
שימוש ב-BigQuery DataFrames ב-dbt
dbt (כלי לבניית נתונים) הוא מסגרת קוד פתוח של שורת פקודה שנועדה לטרנספורמציה של נתונים במחסני נתונים מודרניים. dbt מאפשר טרנספורמציות מודולריות של נתונים באמצעות יצירה של מודלים לשימוש חוזר שמבוססים על SQL ו-Python. הכלי מתזמן את הביצוע של השינויים האלה במחסן הנתונים של היעד, ומתמקד בשלב השינוי של צינור ה-ELT. מידע נוסף זמין במאמרי העזרה של dbt.
ב-dbt, מודל Python הוא טרנספורמציה של נתונים שמוגדרת ומופעלת באמצעות קוד Python בפרויקט dbt. במקום לכתוב SQL ללוגיקת הטרנספורמציה, כותבים סקריפטים של Python ש-dbt מתזמן להרצה בסביבת מחסן הנתונים. מודל Python מאפשר לבצע טרנספורמציות של נתונים שאולי יהיה מורכב או לא יעיל לבטא ב-SQL. הגישה הזו מאפשרת להשתמש ביכולות של Python ועדיין ליהנות ממבנה הפרויקט, מהתזמור, מניהול יחסי התלות, מהבדיקות ומהתכונות של התיעוד ב-dbt. מידע נוסף זמין במאמר בנושא מודלים של Python.
מתאם dbt-bigquery תומך בהרצת קוד Python שמוגדר ב-BigQuery DataFrames. התכונה הזו זמינה ב-dbt Cloud וב-dbt Core.
אפשר גם להשתמש בתכונה הזו על ידי שיבוט של הגרסה האחרונה של מתאם dbt-bigquery.
לפני שמתחילים
כדי להשתמש במתאם dbt-bigquery, צריך להפעיל את ממשקי ה-API הבאים בפרויקט:
- BigQuery API (
bigquery.googleapis.com) - Cloud Storage API (
storage.googleapis.com) - Compute Engine API (
compute.googleapis.com) - Dataform API (
dataform.googleapis.com) - Identity and Access Management API (
iam.googleapis.com) - Vertex AI API (
aiplatform.googleapis.com)
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאה serviceusage.services.enable. איך מקצים תפקידים
התפקידים הנדרשים
מתאם dbt-bigquery תומך באימות שמבוסס על OAuth ועל חשבון שירות. בקטעים הבאים מתוארים התפקידים הנדרשים בהתאם לשיטת האימות שבה אתם מתכננים להשתמש.
OAuth
אם אתם מתכננים לבצע אימות למתאם dbt-bigquery באמצעות OAuth, אתם צריכים לבקש מהאדמין להקצות לכם את התפקידים הבאים:
- התפקיד BigQuery User (
roles/bigquery.user) בפרויקט - התפקיד BigQuery Data Editor (
roles/bigquery.dataEditor) בפרויקט או במערך הנתונים שבו הטבלאות נשמרות - תפקיד המשתמש ב-Colab Enterprise
(
roles/colabEnterprise.user) בפרויקט - תפקיד Storage Admin (
roles/storage.admin) בקטגוריית Cloud Storage של שלב ההכנה להעברה, לצורך הכנת קוד ויומנים
חשבון שירות
אם אתם מתכננים לבצע אימות למתאם dbt-bigquery באמצעות חשבון שירות בפרויקט, בקשו מהאדמין להקצות את התפקידים הבאים לחשבון השירות שבו אתם מתכננים להשתמש:
- תפקיד BigQuery User
(
roles/bigquery.user) - התפקיד BigQuery Data Editor
(
roles/bigquery.dataEditor) - תפקיד משתמש ב-Colab Enterprise
(
roles/colabEnterprise.user) - תפקיד אדמין באחסון
(
roles/storage.admin)
אם אתם מבצעים אימות באמצעות חשבון שירות, ודאו גם שהתפקיד Service Account User (roles/iam.serviceAccountUser) הוקצה לחשבון השירות שבו אתם מתכננים להשתמש.
התחזות לחשבון שירות
אם אתם מתכננים לבצע אימות למתאם dbt-bigquery באמצעות OAuth, אבל רוצים שעיבוד הנתונים והפעלת המחברת יתבצעו תחת הזהות של חשבון שירות באותו פרויקט שבו מופעלים הג'ובים, אתם צריכים לבקש מהאדמין להקצות לכם את התפקידים הבאים:
- התפקיד 'יצירת אסימונים בחשבון שירות'
(
roles/iam.serviceAccountTokenCreator) - משתמש בחשבון שירות
(
roles/iam.serviceAccountUser)
בנוסף, לחשבון השירות שאליו מתחזים צריכים להיות כל התפקידים שנדרשים לאימות.
חשבונות שירות חוצי-פרויקטים
אם אתם מתכננים לבצע אימות למתאם dbt-bigquery באמצעות חשבון שירות בפרויקט אחר, פרויקט פרטי הכניסה, שממנו מופעלים הג'ובים, פרויקט ההפעלה, אתם צריכים לבקש מהאדמין לבצע את הפעולות הבאות:
- משביתים את האילוץ
constraints/iam.disableCrossProjectServiceAccountUsageבפרויקט של פרטי הכניסה. בנוסף לכל התפקידים שנדרשים לאימות חשבון שירות, מקצים לחשבון השירות בפרויקט של פרטי הכניסה את התפקידים הבאים:
- תפקיד סוכן השירות של Vertex AI
(roles/aiplatform.serviceAgent) אל
service-PROJECT_NUMBER@gcp-sa-aiplatform.iam.gserviceaccount.com - Vertex AI Colab Service Agent role
(roles/aiplatform.colabServiceAgent) to
service-PROJECT_NUMBER@gcp-sa-vertex-nb.iam.gserviceaccount.com - התפקיד של סוכן השירות של Compute Engine (roles/compute.serviceAgent) אל
service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.com
- תפקיד סוכן השירות של Vertex AI
(roles/aiplatform.serviceAgent) אל
אם אתם מתכננים לבצע אימות למתאם dbt-bigquery באמצעות OAuth, אבל רוצים שעיבוד הנתונים והפעלת המחברת יתבצעו תחת הזהות של חשבון שירות בפרויקט אחר שבו מופעלים הג'ובים, אתם צריכים לבקש מהאדמין שלכם לבצע את הפעולות הבאות:
- פועלים לפי השלבים שמתוארים למעלה בנושא חשבונות שירות בין פרויקטים עבור חשבון השירות בפרויקט אחר.
- מקצים לכם ולחשבון השירות את התפקידים שנדרשים להתחזות לחשבון השירות
VPC משותף
אם אתם משתמשים ב-Colab Enterprise בסביבת Shared VPC, אתם צריכים לבקש מהאדמין להקצות לכם את התפקידים וההרשאות הבאים:
הרשאה
compute.subnetworks.use: צריך להעניק את ההרשאה הזו לחשבון השירות שזמן הריצה של Colab Enterprise משתמש בו בפרויקט המארח או ברשתות משנה ספציפיות. ההרשאה הזו כלולה בתפקיד Compute Network User (roles/compute.networkUser).הרשאה
compute.subnetworks.get: צריך להעניק את ההרשאה הזו לחשבון השירות שזמן הריצה של Colab Enterprise משתמש בו בפרויקט המארח או ברשתות משנה ספציפיות. ההרשאה הזו כלולה בתפקיד 'צפייה ברשת Compute' (roles/compute.networkViewer).התפקיד Compute Network User (
roles/compute.networkUser): צריך להעניק את התפקיד הזה לסוכן של שירות Gemini Enterprise Agent Platform, service-PROJECT_NUMBER@gcp-sa-aiplatform.iam.gserviceaccount.com, בפרויקט המארח של ה-VPC המשותף.התפקיד Compute Network User (
roles/compute.networkUser): אם נעשה שימוש בתכונה של משימת הפעלת מחברת, צריך להעניק את התפקיד הזה לסוכן השירות של Colab Enterprise,service-PROJECT_NUMBER@gcp-sa-vertex-nb.iam.gserviceaccount.com, בפרויקט המארח של ה-VPC המשותף.
כדי לקרוא הסבר על מתן תפקידים, קראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שתוכלו לקבל את ההרשאות הנדרשות גם באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
סביבת הפעלה של Python
המתאם dbt-bigquery משתמש בשירות ההפעלה של מחברות Colab Enterprise כדי להפעיל את קוד Python של BigQuery DataFrames. מחברת Colab Enterprise נוצרת ומופעלת באופן אוטומטי על ידי מתאם dbt-bigquery לכל מודל Python. אפשר לבחור את הפרויקטGoogle Cloud שבו רוצים להריץ את המחברת. ה-Notebook מריץ את קוד Python מהמודל, שמומר ל-BigQuery SQL על ידי ספריית BigQuery DataFrames. לאחר מכן, קוד ה-SQL של BigQuery מופעל בפרויקט שהוגדר. בתרשים הבא מוצג תהליך הבקרה:
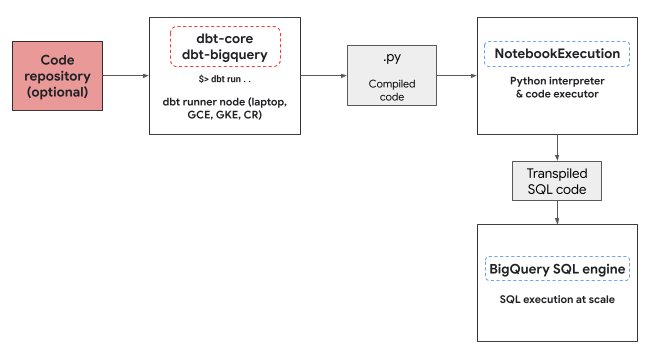
אם אין תבנית מחברת שכבר זמינה בפרויקט ולמשתמש שמריץ את הקוד יש הרשאות ליצור את התבנית, מתאם dbt-bigquery יוצר באופן אוטומטי את תבנית המחברת שמוגדרת כברירת מחדל ומשתמש בה. אפשר גם לציין תבנית מחברת שונה באמצעות הגדרת dbt.
כדי להריץ את ה-notebook, צריך קטגוריה של Cloud Storage זמנית לאחסון הקוד והיומנים. עם זאת, המתאם dbt-bigquery מעתיק את היומנים אל dbt logs, כך שלא צריך לחפש אותם בדלי.
תכונות נתמכות
המתאם dbt-bigquery תומך ביכולות הבאות של מודלים של dbt Python שמופעלים ב-BigQuery DataFrames:
- טעינת נתונים מטבלה קיימת ב-BigQuery באמצעות מאקרו
dbt.source(). - טעינת נתונים ממודלים אחרים של dbt באמצעות מאקרו
dbt.ref()כדי ליצור תלות וגרפים אציקליים מכוונים (DAG) עם מודלים של Python. - ציון חבילות Python מ-PyPi שאפשר להשתמש בהן בהרצת קוד Python. מידע נוסף מופיע במאמר בנושא הגדרות.
- ציון תבנית מותאמת אישית של זמן ריצה של מחברת למודלים של BigQuery DataFrames.
מתאם dbt-bigquery תומך בשיטות המימוש הבאות:
- מימוש טבלה, שבו הנתונים נבנים מחדש כטבלה בכל הפעלה.
- חומריזציה מצטברת עם אסטרטגיית מיזוג, שבה נתונים חדשים או מעודכנים מתווספים לטבלה קיימת, לרוב באמצעות אסטרטגיית מיזוג לטיפול בשינויים.
הגדרת dbt לשימוש ב-BigQuery DataFrames
אם אתם משתמשים ב-dbt Core, אתם צריכים להשתמש בקובץ profiles.yml כדי להשתמש ב-BigQuery DataFrames.
בדוגמה הבאה השתמשנו במתודה oauth:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
אם אתם משתמשים ב-dbt Cloud, אתם יכולים להתחבר לפלטפורמת הנתונים ישירות בממשק של dbt Cloud. בתרחיש הזה, לא צריך קובץ profiles.yml. מידע נוסף זמין במאמר מידע על profiles.yml.
זו דוגמה להגדרה ברמת הפרויקט בקובץ dbt_project.yml:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
אפשר גם להגדיר חלק מהפרמטרים באמצעות dbt.config method
בתוך קוד Python. אם ההגדרות האלה סותרות את הקובץ dbt_project.yml, התצורות עם dbt.config יקבלו עדיפות.
מידע נוסף זמין במאמרים בנושא הגדרות מודל ו-dbt_project.yml.
הגדרות אישיות
אתם יכולים להגדיר את ההגדרות הבאות באמצעות ה-method dbt.config במודל Python. ההגדרות האלה מבטלות את ההגדרות ברמת הפרויקט.
| הגדרות אישיות | חובה | Usage |
|---|---|---|
submission_method |
כן | submission_method=bigframes |
notebook_template_id |
לא | אם לא מציינים תבנית, המערכת יוצרת תבנית ברירת מחדל ומשתמשת בה. |
packages |
לא | מציינים את הרשימה הנוספת של חבילות Python, אם נדרש. |
timeout |
לא | אופציונלי: אפשר להאריך את הזמן הקצוב לתפוגה של ביצוע המשימה. |
דוגמאות למודלים של Python
בקטעים הבאים מוצגים תרחישים לדוגמה ומודלים של Python.
טעינת נתונים מטבלה ב-BigQuery
כדי להשתמש בנתונים מטבלה קיימת ב-BigQuery כמקור במודל Python, צריך קודם להגדיר את המקור הזה בקובץ YAML. הדוגמה הבאה מוגדרת בקובץ source.yml.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
לאחר מכן, יוצרים את מודל Python, שיכול להשתמש במקורות הנתונים שהוגדרו בקובץ ה-YAML הזה:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
הפניה למודל אחר
אפשר ליצור מודלים שתלויים בפלט של מודלים אחרים של dbt, כמו בדוגמה הבאה. כדאי להיעזר בזה אם רוצים ליצור צינורות עיבוד נתונים מודולריים.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
ציון של יחסי תלות של חבילה
אם מודל Python שלכם דורש ספריות ספציפיות של צד שלישי כמו MLflow או Boto3, אתם יכולים להצהיר על החבילה בהגדרות של המודל, כמו בדוגמה הבאה. החבילות האלה מותקנות בסביבת ההפעלה.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
ציון תבנית שאינה ברירת המחדל
כדי לקבל שליטה רבה יותר בסביבת ההרצה או כדי להשתמש בהגדרות שהוגדרו מראש, אפשר להגדיר תבנית מחברת שאינה ברירת המחדל עבור מודל BigQuery DataFrames, כמו בדוגמה הבאה.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
יצירת טבלאות
כשמריצים את מודלי Python ב-dbt, המערכת צריכה לדעת איך לשמור את התוצאות במחסן הנתונים. התהליך הזה נקרא מימוש.
במימוש של טבלה רגילה, dbt יוצר או מחליף באופן מלא טבלה במחסן הנתונים עם הפלט של המודל בכל פעם שהוא מופעל. הפעולה הזו מתבצעת כברירת מחדל, או על ידי הגדרה מפורשת של המאפיין materialized='table', כמו בדוגמה הבאה.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
הוספת נתונים מצטברת באמצעות אסטרטגיית מיזוג מאפשרת ל-dbt לעדכן את הטבלה רק בשורות חדשות או בשורות שעברו שינוי. האפשרות הזו שימושית למערכי נתונים גדולים, כי בנייה מחדש של טבלה בכל פעם עלולה להיות לא יעילה. אחת הדרכים הנפוצות לטפל בעדכונים האלה היא באמצעות אסטרטגיית מיזוג.
הגישה הזו משלבת שינויים בצורה חכמה על ידי ביצוע הפעולות הבאות:
- עדכון של שורות קיימות שהשתנו.
- הוספת שורות חדשות.
- אופציונלי, בהתאם להגדרה: מחיקת שורות שכבר לא מופיעות במקור.
כדי להשתמש באסטרטגיית המיזוג, צריך לציין מאפיין unique_key ש-dbt יכול להשתמש בו כדי לזהות את השורות התואמות בין הפלט של המודל לבין הטבלה הקיימת, כמו שמוצג בדוגמה הבאה.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
פתרון בעיות
אפשר לראות את ההרצה של Python ביומני dbt.
בנוסף, אפשר לראות את הקוד ואת היומנים (כולל הרצות קודמות) בדף Colab Enterprise Executions.
מעבר אל Colab Enterprise Executions
חיוב
כשמשתמשים במתאם dbt-bigquery עם BigQuery DataFrames, Google Cloud יש חיובים על הפעולות הבאות:
ביצוע Notebook: אתם מחויבים על זמן הריצה של ה-Notebook. מידע נוסף זמין במאמר בנושא תמחור של זמן ריצה של מחברת.
הרצת שאילתות BigQuery: ב-Notebook, BigQuery DataFrames ממיר את Python ל-SQL ומריץ את הקוד ב-BigQuery. החיוב מתבצע בהתאם להגדרות הפרויקט ולשאילתה, כמו שמתואר בתמחור של BigQuery DataFrames.
אפשר להשתמש בתווית החיוב הבאה במסוף החיוב של BigQuery כדי לסנן את דוח החיוב לפי הפעלת מחברת ולפי הפעלות של BigQuery שהופעלו על ידי מתאם dbt-bigquery:
- תווית הביצוע של BigQuery:
bigframes-dbt-api
המאמרים הבאים
- מידע נוסף על dbt ו-BigQuery DataFrames זמין במאמר בנושא שימוש ב-BigQuery DataFrames עם מודלים של dbt Python.
- מידע נוסף על מודלים של dbt Python זמין במאמרים Python models ו-Python model configuration.
- מידע נוסף על מחברות Colab Enterprise זמין במאמר בנושא יצירת מחברת Colab Enterprise באמצעות מסוף. Google Cloud
- Google Cloud מידע נוסף על שותפים זמין במאמר Google Cloud Ready - BigQuery Partners.