
Ce tutoriel explique comment migrer des applications avec état dans GKE depuis des types de machines d'ancienne génération, tels que N2, avec des volumes Persistent Disk associés, vers des types de machines de nouvelle génération, tels que N4, avec des volumes Hyperdisk associés, à l'aide de Backup for GKE. Pour en savoir plus sur les types de machines compatibles avec Hyperdisk, consultez la documentation Compute Engine.
Pour illustrer la migration, ce tutoriel utilise la base de données Sakila et la base de données World pour fournir des exemples d'ensembles de données. Sakila est un exemple de base de données fourni par MySQL qui représente un magasin de location de DVD fictif. La base de données "World" contient des données sur les pays et les villes. Le tutoriel utilise deux ensembles de données différents dans des espaces de noms distincts pour simuler un environnement mutualisé complexe.
Ce tutoriel s'adresse aux spécialistes et administrateurs du stockage qui créent et allouent du stockage, et qui gèrent la sécurité des données et l'accès aux données. Pour en savoir plus sur les rôles courants et les exemples de tâches que nous citons dans le contenu Google Cloud, consultez Rôles utilisateur et tâches courantes de GKE.
Architecture de déploiement
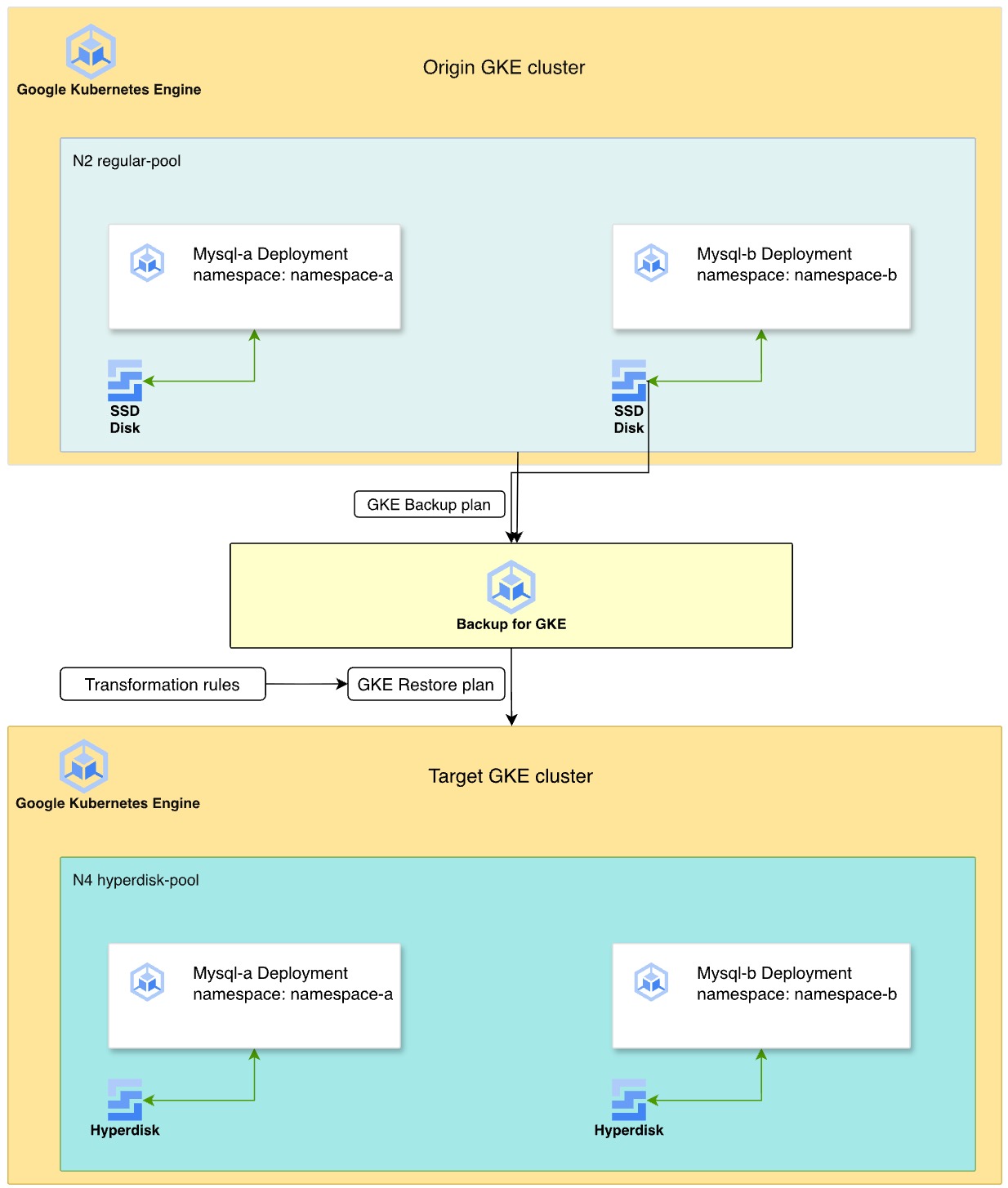
Le schéma suivant illustre le processus d'utilisation de Sauvegarde pour GKE pour migrer des charges de travail MySQL avec état depuis un disque persistant sur des types de machines N2 vers un disque Hyperdisk sur des types de machines N4.
- Cluster d'origine : deux déploiements MySQL résident dans des espaces de noms distincts,
namespace-aetnamespace-b, sur un pool de nœuds de la série de machines N2. Ces déploiements utilisent un disque persistant SSD pour le stockage des données. - Stratégie de sauvegarde : vous activez l'agent Sauvegarde pour GKE sur le cluster et créez un plan de sauvegarde pour capturer les espaces de noms, les données de volume et les secrets. Ensuite, vous exécutez une sauvegarde manuelle pour créer un point de récupération à un moment précis.
- Transformation et restauration : vous définissez un plan de restauration à l'aide de règles de transformation pour adapter les ressources à l'environnement cible.
Ces règles permettent d'effectuer les opérations suivantes :
- Remplacez le
StorageClassdepremium-rwo(PD) par une classe de stockage Hyperdisk nomméebalanced-storage. - Modifiez les règles d'affinité de pods pour vous assurer que les charges de travail restaurées sont planifiées sur un nouveau pool de nœuds N4.
- Remplacez le
- Environnement cible : vous provisionnez un nouveau cluster GKE avec des types de machines N4. Le processus de restauration recrée les disques en tant que volumes Hyperdisk à partir de la sauvegarde et déploie les instances MySQL sur les nœuds N4 compatibles.
Objectifs
Dans ce tutoriel, vous allez apprendre à effectuer les opérations suivantes :
- Préparez les applications avec état GKE pour la sauvegarde.
- Activez le module complémentaire Sauvegarde pour GKE.
- Créez un plan de sauvegarde et sauvegardez le cluster source.
- Créez un plan de restauration qui utilise des règles de transformation pour migrer le stockage vers Hyperdisk.
- Restaurez la charge de travail sur un nouveau cluster et vérifiez les données.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- GKE
- Compute Engine (Persistent Disk and Hyperdisk)
- Backup for GKE
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Assurez-vous de disposer des rôles suivants sur le projet : roles/container.admin, roles/iam.serviceAccountAdmin, roles/compute.admin, roles/gkebackup.admin, roles/monitoring.viewer
Vérifier les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
-
Dans la colonne Compte principal, recherchez toutes les lignes qui vous identifient ou identifient un groupe dont vous faites partie. Pour savoir à quels groupes vous appartenez, contactez votre administrateur.
- Pour toutes les lignes qui vous spécifient ou vous incluent, consultez la colonne Rôle pour vous assurer que la liste inclut les rôles requis.
Attribuer les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
- Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez votre identifiant utilisateur. Il s'agit généralement de l'adresse e-mail d'un compte Google.
- Cliquez sur Sélectionner un rôle, puis recherchez le rôle.
- Pour attribuer des rôles supplémentaires, cliquez sur Ajouter un autre rôle et ajoutez tous les rôles supplémentaires.
- Cliquez sur Enregistrer.
-
Configurer Cloud Shell
-
Dans la console Google Cloud , activez Cloud Shell.
Une session Cloud Shell démarre et affiche une invite de ligne de commande. L'initialisation de la session peut prendre quelques secondes.
- Définissez le projet par défaut :
gcloud config set project PROJECT_IDRemplacez
PROJECT_IDpar l'ID du projet.
Configurer l'environnement
Dans cette section, vous allez préparer les variables d'environnement et cloner l'exemple de dépôt.
Définissez les variables d'environnement pour votre projet, les noms de cluster et la zone :
export PROJECT_ID=PROJECT_ID export KUBERNETES_CLUSTER_PREFIX=backup-gke-migration export TARGET_CLUSTER_PREFIX=restore-gke-migration export ZONE=us-central1-aRemplacez
PROJECT_IDpar l'ID de votre projet Google Cloud.Clonez l'exemple de dépôt de code et accédez au répertoire :
git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples cd kubernetes-engine-samples/databases/backup-migration
Créer le cluster GKE source
Créez un cluster zonal avec un pool de nœuds qui utilise des types de machines N2 et des volumes de disque persistant associés.
Créez le cluster :
gcloud container clusters create ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Créez un pool de nœuds avec des types de machines
n2-standard-4pour la charge de travail source :gcloud container node-pools create regular-pool \ --cluster ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --machine-type n2-standard-4 \ --zone ${ZONE} \ --num-nodes 1Activez le module complémentaire Sauvegarde pour GKE sur le cluster source :
gcloud container clusters update ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE} \ --update-addons=BackupRestore=ENABLEDObtenez les identifiants du cluster :
gcloud container clusters get-credentials ${KUBERNETES_CLUSTER_PREFIX}-cluster --zone ${ZONE}Vérifiez que l'agent Sauvegarde pour GKE est activé :
gcloud container clusters describe ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE}La sortie ressemble à ce qui suit et confirme que l'agent de sauvegarde est activé :
addonsConfig: gkeBackupAgentConfig: enabled: true
Déployer MySQL avec des exemples de données
Déployez deux bases de données MySQL dans des espaces de noms distincts pour simuler un environnement de production.
Créez les espaces de noms
namespace-aetnamespace-b:kubectl create namespace namespace-a kubectl create namespace namespace-bDéployez les charges de travail MySQL dans
namespace-aetnamespace-b:Déployez le fichier
mysql-a-deployment.yaml:kubectl apply -f manifests/02-mysql/mysql-a-deployment.yaml -n namespace-aLe fichier manifeste suivant crée un pod MySQL dans
namespace-aavec des disques SSD Persistent Disk provisionnés de manière dynamique sur les nœudsregular-pool. Le mot de passe racine est défini surmigration:Déployez le fichier
mysql-b-deployment.yaml:kubectl apply -f manifests/02-mysql/mysql-b-deployment.yaml -n namespace-bLe fichier manifeste suivant crée un pod MySQL dans
namespace-bavec des disques SSD Persistent Disk provisionnés de manière dynamique sur les nœudsregular-pool. Le mot de passe racine est défini surmigration:
Déployez un pod client MySQL pour importer des exemples de jeux de données :
kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300sLe fichier manifeste suivant déploie un pod client MySQL :
Connectez-vous au pod client :
kubectl exec -it mysql-client -- bashDans le pod, téléchargez les exemples d'ensembles de données Sakila et World :
curl --output dataset.tgz "https://downloads.mysql.com/docs/sakila-db.tar.gz" tar -xvzf dataset.tgz -C ./ curl --output world-db.tar.gz "https://downloads.mysql.com/docs/world-db.tar.gz" tar xvzf world-db.tar.gz -C ./Importez l'ensemble de données Sakila dans la base de données
mysql-a:mysql -u root -h mysql-a.namespace-a -p # Enter password: migration SOURCE /sakila-db/sakila-schema.sql; SOURCE /sakila-db/sakila-data.sql;Vérifiez les données Sakila importées :
USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Quittez MySQL :
exitImportez l'ensemble de données "World" dans la base de données
mysql-b:mysql -u root -h mysql-b.namespace-b -p # Enter password: migration SOURCE /world-db/world.sql;Vérifiez les données "World" importées :
USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';Le résultat ressemble à ce qui suit :
+-----------------+------------+ | table_name | table_rows | +-----------------+------------+ | city | 4079 | | country | 239 | | countrylanguage | 984 | +-----------------+------------+Quittez MySQL :
exitQuittez le shell du pod client :
exit
Sauvegarder le cluster GKE
Sauvegardez l'intégralité du cluster, y compris les secrets et les volumes.
Créez un plan de sauvegarde :
gcloud beta container backup-restore backup-plans create main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${KUBERNETES_CLUSTER_PREFIX}-cluster \ --selected-namespaces=namespace-a,namespace-b,default \ --include-secrets \ --include-volume-data \ --target-rpo-minutes=1440 \ --backup-retain-days=7 \ --backup-delete-lock-days=3 \ --locked--selected-namespaces: sauvegarde des espaces de noms spécifiques pour éviter les conflits avec les ressources système.--include-volume-data: permet de s'assurer que les données du disque persistant sont sauvegardées.--target-rpo-minutes: configure le calendrier de sauvegarde basé sur l'objectif de point de récupération (RPO). Le RPO correspond à la durée maximale acceptable pendant laquelle des données peuvent être perdues. Il détermine la fréquence des sauvegardes. Avec1440minutes (1 jour), les sauvegardes sont programmées pour s'exécuter quotidiennement.
Créez une sauvegarde :
gcloud beta container backup-restore backups create first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --wait-for-completionAttendez que le résultat
Backup state: SUCCEEDEDs'affiche.Vérifiez que la sauvegarde a été créée :
gcloud beta container backup-restore backups list \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan
Restaurer avec la transformation Hyperdisk
Restaurez la sauvegarde sur un nouveau cluster. La restauration transforme le stockage de disque persistant en Hyperdisk et déplace les charges de travail vers les nœuds N4.
Créez le cluster GKE cible sur un nœud N4 :
gcloud container clusters create ${TARGET_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Créez un pool de nœuds avec des types de machines
n4-standard-4, qui sont requis pour Hyperdisk :gcloud container node-pools create hyperdisk-pool \ --cluster ${TARGET_CLUSTER_PREFIX}-cluster \ --machine-type n4-standard-4 \ --zone ${ZONE} \ --num-nodes 1Obtenez les identifiants du cluster cible :
gcloud container clusters get-credentials ${TARGET_CLUSTER_PREFIX}-cluster --zone ${ZONE}Appliquez l'Hyperdisk
StorageClassnommébalanced-storage:kubectl apply -f manifests/01-storage-class/storage-class-hdb.yamlLe fichier manifeste suivant définit un
StorageClassHyperdisk :Examinez les règles de transformation dans le fichier
manifests/03-transformation-rule/volume.yaml. Ce fichier définit la façon dont les ressources sont modifiées lors de la restauration :- Transformation des PVC : remplace
storageClassNameparbalanced-storage(Hyperdisk). - Transformation du déploiement : met à jour l'affinité de nœud pour planifier les pods sur les nœuds
n4-standard-4.
- Transformation des PVC : remplace
Créez un plan de restauration à l'aide des règles de transformation suivantes :
gcloud beta container backup-restore restore-plans create main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${TARGET_CLUSTER_PREFIX}-cluster \ --namespaced-resource-restore-mode=merge-replace-on-conflict \ --all-namespaces \ --cluster-resource-conflict-policy=use-existing-version \ --cluster-resource-scope-selected-group-kinds=cluster-resource-scope-all-group-kinds \ --volume-data-restore-policy=restore-volume-data-from-backup \ --transformation-rules-file=manifests/03-transformation-rule/volume.yamlEffectuez la restauration :
gcloud beta container backup-restore restores create first-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --restore-plan=main-restore \ --backup=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan/backups/first-backup
Vérifier la migration
Vérifiez que les applications s'exécutent sur le nouveau cluster et que les données sont intactes.
Vérifiez si les pods sont en cours d'exécution :
kubectl get pods -AConnectez-vous au pod client MySQL sur le nouveau cluster :
# Verify that the client Pod is running kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300s kubectl exec -it mysql-client -- bashVérifiez que la base de données Sakila a été restaurée dans
namespace-a:mysql -u root -h mysql-a.namespace-a -p # Password: migration USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Vérifiez la base de données World restaurée dans
namespace-b:mysql -u root -h mysql-b.namespace-b -p # Password: migration USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimez les clusters GKE :
gcloud container clusters delete ${KUBERNETES_CLUSTER_PREFIX}-cluster --location ${ZONE} --quiet gcloud container clusters delete ${TARGET_CLUSTER_PREFIX}-cluster --location ${ZONE} --quietSupprimez les plans de sauvegarde et de restauration :
# Delete the restore plan gcloud beta container backup-restore restore-plans delete main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet # Delete the Backup gcloud beta container backup-restore backups delete first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --quiet # Delete the backup plan gcloud beta container backup-restore backup-plans delete main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet
Étapes suivantes
- En savoir plus sur Sauvegarde pour GKE
- En savoir plus sur les pools de stockage Hyperdisk