
Migrating Teradata to BigQuery tutorial
במאמר הזה מוסבר איך להעביר נתונים מ-Teradata ל-BigQuery באמצעות נתונים לדוגמה. המדריך כולל הוכחת היתכנות (POC) שמסבירה את התהליך של העברת סכימה ונתונים ממחסן נתונים של Teradata ל-BigQuery.
מטרות
- ליצור נתונים סינתטיים ולהעלות אותם ל-Teradata.
- מעבירים את הסכימה והנתונים ל-BigQuery באמצעות שירות העברת הנתונים ל-BigQuery (BQDT).
- מוודאים שהשאילתות מחזירות את אותן תוצאות ב-Teradata וב-BigQuery.
עלויות
במדריך למתחילים הזה נעשה שימוש ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
- BigQuery: במדריך הזה מאוחסנים כמעט 1 GB של נתונים ב-BigQuery, ומעובדים פחות מ-2 GB כשמריצים את השאילתות פעם אחת. במסגרתGoogle Cloud התוכנית בחינם, BigQuery מציע משאבים מסוימים ללא תשלום עד למגבלה מסוימת. מכסות השימוש האלה בחינם זמינות במהלך תקופת הניסיון בחינם ואחריה. אם תחרגו ממגבלות השימוש האלה ותקופת הניסיון בחינם תסתיים, תחויבו בהתאם לתמחור שמופיע בדף תמחור ב-BigQuery.
אפשר להשתמש במחשבון התמחור כדי ליצור הערכת עלות על סמך השימוש החזוי.
דרישות מוקדמות
- מוודאים שיש לכם הרשאות כתיבה והרשאות הפעלה במחשב שיש לו גישה לאינטרנט, כדי שתוכלו להוריד את הכלי ליצירת נתונים ולהפעיל אותו.
- מוודאים שאפשר להתחבר למסד נתונים של Teradata.
מוודאים שבמחשב מותקנים כלי הלקוח BTEQ ו-FastLoad של Teradata. אפשר להוריד את כלי הלקוח של Teradata מהאתר של Teradata. אם אתם צריכים עזרה בהתקנת הכלים האלה, אתם יכולים לבקש מהאדמין שלכם פרטים על התקנה, הגדרה והפעלה שלהם. אפשרות נוספת, או בנוסף ל-BTEQ, היא לבצע את הפעולות הבאות:
- מתקינים כלי עם ממשק גרפי כמו DBeaver.
- מתקינים את Teradata SQL Driver for Python כדי ליצור סקריפטים לאינטראקציות עם Teradata Database.
מוודאים שלמחשב יש קישוריות לרשת עםGoogle Cloud כדי שהסוכן של שירות העברת הנתונים ל-BigQuery יוכל לתקשר עם BigQuery ולהעביר את הסכימה והנתונים.
מבוא
במדריך הזה מוסבר איך לבצע הוכחת היתכנות של מיגרציה. במהלך ההפעלה המהירה, יוצרים נתונים סינתטיים וטוענים אותם ל-Teradata. לאחר מכן משתמשים בשירות העברת הנתונים ל-BigQuery כדי להעביר את הסכימה והנתונים ל-BigQuery. לבסוף, מריצים שאילתות בשני הצדדים כדי להשוות את התוצאות. בסיום התהליך, הסכימה והנתונים מ-Teradata ממופים אחד לאחד ל-BigQuery.
המדריך הזה מיועד לאדמינים של מחסני נתונים, למפתחים ולמומחי נתונים באופן כללי שרוצים להתנסות בהעברת סכימה ונתונים באמצעות שירות העברת הנתונים ל-BigQuery.
יצירת הנתונים
Transaction Processing Performance Council (TPC) הוא ארגון ללא מטרות רווח שמפרסם מפרטים של בדיקות השוואה. המפרטים האלה הפכו לסטנדרטים מקובלים בתחום להפעלת מדדים שקשורים לנתונים.
המפרט של TPC-H הוא מדד השוואתי שמתמקד בתמיכה בקבלת החלטות. במדריך למתחילים הזה משתמשים בחלקים מהמפרט הזה כדי ליצור את הטבלאות ולייצר נתונים סינתטיים כמודל של מחסן נתונים אמיתי. למרות שהמפרט נוצר לצורך השוואה, במדריך הזה לשימוש מהיר אתם משתמשים במודל הזה כחלק מהוכחת ההיתכנות של ההעברה, ולא למשימות השוואה.
- במחשב שדרכו תתחברו ל-Teradata, משתמשים בדפדפן אינטרנט כדי להוריד את הגרסה העדכנית ביותר של כלי TPC-H מהאתר של TPC.
- פותחים טרמינל של פקודות ועוברים לספרייה שבה הורדתם את הכלים.
מחלצים את קובץ ה-ZIP שהורד. מחליפים את file-name בשם של הקובץ שהורדתם:
unzip file-name.zip
ספרייה ששמה כולל את מספר הגרסה של כלי החילוץ. הספרייה הזו כוללת את קוד המקור של TPC לכלי ליצירת נתונים DBGEN ואת המפרט של TPC-H עצמו.
עוברים אל ספריית המשנה
dbgen. משתמשים בשם של ספריית האב שמתאים לגרסה שלכם, כמו בדוגמה הבאה:cd 2.18.0_rc2/dbgenיוצרים קובץ makefile באמצעות התבנית שסופקה:
cp makefile.suite makefileעורכים את קובץ ה-makefile באמצעות כלי לעריכת טקסט. לדוגמה, משתמשים ב-vi כדי לערוך את הקובץ:
vi makefileב-makefile, משנים את הערכים של המשתנים הבאים:
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHיכול להיות שהערכים של מהדר C (
CC) אוMACHINEיהיו שונים בהתאם לסביבה שלכם. אם צריך, אפשר לפנות לאדמין של המערכת.שומרים את השינויים וסוגרים את הקובץ.
מעבדים את קובץ ה-Makefile:
makeיוצרים את נתוני TPC-H באמצעות הכלי
dbgen:dbgen -vתהליך יצירת הנתונים נמשך כמה דקות. הדגל
-v(מפורט) גורם לפקודה לדווח על ההתקדמות. אחרי שהנתונים נוצרים, בתיקייה הנוכחית מופיעים 8 קובצי ASCII עם הסיומת.tbl. הם מכילים נתונים סינתטיים מופרדים באמצעות קו אנכי, שאפשר לטעון אותם לכל אחת מהטבלאות של TPC-H.
העלאת נתוני דוגמה ל-Teradata
בקטע הזה מעלים את הנתונים שנוצרו למסד הנתונים של Teradata.
יצירת מסד הנתונים TPC-H
לקוח Teradata, שנקרא Basic Teradata Query (BTEQ), משמש לתקשורת עם שרת מסד נתונים אחד או יותר של Teradata ולהרצת שאילתות SQL במערכות האלה. בקטע הזה תשתמשו ב-BTEQ כדי ליצור מסד נתונים חדש לטבלאות TPC-H.
פותחים את לקוח Teradata BTEQ:
bteqמתחברים ל-Teradata. מחליפים את teradata-ip ו-teradata-user בערכים המתאימים לסביבה שלכם.
.LOGON teradata-ip/teradata-user
יוצרים מסד נתונים בשם
tpchעם נפח אחסון מוקצה של 2GB:CREATE DATABASE tpch AS PERM=2e+09;יציאה מ-BTEQ:
.QUIT
טעינת הנתונים שנוצרו
בקטע הזה יוצרים סקריפט FastLoad כדי ליצור ולטעון את טבלאות הדוגמה. הגדרות הטבלה מתוארות בסעיף 1.4 של מפרט TPC-H. בקטע 1.2 מופיע תרשים של קשרים בין ישויות של סכימת מסד הנתונים כולה.
בקטע הבא מוסבר איך ליצור את הטבלה lineitem, שהיא הגדולה והמורכבת ביותר מבין הטבלאות של TPC-H. כשמסיימים עם הטבלה lineitem, חוזרים על התהליך הזה לגבי שאר הטבלאות.
בעזרת עורך טקסט, יוצרים קובץ חדש בשם
fastload_lineitem.fl:vi fastload_lineitem.flמעתיקים את הסקריפט הבא לקובץ, שמתחבר למסד הנתונים של Teradata ויוצר טבלה בשם
lineitem.בפקודה
logon, מחליפים את teradata-ip, teradata-user, ואת teradata-pwd בפרטי החיבור.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);הסקריפט מוודא קודם שהטבלה
lineitemוטבלאות השגיאות הזמניות לא קיימות, ואז יוצר את הטבלהlineitem.באותו קובץ, מוסיפים את הקוד הבא, שמעמיס את הנתונים לטבלה החדשה שנוצרה. ממלאים את כל השדות בטבלה בשלושת הבלוקים (
define,insertו-values) ומוודאים שמשתמשים ב-varcharכסוג הנתונים לטעינה.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
הסקריפט FastLoad טוען את הנתונים מקובץ באותה ספרייה שנקרא
lineitem.tbl, שיצרתם בקטע הקודם.שומרים את השינויים וסוגרים את הקובץ.
מריצים את סקריפט FastLoad:
fastload < fastload_lineitem.flחוזרים על התהליך הזה לגבי שאר הטבלאות של TPC-H שמפורטות בקטע 1.4 במפרט של TPC-H. חשוב להתאים את השלבים לכל טבלה.
העברת הסכימה והנתונים ל-BigQuery
ההוראות להעברת הסכימה והנתונים ל-BigQuery מופיעות במדריך נפרד: העברת נתונים מ-Teradata. בקטע הזה מוסבר איך לבצע שלבים מסוימים במדריך. אחרי שתסיימו את השלבים במדריך השני, תחזרו למסמך הזה ותמשיכו לקטע הבא, אימות תוצאות השאילתה.
יצירת מערך נתונים ב-BigQuery
במהלך שלבי ההגדרה הראשוניים Google Cloud , תתבקשו ליצור מערך נתונים ב-BigQuery כדי לאחסן את הטבלאות אחרי ההעברה. נותנים למערך הנתונים את השם tpch. ההנחה בשאילתות שבסוף המדריך הזה היא שזה השם, ולא צריך לבצע בהן שינויים.
# Use the bq utility to create the dataset
bq mk --location=US tpch
יצירה של חשבון שירות
בנוסף, כחלק מ Google Cloud שלבי ההגדרה, צריך ליצור חשבון שירות לניהול זהויות והרשאות גישה (IAM). חשבון השירות הזה משמש לכתיבת הנתונים ב-BigQuery ולאחסון נתונים זמניים ב-Cloud Storage.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
מעניקים הרשאות לחשבון השירות שמאפשרות לו לנהל מערכי נתונים של BigQuery ואת אזור הביניים ב-Cloud Storage:
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
יצירת קטגוריה של Cloud Storage לסביבת Staging
משימה נוספת בהגדרת Google Cloud היא יצירת קטגוריה של Cloud Storage. הקטגוריה הזו משמשת את שירות העברת הנתונים ל-BigQuery כאזור זמני לקובצי נתונים שמועברים ל-BigQuery.
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
ציון תבניות של שמות טבלאות
במהלך ההגדרה של העברה חדשה בשירות העברת הנתונים ל-BigQuery, תתבקשו לציין ביטוי שמציין אילו טבלאות לכלול בהעברה. במדריך למתחילים הזה, כוללים את כל הטבלאות ממסד הנתונים tpch.
הפורמט של הביטוי הוא database.table, ואפשר להחליף את שם הטבלה בתו כללי. מכיוון שתווים כלליים ב-Java מתחילים בשתי נקודות, הביטוי להעברת כל הטבלאות ממסד הנתונים tpch הוא:
tpch..*
שימו לב שיש שתי נקודות.
אימות תוצאות של שאילתות
בשלב הזה יצרתם נתונים לדוגמה, העליתם את הנתונים ל-Teradata ואז העברתם אותם ל-BigQuery באמצעות שירות העברת הנתונים ל-BigQuery, כמו שמוסבר במדריך הנפרד. בקטע הזה, מריצים שתיים מהשאילתות הרגילות של TPC-H כדי לוודא שהתוצאות זהות ב-Teradata וב-BigQuery.
הרצת שאילתה של דוח סיכום התמחור
השאילתה הראשונה היא שאילתת דוח סיכום התמחור (סעיף 2.4.1 במפרט TPC-H). השאילתה הזו מדווחת על מספר הפריטים שחויבו, נשלחו והוחזרו עד לתאריך מסוים.
בדוגמה הבאה מוצגת השאילתה המלאה:
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
מריצים את השאילתה ב-Teradata:
- מריצים את BTEQ ומתחברים ל-Teradata. פרטים נוספים זמינים בקטע יצירת מסד הנתונים TPC-H שבהמשך המאמר הזה.
משנים את רוחב התצוגה של הפלט ל-500 תווים:
.set width 500מעתיקים את השאילתה ומדביקים אותה בהנחיה של BTEQ.
התוצאה אמורה להיראות כך:
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
מריצים את אותה שאילתה ב-BigQuery:
נכנסים למסוף BigQuery:
מעתיקים את השאילתה לעורך השאילתות.
מוודאים ששם מערך הנתונים בשורה
FROMנכון.לוחצים על Run.
התוצאה זהה לתוצאה מ-Teradata.
אפשר גם לבחור מרווחי זמן רחבים יותר בשאילתה כדי לוודא שכל השורות בטבלה נסרקות.
הרצת השאילתה לגבי נפח החיפושים של ספקים מקומיים
השאילתה השנייה לדוגמה היא דוח שאילתות על נפח הספקים המקומיים (קטע 2.4.5 במפרט TPC-H). לכל מדינה באזור, השאילתה הזו מחזירה את ההכנסה שנוצרה מכל פריט שבו הלקוח והספק היו באותה מדינה. התוצאות האלה שימושיות למשל לתכנון המיקום של מרכזי הפצה.
בשאילתה המלאה שמופיעה בהמשך:
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
מריצים את השאילתה ב-Teradata BTEQ ובמסוף BigQuery כמו שמתואר בקטע הקודם.
זו התוצאה שמוחזרת מ-Teradata:
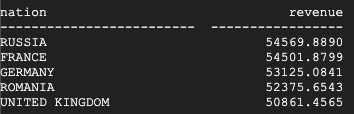
זו התוצאה שמוחזרת מ-BigQuery:
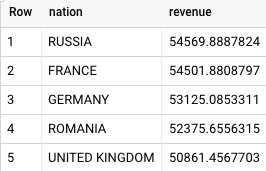
גם Teradata וגם BigQuery מחזירים את אותן תוצאות.
הפעלת השאילתה של מדד הרווח לפי סוג המוצר
הבדיקה הסופית לאימות ההעברה היא השאילתה למדידת הרווח לפי סוג המוצר השאילתה האחרונה לדוגמה (קטע 2.4.9 במפרט TPC-H). לכל מדינה ולכל שנה, השאילתה הזו מוצאת את הרווח מכל החלקים שהוזמנו באותה שנה. הוא מסנן את התוצאות לפי מחרוזת משנה בשמות החלקים ולפי ספק ספציפי.
בדוגמה הבאה מוצגת השאילתה המלאה:
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
מריצים את השאילתה ב-Teradata BTEQ ובמסוף BigQuery כמו שמתואר בקטע הקודם.
זו התוצאה שמוחזרת מ-Teradata:
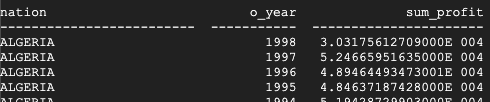
זו התוצאה שמוחזרת מ-BigQuery:
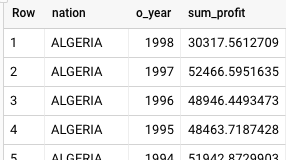
גם Teradata וגם BigQuery מחזירים את אותן תוצאות, אבל ב-Teradata הסכום מוצג בסימון מדעי.
שאילתות נוספות
אפשר גם להריץ את שאר השאילתות של TPC-H שמוגדרות בקטע 2.4 של מפרט TPC-H.
אפשר גם ליצור שאילתות לפי התקן TPC-H באמצעות הכלי QGEN, שנמצא באותה ספרייה כמו הכלי DBGEN. QGEN מבוסס על אותו makefile כמו DBGEN, כך שכשתריצו את הפקודה make כדי לקמפל את dbgen, תיווצר גם ההפעלה qgen.
מידע נוסף על שני הכלים ועל אפשרויות שורת הפקודה שלהם זמין בקובץ README של כל כלי.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שבהם השתמשתם במדריך הזה, צריך להסיר אותם.
מחיקת הפרויקט
הדרך הכי פשוטה להפסיק את החיובים היא למחוק את הפרויקט שיצרתם בשביל המדריך הזה.
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.