
ייצוא מודלים
בדף הזה מוסבר איך לייצא מודלים של BigQuery ML. אפשר לייצא מודלים של BigQuery ML ל-Cloud Storage ולהשתמש בהם לחיזוי אונליין, או לערוך אותם ב-Python. אפשר לייצא מודל BigQuery ML באמצעות:
- באמצעות Google Cloud המסוף.
- שימוש בהצהרה
EXPORT MODEL. - שימוש בפקודה
bq extractבכלי שורת הפקודה של BigQuery. - שליחת משימת
extractבאמצעות ה-API או ספריות הלקוח.
אפשר לייצא את סוגי המודלים הבאים:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSOR-
TENSORFLOW(imported TensorFlow models) PCATRANSFORM_ONLY
ייצוא פורמטים ודוגמאות של מודלים
בטבלה הבאה מוצגים פורמטים של יעד ייצוא לכל סוג של מודל BigQuery ML, ודוגמה לקבצים שנכתבים בקטגוריה של Cloud Storage.
| סוג המודל | פורמט ייצוא המודל | דוגמה לקבצים שיוצאו |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (TF 1.15 ואילך) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py מיועד להרצה מקומית. פרטים נוספים מופיעים במאמר בנושא פריסת מודלים.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (מיובא) | TensorFlow SavedModel | אותם קבצים בדיוק שהיו קיימים כשייבאו את המודל |
ייצוא מודל שאומן באמצעות TRANSFORM
אם המודל מאומן עם הסעיף TRANSFORM, מודל נוסף של עיבוד מקדים מבצע את אותה לוגיקה בסעיף TRANSFORM ונשמר בפורמט TensorFlow SavedModel בספריית המשנה transform.
אפשר לפרוס מודל שאומן באמצעות פסוקית TRANSFORM ב-Gemini Enterprise Agent Platform וגם באופן מקומי. מידע נוסף זמין במאמר בנושא פריסת מודלים.
| פורמט ייצוא המודל | דוגמה לקבצים שיוצאו |
|---|---|
|
מודל חיזוי: TensorFlow SavedModel או Booster (XGBoost 0.82).
מודל לעיבוד מראש של סעיף TRANSFORM: TensorFlow SavedModel (גרסה TF 2.5 ואילך) |
gcs_bucket/
|
המודל לא מכיל את המידע על הנדסת התכונות
שבוצעה מחוץ לסעיף TRANSFORM
במהלך האימון. לדוגמה, כל מה שמופיע בהצהרה SELECT. לכן, תצטרכו להמיר את נתוני הקלט באופן ידני לפני שתזינו אותם למודל של עיבוד מקדים.
סוגי נתונים נתמכים
כשמייצאים מודלים שאומנו באמצעות הפסקה TRANSFORM, סוגי הנתונים הבאים נתמכים להזנה אל הפסקה TRANSFORM.
| סוג הקלט של TRANSFORM | דוגמאות לקלט של פונקציית TRANSFORM | דוגמאות קלט של מודל שעבר אימון מקדים |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| מחרוזת |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| תאריך |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| שעות |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
פונקציות SQL נתמכות
כשמייצאים מודלים שאומנו באמצעות התנאי TRANSFORM, אפשר להשתמש בפונקציות ה-SQL הבאות בתוך התנאי TRANSFORM:
- אופרטורים
-
+, -, *, /, =, <, >, <=, >=, !=, <>,[NOT] BETWEEN, [NOT] IN, IS [NOT] NULL, IS [NOT] TRUE,IS [NOT] FALSE, NOT, AND, OR.
-
- ביטויי תנאי
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- פונקציות מתמטיות
-
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
-
- פונקציות המרה
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- פונקציות של מחרוזות
-
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
-
- פונקציות תאריך
-
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
-
- פונקציות של תאריך ושעה
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- פונקציות שקשורות לזמן
-
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
-
- פונקציות של חותמות זמן
-
TIMESTAMP, TIMESTAMP_ADD, TIMESTAMP_SUB, TIMESTAMP_DIFF,TIMESTAMP_TRUNC, FORMAT_TIMESTAMP, PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP, TIMESTAMP_MICROS, TIMESTAMP_MILLIS,TIMESTAMP_SECONDS, EXTRACT, STRING, UNIX_MICROS, UNIX_MILLIS,UNIX_SECONDS.
-
- פונקציות לעיבוד מקדים ידני
-
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
-
מגבלות
כשמייצאים מודלים, חלות המגבלות הבאות:
ייצוא מודל לא אפשרי אם נעשה שימוש באחת מהתכונות הבאות במהלך האימון:
- סוגי התכונות
ARRAY,TIMESTAMPאוGEOGRAPHYהיו קיימים בנתוני הקלט.
- סוגי התכונות
מודלים שיוצאו לסוגי המודלים
AUTOML_REGRESSORו-AUTOML_CLASSIFIERלא תומכים בפריסה של Agent Platform לחיזוי אונליין.מגבלת הגודל של המודל היא 1GB לייצוא של מודל פירוק מטריצות. גודל המודל פרופורציונלי בערך ל-
num_factors, כך שאם תגיעו למגבלה, תוכלו להקטין אתnum_factorsבמהלך האימון כדי להקטין את גודל המודל.לגבי מודלים שאומנו באמצעות סעיף BigQuery ML
TRANSFORMלעיבוד מקדים ידני של תכונות, אפשר לעיין בסוגי הנתונים ובפונקציות שנתמכים בייצוא.מודלים שאומנו באמצעות פסקה BigQuery ML
TRANSFORMלפני 18 בספטמבר 2023, צריכים לעבור אימון מחדש לפני שניתן יהיה לפרוס אותם דרך מרשם המודלים לחיזוי אונליין.במהלך ייצוא המודל, יש תמיכה ב-
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYוב-TIMESTAMPכנתונים שעברו טרנספורמציה מראש, אבל אין תמיכה בהם כנתונים שעברו טרנספורמציה אחרי הייצוא.
ייצוא מודלים של BigQuery ML
כדי לייצא מודל, בוחרים באחת מהאפשרויות הבאות:
המסוף
פותחים את הדף BigQuery במסוף Google Cloud .
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, מרחיבים את הפרויקט, לוחצים על Datasets (מערכי נתונים) ואז לוחצים על מערך הנתונים.
לוחצים על סקירה כללית > מודלים ולוחצים על שם המודל שמייצאים.
לוחצים על עוד > ייצוא:
בתיבת הדו-שיח Export model to Google Cloud Storage:
- בשדה Select GCS location (בחירת מיקום ב-GCS), מחפשים את המאגר או את מיקום התיקייה שאליהם רוצים לייצא את המודל ולוחצים על Select (בחירה).
- לוחצים על שליחה כדי לייצא את המודל.
כדי לבדוק את התקדמות העבודה, בחלונית Explorer לוחצים על Job history ומחפשים עבודה מסוג EXTRACT.
SQL
ההצהרה EXPORT MODEL מאפשרת לייצא מודלים של BigQuery ML ל-Cloud Storage באמצעות תחביר של שאילתות GoogleSQL.
כדי לייצא מודל BigQuery ML במסוף Google Cloud באמצעות הצהרת EXPORT MODEL, פועלים לפי השלבים הבאים:
נכנסים לדף BigQuery במסוף Google Cloud .
לוחצים על Compose new query.
בשדה עורך השאילתות, מקלידים את הצהרת
EXPORT MODEL.השאילתה הבאה מייצאת מודל בשם
myproject.mydataset.mymodelלקטגוריה של Cloud Storage עם URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
לוחצים על Run. בסיום השאילתה, בחלונית Query results מופיע:
Successfully exported model.
BQ
משתמשים בפקודה bq extract עם הדגל --model.
(אופציונלי) מציינים את הדגל --destination_format ובוחרים את הפורמט של המודל המיוצא.
(אופציונלי) מציינים את הדגל --location ומגדירים את הערך למיקום.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
כאשר:
- location הוא השם של המיקום. הדגל
--locationהוא אופציונלי. לדוגמה, אם אתם משתמשים ב-BigQuery באזור טוקיו, אתם יכולים להגדיר את הערך של הדגל כ-asia-northeast1. אפשר להגדיר ערך ברירת מחדל למיקום באמצעות הקובץ .bigqueryrc. - destination_format הוא הפורמט של המודל המיוצא:
ML_TF_SAVED_MODEL(ברירת מחדל) אוML_XGBOOST_BOOSTER. - project_id הוא מזהה הפרויקט.
- dataset הוא השם של מערך נתוני המקור.
- model הוא המודל שמייצאים.
- bucket הוא השם של קטגוריית Cloud Storage שאליה מייצאים את הנתונים. מערך הנתונים ב-BigQuery והקטגוריה ב-Cloud Storage צריכים להיות באותו מיקום.
- model_folder הוא שם התיקייה שבה ייכתבו קובצי המודל המיוצאים.
דוגמאות:
לדוגמה, הפקודה הבאה מייצאת את mydataset.mymodel בפורמט TensorFlow SavedModel לקטגוריה של Cloud Storage בשם mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
ערך ברירת המחדל של destination_format הוא ML_TF_SAVED_MODEL.
הפקודה הבאה מייצאת את mydataset.mymodel בפורמט XGBoost Booster לקטגוריה של Cloud Storage בשם mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
כדי לייצא מודל, יוצרים משימת extract ומאכלסים את הגדרות המשימה.
(אופציונלי) מציינים את המיקום במאפיין location בקטע jobReference של משאב המשרה.
יוצרים משימת חילוץ שמפנה למודל BigQuery ML וליעד ב-Cloud Storage.
מציינים את מודל המקור באמצעות אובייקט ההגדרה
sourceModelשמכיל את מזהה הפרויקט, מזהה מערך הנתונים ומזהה המודל.המאפיין
destination URI(s)צריך להיות מוגדר באופן מלא, בפורמט gs://bucket/model_folder.מגדירים את מאפיין
configuration.extract.destinationFormatכדי לציין את פורמט היעד. לדוגמה, כדי לייצא מודל של עץ מחוזק, מגדירים את המאפיין הזה לערךML_XGBOOST_BOOSTER.כדי לבדוק את סטטוס העבודה, קוראים ל-jobs.get(job_id) עם המזהה של העבודה שהוחזר מהבקשה הראשונית.
- אם התוצאה היא
status.state = DONE, העבודה הושלמה בהצלחה. - אם מאפיין
status.errorResultקיים, הבקשה נכשלה והאובייקט יכלול מידע שמתאר מה השתבש. - אם
status.errorResultלא מופיע, העבודה הסתיימה בהצלחה, למרות שיכול להיות שהיו כמה שגיאות לא קריטיות. שגיאות לא קריטיות מפורטות במאפייןstatus.errorsשל אובייקט המשימה שמוחזר.
- אם התוצאה היא
הערות לגבי ה-API:
מומלץ ליצור מזהה ייחודי ולהעביר אותו כ-
jobReference.jobIdכשקוראים ל-jobs.insertכדי ליצור משימה. הגישה הזו עמידה יותר בפני כשלים ברשת, כי הלקוח יכול לבצע בדיקה או לנסות שוב באמצעות מזהה המשימה הידוע.הקריאה ל-
jobs.insertבמזהה משימה נתון היא אידמפוטנטית. במילים אחרות, אפשר לנסות שוב כמה פעמים שרוצים עם אותו מזהה משימה, ולכל היותר אחת מהפעולות האלה תצליח.
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
פריסת מודל
אפשר לפרוס את המודל המיוצא ב-Agent Platform וגם באופן מקומי. אם המשפט TRANSFORM של המודל מכיל פונקציות של תאריך, פונקציות של תאריך ושעה, פונקציות של שעה או פונקציות של חותמת זמן, צריך להשתמש בספרייה bigquery-ml-utils בקונטיינר. החריג הוא אם מבצעים פריסה דרך Model Registry, שלא דורשת מודלים מיוצאים או קונטיינרים להצגת מודעות.
פריסה של Agent Platform
| פורמט ייצוא המודל | פריסה |
|---|---|
| TensorFlow SavedModel (מודלים שאינם מודלים של AutoML) | פריסת TensorFlow SavedModel. צריך ליצור את קובץ ה-SavedModel באמצעות גרסה נתמכת של TensorFlow. |
| TensorFlow SavedModel (מודלים של AutoML) | לא נתמך. |
| XGBoost Booster |
משתמשים בשגרה מותאמת אישית של תחזיות. במודלים של XGBoost Booster, מידע על עיבוד מקדים ועיבוד פוסט-עיבוד נשמר בקבצים המיוצאים, ושגרת חיזוי בהתאמה אישית מאפשרת לכם לפרוס את המודל עם הקבצים הנוספים המיוצאים.
צריך ליצור את קובצי המודל באמצעות גרסה נתמכת של XGBoost. |
פריסה מקומית
| פורמט ייצוא המודל | פריסה |
|---|---|
| TensorFlow SavedModel (מודלים שאינם מודלים של AutoML) |
SavedModel הוא פורמט סטנדרטי, ואפשר לפרוס אותו בקונטיינר Docker של TensorFlow Serving. אפשר גם להשתמש בהרצה מקומית של חיזוי אונליין ב-Agent Platform. |
| TensorFlow SavedModel (מודלים של AutoML) | העברת המודל לקונטיינר והרצה שלו. |
| XGBoost Booster |
כדי להפעיל מודלים של XGBoost Booster באופן מקומי, אפשר להשתמש בקובץ main.py
שיוצא:
|
פורמט הפלט של החיזוי
בקטע הזה מפורט פורמט הפלט של התחזית של המודלים המיוצאים לכל סוג מודל. כל המודלים המיוצאים תומכים בחיזוי אצווה, והם יכולים לטפל בכמה שורות קלט בו-זמנית. לדוגמה, יש שתי שורות קלט בכל אחת מהדוגמאות הבאות של פורמט הפלט.
AUTOENCODER
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER ו-RANDOM_FOREST_CLASSIFIER
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR ו-RANDOM_FOREST_REGRESSOR
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
הערה: אנחנו תומכים רק בקבלת קלט של משתמש והפקת פלט של 50 זוגות (predicted_rating, predicted_item) ממוינים לפי predicted_rating בסדר יורד.
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (מיובא)
| פורמט הפלט של החיזוי |
|---|
| זהה למודל המיובא |
PCA
| פורמט הפלט של החיזוי | פלט לדוגמה |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| פורמט הפלט של החיזוי |
|---|
זהה לעמודות שצוינו בסעיף TRANSFORM של המודל
|
הצגה חזותית של מודל XGBoost
אחרי ייצוא המודל, אפשר ליצור תרשים להמחשה של העצים המחוזקים באמצעות plot_tree API בשפת Python. לדוגמה, אפשר להשתמש ב-Colab בלי להתקין את יחסי התלות:
- ייצוא של מודל עץ מחוזק לקטגוריה של Cloud Storage.
- מורידים את הקובץ
model.bstמקטגוריה של Cloud Storage. - ב-נוטבוק של Colab, מעלים את הקובץ
model.bstאלFiles. מריצים את הקוד הבא ב-notebook:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
בדוגמה הזו מוצגים כמה עצים (עץ אחד לכל איטרציה):
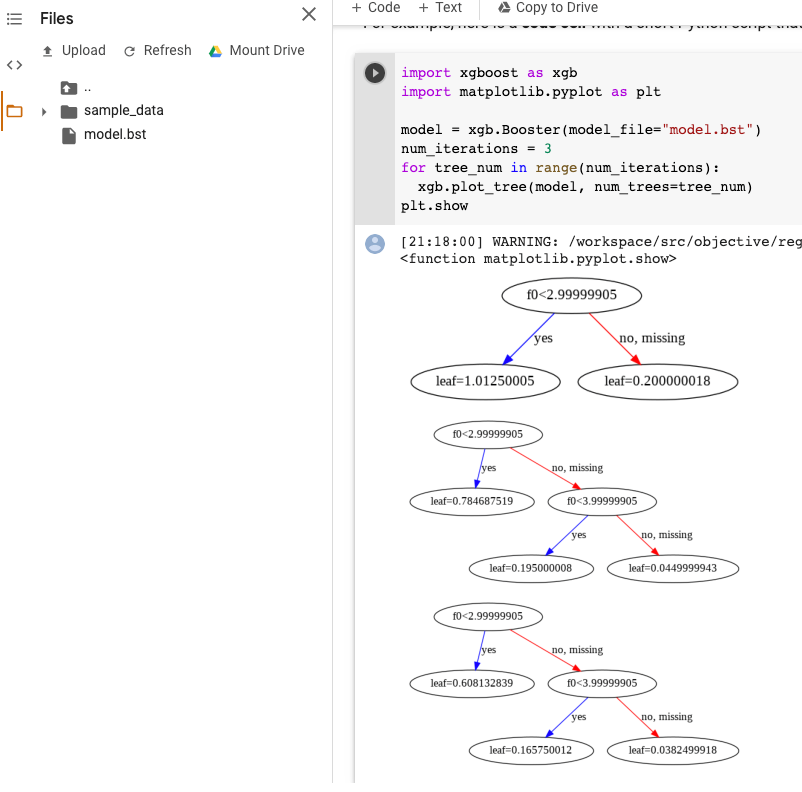
אנחנו לא שומרים את שמות התכונות במודל, ולכן יוצגו שמות כמו f0, f1 וכן הלאה. אפשר למצוא את שמות התכונות המתאימים בקובץ המיוצא assets/model_metadata.json באמצעות השמות האלה (למשל f0) בתור אינדקסים.
ההרשאות הנדרשות
כדי לייצא מודל BigQuery ML ל-Cloud Storage, צריך הרשאות גישה למודל BigQuery ML, הרשאות להפעלת עבודת חילוץ והרשאות לכתיבת הנתונים לקטגוריה של Cloud Storage.
הרשאות ב-BigQuery
כדי לייצא מודל, אתם צריכים לקבל לפחות הרשאות
bigquery.models.export. התפקידים המוגדרים מראש הבאים בניהול הזהויות והרשאות הגישה (IAM) מקבלים את ההרשאותbigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
כדי להריץ משימת ייצוא, אתם צריכים לקבל לפחות הרשאות
bigquery.jobs.create. התפקידים המוגדרים מראש הבאים ב-IAM מקבלים הרשאותbigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
הרשאות ב-Cloud Storage
כדי לכתוב את הנתונים לקטגוריית Cloud Storage קיימת, צריך לקבל הרשאות
storage.objects.create. התפקידים המוגדרים מראש הבאים ב-IAM מקבלים הרשאותstorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
במאמר בקרת גישה יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery ML.
העברת נתונים ב-BigQuery בין מיקומים
אי אפשר לשנות את המיקום של מערך נתונים אחרי שיוצרים אותו, אבל אפשר ליצור עותק של מערך הנתונים.
מדיניות בנושא מכסה
מידע על מכסות של משימות חילוץ זמין במאמר משימות חילוץ בדף מכסות ומגבלות.
תמחור
אין תשלום על ייצוא מודלים של BigQuery ML, אבל הייצוא כפוף למכסות ולמגבלות של BigQuery. מידע נוסף על התמחור של BigQuery זמין בדף תמחור.
אחרי ייצוא הנתונים, תחויבו על אחסון הנתונים ב-Cloud Storage. מידע נוסף על התמחור של Cloud Storage מופיע בדף התמחור של Cloud Storage.
המאמרים הבאים
- עוברים על המדריך ייצוא מודל BigQuery ML לחיזוי אונליין.