
במאמר הזה מתוארות כמה ארכיטקטורות שמספקות זמינות גבוהה (HA) לפריסות של PostgreSQL ב- Google Cloud. זמינות גבוהה היא מדד לחוסן של המערכת בתגובה לכשל בתשתית הבסיסית. במסמך הזה, המונח HA מתייחס לזמינות של אשכולות PostgreSQL בתוך אזור יחיד בענן או בין כמה אזורים, בהתאם לארכיטקטורת ה-HA.
המסמך הזה מיועד לאדמינים של מסדי נתונים, לארכיטקטים של ענן ולמהנדסי DevOps שרוצים ללמוד איך לשפר את האמינות של שכבת הנתונים ב-PostgreSQL על ידי שיפור זמן הפעולה הכולל של המערכת. במאמר הזה נסביר על מושגים שרלוונטיים להרצת PostgreSQL ב-Compute Engine. במסמך לא מוסבר על שימוש במסדי נתונים מנוהלים כמו Cloud SQL ל-PostgreSQL ו-AlloyDB ל-PostgreSQL.
אם מערכת או אפליקציה דורשות מצב מתמשך כדי לטפל בבקשות או בעסקאות, שכבת התמדת הנתונים (שכבת הנתונים) צריכה להיות זמינה כדי לטפל בהצלחה בבקשות לשאילתות או לשינויים בנתונים. השבתה בשכבת הנתונים מונעת מהמערכת או מהאפליקציה לבצע את המשימות הנדרשות.
בהתאם ליעדים למדידת רמת השירות (SLO) של המערכת, יכול להיות שתצטרכו ארכיטקטורה שתספק רמת זמינות גבוהה יותר. יש יותר מדרך אחת להשיג זמינות גבוהה, אבל באופן כללי, אתם מקצים תשתית מיותרת שאפשר להפוך במהירות לזמינה לאפליקציה שלכם.
במסמך הזה מפורטים הנושאים הבאים:
- הגדרות של מונחים שקשורים למושגים של מסד נתונים עם זמינות גבוהה.
- אפשרויות לטופולוגיות של HA PostgreSQL.
- מידע הקשרי שיעזור לכם לשקול כל אחת מהאפשרויות לארכיטקטורה.
הסברים על המונחים
המונחים והמושגים הבאים הם סטנדרטיים בתעשייה, וכדאי להכיר אותם גם למטרות אחרות שלא נכללות במסגרת המסמך הזה.
- שכפול
-
התהליך שבו טרנזקציות כתיבה (
INSERT,UPDATEאוDELETE) ושינויים בסכימה (שפת הגדרת נתונים (DDL)) מתועדים באופן מהימן ביומן, ואז מוחלים באופן סדרתי על כל הצמתים המשוכפלים של מסד הנתונים במורד הזרם בארכיטקטורה. - צומת ראשי
- הצומת שמספק קריאה עם המצב העדכני ביותר של נתונים שנשמרו. כל פעולות הכתיבה במסד הנתונים צריכות להיות מופנות לצומת ראשי.
- צומת רפליקה (משני)
- עותק אונליין של צומת מסד הנתונים הראשי. השינויים משוכפלים באופן סינכרוני או אסינכרוני לצמתי העתקה מצומת ראשי. אפשר לקרוא מתוך צמתי העתקה, אבל צריך להבין שהנתונים עשויים להתעדכן באיחור קל בגלל פרק הזמן מהחשיפה להמרה.
- פרק הזמן שחלף מאז השכפול
- מדידה, במספר רצף יומן (LSN), במזהה עסקה או בזמן. העיכוב בשכפול מבטא את ההבדל בין המועד שבו פעולות שינוי מוחלות על העותק לבין המועד שבו הן מוחלות על הצומת הראשי.
- העברה רציפה לארכיון
- גיבוי מצטבר שבו מסד הנתונים שומר ברציפות עסקאות רציפות בקובץ.
- יומן כתיבה מראש (WAL)
- יומן WAL הוא קובץ יומן שמתעד שינויים בקובצי נתונים לפני שהשינויים מבוצעים בפועל בקבצים. במקרה של קריסת שרת, WAL היא דרך סטנדרטית לוודא את תקינות הנתונים ועמידות הכתיבה.
- רשומת WAL
- רשומה של עסקה שחלה על מסד הנתונים. רשומת WAL מעוצבת ומאוחסנת כסדרה של רשומות שמתארות שינויים ברמת הדף בקובץ הנתונים.
- מספר סידורי ביומן (LSN)
- עסקאות יוצרות רשומות WAL שמצורפות לקובץ WAL. המיקום שבו מתבצעת ההוספה נקרא מספר סידורי ביומן (LSN). זהו מספר שלם בן 64 ביט, שמיוצג כשני מספרים הקסדצימליים שמופרדים על ידי קו נטוי (XXXXXXXX/YYZZZZZZ). האות Z מייצגת את מיקום ההיסט בקובץ WAL.
- קבצים של פלחים
- קבצים שמכילים כמה שיותר רשומות WAL, בהתאם לגודל הקובץ שהגדרתם. לשמות של קובצי פלחים יש עלייה מונוטונית, וגודל הקובץ המוגדר כברירת מחדל הוא 16MB.
- שכפול סינכרוני
-
סוג של שכפול שבו השרת הראשי מחכה שהעותק יאשר שהנתונים נכתבו
ביומן העסקאות של העותק לפני שהוא מאשר התחייבות ללקוח. כשמריצים שכפול סטרימינג, אפשר להשתמש באפשרות
synchronous_commitשל PostgreSQL, שעוזרת להבטיח עקביות בין השרת הראשי לבין העותק המשוכפל. - שכפול אסינכרוני
- סוג של שכפול שבו השרת הראשי לא מחכה שהעותק ישלח אישור שהעסקה התקבלה בהצלחה לפני שהוא מאשר את ביצוע השינוי ללקוח. ההשהיה בשכפול אסינכרוני נמוכה יותר בהשוואה לשכפול סינכרוני. עם זאת, אם השרת הראשי קורס והעסקאות שאושרו בו לא מועברות לשרת המשני, יש סיכוי לאובדן נתונים. שכפול אסינכרוני הוא מצב השכפול שמוגדר כברירת מחדל ב-PostgreSQL, באמצעות העברת יומנים מבוססת-קובץ או שכפול סטרימינג.
- העברת יומנים מבוססת-קבצים
- שיטת שכפול ב-PostgreSQL שמעבירה את קובצי פלח ה-WAL משרת מסד הנתונים הראשי אל העותק המשוכפל. השרת הראשי פועל במצב ארכיון רציף, וכל שירות המתנה פועל במצב שחזור רציף כדי לקרוא את קובצי ה-WAL. סוג השכפול הזה הוא אסינכרוני.
- שכפול של סטרימינג
- שיטת שכפול שבה העותק מתחבר למקור ומקבל באופן רציף רצף של שינויים. העדכונים מגיעים דרך זרם, ולכן השיטה הזו מאפשרת לשמור על העתק מעודכן יותר של הנתונים בהשוואה לשכפול של יומני משלוח. למרות שהשכפול הוא אסינכרוני כברירת מחדל, אפשר גם להגדיר שכפול סינכרוני.
- שכפול פיזי של סטרימינג
- שיטת שכפול שמעבירה שינויים לרפליקה. בשיטה הזו נעשה שימוש ברשומות WAL שמכילות את השינויים הפיזיים בנתונים בצורה של כתובות של בלוקים בדיסק ושינויים ברמת הבייט.
- שכפול לוגי של נתונים בזמן אמת
- שיטת רפליקציה שמתעדת שינויים על סמך זהות הרפליקציה שלהם (מפתח ראשי), ומאפשרת יותר שליטה באופן הרפליקציה של הנתונים בהשוואה לרפליקציה פיזית. בגלל ההגבלות בשכפול לוגי ב-PostgreSQL, שכפול לוגי של סטרימינג דורש הגדרה מיוחדת להגדרה של זמינות גבוהה. במדריך הזה נדון בשכפול פיזי רגיל, ולא בשכפול לוגי.
- זמן פעולה תקינה
- אחוז הזמן שבו מקור מידע פועל ויכול לספק תגובה לבקשה.
- זיהוי כשלים
- התהליך של זיהוי כשל בתשתית.
- יתירות כשל
- התהליך של קידום תשתית הגיבוי או ההמתנה (במקרה הזה, צומת השכפול) כדי שתהפוך לתשתית הראשית. במהלך מעבר לגיבוי, צומת העותק הופך לצומת הראשי.
- מעבר
- התהליך של הפעלת מעבר ידני לגיבוי במערכת ייצור. החלפה בין צמתים בודקת אם המערכת פועלת בצורה תקינה, או מוציאה את הצומת הראשי הנוכחי מהאשכול לצורך תחזוקה.
- יעד משך ההתאוששות (RTO)
- משך הזמן שחלף, בזמן אמת, עד לסיום תהליך המעבר לגיבוי (failover) של שכבת הנתונים. ה-RTO תלוי בכמות הזמן שמקובלת מנקודת מבט עסקית.
- יעד להתאוששות מאסון (RPO)
- כמות אובדן הנתונים (בזמן אמת שחלף) שרמת הנתונים יכולה לשמור כתוצאה מיתירות כשל. ה-RPO תלוי בכמות אובדן הנתונים שמקובלת מנקודת מבט עסקית.
- חלופי
- התהליך של החזרת הצומת הראשי הקודם אחרי שהתנאי שגרם למעבר לגיבוי (failover) תוקן.
- תיקון עצמי
- היכולת של מערכת לפתור בעיות בלי פעולות חיצוניות של מפעיל אנושי.
- חלוקת רשת למחיצות
- מצב שבו שני צמתים בארכיטקטורה – למשל הצומת הראשי והצומת המשוכפל – לא יכולים לתקשר אחד עם השני ברשת.
- מוח חצוי
- מצב שמתרחש כששני צמתים מאמינים בו-זמנית שהם הצומת הראשי.
- קבוצת צמתים
- קבוצה של משאבי מחשוב שמספקים שירות. במסמך הזה, השירות הזה הוא שכבת שימור הנתונים.
- צומת עדים או צומת קוורום
- משאב נפרד של מחשוב שעוזר לקבוצת צמתים לקבוע מה לעשות כשמתרחש מצב של פיצול מוח.
- בחירות ראשיות או בחירות למנהיגות
- התהליך שבו קבוצה של צמתים עם מודעות לעמיתים, כולל צמתים של עדים, קובעת איזה צומת צריך להיות הצומת הראשי.
מתי כדאי לשקול ארכיטקטורת HA
ארכיטקטורות HA מספקות הגנה משופרת מפני השבתה של שכבת הנתונים בהשוואה להגדרות של מסד נתונים עם צומת יחיד. כדי לבחור את האפשרות הכי טובה לתרחיש השימוש בעסק, צריך להבין מהי הסבילות שלכם להשבתה, ואת היתרונות והחסרונות של הארכיטקטורות השונות.
משתמשים בארכיטקטורת HA כשרוצים לספק זמן פעולה ממושך יותר של שכבת הנתונים כדי לעמוד בדרישות האמינות של עומסי העבודה והשירותים. אם הסביבה שלכם יכולה לסבול כמות מסוימת של זמן השבתה, ארכיטקטורה של זמינות גבוהה עלולה להוסיף עלויות ומורכבות מיותרות. לדוגמה, בסביבות פיתוח או בדיקה, בדרך כלל לא נדרשת זמינות גבוהה של רמת מסד הנתונים.
הגדרת הדרישות לזמינות גבוהה
הנה כמה שאלות שיעזרו לכם להחליט איזו אפשרות של זמינות גבוהה ב-PostgreSQL מתאימה לעסק שלכם:
- מהי רמת הזמינות שאתם רוצים להשיג? האם נדרשת לך אפשרות שתאפשר לשירות שלך להמשיך לפעול רק במהלך אזור יחיד או כשל אזורי מלא? חלק מהאפשרויות לזמינות גבוהה מוגבלות לאזור מסוים, ואחרות יכולות להיות רלוונטיות לכמה אזורים.
- אילו שירותים או לקוחות מסתמכים על רמת הנתונים שלכם, ומה העלות לעסק שלכם אם יש זמן השבתה ברמת הנתונים של שמירת הנתונים? אם שירות מיועד רק ללקוחות פנימיים שנדרשים להשתמש במערכת מדי פעם, סביר להניח שדרישות הזמינות שלו נמוכות יותר מאלה של שירות שפונה ללקוחות קצה ומשרת אותם באופן רציף.
- מה התקציב התפעולי שלך? העלות היא שיקול חשוב: כדי לספק זמינות גבוהה, סביר להניח שהעלויות של התשתית והאחסון יגדלו.
- עד כמה התהליך צריך להיות אוטומטי, ובאיזו מהירות צריך לבצע מעבר לגיבוי? (מהו ה-RTO שלך?) אפשרויות ה-HA משתנות בהתאם למהירות שבה המערכת יכולה לבצע מעבר לגיבוי ולחזור להיות זמינה ללקוחות.
- האם אתם יכולים להרשות לעצמכם לאבד נתונים כתוצאה ממעבר לגיבוי? (מהו ה-RPO שלך?) בגלל האופי המבוזר של טופולוגיות HA, יש פשרה בין זמן האחזור של ביצוע פעולות (commit) לבין הסיכון לאובדן נתונים בגלל כשל.
איך HA עובד
בקטע הזה מתואר הסטרימינג והשכפול הסינכרוני של הסטרימינג שמהווים בסיס לארכיטקטורות של זמינות גבוהה ב-PostgreSQL.
שכפול בסטרימינג
שכפול סטרימינג הוא גישה לשכפול שבה העותק מתחבר למקור ומקבל באופן רציף זרם של רשומות WAL. בהשוואה לשכפול של יומני רישום, שכפול של נתונים בזמן אמת מאפשר לשכפול להישאר מעודכן יותר ביחס למקור. PostgreSQL מציע שכפול סטרימינג מובנה החל מגרסה 9. פתרונות רבים של HA ב-PostgreSQL משתמשים בשכפול סטרימינג מובנה כדי לספק את המנגנון לשמירה על סנכרון בין כמה צמתים של העתקים ב-PostgreSQL לבין הצומת הראשי. בהמשך המאמר, בקטע ארכיטקטורות של זמינות גבוהה ב-PostgreSQL, נדון בכמה מהאפשרויות האלה.
כל צומת שכפול דורש משאבי מחשוב ואחסון ייעודיים. תשתית של צומת רפליקה נפרדת מהתשתית של הצומת הראשי. אפשר להשתמש בצמתי העתקה כגיבוי פעיל כדי להציג שאילתות לקוח לקריאה בלבד. הגישה הזו מאפשרת איזון עומסים של שאילתות לקריאה בלבד בין השרת הראשי לבין עותק אחד או יותר.
שכפול סטרימינג הוא אסינכרוני כברירת מחדל. השרת הראשי לא ממתין לאישור מהרפליקה לפני שהוא מאשר את ביצוע העסקה ללקוח. אם השרת הראשי נכשל אחרי שהוא מאשר את העסקה, אבל לפני שההעתק מקבל את העסקה, שכפול אסינכרוני עלול לגרום לאובדן נתונים. אם העותק המשוכפל קודם והופך לשרת ראשי חדש, העסקה הזו לא תופיע.
שכפול סינכרוני של סטרימינג
אפשר להגדיר שכפול בסטרימינג כסינכרוני על ידי בחירה של רפליקה אחת או יותר שתהיה רפליקת המתנה סינכרונית. אם מגדירים את הארכיטקטורה לשכפול סינכרוני, השרת הראשי לא מאשר את ביצוע העסקה עד שהרפליקה מאשרת את התמדת העסקה. שכפול סינכרוני של נתונים בזמן אמת מספק עמידות משופרת בתמורה לזמן אחזור גבוה יותר של טרנזקציות.
אפשרות ההגדרה synchronous_commit מאפשרת גם להגדיר את רמות העמידות המתקדמות הבאות של העותק המשוכפל עבור העסקה:
-
local: רפליקות במצב המתנה סינכרוני לא מעורבות באישור של ביצוע הפעולה. השרת הראשי מאשר את ביצוע העסקאות אחרי שרשומות WAL נכתבות ומועברות לדיסק המקומי שלו. התחייבויות לעסקאות בשרת הראשי לא כוללות רפליקות במצב המתנה. אם יש כשל בשרת הראשי, יכול להיות שהעסקאות יאבדו. -
on[ברירת מחדל]: העתקים משניים במצב המתנה סינכרוני כותבים את העסקאות שאושרו ב-WAL שלהם לפני שהם שולחים אישור לשרת הראשי. השימוש בהגדרהonמבטיח שהעסקה תאבד רק אם יתרחשו בו-זמנית כשלים באחסון של העותק הראשי ושל כל העותקים הסינכרוניים למקרה חירום. מכיוון שהרפליקות שולחות אישור רק אחרי שהן כותבות רשומות WAL, לקוחות שמבצעים שאילתות ברפליקה לא יראו שינויים עד שהרשומות המתאימות של WAL יוחלו על מסד הנתונים של הרפליקה. -
remote_write: עותקים משוכפלים במצב המתנה סינכרוני מאשרים את קבלת רשומת ה-WAL ברמת מערכת ההפעלה, אבל הם לא מבטיחים שרשומת ה-WAL נכתבה לדיסק. מכיוון שהפקודהremote_writeלא מבטיחה שה-WAL נכתב, יכול להיות שהטרנזקציה תאבד אם תהיה תקלה גם בשרת הראשי וגם בשרת המשני לפני שהרשומות ייכתבו.remote_writeמציע עמידות נמוכה יותר מאשר האפשרותon. -
remote_apply: עותקים משוכפלים סינכרוניים במצב המתנה מאשרים את קבלת העסקה ואת ההחלה שלה על מסד הנתונים לפני שהם מאשרים את ביצוע העסקה ללקוח. השימוש בהגדרהremote_applyמבטיח שהעסקה תישמר בעותק המשוכפל, ושתוצאות השאילתות של הלקוח יכללו באופן מיידי את ההשפעות של העסקה. remote_applyמספק עמידות ועקביות גבוהות יותר בהשוואה ל-onול-remote_write.
אפשרות ההגדרה synchronous_commit פועלת עם אפשרות ההגדרה synchronous_standby_names שמציינת את רשימת השרתים במצב המתנה שמשתתפים בתהליך השכפול הסינכרוני. אם לא מציינים שמות של גיבויים סינכרוניים, אישור העסקאות לא מתבצע עד שהשכפול מסתיים.
ארכיטקטורות HA של PostgreSQL
ברמה הבסיסית ביותר, זמינות גבוהה של שכבת הנתונים מורכבת מהרכיבים הבאים:
- מנגנון לזיהוי כשל בצומת הראשי.
- תהליך לביצוע מעבר לגיבוי במקרה של כשל, שבו צומת העותק מקודם להיות צומת ראשי.
- תהליך לשינוי ניתוב השאילתות כך שבקשות האפליקציה יגיעו לצומת הראשי החדש.
- אופציונלי: שיטה לחזרה לארכיטקטורה המקורית באמצעות צמתים ראשיים וצמתים של העתקים לפני מעבר לגיבוי במקרה של כשל, בקיבולת המקורית שלהם.
בקטעים הבאים מפורטת סקירה כללית של ארכיטקטורות ה-HA הבאות:
- תבנית Patroni
- תוסף ושירות pg_auto_failover
- קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי
פתרונות ה-HA האלה מצמצמים את זמן ההשבתה אם יש תשתית או הפסקת חשמל אזורית. כשבוחרים בין האפשרויות האלה, צריך לאזן בין זמן האחזור של ביצוע הפעולה לבין העמידות בהתאם לצרכים העסקיים.
היבט חשוב בארכיטקטורת HA הוא הזמן והמאמץ הידני שנדרשים כדי להכין סביבת המתנה חדשה למעבר גיבוי או למעבר חזרה. אחרת, המערכת יכולה לעמוד רק בכשל אחד, והשירות לא מוגן מפני הפרה של הסכם רמת השירות. מומלץ לבחור בארכיטקטורת HA שיכולה לבצע מעברים אוטומטיים לגיבוי (failover) או מעברים חזרה (switchover) עם תשתית הייצור.
זמינות גבוהה באמצעות תבנית Patroni
Patroni הוא תבנית תוכנה בקוד פתוח (עם רישיון MIT) שפותחה באופן מלא ומתעדכנת באופן פעיל. התבנית מספקת לכם את הכלים להגדיר, לפרוס ולהפעיל ארכיטקטורת HA של PostgreSQL. Patroni מספק מצב אשכול משותף והגדרת ארכיטקטורה שנשמרים בחנות הגדרות מבוזרת (DCS). אפשרויות להטמעה של DCS כוללות את: etcd, Consul, Apache ZooKeeper או Kubernetes. בתרשים הבא מוצגים הרכיבים העיקריים של אשכול Patroni.
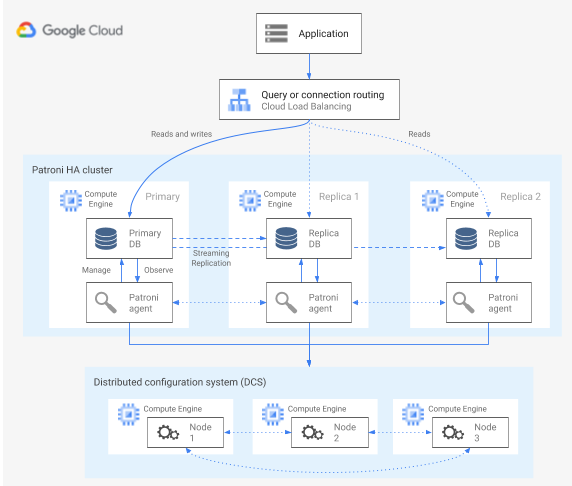
איור 1. תרשים של הרכיבים העיקריים באשכול Patroni.
באיור 1, מאזני העומסים נמצאים מול צמתי PostgreSQL, וסוכני ה-DCS וה-Patroni פועלים בצמתי PostgreSQL.
Patroni מריץ תהליך של סוכן בכל צומת PostgreSQL. תהליך הסוכן מנהל את תהליך PostgreSQL ואת ההגדרה של צומת הנתונים. סוכן Patroni מתאם עם צמתים אחרים דרך DCS. תהליך הסוכן של Patroni חושף גם API בארכיטקטורת REST שאפשר להריץ עליו שאילתות כדי לקבוע את תקינות השירות של PostgreSQL ואת ההגדרה של כל צומת.
כדי לאשר את התפקיד שלו באשכול, הצומת הראשי מעדכן באופן קבוע את מפתח ה-leader ב-DCS. מפתח הלידים כולל אורך חיים (TTL). אם הזמן שמוגדר ל-TTL חולף בלי עדכון, מפתח ה-leader מוצא מה-DCS, ותהליך בחירת ה-leader מתחיל כדי לבחור מפתח ראשי חדש מתוך מאגר המועמדים.
בתרשים הבא מוצג אשכול תקין שבו צומת א' מעדכן בהצלחה את נעילת הצומת הראשי.
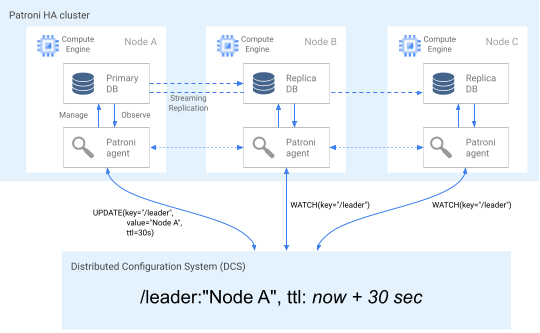
איור 2. תרשים של אשכול תקין.
איור 2 מציג אשכול תקין: צפייה בצומת ב' ובצומת ג' בזמן שצומת א' מעדכן בהצלחה את מפתח הלידים.
זיהוי כשלים
סוכן Patroni משדר את מצב התקינות שלו באופן רציף על ידי עדכון המפתח שלו ב-DCS. במקביל, הסוכן מאמת את תקינות PostgreSQL. אם הסוכן מזהה בעיה, הוא מבצע גידור עצמי של הצומת על ידי כיבוי עצמי, או שהוא מוריד את הצומת לדרגת עותק. כפי שמוצג בתרשים הבא, אם הצומת הפגום הוא הצומת הראשי, מפתח ה-leader שלו ב-DCS יפוג, ותתבצע בחירה חדשה של leader.
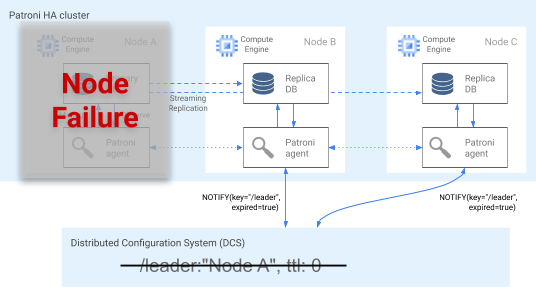
איור 3. תרשים של אשכול פגום.
איור 3 מציג אשכול פגום: צומת ראשי מושבת לא עדכן לאחרונה את מפתח ה-leader שלו ב-DCS, והעותקים המשוכפלים שאינם leader מקבלים הודעה שתוקף מפתח ה-leader פג.
במארחי Linux, Patroni מפעיל גם כלב שמירה ברמת מערכת ההפעלה בצמתים ראשיים. ה-watchdog הזה מאזין להודעות keep-alive מתהליך הסוכן של Patroni. אם התהליך לא מגיב, ולא נשלח אות החיים, מנגנון ה-watchdog מפעיל מחדש את המארח. ה-watchdog עוזר למנוע מצב של פיצול מוח, שבו צומת PostgreSQL ממשיך לשמש כצומת ראשי, אבל מפתח ה-leader ב-DCS פג בגלל כשל בסוכן, ונבחר צומת ראשי (leader) אחר.
תהליך המעבר לגיבוי
אם נעילת הלידר פגה ב-DCS, הצמתים של העותקים המשוכפלים של המועמד מתחילים בבחירת לידר. כשעותק מגלה שחסר נעילת מנהיג, הוא בודק את מיקום השכפול שלו בהשוואה לעותקים האחרים. כל רפליקה משתמשת ב-API ל-REST כדי לקבל את מיקומי יומן ה-WAL של צמתי הרפליקה האחרים, כפי שמוצג בתרשים הבא.
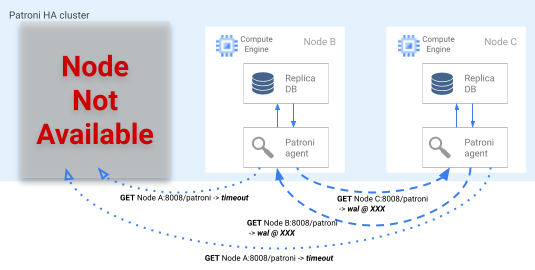
איור 4. תרשים של תהליך המעבר לגיבוי (failover) ב-Patroni.
איור 4 מציג שאילתות של מיקום ביומן WAL ותוצאות מתאימות מצמתי העתק פעילים. הצומת A לא זמין, והצמתים התקינים B ו-C מחזירים זה לזה את אותו מיקום WAL.
הצומת (או הצמתים, אם הם באותו מיקום) הכי עדכני מנסים בו-זמנית לקבל את נעילת ה-Leader ב-DCS. עם זאת, רק צומת אחד יכול ליצור את מפתח המנהל ב-DCS. הצומת הראשון שיצליח ליצור את מפתח המנהיג הוא המנצח במירוץ למנהיגות, כפי שמוצג בתרשים הבא. אפשרות אחרת היא להגדיר מועמדים מועדפים ליתירות כשל על ידי הגדרת התג failover_priority בקובצי התצורה.
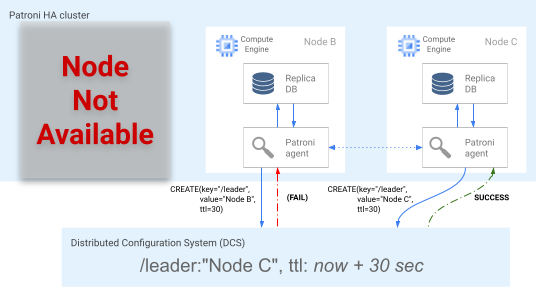
איור 5. דיאגרמה של המירוץ לראשות הטבלה.
באיור 5 מוצג מירוץ לבחירת מנהיג: שני מועמדים לתפקיד מנהיג מנסים להשיג את נעילת המנהיג, אבל רק אחד משני הצמתים, צומת C, מצליח להגדיר את מפתח המנהיג ולנצח במירוץ.
אחרי שהרפליקה זוכה בבחירות, היא מקודמת להיות השרת הראשי החדש. החל מהרגע שבו העותק המשוכפל מקודם, השרת הראשי החדש מעדכן את מפתח ה-leader ב-DCS כדי לשמור על נעילת ה-leader, והצמתים האחרים משמשים כעותקים משוכפלים.
Patroni מספק גם את כלי הבקרה patronictl שמאפשר להריץ מעברים כדי לבדוק את תהליך המעבר האוטומטי בין צמתים.
הכלי הזה עוזר למפעילים לבדוק את הגדרות הזמינות הגבוהה שלהם בסביבת ייצור.
ניתוב שאילתות
תהליך הסוכן של Patroni שפועל בכל צומת חושף נקודות קצה של REST API שמגלות את התפקיד הנוכחי של הצומת: ראשי או משוכפל.
| נקודת קצה של REST | קוד החזרה של HTTP אם הוא ראשי | קוד החזרה של HTTP אם מדובר בעותק |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
בגלל שהתשובות של בדיקות התקינות הרלוונטיות משתנות אם תפקיד של צומת מסוים משתנה, בדיקת תקינות של איזון עומסים יכולה להשתמש בנקודות הקצה האלה כדי להודיע על ניתוב תנועה של צומת ראשי וצומת משוכפל. פרויקט Patroni מספק הגדרות תבנית למאזן עומסים כמו HAProxy. מאזן עומסי רשת פנימי להעברת סיגנל ללא שינוי יכול להשתמש באותן בדיקות תקינות כדי לספק יכולות דומות.
תהליך חלופי
אם יש כשל בצומת, האשכול נשאר במצב פגום. תהליך הגיבוי של Patroni עוזר לשחזר אשכול HA למצב תקין אחרי מעבר לגיבוי. תהליך הגיבוי מנהל את החזרת האשכול למצב המקורי שלו על ידי הפעלה אוטומטית של הצומת המושפע כרפליקה של האשכול.
לדוגמה, יכול להיות שצומת יופעל מחדש בגלל כשל במערכת ההפעלה או בתשתית הבסיסית. אם הצומת הוא הראשי וההפעלה מחדש שלו נמשכת יותר זמן מ-TTL של מפתח ה-leader, מופעלת בחירת leader, נבחר צומת ראשי חדש והוא מקודם. כשמתחיל תהליך Patroni ראשי לא עדכני, הוא מזהה שאין לו את נעילת ה-leader, מוריד את עצמו אוטומטית לדרגת עותק משוכפל ומצטרף לאשכול בתפקיד הזה.
אם יש כשל בצומת שלא ניתן לשחזר, כמו כשל אזורי לא סביר, צריך להפעיל צומת חדש. מפעיל מסד נתונים יכול להפעיל ידנית צומת חדש, או שאפשר להשתמש בקבוצת מופעי מכונה מנוהלים (MIG) אזורית עם שמירת מצב עם מספר צמתים מינימלי כדי להפוך את התהליך לאוטומטי. אחרי שיוצרים את הצומת החדש, Patroni מזהה שהוא חלק מאשכול קיים ומאתחל אותו אוטומטית כרפליקה.
זמינות גבוהה באמצעות התוסף והשירות pg_auto_failover
pg_auto_failover הוא תוסף PostgreSQL בקוד פתוח (רישיון PostgreSQL) שנמצא בפיתוח פעיל. pg_auto_failover מגדיר ארכיטקטורת זמינות גבוהה על ידי הרחבת היכולות הקיימות של PostgreSQL. ל-pg_auto_failover אין תלות בשום דבר מלבד PostgreSQL.
כדי להשתמש בתוסף pg_auto_failover עם ארכיטקטורת HA, צריך לפחות שלושה צמתים, שכל אחד מהם מריץ PostgreSQL עם התוסף המופעל. כל אחד מהצמתים יכול להיכשל בלי להשפיע על זמן הפעולה של קבוצת מסדי הנתונים. אוסף של צמתים שמנוהלים על ידי pg_auto_failover נקרא formation. בתרשים הבא מוצגת ארכיטקטורת pg_auto_failover.
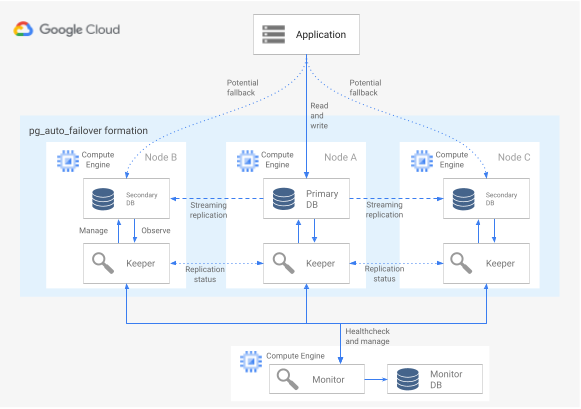
איור 6. תרשים של ארכיטקטורת pg_auto_failover.
באיור 6 מוצגת ארכיטקטורה של pg_auto_failover שמורכבת משני רכיבים עיקריים: שירות Monitor וסוכן Keeper. הכלי Keeper והכלי Monitor כלולים בתוסף pg_auto_failover.
שירותי ניטור
שירות המעקב pg_auto_failover מיושם כתוסף PostgreSQL. כשהשירות יוצר צומת מעקב, הוא מפעיל מופע PostgreSQL עם התוסף pg_auto_failover מופעל. הכלי Monitor שומר על המצב הגלובלי של הקבוצה, מקבל את הסטטוס של בדיקת התקינות מצמתי הנתונים של PostgreSQL, ומנהל את הקבוצה באמצעות הכללים שנקבעו על ידי מכונת מצבים סופית (FSM). בהתאם לכללי ה-FSM למעברים בין מצבים, המערכת Monitor מעבירה הוראות לצמתים בקבוצה לגבי פעולות כמו קידום, הורדה בדרגה ושינויים בהגדרות.
סוכן Keeper
בכל צומת נתונים של pg_auto_failover, התוסף מפעיל תהליך של סוכן Keeper. תהליך Keeper הזה עוקב אחרי שירות PostgreSQL ומנהל אותו. ה-Keeper שולח עדכוני סטטוס לצומת Monitor, ומקבל ומבצע פעולות שה-Monitor שולח בתגובה.
כברירת מחדל, pg_auto_failover מגדיר את כל צמתי הנתונים המשניים בקבוצה כרפליקות סינכרוניות. מספר העותקים הסינכרוניים שנדרשים לביצוע commit מבוסס על ההגדרה number_sync_standby שקובעים ב-Monitor.
זיהוי כשלים
סוכני Keeper בצמתי נתונים ראשיים ומשניים מתחברים מעת לעת לצומת Monitor כדי לדווח על המצב הנוכחי שלהם ולבדוק אם יש פעולות שצריך לבצע. צומת המעקב מתחבר גם לצמתי הנתונים כדי לבצע בדיקת תקינות על ידי הפעלת קריאות ל-API של פרוטוקול PostgreSQL (libpq), בדומה לאפליקציית הלקוח pg_isready() של PostgreSQL. אם אף אחת מהפעולות האלה לא מצליחה אחרי פרק זמן מסוים (30 שניות כברירת מחדל), צומת המעקב קובע שחלה שגיאה בצומת הנתונים. אפשר לשנות את הגדרות התצורה של PostgreSQL כדי להתאים אישית את התזמון של המעקב ואת מספר הניסיונות החוזרים. מידע נוסף זמין במאמר בנושא מעבר לגיבוי כשל וסובלנות תקלות.
אם מתרחש כשל בצומת יחיד, אחד מהתנאים הבאים מתקיים:
- אם צומת הנתונים הלא תקין הוא צומת ראשי, הכלי Monitor מתחיל מעבר לגיבוי.
- אם צומת הנתונים הלא תקין הוא משני, הכלי Monitor משבית את השכפול הסינכרוני עבור הצומת הלא תקין.
- אם הצומת שנכשל הוא צומת המעקב, אי אפשר לבצע מעבר גיבוי אוטומטי. כדי להימנע מנקודת כשל בודדת זו, צריך לוודא שיש מערכת מתאימה למעקב ולתוכנית התאוששות מאסון.
בתרשים הבא מוצגים תרחישי הכשל ומצבי התוצאה של היווצרות שמתוארים ברשימה שלמעלה.
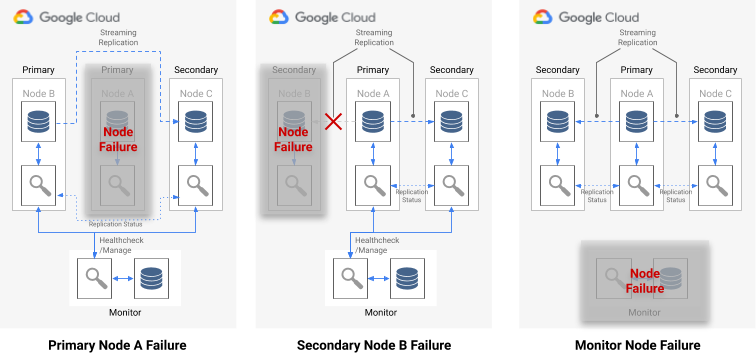
איור 7. תרשים של תרחישי כשל ב-pg_auto_failover.
תהליך המעבר לגיבוי
לכל צומת של מסד נתונים בקבוצה יש את אפשרויות ההגדרה הבאות שקובעות את תהליך המעבר לגיבוי:
-
replication_quorum: אפשרות בוליאנית. אם הערך שלreplication_quorumהואtrue, הצומת נחשב כמועמד פוטנציאלי למעבר לגיבוי. -
candidate_priority: ערך שלם מ-0 עד 100. ערך ברירת המחדל שלcandidate_priorityהוא 50, ואפשר לשנות אותו כדי להשפיע על העדיפות של המעבר לגיבוי. הצמתים מתועדפים כמועמדים פוטנציאליים למעבר לגיבוי (failover) על סמך הערך שלcandidate_priority. לצמתים עם ערךcandidate_priorityגבוה יותר יש עדיפות גבוהה יותר. תהליך המעבר לגיבוי (failover) מחייב שלפחות לשני צמתים תהיה עדיפות מועמדת שאינה אפס בכל תצורת pg_auto_failover.
אם יש כשל בצומת ראשי, צמתים משניים נחשבים לקידום לצומת ראשי אם יש להם שכפול סינכרוני פעיל ואם הם חברים ב-replication_quorum.
הקידום של צמתים משניים מתבצע לפי הקריטריונים הבאים:
- צמתים עם העדיפות הגבוהה ביותר
- מצב המתנה עם מיקום יומן ה-WAL המתקדם ביותר שפורסם במוניטור
- בחירה אקראית כשובר שוויון סופי
מועמד להעברה אוטומטית לגיבוי הוא מועמד עם השהיה אם הוא לא פרסם את מיקום ה-LSN המתקדם ביותר ב-WAL. בתרחיש הזה, pg_auto_failover מתזמן שלב ביניים במנגנון היתירות כשל: המועמד המפגר מאחור מאחזר את הבייטים החסרים של WAL מצומת גיבוי עם מיקום ה-LSN המתקדם ביותר. לאחר מכן, הצומת במצב המתנה מקודם. מערכת Postgres מאפשרת את הפעולה הזו כי שכפול מדורג מאפשר לכל שרת המתנה לפעול כצומת במעלה הזרם עבור שרת המתנה אחר.
ניתוב שאילתות
pg_auto_failover לא מספק יכולות ניתוב שאילתות בצד השרת.
במקום זאת, pg_auto_failover מסתמך על ניתוב שאילתות בצד הלקוח שמשתמש במנהל ההתקן הרשמי של לקוח PostgreSQL libpq.
כשמגדירים את ה-URI של החיבור, מנהל ההתקן יכול לקבל כמה מארחים במילת המפתח host שלו.
ספריית הלקוח שבה האפליקציה משתמשת צריכה לעטוף את libpq או להטמיע את היכולת לספק כמה מארחים כדי שהארכיטקטורה תתמוך ביתירות כשל אוטומטית מלאה.
תהליכי חזרה למצב ראשוני ומעבר
כש-Keeper מפעיל מחדש צומת שנכשל או מתחיל צומת חלופי חדש, התהליך בודק את צומת המעקב כדי לקבוע את הפעולה הבאה שיש לבצע. אם צומת שהופעל מחדש אחרי כשל היה בעבר הצומת הראשי, והכלי Monitor כבר בחר צומת ראשי חדש בהתאם לתהליך המעבר לגיבוי, הכלי Keeper מאתחל מחדש את הצומת הראשי הישן כרפליקה משנית.
pg_auto_failover מספק את הכלי pg_autoctl, שמאפשר להריץ מעברים כדי לבדוק את תהליך היתירות כשל של הצומת. בנוסף לאפשרות למפעילים לבדוק את הגדרות ה-HA שלהם בסביבת ייצור, הכלי עוזר לשחזר אשכול HA למצב תקין אחרי מעבר לגיבוי (failover).
זמינות גבוהה באמצעות קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי
בקטע הזה מתואר גישה לזמינות גבוהה שמשתמשת ברכיבים הבאים של Google Cloud:
- דיסק לאחסון מתמיד אזורי. כשמשתמשים בדיסקים קבועים אזוריים, הנתונים משוכפלים באופן סינכרוני בין שני אזורים באזור, כך שלא צריך להשתמש בשכפול סטרימינג. עם זאת, זמינות גבוהה מוגבלת לשני אזורים בדיוק באזור מסוים.
- קבוצות מנוהלות של מופעי מכונה עם שמירת מצב. זוג של קבוצות מנוהלות של מכונות וירטואליות עם שמירת מצב משמש כחלק ממישור הבקרה כדי להפעיל צומת ראשי אחד של PostgreSQL. כשקבוצת ה-MIG עם שמירת מצב מפעילה מכונה חדשה, היא יכולה לצרף את הדיסק הקיים לאחסון מתמיד אזורי. בכל נקודת זמן, רק אחת משתי קבוצות ה-MIG תכלול מופע פעיל.
- Cloud Storage. אובייקט בקטגוריה של Cloud Storage מכיל הגדרה שמציינת איזה מבין שני ה-MIG מריץ את צומת מסד הנתונים הראשי, ובאיזה MIG צריך ליצור מופע של מעבר לגיבוי.
- בדיקות תקינות של MIG ותיקון אוטומטי. בדיקת התקינות עוקבת אחרי תקינות המופע. אם הצומת הפעיל הופך ללא תקין, בדיקת התקינות מפעילה את תהליך התיקון האוטומטי.
- Logging. כשתיקון אוטומטי מפסיק את הצומת הראשי, נרשמת רשומה ביומן. הרשומות הרלוונטיות ביומן מיוצאות לנושא של יעד Pub/Sub באמצעות מסנן.
- פונקציות Cloud Run מבוססות-אירועים. ההודעה ב-Pub/Sub מפעילה פונקציות Cloud Run. פונקציות Cloud Run משתמשות בהגדרות ב-Cloud Storage כדי לקבוע אילו פעולות לבצע עבור כל קבוצת MIG עם שמירת מצב.
- מאזן עומסי רשת פנימי להעברת סיגנל ללא שינוי. מאזן העומסים מספק ניתוב למכונה הפעילה בקבוצה. כך מובטח ששינוי בכתובת ה-IP של מכונה שנגרם כתוצאה מיצירה מחדש של מכונה יהיה מוסתר מהלקוח.
בתרשים הבא מוצגת דוגמה לזמינות גבוהה באמצעות קבוצות MIG עם שמירת מצב ודיסקים קשיחים אזוריים:

איור 8. תרשים של HA שמשתמש ב-MIG עם שמירת מצב ובדיסקים לאחסון מתמיד אזוריים.
איור 8 מציג צומת ראשי תקין שמשרת תעבורת לקוחות. לקוחות מתחברים לכתובת ה-IP הסטטית של מאזן עומסי הרשת הפנימי להעברת סיגנל ללא שינוי. מאזן העומסים מעביר בקשות של לקוחות למכונה הווירטואלית שפועלת כחלק מקבוצת המכונות המנוהלת. נפחי הנתונים מאוחסנים בדיסקים לאחסון מתמיד אזוריים שמוצמדים.
כדי להטמיע את הגישה הזו, יוצרים תמונה של מכונה וירטואלית עם PostgreSQL שמופעלת באתחול כדי לשמש כתבנית של הגדרות מכונה בקבוצת ה-MIG. צריך גם להגדיר בדיקת תקינות מבוססת-HTTP (כמו HAProxy או pgDoctor) בצומת. בדיקת תקינות מבוססת-HTTP עוזרת לוודא שגם מאזן העומסים וגם קבוצת המופעים יכולים לקבוע את התקינות של צומת PostgreSQL.
דיסק אזורי לאחסון מתמיד
כדי להקצות מכשיר לאחסון בלוקים שמספק שכפול נתונים סינכרוני בין שני אזורים באזור מסוים, אפשר להשתמש באפשרות האחסון regional persistent disk של Compute Engine. דיסק מתמשך אזורי יכול לשמש כאבן בניין בסיסית להטמעה של אפשרות לזמינות גבוהה של PostgreSQL שלא מסתמכת על שכפול הסטרימינג המובנה של PostgreSQL.
אם המכונה הווירטואלית של הצומת הראשי לא זמינה בגלל כשל בתשתית או הפסקה זמנית בשירות באזור, אפשר לחייב את דיסק האחסון המתמיד האזורי להתחבר למכונה וירטואלית באזור הגיבוי באותו אזור.
כדי לצרף את דיסק האחסון המתמיד האזורי למכונה וירטואלית באזור הגיבוי, אפשר לבצע אחת מהפעולות הבאות:
- שומרים על מכונה וירטואלית במצב cold standby באזור הגיבוי. מכונת VM במצב המתנה לא פעיל היא מכונת VM מושבתת שלא מחובר אליה דיסק מתמשך אזורי, אבל היא מכונת VM זהה למכונת ה-VM של הצומת הראשי. אם יש כשל, מכונת ה-VM במצב המתנה קרה מופעלת ודיסק האחסון המתמיד האזורי מותקן בה. במופע של מצב המתנה פעיל ובמופע של הצומת הראשי יש את אותם נתונים.
- יוצרים זוג של קבוצות מנוהלות עם שמירת מצב באמצעות אותה תבנית של הגדרות מכונה. קבוצות ה-MIG מספקות בדיקות תקינות ומשמשות כחלק ממישור הבקרה. אם הצומת הראשי נכשל, נוצרת באופן הצהרתי מכונה של יתירות כשל ב-MIG של היעד. קבוצת ה-MIG של היעד מוגדרת באובייקט Cloud Storage. הגדרות לכל אירוע משמשות לצירוף אחסון מתמיד (persistent disk) אזורי.
אם מזהים במהירות את ההשבתה של שירות הנתונים, פעולת הצירוף הכפוי בדרך כלל מסתיימת תוך פחות מדקה, כך שאפשר להשיג RTO שנמדד בדקות.
אם העסק שלכם יכול לסבול את זמן ההשבתה הנוסף שנדרש כדי לזהות הפסקת חשמל ולדווח עליה, וכדי לבצע את המעבר לגיבוי ידנית, אתם לא צריכים להפוך את תהליך הצירוף הכפוי לאוטומטי. אם סף הטולרנס שלכם ל-RTO נמוך יותר, אתם יכולים להפוך את תהליך הזיהוי והמעבר לגיבוי אוטומטי. לחלופין, Cloud SQL ל-PostgreSQL מספק גם הטמעה מנוהלת מלאה של גישת הזמינות הגבוהה הזו.
זיהוי כשלים ותהליך מעבר לגיבוי (failover)
הגישה לזמינות גבוהה משתמשת ביכולות התיקון האוטומטי של קבוצות מופעי מכונה כדי לעקוב אחרי תקינות הצמתים באמצעות בדיקת תקינות. אם יש בדיקת תקינות שנכשלה, המכונה הקיימת נחשבת ללא תקינה והיא מופסקת. העצירה הזו מתחילה את תהליך המעבר לגיבוי בעזרת Logging, Pub/Sub והפונקציה המופעלת של Cloud Run Functions.
כדי לעמוד בדרישה שהדיסק האזורי תמיד יהיה מחובר למכונה הווירטואלית הזו, אחת משתי קבוצות ה-MIG תוגדר על ידי הפונקציות של Cloud Run ליצירת מופע באחד משני האזורים שבהם הדיסק האזורי לאחסון מתמיד זמין. אם צומת נכשל, המכונה החלופית מופעלת לפי המצב שנשמר ב-Cloud Storage, באזור החלופי.

איור 9. דיאגרמה של כשל אזורי ב-MIG.
באיור 9, הצומת הראשי הקודם באזור א' נכשל, והפונקציות של Cloud Run הגדירו את MIG ב' להפעיל מופע ראשי חדש באזור ב'. מנגנון זיהוי הכשלים מוגדר אוטומטית למעקב אחרי תקינות הצומת הראשי החדש.
ניתוב שאילתות
מאזן עומסי רשת פנימי להעברת סיגנל ללא שינוי מעביר את הלקוחות למכונה שבה פועל שירות PostgreSQL. מאזן העומסים משתמש באותו בדיקת תקינות כמו קבוצת המופעים כדי לקבוע אם המופע זמין לטיפול בשאילתות. אם הצומת לא זמין כי הוא נוצר מחדש, החיבורים ייכשלו. אחרי שהמופע חוזר לפעולה, בדיקות התקינות מתחילות לעבור והחיבורים החדשים מנותבים לצומת הזמין. אין צמתים לקריאה בלבד בהגדרה הזו כי יש רק צומת אחד שפועל.
תהליך חלופי
אם צומת מסד הנתונים נכשל בבדיקת תקינות בגלל בעיה בסיסית בחומרה, הצומת נוצר מחדש במופע בסיסי אחר. בשלב הזה, הארכיטקטורה חוזרת למצב המקורי שלה בלי לבצע שלבים נוספים. עם זאת, אם יש כשל אזורי, ההגדרה ממשיכה לפעול במצב פגום עד שהאזור הראשון מתאושש. למרות שהסיכוי לכך נמוך מאוד, אם יהיו כשלים בו-זמניים בשני האזורים שהוגדרו לשכפול אזורי של דיסק מתמשך ול-MIG עם שמירת מצב, לא תהיה אפשרות לשחזר את מופע PostgreSQL – מסד הנתונים לא יהיה זמין לטיפול בבקשות במהלך ההשבתה.
השוואה בין אפשרויות ה-HA
בטבלאות הבאות מוצגת השוואה בין אפשרויות ה-HA שזמינות ב-Patroni, ב-pg_auto_failover וב-MIGs עם שמירת מצב עם דיסקים קשיחים אזוריים.
הגדרה וארכיטקטורה
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
|
נדרשת ארכיטקטורת HA, הגדרת DCS וניטור והתראות. הגדרת הסוכן בצמתי נתונים היא פשוטה יחסית. |
לא נדרשים יחסי תלות חיצוניים מלבד PostgreSQL. נדרש צומת שמוקדש לניטור. צריך להגדיר זמינות גבוהה (HA) והתאוששות מאסון (DR) בצומת של כלי המעקב כדי לוודא שהוא לא מהווה נקודת כשל יחידה (SPOF). | ארכיטקטורה שמורכבת אך ורק משירותים. Google Cloud אתם מריצים רק צומת מסד נתונים פעיל אחד בכל פעם. |
אפשרות להגדרה של זמינות גבוהה
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
| ניתן להגדרה באופן נרחב: תומך בשכפול סינכרוני ואסינכרוני, ומאפשר לציין אילו צמתים יהיו סינכרוניים ואילו אסינכרוניים. כולל ניהול אוטומטי של הצמתים הסינכרוניים. מאפשר הגדרות HA של כמה אזורים ומספר אזורים. חייבת להיות גישה ל-DCS. | דומה ל-Patroni: ניתן להגדרה במידה רבה. עם זאת, מכיוון שהכלי למעקב זמין רק כמופע יחיד, צריך לקחת בחשבון את הגישה לצומת הזה בכל סוג של הגדרה. | מוגבל לשני תחומים באזור יחיד עם שכפול סינכרוני. |
יכולת לטפל בחלוקת רשת
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
| הגנה עצמית בשילוב עם מעקב ברמת מערכת ההפעלה מספקת הגנה מפני פיצול מוח. אם החיבור ל-DCS נכשל, השרת הראשי יוגדר כרפליקה ויפעיל יתירות כשל כדי להבטיח עמידות על פני זמינות. | משתמש בשילוב של בדיקות תקינות מהשרת הראשי לשרת המעקב ולשרת המשוכפל כדי לזהות חלוקה של הרשת, ומוריד את עצמו בדרגה אם צריך. | לא רלוונטי: יש רק צומת פעיל אחד של PostgreSQL בכל פעם, ולכן אין חלוקה של הרשת. |
עלות
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
| העלות גבוהה כי היא תלויה ב-DCS שתבחרו ובמספר העותקים המשוכפלים של PostgreSQL. ארכיטקטורת Patroni לא מוסיפה עלויות משמעותיות. עם זאת, העלות הכוללת מושפעת מהתשתית הבסיסית, שמשתמשת בכמה מכונות וירטואליות ל-PostgreSQL ול-DCS. האפשרות הזו יכולה להיות הכי יקרה, כי היא משתמשת בכמה רפליקות ובאשכול DCS נפרד. | עלות בינונית כי היא כוללת הפעלה של צומת ניטור ולפחות שלושה צמתי PostgreSQL (אחד ראשי ושניים משוכפלים). | העלות נמוכה כי רק צומת PostgreSQL אחד פועל באופן פעיל בכל זמן נתון. התשלום הוא רק על מופע מחשוב יחיד. |
הגדרת לקוח
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
| החיבור למאזן העומסים שקוף ללקוח. | נדרשת ספריית לקוח שתומכת בהגדרת מספר מארחים בהגדרה כי אי אפשר להשתמש בקלות במאזן עומסים. | החיבור למאזן העומסים שקוף ללקוח. |
מדרגיות
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
| גמישות גבוהה בהגדרת פשרות בין מדרגיות לזמינות. אפשר להוסיף עוד עותקים משוכפלים כדי להגדיל את קצב הקריאה. | בדומה ל-Patroni: אפשר להוסיף עוד עותקים כדי להרחיב את קריאת הנתונים. | הגמישות מוגבלת כי בכל זמן נתון יש רק צומת PostgreSQL פעיל אחד. |
אוטומציה של אתחול צומת PostgreSQL, ניהול תצורה
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
מספק כלים לניהול ההגדרה של PostgreSQL (patronictl
edit-config) ומאתחל אוטומטית צמתים חדשים או צמתים שהופעלו מחדש באשכול. אפשר לאתחל צמתים באמצעות pg_basebackup או כלים אחרים כמו barman.
|
מאתחל אוטומטית צמתים, אבל מוגבל לשימוש רק ב-pg_basebackup כשמאתחלים צומת שכפול חדש.
ניהול ההגדרות מוגבל להגדרות שקשורות ל-pg_auto_failover.
|
קבוצת מכונות עם מצב (Stateful) ודיסק משותף מבטלת את הצורך באתחול של צומת PostgreSQL. מכיוון שתמיד פועל רק צומת אחד, ניהול ההגדרות מתבצע בצומת יחיד. |
אפשרויות התאמה אישית ומגוון תכונות
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
|
ממשק hook שמאפשר להגדיר פעולות שיופעלו בשלבים מרכזיים, כמו הורדה או העלאה של רמת ההרשאה. אפשרויות הגדרה רבות, כמו תמיכה בסוגים שונים של DCS, אמצעים שונים לאתחול רפליקות ודרכים שונות לספק הגדרות של PostgreSQL. מאפשר להגדיר אשכולות במצב המתנה שמאפשרים להעביר אשכולות משוכפלים מדורגים כדי להקל על ההעברה בין אשכולות. |
מוגבל כי מדובר בפרויקט חדש יחסית. | לא רלוונטי. |
סיווג תוכן
| Patroni | pg_auto_failover | קבוצות MIG עם שמירת מצב ודיסקים לאחסון מתמיד אזורי |
|---|---|---|
| הפרויקט זמין מאז 2015, והוא נמצא בשימוש בסביבת ייצור בחברות גדולות כמו Zalando ו-GitLab. | פרויקט חדש יחסית שהוכרז בתחילת 2019. | המוצרים שמופיעים בו זמינים בדרך כלל Google Cloud . |
שיטות מומלצות לתחזוקה ולמעקב
חשוב לתחזק ולנטר את אשכול ה-HA של PostgreSQL כדי להבטיח זמינות גבוהה, שלמות נתונים וביצועים אופטימליים. בקטעים הבאים מפורטות כמה שיטות מומלצות למעקב אחרי אשכול PostgreSQL HA ולתחזוקה שלו.
ביצוע גיבויים קבועים ובדיקות שחזור
מומלץ לגבות באופן קבוע את מסדי הנתונים של PostgreSQL ולבדוק את תהליך השחזור. כך אפשר לשמור על תקינות הנתונים ולמזער את זמן ההשבתה במקרה של הפסקת שירות. כדאי לבדוק את תהליך השחזור כדי לוודא שהגיבויים תקינים ולזהות בעיות פוטנציאליות לפני שמתרחשת הפסקת שירות.
מעקב אחרי שרתי PostgreSQL וזמן השהייה של השכפול
עוקבים אחרי שרתי PostgreSQL כדי לוודא שהם פועלים. מעקב אחרי זמן ההשהיה של השכפול בין הצומת הראשי לצומת המשוכפל. פיגור מוגזם עלול להוביל לחוסר עקביות בנתונים ולאובדן נתונים מוגבר במקרה של יתירות כשל. כדאי להגדיר התראות על עליות משמעותיות בפיגור ולבדוק את שורש הבעיה בהקדם.
שימוש בתצוגות כמו pg_stat_replication ו-pg_replication_slots יכול לעזור לכם לעקוב אחרי פרק הזמן מהחשיפה להמרה.
הטמעה של מאגר חיבורים
שימוש במאגר חיבורים יכול לעזור לכם לנהל ביעילות את החיבורים למסד הנתונים. איגום חיבורים עוזר לצמצם את התקורה של יצירת חיבורים חדשים, וכך לשפר את ביצועי האפליקציה ואת היציבות של שרת מסד הנתונים. כלים כמו PGBouncer ו-Pgpool-II יכולים לספק איגום חיבורים ל-PostgreSQL.
הטמעה של מעקב מקיף
כדי לקבל תובנות לגבי אשכולות PostgreSQL HA, צריך להקים מערכות ניטור חזקות באופן הבא:
- אתם יכולים לעקוב אחרי מדדים חשובים של PostgreSQL ומערכת, כמו ניצול המעבד (CPU), שימוש בזיכרון, קלט/פלט (I/O) בדיסק, פעילות ברשת וחיבורים פעילים.
- איסוף יומנים של PostgreSQL, כולל יומני שרת, יומני WAL ויומני autovacuum, לניתוח מעמיק ולפתרון בעיות.
- כדי לזהות בעיות במהירות, אפשר להשתמש בכלי מעקב ובלוחות בקרה כדי להמחיש את המדדים והיומנים.
- שילוב מדדים ויומנים עם מערכות התראות כדי לקבל התראה יזומה על בעיות פוטנציאליות.
מידע נוסף על מעקב אחרי מופע של Compute Engine זמין במאמר סקירה כללית על Cloud Monitoring.
המאמרים הבאים
- מידע על הגדרת זמינות גבוהה ב-Cloud SQL
- מידע נוסף על אפשרויות זמינות גבוהה באמצעות דיסק קשיח אזורי
- מידע נוסף על Patroni
- מידע נוסף על pg_auto_failover
- לדוגמאות נוספות של ארכיטקטורות, תרשימים ושיטות מומלצות, עיינו במאמר Cloud Architecture Center.
שותפים ביצירת התוכן
Author: Alex Cârciu | Solutions Architect