
[Explore query tracker] と Explore の [パフォーマンス] パネルには、Explore クエリのステップごとのパフォーマンス データが表示されます。このデータは、クエリのパフォーマンスに関する問題のトラブルシューティングと解決のための重要なエントリ ポイントを特定し、改善のための推奨事項を提供します。
Explore クエリ トラッカー
Explore クエリ トラッカーには、クエリの実行中に、クエリの3 つのフェーズの進行状況が表示されます。
![]()
クエリの実行に時間がかかる場合は、クエリ トラッカーで、パフォーマンスの問題の原因となっているクエリのフェーズを確認できます。これは、パフォーマンスの問題が発生する可能性のある場所を特定し、最適化の取り組みを最も効果的に行うために役立ちます。
Explore の [可視化] パネルまたは Explore の [データ] パネルが開いている限り、Explore の実行時にクエリ トラッカーが表示されます。
Explore の [パフォーマンス] パネル
Explore の [パフォーマンス] パネルを表示するには、実行された Explore クエリで [パフォーマンスの詳細を表示] リンクをクリックします。

[パフォーマンス] パネルには、クエリが 3 つのクエリフェーズのそれぞれで費やした時間が表示されます。また、パフォーマンスに関するドキュメントへのリンクと、クエリとクエリの作成に使用された Explore の現在と過去のパフォーマンス データを示す [クエリ履歴] システム アクティビティ ダッシュボードへのリンクも表示されます。
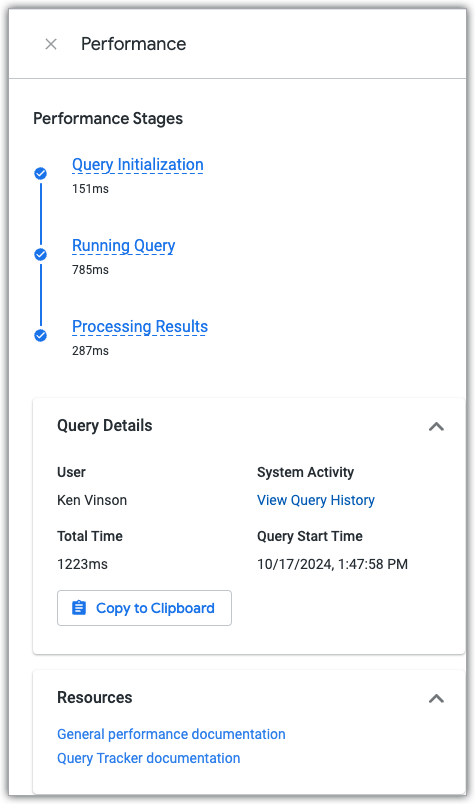
クエリフェーズ
Looker Explore がデータベース クエリを実行すると、クエリは次の 3 つのフェーズで実行されます。
クエリの初期化フェーズ
クエリの初期化フェーズでは、クエリがデータベースに送信される前に必要なすべてのタスクを Looker が行います。クエリの初期化 フェーズには、次のタスクが含まれます。
- LookML モデルのコンパイル
- 永続的な派生テーブル(PDT)を作成する必要があるかどうかの確認
- クエリ SQL の生成
- データベース接続の取得
ドキュメント ページ クエリのパフォーマンス指標を把握するでは、システム アクティビティのクエリ パフォーマンス指標 Explore を使用して、クエリの詳細な内訳を確認する方法について説明しています。クエリ トラッカーのクエリの初期化 フェーズには、クエリ パフォーマンス指標 Explore の非同期ワーカー フェーズ 、初期化フェーズ 、および 接続処理フェーズ で説明されているイベントが含まれます。
クエリの実行フェーズ
クエリの実行フェーズは、Looker がデータベースに接続してクエリを実行し、クエリの結果を返すフェーズです。このフェーズでパフォーマンスの問題が発生した場合は、外部データベースに問題がある可能性があります。たとえば、PDT の再構築に時間がかかり、最適化が必要な場合や、外部データベース テーブルの最適化が必要な場合があります。クエリの実行 フェーズには、次のタスクが含まれます。
- Explore クエリに必要なデータベース内の PDT の構築
- データベースでリクエストされたクエリの実行
ドキュメント ページ クエリのパフォーマンス指標を把握するでは、システム アクティビティのクエリ パフォーマンス指標 Explore を使用して、クエリの詳細な内訳を確認する方法について説明しています。クエリ トラッカーのクエリの実行 フェーズには、クエリ パフォーマンス指標 Explore のメインクエリのフェーズ で説明されているイベントが含まれます。
このフェーズでパフォーマンスの問題が発生した場合に実行できる手順は次のとおりです。
- 可能な限り、
many_to_one結合を使用して Explore を作成します。ビューを最も粒度の細かいレベルから最も詳細なレベル(many_to_one)まで結合すると、通常、クエリ パフォーマンスが最も高くなります。 - 可能な限りキャッシュを最大化して ETL ポリシーと同期し、データベースのクエリ トラフィックを削減します。デフォルトでは、Looker でクエリがキャッシュされるのは 1 時間です。`
persist_with` パラメータを使用して Explore 内で データグループ を適用することで、キャッシュ ポリシーを制御し、Looker のデータ更新を ETL プロセスと同期できます。キャッシュを最大化すると、Looker とバックエンド データ パイプラインの統合を強化できるので、古いデータを分析するリスクを伴わずにキャッシュ使用量を最大化できます。名前付きキャッシュ ポリシーは、モデル全体または個々の Explore と永続的な派生テーブル(PDT)に適用できます。 - Looker の集約テーブルの自動認識機能を使用して、Looker がロール アップまたはサマリー テーブルを作成できます。Looker は可能な限り、特に大規模なデータベースの一般的なクエリの場合にこのテーブルを使用できます。また、集約テーブルの自動認識を利用して、大幅にダッシュボード全体のパフォーマンスを改善することもできます。詳細については、集約テーブルの自動認識のチュートリアルをご覧ください。
- PDT を使用してクエリを高速化します。多くの複雑な結合やパフォーマンスの低い結合を持つ Explore や、サブクエリやサブセレクトを持つディメンションを PDT に変換すると、ビューが事前結合され、ランタイム前に使用可能な状態になります。
- データベース言語が増分 PDT をサポートしている場合は、増分 PDT を構成して、Looker が PDT テーブルの再構築にかかる時間を短縮します。
- Looker で定義された連結済みの 主キーでビューを Explore に結合しないようにします。ビューに含まれる、連結済みの主キーを構成する基本フィールドで結合します。または、ビューの LookML ではなく、テーブルの SQL 定義で事前定義された連結済みの主キーを使用して、ビューを PDT として再作成します。
- ベンチマークには、SQL Runner ツールの Explain を利用します。
EXPLAINは、特定の SQL クエリのデータベースのクエリ実行プランの概要を生成し、最適化できるクエリ コンポーネントを検出できるようにします。詳細については、コミュニティ投稿のEXPLAINを使用して SQL を最適化する方法をご覧ください。 - インデックスを宣言します。各テーブルのインデックスは、Looker で SQL Runner から直接確認できます。テーブルの歯車アイコンをクリックし、[Show Indexes] を選択します。
よく使われる列のうち、インデックスのメリットを得られる列は、重要な日付と外部キーです。これらの列にインデックスを追加すると、ほぼすべてのクエリでパフォーマンスが向上します。これは PDT の場合も同じです。
indexes、sort keys、distributionなどの LookML パラメータが適切に適用できます。
結果の処理フェーズ
結果の処理 フェーズでは、Looker がクエリを処理し、結果をレンダリングします。結果の処理 フェーズには、次のタスクが含まれます。
- クエリ結果をキャッシュにストリーミングする
- 表計算の解決
- Liquid テンプレート言語の結果をフォーマットする
- クエリを結合する
- 合計と小計の計算
ドキュメント ページ クエリのパフォーマンス指標を把握するでは、システム アクティビティのクエリ パフォーマンス指標 Explore を使用して、クエリの詳細な内訳を確認する方法について説明しています。クエリ トラッカーの結果の処理 フェーズには、クエリ パフォーマンス指標 Explore のクエリ後のフェーズ で説明されているイベントが含まれます。
このフェーズでパフォーマンスの問題が発生した場合に実行できる手順は次のとおりです。
- 結果の統合、カスタム フィールド、 および表計算などの機能の使用は控えめにします。これらの機能は、モデルの設計に役立つ概念実証として使用することを目的としています。 使用頻度の高い計算や関数は LookML にハードコードすることをおすすめします。これにより、データベースで処理される SQL を生成します。過剰な計算は Looker インスタンスの Java メモリと競合する可能性があるため、Looker インスタンスのレスポンスが遅くなります。
- ビューファイルの数が多い場合は、モデル内に含めるビューの数を制限します。1 つのモデルにすべてのビューを含めると、パフォーマンスが低下する場合があります。プロジェクト内に多数のビューがある場合は、各モデルに必要なビューファイルのみを含めることを検討してください。モデルにビューグループを含められるように、ビューファイルの名前に戦略的な命名規則を採用することを検討してください。例については、
includesパラメータのドキュメントをご覧ください。 - ダッシュボードのタイルと Look 内に、大量のデータポイントをデフォルトで返すのを避けます。数千のデータポイントを返すクエリは、より多くのメモリを消費します。フロントエンドの
フィルタをダッシュボード、Look、Explore に適用し、LookML レベルで
required filters、conditionally_filter、sql_always_whereパラメータを使用して、可能な限りデータを制限できるようにします。 - クエリのサイズが非常に大きくなり、処理する際に Looker サーバーに負荷がかかる可能性があるため、[**すべての結果**] オプションを使用してのクエリのダウンロードや配信は控えめにします。