
בדף הזה מוסבר איך להכין קובצי Avro שייצאתם ממסדי נתונים שאינם Spanner, ואז לייבא את הקבצים האלה אל Spanner. ההוראות האלה כוללות מידע על מסדי נתונים של GoogleSQL ועל מסדי נתונים של PostgreSQL. אם רוצים לייבא מסד נתונים של Spanner שייצאתם בעבר, אפשר לעיין במאמר בנושא ייבוא קובצי Avro של Spanner.
התהליך משתמש ב-Dataflow. הוא מייבא נתונים מקטגוריה של Cloud Storage שמכילה קבוצה של קובצי Avro וקובץ מניפסט JSON שמציין את טבלאות היעד ואת קובצי Avro שמאכלסים כל טבלה.
לפני שמתחילים
כדי לייבא מסד נתונים של Spanner, צריך קודם להפעיל את ממשקי ה-API של Spanner, Cloud Storage, Compute Engine ו-Dataflow:
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאה serviceusage.services.enable. איך מקצים תפקידים
צריך גם מכסה מספקת והרשאות IAM נדרשות.
דרישות מכסה
הדרישות לגבי מכסות עבור עבודות ייבוא הן:
- Spanner: צריכה להיות לכם קיבולת מחשוב מספקת כדי לתמוך בכמות הנתונים שאתם מייבאים. לא נדרשת קיבולת חישוב נוספת כדי לייבא מסד נתונים, אבל יכול להיות שתצטרכו להוסיף קיבולת חישוב כדי שהעבודה תסתיים תוך זמן סביר. פרטים נוספים מופיעים במאמר בנושא אופטימיזציה של משימות.
- Cloud Storage: כדי לייבא, צריך קטגוריה שמכילה את הקבצים שיוצאו קודם. אין צורך להגדיר גודל לקטגוריה.
- Dataflow: מכסות Compute Engine של כתובות IP, שימוש בדיסק ומעבדים חלות על משימות ייבוא בדיוק כמו על משימות אחרות של Dataflow.
Compute Engine: לפני שמריצים את עבודת הייבוא, צריך להגדיר מכסות ראשוניות ל-Compute Engine, שמשמש את Dataflow. המכסות האלה מייצגות את המספר המקסימלי של משאבים שאתם מאפשרים ל-Dataflow להשתמש בהם עבור העבודה שלכם. ערכי התחלה מומלצים:
- מעבדים: 200
- כתובות IP בשימוש: 200
- Standard persistent disk: 50 TB
בדרך כלל, לא צריך לבצע התאמות נוספות. Dataflow מספקת התאמה אוטומטית של המשאבים לעומס (autoscaling), כך שמשלמים רק על המשאבים בפועל שנעשה בהם שימוש במהלך הייבוא. אם העבודה יכולה להשתמש ביותר משאבים, בממשק המשתמש של Dataflow מוצג סמל אזהרה. העבודה אמורה להסתיים גם אם מופיע סמל אזהרה.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות לייצוא מסד נתונים, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים בחשבון השירות של העובד ב-Dataflow:
- Cloud Spanner Viewer (
roles/spanner.viewer) - Dataflow Worker (
roles/dataflow.worker) - אדמין באחסון (
roles/storage.admin) - קריאה במסד נתונים של Spanner (
roles/spanner.databaseReader) - אדמין מסד נתונים (
roles/spanner.databaseAdmin)
ייצוא נתונים ממסד נתונים שאינו Spanner לקובצי Avro
תהליך הייבוא מביא נתונים מקובצי Avro שנמצאים בקטגוריה של Cloud Storage. אפשר לייצא נתונים בפורמט Avro מכל מקור, וניתן להשתמש בכל שיטה זמינה כדי לעשות זאת.
כדי לייצא נתונים ממסד נתונים שאינו Spanner לקובצי Avro, פועלים לפי השלבים הבאים:
כשמייצאים את הנתונים, חשוב לזכור את הנקודות הבאות:
- אפשר לייצא באמצעות כל אחד מהסוגים הפרימיטיביים של Avro, וגם באמצעות הסוג המורכב array.
כל עמודה בקובצי Avro חייבת להשתמש באחד מסוגי העמודות הבאים:
ARRAYBOOLBYTES*DOUBLEFLOATINTLONG†STRING‡
* בעמודה מסוג
BYTESמשתמשים כדי לייבאNUMERICשל Spanner. פרטים נוספים זמינים בקטע מיפויים מומלצים בהמשך.†,‡ אפשר לייבא
LONGעם חותמת זמן אוSTRINGעם חותמת זמן כ-SpannerTIMESTAMP. פרטים נוספים זמינים בקטע מיפויים מומלצים בהמשך.לא צריך לכלול או ליצור מטא-נתונים כשמייצאים את קובצי Avro.
אין צורך להקפיד על מוסכמת מתן שמות מסוימת לקבצים.
אם לא מייצאים את הקבצים ישירות ל-Cloud Storage, צריך להעלות את קובצי ה-Avro לקטגוריה של Cloud Storage. הוראות מפורטות זמינות במאמר בנושא העלאת אובייקטים ל-Cloud Storage.
ייבוא קובצי Avro ממסדי נתונים שאינם Spanner אל Spanner
כדי לייבא קובצי Avro ממסד נתונים שאינו Spanner אל Spanner, פועלים לפי השלבים הבאים:
- יוצרים טבלאות יעד ומגדירים את הסכימה של מסד הנתונים ב-Spanner.
- יוצרים קובץ
spanner-export.jsonבקטגוריה של Cloud Storage. - מריצים משימת ייבוא של Dataflow באמצעות ה-CLI של gcloud.
שלב 1: יוצרים את הסכימה של מסד הנתונים ב-Spanner
לפני שמריצים את הייבוא, צריך ליצור את טבלת היעד ב-Spanner ולהגדיר את הסכימה שלה.
צריך ליצור סכימה שבה לכל עמודה בקובצי Avro מוגדר סוג העמודה המתאים.
מיפויים מומלצים
GoogleSQL
| סוג העמודה ב-Avro | סוג העמודה ב-Spanner |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOL |
BYTES |
|
DOUBLE |
FLOAT64 |
FLOAT |
FLOAT64 |
INT |
INT64 |
LONG |
|
STRING |
|
PostgreSQL
| סוג העמודה ב-Avro | סוג העמודה ב-Spanner |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOLEAN |
BYTES |
|
DOUBLE |
DOUBLE PRECISION |
FLOAT |
DOUBLE PRECISION |
INT |
BIGINT |
LONG |
|
STRING |
|
שלב 2: יוצרים קובץ spanner-export.json
בנוסף, צריך ליצור קובץ בשם spanner-export.json בקטגוריה של Cloud Storage. הקובץ הזה מציין את הדיאלקט של מסד הנתונים ומכיל מערך tables שמפרט את השם והמיקומים של קובצי הנתונים לכל טבלה.
התוכן של הקובץ הוא בפורמט הבא:
{ "tables": [ { "name": "TABLE1", "dataFiles": [ "RELATIVE/PATH/TO/TABLE1_FILE1", "RELATIVE/PATH/TO/TABLE1_FILE2" ] }, { "name": "TABLE2", "dataFiles": ["RELATIVE/PATH/TO/TABLE2_FILE1"] } ], "dialect":"DATABASE_DIALECT" }
כאשר DATABASE_DIALECT = {GOOGLE_STANDARD_SQL | POSTGRESQL}
אם לא מציינים את רכיב הדיאלקט, ברירת המחדל של הדיאלקט היא GOOGLE_STANDARD_SQL.
שלב 3: מריצים משימת ייבוא של Dataflow באמצעות ה-CLI של gcloud
כדי להתחיל את עבודת הייבוא, פועלים לפי ההוראות לשימוש ב-Google Cloud CLI כדי להריץ עבודה עם התבנית Avro ל-Spanner.
אחרי שמתחילים משימת ייבוא, אפשר לראות פרטים על המשימה במסוף Google Cloud .
אחרי שמשימת הייבוא מסתיימת, מוסיפים את כל האינדקסים המשניים והמפתחות הזרים שנדרשים.
בחירת אזור למשימת הייבוא
אולי כדאי לבחור אזור אחר בהתאם למיקום של קטגוריית Cloud Storage. כדי להימנע מחיובים על העברת נתונים יוצאים, בוחרים אזור שמתאים למיקום של קטגוריית Cloud Storage.
אם המיקום של הקטגוריה ב-Cloud Storage הוא אזור, תוכלו ליהנות משימוש חינמי ברשת אם תבחרו את אותו אזור למשימת הייבוא, בהנחה שהאזור הזה זמין.
אם המיקום של הקטגוריה של Cloud Storage הוא בשני אזורים, אתם יכולים ליהנות משימוש חופשי ברשת אם תבחרו אחד משני האזורים שמרכיבים את שני האזורים עבור עבודת הייבוא, בהנחה שאחד מהאזורים זמין.
- אם אזור שממוקם באותו מקום לא זמין לעבודת הייבוא, או אם המיקום של קטגוריה של Cloud Storage הוא במספר אזורים, יחולו חיובים על העברת נתונים יוצאת. כדי לבחור אזור שבו עלויות העברת הנתונים הן הכי נמוכות, אפשר לעיין בתמחור של העברת נתונים ב-Cloud Storage.
הצגה או פתרון בעיות של משימות בממשק המשתמש של Dataflow
אחרי שמתחילים משימת ייבוא, אפשר לראות את פרטי המשימה, כולל יומנים, בקטע Dataflow במסוף Google Cloud .
הצגת פרטי משימות ב-Dataflow
כדי לראות פרטים של משימות ייבוא או ייצוא שהפעלתם בשבוע האחרון, כולל משימות שפועלות כרגע:
- עוברים לדף סקירה כללית של מסד הנתונים של מסד הנתונים.
- לוחצים על ייבוא/ייצוא בתפריט שבחלונית הימנית. בדף ייבוא/ייצוא של מסד הנתונים מוצגת רשימה של משימות אחרונות.
בדף ייבוא/ייצוא של מסד הנתונים, לוחצים על שם המשימה בעמודה שם משימת Dataflow:
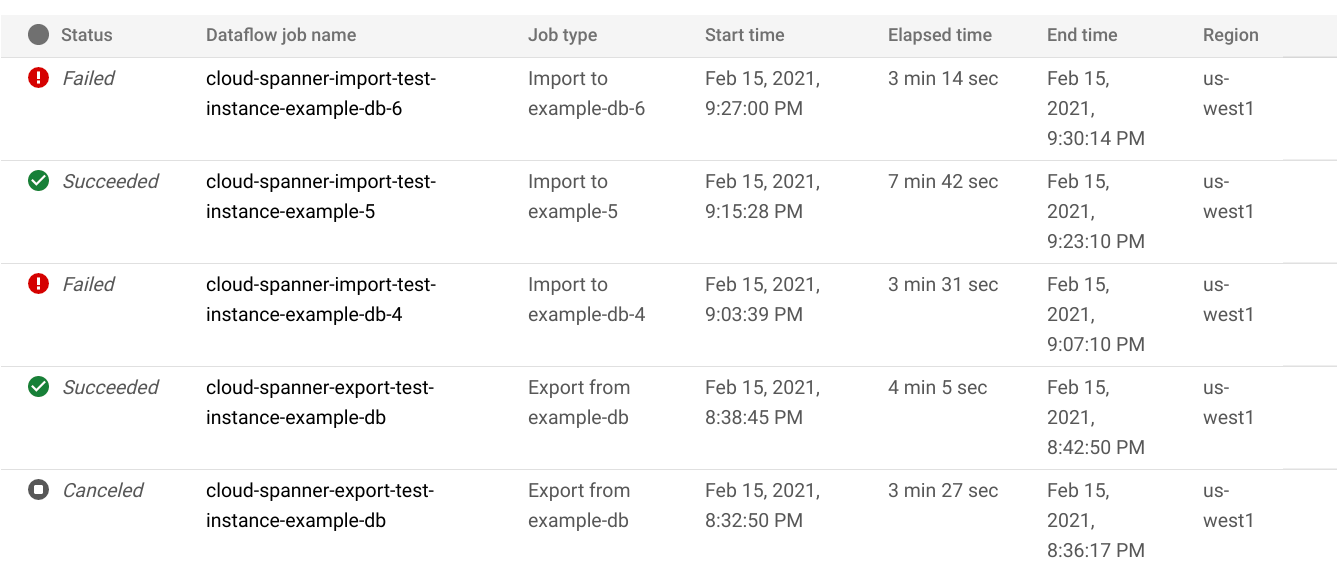
הפרטים של משימת Dataflow מוצגים במסוף Google Cloud .
כדי לראות עבודה שהרצתם לפני יותר משבוע:
נכנסים לדף Dataflow jobs במסוף Google Cloud .
מחפשים את המשרה ברשימה ולוחצים על השם שלה.
הפרטים של משימת Dataflow מוצגים במסוף Google Cloud .
צפייה ביומנים של Dataflow עבור העבודה
כדי להציג את היומנים של משימת Dataflow, עוברים לדף הפרטים של המשימה ולוחצים על Logs (יומנים) משמאל לשם המשימה.
אם משימה נכשלת, כדאי לחפש שגיאות ביומנים. אם יש שגיאות, מספר השגיאות מוצג ליד יומנים:

כדי לראות שגיאות בעבודות:
לוחצים על מספר השגיאות לצד יומנים.
Google Cloud היומנים של העבודה מוצגים במסוף. יכול להיות שתצטרכו לגלול כדי לראות את השגיאות.
מאתרים את הרשומות עם סמל השגיאה
 .
.לוחצים על רשומה ביומן כדי להרחיב את התוכן שלה.
מידע נוסף על פתרון בעיות בעבודות Dataflow זמין במאמר פתרון בעיות בצינורות.
פתרון בעיות שקשורות למשימות ייבוא שנכשלו
אם השגיאות הבאות מופיעות ביומני העבודות:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
בודקים את זמן האחזור של 99% מהפעולות בכרטיסייה Monitoring של מסד הנתונים של Spanner בGoogle Cloud מסוף. אם מוצגים ערכים גבוהים (כמה שניות), זה מצביע על כך שהמופע עמוס מדי, ולכן פעולות הכתיבה נכשלות בגלל פסק זמן.
אחת הסיבות לזמן האחזור הגבוה היא שהמשימה של Dataflow פועלת עם יותר מדי עובדים, מה שגורם לעומס רב מדי על מופע Spanner.
כדי לציין מגבלה על מספר העובדים של Dataflow, במקום להשתמש בכרטיסייה 'ייבוא/ייצוא' בדף פרטי המופע של מסד הנתונים של Spanner במסוף, צריך להתחיל את הייבוא באמצעות תבנית Cloud Storage Avro ל-Spanner של Dataflow ולציין את המספר המקסימלי של העובדים כמו שמתואר: Google Cloudהמסוף
אם משתמשים במסוף Dataflow, הפרמטר Max workers נמצא בקטע Optional parameters בדף Create job from template.
gcloud
מריצים את הפקודה gcloud dataflow jobs run ומציינים את הארגומנט max-workers. לדוגמה:
gcloud dataflow jobs run my-import-job \
--gcs-location='gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
פתרון בעיות שקשורות לשגיאות ברשת
יכול להיות שתקבלו את השגיאה הבאה כשאתם מייצאים מסדי נתונים של Spanner:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
השגיאה הזו מתרחשת כי מערכת Spanner מניחה שאתם מתכוונים להשתמש ברשת VPC במצב אוטומטי בשם default באותו פרויקט כמו משימת Dataflow. אם אין לכם רשת VPC שמוגדרת כברירת מחדל בפרויקט, או אם רשת ה-VPC שלכם היא רשת VPC במצב מותאם אישית, אתם צריכים ליצור משימת Dataflow ולציין רשת או רשת משנה חלופית.
אופטימיזציה של עבודות ייבוא שפועלות לאט
אם פעלתם לפי ההצעות שבהגדרות הראשוניות, בדרך כלל לא תצטרכו לבצע התאמות נוספות. אם העבודה שלכם פועלת לאט, יש עוד כמה אופטימיזציות שאפשר לנסות:
אופטימיזציה של המשימה ומיקום הנתונים: מריצים את משימת Dataflow באותו אזור שבו נמצאים מופע Spanner וקטגוריית Cloud Storage.
מוודאים שיש מספיק משאבים ב-Dataflow: אם המכסות הרלוונטיות של Compute Engine מגבילות את המשאבים של משימת Dataflow, סמל אזהרה
 והודעות יומן מוצגים בדף Dataflow של המשימה במסוף Google Cloud :
והודעות יומן מוצגים בדף Dataflow של המשימה במסוף Google Cloud :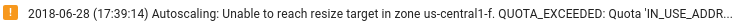
במצב כזה, הגדלת המכסות של מעבדי CPU, כתובות IP בשימוש ודיסק מתמיד סטנדרטי עשויה לקצר את זמן הריצה של העבודה, אבל יכול להיות שתחויבו ביותר חיובים על Compute Engine.
בודקים את ניצול המעבד ב-Spanner: אם ניצול המעבד של המכונה גבוה מ-65%, אפשר להגדיל את קיבולת החישוב במכונה. הקיבולת מוסיפה עוד משאבי Spanner והעבודה אמורה להתבצע מהר יותר, אבל תהיו חשופים ליותר חיובים על Spanner.
גורמים שמשפיעים על הביצועים של עבודת הייבוא
יש כמה גורמים שמשפיעים על משך הזמן שנדרש להשלמת עבודת ייבוא.
גודל מסד הנתונים ב-Spanner: עיבוד של יותר נתונים דורש יותר זמן ומשאבים.
סכימת מסד הנתונים של Spanner, כולל:
- מספר הטבלאות
- גודל השורות
- מספר האינדקסים המשניים
- מספר המפתחות הזרים
- מספר סנכרון שינויים בזרמי נתונים
מיקום הנתונים: הנתונים מועברים בין Spanner לבין Cloud Storage באמצעות Dataflow. מומלץ שכל שלושת הרכיבים יהיו באותו אזור. אם הרכיבים לא נמצאים באותו אזור, העברת הנתונים בין אזורים מאטה את העבודה.
מספר העובדים ב-Dataflow: כדי להשיג ביצועים טובים, צריך מספר אופטימלי של עובדים ב-Dataflow. באמצעות התאמה אוטומטית לעומס (automatic scaling), מערכת Dataflow בוחרת את מספר ה-workers עבור העבודה בהתאם לכמות העבודה שצריך לבצע. עם זאת, מספר ה-workers יהיה מוגבל על ידי המכסות של מעבדי ה-CPU, כתובות ה-IP שבשימוש ודיסק מתמיד סטנדרטי. אם המערכת נתקלת במכסות, מוצג בממשק המשתמש של Dataflow סמל אזהרה. במצב כזה, ההתקדמות איטית יותר, אבל העבודה אמורה להסתיים. התאמת גודל אוטומטית עלולה לגרום לעומס יתר ב-Spanner, וכתוצאה מכך לשגיאות, אם יש כמות גדולה של נתונים לייבא.
עומס קיים ב-Spanner: עבודת ייבוא מוסיפה עומס משמעותי על המעבד במכונת Spanner. אם כבר יש עומס משמעותי על המופע, המשימה תפעל לאט יותר.
כמות קיבולת המחשוב של Spanner: אם ניצול ה-CPU של המופע גבוה מ-65%, העבודה תתבצע לאט יותר.
שיפור הביצועים של הייבוא באמצעות שינוי הגדרות של תהליכי העבודה
כשמתחילים משימת ייבוא של Spanner, צריך להגדיר את העובדים של Dataflow לערך אופטימלי כדי להשיג ביצועים טובים. יותר מדי עובדים גורמים לעומס יתר על Spanner, ומעט מדי עובדים גורמים לביצועי ייבוא לא מרשימים.
המספר המקסימלי של העובדים תלוי מאוד בגודל הנתונים, אבל באופן אידיאלי, ניצול המעבד הכולל של Spanner צריך להיות בין 70% ל-90%. כך מתקבל איזון טוב בין יעילות של Spanner לבין השלמת העבודה ללא שגיאות.
כדי להשיג את יעד הניצול הזה ברוב הסכימות והתרחישים, מומלץ להגדיר מספר מקסימלי של מעבדי vCPU של העובדים בין 4 ל-6 פעמים ממספר הצמתים של Spanner.
לדוגמה, אם יש לכם מופע Spanner עם 10 צמתים, ואתם משתמשים בעובדים מסוג n1-standard-2, אתם יכולים להגדיר את מספר העובדים המקסימלי ל-25, וכך לקבל 50 מעבדים וירטואליים.