
טכנולוגיות האחסון של Google מפעילות חלק מהאפליקציות הגדולות בעולם. עם זאת, לא תמיד אפשר להשיג הגדלה אוטומטית באמצעות המערכות האלה. מעצבים צריכים לחשוב היטב על האופן שבו הם מעצבים את הנתונים שלהם כדי לוודא שהאפליקציה שלהם יכולה להתרחב ולפעול ככל שהיא גדלה בממדים שונים.
Spanner הוא מסד נתונים מבוזר, והשימוש בו בצורה יעילה מחייב חשיבה שונה לגבי עיצוב הסכימה ודפוסי הגישה, בהשוואה למסדי נתונים אחרים. מערכות מבוזרות, מעצם טבען, מחייבות את המעצבים לחשוב על נתונים ועל עיבוד מקומי.
Spanner תומך בשאילתות SQL ובעסקאות עם יכולת של הרחבה אופקית. לרוב נדרש תכנון קפדני כדי לממש את היתרונות המלאים של Spanner. במאמר הזה נסביר כמה מהרעיונות המרכזיים שיעזרו לכם לוודא שהאפליקציה שלכם יכולה להתרחב לרמות שרירותיות ולמקסם את הביצועים שלה. יש שני כלים ספציפיים שמשפיעים מאוד על יכולת ההרחבה: הגדרת מפתח וערבוב.
פריסת טבלה
השורות בטבלת Spanner מאורגנות בסדר לקסיקוגרפי לפי PRIMARY KEY. מבחינה מושגית, המפתחות מסודרים לפי שרשור העמודות בסדר שבו הן מוצהרות בסעיף PRIMARY KEY. התופעה הזו מציגה את כל המאפיינים הרגילים של מקומיות:
- סריקה של הטבלה בסדר לקסיקוגרפי היא יעילה.
- שורות קרובות מספיק יאוחסנו באותם בלוקים בדיסק, וייקראו ויאוחסנו במטמון יחד.
Spanner יוצר רפליקות של הנתונים שלכם בכמה אזורים כדי להבטיח זמינות וקנה מידה. כל אזור מכיל עותק מלא של הנתונים שלכם. כשמבצעים הקצאה של צומת של מופע Spanner, מציינים את קיבולת החישוב שלו. קיבולת המחשוב היא כמות משאבי המחשוב שהוקצו למופע בכל אחד מהתחומים האלה. כל רפליקה היא קבוצה מלאה של הנתונים שלכם, אבל הנתונים בתוך הרפליקה מחולקים למחיצות בין משאבי המחשוב באותו אזור.
הנתונים בכל עותק של Spanner מאורגנים בשתי רמות של היררכיה פיזית: פיצולים של מסדי נתונים ואז בלוקים. פיצולים מכילים טווחים רציפים של שורות, והם היחידה שבאמצעותה Spanner מפזר את מסד הנתונים שלכם בין משאבי המחשוב. עם הזמן, יכול להיות שהפיצולים יחולקו לחלקים קטנים יותר, ימוזגו או יועברו לצמתים אחרים במופע כדי להגדיל את המקביליות ולאפשר לאפליקציה להתרחב. פעולות שמתבצעות על פני פיצולים עולות יותר מפעולות מקבילות שלא מתבצעות על פני פיצולים, בגלל התקשורת המוגברת. זה נכון גם אם הפיצולים האלה מוגשים על ידי אותו צומת.
יש שני סוגים של טבלאות ב-Spanner: טבלאות בסיס (לפעמים נקראות טבלאות ברמה העליונה) וטבלאות משולבות. כדי להגדיר טבלאות משולבות, מציינים טבלה אחרת כטבלת ההורה שלה. כך השורות בטבלה המשולבת מקובצות עם שורת ההורה. לטבלאות בסיס אין הורה, וכל שורה בטבלת בסיס מגדירה שורה חדשה ברמה העליונה, או שורה ראשית. שורות שמשולבות בשורת הבסיס הזו נקראות שורות צאצא, והאוסף של שורת בסיס בתוספת כל הצאצאים שלה נקרא עץ שורות. לפני שמוסיפים שורות צאצא, צריך לוודא שקיימת שורת הורה. שורת ההורה יכולה כבר להיות קיימת במסד הנתונים, או שאפשר להוסיף אותה לפני הוספת שורות הצאצא באותה טרנזקציה.
מערכת Spanner מפצלת מחיצות באופן אוטומטי כשהיא קובעת שזה נחוץ בגלל הגודל או העומס. כדי לשמור על מיקום הנתונים, מערכת Spanner מעדיפה להוסיף גבולות פיצול קרוב ככל האפשר לטבלאות הבסיס, כדי שכל עץ שורות יישמר בפיצול יחיד. המשמעות היא שפעולות בתוך עץ שורות נוטות להיות יעילות יותר, כי סביר להניח שהן לא ידרשו תקשורת עם פיצולים אחרים.
עם זאת, אם יש נקודה חמה בשורה צאצא, Spanner ינסה להוסיף גבולות פיצול לטבלאות משולבות כדי לבודד את השורה של הנקודה החמה, יחד עם כל שורות הצאצא שמתחתיה.
בחירת הטבלאות שיהיו טבלאות בסיס היא החלטה חשובה בתכנון האפליקציה לצורך התאמה להיקף השימוש. בדרך כלל, שורשי הנתונים הם דברים כמו משתמשים, חשבונות, פרויקטים וכדומה, ובטבלאות הצאצא שלהם נמצא רוב הנתונים האחרים על הישות הרלוונטית.
המלצות:
- כדי לשפר את הלוקאליות, כדאי להשתמש בקידומת מפתח משותפת לשורות קשורות באותה טבלה.
- כדאי לשלב נתונים קשורים בטבלה אחרת כשזה הגיוני.
הפשרות שצריך לעשות כשמתמקדים במקומיות
אם נתונים נכתבים או נקראים יחד לעיתים קרובות, אפשר לשפר את זמן האחזור ואת קצב העברת הנתונים על ידי קיבוץ שלהם, בחירה מדוקדקת של מפתחות ראשיים ושימוש בשילוב. הסיבה לכך היא שיש עלות קבועה לתקשורת עם כל שרת או בלוק דיסק, אז למה לא להפיק את המרב מהזמן הזה? בנוסף, ככל שתתקשרו עם יותר שרתים, כך יגדל הסיכוי שתיתקלו בשרת עמוס באופן זמני, והדבר יוביל לעלייה בערכי השהייה (latency) של הזנב. לבסוף, לעסקאות שמתפרסות על פני פיצולים, למרות שהן אוטומטיות ושקופות ב-Spanner, יש עלות מעבד וזמן אחזור גבוהים יותר בגלל האופי המבוזר של אישור דו-שלבי.
מצד שני, אם הנתונים קשורים אבל לא ניגשים אליהם יחד לעיתים קרובות, כדאי להפריד אותם. היתרון הכי גדול של האפשרות הזו הוא כשמדובר בנתונים גדולים שלא ניגשים אליהם לעיתים קרובות. לדוגמה, הרבה מסדי נתונים מאחסנים נתונים בינאריים גדולים מחוץ לפס, בנפרד מנתוני השורה העיקריים, ומשלבים רק הפניות לנתונים הגדולים.
הערה: בבסיס נתונים מבוזר, אי אפשר להימנע מפעולות נתונים לא מקומיות ומפעולות אישור דו-שלבי ברמה מסוימת. אל תנסו ליצור סיפור מושלם של רשות מוניציפאלית לכל פעולה תפעולית. כדאי להתמקד בהשגת המיקום הרצוי לישויות השורש החשובות ביותר ולדפוסי הגישה הנפוצים ביותר, ולאפשר לפעולות מבוזרות שהן פחות תדירות או פחות רגישות לביצועים לקרות כשצריך. התכונות 'אישור דו-שלבי' ו'קריאות מבוזרות' נועדו לפשט את הסכימות ולהקל על עבודת התכנות. בכל תרחישי השימוש, למעט אלה שבהם הביצועים הם קריטיים, עדיף להשתמש בהן.
המלצות:
- ארגון הנתונים בהיררכיות כך שנתונים שנקראים או נכתבים יחד יהיו קרובים זה לזה.
- אם העמודות הגדולות לא נגישות לעיתים קרובות, כדאי לאחסן אותן בטבלאות לא משולבות.
אפשרויות לסימון השעות
אינדקסים משניים מאפשרים למצוא במהירות שורות לפי ערכים שאינם המפתח הראשי. Spanner תומך באינדקסים לא משולבים ובאינדקסים משולבים. אינדקסים לא משולבים הם ברירת המחדל והסוג הכי דומה למה שנתמך בRDBMS אחרים. הן לא מטילות הגבלות על העמודות שמתווספות לאינדקס, ולמרות שהן יעילות, הן לא תמיד הבחירה הטובה ביותר. צריך להגדיר אינדקסים משולבים על עמודות שחולקות קידומת עם טבלת האב, והם מאפשרים שליטה טובה יותר במיקום.
נתוני אינדקס מאוחסנים ב-Spanner באותו אופן שבו מאוחסנות טבלאות, עם שורה אחת לכל רשומה באינדקס. הרבה מהשיקולים לעיצוב טבלאות רלוונטיים גם לאינדקסים. אינדקסים לא משולבים מאחסנים נתונים בטבלאות הבסיס. מכיוון שאפשר לפצל טבלאות בסיס בין כל שורת בסיס, זה מבטיח שאפשר להרחיב אינדקסים לא משולבים לגודל שרירותי, וכמעט לכל עומס עבודה (למעט נקודות חמות). לצערנו, המשמעות היא גם שערכי האינדקס בדרך כלל לא נמצאים באותם פיצולים כמו הנתונים העיקריים. הפעולה הזו יוצרת עבודה נוספת וחביון לכל תהליך כתיבה, ומוסיפה פיצולים נוספים שצריך להתייחס אליהם בזמן הקריאה.
לעומת זאת, אינדקסים משולבים מאחסנים נתונים בטבלאות משולבות. הם מתאימים כשמחפשים בתוך הדומיין של ישות אחת. אינדקסים משולבים מאלצים את הנתונים ואת רשומות האינדקס להישאר באותו עץ שורות, וכך הצירופים ביניהם יעילים הרבה יותר. דוגמאות לשימושים באינדקס משולב:
- גישה לתמונות לפי סדרי מיון שונים, כמו תאריך הצילום, תאריך השינוי האחרון, שם, אלבום וכו'.
- למצוא את כל הפוסטים עם קבוצה מסוימת של תגים.
- איך מוצאים הזמנות קודמות משופינג שכללו פריט מסוים.
המלצות:
- כדאי להשתמש באינדקסים לא משולבים כשצריך למצוא שורות מכל מקום במסד הנתונים.
- מומלץ להשתמש באינדקסים משולבים בכל פעם שהחיפושים מוגבלים לישות אחת.
STORING index clause
אינדקסים משניים מאפשרים למצוא שורות לפי מאפיינים שאינם המפתח הראשי. אם כל הנתונים המבוקשים נמצאים באינדקס עצמו, אפשר לעיין בו בלי לקרוא את הרשומה הראשית. כך אפשר לחסוך משאבים משמעותיים כי לא נדרש איחוד.
לצערנו, מספר מפתחות האינדקס מוגבל ל-16 וגודלם הכולל מוגבל ל-8KiB, ולכן יש מגבלות על מה שאפשר להכניס בהם. כדי לפצות על המגבלות האלה, ל-Spanner יש אפשרות לאחסן נתונים נוספים בכל אינדקס באמצעות סעיף STORING. STORING עמודה באינדקס גורמת לשכפול הערכים שלה, ועוד עותק נשמר באינדקס. אפשר לחשוב על אינדקס עם STORING כעל תצוגה חומרית פשוטה של טבלה אחת (תצוגות לא נתמכות באופן מובנה ב-Spanner בשלב הזה).
שימוש מועיל נוסף ב-STORING הוא כחלק מאינדקס NULL_FILTERED.
כך תוכלו להגדיר תצוגה חומרית של קבוצת משנה דלילה של טבלה, שאפשר לסרוק ביעילות. לדוגמה, אתם יכולים ליצור אינדקס כזה בעמודה is_unread של תיבת דואר כדי להציג את ההודעות שלא נקראו בסריקה של טבלה אחת, בלי לשלם על עותק מלא של כל תיבת דואר.
המלצות:
- מומלץ להשתמש ב-
STORINGבצורה מושכלת כדי לאזן בין ביצועי זמן הקריאה לבין גודל האחסון וביצועי זמן הכתיבה. - אפשר להשתמש ב-
NULL_FILTEREDכדי לשלוט בעלויות האחסון של אינדקסים דלילים.
אנטי-דפוסים
אנטי-תבנית: סדר חותמות הזמן
מעצבי סכימות רבים נוטים להגדיר טבלת בסיס שמסודרת לפי חותמת זמן ומתעדכנת בכל כתיבה. לצערנו, זו אחת מהפעולות הכי פחות ניתנות להרחבה שאפשר לבצע. הסיבה לכך היא שהעיצוב הזה יוצר נקודה חמה גדולה בסוף הטבלה, שקשה לצמצם. ככל ששיעורי הכתיבה עולים, כך גם מספר ה-RPC לפיצול יחיד, וגם אירועי התנגשות נעילה ובעיות אחרות. לרוב, בעיות כאלה לא מופיעות בבדיקות עומס קטנות, אלא אחרי שהאפליקציה נמצאת בייצור במשך זמן מה. בשלב הזה, כבר מאוחר מדי!
אם האפליקציה שלכם חייבת לכלול יומן שבו חותמות הזמן מסודרות, כדאי לשקול אם אפשר להפוך את היומן למקומי על ידי שילוב שלו באחת מטבלאות הבסיס האחרות. היתרון בכך הוא שהאזור החם מתפרס על פני הרבה שורשים. אבל עדיין צריך לוודא שלכל שורש ייחודי יש קצב כתיבה נמוך מספיק.
אם אתם צריכים טבלה גלובלית (חוצת-שורש) עם חותמות זמן מסודרות, ואתם צריכים לתמוך בשיעורי כתיבה גבוהים יותר לטבלה הזו מאשר מה שצומת יחיד יכול לספק, השתמשו בפיצול (sharding) ברמת האפליקציה. חלוקת טבלה (Sharding) היא חלוקה שלה למספר N של חלקים שווים בערך שנקראים Shards. בדרך כלל עושים את זה על ידי הוספת עמודה ShardId עם ערכים שלמים בין [0, N) לפני המפתח הראשי המקורי. בדרך כלל, ה-ShardId לכתיבה נתונה נבחר באופן אקראי או על ידי גיבוב של חלק ממפתח הבסיס. לרוב עדיף להשתמש בגיבוב (hashing) כי אפשר להשתמש בו כדי לוודא שכל הרשומות מסוג מסוים יועברו לאותו שבר, וכך לשפר את הביצועים של השליפה. בכל מקרה, המטרה היא לוודא שלאורך זמן, פעולות הכתיבה יתבצעו באופן שווה בכל השברים.
הגישה הזו אומרת לפעמים שצריך לסרוק את כל הרסיסים כדי לשחזר את הסדר הכולל המקורי של פעולות הכתיבה.
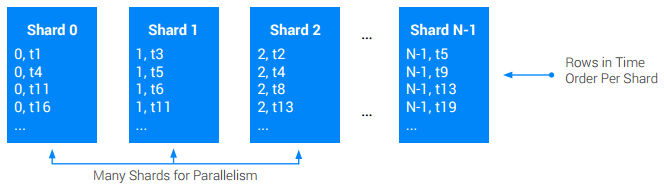
המלצות:
- בכל מחיר, כדאי להימנע מטבלאות ומאינדקסים עם חותמות זמן שבהם קצב הכתיבה גבוה.
- כדאי להשתמש בטכניקה כלשהי כדי לפזר את הנקודות הפעילות, למשל שילוב בטבלה אחרת או חלוקה לשברים.
אנטי-תבנית: רצפים
מפתחי אפליקציות אוהבים להשתמש ברצפים של מסדי נתונים (או בהגדלה אוטומטית) כדי ליצור מפתחות ראשיים. למרבה הצער, ההרגל הזה מימי ה-RDBMS (שנקרא מפתחות סרוגייט) כמעט מזיק כמו האנטי-תבנית של סידור לפי חותמת זמן שמתוארת למעלה. הסיבה לכך היא שרצפים במסד נתונים נוטים להפיק ערכים באופן כמעט מונוטוני לאורך זמן, וכך נוצרים ערכים שמקובצים זה ליד זה. בדרך כלל, כשמשתמשים במזהים האלה כמפתחות ראשיים, נוצרים אזורים חמים, במיוחד בשורות הבסיס.
בניגוד למה שמקובל במערכות RDBMS, אנחנו ממליצים להשתמש במאפיינים מהעולם האמיתי כמפתחות ראשיים, בכל מקרה שזה הגיוני. זה נכון במיוחד אם המאפיין לא ישתנה לעולם.
אם רוצים ליצור מפתחות ראשיים מספריים ייחודיים, כדאי לשאוף לכך שהביטים בסדר גבוה של מספרים עוקבים יתפלגו באופן שווה בערך על פני כל מרחב המספרים. טריק אחד הוא ליצור מספרים עוקבים באמצעים רגילים, ואז לבצע היפוך ביטים כדי לקבל ערך סופי. אפשרות אחרת היא להשתמש בגנרטור של UUID, אבל צריך להיזהר: לא כל פונקציות ה-UUID זהות, וחלקן שומרות את חותמת הזמן בביטים הגבוהים, מה שמבטל את היתרון. מוודאים שמחולל ה-UUID בוחר באופן פסאודו-אקראי ביטים מסדר גבוה.
המלצות:
- לא מומלץ להשתמש בערכים של רצפים מצטברים כמפתחות ראשיים. במקום זאת, צריך להפוך את סדר הביטים של ערך רצף, או להשתמש ב-UUID שנבחר בקפידה.
- עדיף להשתמש בערכים מהעולם האמיתי למפתחות ראשיים במקום במפתחות תחליפיים.