
שיטות מומלצות לניתוח מרחבי
במסמך הזה מפורטות שיטות מומלצות לאופטימיזציה של ביצועי שאילתות גיאוגרפיות ב-BigQuery. אפשר להשתמש בשיטות המומלצות האלה כדי לשפר את הביצועים, לצמצם את העלויות ולקצר את זמני האחזור.
מערכי נתונים יכולים להכיל אוספים גדולים של פוליגונים, צורות מרובות פוליגונים וקווים כדי לייצג ישויות מורכבות – לדוגמה, כבישים, מגרשים ואזורים מוצפים. כל צורה יכולה להכיל אלפי נקודות. ברוב הפעולות המרחביות ב-BigQuery (לדוגמה, חישובים של נקודות מפגש ומרחקים), האלגוריתם הבסיסי בדרך כלל בודק את רוב הנקודות בכל צורה כדי להפיק תוצאה. בפעולות מסוימות, האלגוריתם מבקר בכל הנקודות. בצורות מורכבות, ביקור בכל נקודה יכול להגדיל את העלות ואת משך הפעולות המרחביות. אפשר להשתמש באסטרטגיות ובשיטות שמוצגות במדריך הזה כדי לבצע אופטימיזציה של הפעולות המרחביות הנפוצות האלה, לשפר את הביצועים ולהפחית את העלויות.
במאמר הזה אנחנו מניחים שהטבלאות הגיאו-מרחביות שלכם ב-BigQuery מרוכזות בעמודת מיקום גיאוגרפי.
פישוט צורות
שיטה מומלצת: משתמשים בפונקציות simplify ו-snap-to-grid כדי לאחסן גרסה פשוטה של מערך הנתונים המקורי כתצוגה חומרית.
אפשר לפשט צורות מורכבות רבות עם מספר גדול של נקודות בלי לאבד הרבה מהדיוק. כדי לצמצם את מספר הנקודות בצורות מורכבות, אפשר להשתמש בפונקציות BigQuery ST_SIMPLIFY ו-ST_SNAPTOGRID בנפרד או ביחד.
אפשר לשלב את הפונקציות האלה עם תצוגות חומריות של BigQuery כדי לשמור גרסה פשוטה של מערך הנתונים המקורי כתצוגה חומרית שמתעדכנת אוטומטית בהשוואה לטבלת הבסיס.
פישוט צורות שימושי במיוחד לשיפור העלות והביצועים של מערך נתונים בתרחישי השימוש הבאים:
- צריך לשמור על מידה גבוהה של דמיון לצורה האמיתית.
- אתם צריכים לבצע פעולות ברמת דיוק גבוהה.
- אתם רוצים להאיץ את ההמחשות בלי לאבד פרטים בצורה.
בדוגמת הקוד הבאה אפשר לראות איך משתמשים בפונקציה ST_SIMPLIFY בטבלת בסיס שיש בה עמודה GEOGRAPHY בשם geom. הקוד מפשט צורות ומסיר נקודות בלי לשנות אף קצה של צורה ביותר מהסבילות שצוינה של 1.0 מטר.
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SIMPLIFY(geom, 1.0) AS geom
FROM base_table
)
בדוגמת הקוד הבאה אפשר לראות איך משתמשים בפונקציה ST_SNAPTOGRID כדי להצמיד את הנקודות לרשת ברזולוציה של 0.00001 מעלות:
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SNAPTOGRID(geom, -5) AS geom
FROM base_table
)
הארגומנט grid_size בפונקציה הזו משמש כמעריך, כלומר 10e-5 = 0.00001. הרזולוציה הזו שווה בערך למטר אחד במקרה הגרוע ביותר, שמתרחש בקו המשווה.
אחרי שיוצרים את התצוגות האלה, מריצים שאילתה על התצוגה base_mv באמצעות אותה סמנטיקה של שאילתות שבה משתמשים כדי להריץ שאילתה על טבלת הבסיס. אתם יכולים להשתמש בטכניקה הזו כדי לזהות במהירות אוסף של צורות שצריך לנתח לעומק, ואז לבצע ניתוח שני מעמיק יותר בטבלת הבסיס. כדאי לבדוק את השאילתות כדי לראות אילו ערכי סף מתאימים לנתונים שלכם.
בתרחישי שימוש למדידה, צריך לקבוע את רמת הדיוק שנדרשת בתרחיש השימוש. כשמשתמשים בפונקציה ST_SIMPLIFY, צריך להגדיר את הפרמטר threshold_meters לרמת הדיוק הנדרשת. כדי למדוד מרחקים בקנה מידה של עיר או גדול יותר, מגדירים סף של 10 מטרים. במקרים של קנה מידה קטן יותר – למשל, כשמודדים את המרחק בין בניין למקור המים הקרוב ביותר – כדאי להשתמש בסף קטן יותר של מטר אחד או פחות. שימוש בערכי סף קטנים יותר מוביל להסרה של פחות נקודות מהצורה הנתונה.
כשמציגים שכבות של מפות משירות אינטרנט, אפשר לחשב מראש תצוגות חומריות לרמות זום שונות באמצעות פרויקט bigquery-geotools, שהוא דרייבר ל-Geoserver שמאפשר להציג שכבות מרחביות מ-BigQuery. הדרייבר הזה יוצר כמה תצוגות חומריות עם פרמטרים שונים של סף ST_SIMPLIFY, כך שרמות פירוט נמוכות יותר מוצגות ברמות זום גבוהות יותר.
שימוש בנקודות ובמלבנים
שיטה מומלצת: כדאי לצמצם את הצורה לנקודה או למלבן כדי לייצג את המיקום שלה.
כדי לשפר את הביצועים של השאילתה, אפשר לצמצם את הצורה לנקודה אחת או למלבן. השיטות שמוסברות בקטע הזה לא מייצגות בצורה מדויקת את הפרטים והפרופורציות של הצורה, אלא מותאמות לייצוג המיקום של הצורה.
אתם יכולים להשתמש בנקודה המרכזית הגיאוגרפית של צורה (הצנטרואיד שלה) כדי לייצג את המיקום של הצורה כולה. כדי ליצור את הגבולות של הצורה, אפשר להשתמש במלבן שמכיל את הצורה. הגבולות האלה יכולים לייצג את המיקום של הצורה ולשמור מידע על הגודל היחסי שלה.
השימוש בנקודות ובמלבנים הכי מועיל לשיפור העלות והביצועים של מערך נתונים כשצריך למדוד את המרחק בין שתי נקודות, למשל בין שתי ערים.
לדוגמה, נניח שאתם רוצים לטעון מסד נתונים של חלקות אדמה בארצות הברית לטבלה ב-BigQuery, ואז לקבוע מהו מקור המים הקרוב ביותר.
במקרה כזה, חישוב מראש של מרכזי מגרשים באמצעות הפונקציה ST_CENTROID בשילוב עם השיטה שמתוארת בקטע פשוט צורות במסמך הזה יכול לצמצם את מספר ההשוואות שמבוצעות כשמשתמשים בפונקציות ST_DISTANCE או ST_DWITHIN. כשמשתמשים בפונקציה ST_CENTROID, צריך לקחת בחשבון את מרכז המסה של החבילה בחישוב. חישוב מראש של מרכזי החבילות בדרך הזו יכול גם לצמצם את השונות בביצועים, כי סביר להניח שצורות שונות של חבילות יכילו מספרים שונים של נקודות.
אפשרות נוספת היא להשתמש בפונקציה ST_BOUNDINGBOX במקום בפונקציה ST_CENTROID כדי לחשב מעטפת מלבנית סביב צורת הקלט. השיטה הזו לא יעילה כמו שימוש בנקודה אחת, אבל היא יכולה לצמצם את המקרים של תרחישי קצה מסוימים. הווריאציה הזו עדיין מציעה ביצועים טובים ועקביים, כי הפלט של הפונקציה ST_BOUNDINGBOX תמיד מכיל רק ארבע נקודות שצריך להתייחס אליהן. התוצאה של תיבת התוחמת תהיה מהסוג STRUCT, כלומר תצטרכו לחשב את המרחקים באופן ידני או להשתמש בשיטה של אינדקס וקטורי שמתוארת בהמשך המסמך הזה.
שימוש במעטפות
שיטה מומלצת: כדי לייצג את המיקום של צורה, מומלץ להשתמש ב-Hull כדי לבצע אופטימיזציה.
אם מדמיינים עטיפת צורה בניילון נצמד וחישוב של גבול העטיפה, הגבול הזה נקרא מעטפת קמורה. במעטפת קמורה, כל הזוויות של הצורה שמתקבלת הן קמורות. בדומה למידת ההתפשטות של צורה, הקמור מכיל מידע מסוים על הגודל והפרופורציות היחסיים של הצורה הבסיסית. עם זאת, השימוש במעטפת כרוך בעלות של אחסון ושימוש ביותר נקודות בניתוחים הבאים.
אפשר להשתמש בפונקציה ST_CONVEXHULL כדי לבצע אופטימיזציה של ייצוג המיקום של הצורה. השימוש בפונקציה הזו משפר את הדיוק, אבל פוגע בביצועים. הפונקציה ST_CONVEXHULL דומה לפונקציה ST_EXTENT, אבל צורת הפלט מכילה יותר נקודות ומספר הנקודות משתנה בהתאם למורכבות של צורת הקלט. במערכי נתונים קטנים עם צורות לא מורכבות, שיפור הביצועים יהיה כנראה זניח. אבל במערכי נתונים גדולים מאוד עם צורות גדולות ומורכבות, הפונקציה ST_CONVEXHULL מציעה איזון טוב בין עלות, ביצועים ודיוק.
שימוש במערכות רשת
שיטה מומלצת: השתמשו במערכות רשת גיאוספציאליות כדי להשוות בין אזורים.
אם בתרחישי השימוש שלכם נדרש צבירה של נתונים באזורים מקומיים והשוואה בין צבירות סטטיסטיות של האזורים האלה, כדאי להשתמש במערכת רשת סטנדרטית כדי להשוות בין אזורים שונים.
לדוגמה, קמעונאי יכול לרצות לנתח שינויים דמוגרפיים לאורך זמן באזורים שבהם ממוקמות החנויות שלו או באזורים שבהם הוא שוקל לבנות חנות חדשה. לחלופין, חברת ביטוח יכולה לרצות לשפר את ההבנה שלה לגבי סיכונים לנכסים על ידי ניתוח הסיכונים השכיחים של מפגעים טבעיים באזור מסוים.
שימוש במערכות רשת סטנדרטיות כמו S2 ו-H3 יכול לזרז את הצבירה הסטטיסטית והניתוחים המרחביים. שימוש במערכות רשת כאלה יכול גם לפשט את פיתוח הניתוחים ולשפר את יעילות הפיתוח.
לדוגמה, השוואות באמצעות אזורי מפקד אוכלוסין בארצות הברית סובלות מחוסר עקביות בגודל, ולכן צריך להחיל גורמי תיקון כדי לבצע השוואות בין אזורי מפקד אוכלוסין. בנוסף, מפקדי אוכלוסין וגבולות אדמיניסטרטיביים אחרים משתנים לאורך זמן, ונדרש מאמץ כדי לתקן את השינויים האלה. שימוש במערכות רשת לניתוח מרחבי יכול לעזור להתמודד עם אתגרים כאלה.
שימוש בחיפוש וקטורים ובאינדקסים של וקטורים
שיטה מומלצת: כדאי להשתמש בחיפוש וקטורי ובאינדקסים וקטוריים לשאילתות גיאוגרפיות של השכן הקרוב ביותר.
הוספנו ל-BigQuery יכולות של חיפוש וקטורי כדי לאפשר תרחישי שימוש בלמידת מכונה, כמו חיפוש סמנטי, זיהוי דמיון ו-Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). השיטה שמאפשרת את תרחישי השימוש האלה היא שיטת אינדוקס שנקראת חיפוש של השכן הקרוב המשוער. אתם יכולים להשתמש בחיפוש וקטורים כדי להשוות וקטורים שמייצגים נקודות במרחב, וכך להאיץ ולפשט שאילתות גיאו-מרחביות של השכן הקרוב ביותר.
אפשר להשתמש בחיפוש וקטורי כדי לחפש תכונות לפי רדיוס. קודם כול, מגדירים את הרדיוס של החיפוש. אפשר לגלות את הרדיוס האופטימלי בסט התוצאות של חיפוש השכן הקרוב ביותר. אחרי שמגדירים את הרדיוס, משתמשים בפונקציה ST_DWITHIN כדי לזהות תכונות בקרבת מקום.
לדוגמה, נניח שאתם רוצים למצוא את עשרת הבניינים הכי קרובים לבניין עוגן מסוים שכבר יש לכם את המיקום שלו. אפשר לאחסן את מרכזי הכובד של כל בניין כווקטור בטבלה חדשה, ליצור אינדקס לטבלה ולחפש באמצעות חיפוש וקטורי.
בדוגמה הזו, אפשר גם להשתמש בנתוני Overture Maps ב-BigQuery כדי ליצור טבלה נפרדת של צורות בניינים שמתאימות לאזור עניין ולווקטור שנקרא geom_vector. אזור העניין בדוגמה הזו הוא העיר נורפוק שבווירג'יניה, ארה"ב, שמיוצגת על ידי קוד FIPS 51710, כמו שמוצג בדוגמת הקוד הבאה:
CREATE TABLE vector_search.norfolk_buildings
AS (
SELECT
*,
[
ST_X(ST_CENTROID(building.geometry)),
ST_Y(ST_CENTROID(building.geometry))] AS geom_vector
FROM `bigquery-public-data.overture_maps.building` AS building
INNER JOIN `bigquery-public-data.geo_us_boundaries.counties` AS county
ON (st_intersects(county.county_geom, building.geometry))
WHERE county.county_fips_code = '51710'
)
דוגמת הקוד הבאה מראה איך יוצרים אינדקס וקטורי בטבלה:
CREATE
vector index building_vector_index
ON
vector_search.norfolk_buildings(geom_vector)
OPTIONS (index_type = 'IVF')
השאילתה הזו מזהה את 10 המבנים הקרובים ביותר למבנה עוגן מסוים:
SELECT base.*
FROM
VECTOR_SEARCH(
TABLE vector_search.norfolk_buildings,
'geom_vector',
(
SELECT
geom_vector
FROM
vector_search.norfolk_buildings
WHERE id = '56873794-9873-4fe1-871a-5987bb3a0efb'
),
top_k => 10,
distance_type => 'EUCLIDEAN',
options => '{"fraction_lists_to_search":0.1}')
בחלונית Query results, לוחצים על הכרטיסייה Visualization. במפה מוצג אוסף של צורות בניינים שהכי קרובים לבניין העוגן:
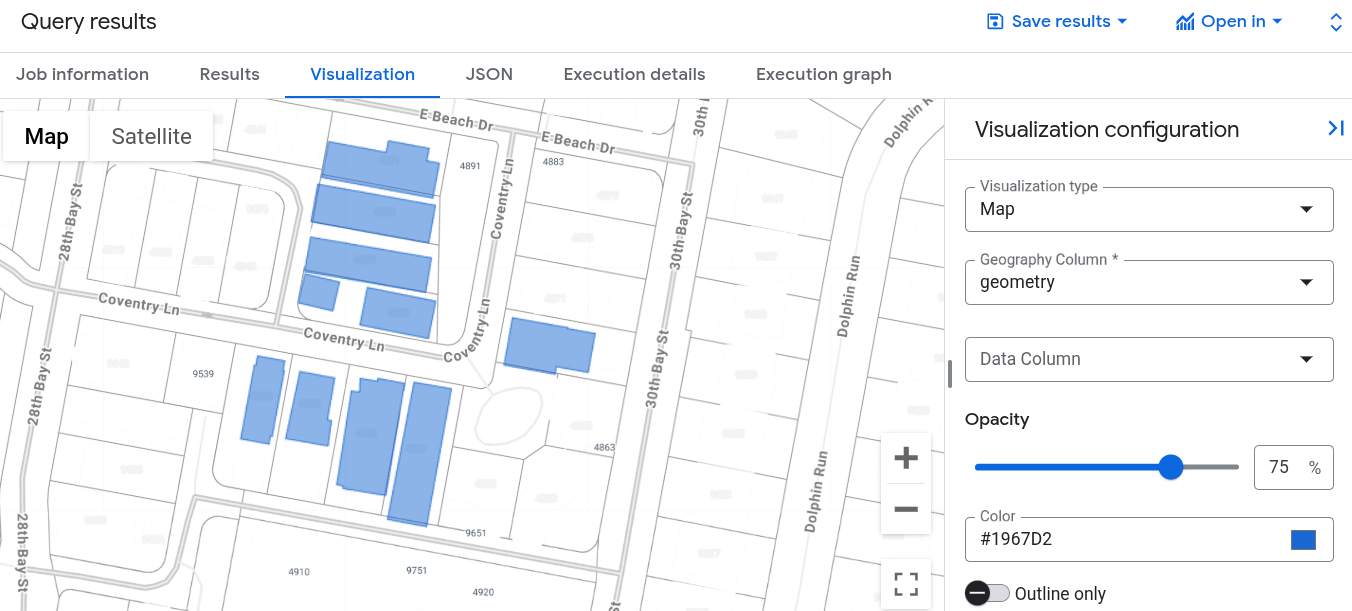
כשמריצים את השאילתה הזו ב Google Cloud מסוף, לוחצים על Job Information ומוודאים שVector Index Usage Mode מוגדר ל-FULLY_USED. המשמעות היא שהשאילתה משתמשת באינדקס הווקטורי building_vector_index שיצרתם קודם.
חלוקת צורות גדולות
שיטה מומלצת: מחלקים צורות גדולות באמצעות הפונקציה ST_SUBDIVIDE.
אפשר להשתמש בפונקציה ST_SUBDIVIDE כדי לפצל צורות גדולות או מחרוזות ארוכות של קווים לצורות קטנות יותר.
המאמרים הבאים
- איך משתמשים במערכות רשת לניתוח מרחבי
- מידע נוסף על פונקציות גיאוגרפיות ב-BigQuery
- איך מנהלים אינדקסים של וקטורים
- מידע נוסף על שיטות מומלצות לאינדוקס מרחבי ולאשכול ב-BigQuery
- במאמר איך מתחילים לעבוד עם ניתוח נתונים גיאו-מרחביים אפשר לקרוא מידע נוסף על ניתוח נתונים גיאו-מרחביים והצגתם ב-BigQuery.