
Apache Hive Metastore-Tabellen zuGoogle Cloudmigrieren
In diesem Dokument wird beschrieben, wie Sie Ihre von Apache Hive Metastore verwalteten Iceberg- und Hive-Tabellen mit dem BigQuery Data Transfer Service zuGoogle Cloud migrieren.
Mit dem Apache Hive Metastore-Migrationsconnector im BigQuery Data Transfer Service können Sie Ihre Hive Metastore-Tabellen nahtlos und in großem Umfang zu Google Cloud migrieren. Dieser Connector unterstützt sowohl Hive- als auch Iceberg-Tabellen aus lokalen Installationen und Cloud-Umgebungen, einschließlich Cloudera-Einrichtungen. Der Hive Metastore-Migrationsconnector unterstützt Dateien, die in den folgenden Datenquellen gespeichert sind:
- Apache Hadoop Distributed File System (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage oder Azure Data Lake Storage Gen2
Mit dem Hive Metastore-Migrationsconnector können Sie Cloud Storage als Dateispeicher verwenden und Ihre Hive Metastore-Tabellen in einem der folgenden Metastore registrieren:
Lakehouse-Laufzeitkatalog – Iceberg-REST-Katalog
Wir empfehlen, den Lakehouse-Laufzeitkatalog „Iceberg-REST-Katalog“ für alle Ihre Iceberg-Daten zu verwenden.
Der Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs sorgt für Interoperabilität zwischen Ihren Abfrage-Engines, da er eine einzige zuverlässige Informationsquelle für alle Ihre Iceberg-Daten bietet. Sie können die Daten mit BigQuery abfragen, zusätzlich zu Apache Spark und anderen OSS-Engines. Der Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs unterstützt nur Iceberg-Tabellenformate.
Lakehouse-Laufzeitkatalog – Hive-Katalog (Vorschau)
Wir empfehlen, den Hive-Katalog des Lakehouse-Laufzeitkatalogs für alle Ihre Hive-Tabellen zu verwenden.
Mit dem Hive-Katalog des Lakehouse-Laufzeitkatalogs können Sie Ihre migrierten Hive-Tabellen mit einem Hive-Katalog im Lakehouse-Laufzeitkatalog registrieren. Dies bietet einen serverlosen Metastore für Apache Hive-Tabellen. Sie können BigQuery verwenden, um die Daten abzufragen (abhängig von Formatbeschränkungen), zusätzlich zu Apache Spark und anderen OSS-Engines.
-
Dataproc Metastore unterstützt sowohl Hive- als auch Iceberg-Tabellenformate. Sie können nur Apache Spark und andere OSS-Engines verwenden, um Daten in Dataproc Metastore zu lesen und zu schreiben.
Dieser Connector unterstützt sowohl vollständige als auch reine Metadatenübertragungen. Bei vollständigen Übertragungen werden sowohl Ihre Daten als auch Ihre Metadaten aus den Quelltabellen in den Ziel-Metastore übertragen. Sie können eine reine Metadatenübertragung erstellen, wenn sich Ihre Daten bereits in Cloud Storage befinden und Sie sie nur in einem Ziel-Metastore registrieren möchten.
Das folgende Diagramm bietet einen Überblick über den Migrationsprozess.
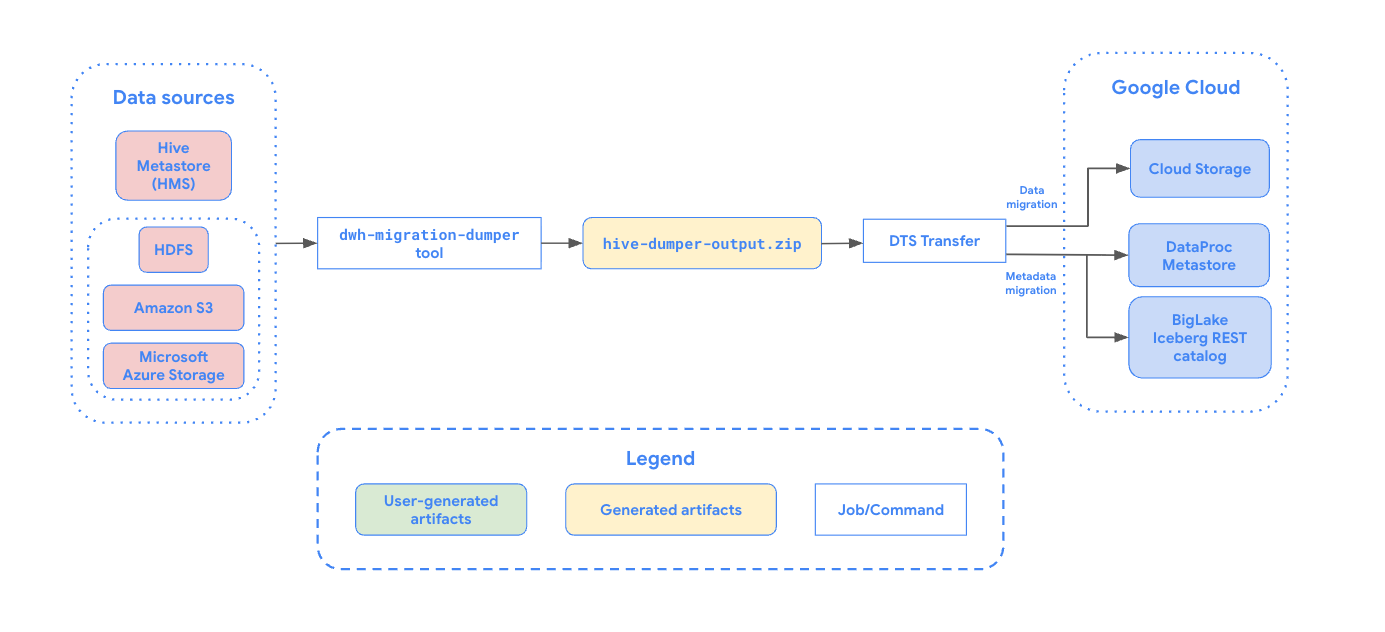
Beschränkungen
Übertragungen von Hive Metastore-Tabellen unterliegen den folgenden Einschränkungen:
- Zwischen zwei geplanten Ausführungen von Hive Metastore-Übertragungen müssen mindestens 30 Minuten liegen. On-demand-Ausführungen können weiterhin in beliebigen Intervallen ausgelöst werden.
- Dateinamen müssen den Anforderungen für die Benennung von Cloud Storage-Objekten entsprechen.
- Für einzelne Objekte in Cloud Storage gilt ein Limit von 5 TiB. Dateien in Ihren Hive-Metastore-Tabellen, die größer als 5 TiB sind, können nicht übertragen werden.
- Storage Transfer Service hat ein bestimmtes Verhalten, wenn Daten in der Quelle geändert werden, während eine Übertragung läuft. Wir raten davon ab, in Tabellen zu schreiben, während sie aktiv migriert werden. Eine Liste der anderen Einschränkungen des Storage Transfer Service finden Sie unter Bekannte Einschränkungen.
Einschränkungen des Hive-Katalogs im Lakehouse-Laufzeitkatalog
Wenn Sie den Hive-Katalog (BIGLAKE_HIVE_CATALOG) des Lakehouse-Laufzeitkatalogs als Ziel-Metastore verwenden, gelten die folgenden Einschränkungen und Hinweise:
- Die Hive-Katalog-ID des Lakehouse-Laufzeitkatalogs darf nur Kleinbuchstaben, Ziffern und Unterstriche (
_) enthalten. Sie darf keine Bindestriche (-) oder Großbuchstaben enthalten. - Sie können Hive-Kataloge des Lakehouse-Laufzeitkatalogs nicht in der Google Cloud Console ansehen oder verwalten. Die migrierten Tabellen sind jedoch im BigQuery-Ziel-Dataset sichtbar und können dort abgefragt werden.
- Es gelten alle Einschränkungen des Hive-Katalogs des Lakehouse-Laufzeitkatalogs für Open-Source-Metadatenformate und ‑Datentypen.
- Informationen zur Kompatibilität mit Formaten wie CSV und JSON finden Sie unter Unterstützte Speicherformate.
- Informationen zu nicht unterstützten Datentypen (z. B.
UNIONoder verschachtelte Arrays) und Spaltenstatistiken finden Sie unter Metastore-Einschränkungen und Partitionseinschränkungen.
Optionen für die Datenaufnahme
In den folgenden Abschnitten finden Sie weitere Informationen zur Konfiguration Ihrer Hive-Metastore-Übertragungen.
Inkrementelle Übertragungen
Wenn eine Übertragungskonfiguration mit einem wiederkehrenden Zeitplan eingerichtet wird, wird die Tabelle auf Google Cloud bei jeder nachfolgenden Übertragung mit den neuesten Änderungen an der Quelltabelle aktualisiert. Beispielsweise werden alle Datenaktualisierungen und alle Einfüge-, Lösch- oder Aktualisierungsvorgänge mit Schemaänderungen bei jeder Übertragung in Google Cloud berücksichtigt.
Partitionen filtern
Sie können eine Teilmenge von Partitionen aus Ihren Hive-Tabellen übertragen, indem Sie eine benutzerdefinierte Filter-JSON-Datei in Cloud Storage angeben. Geben Sie beim Planen der Übertragung den vollständigen Cloud Storage-Pfad zu dieser JSON-Datei mit dem Parameter partition_filter_gcs_path an.
Im Folgenden sehen Sie ein Beispiel für die Struktur der JSON-Datei für Filter:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
Filterbedingungen
Das Feld condition in der JSON-Datei unterstützt die folgenden Werte, jeweils mit einem bestimmten Format für das partitions-Array:
IN: Gibt die genauen Pfade der Partitionen an, die eingeschlossen werden sollen. Das Arraypartitionsenthält Strings, die die genaue Verzeichnisstruktur der Partitionen relativ zum Tabellenbasispfad darstellen (z. B.["partition_key1=value1/partition_key2=value2"]). Sie können mehrere Pfade im Array angeben.LESS_THAN: Enthält Partitionen, in denen der primäre Partitionsschlüsselwert kleiner oder gleich dem angegebenen Wert ist. Daspartitions-Array muss einen einzelnen String im Format["<partition_key>;<value>"]enthalten.GREATER_THAN: Enthält Partitionen, in denen der primäre Partitionsschlüsselwert größer oder gleich dem angegebenen Wert ist. Daspartitions-Array muss einen einzelnen String im Format["<partition_key>;<value>"]enthalten.RANGE: Enthält Partitionen, in denen der primäre Partitions-Schlüsselwert in den angegebenen Bereich fällt (einschließlich). Das Arraypartitionsmuss einen einzelnen String im Format["<partition_key>;<start_value>;<end_value>"]enthalten.
Für die Filterbedingungen gelten die folgenden Regeln und Einschränkungen:
- Inklusive Werte:Filterbedingungen für
GREATER_THAN,LESS_THANundRANGEschließen die angegebenen Werte ein. EinLESS_THAN-Filter mit dem Wert2023enthält beispielsweise Partitionen bis einschließlich2023. - Löschen von Partitionen:Wenn eine vorhandene Zielpartition dem Partitionsfilter entspricht und in der Quelle nicht mehr vorhanden ist, wird sie aus dem Zielmetastore entfernt. Die zugrunde liegenden Datendateien für diese Partition werden jedoch nicht aus dem Cloud Storage-Ziel-Bucket gelöscht.
- Einschränkungen für einzelne Tabellen:
- Mehrere Filter für dieselbe Tabelle sind nicht zulässig.
- Sie können nicht verschiedene Bedingungstypen (z. B.
GREATER_THANundIN) in derselben Tabelle kombinieren.
- Zielpartitionsspalte:Filterbedingungen wie
GREATER_THAN,LESS_THANundRANGEmüssen auf die primäre Partitionsspalte ausgerichtet sein. - Beschränkungen für Präfixe:Die angegebene Filterkombination darf nicht zu mehr als 1.000 Präfixen pro Tabelle führen. Ein Filter wie
year>2020für eine Tabelle, die nachyear/month/daypartitioniert ist, darf beispielsweise weniger als 1.000 eindeutigeyear=-Präfixe enthalten.
Hinweis
Bevor Sie die Übertragung des Hive-Metastores planen, führen Sie die Schritte in diesem Abschnitt aus.
APIs aktivieren
Aktivieren Sie die folgenden APIs in IhremGoogle Cloud -Projekt:
- Data Transfer API
- Storage Transfer API
- BigLake API
Ein Dienst-Agent wird erstellt, wenn Sie die Data Transfer API aktivieren.
Berechtigungen konfigurieren
So konfigurieren Sie Berechtigungen für eine Hive-Metastore-Übertragung:
- Dem Nutzer oder Dienstkonto, das die Übertragung erstellt, muss die Rolle „BigQuery-Administrator“ (
roles/bigquery.admin) zugewiesen werden. Wenn Sie ein Dienstkonto verwenden, wird es nur zum Erstellen der Übertragung verwendet. Beim Aktivieren der Data Transfer API wird ein Dienst-Agent (P4SA) erstellt.
Bitten Sie Ihren Administrator, dem Dienst-Agent die folgenden IAM-Rollen für das Projekt zuzuweisen, damit der Dienst-Agent die erforderlichen Berechtigungen zum Ausführen einer Hive-Metastore-Übertragung hat:
- Storage Transfer-Administrator (
roles/storagetransfer.admin) - Service Usage Consumer (
roles/serviceusage.serviceUsageConsumer) - Storage-Administrator (
roles/storage.admin) -
So migrieren Sie Metadaten in den Lakehouse-Laufzeitkatalog (Iceberg-REST-Katalog oder Hive-Katalog):
BigLake-Administrator (
roles/biglake.admin) -
So migrieren Sie Metadaten zu Dataproc Metastore:
Dataproc Metastore-Dateninhaber (
roles/metastore.metadataOwner)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Ihr Administrator kann dem Dienst-Agent möglicherweise auch die erforderlichen Berechtigungen über benutzerdefinierte Rollen oder andere vordefinierte Rollen erteilen.
- Storage Transfer-Administrator (
Wenn Sie ein Dienstkonto verwenden, weisen Sie dem Dienst-Agent mit dem folgenden Befehl die Rolle
roles/iam.serviceAccountTokenCreatorzu:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Weisen Sie dem Storage Transfer Service-Dienst-Agent (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com) die folgenden Rollen im Projekt zu:roles/storage.admin- Wenn Sie von On-Premise/HDFS migrieren, müssen Sie auch die Rolle
roles/storagetransfer.serviceAgentzuweisen.
Sie können auch detailliertere Berechtigungen konfigurieren. Weitere Informationen finden Sie in diesem Leitfaden:
Metadatendatei für Apache Hive generieren
Führen Sie das dwh-migration-dumper-Tool aus, um Metadaten für Apache Hive zu extrahieren.
Das Tool generiert eine Datei mit dem Namen hive-dumper-output.zip, die in einen Cloud Storage-Bucket hochgeladen werden kann. Dieser Cloud Storage-Bucket wird in diesem Dokument als DUMPER_BUCKET bezeichnet.
Sie können auch regelmäßige Uploads mit einem Skript planen. Weitere Informationen finden Sie unter Ausführung des Dumper-Tools mit einem cron-Job automatisieren.
Storage Transfer Service konfigurieren
Wählen Sie eine der folgenden Optionen aus:
HDFS
Für lokale oder HDFS-Übertragungen ist ein Storage Transfer-Agent erforderlich.
So richten Sie den Agent ein:
- Installieren Sie Docker auf lokalen Agent-Rechnern.
- Erstellen Sie einen Storage Transfer Service-Agent-Pool in Ihrem Google Cloud Projekt.
- Installieren Sie Agents auf Ihren lokalen Agent-Computern.
Amazon S3
Übertragungen von Amazon S3 sind agentenlose Übertragungen.
So konfigurieren Sie den Storage Transfer Service für eine Amazon S3-Übertragung:
- Zugriffsanmeldedaten für AWS Amazon S3 einrichten
- Notieren Sie sich die Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel, nachdem Sie Ihre Zugriffsanmeldedaten eingerichtet haben.
- Fügen Sie die von Storage Transfer Service-Workern verwendeten IP-Bereiche der Liste der zulässigen IP-Adressen hinzu, wenn in Ihrem AWS-Projekt IP-Beschränkungen verwendet werden.
Microsoft Azure
Übertragungen von Microsoft Azure Storage sind agentenlose Übertragungen.
So konfigurieren Sie den Storage Transfer Service für eine Microsoft Azure Storage-Übertragung:
- Generieren Sie ein SAS-Token (Shared Access Signature) für Ihr Microsoft Azure-Speicherkonto.
- Notieren Sie sich das SAS-Token, nachdem Sie es generiert haben.
- Fügen Sie der Liste der zulässigen IP-Adressen die IP-Bereiche hinzu, die von Storage Transfer Service-Workern verwendet werden, wenn für Ihr Microsoft Azure-Speicherkonto IP-Beschränkungen gelten.
Hive-Metastore-Übertragung planen
Wählen Sie eine der folgenden Optionen aus:
Console
Rufen Sie in der Google Cloud -Console die Seite „Datenübertragungen“ auf.
Klicken Sie auf Übertragung erstellen.
Wählen Sie im Abschnitt Quelltyp die Option Hive Metastore aus der Liste Quelle aus.
Wählen Sie unter Standort einen Standorttyp und dann eine Region aus.
Geben Sie im Abschnitt Konfigurationsname für Übertragung als Anzeigename einen Namen für die Datenübertragung ein.
Führen Sie im Abschnitt Zeitplanoptionen folgende Schritte aus:
- Wählen Sie in der Liste Wiederholungshäufigkeit aus, wie oft diese Datenübertragung ausgeführt werden soll. Wenn Sie eine benutzerdefinierte Wiederholungshäufigkeit angeben möchten, wählen Sie Benutzerdefiniert aus. Wenn Sie On-Demand auswählen, wird diese Übertragung ausgeführt, wenn Sie die Übertragung manuell auslösen.
- Wählen Sie gegebenenfalls Jetzt starten oder Zu festgelegter Zeit starten aus und geben Sie ein Startdatum und eine Laufzeit an.
Führen Sie im Abschnitt Details zur Datenquelle folgende Schritte aus:
- Wählen Sie unter Übertragungsstrategie eine der folgenden Optionen aus:
FULL_TRANSFER: Alle Daten übertragen und Metadaten im Ziel-Metastore registrieren. Dies ist die Standardoption.METADATA_ONLY: Nur Metadaten registrieren. Die Daten müssen bereits am richtigen Cloud Storage-Speicherort vorhanden sein, auf den in den Metadaten verwiesen wird.
- Geben Sie bei Table name patterns (Tabellennamensmuster) HDFS-Data-Lake-Tabellen an, die übertragen werden sollen. Geben Sie dazu Tabellennamen oder Muster an, die mit Tabellen in der HDFS-Datenbank übereinstimmen. Sie müssen die Java-Syntax für reguläre Ausdrücke verwenden, um Tabellenmuster anzugeben. Beispiel:
db1..*führt zu Übereinstimmung mit allen Tabellen in db1.db1.table1;db2.table2entspricht table1 in db1 und table2 in db2.
- Geben Sie für BQMS discovery dump gcs path (GCS-Pfad für BQMS-Erkennungsdump) den Pfad zur
hive-dumper-output.zip-Datei ein, die Sie beim Erstellen einer Metadatendatei für Apache Hive generiert haben. Wenn Sie die Automatisierung der Dumper-Ausgabe mitcronverwenden, geben Sie den in--gcs-base-pathkonfigurierten Cloud Storage-Ordnerpfad an, der ZIP-Dateien mit der Dumper-Ausgabe enthält.- Wählen Sie für Speichertyp eine der folgenden Optionen aus. Dieses Feld ist nur verfügbar, wenn Übertragungsstrategie auf
FULL_TRANSFERfestgelegt ist: HDFS: Wählen Sie diese Option aus, wenn Ihr DateispeicherHDFSist. Geben Sie im Feld Name des STS-Agent-Pools den Namen des Agent-Pools an, den Sie beim Konfigurieren des Storage Transfer Agent erstellt haben.S3: Wählen Sie diese Option aus, wenn Ihr DateispeicherAmazon S3ist. Geben Sie in den Feldern Zugriffsschlüssel-ID und Geheimer Zugriffsschlüssel die Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel ein, die Sie beim Einrichten Ihrer Anmeldedaten erstellt haben.AZURE: Wählen Sie diese Option aus, wenn Ihr DateispeicherAzure Blob Storageist. Geben Sie im Feld SAS-Token das SAS-Token an, das Sie beim Einrichten Ihrer Anmeldedaten erstellt haben.
- Wählen Sie für Speichertyp eine der folgenden Optionen aus. Dieses Feld ist nur verfügbar, wenn Übertragungsstrategie auf
- Optional: Geben Sie für GCS-Pfad für Partitionsfilter einen vollständigen Cloud Storage-Pfad zu einer benutzerdefinierten Filter-JSON-Datei ein, um Partitionen aus Quelltabellen zu filtern.
- Geben Sie unter Ziel-GCS-Pfad einen Pfad zu einem Cloud Storage-Bucket ein, in dem die migrierten Daten gespeichert werden sollen.
- Wählen Sie den Metastore-Typ für das Ziel aus der Drop-down-Liste aus:
DATAPROC_METASTORE: Wählen Sie diese Option aus, um Ihre Metadaten in Dataproc Metastore zu speichern. Sie müssen die URL für Dataproc Metastore in Dataproc Metastore-URL angeben.BIGLAKE_REST_CATALOG: Wählen Sie diese Option aus, um Ihre Metadaten im Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs zu speichern. Der Katalog wird basierend auf dem Cloud Storage-Ziel-Bucket erstellt.BIGLAKE_HIVE_CATALOG(Vorabversion): Wählen Sie diese Option aus, um Ihre Metadaten im Hive-Katalog des Lakehouse-Laufzeitkatalogs zu speichern. Sie müssen einen Katalognamen in BigLake Metastore Hive Catalog ID (BigLake Metastore-Hive-Katalog-ID) angeben. Wenn der Katalog nicht vorhanden ist, wird er automatisch erstellt.
- Optional: Geben Sie unter Dienstkonto ein Dienstkonto ein, das für diese Datenübertragung verwendet werden soll. Das Dienstkonto sollte zum selbenGoogle Cloud -Projekt gehören, in dem die Übertragungskonfiguration und das Ziel-Dataset erstellt werden.
- Wählen Sie unter Übertragungsstrategie eine der folgenden Optionen aus:
bq
Geben Sie den Befehl bq mk mit dem Flag --transfer_config für die Übertragungserstellung ein, um die Hive Metastore-Übertragung zu planen:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
Ersetzen Sie Folgendes:
TRANSFER_NAME: Der Anzeigename für die Übertragungskonfiguration. Der Übertragungsname kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.SERVICE_ACCOUNT: Der Name des Dienstkontos, das zum Erstellen der Übertragung verwendet wird.Das Dienstkonto sollte zum selbenGoogle Cloud -Projekt gehören, in dem die Übertragungskonfiguration und das Zieldataset erstellt werden.PROJECT_ID: Projekt-ID in Google Cloud . Wenn--project_idnicht bereitgestellt wird, um ein bestimmtes Projekt anzugeben, wird das Standardprojekt verwendet.REGION: Speicherort dieser Übertragungskonfiguration.TRANSFER_STRATEGY(optional): Geben Sie einen der folgenden Werte an:FULL_TRANSFER: Alle Daten übertragen und Metadaten im Ziel-Metastore registrieren. Dies ist der Standardwert.METADATA_ONLY: Nur Metadaten registrieren. Die Daten müssen bereits am richtigen Cloud Storage-Speicherort vorhanden sein, auf den in den Metadaten verwiesen wird.
LIST_OF_TABLES: Eine Liste der zu übertragenden Entitäten. Verwenden Sie eine hierarchische Namensspezifikation:database.table. In diesem Feld können Sie Tabellen mit RE2-regulären Ausdrücken angeben. Beispiel:db1..*: gibt alle Tabellen in der Datenbank an.db1.table1;db2.table2: eine Liste von Tabellen
DUMPER_BUCKET: der Cloud Storage-Bucket, der die Dateihive-dumper-output.zipenthält. Wenn Sie die Automatisierung der Dumper-Ausgabe mitcronverwenden, ändern Sietable_metadata_pathin den Cloud Storage-Ordnerpfad, der mit--gcs-base-pathin der Cron-Einrichtung konfiguriert wurde, z. B.:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>".MIGRATION_BUCKET: Der GCS-Zielpfad, in den alle zugrunde liegenden Dateien geladen werden. Nur verfügbar, wenntransfer_strategyFULL_TRANSFERist.METASTORE: Der Typ des Metastore, zu dem migriert werden soll. Legen Sie dafür einen der folgenden Werte fest:DATAPROC_METASTORE: Zum Übertragen von Metadaten in Dataproc Metastore.BIGLAKE_REST_CATALOG: Zum Übertragen von Metadaten in den Lakehouse-Laufzeitkatalog (Iceberg-REST-Katalog) (für Iceberg-Tabellen empfohlen).BIGLAKE_HIVE_CATALOG: Metadaten in den Lakehouse-Laufzeitkatalog übertragen Hive-Katalog (empfohlen für Apache Hive-Tabellen) (Vorabversion).
DATAPROC_METASTORE_URL: Die URL Ihres Dataproc Metastore. Erforderlich, wennmetastoreDATAPROC_METASTOREist.HIVE_CATALOG_ID: Die ID des Hive-Katalogs des Lakehouse-Laufzeitkatalogs. Erforderlich, wennmetastoreBIGLAKE_HIVE_CATALOGist. Wenn der Katalog nicht vorhanden ist, wird er automatisch erstellt.STORAGE_TYPE: Geben Sie den zugrunde liegenden Dateispeicher für Ihre Tabellen an. Unterstützte Typen sindHDFS,S3undAZURE. Erforderlich, wenntransfer_strategyFULL_TRANSFERist.AGENT_POOL_NAME: Der Name des Agent-Pools, der zum Erstellen von Agents verwendet wird. Erforderlich, wennstorage_typeHDFSist.AWS_ACCESS_KEY_ID: Die Zugriffsschlüssel-ID aus den Zugriffsanmeldedaten. Erforderlich, wennstorage_typeS3ist.AWS_SECRET_ACCESS_KEY: Der geheime Zugriffsschlüssel aus den Zugangsdaten. Erforderlich, wennstorage_typeS3ist.AZURE_SAS_TOKEN: Das SAS-Token aus Zugriffsanmeldedaten. Erforderlich, wennstorage_typeAZUREist.FILTER_GCS_PATH: (Optional) Ein vollständiger Cloud Storage-Pfad zu einer benutzerdefinierten Filter-JSON-Datei zum Filtern von Partitionen.
Führen Sie diesen Befehl aus, um die Übertragungskonfiguration zu erstellen und die Übertragung der verwalteten Hive-Tabellen zu starten. Übertragungen werden standardmäßig alle 24 Stunden ausgeführt. Sie können sie aber mit Optionen für die Übertragungsplanung konfigurieren.
Nach Abschluss der Übertragung werden Ihre Tabellen im Hadoop-Cluster zu MIGRATION_BUCKET migriert.
Ausführung des Dumper-Tools mit einem cron-Job automatisieren
Sie können inkrementelle Übertragungen automatisieren, indem Sie einen cron-Job zum Ausführen des dwh-migration-dumper-Tools verwenden. Automatisieren Sie die Metadatenextraktion, damit für nachfolgende inkrementelle Übertragungen immer ein aktueller Dump aus der Datenquelle verfügbar ist.
Hinweis
Bevor Sie dieses Automatisierungsskript verwenden, müssen Sie Folgendes tun:
Erfüllen Sie alle Voraussetzungen für das Dumper-Tool.
Installieren Sie die Google Cloud CLI. Das Skript verwendet das
gsutil-Befehlszeilentool, um die Dumper-Ausgabe in Cloud Storage hochzuladen.Führen Sie den folgenden Befehl aus, um sich bei Google Cloud zu authentifizieren und
gsutildas Hochladen von Dateien in Cloud Storage zu ermöglichen:gcloud auth application-default login
Automatisierung planen
Speichern Sie das folgende Skript in einer lokalen Datei. Dieses Skript ist so konzipiert, dass es von einem
cron-Daemon konfiguriert und ausgeführt wird, um das Extrahieren und Hochladen der Dumper-Ausgabe zu automatisieren.#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Führen Sie den folgenden Befehl aus, um das Script ausführbar zu machen:
chmod +x PATH_TO_SCRIPT
Planen Sie das Skript mit
crontab. Ersetzen Sie die Variablen durch die entsprechenden Werte für Ihren Job. Fügen Sie einen Eintrag hinzu, um den Job zu planen. In den folgenden Beispielen wird das Script jeden Tag um 2:30 Uhr ausgeführt:Wenn Sie auf einem Host ausgeführt werden, der direkten Zugriff auf den Hive-Metastore hat und keine Kerberos-Authentifizierung erfordert, führen Sie den folgenden Befehl aus:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Wenn für Ihre Hive-Metastore-Instanz eine Kerberos-Authentifizierung erforderlich ist, führen Sie den folgenden Befehl aus:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
Überlegungen zur Planung
Um veraltete Daten zu vermeiden, sollten Sie das Dumper-Tool vor der geplanten Datenübertragung ausführen.
Wir empfehlen, das Skript einige Male manuell auszuführen, um die durchschnittliche Zeit zu ermitteln, die das Dumper-Tool zum Generieren der Ausgabe benötigt. Anhand dieser Zeit können Sie einen cron-Jobzeitplan festlegen, der vor dem Übertragungslauf ausgeführt wird, um die Datenaktualität zu gewährleisten.
Übertragungsstatus überwachen und ansehen
Sie können Übertragungen auf Ressourcenebene für einzelne Tabellen überwachen, um den Fortschritt zu verfolgen, detaillierte Fehlerinformationen aufzurufen und den Status bestimmter Ressourcen abzufragen, die migriert werden.
Wählen Sie eine der folgenden Optionen aus, um den Fortschritt und Status Ihrer Ressourcen aufzurufen:
Console
Rufen Sie in der Google Cloud Console die Seite Datenübertragungen auf.
Klicken Sie in der Liste auf Ihre Transferkonfiguration.
Klicken Sie auf der Seite Übertragungsdetails auf den Tab Übertragene Tabellen.
Sehen Sie sich die Liste der Ressourcen an, die übertragen werden. Sie können Details wie die folgenden sehen:
- Status der letzten Übertragung: Der aktuelle Status der Ressource basierend auf der letzten Ressourcenübertragung, einschließlich des Fortschritts.
- Tabellenname: Der Name der Ressource, die übertragen wird. Klicken Sie auf den Ressourcennamen, um eine detaillierte Ansicht der Ressource aufzurufen.
- Letzte Ausführung: Die letzte Übertragungsausführung, bei der die Ressource aktualisiert wurde.
- Statusübersicht: detaillierte Fortschrittsmesswerte oder Fehlermeldungen, wenn die Übertragung fehlgeschlagen ist.
- Letzte erfolgreiche Ausführung: Die letzte Ausführung, bei der die Ressource erfolgreich übertragen wurde.
Verwenden Sie die Filterleiste, um nach bestimmten Ressourcen anhand des Namens zu suchen oder nach dem aktuellen Status zu filtern, z. B. Fehlgeschlagene Übertragungen. Der Filter Tabellenname unterstützt den Abgleich von Platzhaltern, z. B. mit *. Für andere Filterfelder wird der Abgleich von Platzhaltern jedoch nicht unterstützt.
API
Mit der BigQuery Data Transfer Service API können Sie den Status von Übertragungsressourcen abfragen.
Alle Ressourcen und deren Status auflisten
Verwenden Sie die Methode projects.locations.transferConfigs.transferResources.list, um alle Ressourcen und deren Status aufzulisten.
Führen Sie die API-Anfrage mit den folgenden Informationen aus:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
curl-Befehl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Sie können die Ergebnisse nach Ressourcenname oder Status filtern. Wenn Sie beispielsweise alle fehlgeschlagenen Übertragungen finden möchten, fügen Sie der Anfrage-URL ?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED" hinzu.
Ersetzen Sie Folgendes:
CONFIG_ID: Die ID der Übertragungskonfiguration.LOCATION: Der Ort, an dem die Übertragungskonfiguration erstellt wurde.PROJECT_ID: die ID des Google Cloud Projekts, in dem die Übertragungen ausgeführt werden.
Bestimmte Ressource abrufen
Verwenden Sie die Methode projects.locations.transferConfigs.transferResources.get, um den Status einer bestimmten Tabelle oder Partition abzurufen.
Führen Sie die API-Anfrage mit den folgenden Informationen aus:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
curl-Befehl:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
Ersetzen Sie Folgendes:
CONFIG_ID: Die ID der Übertragungskonfiguration.LOCATION: Der Ort, an dem die Übertragungskonfiguration erstellt wurde.PROJECT_ID: die ID des Google Cloud Projekts, in dem die Übertragungen ausgeführt werden.RESOURCE_ID: Die ID der Ressource, z. B. der Tabellenname.
Kontingente und Limits für die gleichzeitige Nutzung
Bei jedem BigQuery Data Transfer Service-Lauf wird mit dem Hive Metastore-Connector ein Storage Transfer Service-Job pro Tabelle ausgeführt.
Sobald das Kontingent erreicht ist, wird die Übertragung angehalten, bis wieder mehr Kontingent verfügbar ist. Storage Transfer Service-Jobs werden im Kundenprojekt erstellt und unterliegen den Kontingenten und Limits für Storage Transfer Service.
Preise
Für die Verwendung des Apache Hive Metastore-Connectors zum Übertragen Ihrer Daten fallen keine Kosten an. Nachdem die Daten übertragen wurden, wird das Speichern der Daten am Zielort in Rechnung gestellt. Hier finden Sie weitere Informationen: