透過自訂連接器,您可以整合 Gemini Enterprise 標準連接器程式庫以外的外部資料來源,讓貴機構的專屬資料可供搜尋,並透過 Gemini 和 Google 的進階搜尋智慧功能,以自然語言存取。自訂連接器會直接與 Discovery Engine API 互動,提供強大的資料儲存、索引和智慧搜尋功能。連結器會將來源資訊轉換為標準化的 JSON 文件格式 (結構化內容、中繼資料和存取控制清單 (ACL)),並確保這些資料會整理到資料存放區。這些商店會做為邏輯存放區,理想上代表單一文件格式,各自有專屬的搜尋索引和設定。
自訂連結器的運作方式
自訂連接器會使用自動化資料管道執行三項主要動作:擷取、轉換和同步。這個程序可確保外部資料正確準備並上傳至 Gemini Enterprise。
擷取:連結器會使用 API、資料庫或檔案格式,從外部系統提取資料,包括文件、中繼資料和權限。
轉換:連結器會將原始資料轉換為 Discovery Engine 的文件格式、建構內容和中繼資料,並為每份文件指派全域不重複 ID。如要進行存取權控管,您可以直接使用 Google 辨識的身分,或是對外部使用者或自訂群組進行身分對應。
同步:連結器會將文件上傳至 Gemini Enterprise 資料儲存庫,並透過排定的工作保持最新狀態。資料同步作業是使用為實體建立的資料儲存庫執行。如要進一步瞭解如何建立資料商店,請參閱「資料商店建立程序」。根據需求選擇同步模式:「增量」會新增及更新資料,「完整」則會取代整個資料集。
存取控制清單和身分對應
如要管理文件層級的存取權,請根據資料使用的身分識別格式,選擇「純 ACL」或「身分識別對應」這兩種方法。
純 ACL (AclInfo):如果資料來源使用 (Google Cloud) 可辨識的電子郵件身分,請使用這個方法。這種做法非常適合直接定義存取權。
識別資訊對應:如果資料來源使用使用者名稱、舊版 ID 或其他外部身分識別系統,請使用這個方法:
這項功能會在外部身分群組 (例如 EXT1) 和內部識別資訊提供者 (IDP) 使用者或群組 (例如
IDPUser1@example.com)。這樣一來,系統就能瞭解並套用來源系統中以群組為準的存取權控管,這在 API 傳回群組標籤 (不含完整使用者成員資格) 時,或是在不列出每個文件數千名使用者的情況下有效率地擴充 ACL 時,都非常實用。
身分 ID 對應程序需要將所有巢狀或階層式身分 ID 結構,解析為直接對應的平面清單,通常採用指定的 JSON 格式。
使用專屬的外部身分群組 ID (例如 EXT1),以維護系統完整性。如需更多資訊和範例,請參閱「對應外部身分」。
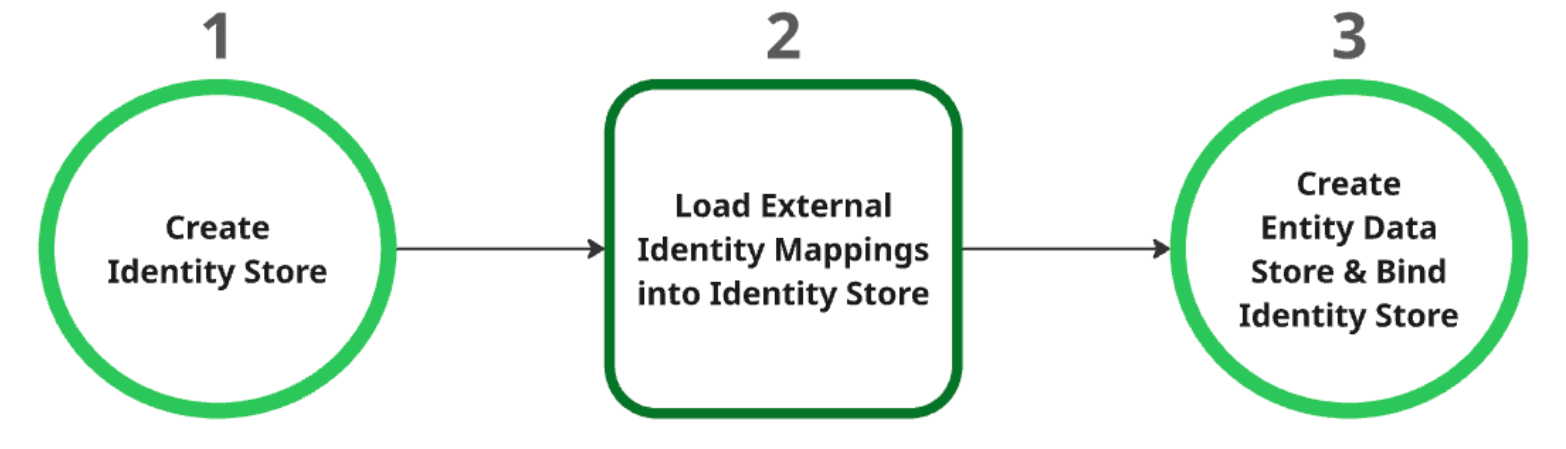
資料儲存庫建立程序
建立身分識別儲存空間:這個儲存空間會做為所有身分識別對應的父項資源。建立專案時,系統會自動擷取專案層級的識別資訊提供者 (IDP) 設定。詳情請參閱「擷取或建立身分識別存放區」。
將外部身分識別對應載入身分識別儲存區:建立身分識別儲存區後,請將外部身分識別資料載入其中。詳情請參閱「將身分對應資料匯入身分存放區」。
建立及繫結實體資料儲存庫:實體資料儲存庫只能在成功建立身分識別儲存庫並載入身分識別對應後建立。您必須在建立實體資料儲存庫時,將識別資訊儲存庫繫結至該儲存庫。如要進一步瞭解如何建立實體資料儲存庫,請參閱「建立資料儲存庫」。
同步處理資料
同步資料有兩種不同的架構模型:
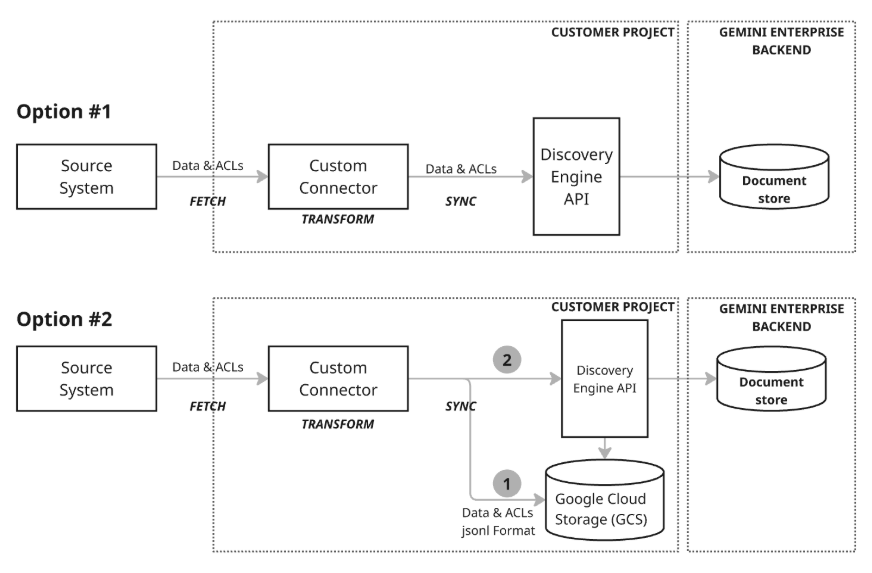
架構模型 1:遞增 upsert:遞增 upsert 方法最適合用於資料串流,且需要即時更新的案例。連接器會運用 Discovery Engine API,在發生小幅變更時呼叫適當的函式,以執行有效率的增量 upsert (插入或更新資料)。這種做法著重於盡量縮小變更大小和延遲時間,即使資料快速變更,也能確保文件儲存空間維持最新狀態。
架構模型 2:與 Google Cloud Storage 全面同步:建議採用這種做法,因為它提供全方位的資料管理功能,且彈性極高。這項功能支援完整同步,可讓您在整個資料集中插入、更新及刪除資料;也支援增量同步,只會傳送變更內容,處理插入和更新作業。因此,這種方法可滿足各種資料需求,特別是管理較大型或較複雜的資料作業。這個模型會使用暫存程序 (圖表中的步驟 1),由連接器先將資料寫入 Google Cloud Storage (GCS),然後從暫存的 GCS 位置呼叫必要的匯入函式,藉此運用 Discovery Engine API 更新文件存放區。
自訂連接器彈性十足,可支援混合式架構,讓您針對快速變更的資料實作漸進式 upsert,並針對排定的完整資料更新或刪除作業,實作全面同步。