
Migrar tabelas do metastore do Apache Hive para Google Cloud
Neste documento, mostramos como migrar suas tabelas do Iceberg e do Hive gerenciadas pelo Apache Hive Metastore para Google Cloud usando o serviço de transferência de dados do BigQuery.
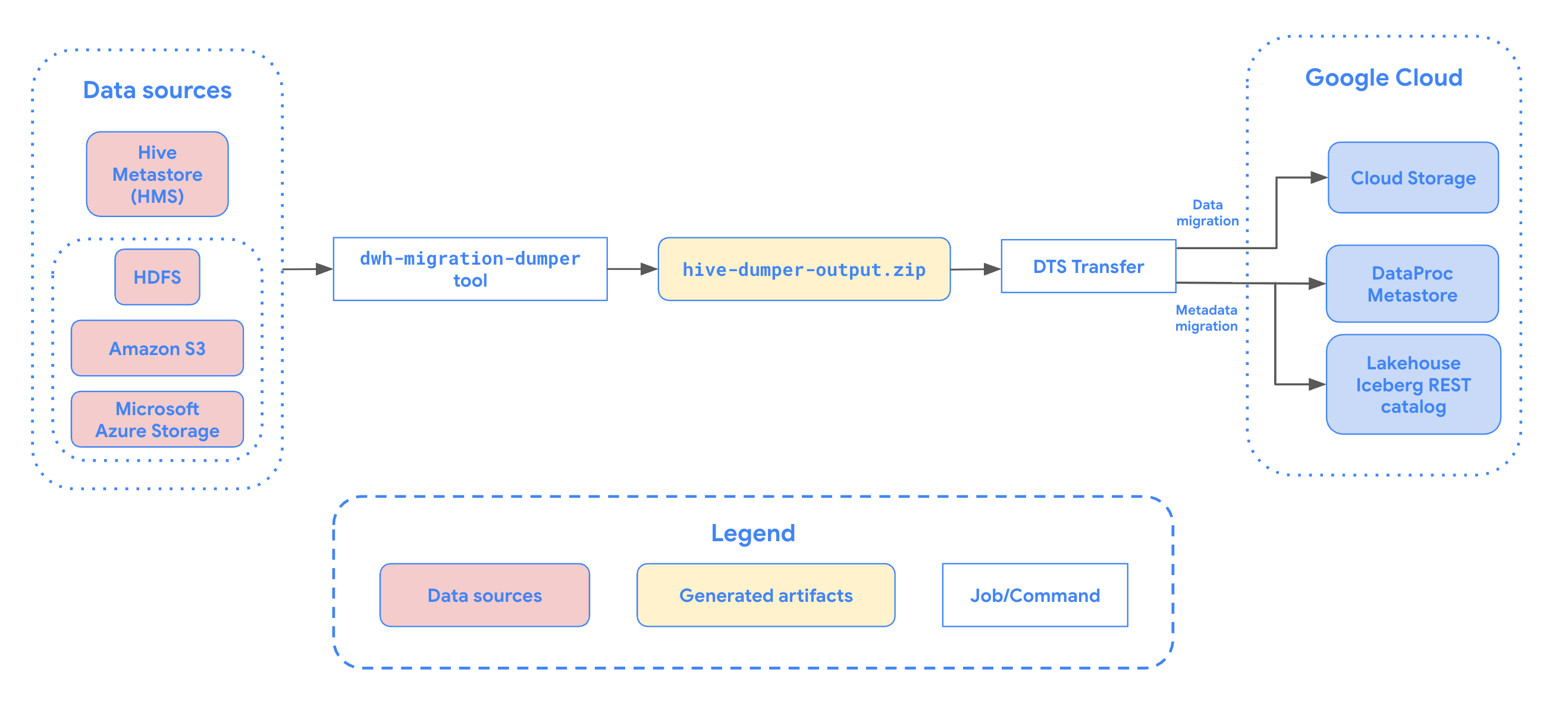
Com o conector de migração do Apache Hive Metastore no serviço de transferência de dados do BigQuery, é possível migrar sem problemas as tabelas do Hive Metastore para Google Cloud em grande escala. Esse conector é compatível com tabelas do Hive e do Iceberg de instalações locais e ambientes de nuvem, incluindo configurações do Cloudera. O conector de migração do metastore do Hive é compatível com arquivos armazenados nas seguintes fontes de dados:
- Sistema de arquivos distribuídos do Apache Hadoop (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Armazenamento de Blobs do Azure ou Azure Data Lake Storage Gen2
Com o conector de migração do metastore do Hive, é possível usar o Cloud Storage como armazenamento de arquivos e registrar as tabelas do metastore do Hive com um dos seguintes metastores:
Catálogo de ambientes de execução do Lakehouse Iceberg REST Catalog
Recomendamos usar o catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse para todos os seus dados do Iceberg.
O catálogo REST do Iceberg do catálogo de tempo de execução do Lakehouse cria interoperabilidade entre seus mecanismos de consulta ao oferecer uma única fonte de verdade para todos os seus dados do Iceberg. É possível usar o BigQuery para consultar os dados, além do Apache Spark e de outros mecanismos de OSS. O catálogo de ambientes de execução do Lakehouse (catálogo REST do Iceberg) é compatível apenas com formatos de tabela do Iceberg.
-
O metastore do Dataproc é compatível com os formatos de tabela Hive e Iceberg. Só é possível usar o Apache Spark e outros mecanismos de OSS para ler e gravar dados no metastore do Dataproc.
Esse conector aceita transferências completas e somente de metadados. As transferências completas transferem seus dados e metadados das tabelas de origem para o metastore de destino. É possível criar uma transferência somente de metadados se você já tiver seus dados no Cloud Storage e quiser apenas registrá-los em um metastore de destino.
O diagrama a seguir mostra uma visão geral do processo de migração.
Limitações
As transferências de tabelas do metastore do Hive estão sujeitas às seguintes limitações:
- As transferências do Hive Metastore precisam ter um intervalo mínimo de 30 minutos entre duas execuções programadas. As execuções sob demanda ainda podem ser acionadas em qualquer intervalo.
- Para migrar tabelas do Hive, use o metastore do Dataproc como metastore de destino.
- Os nomes de arquivos precisam obedecer aos requisitos de nomenclatura de objetos do Cloud Storage.
- O Cloud Storage tem um limite de 5 TiB para objetos únicos. Não será possível transferir arquivos maiores que 5 TiB nas tabelas do metastore do Hive.
- O Serviço de transferência do Cloud Storage tem comportamentos específicos se os dados forem alterados na origem enquanto uma transferência estiver em andamento. Não recomendamos gravar em tabelas enquanto a migração estiver em andamento. Para conferir uma lista de outras limitações do Serviço de transferência do Cloud Storage, consulte Limitações conhecidas.
Opções de ingestão de dados
Nas seções a seguir, você encontra mais informações sobre como configurar suas transferências do metastore do Hive.
Transferências incrementais
Quando uma configuração de transferência é definida com uma programação recorrente, cada transferência subsequente atualiza a tabela no Google Cloud com as atualizações mais recentes feitas na tabela de origem. Por exemplo, todas as atualizações de dados e todas as operações de inserção, exclusão ou atualização com mudanças de esquema são refletidas no Google Cloud a cada transferência.
Filtrar partições
É possível transferir um subconjunto de partições das tabelas do Hive fornecendo um arquivo JSON de filtro personalizado armazenado no Cloud Storage. Ao programar a transferência, forneça o caminho completo do Cloud Storage para esse arquivo JSON usando o parâmetro partition_filter_gcs_path.
Confira a seguir um exemplo da estrutura do arquivo JSON de filtro:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partition":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partition":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partition":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partition":
["partition1;value1;value2"]
}
]
}
Condições de filtro
O campo condition no arquivo JSON aceita os seguintes valores, cada um com
um formato específico para a matriz partition:
IN: especifica os caminhos exatos da partição a serem incluídos. A matrizpartitioncontém strings que representam a estrutura exata de diretórios das partições em relação ao caminho base da tabela (por exemplo,["partition_key1=value1/partition_key2=value2"]). É possível especificar vários caminhos na matriz.LESS_THAN: inclui partições em que o valor da chave de partição principal é menor ou igual ao valor especificado. A matrizpartitionprecisa conter uma única string no formato["<partition_key>;<value>"].GREATER_THAN: inclui partições em que o valor da chave de partição principal é maior ou igual ao valor especificado. A matrizpartitionprecisa conter uma única string no formato["<partition_key>;<value>"].RANGE: inclui partições em que o valor da chave de partição principal está dentro do intervalo especificado (inclusivo). A matrizpartitionprecisa conter uma única string no formato["<partition_key>;<start_value>;<end_value>"].
As condições de filtro estão sujeitas às seguintes regras e restrições:
- Valores inclusivos:as condições de filtro para
GREATER_THAN,LESS_THANeRANGEincluem os valores fornecidos. Por exemplo, um filtro deLESS_THANcom um valor de2023inclui partições até2023. - Exclusão de partição:se uma partição de destino existente atender ao filtro de partição e não estiver mais presente na origem, ela será removida do metastore de destino. No entanto, os arquivos de dados da partição não são excluídos do bucket de destino do Cloud Storage.
- Restrições de tabela única:
- Não é possível usar vários filtros na mesma tabela.
- Não é possível misturar tipos diferentes de condição (por exemplo,
GREATER_THANeIN) na mesma tabela.
- Coluna de partição de destino:as condições de filtro, como
GREATER_THAN,LESS_THANeRANGE, precisam segmentar a coluna de partição principal. - Limitações de prefixo:a combinação de filtros especificada não pode resultar em mais de 1.000 prefixos por tabela. Por exemplo, um filtro como
year>2020em uma tabela particionada poryear/month/dayprecisa resultar em menos de 1.000 prefixosyear=únicos.
Antes de começar
Antes de programar a transferência do metastore do Hive, siga as etapas desta seção.
Ativar APIs
Ative as seguintes APIs no projetoGoogle Cloud :
- API Data Transfer
- API Storage Transfer
Um agente de serviço é criado quando você ativa a API Data Transfer.
Configurar permissões
Para configurar permissões para uma transferência do metastore do Hive, siga as etapas nas seções a seguir.
- O usuário ou a conta de serviço que está criando a transferência precisa receber o papel de administrador do BigQuery (
roles/bigquery.admin). Se você usar uma conta de serviço, ela será usada apenas para criar a transferência. Um agente de serviço (P4SA) é criado ao ativar a API Data Transfer.
Para garantir que o agente de serviço tenha as permissões necessárias para executar uma transferência do Hive Metastore, peça ao administrador para conceder os seguintes papéis do IAM ao agente de serviço no projeto:
- Administrador de transferências do Storage (
roles/storagetransfer.admin) - Consumidor do Service Usage (
roles/serviceusage.serviceUsageConsumer) - Administrador do Storage (
roles/storage.admin) -
Para migrar metadados para o catálogo REST do Iceberg do catálogo de ambientes de execução do Lakehouse:
Administrador do BigLake (
roles/biglake.admin) -
Para migrar metadados para o metastore do Dataproc:
Proprietário de dados do metastore do Dataproc (
roles/metastore.metadataOwner)
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
O administrador também pode conceder ao agente de serviço as permissões necessárias por meio de papéis personalizados ou outros papéis predefinidos.
- Administrador de transferências do Storage (
Se você estiver usando uma conta de serviço, conceda ao agente de serviço o papel
roles/iam.serviceAccountTokenCreatorcom o seguinte comando:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Conceda ao agente de serviço do Serviço de transferência do Cloud Storage (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) os seguintes papéis no projeto:roles/storage.admin- Se você estiver migrando de um ambiente no local/HDFS, também será necessário conceder o papel
roles/storagetransfer.serviceAgent.
Também é possível configurar permissões mais detalhadas. Para mais informações, consulte este guia:
Gerar arquivo de metadados para o Apache Hive
Execute a ferramenta dwh-migration-dumper para extrair
metadados do Apache Hive.
A ferramenta gera um arquivo chamado hive-dumper-output.zip que pode ser enviado
para um bucket do Cloud Storage. Neste documento, esse bucket do Cloud Storage é chamado de DUMPER_BUCKET.
Também é possível programar uploads periódicos usando um script. Para mais informações, consulte
Automatizar a execução da ferramenta dumper com um job cron.
Configurar o Serviço de transferência do Cloud Storage
Selecione uma das seguintes opções:
HDFS
Um agente de transferência do Cloud Storage é necessário para transferências locais ou do HDFS.
Para configurar o agente, faça o seguinte:
- Instale o Docker nas máquinas de agente locais.
- Crie um pool de agentes de serviço do Serviço de transferência do Cloud Storage no seu projeto Google Cloud .
- Instale agentes nas máquinas de agentes locais.
Amazon S3
As transferências do Amazon S3 são feitas sem agentes.
Para configurar o Serviço de transferência do Cloud Storage para uma transferência do Amazon S3, faça o seguinte:
- Configure as credenciais de acesso para o Amazon S3 da AWS.
- Anote o ID da chave de acesso e a chave de acesso secreta depois de configurar as credenciais de acesso.
- Adicione intervalos de IP usados pelos workers do Serviço de transferência do Cloud Storage à lista de IPs permitidos se o projeto da AWS usar restrições de IP.
Microsoft Azure
As transferências do Armazenamento do Microsoft Azure são sem agente.
Para configurar o Serviço de transferência do Cloud Storage para uma transferência do Microsoft Azure Storage, faça o seguinte:
- Gere um token de assinatura de acesso compartilhado (SAS) para sua conta de armazenamento do Microsoft Azure.
- Anote o token SAS depois de gerá-lo.
- Adicione os intervalos de IP usados pelos workers do Serviço de transferência do Cloud Storage à lista de IPs permitidos se a conta de armazenamento do Microsoft Azure usar restrições de IP.
Programar uma transferência do metastore do Hive
Selecione uma das seguintes opções:
Console
Acesse a página "Transferências de dados" no console Google Cloud .
Clique em Criar transferência.
Na seção Tipo de origem, selecione Hive Metastore na lista Origem.
Em Local, selecione um tipo de local e uma região.
No campo Nome de exibição da seção Nome de configuração da transferência, insira um nome para a transferência de dados.
Na seção Opções de programação, realize estas ações:
- Na lista Frequência de repetição, selecione uma opção para especificar com que frequência essa transferência de dados é executada. Para especificar uma frequência de repetição personalizada, selecione Personalizada. Se você selecionar Sob demanda, essa transferência vai ser executada quando você acionar manualmente a transferência.
- Se aplicável, selecione Começar agora ou Começar no horário definido e forneça uma data de início e um horário de execução.
Na seção Detalhes da fonte de dados, faça o seguinte:
- Em Estratégia de transferência, selecione uma das seguintes opções:
FULL_TRANSFER: transfere todos os dados e registra os metadados com o metastore de destino. Essa é a opção padrão.METADATA_ONLY: registra apenas metadados. É necessário ter dados no local correto do Cloud Storage referenciado nos metadados.
- Em Padrões de nome da tabela, especifique as tabelas do data lake do HDFS a serem transferidas fornecendo nomes ou padrões que correspondam às tabelas no banco de dados do HDFS. Você precisa usar a sintaxe de expressão regular do Java para especificar padrões de tabela. Por exemplo:
db1..*corresponde a todas as tabelas em db1.db1.table1;db2.table2corresponde a table1 em db1 e table2 em db2.
- Em Caminho do GCS de despejo de descoberta do BQMS, insira o caminho para o arquivo
hive-dumper-output.zipque você gerou ao criar um arquivo de metadados para Apache Hive. Se você estiver usando automação de saída do dumper comcron, forneça o caminho da pasta do Cloud Storage configurado em--gcs-base-path, que contém arquivos ZIP de saída do dumper.- Em Tipo de armazenamento, selecione uma das seguintes opções: Esse campo só estará disponível se a Estratégia de transferência estiver definida como
FULL_TRANSFER: HDFS: selecione essa opção se o armazenamento de arquivos forHDFS. No campo Nome do pool de agentes do STS, forneça o nome do pool de agentes que você criou ao configurar o Agente de transferência do Storage.S3: selecione essa opção se o armazenamento de arquivos forAmazon S3. Nos campos ID da chave de acesso e Chave de acesso secreta, informe o ID e a chave de acesso secreta que você criou ao configurar suas credenciais de acesso.AZURE: selecione essa opção se o armazenamento de arquivos forAzure Blob Storage. No campo Token SAS, forneça o token SAS criado ao configurar suas credenciais de acesso.
- Em Tipo de armazenamento, selecione uma das seguintes opções: Esse campo só estará disponível se a Estratégia de transferência estiver definida como
- Opcional: em Caminho do gcs do filtro de partição, insira um caminho completo do Cloud Storage para um arquivo JSON de filtro personalizado e filtre partições das tabelas de origem.
- Em Caminho de destino do GCS, insira um caminho para um bucket do Cloud Storage para armazenar os dados migrados.
- Escolha o tipo de metastore de destino na lista suspensa:
DATAPROC_METASTORE(legado): selecione essa opção para armazenar seus metadados no Metastore do Dataproc. Você precisa fornecer o URL do metastore do Dataproc em URL do metastore do Dataproc.BIGLAKE_REST_CATALOG: selecione essa opção para armazenar seus metadados no catálogo REST do Iceberg do ambiente de execução do Lakehouse. O catálogo é criado com base no bucket de destino do Cloud Storage.
- Opcional: em Conta de serviço, insira uma conta de serviço para usar com essa transferência de dados. A conta de serviço precisa pertencer ao mesmo projetoGoogle Cloud em que a configuração de transferência e o conjunto de dados de destino são criados.
- Em Estratégia de transferência, selecione uma das seguintes opções:
bq
Para programar a transferência do metastore do Hive, insira o comando bq mk
e forneça a flag de criação da transferência --transfer_config:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
Substitua:
TRANSFER_NAME: o nome de exibição da configuração da transferência. O nome da transferência pode ser qualquer valor que permita identificá-la facilmente, caso precise modificá-la mais tarde.SERVICE_ACCOUNT: o nome da conta de serviço usado para criar a transferência.A conta de serviço precisa pertencer ao mesmo projetoGoogle Cloud em que a configuração de transferência e o conjunto de dados de destino são criados.PROJECT_ID: o ID do projeto Google Cloud . Se--project_idnão for fornecido para especificar um projeto determinado, o projeto padrão será usado.REGION: local da configuração de transferência.TRANSFER_STRATEGY: (opcional) especifique um dos seguintes valores:FULL_TRANSFER: transfere todos os dados e registra metadados com o metastore de destino. Esse é o valor padrão.METADATA_ONLY: registra apenas metadados. Os dados precisam estar no local correto do Cloud Storage referenciado nos metadados.
LIST_OF_TABLES: uma lista de entidades a serem transferidas. Use uma especificação de nomenclatura hierárquica:database.table. Esse campo aceita expressões regulares RE2 para especificar tabelas. Exemplo:db1..*: especifica todas as tabelas no banco de dadosdb1.table1;db2.table2: uma lista de tabelas
DUMPER_BUCKET: o bucket do Cloud Storage que contém o arquivohive-dumper-output.zip. Se você estiver usando a automação de saída do dumper comcron, mudetable_metadata_pathpara o caminho da pasta do Cloud Storage configurado com--gcs-base-pathna configuração do cron. Por exemplo:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>".MIGRATION_BUCKET: caminho de destino do GCS para onde todos os arquivos subjacentes serão carregados. Disponível apenas setransfer_strategyforFULL_TRANSFER.METASTORE: o tipo de metastore para migrar. Defina um dos seguintes valores:DATAPROC_METASTORE: para transferir metadados para o metastore do Dataproc.BIGLAKE_REST_CATALOG: para transferir metadados para o catálogo de tempo de execução do Lakehouse Catálogo REST do Iceberg.
DATAPROC_METASTORE_URL: o URL do seu metastore do Dataproc. Obrigatório semetastoreforDATAPROC_METASTORE.BIGLAKE_METASTORE_DATASET: o conjunto de dados do BigQuery para seu catálogo de tempo de execução do Lakehouse. Obrigatório semetastoreforBIGLAKE_METASTOREetransfer_strategyforFULL_TRANSFER.STORAGE_TYPE: especifique o armazenamento de arquivos para suas tabelas. Os tipos aceitos sãoHDFS,S3eAZURE. Obrigatório setransfer_strategyforFULL_TRANSFER.AGENT_POOL_NAME: o nome do pool de agentes usado para criar agentes. Obrigatório sestorage_typeforHDFS.AWS_ACCESS_KEY_ID: o ID da chave de acesso das credenciais de acesso. Obrigatório sestorage_typeforS3.AWS_SECRET_ACCESS_KEY: a chave de acesso secreta das credenciais de acesso. Obrigatório sestorage_typeforS3.AZURE_SAS_TOKEN: o token SAS das credenciais de acesso. Obrigatório sestorage_typeforAZURE.FILTER_GCS_PATH: (opcional) um caminho completo do Cloud Storage para um arquivo JSON de filtro personalizado para filtrar partições.
Execute este comando para criar a configuração de transferência e iniciar a transferência de tabelas gerenciadas do Hive. As transferências são programadas para serem executadas a cada 24 horas por padrão, mas podem ser configuradas com opções de programação de transferência.
Quando a transferência for concluída, suas tabelas no cluster do Hadoop serão migradas para MIGRATION_BUCKET.
Automatizar a execução da ferramenta dumper com um job cron
É possível automatizar transferências incrementais usando um job
cron para executar a ferramenta
dwh-migration-dumper. Automatizar a extração de metadados para garantir que um despejo atualizado da fonte de dados esteja disponível para execuções de transferência incremental subsequentes.
Antes de começar
Antes de usar esse script de automação, faça o seguinte:
Conclua todos os pré-requisitos da ferramenta dumper.
Instale a CLI do Google Cloud. O script usa a ferramenta de linha de comando
gsutilpara fazer upload da saída do dumper para o Cloud Storage.Para fazer a autenticação com Google Cloud e permitir que
gsutilfaça upload de arquivos para o Cloud Storage, execute o seguinte comando:gcloud auth application-default login
Programar a automação
Salve o script a seguir em um arquivo local. Esse script foi projetado para ser configurado e executado por um daemon
cronpara automatizar o processo de extração e upload da saída do dumper.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Para tornar o script executável, use o seguinte comando:
chmod +x PATH_TO_SCRIPT
Programe o script usando
crontab, substituindo as variáveis pelos valores apropriados para seu job. Adicione uma entrada para programar o job. Os exemplos a seguir executam o script todos os dias às 2h30:Se você estiver executando em um host que tem acesso direto ao metastore do Hive e não exige autenticação do Kerberos, execute o seguinte comando:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Se a instância do metastore do Hive exigir autenticação do Kerberos, execute o seguinte comando:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
Considerações sobre programação
Para evitar dados desatualizados, execute a ferramenta de despejo antes da transferência de dados programada.
Recomendamos fazer alguns testes manuais do script para determinar o
tempo médio que a ferramenta de despejo leva para gerar a saída. Use esse
tempo para definir um cronograma de job do cron que anteceda a execução da transferência para
garantir a atualização de dados.
Monitorar e conferir o status da transferência
É possível monitorar transferências no nível do recurso para tabelas individuais e acompanhar o progresso, ver detalhes granulares de erros e consultar o estado de recursos específicos que estão sendo migrados.
Para conferir o progresso e o status dos seus recursos, selecione uma das seguintes opções:
Console
No Google Cloud console, acesse a página Transferências de dados.
Clique na configuração de transferência na lista.
Na página Detalhes da transferência, clique na guia Tabelas transferidas.
Confira a lista de recursos que estão sendo transferidos. Você pode conferir detalhes como os seguintes:
- Status da última transferência: o estado atual do recurso com base na transferência mais recente, incluindo o progresso da conclusão.
- Nome da tabela: o nome do recurso que está sendo transferido. Clique no nome do recurso para ver uma visualização detalhada dele.
- Última execução: a última execução de transferência que atualizou o recurso.
- Resumo do status: métricas de progresso granulares ou mensagens de erro se a transferência falhar.
- Última execução concluída: a última execução que transferiu o recurso.
Use a barra de filtros para pesquisar recursos específicos por nome ou filtrar pelo status atual deles, por exemplo, Transferências com falha. O filtro Nome da tabela é compatível com a correspondência de caracteres curinga, por exemplo, usando *, mas não há compatibilidade com outros campos de filtro.
API
É possível consultar o status dos recursos de transferência usando a API do serviço de transferência de dados do BigQuery.
Listar todos os recursos e os status deles
Para listar todos os recursos e os status deles, use o
método projects.locations.transferConfigs.transferResources.list.
Execute a solicitação de API com as seguintes informações:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
curl comando:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
É possível filtrar os resultados por nome ou estado do recurso. Por exemplo, para encontrar
todas as transferências com falha, adicione
?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED"
ao URL da solicitação.
Substitua:
CONFIG_ID: o ID da configuração de transferência.LOCATION: o local em que a configuração de transferência foi criada.PROJECT_ID: o ID do projeto Google Cloud que está executando as transferências.
Receber um recurso específico
Para conferir o status de uma tabela ou partição específica, use o
método projects.locations.transferConfigs.transferResources.get.
Execute a solicitação de API com as seguintes informações:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
curl comando:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Substitua:
CONFIG_ID: o ID da configuração de transferência.LOCATION: o local em que a configuração de transferência foi criada.PROJECT_ID: o ID do Google Cloud projeto que está executando as transferências.RESOURCE_ID: o ID do recurso, por exemplo, o nome da tabela.
Cotas e limites de simultaneidade
Para cada execução do serviço de transferência de dados do BigQuery, o conector do metastore do Hive executa um job do serviço de transferência do Cloud Storage por tabela.
Quando a cota é atingida, a transferência aguarda até que mais cota esteja disponível. Os jobs do Serviço de transferência do Cloud Storage são criados no projeto do cliente e estão sujeitos a cotas e limites do Serviço de transferência do Cloud Storage.
Preços
Não há custo para usar o conector do metastore do Apache Hive e transferir seus dados. Depois que os dados são transferidos, você é cobrado pelo armazenamento deles no destino. Para ver mais informações, consulte os seguintes tópicos: