
כדי לשפר את ניצול המשאבים, אתם יכולים לעקוב אחרי שיעורי השימוש ב-GPU של המכונות הווירטואליות (VM).
כשאתם יודעים את שיעורי השימוש ב-GPU, אתם יכולים לבצע משימות כמו הגדרה של קבוצות מנוהלות של מופעים שאפשר להשתמש בהן כדי לשנות את גודל המשאבים באופן אוטומטי.
כדי לבדוק את מדדי ה-GPU באמצעות Cloud Monitoring, פועלים לפי השלבים הבאים:
- בכל מכונה וירטואלית, מגדירים את סקריפט הדיווח על מדדי ה-GPU. הסקריפט הזה מתקין את סוכן הדיווח על מדדי ה-GPU. הסוכן הזה פועל במכונה הווירטואלית במרווחי זמן קבועים כדי לאסוף נתונים של GPU, ושולח את הנתונים האלה אל Cloud Monitoring.
- בכל מכונה וירטואלית, מריצים את הסקריפט.
- בכל מכונה וירטואלית, מגדירים את סוכן הדיווח של מדדי ה-GPU להפעלה אוטומטית בעת האתחול.
- צפייה ביומנים ב- Google Cloud Cloud Monitoring.
התפקידים הנדרשים
כדי לעקוב אחרי הביצועים של GPU במכונות וירטואליות של Windows, צריך להעניק את התפקידים הנדרשים בניהול זהויות והרשאות גישה (IAM) לגורמים הבאים:
- חשבון השירות שבו משתמשת המכונה הווירטואלית
- חשבון המשתמש שלכם
כדי לוודא שלכם ולחשבון השירות של מכונת ה-VM יש את ההרשאות הנדרשות למעקב אחר הביצועים של ה-GPU במכונות VM של Windows, צריך לבקש מהאדמין להקצות לכם ולחשבון השירות של מכונת ה-VM את תפקידי ה-IAM הבאים בפרויקט:
- Compute Instance Admin (v1) (
roles/compute.instanceAdmin.v1) - כתיבת מדדי מעקב (
roles/monitoring.metricWriter)
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שהאדמין גם יוכל לתת לכם ולחשבון השירות של מכונת ה-VM את ההרשאות שנדרשות באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
הגדרת סקריפט לדיווח על מדדי GPU
דרישות
בכל מכונה וירטואלית, בודקים שאתם עומדים בדרישות הבאות:
- לכל מכונה וירטואלית צריך להיות GPU מצורף.
- בכל מכונה וירטואלית צריך להתקין מנהל התקן של GPU.
הורדת הסקריפט
פותחים טרמינל ב-PowerShell כאדמין ומשתמשים בפקודה Invoke-WebRequest כדי להוריד את הסקריפט.
Invoke-WebRequest זמין ב-PowerShell 3.0 ואילך.
Google Cloud מומלץ להשתמש ב-ctrl+v כדי להדביק את בלוקי הקוד שהועתקו.
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
הפעלת הסקריפט
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
הגדרת הסוכן כך שיופעל אוטומטית בזמן האתחול
כדי לוודא שהסוכן של דיווח מדדי ה-GPU מוגדר להפעלה בזמן אתחול המערכת, משתמשים בפקודה הבאה כדי להוסיף את הסוכן לתזמון המשימות של Windows.
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
בדיקת מדדים ב-Cloud Monitoring
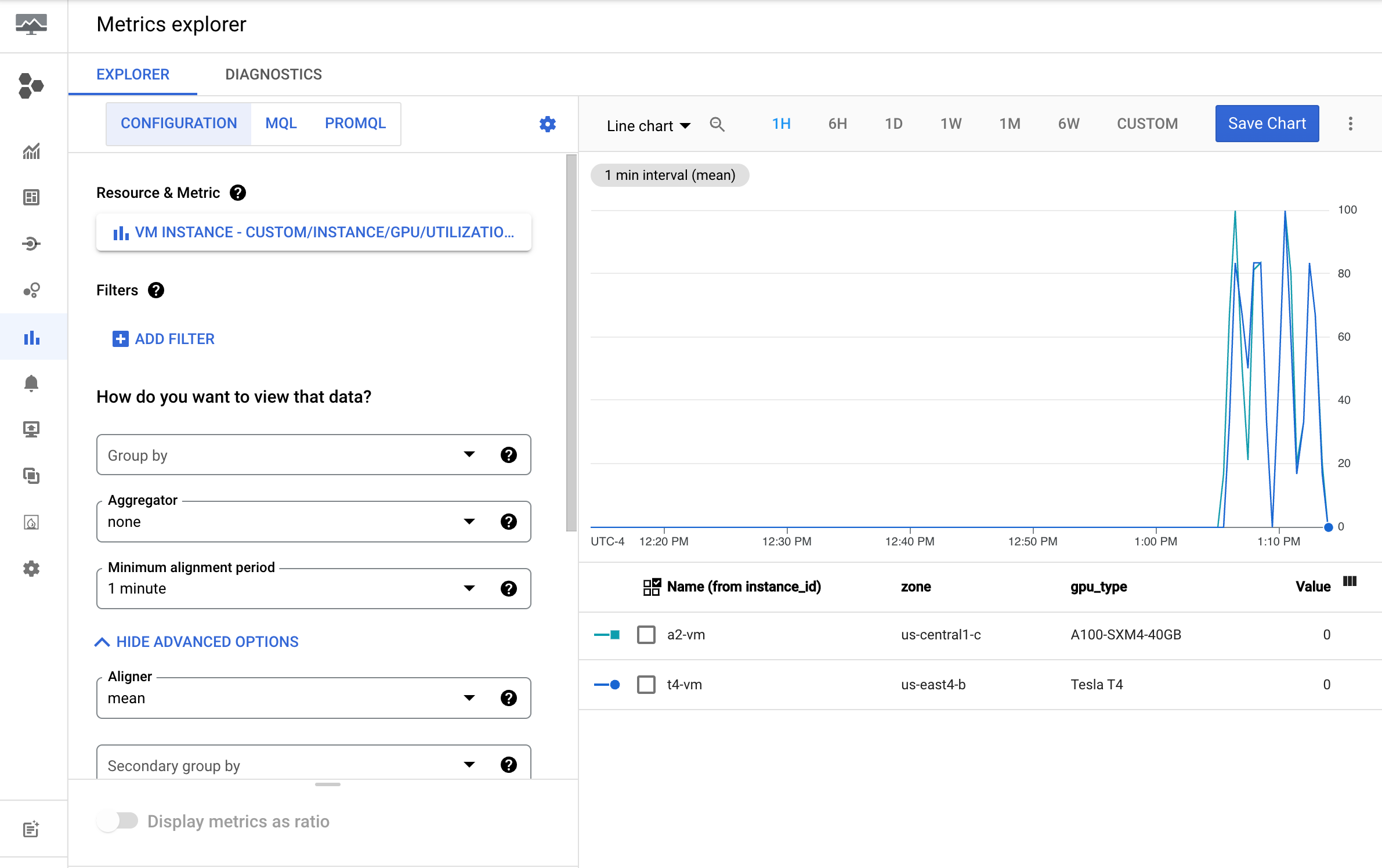
נכנסים לדף Metrics Explorer במסוף Google Cloud .
מרחיבים את התפריט בחירת מדד.
בתפריט Resource, בוחרים באפשרות VM Instance.
בתפריט Metric category בוחרים באפשרות Custom.
בתפריט מדד, בוחרים את המדד שרוצים להציג בתרשים. לדוגמה
custom/instance/gpu/utilization.לוחצים על אישור.
הפלט שלכם לגבי השימוש ב-GPU צריך להיראות כך:
מדדים זמינים
| שם המדד | תיאור |
|---|---|
instance/gpu/utilization |
אחוז הזמן במהלך תקופת הדגימה האחרונה שבה ליבה אחת או יותר פעלה ב-GPU. |
instance/gpu/memory_utilization |
אחוז הזמן במהלך תקופת הדגימה האחרונה שבה בוצעו קריאה או כתיבה של זיכרון גלובלי (מכשיר). |
instance/gpu/memory_total |
הזיכרון הכולל של ה-GPU שהותקן. |
instance/gpu/memory_used |
הזיכרון הכולל שהוקצה על ידי הקשרים הפעילים. |
instance/gpu/memory_used_percent |
אחוז הזיכרון הכולל שהוקצה על ידי הקשרים הפעילים. הערך צריך להיות בין 0 ל-100. |
instance/gpu/memory_free |
סך הזיכרון הפנוי. |
instance/gpu/temperature |
טמפרטורת ליבת ה-GPU בצלזיוס (°C). |
מה השלב הבא?
- במאמר טיפול באירועי תחזוקה של מארחי GPU מוסבר איך לטפל בתחזוקה של מארחי GPU.
- כדי לשפר את ביצועי הרשת, אפשר לקרוא את המאמר בנושא שימוש ברוחב פס גבוה יותר ברשת.