
במדריך הזה מוסבר איך לפרוס ולנהל מערכת מסד נתונים של Microsoft SQL Server בשני Google Cloud אזורים כפתרון לשחזור מאסון (DR), ואיך לבצע מעבר אוטומטי ממכונה של מסד נתונים שנכשלה למכונה שפועלת כרגיל. לצורך המסמך הזה, אסון הוא אירוע שבו מסד נתונים ראשי נכשל או הופך ללא זמין.
מסד נתונים ראשי עלול להיכשל אם האזור שבו הוא ממוקם נכשל או הופך ללא נגיש. גם אם אזור זמין ופועל כרגיל, יכול להיות שמסד נתונים ראשי ייכשל בגלל שגיאת מערכת. במקרים כאלה, תהליך ההתאוששות מאסון (DR) הוא תהליך שבו מסד נתונים משני הופך לזמין ללקוחות כדי להמשיך את העיבוד.
המדריך הזה מיועד למומחי ארכיטקטורת מסדי נתונים, לאדמינים ולמהנדסים.
מטרות
- פריסת סביבה להתאוששות מאסון במספר אזורים ב-Google Cloud באמצעות קבוצות זמינות AlwaysOn של Microsoft SQL Server.
- מדמים אירוע אסון ומבצעים תהליך מלא של התאוששות מאסון כדי לאמת את ההגדרה של התאוששות מאסון.
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
כשמסיימים את המשימות שמתוארות במסמך הזה אפשר למחוק את המשאבים שיצרתם כדי להימנע מחיובים נוספים. מידע נוסף זמין בקטע הסרת המשאבים.
לפני שמתחילים
במדריך הזה תצטרכו פרויקט Google Cloud . אפשר ליצור פרויקט חדש או לבחור פרויקט שכבר יצרתם:
-
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
במסוף Google Cloud , מפעילים את Cloud Shell.
הסבר על תוכנית התאוששות מאסון (DR)
ב- Google Cloud, תוכנית התאוששות מאסון (DR) נועדה לספק המשכיות של העיבוד, במיוחד כשקורה כשל באזור או כשאין גישה לאזור. במערכות כמו מערכת לניהול מסדי נתונים, מטמיעים DR על ידי פריסת המערכת בשני אזורים לפחות. במקרה כזה, המערכת ממשיכה לפעול אם אזור אחד לא זמין.
תוכנית התאוששות מאסון (DR) למערכת מסד נתונים
התהליך של הפיכת מסד נתונים משני לזמין כשמופע מסד הנתונים הראשי נכשל נקרא התאוששות מאסון (DR) של מסד נתונים. לדיון מפורט על הקונספט הזה, אפשר לעיין במאמר שחזור אחרי אסון ב-Microsoft SQL Server. באופן אידיאלי, מצב מסד הנתונים המשני עקבי עם מסד הנתונים הראשי בנקודה שבה מסד הנתונים הראשי הופך ללא זמין, או שמסד הנתונים המשני חסר רק קבוצה קטנה של עסקאות אחרונות ממסד הנתונים הראשי.
ארכיטקטורה של תוכנית התאוששות מאסון (DR)
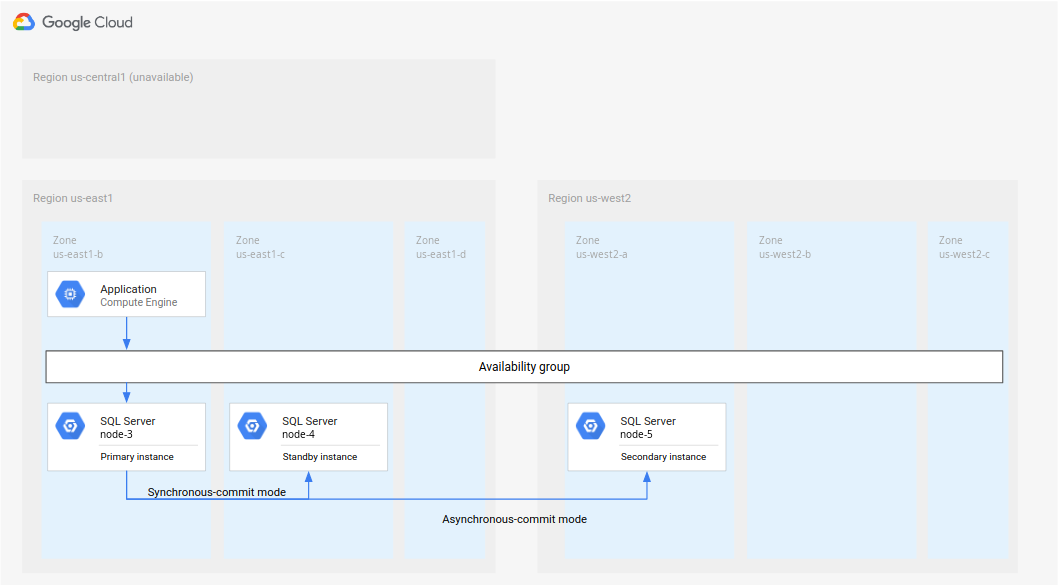
בתרשים הבא מוצגת ארכיטקטורה מינימלית של Microsoft SQL Server שתומכת ב-DR של מסד נתונים.
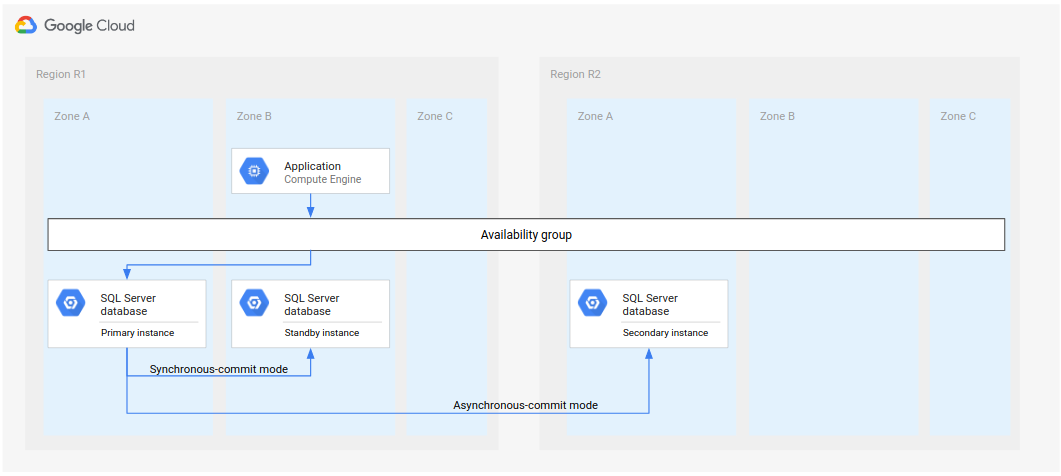
איור 1. ארכיטקטורה סטנדרטית של התאוששות מאסון (DR) עם Microsoft SQL Server.
הארכיטקטורה הזו פועלת באופן הבא:
- שני מופעים של Microsoft SQL Server (מופע ראשי ומופע בהמתנה) ממוקמים באותו אזור (R1), אבל באזורים שונים (אזור A ואזור B). שני המקרים ב-R1 מתאמים את המצבים שלהם באמצעות מצב synchronous-commit. השימוש במצב סינכרוני נובע מהתמיכה שלו בזמינות גבוהה ומהשמירה על מצב נתונים עקבי.
- מופע אחד של Microsoft SQL Server (המופע המשני או המופע לשחזור אחרי אסון) נמצא באזור שני (R2). לצורך DR, המכונה המשנית ב-R2 מסתנכרנת עם המכונה הראשית ב-R1 באמצעות מצב asynchronous-commit. השימוש במצב אסינכרוני נובע מהביצועים שלו (הוא לא מאט את עיבוד השמירה במופע הראשי).
בתרשים שלמעלה מוצגת ארכיטקטורה עם קבוצת זמינות. קבוצת הזמינות, אם משתמשים בה עם מאזין, מספקת את אותו מחרוזת חיבור ללקוחות אם הלקוחות מקבלים שירות מהמקרים הבאים:
- המכונה הראשית
- המופע במצב המתנה (אחרי כשל באזור)
- המופע המשני (אחרי כשל באזור ואחרי שהמופע המשני הופך למופע הראשי החדש)
בווריאציה של הארכיטקטורה שלמעלה, אתם פורסים את שני המופעים שנמצאים באזור הראשון (R1) באותו אזור. הגישה הזו עשויה לשפר את הביצועים, אבל היא לא זמינה מאוד. יכול להיות שיידרש הפסקת פעילות באזור יחיד כדי להתחיל את תהליך ה-DR.
תהליך בסיסי של התאוששות מאסון (DR)
תהליך ה-DR מתחיל כשאי אפשר לגשת לאזור מסוים, ומסד הנתונים הראשי עובר למצב failover כדי להמשיך את העיבוד באזור פעיל אחר. תהליך ה-DR קובע את השלבים התפעוליים שצריך לבצע, באופן ידני או אוטומטי, כדי לצמצם את ההשפעה של הכשל באזור ולהקים מופע ראשי פעיל באזור זמין.
תהליך בסיסי של DR למסד נתונים כולל את השלבים הבאים:
- האזור הראשון (R1), שבו פועל מופע מסד הנתונים הראשי, הופך ללא זמין.
- צוות התפעול מזהה את האסון ומאשר אותו באופן רשמי, ומחליט אם נדרשת יתירות כשל.
- אם נדרש מעבר לגיבוי, מופע מסד הנתונים המשני באזור השני (R2) הופך למופע הראשי החדש.
- הלקוחות ממשיכים את העיבוד במסד הנתונים הראשי החדש ויש להם גישה למופע הראשי ב-R2.
למרות שהתהליך הבסיסי הזה יוצר שוב מסד נתונים ראשי תקין, הוא לא יוצר ארכיטקטורת DR מלאה, שבה למסד הנתונים הראשי החדש יש גיבוי ומסד נתונים משני.
השלמת תהליך ההתאוששות מאסון (DR)
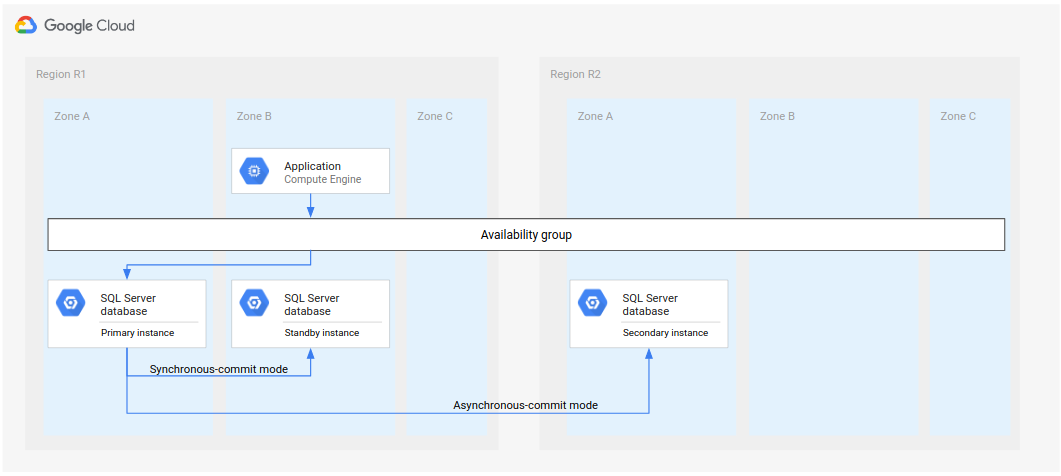
תהליך מלא של DR מרחיב את תהליך ה-DR הבסיסי על ידי הוספת שלבים ליצירת ארכיטקטורת DR מלאה אחרי מעבר לגיבוי. התרשים הבא מציג ארכיטקטורה מלאה של DR למסד נתונים.
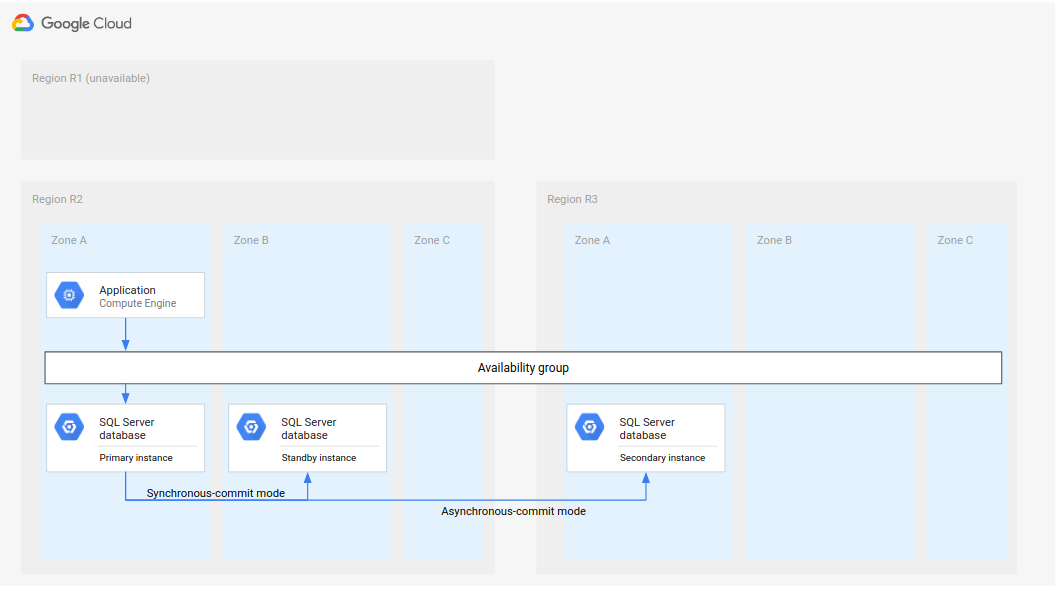
איור 2. תוכנית התאוששות מאסון (DR) עם אזור ראשי לא זמין (R1).
ארכיטקטורת ה-DR המלאה של מסד הנתונים פועלת באופן הבא:
- האזור הראשון (R1), שבו פועל מופע מסד הנתונים הראשי, הופך ללא זמין.
- צוות התפעול מזהה את האסון ומאשר אותו באופן רשמי, ומחליט אם נדרשת יתירות כשל.
- אם נדרש מעבר לגיבוי, מופעלת יצירת מופע של מסד הנתונים המשני באזור השני (R2) בתור המופע הראשי.
- מופע משני נוסף, מופע ההמתנה החדש, נוצר ומופעל ב-R2 ומתווסף למופע הראשי. מופע ההמתנה נמצא באזור אחר מזה של המופע הראשי. מסד הנתונים הראשי כולל עכשיו שני מופעים (ראשי וגיבוי) שזמינים מאוד.
- באזור שלישי (R3), נוצרת ומופעלת אינטס חדש של מסד נתונים משני (במצב המתנה). המופע המשני הזה מחובר באופן אסינכרוני למופע הראשי החדש ב-R2. בשלב הזה, הארכיטקטורה המקורית של התאוששות מאסון נוצרת מחדש ופועלת.
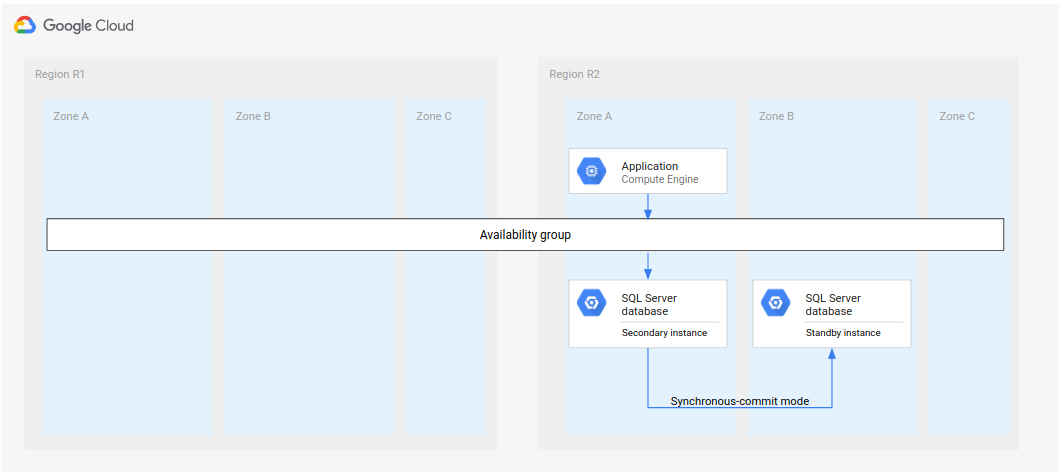
חזרה לאזור משוחזר
אחרי שהאזור הראשון (R1) חוזר למצב אונליין, הוא יכול לארח את מסד הנתונים המשני החדש. אם אזור R1 יהיה זמין מספיק מהר, תוכלו להטמיע את שלב 5 בתהליך השחזור המלא באזור R1 במקום באזור R3 (האזור השלישי). במקרה הזה, לא צריך אזור שלישי.
התרשים הבא מציג את הארכיטקטורה אם R1 יהיה זמין בזמן.
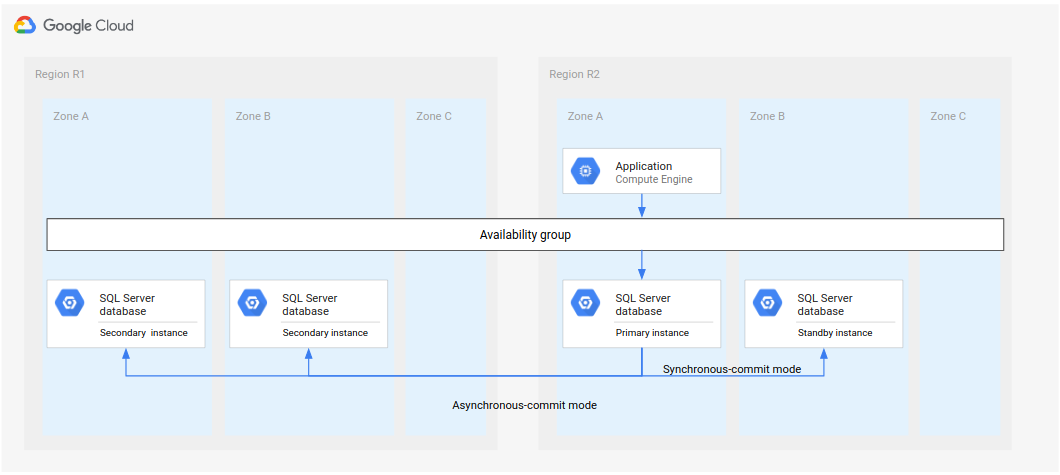
איור 3. שחזור אחרי אסון אחרי שהאזור שנכשל R1 חוזר להיות זמין.
באופן הזה, שלבי ההתאוששות זהים לאלה שמתוארים קודם בתהליך השלם של תוכנית התאוששות מאסון (DR), עם ההבדל ש-R1 הופך למיקום של המכונות המשניות במקום R3.
בחירת מהדורה של SQL Server
המדריך הזה תומך בגרסאות הבאות של Microsoft SQL Server:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- מהדורת SQL Server 2019 Enterprise
- SQL Server 2022 Enterprise Edition
במדריך הזה נעשה שימוש בתכונה AlwaysOn Availability Groups ב-SQL Server.
אם אתם לא צריכים מסד נתונים ראשי של Microsoft SQL Server עם זמינות גבוהה (HA), ומספיק לכם מופע יחיד של מסד נתונים כראשי, אתם יכולים להשתמש בגרסאות הבאות של SQL Server:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
בגרסאות 2016, 2017, 2019 ו-2022 של SQL Server מותקן קובץ האימג' של Microsoft SQL Server Management Studio, כך שלא צריך להתקין אותו בנפרד. עם זאת, בסביבת ייצור מומלץ להתקין מופע אחד של Microsoft SQL Server Management Studio במכונה וירטואלית נפרדת בכל אזור. אם מגדירים סביבת זמינות גבוהה, צריך להתקין את Microsoft SQL Server Management Studio פעם אחת לכל אזור כדי לוודא שהיא תישאר זמינה אם אזור אחר לא יהיה זמין.
הגדרת Microsoft SQL Server ל-DR מרובה אזורים
בקטע הזה נעשה שימוש בתמונות הבאות של Microsoft SQL Server:
-
sql-ent-2016-win-2016ל-Microsoft SQL Server 2016 Enterprise Edition -
sql-ent-2017-win-2016ל-Microsoft SQL Server 2017 Enterprise Edition -
sql-ent-2019-win-2019ל-Microsoft SQL Server 2019 Enterprise Edition -
sql-ent-2022-win-2022ל-Microsoft SQL Server 2022 Enterprise Edition
רשימה מלאה של תמונות זמינה במאמר בנושא תמונות.
הגדרה של אשכול זמינות גבוהה עם שני מופעים
כדי להגדיר ארכיטקטורת DR של מסד נתונים רב-אזורי ל-SQL Server, קודם צריך ליצור אשכול של זמינות גבוהה (HA) עם שני מופעים באזור. מופע אחד משמש כראשי, והמופע השני משמש כמשני. כדי לבצע את השלב הזה, פועלים לפי ההוראות במאמר בנושא הגדרת קבוצות זמינות של SQL Server AlwaysOn.
במדריך הזה נעשה שימוש ב-us-central1 כאזור הראשי (שנקרא R1).
לפני שמתחילים, חשוב לקרוא את הנקודות הבאות:
אם פעלתם לפי השלבים במאמר הגדרת קבוצות זמינות של SQL Server AlwaysOn, יצרתם שני מופעים של SQL Server באותו אזור (
us-central1). פרסתם מופע ראשי של SQL Server (node-1) ב-us-central1-aומופע במצב המתנה (node-2) ב-us-central1-b.למרות שאתם מטמיעים את הארכיטקטורה שבאיור 4 במדריך הזה, מומלץ להגדיר בקר דומיין ביותר מאזור אחד. הגישה הזו מבטיחה שתקימו ארכיטקטורה של מסד נתונים עם זמינות גבוהה (HA) והתאוששות מאסון (DR). לדוגמה, אם מתרחש שיבוש באזור אחד, האזור הזה לא הופך לנקודת כשל יחידה בארכיטקטורה הפרוסה.
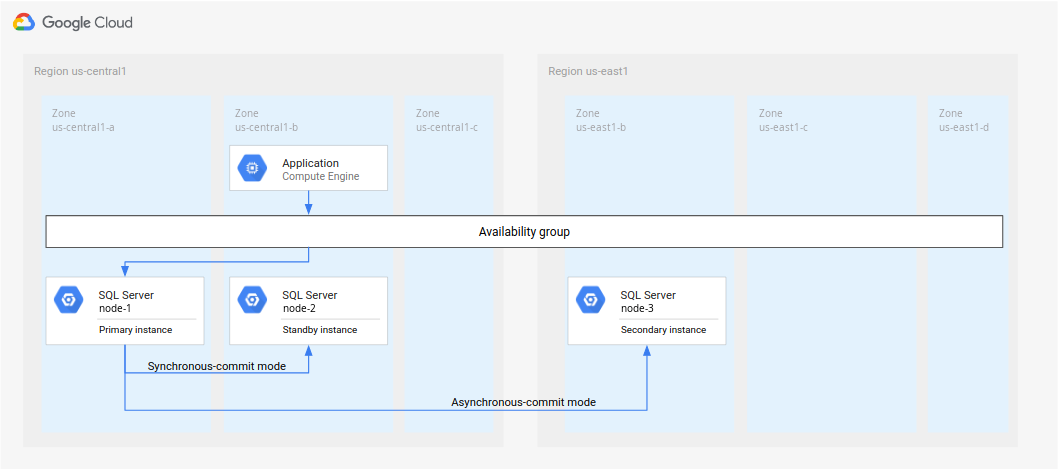
איור 4. ארכיטקטורה סטנדרטית של התאוששות מאסון (DR) שמוטמעת במדריך הזה.
הוספת מופע משני לשחזור לאחר אסון
לאחר מכן מגדירים מופע שלישי של SQL Server (מופע משני שנקרא node-3) ומגדירים את הרשת באופן הבא:
יוצרים סקריפט התמחות עבור הצמתים של Windows Server Failover Cluster. הסקריפט מתקין את התכונה הנדרשת של Windows ויוצר כללי חומת אש עבור WSFC ו-SQL Server. הוא גם מעצב את דיסק הנתונים ויוצר תיקיות של נתונים ויומנים עבור SQL Server:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
מאתחלים את המשתנים הבאים:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8כאשר:
-
VPC_NAME: השם של ה-VPC -
SUBNET_NAME: השם של תת-הרשת באזורus-east1
-
יוצרים מכונה של SQL Server:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1מגדירים סיסמה ל-Windows עבור מופע SQL Server החדש:
במסוף Google Cloud , נכנסים לדף Compute Engine.
בעמודה Connect בשורה של אשכול Compute Engine
node-3, בוחרים באפשרות Set windows password מהרשימה הנפתחת.מגדירים את שם המשתמש והסיסמה. כדאי לרשום אותם לשימוש בהמשך.
לוחצים על RDP כדי להתחבר למופע
node-3.מזינים את שם המשתמש והסיסמה מהשלב הקודם ולוחצים על OK.
מוסיפים את המופע לדומיין Windows:
לוחצים לחיצה ימנית על לחצן ההתחלה (או מקישים על Win+X) ואז לוחצים על Windows PowerShell (Admin).
לוחצים על 'כן' כדי לאשר את ההודעה על העלאת הרשאות.
מצטרפים עם המחשב לדומיין Active Directory ומפעילים מחדש:
Add-Computer -Domain
DOMAIN -Restartמחליפים את
DOMAINבשם ה-DNS של דומיין Active Directory.ממתינים כדקה עד שההפעלה מחדש תסתיים.
הוספת המופע המשני לאשכול המעבר לגיבוי בעת כשל
לאחר מכן, מוסיפים את המופע המשני (node-3) לאשכול Windows failover:
מתחברים למופעים
node-1אוnode-2באמצעות RDP ונכנסים בתור משתמש אדמין.פותחים חלון PowerShell בתור משתמש אדמין ומגדירים משתנים לסביבת האשכול במדריך הזה:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of clusterמחליפים את
SQLSRV_CLUSTERבשם של אשכול SQL Server.מוסיפים את המופע המשני לאשכול:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3יכול להיות שיעבור זמן עד שהפקודה הזו תפעל. התהליך עלול להפסיק להגיב ולא לחזור באופן אוטומטי, לכן מדי פעם צריך ללחוץ על
Enter.בצומת, מפעילים את התכונה AlwaysOn זמינות גבוהה:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
הצומת הוא עכשיו חלק מאשכול המעבר לגיבוי.
הוספת המופע המשני לקבוצת הזמינות הקיימת
לאחר מכן, מוסיפים את המופע של SQL Server (המופע המשני) ואת מסד הנתונים לקבוצת הזמינות:
מתחברים אל
node-3באמצעות Remote Desktop. נכנסים באמצעות חשבון המשתמש בדומיין.פותחים את SQL Server Configuration Manager.
בחלונית הניווט, בוחרים באפשרות SQL Server Services (שירותי SQL Server).
ברשימת השירותים, לוחצים לחיצה ימנית על SQL Server (MSSQLSERVER) ובוחרים באפשרות Properties (מאפיינים).
בקטע כניסה בתור, משנים את החשבון:
- שם החשבון:
DOMAIN\sql_serverכאשרDOMAINהוא שם NetBIOS של דומיין Active Directory. - סיסמה: מזינים את הסיסמה שבחרתם קודם לחשבון הדומיין sql_server.
- שם החשבון:
לוחצים על OK.
כשמופיעה בקשה להפעלה מחדש של SQL Server, בוחרים באפשרות כן.
באחד משלושת צמתי המכונות
node-1,node-2אוnode-3, פותחים את Microsoft SQL Server Management Studio ומתחברים למכונה הראשית –node-1.- עוברים אל Object Explorer.
- לוחצים על הרשימה הנפתחת Connect (קישור).
- בוחרים באפשרות מנוע מסד נתונים.
- מהרשימה הנפתחת שם השרת, בוחרים באפשרות
node-1. אם האשכול לא מופיע ברשימה, מזינים אותו בשדה.
לוחצים על שאילתה חדשה.
מדביקים את הפקודה הבאה כדי להוסיף כתובת IP למאזין שמשמש את הצומת, ואז לוחצים על Execute (ביצוע):
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))מחליפים את
LOAD_BALANCER_IP_ADDRESSבכתובת ה-IP של מאזן העומסים באזורus-east1.ב-Object Explorer, מרחיבים את הצומת AlwaysOn High Availability ואז מרחיבים את הצומת Availability Groups.
לוחצים לחיצה ימנית על קבוצת הזמינות שנקראת
bookshelf-ag, ואז בוחרים באפשרות הוספת עותק משוכפל.בדף Introduction, לוחצים על הצומת AlwaysOn High Availability ואז על הצומת Availability Groups.
בדף Connect to Replicas (חיבור לרפליקות), לוחצים על Connect (חיבור) כדי להתחבר לרפליקה המשנית הקיימת
node-2.בדף Specify Replicas (ציון רפליקות), לוחצים על Add Replica (הוספת רפליקה) ואז מוסיפים את הצומת החדש
node-3. לא בוחרים באפשרות מעבר גיבוי אוטומטי כי מעבר גיבוי אוטומטי גורם לביצוע מחויבות סינכרונית. הגדרה כזו חוצה גבולות אזוריים, ואנחנו לא ממליצים על כך.בדף Select Data Synchronization (בחירת סנכרון נתונים), בוחרים באפשרות Automatic seeding (הוספה אוטומטית של נתונים).
מכיוון שאין מאזין, בדף Validation נוצרת אזהרה שאפשר להתעלם ממנה.
פועלים לפי ההנחיות של אשף ההגדרה.
מצב המעבר לגיבוי עבור node-1 ו-node-2 הוא אוטומטי, אבל עבור node-3 הוא ידני. ההבדל הזה הוא דרך אחת להבחין בין זמינות גבוהה לבין התאוששות מאסון.
קבוצת הזמינות מוכנה. הגדרתם שני צמתים לזמינות גבוהה וצומת שלישי לתוכנית התאוששות מאסון (DR).
הדמיה של תוכנית התאוששות מאסון (DR)
בקטע הזה נבדוק את ארכיטקטורת ההתאוששות מאסון (DR) של המדריך הזה, ונציג יישומי DR אופציונליים.
סימולציה של הפסקת שירות והפעלה של מעבר לגיבוי במקרה של אסון
סימולציה של כשל או הפסקת חשמל באזור הראשי:
ב-Microsoft SQL Server Management Studio ב-
node-1, מתחברים אלnode-1.יוצרים טבלה. אחרי שמוסיפים רפליקות בשלבים הבאים, בודקים אם הטבלה הזו קיימת כדי לוודא שהרפליקה פועלת.
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GOב-Cloud Shell, משביתים את שני השרתים באזור הראשי
us-central1:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
ב-Microsoft SQL Server Management Studio ב-
node-3, מתחברים אלnode-3.מבצעים מעבר לגיבוי בשעת כשל ומגדירים את מצב הזמינות ל-synchronous-commit. צריך לבצע מעבר לגיבוי בעת כשל כי הצומת נמצא במצב של אישור אסינכרוני.
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOאפשר להמשיך את העיבוד.
node-3היא עכשיו המופע הראשי.(אופציונלי) יוצרים טבלה חדשה ב-
node-3. אחרי שמסנכרנים את העותקים עם העותק הראשי החדש, בודקים אם הטבלה הזו משוכפלת לעותקים.USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
למרות ש-node-3 הוא האזור הראשי בשלב הזה, יכול להיות שתרצו לחזור לאזור המקורי או להגדיר מופע משני חדש ומופע המתנה כדי ליצור מחדש ארכיטקטורת DR מלאה. בקטע הבא מפורטות האפשרויות האלה.
(אופציונלי) יצירה מחדש של ארכיטקטורת DR שמשכפלת עסקאות באופן מלא
תרחיש השימוש הזה מתייחס לכשל שבו כל העסקאות משוכפלות מהמסד הנתונים הראשי למסד הנתונים המשני לפני שהמסד הראשי נכשל. בתרחיש האידיאלי הזה, לא מתרחש אובדן נתונים, והמצב של השרת המשני עקבי עם השרת הראשי בנקודת הכשל.
בתרחיש הזה, אפשר ליצור מחדש ארכיטקטורת DR מלאה בשתי דרכים:
- חזרה לשרת הראשי המקורי ולשרת הגיבוי המקורי (אם הם זמינים).
- יצירת גיבוי חדש ומשני ל-
node-3למקרה שהגיבוי הראשי והמקורי לא יהיו זמינים.
גישה 1: חזרה לשרת הראשי ולשרת הגיבוי המקוריים
ב-Cloud Shell, מפעילים את השרת הראשי המקורי (הישן) ואת שרת הגיבוי:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quietב-Microsoft SQL Server Management Studio, מוסיפים שוב את
node-1ואתnode-2כעותקים משניים:ב-
node-3, מוסיפים את שני השרתים במצב asynchronous-commit:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOבתאריך
node-1, מפעילים מחדש את סנכרון מסדי הנתונים:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GOבתאריך
node-2, מפעילים מחדש את סנכרון מסדי הנתונים:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
להגדיר את
node-1כראשי שוב:ב-
node-3, משנים את מצב הזמינות שלnode-1ל-synchronous-commit. המופעnode-1הופך שוב למופע הראשי.USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOב-
node-1, משנים אתnode-1כך שיהיה ראשי, ואת שני הצמתים האחרים כך שיהיו משניים:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
אחרי שכל הפקודות מסתיימות בהצלחה, node-1 הוא השרת הראשי ושאר הצמתים הם משניים, כמו שמוצג בתרשים הבא.
גישה 2: הגדרה של שרת ראשי חדש ושרת גיבוי חדש
יכול להיות שלא תוכלו לשחזר את המופעים הראשיים והמוכנים למעבר המקוריים מהכשל, או שייקח יותר מדי זמן לשחזר אותם, או שהאזור לא נגיש. אחת הגישות היא להשאיר את node-3 כראשי ואז ליצור מכונה חדשה של המתנה ומכונה משנית חדשה, כמו שמוצג בדיאגרמה הבאה.
איור 5. תוכנית התאוששות מאסון (DR) עם אזור ראשי מקורי R1 שלא זמין.
כדי להטמיע את התכונה הזו, צריך לבצע את הפעולות הבאות:
אני רוצה להשאיר את
node-3כראשי בus-east1.מוסיפים מופע חדש של המתנה (
node-4) באזור אחר ב-us-east1. בשלב הזה מגדירים את הפריסה החדשה כזמינה מאוד.יוצרים מופע משני חדש (
node-5) באזור נפרד, לדוגמה,us-west2. בשלב הזה מגדירים את הפריסה החדשה לצורך התאוששות מאסון. הפריסה הכוללת הושלמה. ארכיטקטורת מסד הנתונים תומכת באופן מלא בזמינות גבוהה (HA) ובאפשרות לשחזור מאסון (DR).
(אופציונלי) ביצוע גיבוי כשחסרות עסקאות
כשל לא אידיאלי הוא כשל שבו עסקה אחת או יותר שאושרו בשרת הראשי לא משוכפלות לשרת המשני בנקודת הכשל (נקרא גם כשל קשה). במעבר לגיבוי, כל העסקאות שאושרו ולא שוכפלו יאבדו.
כדי לבדוק את שלבי המעבר לגיבוי בתרחיש הזה, צריך ליצור כשל קשה. הגישה הכי טובה ליצירת כשל קשה היא:
- משנים את הרשת כך שלא תהיה קישוריות בין המופע הראשי לבין המופע המשני.
- משנים את הגיליון הראשי – למשל, מוסיפים טבלה או נתונים.
- פועלים לפי תהליך המעבר לגיבוי שמתואר בהמשך כדי שהמשני יהפוך לראשי החדש.
השלבים בתהליך המעבר לגיבוי זהים לתרחיש האידיאלי, חוץ מהעובדה שהטבלה שנוספה לשרת הראשי אחרי שהקישוריות לרשת נקטעה לא גלויה בשרת המשני.
האפשרות היחידה להתמודדות עם כשל חמור היא להסיר את העותקים המשוכפלים (node-1 ו-node-2) מקבוצת הזמינות ולסנכרן אותם מחדש. הסנכרון משנה את המצב שלהם כך שיתאים למצב של השרת המשני. כל עסקה שלא שוכפלה לפני הכשל תאבד.
כדי להוסיף את node-1 כמופע משני, אפשר לפעול לפי אותן ההוראות להוספת node-3 שצוינו קודם (בקטע הוספת המופע המשני לאשכול המעבר לגיבוי קודם), עם ההבדל הבא: node-3 הוא עכשיו המופע הראשי, ולא node-1. צריך להחליף כל מופע של node-3 בשם השרת שמוסיפים לקבוצת הזמינות. אם נעשה שימוש חוזר באותה מכונה וירטואלית (node-1 ו-node-2), לא צריך להוסיף את השרת ל-Windows Server Failover Cluster, אלא רק להוסיף את מופע SQL Server בחזרה לקבוצת הזמינות.
בשלב הזה, node-3 היא הכתובת הראשית, וnode-1 ו-node-2 הן כתובות משניות. עכשיו אפשר לחזור ל-node-1, להגדיר את node-2 כגיבוי ואת node-3 כמשני. המערכת חוזרת למצב שהיה לפני הכשל.
מעבר אוטומטי לגיבוי (failover)
מעבר אוטומטי לגיבוי למופע משני כראשי עלול ליצור בעיות. אחרי שהשרת הראשי המקורי חוזר להיות זמין, יכול להיווצר מצב של פיצול נתונים אם חלק מהלקוחות ניגשים לשרת המשני וחלק כותבים לשרת הראשי ששוחזר. במקרה כזה, יכול להיות שהמצב של השרת הראשי והמשני יעודכן במקביל, והמצבים שלהם יהיו שונים. כדי להימנע ממצב כזה, במדריך הזה מפורטות הוראות למעבר ידני ליתירות כשל, שבו אתם מחליטים אם (או מתי) לעבור ליתירות כשל.
אם מטמיעים מעבר אוטומטי ליתירות כשל, צריך לוודא שרק אחת מהמכונות שהוגדרו היא המכונה הראשית שאפשר לשנות. לכל מופע במצב המתנה או משני אסור לספק גישת כתיבה ללקוח כלשהו (למעט המופע הראשי לצורך שכפול מצב). בנוסף, צריך להימנע משרשרת מהירה של מעברים אוטומטיים עוקבים בזמן קצר. לדוגמה, מעבר לגיבוי (failover) כל חמש דקות לא יהיה אסטרטגיה אמינה להתאוששות מאסון. בתהליכי מעבר אוטומטי לגיבוי, אפשר לשלב אמצעי הגנה מפני תרחישים בעייתיים כמו אלה, ואפילו לערב אדמין של מסד נתונים בהחלטות מורכבות, אם יש צורך בכך.
ארכיטקטורת פריסה חלופית
במדריך הזה מוגדרת ארכיטקטורה של התאוששות מאסון עם מופע משני שהופך למופע הראשי במעבר לגיבוי, כפי שמוצג בתרשים הבא.
איור 6. ארכיטקטורה סטנדרטית להתאוששות מאסון באמצעות Microsoft SQL Server.
המשמעות היא שבמקרה של יתירות כשל, ה-Deployment שתתקבל תכלול מכונה יחידה עד שיהיה אפשר לחזור למצב הקודם, או עד שתגדירו גיבוי (לזמינות גבוהה) ו-DR (להתאוששות מאסון).
ארכיטקטורת פריסה חלופית היא להגדיר שני מופעים משניים. שני המופעים הם העתקים של המופע הראשי. אם מתרחש מעבר לגיבוי, אפשר להגדיר מחדש את אחד השרתים המשניים כשרת המתנה. התרשימים הבאים מציגים את ארכיטקטורת הפריסה לפני ואחרי מעבר לגיבוי.

איור 7. ארכיטקטורה רגילה של תוכנית התאוששות מאסון (DR) עם שני מופעים משניים.
איור 8. ארכיטקטורה סטנדרטית של התאוששות מאסון עם שני מופעים משניים אחרי מעבר לגיבוי.
עדיין צריך להגדיר אחד משני השרתים המשניים כשרת המתנה (איור 8), אבל התהליך הזה מהיר בהרבה מאשר יצירה והגדרה של שרת המתנה חדש מאפס.
אפשר גם לטפל ב-DR באמצעות הגדרה שדומה לארכיטקטורה הזו של שימוש בשני מופעים משניים. בנוסף לשני שרתים משניים באזור שני (איור 7), אפשר לפרוס עוד שני שרתים משניים באזור שלישי. ההגדרה הזו מאפשרת ליצור ביעילות ארכיטקטורת פריסה עם זמינות גבוהה (HA) ויכולת התאוששות מאסון (DR) אחרי כשל באזור הראשי.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שבהם השתמשתם במדריך הזה:
מחיקת הפרויקט
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- כדאי להעמיק את הקריאה ולהכיר דוגמאות לארכיטקטורות, תרשימים ושיטות מומלצות בנושאי Google Cloud. כל אלה זמינים במרכז הארכיטקטורה של Cloud.