
Looker (Google Cloud Core) doit être connecté à une base de données pour permettre l'exploration des données. Vous pouvez créer une connexion par défaut à une base de données BigQuery SQL standard à l'aide de la connexion au démarrage rapide BigQuery.
Avant de commencer
La configuration d'une connexion au démarrage rapide BigQuery nécessite les autorisations suivantes.
Autorisations Looker
Vous pouvez afficher et modifier la page Connexion au démarrage rapide BigQuery sur la page Accueil de votre instance Looker (Google Cloud Core) si vous disposez de l'une des autorisations Looker suivantes :
- Rôle Administrateur Looker
- Autorisation Looker
manage_project_connections
Autorisations IAM
Les instances Looker (Google Cloud Core) peuvent utiliser les identifiants par défaut de l'application (ADC) pour s'authentifier lorsque vous configurez une connexion à BigQuery. Lorsque vous utilisez les ADC, la connexion s'authentifie auprès de la base de données à l'aide des identifiants du compte de service Looker (Google Cloud Core). Le compte de service doit disposer des autorisations IAM suivantes pour accéder à l'ensemble de données BigQuery :
Pour le projet contenant l'ensemble de données BigQuery, le compte de service Looker doit disposer des rôles IAM suivants :
- Consommateur Service Usage (
roles/serviceusage.serviceUsageConsumer) - Utilisateur de tâche BigQuery (
roles/bigquery.jobUser) Éditeur de données BigQuery (
roles/bigquery.dataEditor) ou les autorisations IAM suivantes :bigquery.config.getbigquery.datasets.createbigquery.datasets.getbigquery.tables.createbigquery.tables.get
- Consommateur Service Usage (
Pour le projet de facturation, le compte de service Looker doit disposer des rôles IAM suivants :
- Consommateur Service Usage (
roles/serviceusage.serviceUsageConsumer) - Utilisateur de tâche BigQuery (
roles/bigquery.jobUser)
- Consommateur Service Usage (
Si le compte de service Looker (Google Cloud Core) ne dispose pas déjà des rôles IAM nécessaires, utilisez l'adresse e-mail du compte de service lorsque vous accordez des rôles dans ce projet. Pour trouver l'adresse e-mail du compte de service, accédez à la page IAM de la Google Cloud console et cochez la case Inclure les attributions de rôles fournies par Google. L'e-mail sera au format service-<project number>@gcp-sa-looker.iam.gserviceaccount.com. Utilisez cet e-mail pour accorder les rôles appropriés au compte de service.
Configurer une connexion au démarrage rapide BigQuery
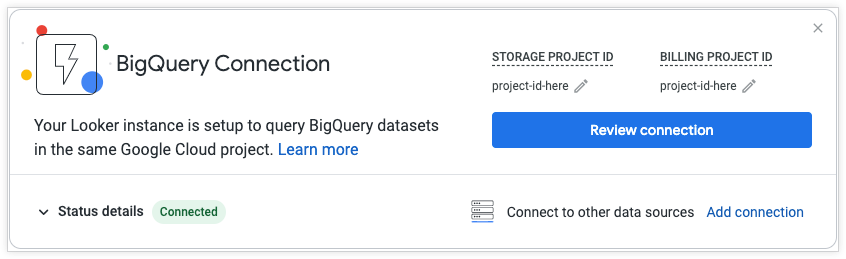
Les utilisateurs disposant des autorisations appropriées peuvent afficher et modifier la connexion au démarrage rapide BigQuery depuis la page Accueil ou la page Connexions du panneau Admin. Sur la page Connexions, la connexion au démarrage rapide BigQuery apparaît sous le nom Connexion BigQuery par défaut. Sur une nouvelle instance, les champs ID du projet Cloud Storage et ID du projet de facturation sont définis par défaut sur Aucun.
Sur la page Accueil, cliquez sur le bouton Examiner la connexion pour gérer la connexion. Vous pouvez fermer la tuile de la page Accueil en cliquant sur le x ou en activant/désactivant l'option Démarrage rapide BigQuery dans la barre latérale Explorer.
La connexion au démarrage rapide BigQuery contient les sections suivantes :
ID du projet de facturation
L'ID du projet sert d'identifiant unique pour le Google Cloud projet de facturation. Le projet de facturation est le Google Cloud projet qui est facturé pour l'utilisation de BigQuery, mais vous pouvez toujours interroger des ensembles de données dans un autre Google Cloud projet si vos développeurs LookML spécifient des noms de tables complets dans le sql_table_name paramètre de vos vues, Explorations ou jointures LookML. Champ obligatoire.
Pour vous authentifier auprès d'une base de données BigQuery à l'aide d'OAuth : pour les connexions BigQuery, Looker (Google Cloud Core) peut utiliser automatiquement les identifiants d'application OAuth que votre administrateur Looker (Google Cloud Core) a utilisés lors de la création de l'instance. Pour en savoir plus, consultez la page Créer un client et des identifiants OAuth pour une instance Looker (Google Cloud Core).
Développez la section Détails de l'état pour tester les paramètres de votre connexion.
Ensemble de données principal
La page Ensemble de données principal contient les paramètres suivants.
ID du projet Cloud Storage
Dans le champ ID de projet Cloud Storage, saisissez l'ID du projet contenant l'ensemble de données BigQuery auquel vous souhaitez vous connecter, même s'il s'agit du même projet que celui contenant l'instance Looker (Google Cloud Core). Champ obligatoire.
Ensemble de données principal
L'ensemble de données principal est l'endroit où BigQuery recherchera des tables si leur emplacement n'est pas spécifié dans le texte de la requête SQL. Notez que les requêtes Looker (Google Cloud Core) peuvent faire référence à des tables de n'importe quel projet ou ensemble de données, à condition que les requêtes utilisent des noms de tables complets au format project_id.dataset_name.table_name. Le compte de service Looker (Google Cloud Core) aura également besoin des autorisations IAM appropriées pour accéder aux tables à cet emplacement. Champ obligatoire.
Pour en savoir plus sur les ensembles de données, consultez la page de documentation Connecter Looker à BigQuery.
Développez la section Détails de l'état pour tester les paramètres de votre connexion.
Configurer les paramètres facultatifs de votre connexion BigQuery
La section Paramètres facultatifs contient les options suivantes :
Nombre maximal de connexions par nœud : nombre maximal de connexions simultanées à la base de données. Remarque : Ce paramètre s'applique à chaque nœud du déploiement Looker (Google Cloud Core). La valeur doit être comprise entre 5 et 100, et vous pouvez conserver la valeur par défaut indiquée. Pour en savoir plus sur ce paramètre, consultez la section Nombre maximal de connexions par nœud de la page de documentation Connecter Looker à votre base de données.
Délai d'inactivité du pool de connexions : durée d'attente, en secondes, avant l'expiration d'une requête lorsque le pool de connexions est saturé. Vous pouvez conserver la valeur par défaut indiquée. Pour en savoir plus sur ce paramètre, consultez la section Délai d'inactivité du pool de connexions de la page de documentation Connecter Looker à votre base de données.
Paramètres JDBC supplémentaires : ajoutez des paramètres JDBC supplémentaires, tels que des étiquettes BigQuery (voir la section Étiquettes de tâches et commentaires de contexte pour les connexions BigQuery sur cette page pour en savoir plus).
Calendrier de maintenance : expression Cron indiquant la fréquence maximale des vérifications des déclencheurs de groupe de données et de la maintenance des PDT. Pour en savoir plus sur ce paramètre, consultez la documentation Calendrier de maintenance.
SSL : choisissez si vous souhaitez, ou non, utiliser le chiffrement SSL pour protéger vos données pendant leur transition entre Looker (Google Cloud Core) et votre base de données. Le chiffrement SSL n'est qu'une option parmi tant d'autres pour protéger vos données ; d'autres options sécurisées sont décrites sur la page de documentation Sécurisation de l'accès à la base de données.
Vérifier SSL : choisissez si vous souhaitez demander une vérification du certificat SSL utilisé par la connexion. Pour en savoir plus sur ce paramètre, consultez la section Vérifier SSL de la page de documentation Connecter Looker à votre base de données.
Précharger les tables et les colonnes : dans l’Exécuteur SQL, toutes les informations de la table sont préchargées dès que vous sélectionnez une connexion et un schéma. Cela permet à l'Exécuteur SQL d'afficher rapidement les colonnes de la table dès que vous cliquez sur un nom de table. Néanmoins, pour les connexions et les schémas comportant de nombreuses tables ou des tables très volumineuses, il se peut que vous ne souhaitiez pas que l'Exécuteur SQL précharge l'ensemble des informations.
Extraire et mettre en cache le schéma : pour certaines fonctionnalités d'écriture SQL telles que la reconnaissance d'agrégats, Looker (Google Cloud Core) utilise le schéma d'informations de votre base de données pour optimiser l'écriture SQL. Pour en savoir plus sur ce paramètre, consultez la section Extraire le schéma d'informations pour l'écriture SQL de la page de documentation Connecter Looker à votre base de données.
Activer les PDT : activez le bouton Activer les PDT pour activer les tables dérivées persistantes. Lorsque les PDT sont activées, la fenêtre Paramètres facultatifs affiche des champs PDT supplémentaires et la section Remplacements pour les PDT.
Base de données temporaire : saisissez l'ensemble de données dans BigQuery où Looker (Google Cloud Core) créera des tables dérivées persistantes. Vous devez configurer cet ensemble de données à l'avance en utilisant les autorisations en écriture appropriées. Ce champ est obligatoire pour utiliser les PDT.
Nombre maximal de connexions du générateur de PDT : le paramètre Nombre maximal de connexions du générateur de PDT est défini par défaut sur 1, mais peut atteindre 100. Toutefois, la valeur ne peut pas être supérieure à celle définie dans le Nombre maximal de connexions par nœud. Pour en savoir plus sur ce paramètre, consultez la section Nombre maximal de connexions du générateur de PDT de la page de documentation Connecter Looker à votre base de données. Vous devez configurer cette valeur attentivement. Si cette valeur est trop élevée, vous risquez de submerger votre base de données. Si cette valeur est faible, les tables PDT ou agrégées de grande taille peuvent retarder la création d'autres tables persistantes ou ralentir les autres requêtes sur la connexion.
Relancer les PDT dérivées persistantes en échec : le bouton Relancer les générations de PDT persistantes en échec configure la manière dont le régénérateur Looker (Google Cloud Core) tente de régénérer les tables persistantes déclenchées qui ont échoué lors du cycle de régénération précédent. Pour en savoir plus sur ce paramètre, consultez la section Relancer les PDT persistantes en échec de la page de documentation Connecter Looker à votre base de données.
Contrôle des tables dérivées persistantes via l'API : le bouton Contrôle des tables dérivées persistantes via l'API détermine si les appels d'API
start_pdt_build,check_pdt_buildetstop_pdt_buildpeuvent être utilisés pour cette connexion. Lorsque le bouton Contrôle des tables dérivées persistantes via l'API est désactivé, ces appels d'API échoueront lorsqu'ils font référence aux PDT sur cette connexion.Remplacements pour les PDT : si votre base de données est compatible avec les tables dérivées persistantes et que vous avez activé le bouton Activer les PDT dans les paramètres de connexion, Looker (Google Cloud Core) affiche la section Remplacements pour les PDT. Dans la section Remplacements pour les PDT , vous pouvez saisir des paramètres JDBC distincts (host, port, database, username, password, schema, additional parameters et after connect statements) qui sont spécifiques aux processus PDT. Pour en savoir plus sur ce paramètre, consultez la section Remplacements pour les PDT de la page de documentation Connecter Looker à votre base de données.
Fuseau horaire de la base de données : fuseau horaire dans lequel votre base de données stocke les informations temporelles. Looker (Google Cloud Core) doit connaître cette information afin de convertir les valeurs de date/heure pour les utilisateurs et ainsi simplifier la compréhension et l'utilisation des données temporelles. Pour en savoir plus, consultez la page de documentation Utiliser les paramètres de fuseau horaire.
Fuseau horaire de la requête : l'option Fuseau horaire de la requête n'est visible que si vous avez désactivé l'option Fuseaux horaires spécifiques à l'utilisateur. Pour en savoir plus, consultez la page de documentation Utiliser les paramètres de fuseau horaire.
Développez la section Détails de l'état pour tester les paramètres de votre connexion.
Examen
Examinez et modifiez les informations de connexion que vous avez saisies dans les sections précédentes de la section Examen.
Développez la section Détails de l'état pour tester les paramètres de votre connexion. Cliquez sur l'icône de modification à côté de chaque section pour revenir à cette section et modifier vos paramètres.
Enregistrer et tester la connexion
Pour enregistrer les modifications apportées à la connexion au démarrage rapide BigQuery, cliquez sur Enregistrer.
Vous pouvez tester vos paramètres de connexion à partir de plusieurs endroits de l'interface utilisateur Looker (Google Cloud Core) :
- Développez la section Détails de l'état en bas de l'une des pages de connexion au démarrage rapide, puis cliquez sur Tester la connexion.
- Sur la page Accueil, développez la section Détails de l'état en bas de la tuile de connexion au démarrage rapide, puis cliquez sur Tester la connexion.
- Sur la page d'administration Connexions, sélectionnez le bouton Tester à côté de la liste de la connexion, comme décrit sur la page de documentation Connexions.
Une fois que vous avez saisi les paramètres de connexion, cliquez sur Tester pour vérifier que les informations sont correctes et que la base de données peut se connecter.
Si votre connexion échoue à un ou plusieurs tests, voici quelques options de dépannage :
- Essayez quelques étapes de dépannage disponibles sur la page de documentation Tester la connectivité de la base de données.
- Accédez aux journaux de votre instance Looker (Google Cloud Core) pour obtenir des messages d'erreur plus détaillés.
- Contactez l'assistance pour obtenir de l'aide supplémentaire pour le dépannage.
Étape suivante
- Gérer les utilisateurs dans Looker (Google Cloud Core)
- Administrer une instance Looker (Google Cloud Core) depuis la console Google Cloud
- Paramètres d'administration de Looker (Google Cloud Core)
- Utiliser l'exemple de projet LookML sur une instance Looker (Google Cloud Core)