
בדף הזה מוסבר איך לייצא מסדי נתונים של Spanner באמצעותGoogle Cloud המסוף.
כדי לייצא מסד נתונים של Spanner באמצעות API בארכיטקטורת REST או Google Cloud CLI, צריך לבצע את השלבים שבקטע לפני שמתחילים בדף הזה, ואז לעיין בהוראות המפורטות במאמר Spanner to Cloud Storage Avro במסמכי התיעוד של Dataflow. תהליך הייצוא משתמש ב-Dataflow וכותב נתונים לתיקייה בקטגוריה של Cloud Storage. התיקייה שמתקבלת מכילה קבוצה של קובצי Avro וקובצי מניפסט בפורמט JSON.
לפני שמתחילים
כדי לייצא מסד נתונים של Spanner, צריך קודם להפעיל את ממשקי ה-API של Spanner, Cloud Storage, Compute Engine ו-Dataflow:
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאה serviceusage.services.enable. איך מקצים תפקידים
צריך גם מכסה מספקת והרשאות IAM נדרשות.
דרישות מכסה
הדרישות בנוגע למכסה של משימות ייצוא הן:
- Spanner: לא נדרשת קיבולת חישוב נוספת כדי לייצא מסד נתונים, אבל יכול להיות שתצטרכו להוסיף קיבולת חישוב כדי שהעבודה תסתיים תוך זמן סביר. פרטים נוספים מופיעים במאמר בנושא אופטימיזציה של משימות.
- Cloud Storage: כדי לייצא, צריך ליצור קטגוריה לקבצים המיוצאים אם אין לכם קטגוריה כזו. אפשר לעשות את זה במסוף Google Cloud , דרך הדף Cloud Storage או במהלך יצירת הייצוא דרך הדף Spanner. אין צורך להגדיר גודל לקטגוריה.
- Dataflow: משימות ייצוא כפופות לאותן מכסות של Compute Engine של מעבד, שימוש בדיסק וכתובת IP כמו משימות אחרות של Dataflow.
Compute Engine: לפני שמריצים את עבודת הייצוא, צריך להגדיר מכסות ראשוניות ל-Compute Engine, שמשמש את Dataflow. המכסות האלה מייצגות את המספר המקסימלי של משאבים שאתם מאפשרים ל-Dataflow להשתמש בהם עבור העבודה שלכם. ערכי התחלה מומלצים:
- מעבדים: 200
- כתובות IP בשימוש: 200
- Standard persistent disk: 50 TB
בדרך כלל, לא צריך לבצע התאמות נוספות. Dataflow מספקת התאמה אוטומטית של המשאבים לעומס (autoscaling), כך שמשלמים רק על המשאבים בפועל שנעשה בהם שימוש במהלך הייצוא. אם העבודה יכולה להשתמש ביותר משאבים, בממשק המשתמש של Dataflow מוצג סמל אזהרה. העבודה אמורה להסתיים גם אם מופיע סמל אזהרה.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות לייצוא מסד נתונים, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים בחשבון השירות של העובד ב-Dataflow:
- Cloud Spanner Viewer (
roles/spanner.viewer) - Dataflow Worker (
roles/dataflow.worker) - אדמין באחסון (
roles/storage.admin) - קריאה במסד נתונים של Spanner (
roles/spanner.databaseReader) - אדמין מסד נתונים (
roles/spanner.databaseAdmin)
כדי להשתמש במשאבי מחשוב עצמאיים של Spanner Data Boost במהלך ייצוא, צריך גם את הרשאת spanner.databases.useDataBoost IAM. מידע נוסף מופיע במאמר סקירה כללית על Data Boost.
ייצוא מסד נתונים
אחרי שתעמדו בדרישות המכסה וה-IAM שמתוארות למעלה, תוכלו לייצא מסד נתונים קיים של Spanner.
כדי לייצא את מסד הנתונים של Spanner לקטגוריה של Cloud Storage:
עוברים לדף Instances ב-Spanner.
לוחצים על השם של המכונה שמכילה את מסד הנתונים.
בחלונית הימנית, לוחצים על Import/Export ואז על הלחצן Export.
בקטע בחירת המקום לאחסון הייצוא, לוחצים על עיון.
אם עדיין אין לכם קטגוריה של Cloud Storage לייצוא:
- לוחצים על New bucket (מאגר חדש)
 .
. - מזינים שם לקטגוריה. שמות של קטגוריות חייבים להיות ייחודיים ב-Cloud Storage.
- בוחרים סוג אחסון (storage class) ומיקום שיהיו ברירת המחדל ולוחצים על יצירה.
- לוחצים על הדלי כדי לבחור אותו.
אם כבר יש לכם קטגוריה, בוחרים אותה מהרשימה הראשונית או לוחצים על חיפוש
 כדי לסנן את הרשימה, ואז לוחצים על הקטגוריה כדי לבחור אותה.
כדי לסנן את הרשימה, ואז לוחצים על הקטגוריה כדי לבחור אותה.- לוחצים על New bucket (מאגר חדש)
לוחצים על בחירה.
בתפריט הנפתח בחירת מסד נתונים לייצוא, בוחרים את מסד הנתונים שרוצים לייצא.
אופציונלי: כדי לייצא את מסד הנתונים מנקודת זמן קודמת, מסמנים את התיבה ומזינים חותמת זמן.
בוחרים אזור בתפריט הנפתח בחירת אזור למשימת הייצוא.
אופציונלי: כדי להצפין את מצב צינור עיבוד הנתונים באמצעות מפתח הצפנה בניהול הלקוח:
- לוחצים על הצגת אפשרויות ההצפנה.
- בוחרים באפשרות Use a customer-managed encryption key (CMEK) (שימוש במפתח הצפנה בניהול הלקוח).
- בוחרים את המפתח מהרשימה הנפתחת.
האפשרות הזו לא משפיעה על ההצפנה ברמת קטגוריית היעד של Cloud Storage. כדי להפעיל CMEK בקטגוריה של Cloud Storage, אפשר לעיין במאמר בנושא שימוש ב-CMEK עם Cloud Storage.
אופציונלי: כדי לייצא באמצעות Spanner Data Boost, מסמנים את תיבת הסימון Use Spanner Data Boost (שימוש ב-Spanner Data Boost). מידע נוסף מופיע במאמר סקירה כללית על Data Boost.
מסמנים את התיבה בקטע אישור חיובים כדי לאשר שיש חיובים בנוסף לאלה שנובעים ממופע Spanner הקיים.
לוחצים על ייצוא.
בדף Database Import/Export במסוף Google Cloud מופיע עכשיו פריט בשורה של משימת הייצוא ברשימה Import/Export jobs, כולל הזמן שחלף מאז תחילת המשימה:
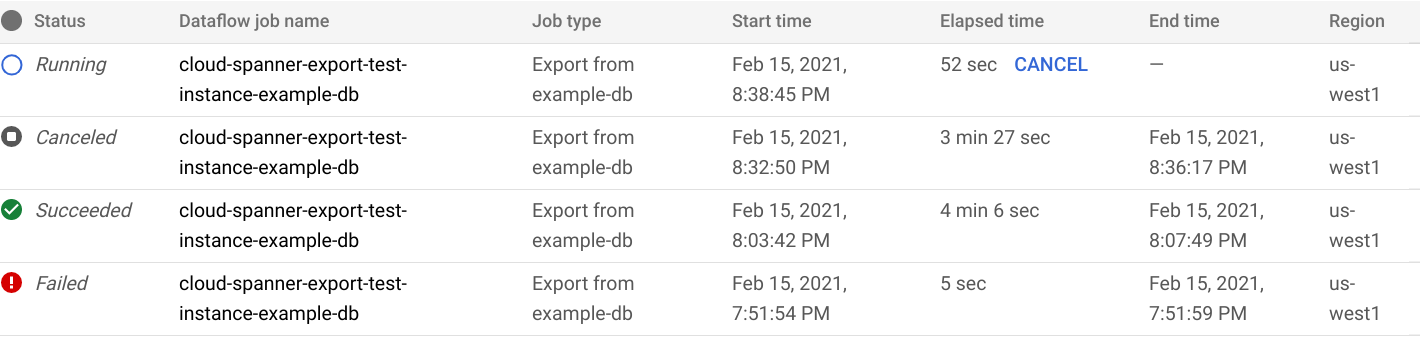
כשהמשימה מסתיימת או מופסקת, הסטטוס מתעדכן ברשימה Import/Export (ייבוא/ייצוא). אם העבודה הושלמה בהצלחה, הסטטוס Succeeded מוצג:

אם המשימה נכשלה, הסטטוס נכשל מוצג:

כדי לראות את הפרטים של פעולת Dataflow עבור המשימה, לוחצים על שם המשימה בעמודה Dataflow job name (שם משימת Dataflow).
אם העבודה נכשלת, צריך לבדוק את היומנים של Dataflow כדי לראות את פרטי השגיאה.
כדי להימנע מחיובים ב-Cloud Storage על קבצים שנוצרו על ידי משימת הייצוא שנכשלה, צריך למחוק את התיקייה והקבצים שבה. מידע על איתור התיקייה מופיע במאמר צפייה בייצוא.
הערה לגבי ייצוא של עמודות שנוצרו ושל סנכרון שינויים בזרמי נתונים
הערכים בעמודה שנוצרה ומאוחסנת לא מיוצאים. הגדרת העמודה מיוצאת לסכימת Avro כשדה רשומה מסוג null, והגדרת העמודה מיוצאת כמאפיינים מותאמים אישית של השדה. עד שמילוי החוסרים (backfill) של עמודה חדשה שנוצרה יושלם, המערכת מתעלמת מהעמודה כאילו היא לא קיימת בסכימה.
סנכרון שינויים בזרמי נתונים שמיוצאים כקובצי Avro מכילים רק את הסכימה של סנכרון שינויים בזרמי נתונים, ולא רשומות של שינויים בנתונים.
הערה לגבי ייצוא רצפים
רצפים (GoogleSQL,
PostgreSQL)
הם אובייקטים של סכימה שמשמשים ליצירת ערכים של מספרים שלמים ייחודיים.
מערכת Spanner מייצאת כל אובייקט סכימה לסכימת Avro כשדה רשומה, עם סוג הרצף, הטווח המדלג והמונה שלו כמאפיינים של השדה. שימו לב: כדי למנוע איפוס של רצף ויצירה של ערכים כפולים אחרי הייבוא, במהלך ייצוא הסכימה, הפונקציה GET_INTERNAL_SEQUENCE_STATE() (GoogleSQL, PostgreSQL) מתעדת את מונה הרצף. מערכת Spanner מוסיפה למספר 1,000, וכותבת את הערך החדש של המספר בשדה הרשומה. הגישה הזו מונעת שגיאות של ערכים כפולים שעשויות לקרות אחרי הייבוא.
אם מתבצעות עוד פעולות כתיבה במסד הנתונים של המקור במהלך ייצוא הנתונים, צריך להתאים את מונה הרצף בפועל באמצעות ההצהרה ALTER SEQUENCE(GoogleSQL, PostgreSQL).
בייבוא, הרצף מתחיל מהמונה החדש הזה במקום מהמונה שנמצא בסכימה. אפשר גם להשתמש בהצהרה ALTER SEQUENCE
(GoogleSQL,
PostgreSQL)
כדי לעדכן את הרצף עם מונה חדש.
הצגת הייצוא ב-Cloud Storage
כדי לראות את התיקייה שמכילה את מסד הנתונים המיוצא בGoogle Cloud מסוף, עוברים לדף Cloud Storage browser ובוחרים את הקטגוריה שבחרתם קודם:
הקטגוריה מכילה עכשיו תיקייה עם מסד הנתונים המיוצא. שם התיקייה מתחיל במזהה המופע, בשם מסד הנתונים ובחותמת הזמן של עבודת הייצוא. התיקייה מכילה:
- קובץ
spanner-export.json - קובץ
TableName-manifest.jsonלכל טבלה במסד הנתונים שייצאתם. קובץ אחד או יותר של
TableName.avro-#####-of-#####המספר הראשון בתוסף.avro-#####-of-#####מייצג את האינדקס של קובץ ה-Avro, החל מאפס, והמספר השני מייצג את מספר קובצי ה-Avro שנוצרו לכל טבלה.לדוגמה,
Songs.avro-00001-of-00002הוא השני מבין שני קבצים שמכילים את הנתונים של הטבלהSongs.קובץ
ChangeStreamName-manifest.jsonלכל change stream במסד הנתונים שייצאתם.ChangeStreamName.avro-00000-of-00001קובץ לכל מקור נתונים לשינויים. הקובץ הזה מכיל נתונים ריקים עם סכמת Avro בלבד של שינוי הנתונים.
בחירת אזור למשימת הייבוא
אולי כדאי לבחור אזור אחר בהתאם למיקום של קטגוריית Cloud Storage. כדי להימנע מחיובים על העברת נתונים יוצאים, בוחרים אזור שמתאים למיקום של קטגוריית Cloud Storage.
אם המיקום של הקטגוריה ב-Cloud Storage הוא אזור, תוכלו ליהנות משימוש חינמי ברשת אם תבחרו את אותו אזור למשימת הייבוא, בהנחה שהאזור הזה זמין.
אם המיקום של הקטגוריה של Cloud Storage הוא בשני אזורים, אתם יכולים ליהנות משימוש חופשי ברשת אם תבחרו אחד משני האזורים שמרכיבים את שני האזורים עבור עבודת הייבוא, בהנחה שאחד מהאזורים זמין.
- אם אזור שממוקם באותו מקום לא זמין לעבודת הייבוא, או אם המיקום של קטגוריה של Cloud Storage הוא במספר אזורים, יחולו חיובים על העברת נתונים יוצאת. כדי לבחור אזור שבו עלויות העברת הנתונים הן הכי נמוכות, אפשר לעיין בתמחור של העברת נתונים ב-Cloud Storage.
ייצוא של קבוצת משנה של טבלאות
אם רוצים לייצא רק את הנתונים מטבלאות מסוימות ולא את כל מסד הנתונים, אפשר לציין את הטבלאות האלה במהלך הייצוא. במקרה הזה, Spanner מייצא את הסכימה כולה של מסד הנתונים, כולל הנתונים של הטבלאות שציינתם, ומשאיר את כל הטבלאות האחרות בקובץ המיוצא, אבל ריקות.
אפשר לציין קבוצת משנה של טבלאות לייצוא באמצעות הדף Dataflow במסוף Google Cloud או באמצעות ה-CLI של gcloud. (הפעולה הזו לא זמינה בדף של Spanner).
אם מייצאים נתונים מטבלה שהיא צאצא של טבלה אחרת, צריך לייצא גם את הנתונים של טבלת האב. אם ההורים לא מיוצאים, משימת הייצוא נכשלת.
כדי לייצא קבוצת משנה של טבלאות, מתחילים את הייצוא באמצעות התבנית Spanner to Cloud Storage Avro של Dataflow, ומציינים את הטבלאות באמצעות דף Dataflow במסוף Google Cloud או באמצעות ה-CLI של gcloud, כמו שמתואר:
המסוף
אם אתם משתמשים בדף Dataflow במסוף Google Cloud , הפרמטר Cloud Spanner Table name(s) נמצא בקטע Optional parameters בדף Create job from template. אפשר לציין כמה טבלאות בפורמט מופרד בפסיקים.
gcloud
מריצים את הפקודה gcloud dataflow jobs run ומציינים את הארגומנט tableNames. לדוגמה:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=table1,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
כדי לציין כמה טבלאות ב-gcloud, צריך להשתמש בהסרת תווי escape מסוג מילון.
בדוגמה הבאה נעשה שימוש ב-| כתו בריחה:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='^|^instanceId=test-instance|databaseId=example-db|tableNames=table1,table2|outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
הפרמטר shouldExportRelatedTables הוא אפשרות נוחה לייצוא אוטומטי של כל טבלאות ההורה של הטבלאות שנבחרו. לדוגמה, בהיררכיית הסכימה הזו עם הטבלאות Singers, Albums ו-Songs, צריך לציין רק את Songs. האפשרות shouldExportRelatedTables תייצא גם את Singers
ואת Albums כי Songs הוא צאצא של שניהם.
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=Songs,shouldExportRelatedTables=true,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
הצגה או פתרון בעיות של משימות בממשק המשתמש של Dataflow
אחרי שמתחילים פעולת ייצוא, אפשר לראות את פרטי הפעולה, כולל יומנים, בקטע Dataflow במסוף Google Cloud .
הצגת פרטי משימות ב-Dataflow
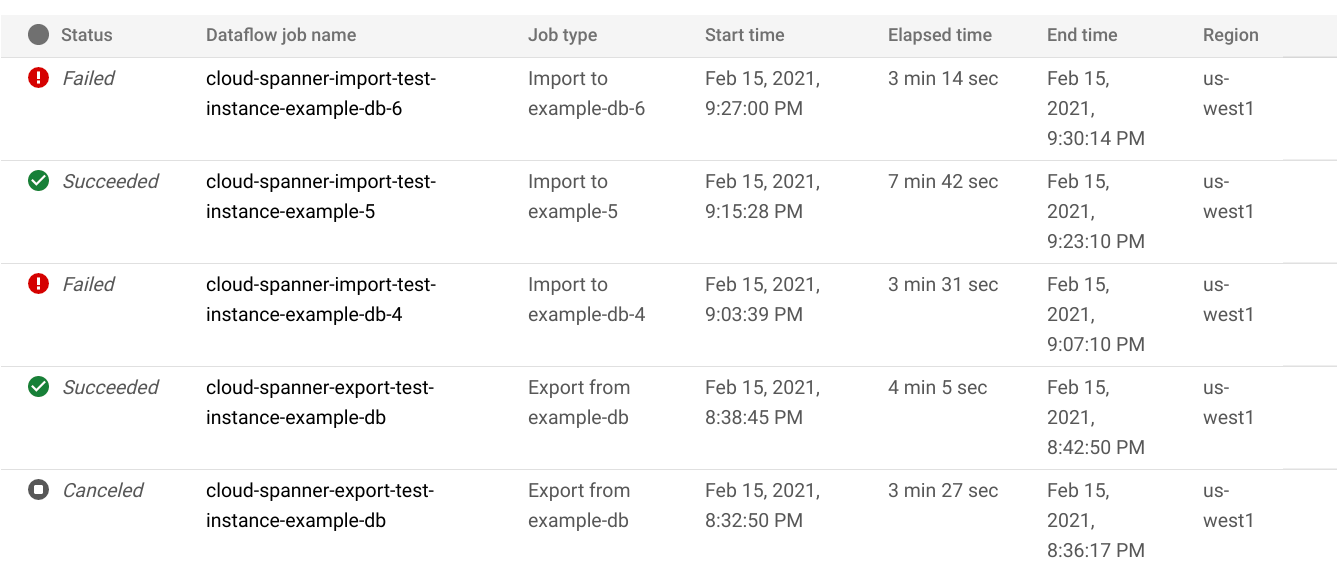
כדי לראות פרטים של משימות ייבוא או ייצוא שהפעלתם בשבוע האחרון, כולל משימות שפועלות כרגע:
- עוברים לדף סקירה כללית של מסד הנתונים של מסד הנתונים.
- לוחצים על ייבוא/ייצוא בתפריט שבחלונית הימנית. בדף ייבוא/ייצוא של מסד הנתונים מוצגת רשימה של משימות אחרונות.
בדף ייבוא/ייצוא של מסד הנתונים, לוחצים על שם המשימה בעמודה שם משימת Dataflow:
הפרטים של משימת Dataflow מוצגים במסוף Google Cloud .
כדי לראות עבודה שהרצתם לפני יותר משבוע:
נכנסים לדף Dataflow jobs במסוף Google Cloud .
מחפשים את המשרה ברשימה ולוחצים על השם שלה.
הפרטים של משימת Dataflow מוצגים במסוף Google Cloud .
צפייה ביומנים של Dataflow עבור העבודה
כדי להציג את היומנים של משימת Dataflow, עוברים לדף הפרטים של המשימה ולוחצים על Logs (יומנים) משמאל לשם המשימה.
אם משימה נכשלת, כדאי לחפש שגיאות ביומנים. אם יש שגיאות, מספר השגיאות מוצג ליד יומנים:

כדי לראות שגיאות בעבודות:
לוחצים על מספר השגיאות לצד יומנים.
Google Cloud היומנים של העבודה מוצגים במסוף. יכול להיות שתצטרכו לגלול כדי לראות את השגיאות.
מאתרים את הרשומות עם סמל השגיאה
 .
.לוחצים על רשומה ביומן כדי להרחיב את התוכן שלה.
מידע נוסף על פתרון בעיות בעבודות Dataflow זמין במאמר פתרון בעיות בצינורות.
פתרון בעיות שקשורות למשימות ייצוא שנכשלו
אם השגיאות הבאות מופיעות ביומני העבודות:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
בודקים את זמן האחזור של קריאה ב-99% בכרטיסייה Monitoring של מסד הנתונים של Spanner בGoogle Cloud מסוף. אם הערכים גבוהים (כמה שניות), המשמעות היא שהמופע עמוס מדי, ולכן קריאות נכשלות בגלל פסק זמן.
אחת הסיבות לזמן האחזור הגבוה היא שהמשימה של Dataflow פועלת עם יותר מדי עובדים, מה שגורם לעומס רב מדי על מופע Spanner.
כדי לציין מגבלה על מספר העובדים של Dataflow, במקום להשתמש בכרטיסייה Import/Export בדף פרטי המופע של מסד הנתונים של Spanner במסוף, צריך להפעיל את הייצוא באמצעות התבנית Spanner to Cloud Storage Avro של Dataflow ולציין את המספר המקסימלי של העובדים כמו שמתואר: Google Cloudהמסוף
אם משתמשים במסוף Dataflow, הפרמטר Max workers נמצא בקטע Optional parameters בדף Create job from template.
gcloud
מריצים את הפקודה gcloud dataflow jobs run ומציינים את הארגומנט max-workers. לדוגמה:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
פתרון בעיות שקשורות לשגיאות ברשת
יכול להיות שתקבלו את השגיאה הבאה כשאתם מייצאים מסדי נתונים של Spanner:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
השגיאה הזו מתרחשת כי מערכת Spanner מניחה שאתם מתכוונים להשתמש ברשת VPC במצב אוטומטי בשם default באותו פרויקט כמו משימת Dataflow. אם אין לכם רשת VPC שמוגדרת כברירת מחדל בפרויקט, או אם רשת ה-VPC שלכם היא רשת VPC במצב מותאם אישית, אתם צריכים ליצור משימת Dataflow ולציין רשת או רשת משנה חלופית.
אופטימיזציה של משימות ייצוא שפועלות לאט
אם פעלתם לפי ההצעות שבהגדרות הראשוניות, בדרך כלל לא תצטרכו לבצע התאמות נוספות. אם העבודה שלכם פועלת לאט, יש עוד כמה אופטימיזציות שאפשר לנסות:
אופטימיזציה של המשימה ומיקום הנתונים: מריצים את משימת Dataflow באותו אזור שבו נמצאים מופע Spanner וקטגוריית Cloud Storage.
מוודאים שיש מספיק משאבים ב-Dataflow: אם המכסות הרלוונטיות של Compute Engine מגבילות את המשאבים של משימת Dataflow, סמל אזהרה
 והודעות יומן מוצגים בדף Dataflow של המשימה במסוף Google Cloud :
והודעות יומן מוצגים בדף Dataflow של המשימה במסוף Google Cloud :
במצב כזה, הגדלת המכסות של מעבדי CPU, כתובות IP בשימוש ודיסק מתמיד סטנדרטי עשויה לקצר את זמן הריצה של העבודה, אבל יכול להיות שתחויבו ביותר חיובים על Compute Engine.
בודקים את ניצול המעבד ב-Spanner: אם ניצול המעבד של המכונה גבוה מ-65%, אפשר להגדיל את קיבולת החישוב במכונה. הקיבולת מוסיפה עוד משאבי Spanner והעבודה אמורה להתבצע מהר יותר, אבל תהיו חשופים ליותר חיובים על Spanner.
גורמים שמשפיעים על הביצועים של עבודת הייצוא
יש כמה גורמים שמשפיעים על משך הזמן שנדרש להשלמת עבודת ייצוא.
גודל מסד הנתונים ב-Spanner: עיבוד של יותר נתונים דורש יותר זמן ומשאבים.
סכימת מסד הנתונים של Spanner, כולל:
- מספר הטבלאות
- גודל השורות
- מספר האינדקסים המשניים
- מספר המפתחות הזרים
- מספר סנכרון שינויים בזרמי נתונים
מיקום הנתונים: הנתונים מועברים בין Spanner לבין Cloud Storage באמצעות Dataflow. מומלץ שכל שלושת הרכיבים יהיו באותו אזור. אם הרכיבים לא נמצאים באותו אזור, העברת הנתונים בין אזורים מאטה את העבודה.
מספר העובדים ב-Dataflow: כדי להשיג ביצועים טובים, צריך מספר אופטימלי של עובדים ב-Dataflow. באמצעות התאמה אוטומטית לעומס (automatic scaling), מערכת Dataflow בוחרת את מספר ה-workers עבור העבודה בהתאם לכמות העבודה שצריך לבצע. עם זאת, מספר ה-workers יהיה מוגבל על ידי המכסות של מעבדי ה-CPU, כתובות ה-IP שבשימוש ודיסק מתמיד סטנדרטי. אם המערכת נתקלת במכסות, מוצג בממשק המשתמש של Dataflow סמל אזהרה. במצב כזה, ההתקדמות איטית יותר, אבל העבודה אמורה להסתיים.
עומס קיים ב-Spanner: בדרך כלל, משימת ייצוא מוסיפה עומס קל למופע Spanner. אם כבר יש עומס משמעותי על המופע, המשימה תפעל לאט יותר.
כמות קיבולת המחשוב של Spanner: אם ניצול ה-CPU של המופע גבוה מ-65%, העבודה תתבצע לאט יותר.