Custom connectors let you integrate external data sources that fall outside the Gemini Enterprise standard connector library, making your organization's unique data searchable and accessible using natural language, powered by Gemini and Google's advanced search intelligence. The custom connector interacts directly with the Discovery Engine API, which enables robust data storage, indexing, and intelligent search capabilities. The connector converts the source information into the standardized JSON-based Document format (structuring the content, metadata, and Access Control Lists (ACLs)) and ensures this data is organized into Data stores. These stores act as logical repositories, ideally representing a single document format, each with its own dedicated search index and configurations.
How custom connectors work
Custom connectors work by using an automated data pipeline to perform three key actions: Fetch, Transform, and Sync. This process ensures external data is correctly prepared and uploaded to Gemini Enterprise.
Fetch: The connector pulls data, including documents, metadata, and permissions, from external system using its APIs, databases, or file formats.
Transform: The connector converts raw data into the document format of the Discovery Engine, structures the content and metadata, and assigns a globally unique ID to each document. For access controls, you can use either Google-recognized identities directly or identity mapping for external users or custom groups.
Sync: The connector uploads the documents to Gemini Enterprise data stores and keeps them updated through scheduled jobs. The data sync is performed using a data store created for an entity. For more information about creating data store, see Data store creation process. Choose a sync mode based on your needs: Incremental adds and updates data, while Full replaces the entire dataset.
ACLs and Identity mapping
To manage document-level access, choose between two methods — Pure ACLs or Identity Mapping, depending on the identity format used by the data.
Pure ACLs (AclInfo): This method is used when the data source uses email-based identities recognized by (Google Cloud). This approach is ideal for directly defining who has access.
Identity mapping: This method is used when the data source uses usernames, legacy IDs, or other external identity systems:
It establishes a clear and one-to-one association between external identity groups (e.g., EXT1) and internal Identity Provider (IDP) users or groups (e.g.,
IDPUser1@example.com).It allows the system to understand and apply group-based access controls from the source system, which is useful when an API returns group labels without full user memberships or for efficiently scaling ACLs without listing thousands of users per document.
The identity mapping process requires resolving all nested or hierarchical identity structures into a flat list of direct mappings, typically in a specified JSON format.
Use unique external identity group IDs (e.g., EXT1) for external identities to maintain system integrity. For more information and examples, see Map external identities.
Data store creation process
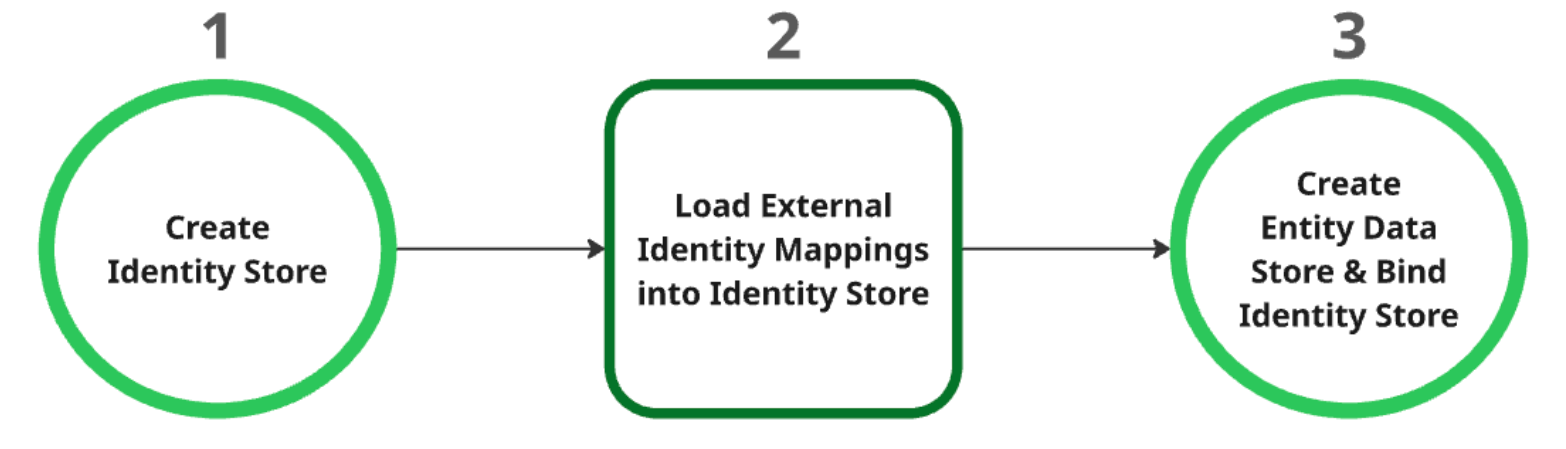
Create the identity store: This store acts as the parent resource for all identity mappings. Upon creation, project-level Identity Provider (IDP) settings are automatically fetched. For more information, see Retrieve or create identity store.
Load external identity mappings into identity store: After creating the identity store, load the external identity data into it. For more information, see Ingest identity mapping into identity store.
Create and bind the entity data store: The entity data store can only be created after the identity store is successfully created and the identity mappings are loaded. You must bind the identity store to the entity data store during its creation. For more information about creating entity data store, see Create data store.
Data sync
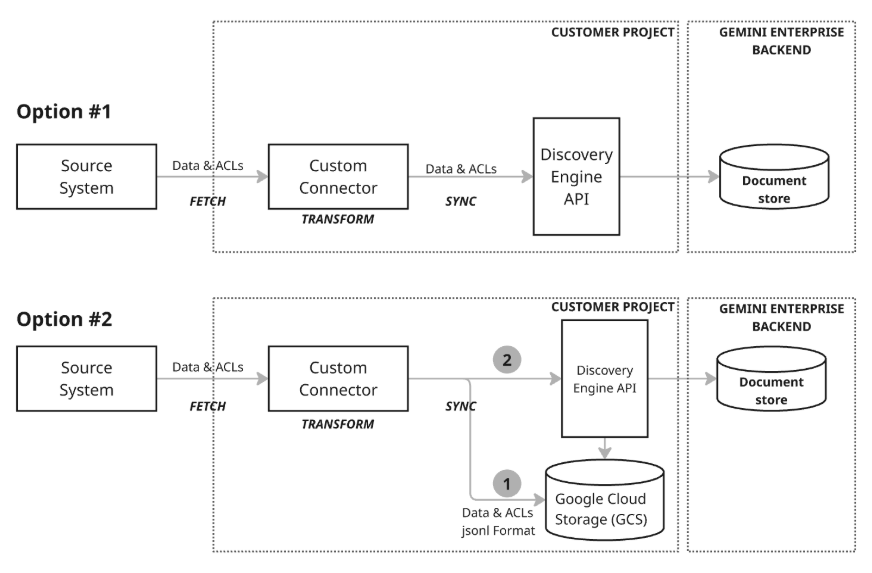
There are two different architecture models for syncing data:
Architecture Model 1: Incremental upsert: The incremental upsert approach is best suited for scenarios where data is streaming and requires real-time updates. The connector leverages the Discovery Engine API to perform efficient, incremental upserts (inserting or updating data) by calling the appropriate functions with small changes as they occur. This focus on minimal change sizes and minimal delay keeps the document store highly current, even with fast-changing data.
Architecture Model 2: Comprehensive sync with Google Cloud Storage: This recommended approach offers a comprehensive set of data management features and high flexibility. It supports full syncs, which allow for data insertion, updating, and deletion across the entire dataset, and incremental syncs, which handle only inserts and updates by sending changes. This makes the approach robust for a wide range of data needs, particularly for managing larger or more complex data operations. This model utilizes a staging process (step 1 in the diagram) where the connector first writes the data to Google Cloud Storage (GCS), then leverages the Discovery Engine API to update the document store by calling the necessary import functions from the staged GCS location.
Custom connectors are flexible enough to support a hybrid architecture, allowing you to implement incremental upsert for fast-changing data and comprehensive sync for scheduled full data updates or deletions.