
Neste tutorial, demonstramos como migrar aplicativos com estado no GKE de tipos de máquinas de geração mais antiga, como N2, com volumes Persistent Disk anexados, para tipos de máquinas de geração mais recente, como N4, com volumes de Hyperdisk anexados, usando o Backup para GKE. Para mais informações sobre os tipos de máquina compatíveis com o Hyperdisk, consulte a documentação do Compute Engine.
Para demonstrar a migração, este tutorial usa os bancos de dados Sakila e World para fornecer conjuntos de dados de amostra. Sakila é um banco de dados de amostra fornecido pelo MySQL que representa uma locadora de DVD fictícia. O banco de dados "World" contém dados sobre países e cidades. O tutorial usa dois conjuntos de dados diferentes em namespaces separados para simular um ambiente multitenant complexo.
Este tutorial é destinado a especialistas e administradores de armazenamento que criam e alocam armazenamento, além de gerenciar a segurança de dados e o acesso aos dados. Para saber mais sobre papéis comuns e tarefas de exemplo referenciados no conteúdo do Google Cloud, consulte Tarefas e papéis de usuário comuns do GKE.
Arquitetura de implantação
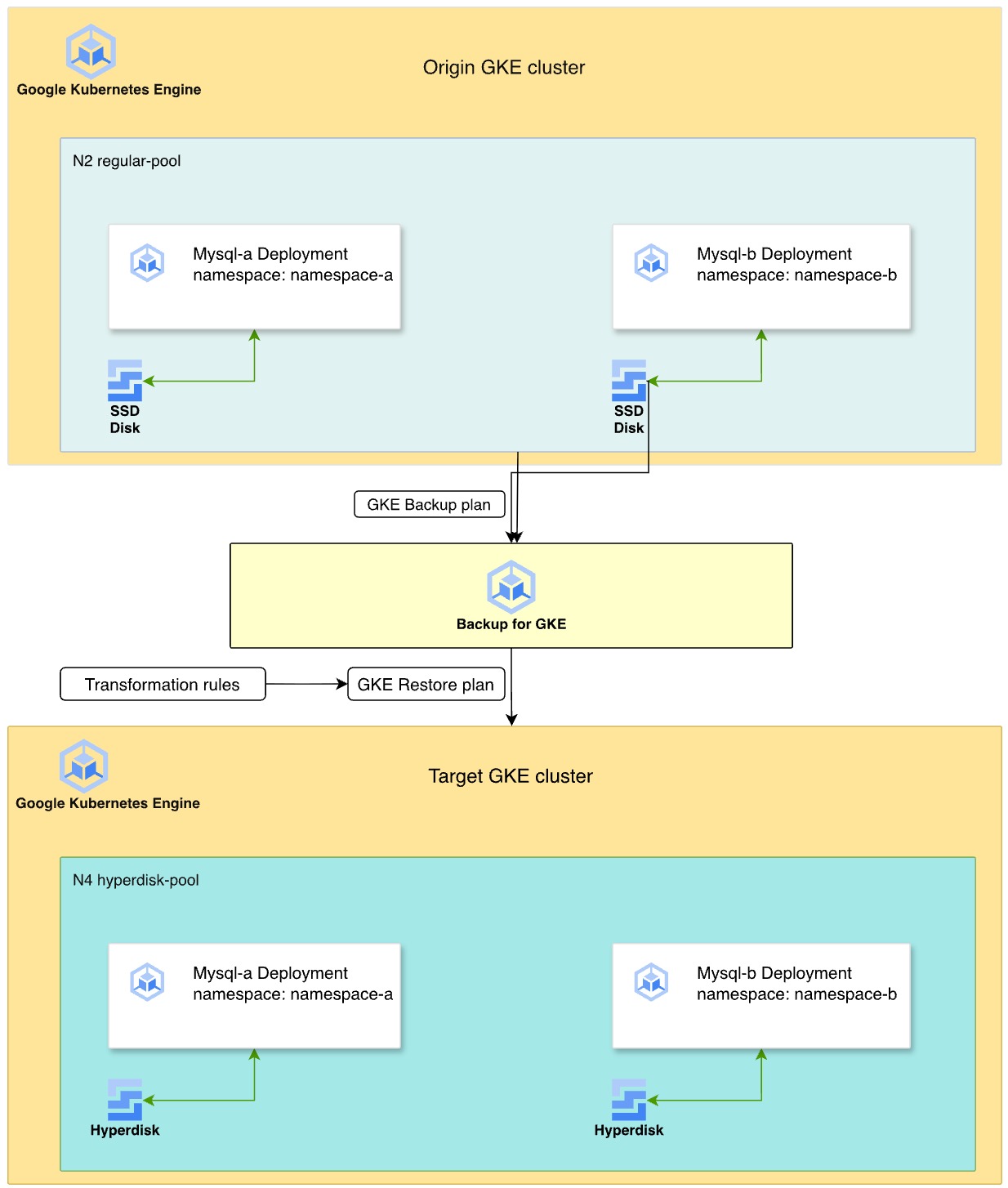
O diagrama a seguir ilustra o processo de uso do Backup para GKE para migrar cargas de trabalho do MySQL com estado do Persistent Disk em tipos de máquinas N2 para o Hyperdisk em tipos de máquinas N4.
- Cluster de origem:duas implantações do MySQL residem em namespaces separados,
namespace-aenamespace-b, em um pool de nós da série N2. Esses implantações usam disco permanente SSD para armazenamento de dados. - Estratégia de backup:ative o agente do Backup para GKE no cluster e crie um plano de backup para capturar os namespaces, os dados de volume e os secrets. Em seguida, execute um backup manual para criar um ponto de recuperação pontual.
- Transformação e restauração:você define um plano de restauração usando regras de transformação para adaptar os recursos ao ambiente de destino.
Essas regras fazem o seguinte:
- Troque o
StorageClassdepremium-rwo(DP) por uma classe de armazenamento do Hyperdisk chamadabalanced-storage. - Modifique as regras de afinidade de pod para garantir que as cargas de trabalho restauradas sejam programadas em um novo pool de nós N4.
- Troque o
- Ambiente de destino:você provisiona um novo cluster do GKE com tipos de máquina N4. O processo de restauração recria os discos como volumes do Hyperdisk com base no backup e implanta as instâncias do MySQL nos nós N4 compatíveis.
Objetivos
Neste tutorial, você vai aprender a fazer o seguinte:
- Prepare aplicativos com estado do GKE para backup.
- Ative o complemento Backup para GKE.
- Crie um plano de backup e faça backup do cluster de origem.
- Crie um plano de restauração que use regras de transformação para migrar o armazenamento para o Hyperdisk.
- Restaure a carga de trabalho para um novo cluster e verifique os dados.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
- GKE
- Compute Engine (Persistent Disk and Hyperdisk)
- Backup for GKE
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Faça login na sua conta do Google Cloud . Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Verifique se você tem os seguintes papéis no projeto: roles/container.admin, roles/iam.serviceAccountAdmin, roles/compute.admin, roles/gkebackup.admin, roles/monitoring.viewer
Verificar os papéis
-
No console do Google Cloud , acesse a página IAM.
Acessar IAM - Selecione o projeto.
-
Na coluna Principal, encontre todas as linhas que identificam você ou um grupo no qual você está incluído. Para saber em quais grupos você está incluído, entre em contato com o administrador.
- Em todas as linhas que especificam ou incluem você, verifique a coluna Papel para ver se a lista de papéis inclui os papéis necessários.
Conceder os papéis
-
No console do Google Cloud , acesse a página IAM.
Acessar IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos principais, digite seu identificador de usuário. Normalmente, é o endereço de e-mail de uma Conta do Google.
- Clique em Selecionar um papel e pesquise o papel.
- Para conceder outros papéis, adicione-os clicando em Adicionar outro papel.
- Clique em Salvar.
-
Configurar o Cloud Shell
-
No console do Google Cloud , ative o Cloud Shell.
Uma sessão do Cloud Shell é iniciada e exibe um prompt de linha de comando. A inicialização da sessão pode levar alguns segundos.
- Defina seu projeto padrão:
gcloud config set project PROJECT_IDSubstitua
PROJECT_IDpela ID do seu projeto.
Configure o ambiente
Nesta seção, você prepara as variáveis de ambiente e clona o repositório de exemplo.
Defina as variáveis de ambiente para o projeto, os nomes do cluster e a zona:
export PROJECT_ID=PROJECT_ID export KUBERNETES_CLUSTER_PREFIX=backup-gke-migration export TARGET_CLUSTER_PREFIX=restore-gke-migration export ZONE=us-central1-aSubstitua
PROJECT_IDpelo ID do projeto do Google Cloud.Clone o repositório do exemplo de código e navegue até o diretório:
git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples cd kubernetes-engine-samples/databases/backup-migration
Criar o cluster do GKE de origem
Crie um cluster zonal com um pool de nós que usa tipos de máquinas N2 e volumes Persistent Disk anexados.
Crie o cluster:
gcloud container clusters create ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Crie um pool de nós com tipos de máquina
n2-standard-4para a carga de trabalho de origem:gcloud container node-pools create regular-pool \ --cluster ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --machine-type n2-standard-4 \ --zone ${ZONE} \ --num-nodes 1Ative o complemento Backup para GKE no cluster de origem:
gcloud container clusters update ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE} \ --update-addons=BackupRestore=ENABLEDReceba as credenciais para o cluster:
gcloud container clusters get-credentials ${KUBERNETES_CLUSTER_PREFIX}-cluster --zone ${ZONE}Verifique se o agente do Backup para GKE está ativado:
gcloud container clusters describe ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE}A saída será semelhante a esta e vai confirmar que o agente de backup está ativado:
addonsConfig: gkeBackupAgentConfig: enabled: true
Implantar o MySQL com dados de amostra
Implante dois bancos de dados MySQL em namespaces separados para simular um ambiente de produção.
Crie os namespaces
namespace-aenamespace-b:kubectl create namespace namespace-a kubectl create namespace namespace-bImplante as cargas de trabalho do MySQL em
namespace-aenamespace-b:Implante o arquivo
mysql-a-deployment.yaml:kubectl apply -f manifests/02-mysql/mysql-a-deployment.yaml -n namespace-aO manifesto a seguir cria um pod do MySQL em
namespace-acom discos SSD de disco permanente provisionados dinamicamente nos nósregular-pool. A senha de root é definida comomigration:Implante o arquivo
mysql-b-deployment.yaml:kubectl apply -f manifests/02-mysql/mysql-b-deployment.yaml -n namespace-bO manifesto a seguir cria um pod do MySQL em
namespace-bcom discos SSD de disco permanente provisionados dinamicamente nos nósregular-pool. A senha de root é definida comomigration:
Implante um pod de cliente MySQL para fazer upload de conjuntos de dados de amostra:
kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300sO manifesto a seguir implanta um pod de cliente MySQL:
Conecte-se ao pod cliente:
kubectl exec -it mysql-client -- bashDentro do pod, faça o download dos conjuntos de dados de amostra Sakila e World:
curl --output dataset.tgz "https://downloads.mysql.com/docs/sakila-db.tar.gz" tar -xvzf dataset.tgz -C ./ curl --output world-db.tar.gz "https://downloads.mysql.com/docs/world-db.tar.gz" tar xvzf world-db.tar.gz -C ./Importe o conjunto de dados Sakila para o banco de dados
mysql-a:mysql -u root -h mysql-a.namespace-a -p # Enter password: migration SOURCE /sakila-db/sakila-schema.sql; SOURCE /sakila-db/sakila-data.sql;Verifique os dados importados do Sakila:
USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Saia do MySQL:
exitImporte o conjunto de dados "World" para o banco de dados
mysql-b:mysql -u root -h mysql-b.namespace-b -p # Enter password: migration SOURCE /world-db/world.sql;Verifique os dados importados do mundo:
USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';O resultado será o seguinte:
+-----------------+------------+ | table_name | table_rows | +-----------------+------------+ | city | 4079 | | country | 239 | | countrylanguage | 984 | +-----------------+------------+Saia do MySQL:
exitSaia do shell do pod cliente:
exit
Fazer backup do cluster do GKE
Faça backup de todo o cluster, incluindo segredos e volumes.
Crie um plano de backup:
gcloud beta container backup-restore backup-plans create main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${KUBERNETES_CLUSTER_PREFIX}-cluster \ --selected-namespaces=namespace-a,namespace-b,default \ --include-secrets \ --include-volume-data \ --target-rpo-minutes=1440 \ --backup-retain-days=7 \ --backup-delete-lock-days=3 \ --locked--selected-namespaces:faz backup de namespaces específicos para evitar conflitos com recursos do sistema.- O
--include-volume-dataajuda a garantir que os dados do Persistent Disk sejam armazenados em backup. --target-rpo-minutes: configura a programação de backup com base no objetivo do ponto de recuperação (RPO). O RPO é o período máximo aceitável em que os dados podem ser perdidos e determina a frequência de backup. Com1440minutos (1 dia), os backups são programados para serem executados diariamente.
Crie um backup:
gcloud beta container backup-restore backups create first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --wait-for-completionAguarde a saída mostrar
Backup state: SUCCEEDED.Verifique se o backup foi criado:
gcloud beta container backup-restore backups list \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan
Restaurar com transformação do Hyperdisk
Restaure o backup para um novo cluster. A restauração transforma o armazenamento de Persistent Disk para hiperdisco e move as cargas de trabalho para nós N4.
Crie o cluster de destino do GKE em um nó N4:
gcloud container clusters create ${TARGET_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Crie um pool de nós com tipos de máquina
n4-standard-4, que são necessários para o hiperdisco:gcloud container node-pools create hyperdisk-pool \ --cluster ${TARGET_CLUSTER_PREFIX}-cluster \ --machine-type n4-standard-4 \ --zone ${ZONE} \ --num-nodes 1Receba as credenciais do cluster de destino:
gcloud container clusters get-credentials ${TARGET_CLUSTER_PREFIX}-cluster --zone ${ZONE}Aplique o Hyperdisk
StorageClasschamadobalanced-storage:kubectl apply -f manifests/01-storage-class/storage-class-hdb.yamlO manifesto a seguir define um
StorageClassdo Hyperdisk:Revise as regras de transformação no arquivo
manifests/03-transformation-rule/volume.yaml. Esse arquivo define como os recursos são modificados durante a restauração:- Transformação de PVC:muda o
storageClassNameparabalanced-storage(Hyperdisk). - Transformação de implantação:atualiza a afinidade de nós para programar pods em nós
n4-standard-4.
- Transformação de PVC:muda o
Crie um plano de restauração usando estas regras de transformação:
gcloud beta container backup-restore restore-plans create main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${TARGET_CLUSTER_PREFIX}-cluster \ --namespaced-resource-restore-mode=merge-replace-on-conflict \ --all-namespaces \ --cluster-resource-conflict-policy=use-existing-version \ --cluster-resource-scope-selected-group-kinds=cluster-resource-scope-all-group-kinds \ --volume-data-restore-policy=restore-volume-data-from-backup \ --transformation-rules-file=manifests/03-transformation-rule/volume.yamlFaça a restauração:
gcloud beta container backup-restore restores create first-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --restore-plan=main-restore \ --backup=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan/backups/first-backup
Verificar a migração
Verifique se os aplicativos estão sendo executados no novo cluster e se os dados estão intactos.
Verifique se os pods estão em execução:
kubectl get pods -AConecte-se ao pod cliente do MySQL no novo cluster:
# Verify that the client Pod is running kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300s kubectl exec -it mysql-client -- bashVerifique o banco de dados Sakila restaurado em
namespace-a:mysql -u root -h mysql-a.namespace-a -p # Password: migration USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Verifique o banco de dados World restaurado em
namespace-b:mysql -u root -h mysql-b.namespace-b -p # Password: migration USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Exclua os clusters do GKE:
gcloud container clusters delete ${KUBERNETES_CLUSTER_PREFIX}-cluster --location ${ZONE} --quiet gcloud container clusters delete ${TARGET_CLUSTER_PREFIX}-cluster --location ${ZONE} --quietExclua os planos de backup e restauração:
# Delete the restore plan gcloud beta container backup-restore restore-plans delete main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet # Delete the Backup gcloud beta container backup-restore backups delete first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --quiet # Delete the backup plan gcloud beta container backup-restore backup-plans delete main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet
A seguir
- Saiba mais sobre o Backup para GKE.
- Leia sobre os pools de armazenamento do Hyperdisk.