
Migrer les tables Apache Hive Metastore versGoogle Cloud
Ce document explique comment migrer vos tables Iceberg et Hive gérées par Apache Hive Metastore versGoogle Cloud à l'aide du service de transfert de données BigQuery.
Le connecteur de migration Apache Hive Metastore du service de transfert de données BigQuery vous permet de migrer facilement vos tables Hive Metastore vers Google Cloud à grande échelle. Ce connecteur est compatible avec les tables Hive et Iceberg provenant d'installations sur site et d'environnements cloud, y compris les configurations Cloudera. Le connecteur de migration Hive Metastore est compatible avec les fichiers stockés dans les sources de données suivantes :
- Système de fichiers distribué Hadoop (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage ou Azure Data Lake Storage Gen2
Avec le connecteur de migration Hive Metastore, vous pouvez utiliser Cloud Storage comme stockage de fichiers et enregistrer vos tables Hive Metastore avec l'un des metastores suivants :
Catalogue d'environnements d'exécution Lakehouse : catalogue REST Iceberg
Nous vous recommandons d'utiliser le catalogue REST Iceberg du catalogue d'exécution Lakehouse pour toutes vos données Iceberg.
Le catalogue REST Iceberg du catalogue d'environnements d'exécution Lakehouse crée une interopérabilité entre vos moteurs de requête en offrant une source unique de vérité pour toutes vos données Iceberg. Vous pouvez utiliser BigQuery pour interroger les données, en plus d'Apache Spark et d'autres moteurs OSS. Le catalogue d'environnements d'exécution Lakehouse (catalogue REST Iceberg) n'est compatible qu'avec les formats de table Iceberg.
Catalogue Hive du catalogue d'environnements d'exécution Lakehouse (Aperçu)
Nous vous recommandons d'utiliser le catalogue Hive de l'environnement d'exécution Lakehouse pour toutes vos tables Hive.
Le catalogue Hive du catalogue d'environnements d'exécution Lakehouse vous permet d'enregistrer vos tables Hive migrées avec le catalogue d'environnements d'exécution Lakehouse à l'aide d'un catalogue Hive. Il s'agit d'un metastore sans serveur pour les tables Apache Hive. Vous pouvez utiliser BigQuery pour interroger les données (sous réserve de limitations de format), en plus d'Apache Spark et d'autres moteurs OSS.
-
Dataproc Metastore est compatible avec les formats de table Hive et Iceberg. Vous ne pouvez utiliser qu'Apache Spark et d'autres moteurs OSS pour lire et écrire des données dans Dataproc Metastore.
Ce connecteur est compatible avec les transferts complets et les transferts de métadonnées uniquement. Les transferts complets transfèrent à la fois vos données et vos métadonnées de vos tables sources vers votre metastore cible. Vous pouvez créer un transfert de métadonnées uniquement si vos données se trouvent déjà dans Cloud Storage et si vous souhaitez uniquement les enregistrer dans un métastore de destination.
Le diagramme suivant présente une vue d'ensemble du processus de migration.
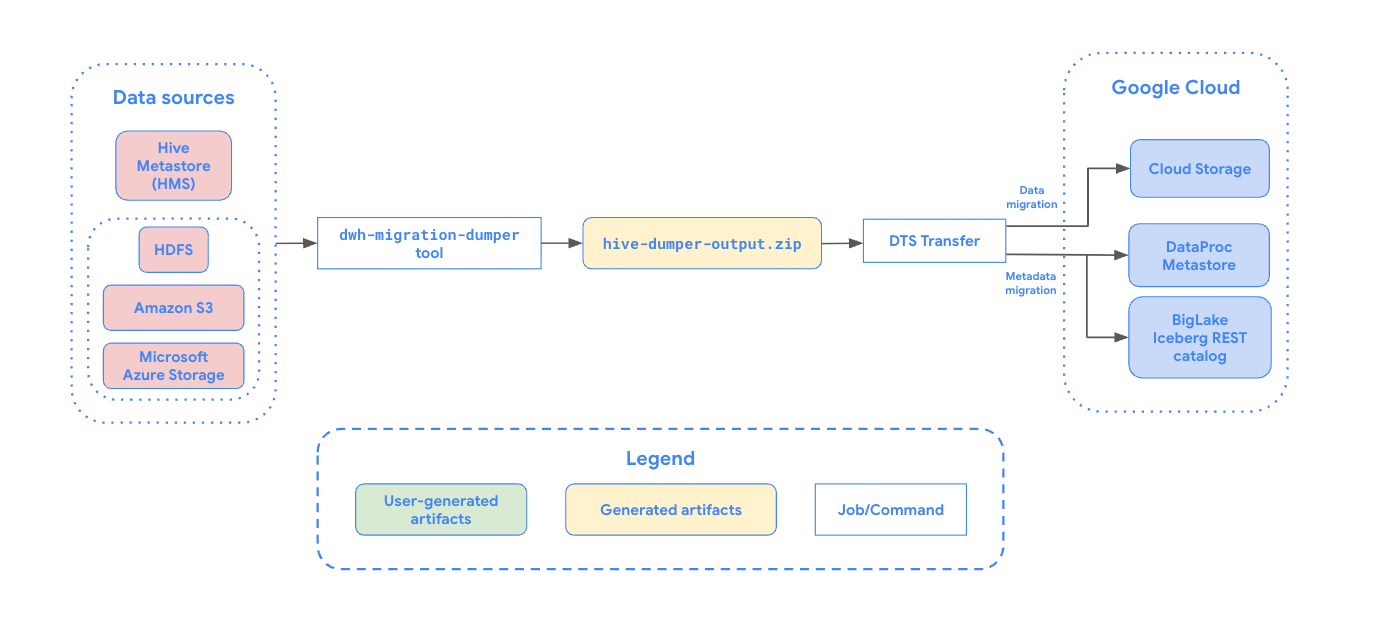
Limites
Les transferts de tables Hive Metastore sont soumis aux limitations suivantes :
- Les transferts Hive Metastore doivent être espacés d'au moins 30 minutes entre deux exécutions planifiées. Les exécutions à la demande peuvent toujours être déclenchées à n'importe quel intervalle.
- Les noms de fichiers doivent respecter les exigences concernant les noms d'objets Cloud Storage.
- La taille des objets individuels dans Cloud Storage est limitée à 5 Tio. Le transfert des fichiers de plus de 5 Tio dans vos tables Hive Metastore échouera.
- Le service de transfert de stockage a des comportements spécifiques si les données sont modifiées à la source pendant un transfert. Nous vous déconseillons d'écrire dans les tables pendant qu'elles sont en cours de migration. Pour obtenir la liste des autres limites du service de transfert de stockage, consultez les limitations connues.
Limites du catalogue Hive du catalogue d'environnements d'exécution Lakehouse
Lorsque vous utilisez le catalogue Hive du catalogue d'exécution Lakehouse (BIGLAKE_HIVE_CATALOG) comme metastore de destination, les limites et considérations suivantes s'appliquent :
- L'ID de catalogue Hive du catalogue du runtime Lakehouse ne doit contenir que des lettres minuscules, des chiffres et des traits de soulignement (
_). Il ne doit pas contenir de tirets (-) ni de lettres majuscules. - Vous ne pouvez pas afficher ni gérer les catalogues Hive du catalogue d'exécution Lakehouse dans la console Google Cloud . Toutefois, les tables migrées sont visibles et peuvent être interrogées dans l'ensemble de données BigQuery cible.
- Toutes les limites du catalogue Hive du runtime Lakehouse pour les formats de métadonnées et les types de données Open Source s'appliquent.
- Pour en savoir plus sur la compatibilité avec les formats tels que CSV et JSON, consultez Formats de stockage compatibles.
- Pour en savoir plus sur les types de données non compatibles (tels que
UNIONou les tableaux imbriqués) et les statistiques sur les colonnes, consultez Limites du metastore et Limites des partitions.
Options d'ingestion de données
Les sections suivantes fournissent plus d'informations sur la façon de configurer vos transferts Hive Metastore.
Transferts incrémentiels
Lorsqu'une configuration de transfert est définie avec une programmation récurrente, chaque transfert ultérieur met à jour le tableau sur Google Cloud avec les dernières modifications apportées au tableau source. Par exemple, toutes les mises à jour de données, ainsi que toutes les opérations d'insertion, de suppression ou de mise à jour avec des modifications de schéma sont reflétées dans Google Cloud à chaque transfert.
Filtrer les partitions
Vous pouvez transférer un sous-ensemble de partitions de vos tables Hive en fournissant un fichier JSON de filtre personnalisé stocké dans Cloud Storage. Lorsque vous planifiez le transfert, indiquez le chemin d'accès Cloud Storage complet à ce fichier JSON à l'aide du paramètre partition_filter_gcs_path.
Voici un exemple de structure de fichier JSON de filtre :
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
Conditions de filtrage
Le champ condition du fichier JSON accepte les valeurs suivantes, chacune avec un format spécifique pour le tableau partitions :
IN: spécifie les chemins d'accès exacts des partitions à inclure. Le tableaupartitionscontient des chaînes représentant la structure exacte des répertoires des partitions par rapport au chemin de base de la table (par exemple,["partition_key1=value1/partition_key2=value2"]). Vous pouvez spécifier plusieurs chemins d'accès dans le tableau.LESS_THAN: inclut les partitions dont la valeur de la clé de partition principale est inférieure ou égale à la valeur spécifiée. Le tableaupartitionsdoit contenir une seule chaîne au format["<partition_key>;<value>"].GREATER_THAN: inclut les partitions dont la valeur de la clé de partition principale est supérieure ou égale à la valeur spécifiée. Le tableaupartitionsdoit contenir une seule chaîne au format["<partition_key>;<value>"].RANGE: inclut les partitions dont la valeur de clé de partition principale se trouve dans la plage spécifiée (inclusive). Le tableaupartitionsdoit contenir une seule chaîne au format["<partition_key>;<start_value>;<end_value>"].
Les conditions de filtre sont soumises aux règles et restrictions suivantes :
- Valeurs inclusives : les conditions de filtre pour
GREATER_THAN,LESS_THANetRANGEincluent les valeurs fournies. Par exemple, un filtreLESS_THANavec une valeur de2023inclut les partitions jusqu'à2023inclus. - Suppression de partitions : si une partition de destination existante répond au filtre de partition et n'est plus présente dans la source, elle est supprimée du metastore de destination. Toutefois, les fichiers de données sous-jacents de cette partition ne sont pas supprimés du bucket Cloud Storage de destination.
- Restrictions concernant les tableaux individuels :
- Vous ne pouvez pas appliquer plusieurs filtres au même tableau.
- Vous ne pouvez pas combiner différents types de conditions (par exemple,
GREATER_THANetIN) dans le même tableau.
- Colonne de partition cible : les conditions de filtrage telles que
GREATER_THAN,LESS_THANetRANGEdoivent cibler la colonne de partition principale. - Limites de préfixes : la combinaison de filtres spécifiée ne doit pas générer plus de 1 000 préfixes par table. Par exemple, un filtre tel que
year>2020sur une table partitionnée paryear/month/daydoit générer moins de 1 000 préfixesyear=uniques.
Avant de commencer
Avant de planifier un transfert Hive Metastore, suivez les étapes décrites dans cette section.
Activer les API
Activez les API suivantes dans votre projetGoogle Cloud :
- API Data Transfer
- API Storage Transfer
- API BigLake
Un agent de service est créé lorsque vous activez l'API Data Transfer.
Configurer les autorisations
Pour configurer les autorisations pour un transfert Hive Metastore, suivez les étapes décrites dans les sections suivantes.
- L'utilisateur ou le compte de service qui crée le transfert doit disposer du rôle Administrateur BigQuery (
roles/bigquery.admin). Si vous utilisez un compte de service, il ne sert qu'à créer le transfert. Un agent de service (P4SA) est créé lorsque vous activez l'API Data Transfer.
Pour vous assurer que l'agent de service dispose des autorisations nécessaires pour exécuter un transfert Hive Metastore, demandez à votre administrateur d'accorder à l'agent de service les rôles IAM suivants sur le projet :
- Administrateur de transfert de stockage (
roles/storagetransfer.admin) - Consommateur Service Usage (
roles/serviceusage.serviceUsageConsumer) - Administrateur de l'espace de stockage (
roles/storage.admin) -
Pour migrer les métadonnées vers le catalogue d'exécution Lakehouse (catalogue REST Iceberg ou catalogue Hive) :
Administrateur BigLake (
roles/biglake.admin) -
Pour migrer des métadonnées vers Dataproc Metastore :
Propriétaire de données Dataproc Metastore (
roles/metastore.metadataOwner)
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Votre administrateur peut également attribuer à l'agent de service les autorisations requises via des rôles personnalisés ou d'autres rôles prédéfinis.
- Administrateur de transfert de stockage (
Si vous utilisez un compte de service, accordez à l'agent de service le rôle
roles/iam.serviceAccountTokenCreatorà l'aide de la commande suivante :gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Attribuez les rôles suivants à l'agent de service du service de transfert de stockage (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) dans le projet :roles/storage.admin- Si vous effectuez la migration depuis un système sur site/HDFS, vous devez également accorder le rôle
roles/storagetransfer.serviceAgent.
Vous pouvez également configurer des autorisations plus précises. Pour en savoir plus, consultez le guide suivant :
Générer un fichier de métadonnées pour Apache Hive
Exécutez l'outil dwh-migration-dumper pour extraire les métadonnées pour Apache Hive.
L'outil génère un fichier nommé hive-dumper-output.zip, qui peut être importé dans un bucket Cloud Storage. Dans ce document, ce bucket Cloud Storage est appelé DUMPER_BUCKET.
Vous pouvez également planifier des importations périodiques à l'aide d'un script. Pour en savoir plus, consultez Automatiser l'exécution de l'outil de vidage avec un job cron.
Configurer le service de transfert de stockage
Sélectionnez l'une des options suivantes :
HDFS
Un agent de transfert de stockage est requis pour les transferts sur site ou HDFS.
Pour configurer l'agent, procédez comme suit :
- Installez Docker sur les machines agents sur site.
- Créez un pool d'agents service de transfert de stockage Service dans votre projet Google Cloud .
- Installez des agents sur vos machines d'agents sur site.
Amazon S3
Les transferts depuis Amazon S3 sont des transferts sans agent.
Pour configurer le service de transfert de stockage pour un transfert Amazon S3, procédez comme suit :
- Configurez les identifiants d'accès pour AWS Amazon S3.
- Notez l'ID de clé d'accès et la clé d'accès secrète après avoir configuré vos identifiants d'accès.
- Ajoutez les plages d'adresses IP utilisées par les nœuds de calcul du service de transfert de stockage à votre liste d'adresses IP autorisées si votre projet AWS utilise des restrictions d'adresses IP.
Microsoft Azure
Les transferts depuis Microsoft Azure Storage sont des transferts sans agent.
Pour configurer le service de transfert de stockage pour un transfert Microsoft Azure Storage, procédez comme suit :
- Générez un jeton de signature d'accès partagé (SAP) pour votre compte de stockage Microsoft Azure.
- Notez le jeton SAP après l'avoir généré.
- Ajoutez les plages d'adresses IP utilisées par les nœuds de calcul du service de transfert de stockage à votre liste d'adresses IP autorisées si votre compte Microsoft Azure Storage utilise des restrictions d'adresses IP.
Planifier un transfert Hive Metastore
Sélectionnez l'une des options suivantes :
Console
Accédez à la page "Transferts de données" dans la console Google Cloud .
Cliquez sur Créer un transfert.
Dans la section Type de source, sélectionnez Hive Metastore dans la liste Source.
Pour Emplacement, sélectionnez un type d'emplacement, puis une région.
Dans la section Nom de la configuration de transfert, sous Nom à afficher, saisissez le nom du transfert de données.
Dans la section Options de programmation, procédez comme suit :
- Dans la liste Fréquence de répétition, sélectionnez une option pour spécifier la fréquence d'exécution de ce transfert de données. Pour spécifier une fréquence de répétition personnalisée, sélectionnez Personnalisée. Si vous sélectionnez À la demande, ce transfert s'exécute lorsque vous le déclenchez manuellement.
- Le cas échéant, sélectionnez Commencer ou Commencer à l'heure définie, puis indiquez une date de début et une heure d'exécution.
Dans la section Data source details (Détails de la source de données), procédez comme suit :
- Pour Stratégie de transfert, sélectionnez l'une des options suivantes :
FULL_TRANSFER: transfère toutes les données et enregistre les métadonnées dans le metastore cible. Il s'agit de l'option par défaut.METADATA_ONLY: enregistrez uniquement les métadonnées. Les données doivent déjà être présentes à l'emplacement Cloud Storage correct référencé dans les métadonnées.
- Dans Modèles de nom de table, spécifiez les tables du lac de données HDFS à transférer en fournissant les noms de table ou les modèles correspondant aux tables de la base de données HDFS. Vous devez utiliser la syntaxe d'expression régulière Java pour spécifier les modèles de table. Exemple :
db1..*correspond à toutes les tables de db1.db1.table1;db2.table2correspond à table1 dans db1 et à table2 dans db2.
- Pour Chemin d'accès GCS du fichier de vidage de découverte BQMS, saisissez le chemin d'accès au fichier
hive-dumper-output.zipque vous avez généré lorsque vous avez créé un fichier de métadonnées pour Apache Hive. Si vous utilisez l'automatisation de la sortie du dumper aveccron, indiquez le chemin d'accès au dossier Cloud Storage configuré dans--gcs-base-path, qui contient les fichiers ZIP de sortie du dumper.- Pour Type de stockage, sélectionnez l'une des options suivantes. Ce champ n'est disponible que si Stratégie de transfert est défini sur
FULL_TRANSFER: HDFS: sélectionnez cette option si votre stockage de fichiers estHDFS. Dans le champ Nom du pool d'agents STS, vous devez indiquer le nom du pool d'agents que vous avez créé lorsque vous avez configuré votre agent Storage Transfer.S3: sélectionnez cette option si votre stockage de fichiers estAmazon S3. Dans les champs ID de clé d'accès et Clé d'accès secrète, vous devez fournir l'ID de clé d'accès et la clé d'accès secrète que vous avez créés lorsque vous avez configuré vos identifiants d'accès.AZURE: sélectionnez cette option si votre stockage de fichiers estAzure Blob Storage. Dans le champ Jeton SAP, vous devez fournir le jeton SAP que vous avez créé lorsque vous avez configuré vos identifiants d'accès.
- Pour Type de stockage, sélectionnez l'une des options suivantes. Ce champ n'est disponible que si Stratégie de transfert est défini sur
- Facultatif : Pour Chemin d'accès GCS du filtre de partitionnement, saisissez un chemin d'accès Cloud Storage complet vers un fichier JSON de filtre personnalisé afin de filtrer les partitions des tables sources.
- Dans le champ Chemin GCS de destination, saisissez le chemin d'accès à un bucket Cloud Storage pour stocker vos données migrées.
- Sélectionnez le type de metastore de destination dans la liste déroulante :
DATAPROC_METASTORE: sélectionnez cette option pour stocker vos métadonnées dans Dataproc Metastore. Vous devez fournir l'URL de Dataproc Metastore dans URL Dataproc Metastore.BIGLAKE_REST_CATALOG: sélectionnez cette option pour stocker vos métadonnées dans le catalogue REST Iceberg du catalogue d'exécution Lakehouse. Le catalogue est créé en fonction du bucket Cloud Storage de destination.BIGLAKE_HIVE_CATALOG(preview) : sélectionnez cette option pour stocker vos métadonnées dans le catalogue Hive du catalogue Lakehouse Runtime. Vous devez fournir un nom de catalogue dans ID du catalogue Hive BigLake Metastore. Si le catalogue n'existe pas, il sera créé automatiquement.
- Facultatif : Pour Compte de service, saisissez un compte de service à utiliser avec ce transfert de données. Le compte de service doit appartenir au même projetGoogle Cloud que celui dans lequel la configuration du transfert et l'ensemble de données de destination sont créés.
- Pour Stratégie de transfert, sélectionnez l'une des options suivantes :
bq
Pour planifier un transfert Hive Metastore, saisissez la commande bq mk et indiquez l'indicateur de création de transfert --transfer_config :
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
Remplacez les éléments suivants :
TRANSFER_NAME: nom à afficher de la configuration de transfert. Ce nom peut correspondre à toute valeur permettant d'identifier le transfert si vous devez le modifier ultérieurement.SERVICE_ACCOUNT: nom du compte de service utilisé pour créer votre transfert.Le compte de service doit appartenir au même projetGoogle Cloud dans lequel la configuration du transfert et l'ensemble de données de destination sont créés.PROJECT_ID: ID de votre projet Google Cloud . Si vous ne fournissez pas de--project_idafin de spécifier un projet particulier, le projet par défaut est utilisé.REGION: emplacement de cette configuration de transfert.TRANSFER_STRATEGY: (facultatif) spécifiez l'une des valeurs suivantes :FULL_TRANSFER: transfère toutes les données et enregistre les métadonnées dans le metastore cible. Il s'agit de la valeur par défaut.METADATA_ONLY: enregistrez uniquement les métadonnées. Les données doivent déjà être présentes à l'emplacement Cloud Storage approprié référencé dans les métadonnées.
LIST_OF_TABLES: liste des entités à transférer. Utilisez une spécification de nommage hiérarchique :database.table. Ce champ accepte les expressions régulières RE2 pour spécifier les tables. Par exemple :db1..*: spécifie toutes les tables de la base de données.db1.table1;db2.table2: liste des tables
DUMPER_BUCKET: bucket Cloud Storage contenant le fichierhive-dumper-output.zip. Si vous utilisez l'automatisation de la sortie dumper aveccron, remplaceztable_metadata_pathpar le chemin d'accès au dossier Cloud Storage configuré avec--gcs-base-pathdans la configuration cron. Par exemple :"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>".MIGRATION_BUCKET: chemin d'accès GCS de destination vers lequel tous les fichiers sous-jacents seront chargés. Disponible uniquement sitransfer_strategyest défini surFULL_TRANSFER.METASTORE: type de metastore vers lequel migrer. Définissez ce paramètre sur l'une des valeurs suivantes :DATAPROC_METASTORE: pour transférer des métadonnées vers Dataproc Metastore.BIGLAKE_REST_CATALOG: pour transférer les métadonnées vers le catalogue d'environnements d'exécution Lakehouse, catalogue REST Iceberg (recommandé pour les tables Iceberg).BIGLAKE_HIVE_CATALOG: pour transférer les métadonnées vers le catalogue d'exécution Lakehouse, catalogue Hive (recommandé pour les tables Apache Hive) (aperçu).
DATAPROC_METASTORE_URL: URL de votre Dataproc Metastore. Obligatoire simetastoreestDATAPROC_METASTORE.HIVE_CATALOG_ID: ID du catalogue Hive du catalogue Lakehouse Runtime. Obligatoire si la valeur demetastoreestBIGLAKE_HIVE_CATALOG. Si le catalogue n'existe pas, il sera créé automatiquement.STORAGE_TYPE: spécifiez le stockage de fichiers sous-jacent pour vos tables. Les types acceptés sontHDFS,S3etAZURE. Obligatoire sitransfer_strategyestFULL_TRANSFER.AGENT_POOL_NAME: nom du pool d'agents utilisé pour créer des agents. Obligatoire si la valeur destorage_typeestHDFS.AWS_ACCESS_KEY_ID: ID de la clé d'accès à partir des identifiants d'accès. Obligatoire sistorage_typeest défini surS3.AWS_SECRET_ACCESS_KEY: clé d'accès secrète provenant des identifiants d'accès. Obligatoire sistorage_typeest défini surS3.AZURE_SAS_TOKEN: jeton SAP provenant des identifiants d'accès. Obligatoire sistorage_typeestAZURE.FILTER_GCS_PATH: (facultatif) chemin d'accès Cloud Storage complet à un fichier JSON de filtre personnalisé pour filtrer les partitions.
Exécutez cette commande pour créer la configuration du transfert et démarrer le transfert des tables gérées Hive. Les transferts sont programmés pour s'exécuter toutes les 24 heures par défaut, mais peuvent être configurés avec les options de planification des transferts.
Une fois le transfert terminé, vos tables du cluster Hadoop seront migrées vers MIGRATION_BUCKET.
Automatiser l'exécution de l'outil de vidage avec un job cron
Vous pouvez automatiser les transferts incrémentiels à l'aide d'une tâche cron pour exécuter l'outil dwh-migration-dumper. Automatiser l'extraction des métadonnées pour s'assurer qu'une décharge à jour de la source de données est disponible pour les exécutions de transfert incrémentiel ultérieures.
Avant de commencer
Avant d'utiliser ce script d'automatisation, vous devez effectuer les opérations suivantes :
Remplissez toutes les conditions préalables pour l'outil de vidage.
Installez la Google Cloud CLI. Le script utilise l'outil de ligne de commande
gsutilpour importer la sortie du dumper dans Cloud Storage.Pour vous authentifier auprès de Google Cloud afin d'autoriser
gsutilà importer des fichiers dans Cloud Storage, exécutez la commande suivante :gcloud auth application-default login
Planifier l'automatisation
Enregistrez le script suivant dans un fichier local. Ce script est conçu pour être configuré et exécuté par un daemon
cronafin d'automatiser le processus d'extraction et d'importation des résultats du dumper.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Pour rendre le script exécutable, exécutez la commande suivante :
chmod +x PATH_TO_SCRIPT
Planifiez le script à l'aide de
crontab, en remplaçant les variables par les valeurs appropriées pour votre tâche. Ajoutez une entrée pour planifier la tâche. Les exemples suivants exécutent le script tous les jours à 2h30 :Si vous exécutez sur un hôte qui a un accès direct au metastore Hive et qui ne nécessite pas d'authentification Kerberos, exécutez la commande suivante :
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Si votre instance Hive Metastore nécessite une authentification Kerberos, exécutez la commande suivante :
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
Points à prendre en compte pour la planification
Pour éviter que les données ne deviennent obsolètes, exécutez l'outil de vidage avant le transfert de données planifié.
Nous vous recommandons d'exécuter manuellement le script plusieurs fois pour déterminer le temps moyen nécessaire à l'outil de vidage pour générer son résultat. Utilisez cette planification pour définir un calendrier de tâches cron qui précède l'exécution de votre transfert afin de garantir la fraîcheur des données.
Surveiller et afficher l'état des transferts
Vous pouvez surveiller les transferts au niveau des ressources pour les tables individuelles afin de suivre la progression, d'afficher des informations détaillées sur les erreurs et d'interroger l'état des ressources spécifiques en cours de migration.
Pour afficher la progression et l'état de vos ressources, sélectionnez l'une des options suivantes :
Console
Dans la console Google Cloud , accédez à la page Transferts de données.
Cliquez sur votre configuration de transfert dans la liste.
Sur la page Détails du transfert, cliquez sur l'onglet Tables transférées.
Affichez la liste des ressources transférées. Vous pouvez consulter des informations telles que :
- État du dernier transfert : état actuel de la ressource en fonction du dernier transfert de ressources, y compris la progression de l'opération.
- Nom de la table : nom de la ressource transférée. Cliquez sur le nom de la ressource pour afficher une vue détaillée de celle-ci.
- Dernière exécution : dernière exécution du transfert ayant mis à jour la ressource.
- Résumé de l'état : métriques de progression précises ou messages d'erreur en cas d'échec du transfert.
- Dernière exécution réussie : dernière exécution qui a transféré la ressource avec succès.
Utilisez la barre de filtres pour rechercher des ressources spécifiques par nom ou filtrer par leur état actuel (par exemple, Transferts échoués). Le filtre Nom de la table est compatible avec les caractères génériques (par exemple, *), mais pas les autres champs de filtre.
API
Vous pouvez interroger l'état des ressources de transfert à l'aide de l'API du service de transfert de données BigQuery.
Lister toutes les ressources et leurs états
Pour lister toutes les ressources et leur état, utilisez la méthode projects.locations.transferConfigs.transferResources.list.
Exécutez la requête API avec les informations suivantes :
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
Commande curl :
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Vous pouvez filtrer les résultats par nom ou état de la ressource. Par exemple, pour trouver tous les transferts ayant échoué, ajoutez ?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED" à l'URL de la requête.
Remplacez les éléments suivants :
CONFIG_ID: ID de la configuration de transfert.LOCATION: emplacement où la configuration de transfert a été créée.PROJECT_ID: ID du projet Google Cloud qui exécute les transferts.
Obtenir une ressource spécifique
Pour obtenir l'état d'une table ou d'une partition spécifique, utilisez la méthode projects.locations.transferConfigs.transferResources.get.
Exécutez la requête API avec les informations suivantes :
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
Commande curl :
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Remplacez les éléments suivants :
CONFIG_ID: ID de la configuration de transfert.LOCATION: emplacement où la configuration de transfert a été créée.PROJECT_ID: ID du Google Cloud projet qui exécute les transferts.RESOURCE_ID: ID de la ressource, par exemple le nom de la table.
Quotas et limites de simultanéité
Pour chaque exécution du service de transfert de données BigQuery, le connecteur Hive Metastore exécute une tâche service de transfert de stockage par table.
Une fois le quota atteint, le transfert attend qu'un quota supplémentaire soit disponible. Les tâches du service de transfert de stockage sont créées dans le projet client et sont soumises aux quotas et limites du service de transfert de stockage.
Tarifs
L'utilisation du connecteur Apache Hive Metastore pour transférer vos données est sans frais. Une fois les données transférées, leur stockage dans votre destination vous est facturé. Pour en savoir plus, consultez les ressources suivantes :