
Gemini로 데이터 준비
이 문서에서는 Gemini의 SQL 코드 추천을 사용하여 BigQuery 데이터 준비 내에서 데이터를 정리하고 변환하는 방법을 설명합니다.
자세한 내용은 BigQuery 데이터 준비 개요를 참고하세요.
시작하기 전에
데이터 준비 세션 시작
새 데이터 준비를 만들거나, 기존 테이블 또는 Cloud Storage나 Google Drive 파일에서 시작하거나, 기존 데이터 준비를 열어 BigQuery 데이터 준비 편집기를 엽니다. 데이터 준비를 만들 때 어떤 일이 일어나는지에 관한 자세한 내용은 데이터 준비 진입점을 참고하세요.
BigQuery 페이지에서 다음 방법으로 데이터 준비 편집기로 이동할 수 있습니다.
새로 만들기
BigQuery에서 새 데이터 준비를 만들려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 - 새로 만들기 목록으로 이동하여 데이터 준비를 클릭합니다. 데이터 준비 편집기가 제목이 없는 새 데이터 준비 탭에 표시됩니다.
- 편집기의 검색창에 테이블 이름 또는 키워드를 입력하고 테이블을 선택합니다. 테이블의 데이터 준비 편집기가 열리고 데이터 탭에 데이터 미리보기와 Gemini의 초기 데이터 준비 추천이 표시됩니다.
- 선택사항: 보기를 간소화하려면 전체 화면 전체 화면을 클릭하여 전체 화면 모드를 사용 설정합니다.
선택사항: 데이터 준비 세부정보, 버전 기록을 보거나 새 댓글을 추가하거나 기존 댓글에 답글을 달려면 툴바를 사용합니다.
댓글 툴바 기능은 프리뷰 버전으로 제공됩니다. 이 기능에 대한 의견을 제공하거나 지원을 요청하려면 bqui-workspace-pod@google.com으로 이메일을 보내세요.
표에서 만들기
기존 테이블에서 새 데이터 준비를 만들려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 - 왼쪽 창에서 탐색기를 클릭합니다.
- 탐색기 창에서 프로젝트를 펼치고 데이터 세트를 클릭한 후 데이터 세트를 선택합니다.
- 표 이름에서 more_vert 작업 > > 데이터 준비에서 열기를 클릭합니다. 테이블의 데이터 준비 편집기가 열리고 데이터 탭에 데이터 미리보기와 Gemini의 초기 데이터 준비 추천이 표시됩니다.
- 선택사항: 보기를 간소화하려면 전체 화면 전체 화면을 클릭하여 전체 화면 모드를 사용 설정합니다.
선택사항: 데이터 준비 세부정보, 버전 기록을 보거나 새 댓글을 추가하거나 기존 댓글에 답글을 달려면 툴바를 사용합니다.
댓글 툴바 기능은 프리뷰 버전으로 제공됩니다. 이 기능에 대한 의견을 제공하거나 지원을 요청하려면 bqui-workspace-pod@google.com으로 이메일을 보내세요.
파일에서 만들기
Cloud Storage 또는 Google Drive의 파일에서 새 데이터 준비를 만들려면 다음 단계를 따르세요.
파일 로드
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 - 새로 만들기 목록에서 데이터 준비를 클릭합니다. 데이터 준비 편집기가 제목 없는 새 데이터 준비 탭에 표시됩니다.
- 데이터 소스 목록에서 Google Cloud Storage 또는 Google Drive를 클릭합니다. 데이터 준비 대화상자가 열립니다.
- 소스 섹션에서 파일을 선택합니다.
- Cloud Storage: Cloud Storage 버킷에서 파일을 선택하거나 소스 경로를 입력합니다.
예를 들어 CSV 파일의 경로를 입력합니다.
STORAGE_BUCKET_NAME/FILE_NAME.csv*.csv과 같은 와일드 카드 검색이 지원됩니다. - Google Drive: URI를 입력하여 Google Drive에서 파일을 선택합니다. 데이터의 하위 집합을 로드하려면 특정 시트 이름과 범위를 입력하면 됩니다.
파일 형식은 자동으로 감지됩니다. 지원되는 형식은 Avro, CSV, JSONL, ORC, Parquet입니다. DAT, TSV, TXT와 같은 기타 호환 파일 형식은 CSV 형식으로 읽습니다. Google Drive 옵션은 Google Sheets 형식도 지원합니다.
- Cloud Storage: Cloud Storage 버킷에서 파일을 선택하거나 소스 경로를 입력합니다.
예를 들어 CSV 파일의 경로를 입력합니다.
- 파일을 업로드할 외부 스테이징 테이블을 정의합니다. 스테이징 테이블 섹션에 새 테이블의 프로젝트, 데이터 세트, 테이블 이름을 입력합니다.
- 스키마 섹션에서 스키마를 검토합니다.
Gemini가 파일에서 열 이름을 확인합니다. 찾지 못하면 제안을 제공합니다.
기본적으로 데이터 준비 파일은 데이터를 문자열로 로드합니다. 파일 데이터를 준비할 때 더 구체적인 데이터 유형을 정의할 수 있습니다. - 선택사항: 고급 옵션에서 작업이 실패하기 전에 허용되는 오류 수와 같은 정보를 추가할 수 있습니다. Gemini는 파일의 콘텐츠를 기반으로 추가 옵션을 제공합니다.
- 선택사항: 데이터 준비 편집기에서 새 스테이징 테이블을 미리 보려면 미리보기 생성을 선택합니다.
- 만들기를 클릭합니다. 파일의 데이터 준비 편집기가 열리고 데이터 탭에 데이터 미리보기와 Gemini의 초기 데이터 준비 추천이 표시됩니다.
- 선택사항: 보기를 간소화하려면 전체 화면 전체 화면을 클릭하여 전체 화면 모드를 사용 설정합니다.
선택사항: 데이터 준비 세부정보, 버전 기록을 보거나 새 댓글을 추가하거나 기존 댓글에 답글을 달려면 툴바를 사용합니다.
댓글 툴바 기능은 프리뷰 버전으로 제공됩니다. 이 기능에 대한 의견을 제공하거나 지원을 요청하려면 bqui-workspace-pod@google.com으로 이메일을 보내세요.
파일 준비
데이터 뷰에서 다음 단계에 따라 로드한 스테이징된 데이터를 준비합니다.
- 선택사항: 변환 제안의 추천 목록을 탐색하거나 열을 선택하고 열에 대한 제안을 생성하여 관련 열에 더 강력한 데이터 유형을 정의합니다.
- 선택사항: 유효성 검사 규칙을 정의합니다. 자세한 내용은 오류 테이블 구성 및 검증 규칙 추가를 참고하세요.
- 대상 테이블을 추가합니다.
- 대상 테이블에 데이터를 로드하려면 데이터 준비를 실행합니다.
- 선택사항: 데이터 준비 실행을 예약합니다.
- 선택사항: 데이터를 점진적으로 처리하여 데이터 준비 최적화
기존 데이터 준비 열기
기존 데이터 준비의 편집기를 열려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 - 왼쪽 창에서 탐색기를 클릭합니다.
- 탐색기 창에서 프로젝트 이름을 클릭한 다음 데이터 준비를 클릭합니다.
- 기존 데이터 준비를 선택합니다. 데이터 준비 파이프라인의 그래프 뷰가 표시됩니다.
- 그래프에서 노드 중 하나를 선택합니다. 테이블의 데이터 준비 편집기가 열리고 데이터 탭에 데이터 미리보기와 Gemini의 초기 데이터 준비 추천이 표시됩니다.
- 선택사항: 보기를 간소화하려면 전체 화면 전체 화면을 클릭하여 전체 화면 모드를 사용 설정합니다.
선택사항: 데이터 준비 세부정보, 버전 기록을 보거나 새 댓글을 추가하거나 기존 댓글에 답글을 달려면 툴바를 사용합니다.
댓글 툴바 기능은 프리뷰 버전으로 제공됩니다. 이 기능에 대한 의견을 제공하거나 지원을 요청하려면 bqui-workspace-pod@google.com으로 이메일을 보내세요.
데이터 준비 단계 추가
단계별로 데이터를 준비합니다. Gemini에서 추천하는 단계를 미리 보거나 적용할 수 있습니다. 추천을 개선하거나 자체 단계를 적용할 수도 있습니다.
Gemini의 추천 적용 및 개선
테이블의 데이터 준비 편집기를 열면 Gemini가 로드된 표의 데이터와 스키마를 검사하고 필터 및 변환 추천을 생성합니다. 추천은 단계 목록의 카드에 표시됩니다.
다음 이미지는 Gemini에서 추천하는 단계를 적용하고 개선할 수 있는 위치를 보여줍니다.
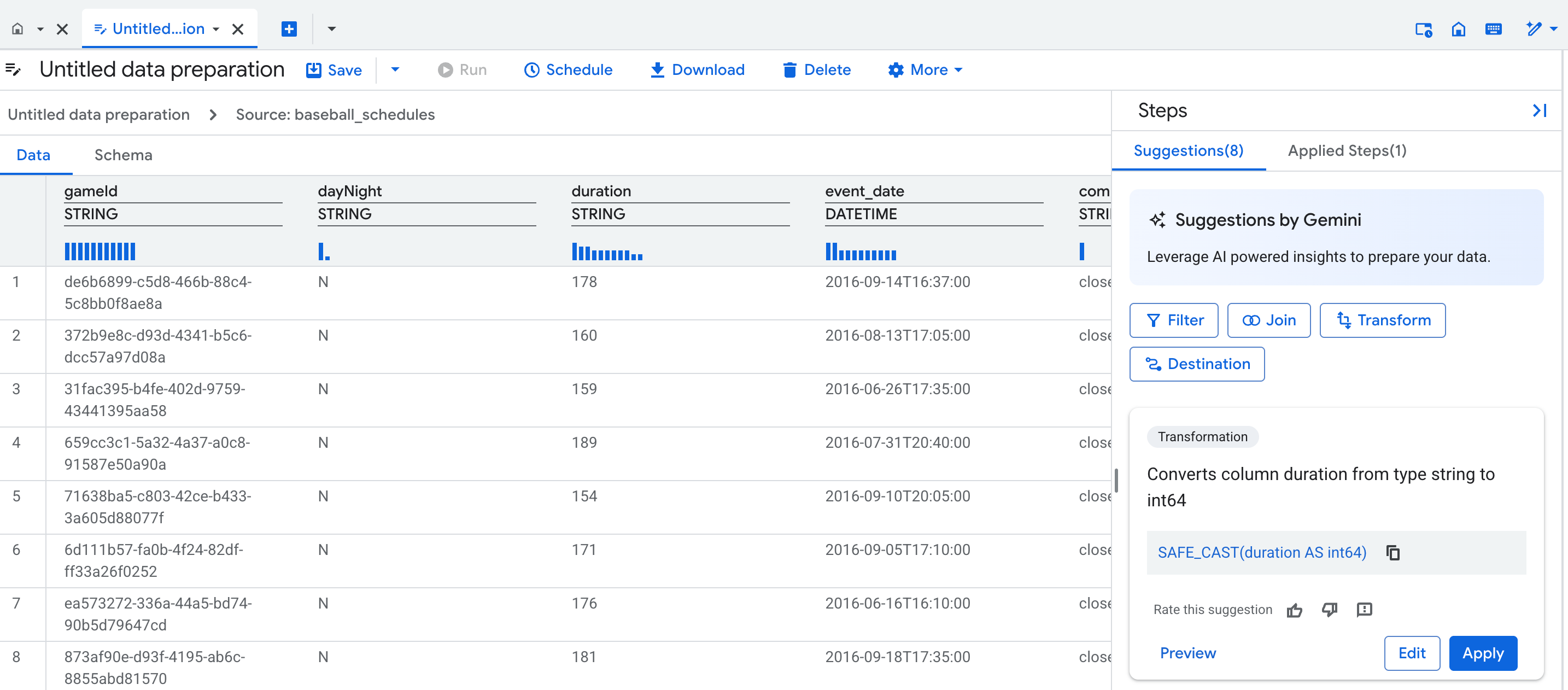
Gemini의 추천을 데이터 준비 단계로 적용하려면 다음 안내를 따르세요.
- 데이터 뷰에서 열 이름 또는 특정 셀을 클릭합니다. Gemini는 데이터를 필터링하고 변환하는 방법을 추천합니다.
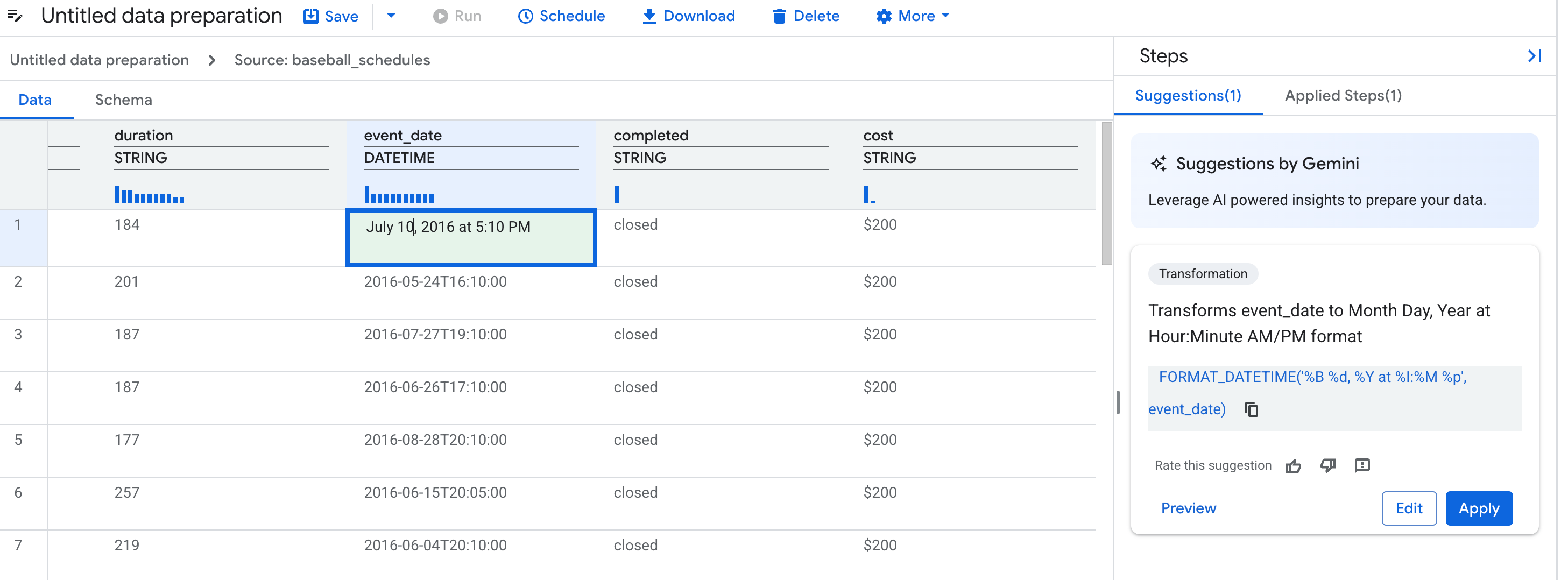
선택사항: 추천을 개선하려면 테이블에서 1~3개 셀의 값을 수정하여 열의 값이 어떻게 표시되어야 하는지 보여줍니다. 예를 들어 모든 날짜의 형식을 지정할 방식으로 날짜를 입력합니다. Gemini가 변경사항을 기반으로 새로운 추천을 생성합니다.
다음 이미지는 값을 수정하여 Gemini에서 추천하는 단계를 개선하는 방법을 보여줍니다.
추천 카드를 선택합니다.
- 선택사항: 추천 카드의 결과를 미리 보려면 미리보기를 클릭합니다.
- 선택사항: 자연어를 사용하여 추천 카드를 수정하려면 수정을 클릭합니다.
적용을 클릭합니다.
자연어 또는 SQL 표현식으로 단계 추가
기존 추천이 요구사항을 충족하지 않으면 단계를 추가합니다. 열 또는 단계 유형을 선택한 다음 자연어를 사용하여 원하는 작업을 설명합니다.
변환 추가
- 데이터 또는 스키마 뷰에서 변환 옵션을 선택합니다. Gemini가 데이터 변환을 이해할 수 있도록 열을 선택하거나 예를 추가할 수도 있습니다.
- 설명 필드에
Convert the state column to uppercase과 같은 프롬프트를 입력합니다. 보내기 보내기를 클릭합니다.
Gemini가 프롬프트를 기반으로 SQL 표현식과 새 설명을 생성합니다.
대상 열 목록에서 열 이름을 선택하거나 입력합니다.
선택사항: SQL 표현식을 업데이트하려면 프롬프트를 수정한 후 보내기 보내기를 클릭하거나 SQL 표현식을 직접 입력합니다.
선택사항: 미리보기를 클릭하고 단계를 검토합니다.
적용을 클릭합니다.
JSON 열 평탄화
키-값 쌍을 더 쉽게 액세스하고 분석하려면 JSON 열을 평면화하세요. 예를 들어 country 및 device_type 키가 포함된 user_properties라는 JSON 열이 있는 경우 이 열을 평면화하면 country 및 device_type가 자체 최상위 열로 추출되므로 분석에서 직접 사용할 수 있습니다.
BigQuery의 Gemini는 JSON의 최상위 수준에서만 필드를 추출하는 작업을 추천합니다. 추출된 필드에 JSON 객체가 많이 포함되어 있는 경우 추가적 단계에서 이를 평탄화하여 콘텐츠에 액세스할 수 있습니다.
- JSON 소스 테이블의 데이터 뷰에서 열 또는 셀을 선택합니다.
- 평탄화를 클릭하여 추천을 생성합니다.
- 선택사항: SQL 표현식을 업데이트하려면 SQL 표현식을 직접 입력하면 됩니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
평탄화에는 다음과 같은 동작이 있습니다.
- JSON이 포함된 셀이나 열을 선택하면 데이터 뷰에 평탄화 옵션이 표시됩니다. 단계 추가를 클릭하면 기본적으로 표시되지 않습니다.
- 선택한 행에 JSON 키가 없으면 생성된 추천에 해당 키가 포함되지 않습니다. 이러한 문제로 인해 데이터를 평탄화할 때 일부 열이 누락될 수 있습니다.
- 평탄화 중에 열 이름이 충돌하면 반복되는 열 이름이
_<i>형식으로 끝납니다. 예를 들어address라는 열이 이미 있는 경우 새로운 평탄화된 열 이름은address_1입니다. - 평탄화된 열 이름은 BigQuery 열 이름 지정 규칙을 따릅니다.
- JSON 키 필드를 비워 두면 기본 열 이름 형식은
f<i>_입니다.
RECORD 또는 STRUCT 열 평탄화
중첩된 필드에 더 쉽게 액세스하고 분석하려면 RECORD 또는 STRUCT 데이터 유형으로 열을 평면화하세요. 예를 들어 timestamp 및 action 필드가 포함된 event_log 레코드가 있는 경우 이 레코드를 평면화하면 timestamp 및 action가 자체 최상위 열로 추출되므로 직접 변환할 수 있습니다.
이 프로세스는 레코드에서 최대 10단계 깊이의 모든 중첩 열을 추출하고 각 열에 대해 새 열을 만듭니다. 새 열 이름은 상위 열의 이름과 중첩된 필드 이름을 밑줄로 구분하여 조합하여 생성됩니다(예: PARENT-COLUMN-NAME_FIELD-NAME). 원래 열은 삭제됩니다. 원본 열을 유지하려면 적용된 단계 목록에서 열 삭제 단계를 삭제하면 됩니다.
레코드를 평면화하려면 다음 단계를 따르세요.
- 소스 테이블의 데이터 뷰에서 레코드 열을 선택합니다.
- 평탄화를 클릭하여 추천을 생성합니다.
- 선택사항: SQL 표현식을 업데이트하려면 SQL 표현식을 직접 입력하면 됩니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
배열 중첩 해제
중첩 해제는 배열의 각 요소를 자체 행으로 확장하여 다른 원래 열 값을 각 새 행으로 복제합니다. 이 작업은 API 응답 목록과 같이 요소 수가 가변적인 배열이 포함된 열을 분석하는 데 유용합니다.
다음 열 유형은 중첩 해제할 수 있습니다.
ARRAY데이터 유형: 배열의 기본 유형 요소로 중첩 해제됩니다. 예를 들어ARRAY<STRUCT<...>>의 중첩 해제는STRUCT유형의 요소를 생성합니다.JSON열: 열 내의 JSON 배열을JSON유형의 요소로 중첩 해제합니다.
배열을 중첩 해제하면 중첩 해제된 요소가 포함된 새 열이 생성됩니다. 기본적으로 원래 배열 열은 삭제됩니다. 원본 열을 유지하려면 적용된 단계 목록에서 열 삭제 단계를 삭제합니다.
배열을 중첩 해제하려면 다음 단계를 따르세요.
- 소스 테이블의 데이터 뷰에서
ARRAY열을 선택합니다. - Unnest(중첩 해제)를 클릭하여 추천을 생성합니다.
- 선택사항: SQL 표현식을 업데이트하려면 SQL 표현식을 직접 입력하면 됩니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
행 필터링
행을 삭제하는 필터를 추가하려면 다음 단계를 따르세요.
- 데이터 또는 스키마 뷰에서 필터 옵션을 선택합니다. Gemini가 데이터 필터를 이해하는 데 도움이 되는 열을 선택할 수도 있습니다.
- 설명 필드에
Column ID should not be NULL과 같은 프롬프트를 입력합니다. - 생성을 클릭합니다. Gemini가 프롬프트를 기반으로 SQL 표현식과 새 설명을 생성합니다.
- 선택사항: SQL 표현식을 업데이트하려면 프롬프트를 수정한 후 보내기 보내기를 클릭하거나 SQL 표현식을 직접 입력합니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
필터 표현식 형식
필터의 SQL 표현식은 지정된 조건과 일치하는 행을 유지합니다. 이는 SELECT … WHERE SQL_EXPRESSION 문에 해당합니다.
예를 들어 year 열이 2000 이상인 레코드를 보관하려면 조건은 year >= 2000입니다.
표현식은 WHERE 절에 대한 BigQuery SQL 구문을 따라야 합니다.
데이터 중복 삭제
데이터에서 중복 행을 삭제하려면 다음 단계를 따르세요.
- 데이터 또는 스키마 뷰에서 중복 삭제 옵션을 선택합니다. Gemini가 초기 중복 제거 제안을 제공합니다.
- 선택사항: 추천을 수정하려면 새 설명을 입력하고 보내기 보내기를 클릭합니다.
- 선택사항: 중복 삭제 단계를 수동으로 구성하려면 다음 옵션을 사용하세요.
- 레코드 선택 목록에서 다음 전략 중 하나를 선택합니다.
- First: 이 전략은 중복 삭제 키 값이 동일한 각 행 그룹에 대해
ORDER BY표현식을 기반으로 첫 번째 행을 선택하고 나머지는 삭제합니다. - Last: 중복 삭제 키 값이 동일한 각 행 그룹에 대해 이 전략은
ORDER BY표현식을 기반으로 마지막 행을 선택하고 나머지는 삭제합니다. - Any: 이 전략은 중복 삭제 키 값이 동일한 각 행 그룹에서 행을 선택하고 나머지는 삭제합니다.
- Distinct: 표의 모든 열에서 중복 행을 모두 삭제합니다.
- First: 이 전략은 중복 삭제 키 값이 동일한 각 행 그룹에 대해
- 중복 삭제 키 필드에서 중복 행을 식별할 열 또는 표현식을 하나 이상 선택합니다. 이 필드는 레코드 선택 전략이 First, Last 또는 Any인 경우에 적용됩니다.
- 정렬 기준 표현식 필드에 행 순서를 정의하는 표현식을 입력합니다. 예를 들어 가장 최근 행을 선택하려면
datetime DESC를 입력합니다. 이름별로 알파벳순으로 첫 번째 행을 선택하려면last_name과 같은 열 이름을 입력합니다. 표현식은 BigQuery의 표준ORDER BY절과 동일한 규칙을 따릅니다. 이 필드는 레코드 선택 전략이 First 또는 Last인 경우에만 적용됩니다.
- 레코드 선택 목록에서 다음 전략 중 하나를 선택합니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
열 삭제
데이터 준비에서 하나 이상의 열을 삭제하려면 다음 단계를 따르세요.
- 데이터 또는 스키마 뷰에서 삭제할 열을 선택합니다.
- 삭제를 클릭합니다. 삭제된 열에 대해 새로 적용된 단계가 추가됩니다.
Gemini로 조인 작업 추가
데이터 준비에서 두 소스 간에 조인 작업 단계를 추가하려면 다음 단계를 따르세요.
- 데이터 준비의 노드에 대한 데이터 뷰에서 추천 목록으로 이동하여 조인 옵션을 클릭합니다.
- 조인 추가 대화상자에서 찾아보기를 클릭한 다음 조인 작업과 관련된 다른 테이블(조인의 오른쪽이라고 함)을 선택합니다.
- 선택사항: 실행할 조인 작업 유형(예: 내부 조인)을 선택합니다.
다음 필드에서 Gemini가 생성한 조인 키 정보를 검토합니다.
- 조인 설명: 조인 작업의 SQL 표현식에 대한 자연어 설명입니다. 이 설명을 수정하고 보내기 보내기를 클릭하면 Gemini에서 새 SQL 조인 조건을 추천합니다.
조인 조건: 조인 작업의
ON절 내 SQL 표현식입니다.L및R한정자를 사용하여 각각 왼쪽 및 오른쪽 소스 테이블을 참조할 수 있습니다. 예를 들어 왼쪽 테이블의customer_id열을 오른쪽 테이블의customer_id열에 조인하려면L.customerId = R.customerId을 입력합니다. 이러한 한정자는 대소문자를 구분하지 않습니다.
선택사항: Gemini의 추천을 수정하려면 조인 설명 필드를 수정한 다음 보내기 보내기를 클릭합니다.
선택사항: 데이터 준비의 조인 작업 설정을 미리 보려면 미리보기를 클릭합니다.
적용을 클릭합니다.
조인 작업 단계가 생성됩니다. 선택한 소스 테이블(조인의 오른쪽)과 조인 작업이 적용된 단계 목록과 데이터 준비의 그래프 뷰에 있는 노드에 반영됩니다.
데이터 집계
- 데이터 또는 스키마 뷰에서 집계 옵션을 선택합니다.
- 설명 필드에
Find the total revenue for a region과 같은 프롬프트를 입력합니다. 보내기를 클릭합니다.
Gemini가 프롬프트를 기반으로 그룹화 키와 집계 표현식을 생성합니다.
선택사항: 필요한 경우 생성된 그룹화 키 또는 집계 표현식을 수정합니다.
선택사항: 그룹화 키와 집계 표현식을 수동으로 추가할 수 있습니다.
- 그룹화 키 필드에 열 이름 또는 표현식을 입력합니다. 비워 두면 결과 테이블에 행이 하나 있습니다. 표현식을 입력하는 경우 별칭(
AS절)이 있어야 합니다(예:EXTRACT(YEAR FROM order_date) AS order_year). 중복은 허용되지 않습니다. - 집계 표현식 필드에 별칭(
AS절)이 있는 집계 표현식을 입력합니다(예:SUM(quantity) AS total_quantity). 쉼표로 구분된 여러 표현식을 입력할 수 있습니다. 중복은 허용되지 않습니다. 지원되는 집계 표현식 목록은 집계 함수를 참고하세요.
- 그룹화 키 필드에 열 이름 또는 표현식을 입력합니다. 비워 두면 결과 테이블에 행이 하나 있습니다. 표현식을 입력하는 경우 별칭(
선택사항: 미리보기를 클릭하고 단계를 검토합니다.
적용을 클릭합니다.
오류 테이블 구성 및 검증 규칙 추가
오류를 오류 테이블로 전송하거나 데이터 준비 실행을 실패시키는 검증 규칙을 만드는 필터를 추가할 수 있습니다.
오류 테이블 구성
오류 테이블을 구성하려면 다음 단계를 따르세요.
- 데이터 준비 편집기에서 툴바로 이동하여 더보기 > 오류 테이블을 클릭합니다.
- 오류 테이블 사용 설정을 클릭합니다.
- 테이블 위치를 정의합니다.
- 선택사항: 오류의 최대 보관 기간을 정의합니다.
- 저장을 클릭합니다.
검증 규칙 추가
검증 규칙을 추가하려면 다음 단계를 따르세요.
- 데이터 또는 스키마 뷰에서 필터 옵션을 클릭합니다. Gemini가 데이터 필터를 이해하는 데 도움이 되는 열을 선택할 수도 있습니다.
- 단계에 대한 설명을 입력합니다.
WHERE절의 형태로 SQL 표현식을 입력합니다.- 선택사항: SQL 표현식이 검증 규칙으로 작동하도록 하려면 검증 실패 행이 오류 테이블로 이동 체크박스를 선택합니다. 데이터 준비 툴바에서 더보기 > 오류 테이블을 클릭하여 필터를 검증으로 변경할 수도 있습니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
대상 테이블 추가 또는 변경
데이터 준비를 실행하거나 예약하려면 대상 테이블이 필요합니다. 데이터 준비 출력의 대상 테이블을 추가하거나 변경하려면 다음 단계를 따르세요.
- 데이터 또는 스키마 뷰의 추천 목록에서 대상을 클릭합니다.
- 대상 테이블이 저장된 프로젝트를 선택합니다.
- 데이터 세트 중 하나를 선택하거나 새 데이터 세트를 로드합니다.
- 대상 테이블을 입력합니다. 테이블이 없으면 데이터 준비 단계에서 첫 번째 실행 시 새 테이블을 만듭니다. 자세한 내용은 쓰기 모드를 참조하세요.
- 데이터 세트를 대상 데이터 세트로 선택합니다.
- 저장을 클릭합니다.
적용된 단계의 데이터 샘플 및 스키마 보기
데이터 준비의 특정 단계에서 샘플 및 스키마 세부정보를 보려면 다음 단계를 따르세요.
- 데이터 준비 편집기에서 단계 목록으로 이동하여 적용된 단계를 클릭합니다.
- 단계를 선택합니다. 데이터 및 스키마 탭이 표시되며 이 특정 단계의 데이터 샘플과 스키마가 표시됩니다.
적용된 단계 수정
적용된 단계를 수정하려면 다음 단계를 따르세요.
- 데이터 준비 편집기에서 단계 목록으로 이동하여 적용된 단계를 클릭합니다.
- 단계를 선택합니다.
- 단계 옆에 있는 more_vert 메뉴 > 수정을 클릭합니다.
- 적용된 단계 수정 대화상자에서 다음을 수행할 수 있습니다.
- 단계의 설명을 수정합니다.
- 설명을 수정하고 send 보내기를 클릭하여 Gemini의 추천을 받습니다.
- SQL 표현식을 수정합니다.
- 대상 열 필드에서 열을 선택합니다.
- 선택사항: 미리보기를 클릭하고 단계를 검토합니다.
- 적용을 클릭합니다.
적용된 단계 삭제
적용된 단계를 삭제하려면 다음 단계를 따르세요.
- 데이터 준비 편집기에서 단계 목록으로 이동하여 적용된 단계를 클릭합니다.
- 단계를 선택합니다.
- more_vert 메뉴 > 삭제를 클릭합니다.
데이터 준비 실행
데이터 준비 단계를 추가하고 대상을 구성하고 검증 오류를 수정한 후에는 데이터 샘플에서 테스트 실행을 수행하거나 단계를 배포하고 데이터 준비 실행을 예약할 수 있습니다. 자세한 내용은 데이터 준비 예약을 참조하세요.
데이터 준비 샘플 새로고침
샘플의 데이터는 자동으로 새로고침되지 않습니다. 데이터 준비의 소스 테이블 데이터가 변경되었지만 변경사항이 준비의 데이터 샘플에 반영되지 않은 경우 더보기 > 샘플 새로고침을 클릭합니다.
다음 단계
- 데이터 준비를 예약하는 방법 알아보기
- 데이터 준비 관리 알아보기
- BigQuery의 Gemini 가격 책정을 검토하세요.