

Questo documento è la prima parte di una serie che tratta il ripristino di emergenza (RE) in Google Cloud. Questa parte fornisce una panoramica del processo di pianificazione del RE: ciò che devi sapere per progettare e implementare un piano di RE. Le parti successive trattano casi d'uso specifici del RE con implementazioni di esempio su Google Cloud.
La serie è composta dalle seguenti parti:
- Guida alla pianificazione del ripristino di emergenza (questo documento)
- Componenti di base per il disaster recovery
- Scenari di disaster recovery dei dati
- Scenari di ripristino di emergenza delle applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso del disaster recovery: applicazioni di analisi dei dati con limitazioni a livello di località
- Progettazione ripristino di emergenza per le interruzioni dell'infrastruttura cloud
Gli eventi che interrompono il servizio possono verificarsi in qualsiasi momento. La rete potrebbe subire un'interruzione, l'ultimo push dell'applicazione potrebbe introdurre un bug critico o potresti dover affrontare una calamità naturale. Quando le cose vanno male, è importante avere un piano di RE solido, mirato e ben testato.
Con un piano di RE ben progettato e testato, puoi assicurarti che, in caso di catastrofe, l'impatto sui profitti della tua attività sia minimo. Indipendentemente dalle tue esigenze di RE, Google Cloud offre una selezione solida, flessibile ed economica di prodotti e funzionalità che puoi utilizzare per creare o ampliare la soluzione più adatta a te.
Nozioni di base sulla pianificazione del RE
Il RE è un sottoinsieme della pianificazione della continuità aziendale. La pianificazione del RE inizia con un'analisi dell'impatto aziendale che definisce due metriche chiave:
- Un obiettivo del tempo di ripristino (RTO), ovvero il periodo di tempo massimo accettabile per cui l'applicazione può essere offline. Questo valore viene solitamente definito nell'ambito di un accordo sul livello del servizio (SLA) più ampio .
- Un Recovery Point Objective (RPO), ovvero il periodo di tempo massimo accettabile durante il quale i dati potrebbero andare persi dall'applicazione a causa di un incidente grave. Questa metrica varia in base ai modi in cui vengono utilizzati i dati. Ad esempio, i dati utente modificati di frequente potrebbero avere un RPO di pochi minuti. Al contrario, i dati meno critici e modificati di rado potrebbero avere un RPO di diverse ore. (Questa metrica descrive solo la durata del tempo; non riguarda la quantità o la qualità dei dati persi.)
In genere, più piccoli sono i valori RTO e RPO (ovvero più velocemente l'applicazione deve riprendersi da un'interruzione), maggiori sono i costi per eseguire l'applicazione. Il grafico seguente mostra il rapporto tra costo e RTO/RPO.
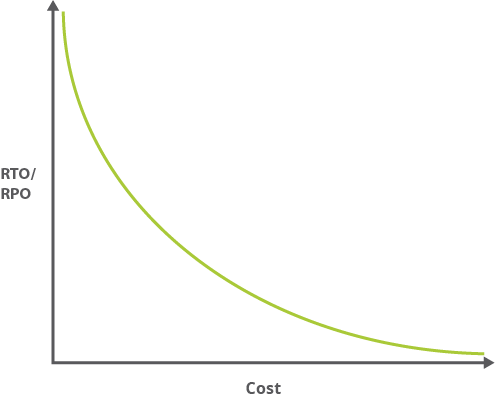
Poiché i valori RTO e RPO più piccoli spesso comportano una maggiore complessità, il sovraccarico amministrativo associato segue una curva simile. Un'applicazione a disponibilità elevata potrebbe richiedere la gestione della distribuzione tra due data center fisicamente separati, la gestione della replica e altro ancora.
I valori RTO e RPO in genere vengono aggregati in un'altra metrica: il obiettivo del livello di servizio (SLO), che è un elemento misurabile chiave di uno SLA. Spesso SLA e SLO vengono confusi. Uno SLA è l'intero accordo che specifica il servizio da fornire, come viene supportato, orari, località, costi, prestazioni, sanzioni e responsabilità delle parti coinvolte. Gli SLO sono caratteristiche specifiche e misurabili dello SLA, come disponibilità, throughput, frequenza, tempo di risposta o qualità. Uno SLA può contenere molti SLO. RTO e RPO sono misurabili e devono essere considerati SLO.
Puoi leggere ulteriori informazioni su SLO e SLA nel libro Site Reliability Engineering di Google.
Potresti anche pianificare un'architettura per l'alta affidabilità (HA). La disponibilità elevata non si sovrappone completamente al RE, ma spesso è necessario tenerla in considerazione quando si pensa ai valori RTO e RPO. La disponibilità elevata contribuisce a garantire un livello concordato di prestazioni operative, in genere uptime, per un periodo superiore al normale. Quando esegui workload di produzione su Google Cloud, potresti utilizzare un sistema distribuito a livello globale in modo che, in caso di problemi in una regione, l'applicazione continui a fornire il servizio anche se è meno ampiamente disponibile. In sostanza, l'applicazione richiama il suo piano di RE.
Perché Google Cloud?
Google Cloud può ridurre notevolmente i costi associati sia a RTO che a RPO rispetto al soddisfacimento dei requisiti RTO e RPO on-premise. Ad esempio, la pianificazione del RE richiede di tenere conto di una serie di requisiti, tra cui i seguenti:
- Capacità:garantire risorse sufficienti per la scalabilità in base alle esigenze.
- Sicurezza:fornire sicurezza fisica per proteggere gli asset.
- Infrastruttura di rete:inclusi componenti software come firewall e bilanciatori del carico.
- Assistenza:mettere a disposizione tecnici qualificati per eseguire la manutenzione e risolvere i problemi.
- Larghezza di banda:pianificare una larghezza di banda adatta al carico di picco.
- Strutture:garantire l'infrastruttura fisica, comprese apparecchiature e alimentazione.
Fornendo una soluzione altamente gestita su una piattaforma di produzione di livello mondiale, Google Cloud ti aiuta a bypassare la maggior parte o tutti questi fattori complicanti, eliminando molti costi aziendali nel processo. Inoltre,l'attenzione di Google Cloud's alla semplicità amministrativa comporta anche la riduzione dei costi di gestione di un'applicazione complessa.
Google Cloud offre diverse funzionalità pertinenti alla pianificazione del RE, tra cui le seguenti:
- Una rete globale. Google dispone di una delle reti informatiche più grandi e avanzate al mondo. La rete backbone di Google utilizza avanzati servizi di networking software-defined e di memorizzazione nella cache perimetrale per offrire prestazioni elevate, coerenti e scalabili.
- Ridondanza. Più punti di presenza (POP) in tutto il mondo significano una forte ridondanza. I dati vengono sottoposti a mirroring automatico tra i dispositivi di archiviazione in più località.
- Scalabilità. Google Cloud è progettato per scalare come altri prodotti Google (ad esempio Ricerca e Gmail), anche in caso di picchi di traffico elevati. I servizi gestiti come Cloud Run, Compute Engine e Firestore offrono la scalabilità automatica che consente all'applicazione di aumentare e diminuire in base alle esigenze.
- Sicurezza. Il modello di sicurezza di Google si basa su decenni di esperienza nell'aiutare a proteggere i clienti su applicazioni Google come Gmail e Google Workspace. Inoltre, i team SRE (Site Reliability Engineering) di Google contribuiscono a garantire un'elevata affidabilità e a impedire utilizzi illeciti delle risorse della piattaforma.
- Conformità. Google è sottoposta a regolari audit indipendenti di terze parti per verificare che Google Cloud sia in linea con le normative e le best practice in materia di sicurezza, privacy, e conformità. Google Cloud è conforme a certificazioni come ISO 27001, SOC 2/3 e PCI DSS 3.0.
Modelli di RE
I modelli di RE sono considerati freddi, caldi o attivi. Questi modelli indicano la facilità con cui il sistema può riprendersi in caso di problemi. Un'analogia potrebbe essere quella che faresti se stessi guidando e forassi uno pneumatico dell'auto.
Il modo in cui gestisci una gomma a terra dipende dalla tua preparazione:
- Freddo: non hai una gomma di scorta, quindi devi chiamare qualcuno che ti porti una gomma nuova e la sostituisca. Il viaggio si interrompe fino all'arrivo dell'assistenza per effettuare la riparazione.
- Caldo: hai una gomma di scorta e un kit di sostituzione, quindi puoi tornare in strada utilizzando ciò che hai in auto. Tuttavia, devi interrompere il viaggio per risolvere il problema.
- Attivo: hai pneumatici run-flat. Potresti dover rallentare un po', ma non c'è un impatto immediato sul tuo viaggio. Le gomme funzionano abbastanza bene da poter continuare (anche se alla fine dovrai risolvere il problema).
Creare un piano di RE dettagliato
Questa sezione fornisce consigli su come creare il piano di RE.
Progettare in base agli obiettivi di ripristino
Quando progetti il piano di RE, devi combinare le tecniche di ripristino di applicazioni e dati e guardare il quadro generale. Il modo tipico per farlo è esaminare i valori RTO e RPO e il modello di RE che puoi adottare per soddisfare questi valori. Ad esempio, nel caso di dati storici orientati alla conformità, probabilmente non hai bisogno di un accesso rapido ai dati, quindi è appropriato un valore RTO elevato e un modello di RE freddo. Tuttavia, se il tuo servizio online subisce un'interruzione, dovrai essere in grado di recuperare sia i dati sia la parte dell'applicazione rivolta agli utenti il più rapidamente possibile. In questo caso, un modello attivo sarebbe più appropriato. Il sistema di notifica via email, che in genere non è business-critical, è probabilmente un candidato per un modello caldo.
Per indicazioni sull'utilizzo di Google Cloud per affrontare gli scenari di RE comuni, consulta gli scenari di ripristino delle applicazioni. Questi scenari forniscono strategie di RE mirate per una varietà di casi d'uso e offrono implementazioni di esempio su Google Cloud per ciascuno.
Progettare per il ripristino end-to-end
Non è sufficiente avere un piano per il backup o l'archiviazione dei dati. Assicurati che il piano di RE riguardi l'intero processo di ripristino, dal backup al ripristino alla pulizia. Ne parliamo nei documenti correlati sui dati e sul ripristino del RE.
Rendere specifiche le attività
Quando è il momento di eseguire il piano di RE, non vuoi dover indovinare il significato di ogni passaggio. Fai in modo che ogni attività del piano di RE sia costituita da uno o più comandi o azioni concreti e non ambigui. Ad esempio, "Esegui lo script di ripristino" è troppo generico. Al contrario, "Apri una shell ed esegui /home/example/restore.sh" è preciso e concreto.
Implementare misure di controllo
Aggiungi controlli per impedire che si verifichino disastri e per rilevare i problemi prima che si verifichino. Ad esempio, aggiungi un monitor che invii un avviso quando un flusso che distrugge i dati, come una pipeline di eliminazione, mostra picchi imprevisti o altre attività insolite. Questo monitor potrebbe anche terminare i processi della pipeline se viene raggiunta una determinata soglia di eliminazione, evitando una situazione catastrofica.
Preparare il software
Parte della pianificazione del RE consiste nell'assicurarsi che il software su cui fai affidamento sia pronto per un evento di ripristino.
Verificare di poter installare il software
Assicurati che il software dell'applicazione possa essere installato dall'origine o da un'immagine preconfigurata. Assicurati di disporre della licenza appropriata per qualsiasi software che eseguirai il deployment su Google Cloud—per indicazioni, rivolgiti al fornitore del software.
Assicurati che le risorse di Compute Engine necessarie siano disponibili nell'ambiente di ripristino. Potrebbe essere necessario preallocare o prenotare le istanze.
Progettare il deployment continuo per il ripristino
Il set di strumenti di deployment continuo (CD) è un componente integrante quando esegui il deployment delle applicazioni. Nell'ambito del piano di ripristino, devi considerare dove eseguire il deployment degli artefatti nell'ambiente ripristinato. Pianifica dove vuoi ospitare l'ambiente e gli artefatti di CD: devono essere disponibili e operativi in caso di disastro.
Implementare controlli di sicurezza e conformità
Quando progetti un piano di RE, la sicurezza è importante. Gli stessi controlli che hai nell'ambiente di produzione devono essere applicati all'ambiente ripristinato. Anche le normative di conformità si applicheranno all'ambiente ripristinato.
Configurare la sicurezza allo stesso modo per gli ambienti di RE e di produzione
Assicurati che i controlli di rete forniscano la stessa separazione e lo stesso blocco utilizzati dall'ambiente di produzione di origine. Scopri come configurare il VPC condiviso e i firewall per stabilire un controllo centralizzato di rete e sicurezza del deployment, configurare le subnet e controllare il traffico in entrata e in uscita. Scopri come utilizzare i service account per implementare il principio del privilegio minimo per le applicazioni che accedono alle Google Cloud API. Assicurati di utilizzare i service account come parte delle regole firewall.
Assicurati di concedere agli utenti lo stesso accesso all'ambiente di RE che hanno nell'ambiente di produzione di origine. Il seguente elenco descrive i modi per sincronizzare le autorizzazioni tra gli ambienti:
Se il tuo ambiente di produzione è Google Cloud, la replica dei criteri IAM nell'ambiente di RE è semplice. Puoi utilizzare strumenti Infrastructure as Code (IaC) come Terraform per eseguire il deployment dei criteri IAM in produzione. Quindi, utilizza gli stessi strumenti per associare i criteri alle risorse corrispondenti nell'ambiente di RE nell'ambito del processo di creazione dell'ambiente di RE.
Se il tuo ambiente di produzione è on-premise, mappa i ruoli funzionali, come i ruoli di amministratore di rete e revisore, ai criteri IAM che hanno i ruoli IAM appropriati. La documentazione di IAM contiene alcuni esempi di configurazioni di ruoli funzionali . Ad esempio, consulta la documentazione per la creazione di ruoli funzionali di rete e di logging di audit.
Devi configurare i criteri IAM per concedere le autorizzazioni appropriate ai prodotti. Ad esempio, potresti voler limitare l'accesso a bucket Cloud Storage specifici.
Se il tuo ambiente di produzione è un altro cloud provider, mappa le autorizzazioni nei criteri IAM dell'altro provider ai Google Cloud criteri IAM.
Verificare la sicurezza del RE
Dopo aver configurato le autorizzazioni per l'ambiente di RE, assicurati di testare tutto. Crea un ambiente di test. Verifica che le autorizzazioni che concedi agli utenti corrispondano a quelle che hanno on-premise.
Assicurarsi che gli utenti possano accedere all'ambiente di RE
Non aspettare che si verifichi un disastro prima di verificare che gli utenti possano accedere all'ambiente di RE. Assicurati di aver concesso i diritti di accesso appropriati a utenti, sviluppatori, operatori, data scientist, amministratori della sicurezza, amministratori di rete e qualsiasi altro ruolo nella tua organizzazione. Se utilizzi un sistema di identità alternativo, assicurati che gli account siano stati sincronizzati con il tuo account Cloud Identity. Poiché l'ambiente di RE sarà il tuo ambiente di produzione per un po' di tempo, chiedi agli utenti che dovranno accedere all'ambiente di RE di accedere e risolvere eventuali problemi di autenticazione. Incorpora gli utenti che accedono all'ambiente di RE come parte dei test di RE regolari che implementi.
Formare gli utenti
Gli utenti devono capire come eseguire le azioni in Google Cloud cui sono abituati a eseguire nell'ambiente di produzione, come l'accesso e l'accesso alle VM. Utilizzando l'ambiente di test, insegna agli utenti come eseguire queste attività in modo da salvaguardare la sicurezza del sistema.
Assicurarsi che l'ambiente di RE soddisfi i requisiti di conformità
Verifica che l'accesso all'ambiente di RE sia limitato solo a chi ne ha bisogno. Assicurati che i dati PII siano oscurati e criptati. Se esegui regolarmente test di penetrazione sul tuo ambiente di produzione, devi includere l'ambiente di RE nell'ambito e eseguire test regolari creando un ambiente di RE.
Assicurati che, mentre l'ambiente di RE è in servizio, tutti i log raccolti vengano compilati nell'archivio dei log dell'ambiente di produzione. Allo stesso modo, assicurati che, nell'ambito dell'ambiente di RE, tu possa esportare i log di audit raccolti tramite Cloud Logging nell'archivio del sink di log principale. Utilizza le funzionalità del sink di esportazione. Per i log delle applicazioni, crea un mirror dell'ambiente di logging e monitoraggio on-premise. Se il tuo ambiente di produzione è un altro cloud provider, mappa il logging e il monitoraggio di questo provider ai servizi equivalenti Google Cloud Disponi di una procedura per formattare l'input nell'ambiente di produzione.
Trattare i dati recuperati come dati di produzione
Assicurati che i controlli di sicurezza applicati ai dati di produzione vengano applicati anche ai dati recuperati: devono essere applicati gli stessi requisiti di autorizzazioni, crittografia e audit.
Scopri dove si trovano i backup e chi è autorizzato a ripristinare i dati. Assicurati che il processo di disaster recovery sia sottoponibile ad audit: dopo un ripristino di emergenza, assicurati di poter mostrare chi aveva accesso ai dati di backup e chi ha eseguito il ripristino.
Assicurarsi che il piano di RE funzioni
Assicurati che, in caso di disastro, il piano di RE funzioni come previsto.
Mantenere più di un percorso di recupero dei dati
In caso di disastro, il metodo di connessione a Google Cloud potrebbe non essere disponibile. Implementa un mezzo di accesso alternativo a Google Cloud per assicurarti di poter trasferire i dati a Google Cloud. Verifica regolarmente che il percorso di backup sia operativo.
Testare regolarmente il piano
Dopo aver creato un piano di RE, testalo regolarmente, annotando eventuali problemi e modificando il piano di conseguenza. Utilizzando Google Cloud, puoi testare gli scenari di ripristino a costi minimi. Ti consigliamo di implementare quanto segue per facilitare i test:
- Automatizzare il provisioning dell'infrastruttura. Puoi utilizzare strumenti IaC come Terraform per automatizzare il provisioning della tua Google Cloud infrastruttura. Se esegui l'ambiente di produzione on-premise, assicurati di avere un processo di monitoraggio in grado di avviare il processo di RE quando rileva un errore e di attivare le azioni di ripristino appropriate.
- Monitorare gli ambienti con Google Cloud Observability. Google Cloud offre eccellenti strumenti di logging e monitoraggio a cui puoi accedere tramite chiamate API, consentendoti di automatizzare il deployment degli scenari di ripristino reagendo alle metriche. Quando progetti i test, assicurati di avere un monitoraggio e avvisi appropriati in grado di attivare le azioni di ripristino appropriate.
Esegui i test indicati in precedenza:
- Verifica che le autorizzazioni e l'accesso utente funzionino nell'ambiente di RE come nell'ambiente di produzione.
- Esegui test di penetrazione sull'ambiente di RE.
- Esegui un test in cui il percorso di accesso abituale a Google Cloud non funziona.
Passaggi successivi
- Scopri di più su Google Cloud geografia e regioni.
- Leggi altri documenti di questa serie sul RE:
- Componenti di base per il disaster recovery
- Scenari di disaster recovery dei dati
- Scenari di ripristino di emergenza delle applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso del disaster recovery: applicazioni di analisi dei dati con limitazioni a livello di località
- Progettazione ripristino di emergenza per le interruzioni dell'infrastruttura cloud
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.
Collaboratori
Autori:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect