראשיים.
שימו לב: אחרי שמגדירים מפתח ראשי, אי אפשר להוסיף או להסיר עמודה של מפתח ראשי, או לשנות ערך של מפתח ראשי, בלי למחוק את הטבלה וליצור אותה מחדש. מידע נוסף על הגדרת המפתח הראשי זמין במאמר סכימה ומודל נתונים – מפתחות ראשיים.
שילוב של טבלאות
ב-Spanner יש תכונה שמאפשרת להגדיר שני טבלאות כבעלות קשר הורה-צאצא מסוג אחד-לרבים. הפעולה הזו משלבת את שורות הנתונים של הצאצאים עם שורת ההורה באחסון, ובעצם מבצעת מראש את הפעולה join בטבלה ומשפרת את היעילות של אחזור הנתונים כשמבצעים שאילתה על ההורה והצאצאים יחד.
המפתח הראשי של טבלת הצאצא חייב להתחיל עם עמודות המפתח הראשי של טבלת האב. מנקודת המבט של שורת הילד, המפתח הראשי של שורת ההורה נקרא מפתח זר. אפשר להגדיר עד 6 רמות של קשרים בין הורה לצאצא.
אתם יכולים להגדיר פעולות למחיקה בטבלאות צאצא כדי לקבוע מה יקרה כששורת האב תימחק: כל שורות הצאצא יימחקו, או שמחיקת שורת האב תיחסם אם קיימות שורות צאצא.
הנה דוגמה ליצירת טבלת אלבומים שמשולבת בטבלת האבות Singers שהוגדרה קודם:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
יצירת אינדקסים משניים
אפשר גם ליצור אינדקסים משניים כדי ליצור אינדקס לנתונים בטבלה מחוץ למפתח הראשי.
ב-Spanner, אינדקסים משניים מיושמים באותו אופן כמו טבלאות, ולכן ערכי העמודות שמשמשים כמפתחות אינדקס כפופים לאותם אילוצים כמו המפתחות הראשיים של טבלאות. זה גם אומר שהאינדקסים נהנים מאותן ערבויות עקביות כמו טבלאות Spanner.
חיפושי ערכים באמצעות אינדקסים משניים זהים למעשה לשאילתה עם צירוף טבלה. אפשר לשפר את הביצועים של שאילתות באמצעות אינדקסים על ידי אחסון עותקים של ערכי העמודות של הטבלה המקורית באינדקס המשני באמצעות פסוקית STORING, וכך להפוך אותו לאינדקס מכסה.
אופטימיזציית השאילתות של Spanner תשתמש אוטומטית רק באינדקסים משניים אם האינדקס עצמו מאחסן את כל העמודות שמופיעות בשאילתה (שאילתה מכוסה). כדי לכפות שימוש באינדקס כשמריצים שאילתות על עמודות בטבלה המקורית, צריך להשתמש בהוראה FORCE INDEX בהצהרת ה-SQL, למשל:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
אפשר להשתמש באינדקסים כדי לאכוף ערכים ייחודיים בעמודה בטבלה, על ידי הגדרה של אינדקס UNIQUE בעמודה הזו. האינדקס ימנע הוספה של ערכים כפולים.
הנה דוגמה להצהרת DDL שיוצרת אינדקס משני לטבלה Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
שימו לב: אם תיצרו אינדקסים נוספים אחרי שהנתונים ייטענו, יכול להיות שיעבור זמן עד שהאינדקס יאוכלס. מומלץ להגביל את קצב ההוספה שלהם לממוצע של שלושה ביום. למידע נוסף על יצירת אינדקסים משניים, אפשר לעיין במאמר בנושא אינדקסים משניים. מידע נוסף על המגבלות בנוגע ליצירת אינדקסים זמין במאמר עדכוני סכימה.
שלב 2: תרגום של שאילתות SQL
Spanner משתמש בדיאלקט ANSI 2011 של SQL עם הרחבות, ויש לו הרבה פונקציות ואופרטורים שעוזרים לתרגם ולצבור את הנתונים. צריך להמיר את כל שאילתות ה-SQL שמשתמשות בתחביר, בפונקציות ובסוגים שספציפיים ל-Oracle, כדי שהן יהיו תואמות ל-Spanner.
Spanner לא תומך בנתונים מובנים כהגדרות של עמודות, אבל אפשר להשתמש בנתונים מובנים בשאילתות SQL באמצעות סוגי הנתונים ARRAY ו-STRUCT.
לדוגמה, אפשר לכתוב שאילתה שתחזיר את כל האלבומים של אומן מסוים באמצעות ARRAY של STRUCTs בשאילתה אחת (תוך ניצול הנתונים שצורפו מראש).
מידע נוסף זמין בקטע הערות לגבי שאילתות משנה במאמרי העזרה.
אפשר ליצור פרופיל של שאילתות SQL באמצעות הדף Spanner Studio ב Google Cloud Console כדי להריץ את השאילתה. באופן כללי, שאילתות שמבצעות סריקות מלאות של טבלאות גדולות הן יקרות מאוד, ולכן מומלץ להשתמש בהן במשורה.
מידע נוסף על אופטימיזציה של שאילתות SQL זמין במאמר שיטות מומלצות לשימוש ב-SQL.
שלב 3: מעבירים את האפליקציה לשימוש ב-Spanner
Spanner מספק קבוצה של ספריות לקוח בשפות שונות, ואפשרות לקרוא ולכתוב נתונים באמצעות קריאות ל-API ספציפיות ל-Spanner, וגם באמצעות שאילתות SQL והצהרות של שפת שינוי נתונים (DML). יכול להיות ששימוש בקריאות API יהיה מהיר יותר עבור שאילתות מסוימות, כמו קריאות ישירות של שורות לפי מפתח, כי לא צריך לתרגם את הצהרת ה-SQL.
אפשר גם להשתמש במנהל התקן (driver) של Java Database Connectivity (JDBC) כדי להתחבר ל-Spanner, תוך מינוף של כלים ותשתית קיימים שאין להם אינטגרציה מובנית.
במסגרת תהליך ההעברה, צריך להטמיע באפליקציה תכונות שלא זמינות ב-Spanner. לדוגמה, כדי להפעיל טריגר לאימות ערכי נתונים ולעדכון טבלה קשורה, צריך להטמיע את הטריגר באפליקציה באמצעות טרנזקציה של קריאה/כתיבה כדי לקרוא את השורה הקיימת, לאמת את האילוץ ואז לכתוב את השורות המעודכנות בשתי הטבלאות.
רמת הבידוד שמוגדרת כברירת מחדל בעסקאות ב-Spanner היא בידוד ניתן לסידור, שמבטיח עקביות חיצונית של הנתונים. Spanner מציע גם בידוד קריאה חוזרת. מומלץ להגדיר את רמת הבידוד כ'קריאה חוזרת' ואת בקרת בו-זמניות כבקרת בו-זמניות פסימית כחלק מתהליך העברת האפליקציה, כדי שהסמנטיקה של הטרנזקציות ב-Spanner תתאים באופן הדוק לסמנטיקה של טרנזקציות ברירת המחדל ב-Oracle. הוראות להגדרת רמת הבידוד ובקרת הגישה בו-זמנית באפליקציה מופיעות במאמרים שימוש ברמת הבידוד 'קריאה חוזרת' והגדרת בקרת גישה בו-זמנית.
Spanner מציע עסקאות לקריאה ולכתיבה ועסקאות לקריאה בלבד. בנוסף, אפשר להחיל על עסקאות קריאה גבולות של חותמות זמן, שבהם קוראים גרסה עקבית של הנתונים שצוינו בדרכים הבאות:
- בשעה מדויקת בעבר (עד שעה אחת לפני כן).
- בעתיד (הקריאה תיחסם עד שהזמן הזה יגיע).
- עם מידה מקובלת של נתונים לא עדכניים, שתחזיר תצוגה עקבית עד לנקודת זמן מסוימת בעבר, בלי שתצטרכו לבדוק אם נתונים מאוחרים יותר זמינים בעותק אחר. הפעולה הזו יכולה לשפר את הביצועים, אבל עלולה לגרום לנתונים לא עדכניים.
שלב 4: מעבירים את הנתונים מ-Oracle ל-Spanner
כדי להעביר את הנתונים מ-Oracle ל-Spanner, צריך לייצא את מסד הנתונים של Oracle לפורמט קובץ נייד, למשל CSV, ואז לייבא את הנתונים האלה ל-Spanner באמצעות Dataflow.
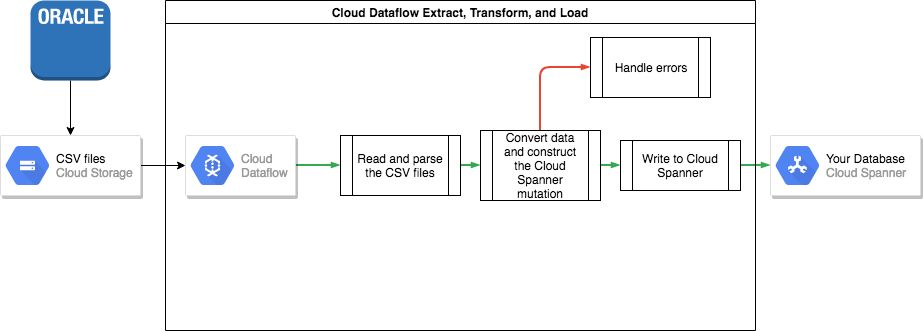
ייצוא בכמות גדולה מ-Oracle
Oracle לא מספקת כלי עזר מובנים לייצוא או להעברה של כל מסד הנתונים לפורמט קובץ נייד.
חלק מהאפשרויות לייצוא מפורטות בשאלות הנפוצות של Oracle.
למשל:
- שימוש ב-SQL*plus או ב-SQLcl כדי להעביר שאילתה לקובץ טקסט.
- כתיבת פונקציית PL/SQL באמצעות UTL_FILE כדי להעביר טבלה במקביל לקובצי טקסט.
- שימוש בתכונות ב-Oracle APEX או ב-Oracle SQL Developer כדי להעביר טבלה לקובץ CSV או קובץ XML.
החיסרון של כל אחת מהשיטות האלה הוא שאפשר לייצא רק טבלה אחת בכל פעם. כלומר, צריך להשהות את האפליקציה או להעביר את מסד הנתונים למצב השבתה כדי שמסד הנתונים יישאר במצב עקבי במהלך הייצוא.
אפשרויות אחרות כוללות כלים של צד שלישי, כמו אלה שמפורטים בדף שאלות נפוצות בנושא Oracle. חלק מהכלים האלה יכולים לבטל טעינה של תצוגה עקבית של כל מסד הנתונים.
אחרי שהם יורדים, צריך להעלות את קובצי הנתונים האלה לקטגוריה ב-Cloud Storage כדי שיהיה אפשר לייבא אותם.
ייבוא בכמות גדולה אל Spanner
יכול להיות שסכימות מסד הנתונים שונות בין Oracle לבין Spanner, ולכן יכול להיות שתצטרכו לבצע המרות נתונים מסוימות כחלק מתהליך הייבוא.
הדרך הקלה ביותר לבצע את המרות הנתונים האלה ולייבא את הנתונים אל Spanner היא באמצעות Dataflow.
Dataflow הוא שירות מבוזר של חילוץ, טרנספורמציה וטעינה (ETL). Google Cloud הוא מספק פלטפורמה להפעלת צינורות נתונים שנכתבו באמצעות Apache Beam SDK כדי לקרוא ולעבד כמויות גדולות של נתונים במקביל בכמה מכונות.
כדי להגדיר קריאה, שינוי וכתיבה של הנתונים, צריך לכתוב תוכנת Java פשוטה ב-Apache Beam SDK. קיימים מחברים של Beam ל-Cloud Storage ול-Spanner, כך שצריך לכתוב רק את הקוד של טרנספורמציית הנתונים עצמה.
דוגמה לצינור פשוט שקורא מקובצי CSV וכותב ל-Spanner מופיעה במאגר קוד לדוגמה שמצורף למאמר הזה.
אם משתמשים בטבלאות משולבות של הורה-צאצא בסכימה של Spanner, צריך להקפיד בתהליך הייבוא על כך שהשורה של ההורה תיווצר לפני השורה של הצאצא. קוד צינור הייבוא של Spanner מטפל בזה על ידי ייבוא כל הנתונים של טבלאות ברמת הבסיס קודם, אחר כך כל טבלאות הצאצא ברמה 1, אחר כך כל טבלאות הצאצא ברמה 2 וכן הלאה.
אפשר להשתמש ישירות בצינור הייבוא של Spanner כדי לייבא את הנתונים בכמות גדולה,אבל בשביל זה הנתונים צריכים להיות בקובצי Avro עם הסכימה הנכונה.
שלב 5: שמירה על עקביות בין שני מסדי הנתונים
באפליקציות רבות יש דרישות זמינות שלא מאפשרות להשאיר את האפליקציה במצב אופליין למשך הזמן שנדרש לייצוא ולייבוא של הנתונים. בזמן שמעבירים את הנתונים ל-Spanner, האפליקציה ממשיכה לשנות את מסד הנתונים הקיים. צריך לשכפל את העדכונים למסד הנתונים של Spanner בזמן שהאפליקציה פועלת.
יש כמה שיטות לסנכרון בין שני מסדי הנתונים, כולל סימון נתונים שהשתנו (CDC) והטמעה של עדכונים בו-זמניים באפליקציה.
סימון נתונים שהשתנו (CDC)
Oracle GoldenGate יכול לספק זרם של לכידת נתונים משתנים (CDC) למסד הנתונים של Oracle. Oracle LogMiner או Oracle XStream Out הן ממשקי חלופיים למסד הנתונים של Oracle לקבלת נתוני CDC שלא כוללים את Oracle GoldenGate.
אתם יכולים לכתוב אפליקציה שנרשמת לאחד מהזרמים האלה ומבצעת את אותם שינויים (אחרי המרת הנתונים, כמובן) במסד הנתונים של Spanner. אפליקציה כזו לעיבוד זרמי נתונים (stream processing) צריכה לכלול כמה תכונות:
- מתחברים למסד הנתונים של Oracle (מסד הנתונים של המקור).
- מתבצעת התחברות ל-Spanner (מסד נתונים יעד).
- ביצוע חוזר של הפעולות הבאות:
- קבלת הנתונים שנוצרו על ידי אחד ממקורות הנתונים של CDC במסד נתונים של Oracle.
- הסבר על הנתונים שנוצרים על ידי מקור הנתונים של CDC.
- המרת הנתונים להצהרות Spanner
INSERT. - מריצים את ההצהרות של Spanner
INSERT.
טכנולוגיה להעברת מסדי נתונים היא טכנולוגיית ביניים שכוללת את התכונות הנדרשות כחלק מהפונקציונליות שלה. פלטפורמת העברת מסדי הנתונים מותקנת כרכיב נפרד במיקום המקור או במיקום היעד, בהתאם לדרישות הלקוח. פלטפורמת העברת מסדי נתונים דורשת רק הגדרת קישוריות של מסדי הנתונים הרלוונטיים כדי לציין ולהתחיל העברת נתונים רציפה ממסד הנתונים של המקור למסד הנתונים של היעד.
Striim היא פלטפורמה טכנולוגית להעברת מסדי נתונים שזמינה ב-Google Cloud. הוא מספק קישוריות לזרמי CDC מ-Oracle GoldenGate, וגם מ-Oracle LogMiner ומ-Oracle XStream Out. Striim מספק כלי גרפי שמאפשר להגדיר קישוריות למסד נתונים וכללי טרנספורמציה שנדרשים כדי להעביר נתונים מ-Oracle ל-Spanner.
אתם יכולים להתקין את Striim מ-Google Cloud Marketplace, להתחבר למסדי הנתונים של המקור והיעד, להטמיע כללי טרנספורמציה ולהתחיל להעביר נתונים בלי שתצטרכו לבנות בעצמכם אפליקציה לעיבוד זרמי נתונים (stream processing).
עדכונים בו-זמניים לשני מסדי הנתונים מהאפליקציה
שיטה חלופית היא לשנות את האפליקציה כך שתבצע פעולות כתיבה בשני בסיסי הנתונים. מסד נתונים אחד (בשלב הראשון Oracle) ייחשב כמקור האמת, ואחרי כל כתיבה למסד הנתונים, השורה כולה תיקרא, תומר ותיכתב למסד הנתונים של Spanner.
כך האפליקציה דורסת כל הזמן את השורות ב-Spanner עם הנתונים העדכניים ביותר.
אחרי שמוודאים שכל הנתונים הועברו בצורה נכונה, אפשר להגדיר את מסד הנתונים של Spanner כמקור האמת.
המנגנון הזה מספק דרך לחזור אחורה אם מתגלות בעיות כשעוברים ל-Spanner.
אימות עקביות הנתונים
בזמן שהנתונים מוזרמים למסד הנתונים של Spanner, אפשר להריץ השוואה בין הנתונים ב-Spanner לבין הנתונים ב-Oracle באופן תקופתי כדי לוודא שהנתונים עקביים.
כדי לוודא שהנתונים עקביים, אפשר להריץ שאילתה בשני מקורות הנתונים ולהשוות את התוצאות.
אפשר להשתמש ב-Dataflow כדי לבצע השוואה מפורטת של מערכי נתונים גדולים באמצעות הטרנספורמציה Join. הטרנספורמציה הזו מקבלת 2 מערכי נתונים עם מפתחות, ומתאימה את הערכים לפי המפתח. אחר כך אפשר להשוות בין הערכים התואמים כדי לבדוק אם הם שווים.
אתם יכולים להפעיל את האימות הזה באופן קבוע עד שרמת העקביות תתאים לדרישות העסק שלכם.
שלב 6: מעבר ל-Spanner כמקור המידע המהימן של האפליקציה
אחרי שתוודאו שהנתונים הועברו בצורה תקינה, תוכלו להגדיר את Spanner כמקור המהימן של הנתונים באפליקציה. ממשיכים לכתוב בחזרה שינויים במסד הנתונים של Oracle כדי לשמור על עדכניות של מסד הנתונים של Oracle, וכך יש לכם אפשרות לבטל את השינויים אם מתעוררות בעיות.
לבסוף, אפשר להשבית ולהסיר את קוד העדכון של מסד הנתונים של Oracle ולסגור את מסד הנתונים של Oracle.
ייצוא וייבוא של מסדי נתונים ב-Spanner
אפשר גם לייצא את הטבלאות מ-Spanner לקטגוריה של Cloud Storage באמצעות תבנית Dataflow. התיקייה שמתקבלת מכילה קבוצה של קובצי Avro וקובצי מניפסט JSON שמכילים את הטבלאות שייצאתם. אפשר להשתמש בקבצים האלה למטרות שונות, כולל:
- גיבוי מסד הנתונים לצורך עמידה במדיניות שמירת הנתונים או לצורך התאוששות מאסון.
- ייבוא קובץ ה-Avro למוצרים אחרים Google Cloud כמו BigQuery.
מידע נוסף על תהליך הייצוא והייבוא זמין במאמרים בנושא ייצוא מסדי נתונים וייבוא מסדי נתונים.
המאמרים הבאים
- מידע נוסף על אופטימיזציה של סכימת Spanner
- במקרים מורכבים יותר, אפשר להשתמש ב-Dataflow.