
本教學課程說明如何將 Transformer 模型匯出為開放式神經網路交換 (ONNX) 格式、將 ONNX 模型匯入 BigQuery 資料集,然後使用該模型透過 SQL 查詢產生嵌入。
本教學課程使用 sentence-transformers/all-MiniLM-L6-v2 模型。這個句子轉換器模型以快速且有效率地生成句子嵌入而聞名。句子嵌入可擷取文字的深層含義,因此能執行語意搜尋、叢集和句子相似度等工作。
ONNX 提供統一格式,可用於表示任何機器學習 (ML) 架構。BigQuery ML 支援 ONNX,因此您可以執行下列操作:
- 使用您喜愛的架構訓練模型。
- 將模型轉換為 ONNX 模型格式。
- 將 ONNX 模型匯入 BigQuery,並使用 BigQuery ML 進行預測。
目標
- 使用 Hugging Face Optimum CLI 將
sentence-transformers/all-MiniLM-L6-v2模型匯出至 ONNX。 - 使用
CREATE MODEL陳述式將 ONNX 模型匯入 BigQuery。 - 使用
ML.PREDICT函式,透過匯入的 ONNX 模型生成嵌入。
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
如要根據預測用量估算費用,請使用 Pricing Calculator。
完成本文所述工作後,您可以刪除建立的資源,避免繼續計費,詳情請參閱「清除所用資源」。
事前準備
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
啟用 BigQuery 和 Cloud Storage API。
啟用 API 時所需的角色
您必須具備
serviceusage.services.enable權限,才能啟用 API。如果您建立了專案,可能已透過「擁有者」角色 (roles/owner) 取得這項權限。否則,您可以透過「服務使用情形管理員」角色 (roles/serviceusage.serviceUsageAdmin) 取得這項權限。瞭解如何授予角色。- 請確認您具備必要權限,可執行本文件中的工作。
必要的角色
如果您建立新專案,您就是專案擁有者,並已獲得完成本教學課程所需的所有 Identity and Access Management (IAM) 權限。
如果您使用現有專案,請執行下列操作。
請確認您在專案中具備下列角色:
- BigQuery Studio 管理員 (
roles/bigquery.studioAdmin) - Storage 物件建立者 (
roles/storage.objectCreator)
檢查角色
-
前往 Google Cloud 控制台的「IAM」頁面。
前往「IAM」頁面 - 選取專案。
-
在「主體」欄中,找出所有識別您或您所屬群組的資料列。如要瞭解自己所屬的群組,請與管理員聯絡。
- 針對指定或包含您的所有列,請檢查「角色」欄,確認角色清單是否包含必要角色。
授予角色
-
前往 Google Cloud 控制台的「IAM」頁面。
前往「IAM」頁面 - 選取專案。
- 按一下「Grant access」(授予存取權)。
-
在「New principals」(新增主體) 欄位中,輸入您的使用者 ID。 這通常是指 Google 帳戶的電子郵件地址。
- 按一下「Select a role」(選取角色),然後搜尋角色。
- 如要授予其他角色,請按一下「Add another role」(新增其他角色),然後新增其他角色。
- 按一下「Save」(儲存)。
如要進一步瞭解 BigQuery 中的 IAM 權限,請參閱 IAM 權限。
將 Transformer 模型檔案轉換為 ONNX
您也可以選擇按照本節的步驟,手動將 sentence-transformers/all-MiniLM-L6-v2 模型和權杖化工具轉換為 ONNX。否則,您可以使用公開 gs://cloud-samples-dataCloud Storage bucket 中已轉換的範例檔案。
如果選擇手動轉換檔案,您必須具備已安裝 Python 的本機指令列環境。如要進一步瞭解如何安裝 Python,請參閱 Python 下載頁面。
將 Transformer 模型匯出為 ONNX
使用 Hugging Face Optimum CLI 將 sentence-transformers/all-MiniLM-L6-v2 模型匯出至 ONNX。如要進一步瞭解如何使用 Optimum CLI 匯出模型,請參閱「使用 optimum.exporters.onnx 將模型匯出為 ONNX 格式」。
如要匯出模型,請開啟指令列環境並按照下列步驟操作:
安裝 Optimum CLI:
pip install optimum[onnx]匯出模型。
--model引數會指定 Hugging Face 模型 ID。--opset引數會指定 ONNXRuntime 程式庫版本,並設為17,以維持與 BigQuery 支援的 ONNXRuntime 程式庫相容。optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
模型檔案會匯出至 all-MiniLM-L6-v2 目錄,並命名為 model.onnx。
對 Transformer 模型套用量化
使用 Optimum CLI 將量化套用至匯出的 Transformer 模型,以縮減模型大小並加快推論速度。詳情請參閱「量化」一節。
如要對模型套用量化,請在指令列執行下列指令:
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
量化模型檔案會匯出至 all-MiniLM-L6-v2_quantized 目錄,並命名為 model_quantized.onnx。
將權杖化工具轉換為 ONNX
如要使用 ONNX 格式的 Transformer 模型生成嵌入,通常會使用權杖化工具產生模型的兩個輸入內容:input_ids 和 attention_mask。
如要產生這些輸入內容,請使用 onnxruntime-extensions 程式庫,將 sentence-transformers/all-MiniLM-L6-v2 模型的分詞器轉換為 ONNX 格式。轉換權杖化工具後,您就能直接對原始文字輸入內容執行權杖化,以產生 ONNX 預測結果。
如要轉換權杖化工具,請在指令列上按照下列步驟操作:
安裝 Optimum CLI:
pip install optimum[onnx]使用您選擇的文字編輯器,建立名為
convert-tokenizer.py的檔案。以下範例使用 nano 文字編輯器:nano convert-tokenizer.py複製下列 Python 指令碼,並貼到
convert-tokenizer.py檔案中:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())儲存
convert-tokenizer.py檔案。執行 Python 指令碼來轉換權杖化工具:
python convert-tokenizer.py
轉換後的權杖化工具會匯出至 all-MiniLM-L6-v2_quantized 目錄,並命名為 tokenizer.onnx。
將轉換後的模型檔案上傳至 Cloud Storage
轉換 Transformer 模型和權杖化工具後,請執行下列操作:
建立資料集
建立 BigQuery 資料集來儲存機器學習模型。控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
在「Explorer」窗格中,按一下專案名稱。
依序點按 「View actions」(查看動作) >「Create dataset」(建立資料集)。
在「建立資料集」頁面中,執行下列操作:
在「Dataset ID」(資料集 ID) 中輸入
bqml_tutorial。針對「Location type」(位置類型) 選取「Multi-region」(多區域),然後選取「US」(美國)。
其餘設定請保留預設狀態,然後按一下「建立資料集」。
bq
如要建立新的資料集,請使用 bq mk --dataset 指令。
建立名為
bqml_tutorial的資料集,並將資料位置設為US。bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
確認資料集已建立完成:
bq ls
API
請呼叫 datasets.insert 方法,搭配已定義的資料集資源。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程,完成 BigQuery DataFrames 設定。詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
將 ONNX 模型匯入 BigQuery
將轉換後的權杖化工具和句子轉換器模型匯入為 BigQuery ML 模型。
選取下列選項之一:
控制台
在 Google Cloud 控制台開啟 BigQuery Studio。
在查詢編輯器中,執行下列
CREATE MODEL陳述式,建立tokenizer模型。CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
請將
TOKENIZER_BUCKET_PATH改成您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TOKENIZER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx。作業完成後,「查詢結果」窗格中會顯示類似以下的訊息:
Successfully created model named tokenizer。點選「前往模型」,開啟「詳細資料」窗格。
查看「特徵欄」部分,瞭解模型輸入內容,並查看「標籤欄」部分,瞭解模型輸出內容。
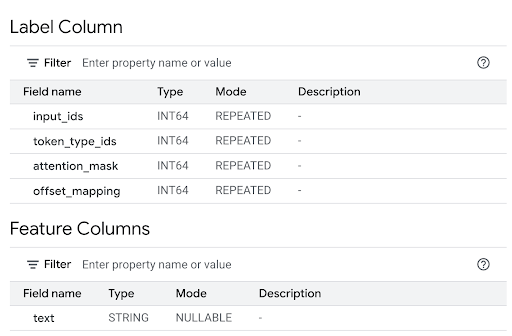
在查詢編輯器中,執行下列
CREATE MODEL陳述式,建立all-MiniLM-L6-v2模型。CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
請將
TRANSFORMER_BUCKET_PATH改成您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TRANSFORMER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx。作業完成後,「查詢結果」窗格中會顯示類似以下的訊息:
Successfully created model named all-MiniLM-L6-v2。點選「前往模型」,開啟「詳細資料」窗格。
查看「特徵欄」部分,瞭解模型輸入內容,並查看「標籤欄」部分,瞭解模型輸出內容。
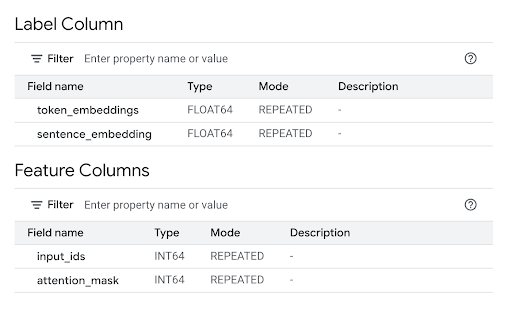
bq
使用 bq 指令列工具的 query 指令執行 CREATE MODEL 陳述式。
在指令列中,執行下列指令來建立
tokenizer模型。bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"請將
TOKENIZER_BUCKET_PATH改成您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TOKENIZER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx。作業完成後,您會看到類似以下的訊息:
Successfully created model named tokenizer。在指令列中,執行下列指令來建立
all-MiniLM-L6-v2模型。bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"請將
TRANSFORMER_BUCKET_PATH改成您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TRANSFORMER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx。作業完成後,您會看到類似以下的訊息:
Successfully created model named all-MiniLM-L6-v2。匯入模型後,請確認模型是否顯示在資料集中。
bq ls -m bqml_tutorial
輸出結果會與下列內容相似:
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
使用 jobs.insert 方法匯入模型。在要求主體中,使用 CREATE MODEL 陳述式填入 QueryRequest 資源的 query 參數。
請使用下列
query參數值建立tokenizer模型。{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }更改下列內容:
PROJECT_ID為您的專案 ID。TOKENIZER_BUCKET_PATH,並將其替換為您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TOKENIZER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx。
請使用下列
query參數值建立all-MiniLM-L6-v2模型。{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }更改下列內容:
PROJECT_ID為您的專案 ID。TRANSFORMER_BUCKET_PATH,並提供您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TRANSFORMER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx。
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程,完成 BigQuery DataFrames 設定。詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
使用 ONNXModel 物件匯入權杖化工具和句子轉換器模型。
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
更改下列內容:
PROJECT_ID為您的專案 ID。TOKENIZER_BUCKET_PATH,並將其替換為您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TOKENIZER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx。TRANSFORMER_BUCKET_PATH,並提供您上傳至 Cloud Storage 的模型路徑。如果您使用範例模型,請將TRANSFORMER_BUCKET_PATH替換為下列值:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx。
使用匯入的 ONNX 模型生成嵌入
使用匯入的權杖化工具和句子轉換器模型,根據bigquery-public-data.imdb.reviews公開資料集的資料生成嵌入。
選取下列選項之一:
控制台
使用 ML.PREDICT 函式,透過模型生成嵌入。
查詢會使用巢狀 ML.PREDICT 呼叫,直接透過權杖化工具和嵌入模型處理原始文字,如下所示:
- 權杖化 (內部查詢):內部
ML.PREDICT呼叫會使用bqml_tutorial.tokenizer模型。並以bigquery-public-data.imdb.reviews公開資料集的title欄做為text輸入內容。tokenizer模型會將原始文字字串轉換為主要模型所需的數值權杖輸入內容,包括input_ids和attention_mask輸入內容。 - 生成嵌入 (外部查詢):外部
ML.PREDICT呼叫會使用bqml_tutorial.all-MiniLM-L6-v2模型。這項查詢會將內部查詢輸出內容中的input_ids和attention_mask資料欄做為輸入內容。
SELECT 陳述式會擷取 sentence_embedding 資料欄,這是代表文字語意嵌入的 FLOAT 值陣列。
在 Google Cloud 控制台開啟 BigQuery Studio。
在查詢編輯器中執行下列查詢。
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
結果大致如下:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
使用 bq 指令列工具的 query 指令執行查詢。這項查詢會使用 ML.PREDICT 函式,透過模型產生嵌入。
查詢會使用巢狀 ML.PREDICT 呼叫,直接透過權杖化工具和嵌入模型處理原始文字,如下所示:
- 權杖化 (內部查詢):內部
ML.PREDICT呼叫會使用bqml_tutorial.tokenizer模型。並以bigquery-public-data.imdb.reviews公開資料集的title欄做為text輸入內容。tokenizer模型會將原始文字字串轉換為主要模型所需的數值權杖輸入內容,包括input_ids和attention_mask輸入內容。 - 生成嵌入 (外部查詢):外部
ML.PREDICT呼叫會使用bqml_tutorial.all-MiniLM-L6-v2模型。這項查詢會將內部查詢輸出內容中的input_ids和attention_mask資料欄做為輸入內容。
SELECT 陳述式會擷取 sentence_embedding 資料欄,這是代表文字語意嵌入的 FLOAT 值陣列。
在指令列中執行下列指令,即可執行查詢。
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
結果大致如下:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程,完成 BigQuery DataFrames 設定。詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
使用 predict 方法,透過 ONNX 模型生成嵌入。
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
predictions.peek(5)
輸出結果會與下列內容相似:
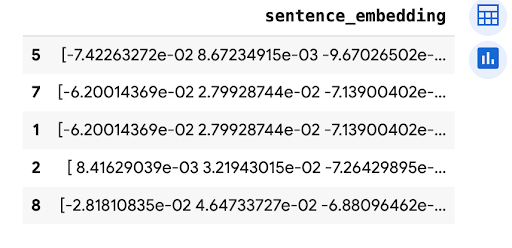
清除所用資源
為避免因為本教學課程所用資源,導致系統向 Google Cloud 收取費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除專案
控制台
- 前往 Google Cloud 控制台的「Manage resources」(管理資源) 頁面。
- 在專案清單中選取要刪除的專案,然後點選「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下 [Shut down] (關閉) 以刪除專案。
gcloud
刪除 Google Cloud 專案:
gcloud projects delete PROJECT_ID
刪除個別資源
或者,如要移除本教學課程中使用的個別資源,請執行下列操作:
後續步驟
- 瞭解如何使用文字嵌入執行語意搜尋和檢索增強生成 (RAG)。
- 如要進一步瞭解如何將 Transformer 模型轉換為 ONNX,請參閱「使用
optimum.exporters.onnx將模型匯出至 ONNX」。 - 如要進一步瞭解如何匯入 ONNX 模型,請參閱「ONNX 模型的
CREATE MODEL陳述式」。 - 如要進一步瞭解如何執行預測,請參閱「
ML.PREDICT函式」。 - 如需 BigQuery ML 的總覽,請參閱 BigQuery ML 簡介。
- 如要開始使用 BigQuery ML,請參閱在 BigQuery ML 中建立機器學習模型。