
Tutorial ini mengajarkan cara menggunakan model deret waktu multivariat untuk memperkirakan nilai mendatang untuk kolom tertentu, berdasarkan nilai historis beberapa fitur input.
Tutorial ini memperkirakan deret waktu tunggal. Nilai yang diperkirakan dihitung satu kali untuk setiap titik waktu dalam data input.
Tutorial ini menggunakan data dari
set data publik bigquery-public-data.epa_historical_air_quality. Set data ini berisi informasi tentang materi partikulat (PM2.5) harian, suhu, dan kecepatan angin yang dikumpulkan dari beberapa kota di AS.
Tujuan
Tutorial ini memandu Anda menyelesaikan tugas-tugas berikut:
- Membuat model deret waktu untuk memperkirakan nilai PM2.5 menggunakan
pernyataan
CREATE MODEL. - Mengevaluasi informasi autoregressive integrated moving average (ARIMA) dalam model menggunakan
fungsi
ML.ARIMA_EVALUATE. - Memeriksa koefisien model menggunakan
fungsi
ML.ARIMA_COEFFICIENTS. - Mengambil nilai PM2.5 yang diperkirakan dari model menggunakan
fungsi
ML.FORECAST. - Mengevaluasi akurasi model menggunakan
fungsi
ML.EVALUATE. - Mengambil komponen deret waktu, seperti tren musiman, tren, dan
atribusi fitur, menggunakan
fungsi
ML.EXPLAIN_FORECAST. Anda dapat memeriksa komponen deret waktu ini untuk menjelaskan nilai yang diperkirakan.
Biaya
Tutorial ini menggunakan komponen Google Cloudyang dapat ditagih, termasuk:
- BigQuery
- BigQuery ML
Untuk informasi selengkapnya tentang biaya BigQuery, lihat halaman harga BigQuery.
Untuk informasi selengkapnya tentang biaya BigQuery ML, lihat harga BigQuery ML.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery secara otomatis diaktifkan dalam project baru.
Untuk mengaktifkan BigQuery dalam project yang sudah ada, buka
Aktifkan BigQuery API.
Peran yang diperlukan untuk mengaktifkan API
Untuk mengaktifkan API, Anda memerlukan peran IAM Service Usage Admin (
roles/serviceusage.serviceUsageAdmin), yang berisi izinserviceusage.services.enable. Pelajari cara memberikan peran.
Izin yang Diperlukan
Untuk membuat set data, Anda memerlukan izin IAM
bigquery.datasets.create.Untuk membuat model, Anda memerlukan izin berikut:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Untuk menjalankan inferensi, Anda memerlukan izin berikut:
bigquery.models.getDatabigquery.jobs.create
Untuk mengetahui informasi lebih lanjut tentang peran dan izin IAM di BigQuery, baca Pengantar IAM.
Membuat set data
Buat set data BigQuery untuk menyimpan model ML Anda.
Konsol
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
bqml_tutorial.Untuk Location type, pilih Multi-region, lalu pilih US.
Jangan ubah setelan default yang tersisa, lalu klik Create dataset.
bq
Untuk membuat set data baru, gunakan
perintah bq mk --dataset.
Buat set data bernama
bqml_tutorialdengan lokasi data ditetapkan keUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Pastikan set data telah dibuat:
bq ls
API
Panggil metode datasets.insert dengan resource set data yang ditentukan.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Membuat tabel data input
Buat tabel data yang dapat Anda gunakan untuk melatih dan mengevaluasi model. Tabel ini menggabungkan kolom dari beberapa tabel dalam set data bigquery-public-data.epa_historical_air_quality untuk memberikan data cuaca harian. Anda juga membuat kolom berikut untuk digunakan sebagai
variabel input untuk model:
date: tanggal observasipm25nilai rata-rata PM2,5 untuk setiap hariwind_speed: kecepatan angin rata-rata untuk setiap haritemperature: suhu tertinggi untuk setiap hari
Dalam kueri GoogleSQL berikut, klausa FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary menunjukkan bahwa Anda membuat kueri tabel *_daily_summary di set data epa_historical_air_quality. Tabel ini adalah
tabel yang dipartisi.
Ikuti langkah-langkah berikut untuk membuat tabel data input:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date);
Memvisualisasikan data input
Sebelum membuat model, Anda dapat secara opsional memvisualisasikan data deret waktu input untuk memahami distribusinya. Anda dapat melakukannya menggunakan Data Studio.
Ikuti langkah-langkah berikut untuk memvisualisasikan data deret waktu:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;
Setelah kueri selesai, klik Open in > Data Studio. Data Studio akan terbuka di tab baru. Selesaikan langkah-langkah berikut di tab baru.
Di Data Studio, klik Sisipkan > Diagram deret waktu.
Di panel Chart, pilih tab Setup.
Di bagian Metric, tambahkan kolom pm25, temperature, dan wind_speed, lalu hapus metrik Record Count default. Diagram yang dihasilkan akan terlihat mirip dengan berikut ini:

Dengan melihat diagram, Anda dapat melihat bahwa deret waktu input memiliki pola musiman mingguan.
Buat model deret waktu
Buat model deret waktu untuk memperkirakan nilai materi partikulat, sebagaimana diwakili
oleh kolom pm25, menggunakan nilai kolom pm25, wind_speed, dan temperature
sebagai variabel input. Latih model pada data kualitas udara dari tabel
bqml_tutorial.seattle_air_quality_daily, dengan memilih data yang dikumpulkan
antara 1 Januari 2012 dan 31 Desember 2020.
Dalam kueri berikut, klausa OPTIONS(model_type='ARIMA_PLUS_XREG',
time_series_timestamp_col='date', ...) menunjukkan bahwa Anda membuat
model ARIMA dengan regresor eksternal. Opsi
auto_arima
dari pernyataan CREATE MODEL secara default adalah TRUE, sehingga algoritma auto.ARIMA
akan otomatis menyesuaikan hyperparameter dalam model. Algoritma ini sesuai dengan beberapa model kandidat dan memilih model terbaik, yaitu model dengan kriteria informasi Akaike (AIC) terendah.
Opsi
data_frequency
dari pernyataan CREATE MODEL secara default adalah AUTO_FREQUENCY, sehingga
proses pelatihan secara otomatis menyimpulkan frekuensi data dari deret waktu
input.
Ikuti langkah-langkah berikut untuk membuat model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', # Identifies the column that contains time points time_series_data_col = 'pm25') # Identifies the column to forecast AS SELECT date, # The column that contains time points pm25, # The column to forecast temperature, # Temperature input to use in forecasting wind_speed # Wind speed input to use in forecasting FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31');
Kueri membutuhkan waktu sekitar 20 detik untuk diselesaikan, setelah itu Anda dapat mengakses model
seattle_pm25_xreg_model. Karena kueri tersebut menggunakan pernyataanCREATE MODELuntuk membuat model, Anda tidak akan melihat hasil kueri.
Mengevaluasi model kandidat
Evaluasi model deret waktu menggunakan fungsi ML.ARIMA_EVALUATE. Fungsi ML.ARIMA_EVALUATE menampilkan metrik evaluasi
semua model kandidat yang dievaluasi selama proses penyesuaian hyperparameter
otomatis.
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
Hasilnya akan terlihat seperti berikut:

Kolom output
non_seasonal_p,non_seasonal_d,non_seasonal_q, danhas_driftmenentukan model ARIMA dalam pipeline pelatihan. Kolom outputlog_likelihood,AIC, danvariancerelevan dengan proses penyesuaian model ARIMA.Algoritma
auto.ARIMAmenggunakan pengujian KPSS untuk menentukan nilai terbaik untuknon_seasonal_d, yang dalam hal ini adalah1. Jikanon_seasonal_dadalah1, algoritmaauto.ARIMAakan melatih 42 model ARIMA kandidat yang berbeda secara paralel. Dalam contoh ini, ke-42 model kandidat sudah valid, sehingga output berisi 42 baris, satu untuk setiap model ARIMA kandidat; jika beberapa model tidak valid, model tersebut akan dikecualikan dari output. Model kandidat ini ditampilkan dalam urutan menaik berdasarkan AIC. Model di baris pertama memiliki AIC terendah, dan dianggap sebagai model terbaik. Model terbaik disimpan sebagai model akhir dan digunakan saat Anda memanggil fungsi sepertiML.FORECASTpada model.Kolom
seasonal_periodsberisi informasi tentang pola musiman yang diidentifikasi dalam data deret waktu. Hal ini tidak ada hubungannya dengan pemodelan ARIMA, sehingga memiliki nilai yang sama di semua baris output. Pola ini melaporkan pola mingguan, yang sesuai dengan hasil yang Anda lihat jika Anda memilih untuk memvisualisasikan data input.Kolom
has_holiday_effect,has_spikes_and_dips, danhas_step_changesmemberikan informasi tentang data deret waktu input, dan tidak terkait dengan pemodelan ARIMA. Kolom ini ditampilkan karena nilai opsidecompose_time_seriesdalam pernyataanCREATE MODELadalahTRUE. Kolom ini juga memiliki nilai yang sama di semua baris output.Kolom
error_messagemenampilkan error yang terjadi selama proses penyesuaianauto.ARIMA. Salah satu kemungkinan penyebab error adalah saat kolomnon_seasonal_p,non_seasonal_d,non_seasonal_q, danhas_driftyang dipilih tidak dapat menstabilkan deret waktu. Untuk mengambil pesan error dari semua model kandidat, tetapkan opsishow_all_candidate_modelskeTRUEsaat Anda membuat model.Untuk mengetahui informasi selengkapnya tentang kolom output, lihat fungsi
ML.ARIMA_EVALUATE.
Memeriksa koefisien model
Periksa koefisien model deret waktu menggunakan
fungsi ML.ARIMA_COEFFICIENTS.
Ikuti langkah-langkah berikut untuk mengambil koefisien model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
Hasilnya akan terlihat seperti berikut:
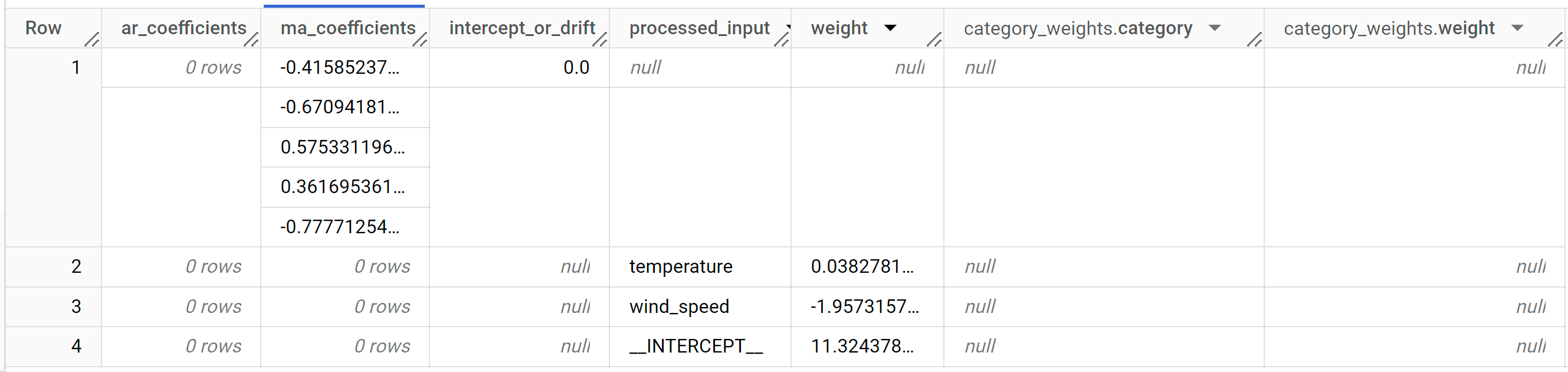
Kolom output
ar_coefficientsmenampilkan koefisien model bagian autoregresif (AR) dari model ARIMA. Demikian pula, kolom outputma_coefficientsmenampilkan koefisien model bagian rata-rata bergerak (MA) dari model ARIMA. Kedua kolom ini berisi nilai array, yang panjangnya sama dengannon_seasonal_pdannon_seasonal_qsecara berurutan. Anda melihat di output fungsiML.ARIMA_EVALUATEbahwa model terbaik memiliki nilainon_seasonal_psebesar0dan nilainon_seasonal_qsebesar5. Oleh karena itu, dalam outputML.ARIMA_COEFFICIENTS, nilaiar_coefficientsadalah array kosong dan nilaima_coefficientsadalah array 5 elemen. Nilaiintercept_or_driftadalah istilah konstan dalam model ARIMA.Kolom output
processed_input,weight, dancategory_weightsmenunjukkan bobot untuk setiap fitur dan intersepsi dalam model regresi linear. Jika fitur adalah fitur numerik, bobotnya ada di kolomweight. Jika fitur adalah fitur kategoris, nilaicategory_weightsadalah array nilai struct, dengan setiap nilai struct berisi nama dan bobot kategori tertentu.Untuk mengetahui informasi selengkapnya tentang kolom output, lihat fungsi
ML.ARIMA_COEFFICIENTS.
Menggunakan model untuk memperkirakan data
Perkirakan nilai deret waktu mendatang menggunakan fungsi ML.FORECAST.
Dalam kueri GoogleSQL berikut, klausa STRUCT(30 AS horizon, 0.8 AS confidence_level) menunjukkan bahwa kueri memperkirakan 30 titik waktu di masa mendatang, dan menghasilkan interval prediksi dengan tingkat keyakinan 80%.
Ikuti langkah-langkah berikut untuk memperkirakan data dengan model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
Hasilnya akan terlihat seperti berikut:
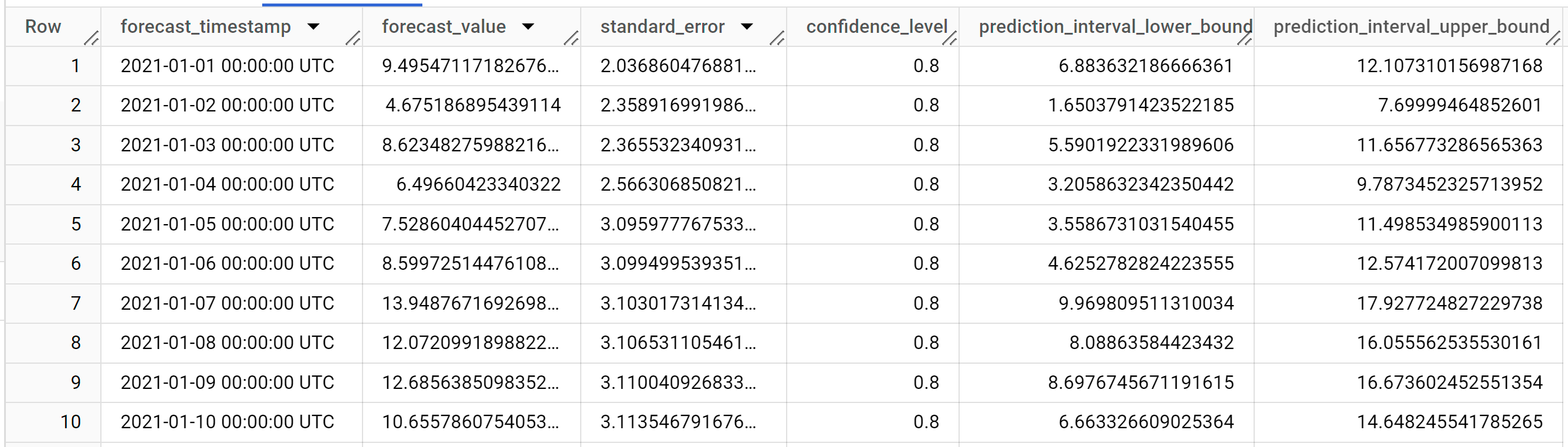
Baris output diurutkan secara kronologis berdasarkan nilai kolom
forecast_timestamp. Dalam perkiraan deret waktu, interval prediksi, sebagaimana diwakili oleh nilai kolomprediction_interval_lower_bounddanprediction_interval_upper_bound, sama pentingnya dengan nilai kolomforecast_value. Nilaiforecast_valueadalah titik tengah interval prediksi. Interval prediksi bergantung pada nilai kolomstandard_errordanconfidence_level.Untuk mengetahui informasi selengkapnya tentang kolom output, lihat fungsi
ML.FORECAST.
Mengevaluasi akurasi perkiraan
Evaluasi akurasi perkiraan model menggunakan fungsi ML.EVALUATE.
Dalam kueri GoogleSQL berikut, pernyataan SELECT kedua memberikan data dengan fitur mendatang, yang digunakan untuk memperkirakan nilai mendatang agar dibandingkan dengan data aktual.
Ikuti langkah-langkah berikut untuk mengevaluasi akurasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon));
Hasilnya akan terlihat seperti berikut:

Untuk mengetahui informasi selengkapnya tentang kolom output, lihat fungsi
ML.EVALUATE.
Menjelaskan hasil perkiraan
Anda bisa mendapatkan metrik keterjelasan selain data perkiraan dengan menggunakan fungsi
ML.EXPLAIN_FORECAST. Fungsi ML.EXPLAIN_FORECAST memperkirakan
nilai deret waktu di masa mendatang dan juga menampilkan semua komponen terpisah dari
deret waktu.
Mirip dengan fungsi ML.FORECAST, klausa STRUCT(30 AS horizon, 0.8 AS confidence_level) yang digunakan dalam fungsi ML.EXPLAIN_FORECAST menunjukkan bahwa kueri memperkirakan 30 titik waktu di masa mendatang dan menghasilkan interval prediksi dengan keyakinan 80%.
Ikuti langkah-langkah berikut untuk menjelaskan hasil model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
Hasilnya akan terlihat seperti berikut:
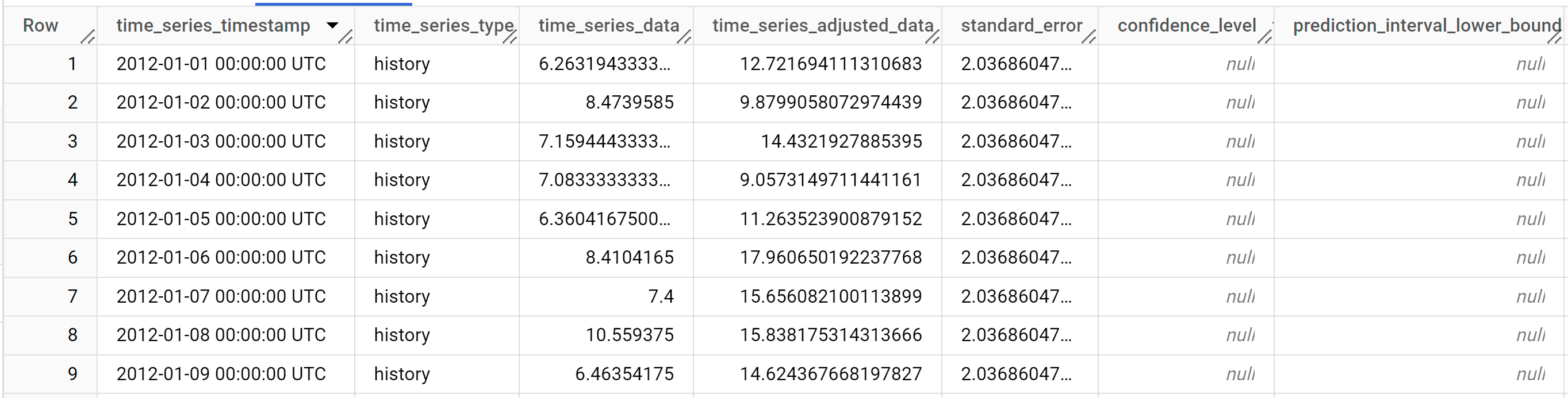
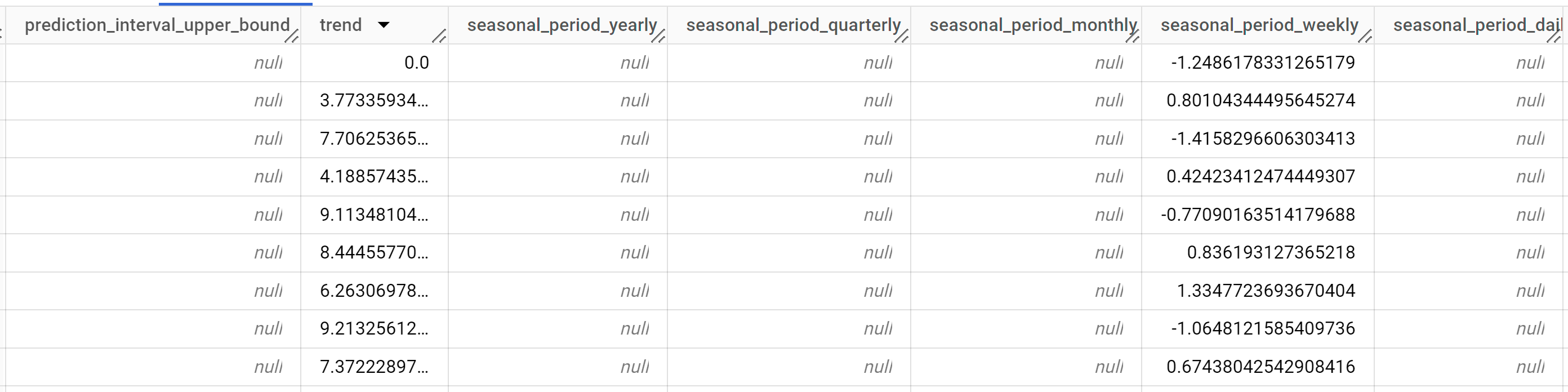
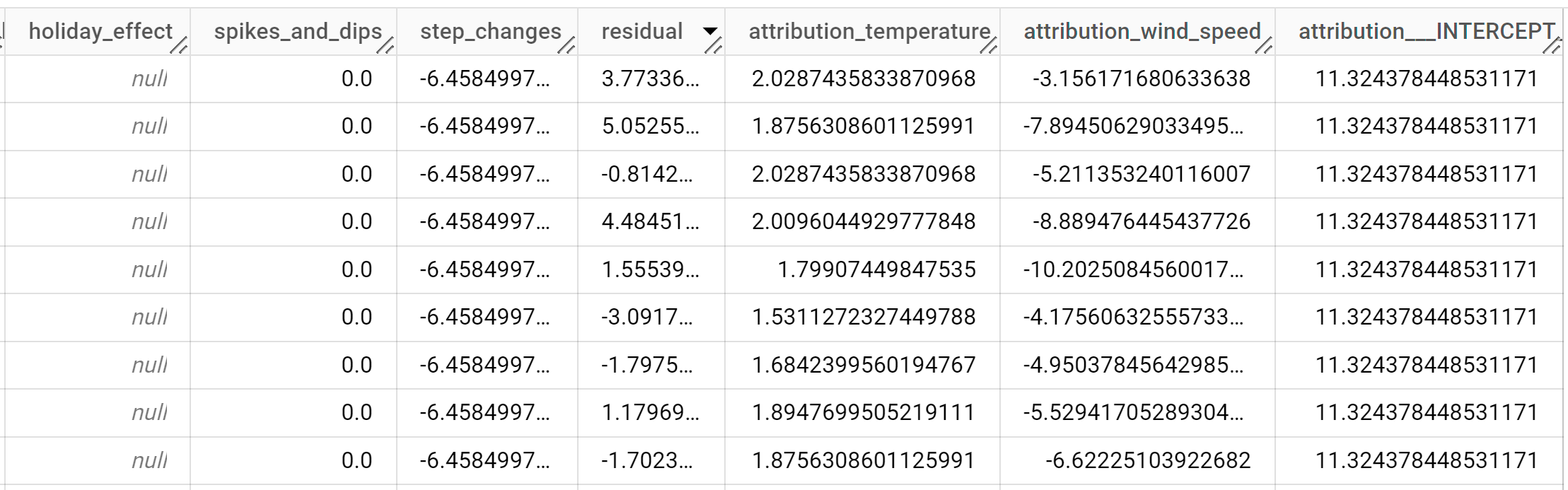
Baris output diurutkan secara kronologis berdasarkan nilai kolom
time_series_timestamp.Untuk mengetahui informasi selengkapnya tentang kolom output, lihat fungsi
ML.EXPLAIN_FORECAST.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus resource satu per satu.
- Anda dapat menghapus project yang dibuat.
- Atau, Anda dapat menyimpan project dan menghapus set data.
Menghapus set data
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan kembali project tersebut, Anda dapat menghapus set data yang dibuat dalam tutorial ini:
Jika perlu, buka halaman BigQuery di konsolGoogle Cloud .
Di navigasi, klik set data bqml_tutorial yang telah Anda buat.
Klik Delete dataset di sisi kanan jendela. Tindakan ini akan menghapus set data, tabel, dan semua data.
Pada dialog Hapus set data, konfirmasi perintah hapus dengan mengetikkan nama set data Anda (
bqml_tutorial), lalu klik Hapus.
Menghapus project Anda
Untuk menghapus project:
- Di Konsol Google Cloud , buka halaman Manage resources.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Langkah berikutnya
- Pelajari cara memperkirakan deret waktu tunggal dengan model univariat
- Pelajari cara memperkirakan beberapa deret waktu dengan model univariat
- Pelajari cara menskalakan model univariat saat memperkirakan beberapa deret waktu di banyak baris.
- Pelajari cara memperkirakan beberapa deret waktu secara hierarkis dengan model univariat
- Untuk ringkasan BigQuery ML, lihat Pengantar AI dan ML di BigQuery.