
מה זה BI Engine?
BigQuery BI Engine הוא שירות ניתוח מהיר בזיכרון שמאפשר להריץ במהירות שאילתות SQL רבות ב-BigQuery, באמצעות שמירת הנתונים שבהם אתם משתמשים הכי הרבה במטמון בצורה חכמה. BI Engine יכול להאיץ שאילתות SQL מכל מקור, כולל שאילתות שנכתבו על ידי כלי ויזואליזציה של נתונים, ויכול לנהל טבלאות שנשמרו במטמון לצורך אופטימיזציה שוטפת. כך אפשר לשפר את ביצועי השאילתות בלי לבצע כוונון ידני או חלוקה לשכבות של נתונים. אתם יכולים להשתמש בקיבוץ לאשכולות ובחלוקה למחיצות כדי לבצע אופטימיזציה נוספת של הביצועים של טבלאות גדולות באמצעות BI Engine.
לדוגמה, אם בלוח הבקרה מוצגים רק הנתונים מהרבעון האחרון, כדאי לחלק את הטבלאות לפי זמן כדי שרק המחיצות האחרונות ייטענו לזיכרון. אפשר גם לשלב את היתרונות של תצוגות חומריות ושל BI Engine. השיטה הזו יעילה במיוחד כשמשתמשים בתצוגות חומריות כדי לבצע צירוף ושיטוח של נתונים, במטרה לבצע אופטימיזציה של המבנה שלהם ל-BI Engine.
היתרונות של BI Engine:
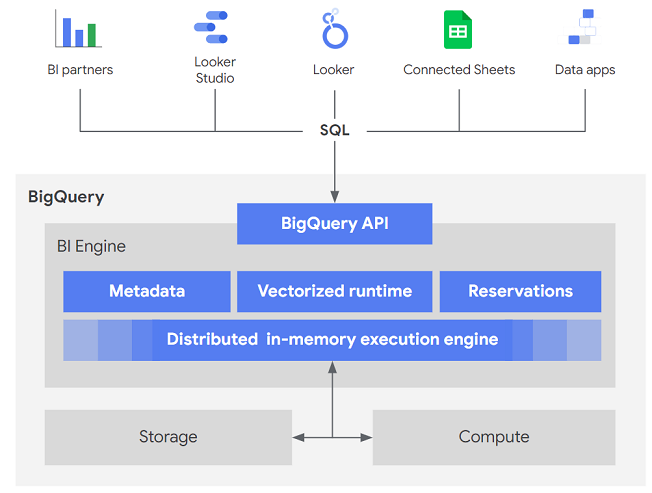
- BigQuery API: BI Engine משתלב ישירות עם BigQuery API. כל פתרון BI או אפליקציה בהתאמה אישית שפועלים עם BigQuery API באמצעות מנגנונים סטנדרטיים כמו REST או מנהלי התקנים של JDBC ו-ODBC יכולים להשתמש ב-BI Engine ללא שינוי.
- זמן ריצה וקטורי: באמצעות BI Engine, BigQuery משתמש בטכניקה מודרנית שנקראת עיבוד וקטורי. שימוש בעיבוד וקטורי במנוע הרצה מאפשר שימוש יעיל יותר בארכיטקטורת מעבד (CPU) מודרנית, על ידי פעולה על אצוות של נתונים בכל פעם. בנוסף, BI Engine משתמש בקידודים מתקדמים של נתונים, במיוחד בקידוד מילוני ובקידוד אורך רצף, כדי לדחוס עוד יותר את הנתונים שמאוחסנים בשכבת הזיכרון.
- שילוב חלק: BI Engine פועל עם תכונות ומטא-נתונים של BigQuery, כולל תצוגות מורשות, אבטחה ברמת העמודה והשורה והסתרת נתונים.
- הזמנות: הזמנות של BI Engine מנהלות הקצאת זיכרון ברמת מיקום הפרויקט. BI Engine שומר במטמון עמודות או מחיצות ספציפיות שנשלחו לגביהן שאילתות, ומעניק עדיפות לאלה שנמצאות בטבלאות שמסומנות כמועדפות.
הארכיטקטורה של BI Engine
BI Engine משתלב עם כל כלי בינה עסקית (BI), כולל Looker, Tableau, Power BI ואפליקציות בהתאמה אישית, כדי להאיץ את חיפוש הנתונים והניתוח שלהם.
תרחישי שימוש ב-BI Engine
BI Engine יכול להאיץ באופן משמעותי הרבה שאילתות SQL, כולל אלה שמשמשות ללוחות בקרה של BI. ההאצה הכי יעילה אם מזהים את הטבלאות שחיוניות לשאילתות ומסמנים אותן כטבלאות מועדפות. כדי להשתמש ב-BI Engine, צריך ליצור הזמנה שמגדירה את קיבולת האחסון שמוקדשת ל-BI Engine. אתם יכולים לאפשר ל-BigQuery לקבוע אילו טבלאות יישמרו במטמון על סמך דפוסי השימוש בפרויקט, או לסמן טבלאות ספציפיות כדי למנוע מתנועה אחרת להפריע להאצה.
BI Engine שימושי בתרחישי השימוש הבאים:
- אתם משתמשים בכלים של BI כדי לנתח את הנתונים: BI Engine יכול להאיץ שאילתות של BigQuery, בלי קשר למקום שבו הן מופעלות – במסוף של BigQuery, בספריית לקוח או דרך API או מחבר ODBC או JDBC. האפשרות הזו יכולה לשפר משמעותית את הביצועים של לוחות בקרה שמחוברים ל-BigQuery דרך חיבור מובנה (API) או מחברים.
- יש לכם טבלאות מסוימות שמתבצעות לגביהן שאילתות בתדירות הגבוהה ביותר: BI Engine מאפשר לכם להגדיר טבלאות מועדפות ספציפיות כדי להאיץ את הביצועים. האפשרות הזו שימושית אם יש לכם קבוצת משנה של טבלאות שמתבצעות לגביהן שאילתות בתדירות גבוהה יותר, או שהן משמשות למרכזי בקרה עם נראות גבוהה.
יכול להיות ש-BI Engine לא יתאים לצרכים שלכם במקרים הבאים:
אתם משתמשים בתווים כלליים לחיפוש בשאילתות: שאילתות שמפנות לטבלאות תווים כלליים לחיפוש לא נתמכות על ידי BI Engine ולא נהנות מהאצה.
אתם מסתמכים במידה רבה על תכונות של BigQuery שלא נתמכות: למרות ש-BI Engine תומך ברוב הפונקציות והאופרטורים של SQL כשמחברים כלי בינה עסקית (BI) ל-BigQuery, יש תכונות שלא נתמכות, כולל טבלאות חיצוניות ופונקציות מוגדרות על ידי המשתמש שאינן SQL.
שיקולים לגבי BI Engine
כשמחליטים איך להגדיר את BI Engine, כדאי להביא בחשבון את הנקודות הבאות:
איך מוודאים שההאצה תפעל בשאילתות ספציפיות
כדי לוודא שקבוצה מסוימת של שאילתות תמיד תואץ, אפשר ליצור פרויקט נפרד עם הזמנה של BI Engine. כדי לעשות זאת, צריך לוודא שההקצאה של BI Engine בפרויקט הזה גדולה מספיק כדי להתאים לגודל של כל הטבלאות שמשמשות בשאילתות האלה, ולהגדיר את הטבלאות האלה כטבלאות מועדפות ל-BI Engine. צריך להריץ בפרויקט הזה רק את השאילתות שצריך להאיץ.
מצמצמים את מספר שאילתות ה-join
BI Engine פועל בצורה הטובה ביותר עם נתונים שצורפו או צורפו מראש, ועם נתונים במספר קטן של צירופים. זה נכון במיוחד כשצד אחד של הצירוף גדול והצדדים האחרים קטנים בהרבה, למשל כשמפעילים שאילתה על טבלת עובדות גדולה שמצורפת לטבלת מימדים קטנה. אפשר לשלב את BI Engine עם תצוגות חומריות שמבצעות הצטרפויות כדי ליצור טבלה גדולה ושטוחה אחת. כך, לא צריך לבצע את אותם צירופים בכל שאילתה.
הסבר על ההשפעה של BI Engine
כדי להבין טוב יותר איך עומסי העבודה שלכם נהנים מ-BI Engine, אתם יכולים לעיין בנתוני השימוש ב-Cloud Monitoring או להריץ שאילתה ב-INFORMATION_SCHEMA ב-BigQuery. כדי לקבל השוואה מדויקת ככל האפשר, חשוב להשבית את האפשרות Use cached results ב-BigQuery. מידע נוסף זמין במאמר שימוש בתוצאות של שאילתות שנשמרו במטמון.
מגבלות
שאילתות שמכילות את הפונקציה VECTOR_SEARCH לא מואצות על ידי BigQuery BI Engine.
מכסות ומגבלות
במאמר מכסות ומגבלות ב-BigQuery מפורטות המכסות והמגבלות שחלות על BI Engine.
תמחור
מידע על התמחור של BI Engine זמין בדף תמחור ב-BigQuery.
אופטימיזציה והאצה של שאילתות
BigQuery, ובהרחבה BI Engine, מפרק את תוכנית השאילתה שנוצרת עבור שאילתת SQL לשאילתות משנה. שאילתת משנה מכילה מספר פעולות, כמו סריקה, סינון או צבירה של נתונים, ולרוב היא יחידת הביצוע בשבר.
כל שאילתות ה-SQL הנתמכות ב-BigQuery מופעלות בצורה תקינה על ידי BI Engine, אבל רק שאילתות משנה מסוימות עוברות אופטימיזציה. בפרט, BI Engine מותאם במיוחד לשאילתות משנה ברמת העלה שסורקות את הנתונים מהאחסון ומבצעות פעולות כמו סינון, חישוב, צבירה, מיון לפי סדר וסוגים מסוימים של צירופים. שאילתות משנה אחרות שלא מואצות באופן מלא על ידי BI Engine חוזרות ל-BigQuery לצורך ביצוע.
בגלל האופטימיזציה הסלקטיבית הזו, שאילתות פשוטות של בינה עסקית או שאילתות מסוג לוח בקרה מפיקות את התועלת הגדולה ביותר מ-BI Engine (כי הן מניבות פחות שאילתות משנה), כי רוב זמן הביצוע מושקע בשאילתות משנה ברמת העלה שמבצעות עיבוד של נתונים גולמיים.
המאמרים הבאים
- מידע על פונקציות שעברו אופטימיזציה ל-BI Engine
- במאמר שמירת קיבולת ב-BI Engine מוסבר איך ליצור הזמנה ב-BI Engine.
- מידע על הגדרת טבלאות מועדפות זמין במאמר טבלאות מועדפות ב-BI Engine.
- כדי להבין את השימוש ב-BI Engine, אפשר לעיין במאמר מעקב אחרי BI Engine באמצעות Cloud Monitoring.