
Planifier un transfert Snowflake
Le connecteur Snowflake fourni par le service de transfert de données BigQuery vous permet de planifier et de gérer des jobs de transfert automatisés pour migrer des données de Snowflake vers BigQuery à l'aide de listes d'adresses IP publiques autorisées.
Présentation
Le connecteur Snowflake engage les agents de migration dans Google Kubernetes Engine et déclenche une opération de chargement depuis Snowflake vers une zone de préproduction du bucket Cloud Storage.
- Pour les comptes Snowflake hébergés sur Amazon Web Services (AWS), Azure ou Google Cloud, les données sont d'abord préparées dans votre bucket Cloud Storage, puis transférées vers BigQuery avec le service de transfert de données BigQuery.
Le schéma suivant illustre les transferts de données publiques depuis des comptes Snowflake hébergés sur Amazon Web Services (AWS) ou Azure, ou des comptes Snowflake hébergés sur Google Cloud.
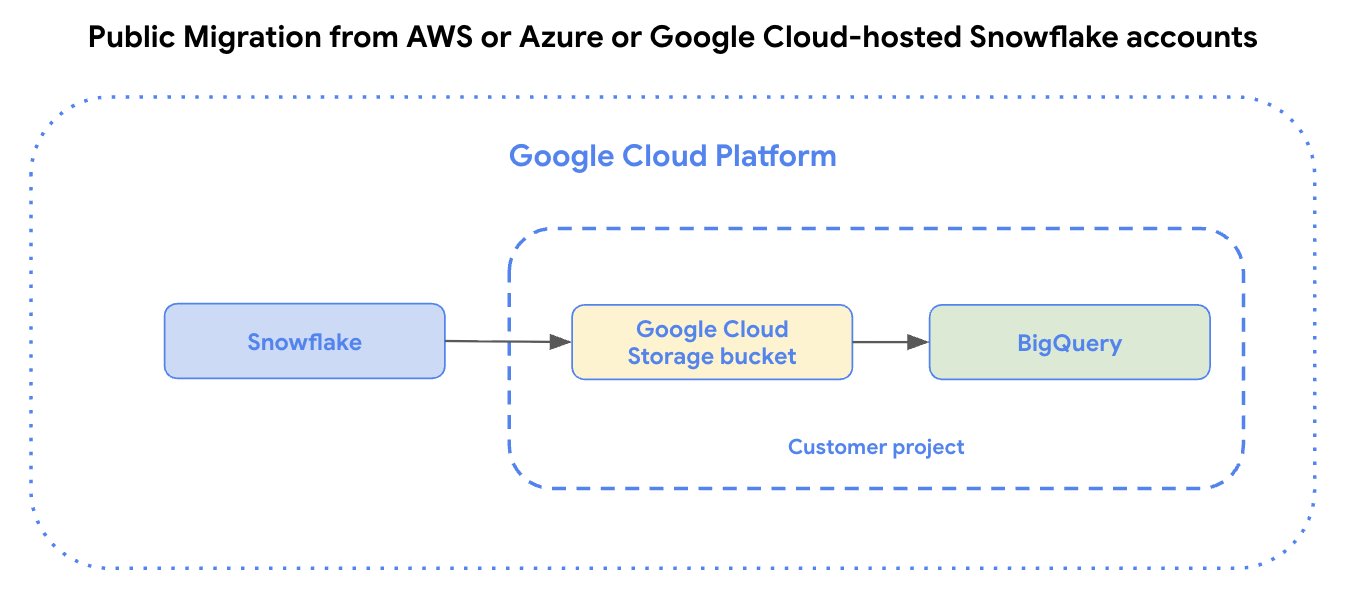
Limites
Les transferts de données effectués à l'aide du connecteur Snowflake sont soumis aux limitations suivantes :
- Le connecteur Snowflake n'accepte que les transferts depuis des tables d'une même base de données et d'un même schéma Snowflake. Pour transférer des données depuis des tables comportant plusieurs bases de données ou schémas Snowflake, vous pouvez configurer chaque job de transfert séparément.
- La vitesse de chargement des données de Snowflake vers votre bucket Amazon S3, votre conteneur Azure Blob Storage ou votre bucket Cloud Storage est limitée par l'entrepôt de données Snowflake que vous avez choisi pour ce transfert.
- BigQuery écrit les données de Snowflake dans Cloud Storage sous forme de fichiers Parquet. Les fichiers Parquet ne sont pas compatibles avec les types de données
TIMESTAMP_TZetTIMESTAMP_LTZ. Si vos données contiennent ces types, vous pouvez les exporter vers Amazon S3 sous forme de fichiers CSV, puis importer ces fichiers CSV dans BigQuery. Pour en savoir plus, consultez Présentation des transferts Amazon S3.
Avant de commencer
Avant de configurer un transfert Snowflake, vous devez effectuer toutes les étapes listées dans cette section. Vous trouverez ci-dessous la liste de toutes les étapes requises.
- Préparer votre projet Google Cloud
- Rôles BigQuery requis
- Préparer votre bucket de préproduction
- Créer un utilisateur Snowflake avec les autorisations requises
- Ajouter des règles de réseau
- Facultatif : Détection et mappage du schéma
- Évaluer votre instance Snowflake pour identifier les types de données non compatibles
- Facultatif : activer les transferts incrémentiels
- Facultatif : Activer la connectivité privée
- Recueillir les informations de transfert
- Si vous envisagez de spécifier une clé de chiffrement gérée par le client (CMEK), assurez-vous que votre compte de service est autorisé à procéder au chiffrement et au déchiffrement, et que vous disposez de l'ID de ressource de la clé Cloud KMS requis pour utiliser des clés CMEK. Pour en savoir plus sur le fonctionnement des clés CMEK avec les transferts, consultez Spécifier une clé de chiffrement avec les transferts.
Préparer votre projet Google Cloud
Pour créer et configurer votre projet Google Cloud pour un transfert Snowflake, procédez comme suit :
Créez un projet Google Cloud ou sélectionnez-en un existant.
Vérifiez que vous avez effectué toutes les actions requises pour activer le service de transfert de données BigQuery.
Créez un ensemble de données BigQuery pour stocker vos données. Vous n'avez pas besoin de créer de tables.
Rôles BigQuery requis
Pour obtenir les autorisations nécessaires pour créer un transfert de données Service de transfert de données BigQuery, demandez à votre administrateur de vous accorder le rôle IAM Administrateur BigQuery (roles/bigquery.admin) sur votre projet.
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Ce rôle prédéfini contient les autorisations requises pour créer un transfert de données du service de transfert de données BigQuery. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour créer un transfert de données du service de transfert de données BigQuery :
-
Autorisations du service de transfert de données BigQuery :
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
Autorisations BigQuery :
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus, consultez Accorder l'accès bigquery.admin.
Préparer le bucket de préproduction
Pour préparer un transfert de données Snowflake, créez un bucket intermédiaire, puis configurez-le pour autoriser l'accès en écriture depuis Snowflake. Vous devez préproduire les données Snowflake dans un bucket Cloud Storage avant de pouvoir les charger dans BigQuery.
- Créez un bucket Cloud Storage.
- Créez et configurez un objet d'intégration de stockage Snowflake pour permettre à Snowflake d'écrire des données dans le bucket Cloud Storage en tant qu'étape externe.
- Lorsque vous exécutez la commande
DESCRIBE INTEGRATION, le compte de service Cloud Storage est listé dans le champSTORAGE_GCP_SERVICE_ACCOUNT. Accordez au compte de service Cloud Storage les autorisations suivantes sur le bucket Cloud Storage :storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
Pour autoriser l'accès au bucket intermédiaire, accordez le rôle
roles/storage.objectViewerà l'agent de service DTS à l'aide de la commande suivante :gcloud storage buckets add-iam-policy-binding gs://STAGING_BUCKET_NAME \ --member=serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com \ --role=roles/storage.objectViewer
Pour un transfert de données Snowflake privé, créez le bucket intermédiaire et configurez-le pour la connectivité privée.
Créer un utilisateur Snowflake avec les autorisations requises
Lors d'un transfert Snowflake, le connecteur Snowflake se connecte à votre compte Snowflake à l'aide d'une connexion JDBC. Vous devez créer un utilisateur Snowflake avec un rôle personnalisé qui ne dispose que des droits nécessaires pour effectuer le transfert de données :
// Create and configure new role, MIGRATION_ROLE
GRANT USAGE
ON WAREHOUSE WAREHOUSE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON DATABASE DATABASE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON SCHEMA DATABASE_NAME.SCHEMA_NAME
TO ROLE MIGRATION_ROLE;
// You can modify this to give select permissions for all tables in a schema
GRANT SELECT
ON TABLE DATABASE_NAME.SCHEMA_NAME.TABLE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON INTEGRATION STORAGE_INTEGRATION_OBJECT_NAME
TO ROLE MIGRATION_ROLE;
Remplacez les éléments suivants :
MIGRATION_ROLE: nom du rôle personnalisé que vous créezWAREHOUSE_NAME: nom de votre entrepôt de donnéesDATABASE_NAME: nom de votre base de données SnowflakeSCHEMA_NAME: nom de votre schéma SnowflakeTABLE_NAME: nom de la base de données Snowflake incluse dans ce transfert de données.STORAGE_INTEGRATION_OBJECT_NAME: nom de votre objet d'intégration de stockage Snowflake.
Générer une paire de clés pour l'authentification
Étant donné que Snowflake n'accepte plus les connexions avec mot de passe à un seul facteur, nous vous recommandons d'utiliser une paire de clés pour l'authentification.
Vous pouvez configurer une paire de clés en générant une paire de clés RSA chiffrée ou non chiffrée, puis en attribuant la clé publique à un utilisateur Snowflake. Pour en savoir plus, consultez Configurer l'authentification par paire de clés.
Autoriser le déchargement vers des emplacements externes intégrés
Le connecteur Snowflake décharge les données vers des emplacements externes intégrés lors du transfert. Si votre compte Snowflake limite le déchargement aux emplacements intégrés, le transfert échoue.
Pour autoriser le déchargement vers des emplacements intégrés, exécutez la commande SQL suivante dans votre compte Snowflake. Vous devez disposer du rôle ACCOUNTADMIN dans Snowflake pour exécuter cette commande.
ALTER ACCOUNT SET PREVENT_UNLOAD_TO_INLINE_URL = false;
Ajouter des règles de réseau
Pour la connectivité publique, le compte Snowflake autorise par défaut la connexion publique avec les identifiants de la base de données. Toutefois, il est possible que vous ayez configuré des règles ou des stratégies réseau qui pourraient empêcher le connecteur Snowflake de se connecter à votre compte. Dans ce cas, vous devez ajouter les adresses IP nécessaires à votre liste d'autorisation. Pour en savoir plus, consultez Configurer des règles de réseau pour les transferts Snowflake.
Détection et mappage de schémas
Pour définir votre schéma, vous pouvez utiliser le service de transfert de données BigQuery afin de détecter automatiquement le schéma et la mise en correspondance des types de données lorsque vous transférez des données de Snowflake vers BigQuery. Vous pouvez également utiliser le moteur de traduction pour définir manuellement votre schéma et vos types de données.
Pour en savoir plus, consultez Détection et mappage de schéma pour Snowflake.
Activer les transferts incrémentiels
Pour configurer un transfert incrémentiel de données Snowflake, consultez Configurer des transferts incrémentiels pour Snowflake.
Activer la connectivité privée
Si vous souhaitez créer un transfert de données Snowflake privé, vous devez configurer votre réseau pour la connectivité privée.
Recueillir les informations de transfert
Recueillez les informations dont vous avez besoin pour configurer la migration avec le service de transfert de données BigQuery :
- L'identifiant de votre compte Snowflake, qui correspond au préfixe de l'URL de votre compte Snowflake. Par exemple,
ACCOUNT_IDENTIFIER.snowflakecomputing.com. - Nom d'utilisateur et clé privée associée disposant des autorisations appropriées pour votre base de données Snowflake. Il peut simplement disposer des autorisations requises pour exécuter le transfert de données.
- L'URI du bucket intermédiaire à utiliser pour le transfert. Nous vous recommandons de définir une règle de cycle de vie pour ce bucket afin d'éviter des frais inutiles.
- URI du bucket Cloud Storage dans lequel vous avez stocké les fichiers de mappage de schéma obtenus à partir du moteur de traduction.
Configurer un transfert Snowflake
Sélectionnez l'une des options suivantes :
Console
Accédez à la page "Transferts de données" dans la console Google Cloud .
Cliquez sur Créer un transfert.
Dans la section Source type (Type de source), sélectionnez Snowflake Migration (Migration Snowflake) dans la liste Source.
Dans la section Transfer config name (Nom de la configuration de transfert), saisissez un nom pour le transfert, tel que
My migration, dans le champ Display name (Nom à afficher). Le nom à afficher peut être n'importe quelle valeur permettant d'identifier le transfert si vous devez le modifier par la suite.Dans la section Destination settings (Paramètres de destination), choisissez l'ensemble de données que vous avez créé dans la liste Dataset (Ensemble de données).
Dans la section Identifiants Snowflake, procédez comme suit :
- Pour Identifiant de compte, saisissez un identifiant unique pour votre compte Snowflake, qui est une combinaison du nom de votre organisation et du nom de votre compte. L'identifiant correspond au préfixe de l'URL du compte Snowflake, et non à l'URL complète. Exemple :
ACCOUNT_IDENTIFIER.snowflakecomputing.com - Dans le champ Nom d'utilisateur, saisissez le nom d'utilisateur Snowflake dont les identifiants et l'autorisation sont utilisés pour accéder à votre base de données afin de transférer les tables Snowflake. Nous vous recommandons d'utiliser l'utilisateur que vous avez créé pour ce transfert.
- Pour Authentication Mechanism (Mécanisme d'authentification), sélectionnez une méthode d'authentification des utilisateurs Snowflake :
MOT DE PASSE
- Dans le champ Mot de passe, saisissez le mot de passe de l'utilisateur Snowflake.
KEY_PAIR
- Pour Clé privée, saisissez la clé privée associée à la clé publique associée à l'utilisateur Snowflake.
- Pour Is Private Key Encrypted (La clé privée est-elle chiffrée ?), cochez cette case si la clé privée est chiffrée avec une phrase secrète.
- Dans le champ Phrase secrète de la clé privée, saisissez la phrase secrète de la clé privée chiffrée. Ce champ est obligatoire si vous avez sélectionné Is Private Key Encrypted (La clé privée est-elle chiffrée ?). Pour en savoir plus, consultez Générer une paire de clés pour l'authentification.
- Pour Entrepôt, saisissez un entrepôt utilisé pour l'exécution de ce transfert de données.
- Pour Base de données Snowflake, saisissez le nom de la base de données Snowflake qui contient les tables incluses dans ce transfert de données.
- Pour Schéma Snowflake, saisissez le nom du schéma Snowflake qui contient les tables incluses dans ce transfert de données.
- Pour Identifiant de compte, saisissez un identifiant unique pour votre compte Snowflake, qui est une combinaison du nom de votre organisation et du nom de votre compte. L'identifiant correspond au préfixe de l'URL du compte Snowflake, et non à l'URL complète. Exemple :
Dans la section Configuration du stockage, procédez comme suit :
- Dans le champ Nom de l'objet d'intégration de stockage, saisissez le nom de l'objet d'intégration de stockage Snowflake.
- Facultatif : Pour Taille maximale des fichiers, spécifiez la taille maximale de chaque fichier déchargé de Snowflake vers l'emplacement intermédiaire (en Mo).
Pour Fournisseur de services cloud, sélectionnez
AWS,AZUREouGCPselon le fournisseur de services cloud qui héberge votre compte Snowflake.- Pour URI GCS, saisissez l'URI du bucket Cloud Storage à utiliser comme bucket intermédiaire.
Dans la section Compte de service, procédez comme suit :
- Dans le champ Compte de service, saisissez un compte de service à utiliser avec ce transfert de données. Le compte de service doit appartenir au même projetGoogle Cloud que celui dans lequel la configuration du transfert et l'ensemble de données de destination sont créés. Le compte de service doit disposer des autorisations requises
storage.objects.listetstorage.objects.get.
- Dans le champ Compte de service, saisissez un compte de service à utiliser avec ce transfert de données. Le compte de service doit appartenir au même projetGoogle Cloud que celui dans lequel la configuration du transfert et l'ensemble de données de destination sont créés. Le compte de service doit disposer des autorisations requises
Dans la section Configuration du schéma, procédez comme suit :
- Pour Type d'ingestion, sélectionnez Complet ou Incrémentiel. Pour en savoir plus, consultez Configurer les transferts incrémentaux.
- Sous Table name patterns (Modèles de nom de table), spécifiez une table à transférer en saisissant un nom ou un modèle qui correspond au nom de la table dans le schéma. Vous pouvez utiliser des expressions régulières pour spécifier le modèle, par exemple
table1_regex;table2_regex. Le modèle doit suivre la syntaxe d'expression régulière Java. Par exemple,lineitem;ordertbrenvoie les tables nomméeslineitemetordertb..*renvoie toutes les tables.
- Facultatif : Pour Utiliser la sortie BigQuery Translation Engine, cochez cette case si vous souhaitez spécifier un chemin d'accès personnalisé pour la sortie de la traduction.
- Facultatif : Pour Chemin d'accès GCS de la sortie de traduction, spécifiez le chemin d'accès au dossier Cloud Storage contenant les fichiers de mappage de schéma du moteur de traduction. Vous pouvez laisser ce champ vide pour que le connecteur Snowflake détecte automatiquement votre schéma.
- Le chemin d'accès doit respecter le format
translation_target_base_uri/metadata/config/db/schema/et se terminer par/.
- Le chemin d'accès doit respecter le format
- Facultatif : Pour Chemin d'accès au fichier de schéma personnalisé, spécifiez le chemin d'accès Cloud Storage à un fichier de schéma personnalisé.
- Facultatif : Pour Mapper le type Snowflake NUMBER à zéro décimale sur le type BigQuery INT64, sélectionnez ce champ si vous souhaitez que les types Snowflake
NUMBER(p, 0)soient mappés sur les types BigQueryINT64.
Dans la section Connectivité réseau, procédez comme suit :
- Pour Utiliser un réseau privé, sélectionnez True si vous créez un transfert de données privées.
- Pour Rattachement de service PSC, si vous créez une connexion privée, saisissez l'URI du rattachement de service. Pour en savoir plus, consultez Créer une configuration de transfert Snowflake privée.
- Pour Private Network Service, si vous créez un transfert de données privé, saisissez le lien autoréférentiel de l'annuaire des services. Pour en savoir plus, consultez Créer une configuration de transfert Snowflake privée.
Facultatif : dans la section Options de notification, procédez comme suit :
- Cliquez sur le bouton pour activer les notifications par e-mail. Lorsque vous activez cette option, l'administrateur de transfert reçoit une notification par e-mail en cas d'échec de l'exécution du transfert.
- Pour le champ Select a Pub/Sub topic (Sélectionner un sujet Pub/Sub), choisissez le nom de votre sujet ou cliquez sur Create a topic (Créer un sujet). Cette option configure les notifications d'exécution Cloud Pub/Sub pour votre transfert.
Si vous utilisez des CMEK, dans la section Options avancées, sélectionnez Clé gérée par le client. La liste des CMEK disponibles s'affiche. Pour en savoir plus sur le fonctionnement des CMEK avec le Service de transfert de données BigQuery, consultez Spécifier une clé de chiffrement avec les transferts.
Cliquez sur Enregistrer.
La console Google Cloud affiche tous les détails de configuration du transfert, y compris un nom de ressource pour ce transfert.
bq
Saisissez la commande bq mk, puis spécifiez l'option de création de transfert --transfer_config. Les paramètres suivants sont également requis :
--project_id--data_source--target_dataset--display_name--params
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters'
Remplacez les éléments suivants :
- project_id : ID de votre projet Google Cloud . Si
--project_idn'est pas spécifié, le projet par défaut est utilisé. - data_source : source de données,
snowflake_migration. - dataset : ensemble de données cible de BigQuery pour la configuration de transfert.
- name : nom à afficher de la configuration de transfert. Ce nom peut correspondre à toute valeur permettant d'identifier le transfert si vous devez le modifier ultérieurement.
- service_account : (facultatif) nom du compte de service utilisé pour authentifier le transfert. Le compte de service doit appartenir au même
project_idque celui utilisé pour créer le transfert et doit disposer de tous les rôles requis. - parameters correspond aux paramètres de la configuration de transfert créée, au format JSON. Exemple :
--params='{"param":"param_value"}'.
Vous pouvez configurer les paramètres suivants pour votre configuration de transfert Snowflake :
account_identifier: spécifiez un identifiant unique pour votre compte Snowflake, qui est une combinaison du nom de votre organisation et du nom de votre compte. L'identifiant correspond au préfixe de l'URL du compte Snowflake, et non à l'URL complète. Exemple :account_identifier.snowflakecomputing.comusername: spécifiez le nom d'utilisateur Snowflake dont les identifiants et l'autorisation sont utilisés pour accéder à votre base de données afin de transférer les tables Snowflake.auth_mechanism: spécifiez la méthode d'authentification des utilisateurs Snowflake. Les valeurs acceptées sontPASSWORDetKEY_PAIR. Pour en savoir plus, consultez Générer une paire de clés pour l'authentification.password: spécifiez le mot de passe de l'utilisateur Snowflake. Ce champ est obligatoire si vous avez spécifiéPASSWORDdans le champauth_mechanism.private_key: spécifiez la clé privée associée à la clé publique associée à l'utilisateur Snowflake. Ce champ est obligatoire si vous avez spécifiéKEY_PAIRdans le champauth_mechanism.is_private_key_encrypted: spécifieztruesi la clé privée est chiffrée avec une phrase secrète.private_key_passphrase: spécifiez la phrase secrète pour la clé privée chiffrée. Ce champ est obligatoire si vous avez spécifiéKEY_PAIRdans le champauth_mechanismettruedans le champis_private_key_encrypted.warehouse: spécifiez un entrepôt utilisé pour l'exécution de ce transfert de données.service_account: spécifiez un compte de service à utiliser avec ce transfert de données. Le compte de service doit appartenir au même projet Google Cloud que celui dans lequel la configuration du transfert et l'ensemble de données de destination sont créés. Le compte de service doit disposer des autorisations requisesstorage.objects.listetstorage.objects.get.database: spécifiez le nom de la base de données Snowflake contenant les tables incluses dans ce transfert de données.schema: spécifiez le nom du schéma Snowflake contenant les tables incluses dans ce transfert de données.table_name_patterns: spécifiez une table à transférer en saisissant un nom ou un modèle correspondant au nom de la table dans le schéma. Vous pouvez utiliser des expressions régulières pour spécifier le modèle, par exempletable1_regex;table2_regex. Le modèle doit suivre la syntaxe d'expression régulière Java. Par exemple,lineitem;ordertbrenvoie les tables nomméeslineitemetordertb..*renvoie toutes les tables.Vous pouvez également laisser ce champ vide pour migrer toutes les tables à partir du schéma spécifié.
ingestion_mode: spécifiez le mode d'ingestion pour le transfert. Les valeurs acceptées sontFULLetINCREMENTAL. Pour en savoir plus, consultez Configurer les transferts incrémentiels.translation_output_gcs_path: (facultatif) spécifiez le chemin d'accès au dossier Cloud Storage contenant les fichiers de mappage de schéma du moteur de traduction. Vous pouvez laisser ce champ vide pour que le connecteur Snowflake détecte automatiquement votre schéma.- Le chemin d'accès doit respecter le format
gs://translation_target_base_uri/metadata/config/db/schema/et se terminer par/.
- Le chemin d'accès doit respecter le format
storage_integration_object_name: spécifiez le nom de l'objet d'intégration du stockage Snowflake.max_file_size_mb: (facultatif) spécifiez la taille maximale de chaque fichier déchargé de Snowflake vers l'emplacement intermédiaire en Mo. La valeur doit être comprise entre16et5120. La valeur par défaut est512.staging_gcs_uri: saisissez l'URI du bucket Cloud Storage à utiliser pour préparer vos données.use_private_network: si vous créez un transfert de données privées, définissez la valeur surTRUE.service_attachment: si vous créez un transfert de données privé, spécifiez l'URI du rattachement de service. Pour en savoir plus, consultez Créer une configuration de transfert Snowflake privée.private_network_service: si vous créez un transfert de données privé, spécifiez le lien autonome du service NLB. Pour en savoir plus, consultez Créer une configuration de transfert Snowflake privée.
Par exemple, pour un compte Snowflake hébergé sur AWS, la commande suivante crée un transfert Snowflake nommé Snowflake transfer config avec un ensemble de données cible nommé your_bq_dataset et un projet dont l'ID est your_project_id.
PARAMS='{ "account_identifier": "your_account_identifier", "auth_mechanism": "KEY_PAIR", "aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_aws_secret_access_key", "cloud_provider": "AWS", "database": "your_sf_database", "ingestion_mode": "INCREMENTAL", "private_key": "-----BEGIN PRIVATE KEY----- privatekey\nseparatedwith\nnewlinecharacters=-----END PRIVATE KEY-----", "schema": "your_snowflake_schema", "service_account": "your_service_account", "storage_integration_object_name": "your_storage_integration_object", "max_file_size_mb": "512", "staging_s3_uri": "s3://your/s3/bucket/uri", "table_name_patterns": ".*", "translation_output_gcs_path": "gs://sf_test_translation/output/metadata/config/database_name/schema_name/", "username": "your_sf_username", "warehouse": "your_warehouse" }' bq mk --transfer_config \ --project_id=your_project_id \ --target_dataset=your_bq_dataset \ --display_name='snowflake transfer config' \ --params="$PARAMS" \ --data_source=snowflake_migration
API
Utilisez la méthode projects.locations.transferConfigs.create et fournissez une instance de la ressource TransferConfig.
Spécifier une clé de chiffrement avec les transferts
Vous pouvez spécifier des clés de chiffrement gérées par le client (CMEK) pour chiffrer les données d'une exécution de transfert. Vous pouvez utiliser une clé CMEK pour accepter les transferts provenant de Snowflake.Lorsque vous spécifiez une clé CMEK avec un transfert, le service de transfert de données BigQuery l'applique à tous les caches sur disque intermédiaires des données ingérées afin que l'intégralité du workflow de transfert de données soit compatible avec CMEK.
Vous ne pouvez pas mettre à jour un transfert existant pour ajouter une clé CMEK si le transfert n'a pas été initialement créé avec une clé CMEK. Par exemple, vous ne pouvez pas modifier une table de destination initialement chiffrée par défaut pour être chiffrée avec des clés CMEK. À l'inverse, vous ne pouvez pas modifier une table de destination chiffrée par CMEK pour obtenir un type de chiffrement différent.
Vous pouvez mettre à jour une clé CMEK pour un transfert si la configuration de celui-ci a été initialement créée avec un chiffrement CMEK. Lorsque vous mettez à jour une clé CMEK pour une configuration de transfert, le service de transfert de données BigQuery propage cette clé aux tables de destination à la prochaine exécution du transfert, où le service de transfert de données BigQuery remplace toutes les clés CMEK obsolètes par la nouvelle clé lors de l'exécution du transfert. Pour en savoir plus, consultez Mettre à jour un transfert.
Vous pouvez également utiliser les clés par défaut d'un projet. Lorsque vous spécifiez une clé de projet par défaut avec un transfert, le service de transfert de données BigQuery utilise cette clé pour toutes les nouvelles configurations de transfert.
Quotas et limites
Par défaut, BigQuery a un quota de charge de 15 To par tâche de chargement et par table. En interne, Snowflake compresse les données de la table. La taille de la table exportée est donc supérieure à celle indiquée par Snowflake.
Pour améliorer les temps de chargement des tables plus volumineuses et supprimer la limite de chargement BigQuery de 15 To, spécifiez le type de job PIPELINE pour votre attribution de réservation.
En raison du modèle de cohérence d'Amazon S3, il est possible que certains fichiers ne soient pas inclus dans le transfert vers BigQuery.
Optimiser les performances de transfert de données
Vous pouvez surveiller les performances de vos transferts de données en consultant les journaux de transfert de données. Pour améliorer les performances de vos transferts de données, nous vous recommandons d'effectuer les étapes d'optimisation suivantes :
- Conservez votre instance Snowflake, votre bucket intermédiaire et votre ensemble de données BigQuery dans la même région.
- Pour améliorer la vitesse de déchargement des tables, procédez comme suit :
- Augmentez la taille de votre entrepôt de données virtuel Snowflake, en particulier lorsque vous transférez de grandes tables Snowflake (1 Tio ou plus).
- Ajustez l'option
MAX_FILE_SIZEdans la configuration du transfert.- Des fichiers moins volumineux peuvent améliorer la vitesse de transfert, mais s'ils sont trop petits, cela peut entraîner un trop grand nombre de fichiers.
- Vous pouvez améliorer la vitesse de chargement des tables en augmentant le nombre de réservations d'emplacements BigQuery pour les types de jobs
PIPELINEetQUERY. - Lorsque vous effectuez un transfert complet, évitez le clustering et le partitionnement sur la table BigQuery de destination.
- Lorsque vous effectuez un transfert incrémentiel en mode Upsert, pensez à regrouper et à partitionner les colonnes de clé primaire pour améliorer les performances du transfert.
- Toutefois, évitez le clustering et le partitionnement sur les colonnes non clés primaires pour éviter des opérations de fusion plus lentes.
Tarifs
Pour plus d'informations sur la tarification du service de transfert de données BigQuery, consultez la page Tarifs.
- Si l'entrepôt de données Snowflake et le bucket Amazon S3 se trouvent dans des régions différentes, Snowflake applique des frais de sortie lorsque vous exécutez un transfert de données Snowflake. Aucuns frais de sortie ne s'appliquent aux transferts de données Snowflake si l'entrepôt de données Snowflake et le bucket Amazon S3 se trouvent dans la même région.
- Lorsque des données sont transférées d'AWS vers Google Cloud, des frais de sortie inter-cloud s'appliquent.
Étapes suivantes
- Obtenez plus d'informations sur le Service de transfert de données BigQuery.
- Migrez du code SQL avec la traduction SQL par lot.