
במאמר הזה מתואר ארכיטקטורת הפניה שעוזרת ליצור מנגנון לייצוא יומנים שמוכן לייצור, ניתן להרחבה, עמיד בפני תקלות ומזרים יומנים ואירועים מהמשאבים שלכם ב- Google Cloud אל Splunk. Splunk הוא כלי פופולרי לניתוח נתונים שמציע פלטפורמה מאוחדת לאבטחה ולניטור. למעשה, אתם יכולים לבחור לייצא את נתוני הרישום ל-Splunk Enterprise או ל-Splunk Cloud Platform. אדמינים יכולים להשתמש בארכיטקטורה הזו גם לתרחישי שימוש של פעולות IT או אבטחה.
ארכיטקטורת ההפניה הזו מניחה היררכיית משאבים שדומה לתרשים הבא. כל יומני המשאבים מרמת הארגון, התיקייה והפרויקט נאספים ליעד מצטבר. לאחר מכן, היעד המצטבר שולח את היומנים האלה לצינור לייצוא יומנים, שמעבד את היומנים ומייצא אותם ל-Splunk. Google Cloud

ארכיטקטורה
בתרשים הבא מוצגת ארכיטקטורת ההפניה שבה משתמשים כשפורסים את הפתרון הזה. בתרשים הזה מוצג איך נתוני יומן זורמים מ-Google Cloud אל Splunk.

הארכיטקטורה הזו כוללת את הרכיבים הבאים:
- Cloud Logging: כדי להתחיל את התהליך, Cloud Logging אוסף את היומנים אל מאגר יומנים מצטבר ברמת הארגון ושולח את היומנים אל Pub/Sub.
- Pub/Sub: שירות Pub/Sub יוצר נושא ומינוי יחידים ליומנים ומעביר את היומנים לצינור הראשי של Dataflow.
- Dataflow: בארכיטקטורת ההפניה הזו יש שני צינורות עיבוד נתונים של Dataflow:
- פייפליין ראשי של Dataflow: במרכז התהליך, הפייפליין הראשי של Dataflow הוא פייפליין סטרימינג מ-Pub/Sub ל-Splunk, ששולף יומנים מהמינוי ל-Pub/Sub ומעביר אותם ל-Splunk.
- צינור עיבוד נתונים משני של Dataflow: צינור עיבוד הנתונים המשני של Dataflow פועל במקביל לצינור עיבוד הנתונים הראשי של Dataflow, והוא צינור עיבוד נתונים בסטרימינג מסוג Pub/Sub ל-Pub/Sub שנועד להפעיל מחדש הודעות אם המסירה נכשלת.
- Splunk: בסוף התהליך, Splunk Enterprise או Splunk Cloud Platform פועלים כ-HTTP Event Collector (HEC) ומקבלים את היומנים לצורך ניתוח נוסף. אפשר לפרוס את Splunk באופן מקומי, ב-Google Cloud כ-SaaS או בגישה היברידית.
תרחיש שימוש
בארכיטקטורת ההפניה הזו נעשה שימוש בגישה מבוססת-דחיפה בענן. בשיטה הזו שמבוססת על שליחת נתונים, משתמשים בתבנית Pub/Sub to Splunk Dataflow כדי להזרים יומנים אל Splunk HTTP Event Collector (HEC). בארכיטקטורת ההפניה מוסבר גם על תכנון הקיבולת של צינור Dataflow ועל דרכים לטפל בכשלים פוטנציאליים בהעברה במקרים של בעיות זמניות בשרת או ברשת.
למרות שהארכיטקטורה הזו מתמקדת ביומנים של Google Cloud , אפשר להשתמש באותה ארכיטקטורה כדי לייצא נתונים אחרים של Google Cloud , כמו שינויים בנכסים בזמן אמת וממצאי אבטחה. על ידי שילוב יומנים מ-Cloud Logging, אתם יכולים להמשיך להשתמש בשירותי שותפים קיימים כמו Splunk כפתרון מאוחד לניתוח יומנים.
לשיטה שמבוססת על דחיפת נתונים ל-Splunk יש את היתרונות הבאים: Google Cloud
- שירות מנוהל. בתור שירות מנוהל, Dataflow שומר על המשאבים הנדרשים ב- Google Cloud למשימות של עיבוד נתונים, כמו ייצוא יומנים.
- עומס עבודה מבוזר. השיטה הזו מאפשרת לכם לפזר את עומסי העבודה בין כמה עובדים לעיבוד מקביל, כך שלא תהיה נקודת כשל יחידה.
- אבטחה. Google Cloud מעביר את הנתונים שלכם ל-Splunk HEC, כך שאין צורך ליצור ולנהל מפתחות של חשבון שירות, ואין את נטל התחזוקה והאבטחה שקשור לכך.
- שינוי גודל אוטומטי. שירות Dataflow משנה את גודל מספר העובדים באופן אוטומטי בתגובה לשינויים בנפח היומנים הנכנסים ובפיגור.
- עמידות בפני תקלות. אם יש בעיות זמניות בשרת או ברשת, השיטה מבוססת-הדחיפה מנסה לשלוח מחדש את הנתונים ל-Splunk HEC באופן אוטומטי. הוא גם תומך בנושאים לא מעובדים (שנקראים גם נושאים של הודעות שלא נמסרו) לכל הודעות היומן שלא ניתן למסור, כדי למנוע אובדן נתונים.
- פשטות. אתם נמנעים מהוצאות ניהול ומהעלות של הפעלת heavy forwarders אחד או יותר ב-Splunk.
ארכיטקטורת ההפניה הזו רלוונטית לעסקים בתחומים רבים, כולל תחומים מפוקחים כמו שירותים פיננסיים ותרופות. כשבוחרים לייצא את הנתונים ל-Splunk, יכולות להיות לכך כמה סיבות: Google Cloud
- ניתוח נתונים עסקיים
- תפעול IT
- מעקב אחר ביצועי אפליקציות
- תפעול אבטחה (SecOps)
- תאימות
חלופות עיצוב
שיטה חלופית לייצוא יומנים ל-Splunk היא שיטה שבה שולפים יומנים מ-Google Cloud. בשיטה הזו, שמבוססת על משיכה, משתמשים ב-Google Cloud APIs כדי לאחזר את הנתונים באמצעות Splunk Add-on for Google Cloud. אפשר להשתמש בשיטה מבוססת-משיכה במצבים הבאים:
- פריסת Splunk שלכם לא מציעה נקודת קצה של Splunk HEC.
- עוצמת הקול של היומן נמוכה.
- אתם רוצים לייצא ולנתח מדדים של Cloud Monitoring, אובייקטים של Cloud Storage, מטא-נתונים של Cloud Resource Manager API, נתוני חיוב ב-Cloud או יומנים עם נפח נמוך.
- אתם כבר מנהלים לפחות משגר כבד אחד ב-Splunk.
- אתם משתמשים ב-Inputs Data Manager for Splunk Cloud.
בנוסף, חשוב לזכור את השיקולים הנוספים שמתעוררים כשמשתמשים בשיטה הזו שמבוססת על משיכה:
- עובד יחיד מטפל בעומס העבודה של הטמעת נתונים, ולכן אין אפשרות להתאמה אוטומטית לעומס.
- ב-Splunk, שימוש ב-heavy forwarder כדי לשלוף נתונים עלול לגרום לנקודת כשל יחידה.
- בשיטה מבוססת-השליפה, צריך ליצור ולנהל את המפתחות של חשבון השירות שמשמשים להגדרת התוסף Splunk for Google Cloud.
לפני שמשתמשים בתוסף Splunk, צריך להפנות את רשומות היומן ל-Pub/Sub באמצעות sink ביומן. כדי ליצור sink ביומן עם נושא Pub/Sub כיעד, ראו יצירת יעד.
חשוב להקצות את התפקיד 'פרסום הודעות ב-Pub/Sub' (roles/pubsub.publisher) לזהות הכתיבה של יעד הנתונים בנושא ב-Pub/Sub. מידע נוסף על הגדרת הרשאות ליעד של נתוני Sink זמין במאמר בנושא הגדרת הרשאות ליעד.
כדי להפעיל את התוסף Splunk, מבצעים את השלבים הבאים:
- ב-Splunk, פועלים לפי ההוראות של Splunk כדי להתקין את Splunk Add-on for Google Cloud.
- אם עדיין אין לכם מינוי כזה, אתם צריכים ליצור מינוי שליפה של Pub/Sub לנושא Pub/Sub שאליו מנותבים היומנים.
- יוצרים חשבון שירות.
- יוצרים מפתח לחשבון השירות עבור חשבון השירות שיצרתם.
- כדי לאפשר לחשבון לקבל הודעות מהמינוי ל-Pub/Sub, צריך להקצות לחשבון השירות את התפקידים 'צפייה ב-Pub/Sub' (
roles/pubsub.viewer) ו'הרשמה ל-Pub/Sub' (roles/pubsub.subscriber). ב-Splunk, פועלים לפי ההוראות של Splunk כדי להגדיר קלט Pub/Sub חדש ב-Splunk Add-on for Google Cloud.
ההודעות של Pub/Sub מייצוא היומן מופיעות ב-Splunk.
כדי לוודא שהתוסף פועל, פועלים לפי השלבים הבאים:
- ב-Cloud Monitoring, פותחים את Metrics Explorer.
- בתפריט Resources בוחרים באפשרות
pubsub_subscription. - בקטגוריות מדדים, בוחרים באפשרות
pubsub/subscription/pull_message_operation_count. - עוקבים אחרי מספר הפעולות של שליפת הודעות למשך דקה עד שתי דקות.
שיקולים לגבי העיצוב
ההנחיות הבאות יעזרו לכם לפתח ארכיטקטורה שעומדת בדרישות הארגון שלכם בנוגע לאבטחה, פרטיות, תאימות, יעילות תפעולית, מהימנות, עמידות בפני תקלות, ביצועים ואופטימיזציה של עלויות.
אבטחה, פרטיות ותאימות
בקטעים הבאים מתוארים שיקולי האבטחה של ארכיטקטורת ההפניה הזו:
- שימוש בכתובות IP פרטיות כדי לאבטח את המכונות הווירטואליות שתומכות בצינור עיבוד הנתונים של Dataflow
- הפעלת גישה פרטית ל-Google
- הגבלת תעבורת נתונים נכנסת (ingress) של Splunk HEC לכתובות IP מוכרות שמשמשות את Cloud NAT
- שמירת הטוקן של Splunk HEC ב-Secret Manager
- יצירת חשבון שירות מותאם אישית של Dataflow worker כדי לפעול לפי השיטות המומלצות של הרשאות מינימליות
- הגדרת אימות SSL לאישור CA בסיסי פנימי אם משתמשים ב-CA פרטי
שימוש בכתובות IP פרטיות כדי לאבטח את המכונות הווירטואליות שתומכות בצינור עיבוד הנתונים ב-Dataflow
מומלץ להגביל את הגישה למכונות הווירטואליות של העובדים שמשמשות בצינור Dataflow. כדי להגביל את הגישה, צריך לפרוס את המכונות הווירטואליות האלה עם כתובות IP פרטיות. עם זאת, המכונות הווירטואליות האלה צריכות גם להיות מסוגלות להשתמש ב-HTTPS כדי להזרים את היומנים המיוצאים ל-Splunk ולגשת לאינטרנט. כדי לספק גישה ל-HTTPS, צריך שער Cloud NAT שמקצה באופן אוטומטי כתובות IP של Cloud NAT למכונות הווירטואליות שזקוקות להן. חשוב למפות את רשת המשנה שמכילה את המכונות הווירטואליות לשער Cloud NAT.
הפעלת גישה פרטית ל-Google
כשיוצרים שער Cloud NAT, הגישה הפרטית ל-Google מופעלת באופן אוטומטי. עם זאת, כדי לאפשר לעובדי Dataflow עם כתובות IP פרטיות לגשת לכתובות ה-IP החיצוניות שבהן משתמשים Cloud APIs והשירותים של Google Cloud, צריך גם להפעיל באופן ידני גישה פרטית ל-Google עבור רשת המשנה.
הגבלת תעבורת נתונים נכנסת (ingress) של Splunk HEC לכתובות IP מוכרות שמשמשות את Cloud NAT
אם רוצים להגביל את התנועה אל Splunk HEC לקבוצת משנה של כתובות IP ידועות, אפשר לשריין כתובות IP סטטיות ולהקצות אותן באופן ידני לשער Cloud NAT. בהתאם לפריסת Splunk, תוכלו להגדיר את כללי חומת האש של Splunk HEC ingress באמצעות כתובות ה-IP הסטטיות האלה. מידע נוסף על Cloud NAT זמין במאמר הגדרה וניהול של תרגום כתובות רשת באמצעות Cloud NAT.
אחסון הטוקן של Splunk HEC ב-Secret Manager
כשפורסים את צינור הנתונים של Dataflow, אפשר להעביר את ערך הטוקן באחת מהדרכים הבאות:
- Plaintext
- טקסט מוצפן שהוצפן באמצעות מפתח של Cloud Key Management Service
- גרסת סוד מוצפנת ומנוהלת על ידי Secret Manager
באדריכלות ההפניה הזו, משתמשים באפשרות Secret Manager כי היא מציעה את הדרך הכי פשוטה ויעילה להגן על אסימון Splunk HEC. האפשרות הזו גם מונעת דליפה של אסימון Splunk HEC ממסוף Dataflow או מפרטי העבודה.
סוד ב-Secret Manager מכיל אוסף של גרסאות סוד. כל גרסה של סוד מאחסנת את נתוני הסוד בפועל, כמו טוקן Splunk HEC. אם תבחרו בהמשך להחליף את אסימון Splunk HEC כאמצעי אבטחה נוסף, תוכלו להוסיף את האסימון החדש כגרסה חדשה של הסוד הזה. מידע כללי על החלפה של סודות זמין במאמר מידע על לוחות זמנים להחלפה.
יצירת חשבון שירות בהתאמה אישית של עובד Dataflow כדי לפעול לפי השיטות המומלצות של הרשאות מינימליות
תהליכי Worker בצינור Dataflow משתמשים בחשבון השירות של תהליכי Worker ב-Dataflow כדי לגשת למשאבים ולהריץ פעולות. כברירת מחדל, העובדים משתמשים בחשבון השירות שמשמש כברירת המחדל של Compute Engine בפרויקט שלכם כחשבון השירות של העובד, מה שמעניק להם הרשאות רחבות לכל המשאבים בפרויקט. עם זאת, כדי להריץ משימות Dataflow בסביבת ייצור, מומלץ ליצור חשבון שירות בהתאמה אישית עם סט מינימלי של תפקידים והרשאות. לאחר מכן, תוכלו להקצות את חשבון השירות המותאם אישית הזה לעובדים בצינור Dataflow.
בתרשים הבא מפורטים התפקידים הנדרשים שצריך להקצות לחשבון שירות כדי שעובדי Dataflow יוכלו להריץ משימת Dataflow בהצלחה.
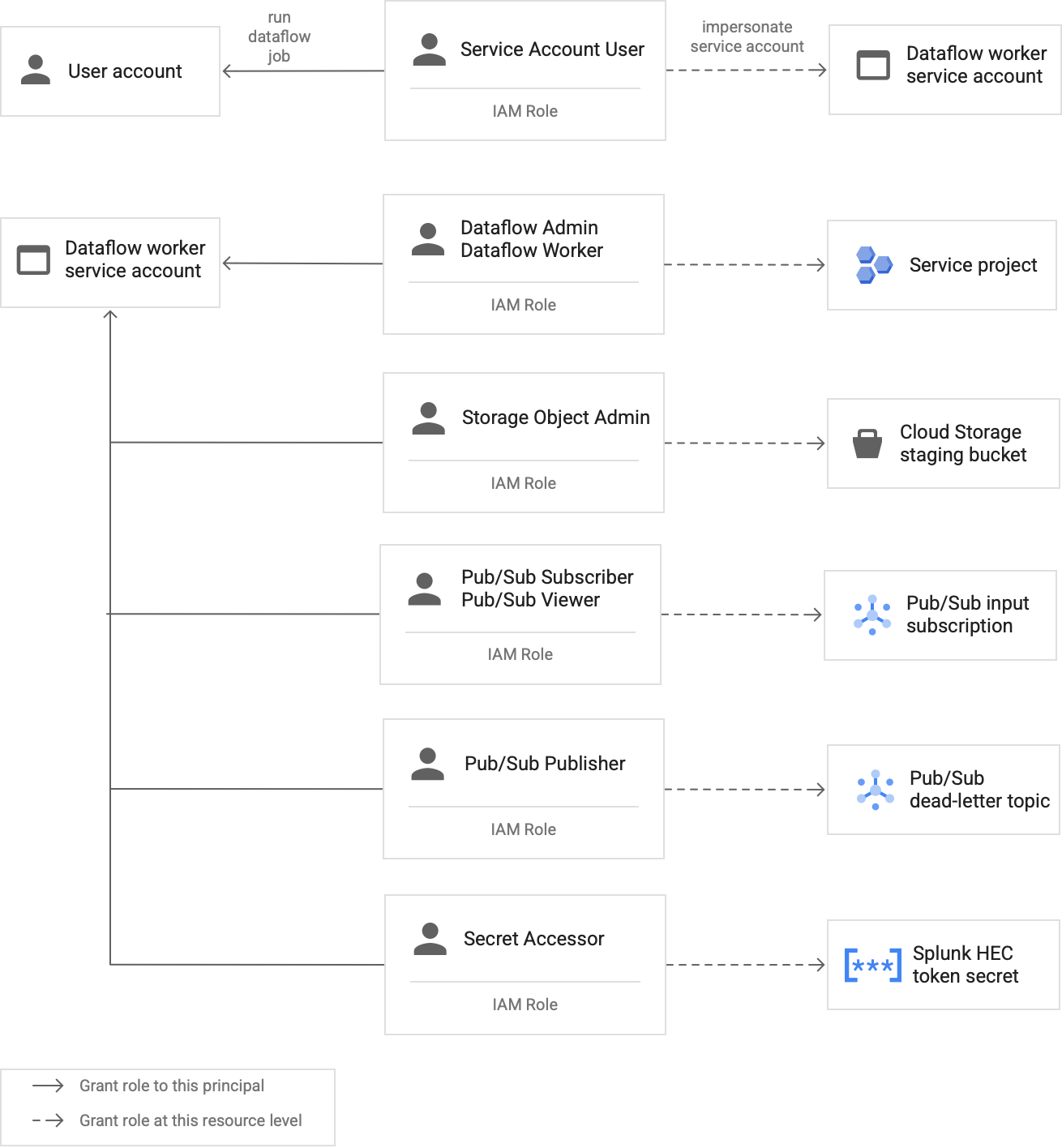
כפי שמוצג בדיאגרמה, צריך להקצות את התפקידים הבאים לחשבון השירות של ה-worker ב-Dataflow:
- אדמין של Dataflow
- Dataflow Worker
- אדמין של אובייקט אחסון
- מנוי ל-Pub/Sub
- כלי הצפייה ב-Pub/Sub
- פרסום הודעות ב-Pub/Sub
- Secret Accessor
הגדרת אימות SSL באמצעות אישור CA בסיסי פנימי אם משתמשים ב-CA פרטי
כברירת מחדל, צינור עיבוד הנתונים של Dataflow משתמש במאגר האישורים של עובד Dataflow כדי לאמת את אישור ה-SSL של נקודת הקצה של Splunk HEC. אם אתם משתמשים ברשות אישורים (CA) פרטית כדי לחתום על אישור SSL שמשמש את נקודת הקצה של Splunk HEC, אתם יכולים לייבא את אישור ה-CA הבסיסי הפנימי שלכם למאגר האישורים המהימנים. לאחר מכן, תהליך העבודה של Dataflow יכול להשתמש באישור המיובא כדי לאמת את אישור ה-SSL.
אתם יכולים להשתמש באישור CA פנימי משלכם ולייבא אותו לפריסות של Splunk עם אישורים בחתימה עצמית או אישורים חתומים באופן פרטי. אפשר גם להשבית את אימות ה-SSL לחלוטין למטרות פיתוח ובדיקה פנימיות בלבד. השיטה הזו של CA פנימי ברמת הבסיס מתאימה במיוחד לפריסות פנימיות של Splunk שלא חשופות לאינטרנט.
מידע נוסף זמין במאמר פרמטרים של תבנית Pub/Sub ל-Splunk Dataflow
rootCaCertificatePath ו-disableCertificateValidation.
יעילות תפעולית
בקטעים הבאים מתוארים שיקולים לגבי יעילות תפעולית בארכיטקטורת ההפניה הזו:
שימוש בפונקציה מוגדרת על ידי המשתמש (UDF) כדי לשנות יומנים או אירועים בזמן ההעברה
תבנית Pub/Sub ל-Splunk Dataflow תומכת בפונקציות שמוגדרות על ידי המשתמש (UDF) לצורך שינוי אירועים בהתאמה אישית. דוגמאות לתרחישי שימוש כוללות הוספת שדות לרשומות, צנזורה של שדות רגישים או סינון רשומות לא רצויות. פונקציות UDF מאפשרות לשנות את פורמט הפלט של צינור Dataflow בלי צורך לבצע קומפילציה מחדש או לתחזק את קוד התבנית עצמו. בארכיטקטורת ההפניה הזו נעשה שימוש בפונקציית UDF כדי לטפל בהודעות שצינור לא יכול להעביר ל-Splunk.
הפעלה מחדש של הודעות שלא עברו עיבוד
לפעמים, הצינור מקבל שגיאות מסירה ולא מנסה למסור את ההודעה שוב. במקרה כזה, Dataflow שולח את ההודעות שלא עברו עיבוד לנושא שלא עבר עיבוד, כמו שמוצג בתרשים הבא. אחרי שתתקנו את הסיבה הבסיסית לכשל במסירה, תוכלו להפעיל מחדש את ההודעות שלא עברו עיבוד.
השלבים הבאים מתארים את התהליך שמוצג בתרשים הקודם:
- צינור עיבוד המסירה הראשי מ-Pub/Sub ל-Splunk מעביר אוטומטית הודעות שלא ניתן למסור לנושא שלא עבר עיבוד, כדי שהמשתמש יוכל לבדוק אותן.
המפעיל או מהנדס אמינות האתר (SRE) בודקים את ההודעות שנכשלו במינוי שלא עבר עיבוד. המפעיל פותר את הבעיה ומתקן את הסיבה הבסיסית לכישלון המסירה. לדוגמה, תיקון של הגדרה שגויה של אסימון HEC עשוי לאפשר את מסירת ההודעות.
המפעיל מפעיל את צינור ההודעות של ההודעות שנכשלו בשליחה מחדש. צינור הנתונים הזה של Pub/Sub ל-Pub/Sub (שמסומן בקטע המקווקו בתרשים הקודם) הוא צינור נתונים זמני שמעביר את ההודעות שנכשלו מהמינוי שלא עבר עיבוד בחזרה לנושא המקורי של יעד היומן.
צינור העיבוד הראשי של המסירה מעבד מחדש את ההודעות שנכשלו קודם. בשלב הזה, צינור העיבוד צריך להשתמש ב-UDF כדי לזהות ולפענח בצורה נכונה את המטען הייעודי (payload) של ההודעות שנכשלו. הקוד הבא הוא דוגמה לפונקציה שמיישמת את לוגיקת הפענוח המותנה הזו, כולל סיכום של ניסיונות המסירה למטרות מעקב:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
אמינות ועמידות בפני תקלות
בטבלה הבאה, טבלה 1, מפורטות כמה שגיאות אפשריות בשליחה של Splunk, שקשורות למהימנות ולסבילות לתקלות. בטבלה מפורטים גם מאפייני errorMessage התואמים שהצינור מתעד בכל הודעה לפני שהוא מעביר את ההודעות האלה לנושא שלא עבר עיבוד.
טבלה 1: סוגי שגיאות מסירה ב-Splunk
| סוג שגיאת הצגת המודעות | האם הצינור מנסה שוב באופן אוטומטי? | דוגמה למאפיין errorMessage |
|---|---|---|
שגיאה זמנית בחיבור לרשת |
כן |
או
|
שגיאת 5xx בשרת Splunk |
כן |
|
שגיאת 4xx בשרת Splunk |
לא |
|
השרת של Splunk לא פועל |
לא |
|
אישור SSL לא חוקי של Splunk |
לא |
|
שגיאת תחביר JavaScript בפונקציה בהגדרת המשתמש (UDF) |
לא |
|
במקרים מסוימים, פייפליין משתמש בהשהיה מעריכית לפני ניסיון חוזר (exponential backoff) ומנסה באופן אוטומטי למסור את ההודעה שוב. לדוגמה, כששרת Splunk יוצר קוד שגיאה 5xx, פייפליין צריך למסור מחדש את ההודעה. קודי השגיאה האלה נוצרים כשנקודת הקצה של Splunk HEC עמוסה מדי.
לחלופין, יכול להיות שיש בעיה מתמשכת שמונעת את שליחת ההודעה לנקודת הקצה של HEC. במקרים כאלה, צינור הנתונים לא ינסה לשלוח את ההודעה שוב. הנה כמה דוגמאות לבעיות מתמשכות:
- שגיאת תחביר בפונקציית UDF.
- טוקן HEC לא תקין שגורם לשרת Splunk ליצור תגובת שרת
4xxForbidden.
אופטימיזציה של הביצועים והעלויות
לגבי אופטימיזציה של הביצועים והעלויות, צריך לקבוע את הגודל המקסימלי ואת קצב העברת הנתונים של צינור עיבוד הנתונים של Dataflow. צריך לחשב את הערכים הנכונים של הגודל וקצב העברת הנתונים כדי שצינור הנתונים יוכל להתמודד עם נפח השיא היומי של היומנים (GB/day) ועם קצב ההודעות ביומן (אירועים לשנייה, או EPS) מהמינוי של Pub/Sub במעלה הזרם.
צריך לבחור את הגודל ואת ערכי התפוקה כך שלא יתרחשו במערכת אף אחת מהבעיות הבאות:
- עיכובים שנגרמים בגלל הצטברות של הודעות או הגבלת קצב השליחה של הודעות.
- עלויות נוספות כתוצאה מהקצאת יתר של משאבים בצינור.
אחרי שמבצעים את החישובים של הגודל וקצב העברת הנתונים, אפשר להשתמש בתוצאות כדי להגדיר צינור נתונים אופטימלי שמאזן בין ביצועים לעלות. כדי להגדיר את הקיבולת של צינור המכירות, משתמשים בהגדרות הבאות:
- הדגלים סוג מכונה ו-Machine count הם חלק מפקודת gcloud שפורסת את משימת Dataflow. הדגלים האלה מאפשרים להגדיר את הסוג ואת מספר המכונות הווירטואליות שבהן רוצים להשתמש.
- הפרמטרים Parallelism ו-Batch count הם חלק מהתבנית Pub/Sub to Splunk Dataflow. הפרמטרים האלה חשובים להגדלת ה-EPS בלי להעמיס על נקודת הקצה של Splunk HEC.
בקטעים הבאים מוסבר על ההגדרות האלה. בקטעים האלה מופיעות גם נוסחאות ודוגמאות לחישובים שמתבססים על כל נוסחה, כשזה רלוונטי. החישובים והערכים שמתקבלים בדוגמאות האלה מבוססים על ארגון עם המאפיינים הבאים:
- יוצרת 1TB של יומנים מדי יום.
- גודל ההודעה הממוצע הוא 1KB.
- שיעור ההודעות המקסימלי שנשלח ברציפות גבוה פי שניים מהשיעור הממוצע.
סביבת Dataflow שלכם היא ייחודית, ולכן כשמבצעים את השלבים צריך להחליף את ערכי הדוגמה בערכים מהארגון שלכם.
סוג המכונה
שיטה מומלצת: מגדירים את הדגל --worker-machine-type לערך n2-standard-4 כדי לבחור גודל מכונה שמספק את יחס הביצועים לעלות הטוב ביותר.
מכיוון שסוג המכונה n2-standard-4 יכול לטפל ב-12,000 EPS, מומלץ להשתמש בסוג המכונה הזה כבסיס לכל העובדים של Dataflow.
בארכיטקטורת ההפניה הזו, מגדירים את הדגל --worker-machine-type לערך n2-standard-4.
מספר המכונות
שיטה מומלצת: מגדירים את הדגל --max-workers כדי לשלוט במספר המקסימלי של תהליכי worker שנדרשים לטיפול בשיא הצפוי של EPS.
התאמה אוטומטית לעומס ב-Dataflow מאפשרת לשירות לשנות באופן דינמי את מספר ה-workers שמשמשים להפעלת פייפליין הסטרימינג, כשמתבצעים שינויים בשימוש במשאבים ובטעינה. כדי להימנע מהקצאת יתר של משאבים כשמשתמשים בהתאמת קנה מידה אוטומטית, מומלץ להגדיר תמיד את המספר המקסימלי של מכונות וירטואליות שמשמשות כעובדי Dataflow. מגדירים את המספר המקסימלי של מכונות וירטואליות באמצעות הדגל --max-workers כשפורסים את צינור הנתונים של Dataflow.
מערכת Dataflow מקצה באופן סטטי את רכיב האחסון באופן הבא:
צינור לעיבוד נתונים עם שינוי גודל אוטומטי פורס דיסק אחסון מתמיד אחד לכל עובד פוטנציאלי של סטרימינג. גודל ברירת המחדל של הדיסק המתמיד הוא 400GB, ואתם מגדירים את המספר המקסימלי של העובדים באמצעות הדגל
--max-workers. הדיסקים מותקנים בעובדים הפעילים בכל נקודת זמן, כולל בזמן ההפעלה.מכיוון שכל מופע של Worker מוגבל ל-15 דיסקים קבועים, המספר המינימלי של Workers להפעלה הוא
⌈--max-workers/15⌉. לכן, אם ערך ברירת המחדל הוא--max-workers=20, השימוש בצינור (והעלות) הוא כדלקמן:- אחסון: סטטי עם 20 דיסקים לאחסון מתמיד.
- Compute: דינמי עם מינימום של 2 מופעי worker (⌈20/15⌉ = 2) ומקסימום של 20.
הערך הזה שווה ל-8TB של דיסק אחסון מתמיד. גודל כזה של דיסק מתמשך עלול לגרום לעלויות מיותרות אם הדיסקים לא בשימוש מלא, במיוחד אם רק עובד אחד או שניים מריצים את רוב הזמן.
כדי לקבוע את המספר המקסימלי של עובדים שדרושים לצינור הנתונים, משתמשים בנוסחאות הבאות לפי הסדר:
כדי לחשב את המספר הממוצע של אירועים לשנייה (EPS), משתמשים בנוסחה הבאה:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)דוגמה לחישוב: בהינתן ערכי הדוגמה של 1TB של יומנים ליום עם גודל הודעה ממוצע של 1KB, הנוסחה הזו יוצרת ערך EPS ממוצע של 11.5k EPS.
כדי לקבוע את שיעור האירועים לשנייה (EPS) המקסימלי המתמשך, משתמשים בנוסחה הבאה, שבה המכפיל N מייצג את אופי הרישום של פרצי נתונים:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)חישוב לדוגמה: בהינתן ערך לדוגמה של N=2 והערך הממוצע של EPS 11.5k שחישבתם בשלב הקודם, הנוסחה הזו יוצרת ערך שיא קבוע של EPS 23k.
כדי לקבוע את המספר המקסימלי הנדרש של vCPU, משתמשים בנוסחה הבאה:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)דוגמה לחישוב: באמצעות ערך ה-EPS המקסימלי המתמשך של 23,000 שחישבתם בשלב הקודם, הנוסחה הזו יוצרת מקסימום של ⌈23 / 3⌉ = 8 ליבות vCPU.
כדי לקבוע את המספר המקסימלי של עובדי Dataflow, משתמשים בנוסחה הבאה:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)דוגמה לחישוב: אם הערך המקסימלי של vCPU הוא 8, כפי שחושב בשלב הקודם, הנוסחה [8/4] מחזירה את המספר המקסימלי 2 עבור סוג המכונה
n2-standard-4.
בדוגמה הזו, מגדירים את הערך של הדגל --max-workers ל-2 על סמך קבוצת החישובים הקודמת. עם זאת, חשוב לזכור להשתמש בערכים ובחישובים הייחודיים שלכם כשמטמיעים את ארכיטקטורת ההפניה הזו בסביבה שלכם.
מקביליות
שיטה מומלצת: מגדירים את הפרמטר parallelism בתבנית Pub/Sub to Splunk Dataflow כך שיהיה כפול ממספר ה-vCPU שמשמש את המספר המקסימלי של עובדי Dataflow.
הפרמטר parallelism עוזר למקסם את מספר החיבורים המקבילים של Splunk HEC, וכך למקסם את שיעור ה-EPS של צינור הנתונים.
ערך ברירת המחדל parallelism של 1 משבית את ההפעלה המקבילית ומגביל את קצב הפלט. כדי להביא בחשבון 2 עד 4 חיבורים מקבילים לכל vCPU, עם המספר המקסימלי של תהליכי worker שנפרסו, צריך לבטל את הגדרת ברירת המחדל הזו. ככלל, כדי לחשב את ערך ברירת המחדל של ההגדרה הזו, מכפילים את המספר המקסימלי של עובדי Dataflow במספר המעבדים הווירטואליים לכל עובד, ואז מכפילים את הערך הזה ב-2.
כדי לקבוע את המספר הכולל של חיבורים מקבילים ל-Splunk HEC בכל העובדים של Dataflow, משתמשים בנוסחה הבאה:
דוגמה לחישוב: אם מספר המעבדים הווירטואליים המקסימלי הוא 8, כמו בדוגמה שחישבנו קודם, הנוסחה הזו תיתן את מספר החיבורים המקבילים: 8 x 2 = 16.
בדוגמה הזו, מגדירים את הפרמטר parallelism לערך 16 על סמך החישוב מהדוגמה הקודמת. עם זאת, חשוב לזכור להשתמש בערכים ובחישובים הייחודיים שלכם כשמפעילים את ארכיטקטורת ההפניה הזו בסביבה שלכם.
מספר הבקשות באצווה
שיטה מומלצת: כדי לאפשר ל-Splunk HEC לעבד אירועים בקבוצות ולא אחד בכל פעם, צריך להגדיר את הפרמטר batchCount לערך שבין 10 ל-50 אירועים/בקשה ליומנים.
הגדרת מספר הפריטים בחבילה עוזרת להגדיל את מספר האירועים לשנייה (EPS) ולהפחית את העומס על נקודת הקצה של Splunk HEC. ההגדרה משלבת כמה אירועים בחבילה אחת כדי לייעל את העיבוד. מומלץ להגדיר את הפרמטר batchCount לערך שבין 10 ל-50 אירועים/בקשה עבור יומנים, בתנאי שעיכוב החיץ המקסימלי של שתי שניות מקובל.
מכיוון שהגודל הממוצע של הודעת יומן הוא 1KB בדוגמה הזו, מומלץ לשלוח לפחות 10 אירועים בכל בקשה. בדוגמה הזו, צריך להגדיר את הפרמטר batchCount לערך 10. עם זאת, חשוב לזכור להשתמש בערכים ובחישובים הייחודיים שלכם כשמפעילים את ארכיטקטורת ההפניה הזו בסביבה שלכם.
למידע נוסף על ההמלצות האלה לשיפור הביצועים ואופטימיזציה של העלויות, אפשר לעיין במאמר בנושא תכנון צינורות Dataflow.
המאמרים הבאים
- רשימה מלאה של פרמטרים של תבנית Pub/Sub ל-Splunk Dataflow זמינה במסמכי התיעוד של Pub/Sub ל-Splunk Dataflow.
- תבניות Terraform תואמות שיעזרו לכם לפרוס את ארכיטקטורת העזר הזו זמינות במאגר GitHub
terraform-splunk-log-export. הוא כולל לוח בקרה מוכן מראש של Cloud Monitoring למעקב אחרי צינור עיבוד הנתונים של Splunk Dataflow. - פרטים נוספים על מדדים מותאמים אישית של Splunk Dataflow ועל רישום ביומן כדי לעזור לכם לעקוב אחרי צינורות הנתונים של Splunk Dataflow ולפתור בעיות בהם זמינים בבלוג New observability features for your Splunk Dataflow streaming pipelines.
- לדוגמאות נוספות של ארכיטקטורות, תרשימים ושיטות מומלצות, עיינו במאמר Cloud Architecture Center.