
בדף הזה מוסבר איך הקצאת משאבים לפי התפוקה שנקבעה פועלת, איך לשלוט בחריגות או לעקוף את הקצאת משאבים לפי התפוקה שנקבעה ואיך לעקוב אחרי השימוש.
איך הקצאת משאבים לפי התפוקה שנקבעה פועלת
בקטע הזה מוסבר איך הקצאת משאבים לפי התפוקה שנקבעה פועלת באמצעות בדיקת המכסה במהלך תקופת אכיפת המכסה.
בדיקת מכסת הקצאת משאבים לפי התפוקה שנקבעה
המכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה היא מכפלה של מספר יחידות ההרחבה של ה-AI הגנרטיבי (GSU) שנרכשו והתפוקה לכל GSU. הבדיקה מתבצעת בכל פעם ששולחים בקשה במסגרת תקופת האכיפה של המכסה, כלומר התדירות שבה נאכפת המכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה.
בזמן קבלת הבקשה, גודל התגובה האמיתי לא ידוע. מכיוון שאנחנו נותנים עדיפות למהירות התגובה באפליקציות בזמן אמת, הקצאת משאבים לפי התפוקה שנקבעה מעריכה את גודל הטוקן של הפלט. אם האומדן הראשוני חורג מהמכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה הזמינה, הבקשה מעובדת כתשלום לפי שימוש. אחרת, היא מעובדת כהקצאת משאבים לפי התפוקה שנקבעה. ההשוואה מתבצעת בין האומדן הראשוני לבין המכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה.
כשהתשובה נוצרת וגודל האסימון של הפלט האמיתי ידוע, המערכת מתקנת את נתוני השימוש והמכסה בפועל על ידי הוספת ההפרש בין ההערכה לבין השימוש בפועל לסכום המכסה הזמין של הקצאת משאבים לפי התפוקה שנקבעה.
חלונות לאכיפת מכסת הקצאת משאבים לפי התפוקה שנקבעה
Vertex AI משתמש בחלון דינמי כדי לאכוף את מכסת הקצאת המשאבים לפי התפוקה שנקבעה למודלים של Gemini. כך תוכלו להשיג יציבות אופטימלית בתנועה שנוטה לעליות חדות. במקום חלון קבוע, מערכת Vertex AI אוכפת את המכסה על חלון גמיש שמתכוונן אוטומטית, בהתאם לסוג המודל ולמספר יחידות ה-GSU שהקציתם. כתוצאה מכך, יכול להיות שבמקרים מסוימים תהיה לכם באופן זמני תנועה בעדיפות גבוהה שתחרוג ממכסת השימוש שלכם על בסיס שנייה. עם זאת, אסור לחרוג מהמכסה במהלך חלון הזמן. התקופות האלה מבוססות על השעה בשעון הפנימי של Vertex AI, והן לא תלויות במועד שליחת הבקשות.
איך פועל חלון האכיפה של המכסה
חלון האכיפה קובע עד כמה אפשר לחרוג מהמגבלה לשנייה, לפני שמתבצעת הגבלת קצב. החלון הזה מוחל באופן אוטומטי. שימו לב: יכול להיות שיהיו שינויים בחלונות האלה כדי לשפר את הביצועים והמהימנות.
הקצאות קטנות של יחידות GSU (3 יחידות GSU או פחות): חלון הזמן יכול להיות בין 40 ל-120 שניות כדי לאפשר עיבוד של בקשות גדולות יותר ללא הפרעה.
לדוגמה, אם קונים יחידת GSU אחת של
gemini-2.5-flash, מקבלים בממוצע 2,690 אסימונים לשנייה של תפוקה רציפה. השימוש הכולל שלכם בכל חלון של 120 שניות לא יכול לעלות על 322,800 אסימונים (2,690 אסימונים לשנייה * 120 שניות). לכן, אם תשלחו בקשה שמשתמשת ב-70,000 טוקנים לשנייה, אבל השימוש הכולל במשך 120 שניות יישאר מתחת ל-322,800 טוקנים, אז השימוש ב-70,000 טוקנים לשנייה עדיין ייחשב כהקצאת משאבים לפי התפוקה שנקבעה, כי השימוש הממוצע לא יעלה על 2,690 טוקנים לשנייה.הקצאות רגילות (בגודל בינוני) של יחידות GSU (יותר מ-3 יחידות GSU): בהטמעות של יחידות GSU בגודל בינוני (לדוגמה, פחות מ-50 יחידות GSU), חלון הזמן יכול להיות בין 5 שניות ל-30 שניות. הסף והחלונות של ההקשר משתנים בהתאם למודל.
לדוגמה, אם קונים 25 יחידות GSU של
gemini-2.5-flash, מקבלים תפוקה רציפה של 67,250 טוקנים בממוצע לשנייה (2,690 טוקנים לשנייה כפול 25). השימוש הכולל שלכם בכל חלון של 30 שניות לא יכול לעלות על 2,017,500 אסימונים (67,250 אסימונים לשנייה * 30 שניות). לכן, אם תשלחו בקשה שמשתמשת ב-1,000,000 טוקנים לשנייה, אבל סך השימוש במשך 30 שניות יישאר בטווח של 2,017,500 טוקנים, עדיין ייחשב השימוש ב-1,000,000 טוקנים לשנייה כהקצאת משאבים לפי התפוקה שנקבעה, כי השימוש הממוצע לא יעלה על 67,250 טוקנים לשנייה.הקצאות GSU ברמת דיוק גבוהה (בפריסה רחבת היקף): בפריסות GSU רחבות היקף (לדוגמה, 50 GSU או יותר), חלון הזמן יכול להיות בין שנייה אחת ל-5 שניות, כדי להבטיח שעיבוד הבקשות בתדירות גבוהה יתבצע ברמת הדיוק המקסימלית בכל התשתית.
לדוגמה, אם קונים 250 יחידות GSU של
gemini-2.5-flash, מקבלים תפוקה רציפה של 672,500 טוקנים בממוצע לשנייה (250 כפול 2,690 טוקנים לשנייה). השימוש הכולל שלכם בכל חלון של 5 שניות לא יכול לעלות על 3,362,500 טוקנים (672,500 טוקנים בשנייה * 5 שניות). לכן, אם תשלחו בקשה שמשתמשת ב-5,000,000 טוקנים בשנייה, היא לא תעובד כהקצאת משאבים לפי התפוקה שנקבעה, כי השימוש הכולל ב-5,000,000 טוקנים חורג ממגבלת 3,362,500 הטוקנים בחלון של 5 שניות. לעומת זאת, בקשה שמשתמשת ב-1,000,000 טוקנים לשנייה יכולה לעבור עיבוד כהקצאת משאבים לפי התפוקה שנקבעה, אם השימוש הממוצע בחלון של 5 שניות לא עולה על 672,500 טוקנים לשנייה.
שליטה בחריגות או עקיפה של הקצאת משאבים לפי התפוקה שנקבעה
אפשר להשתמש ב-API כדי לשלוט על חריגות כשחורגים מהתפוקה שנרכשה, או כדי לעקוף את הקצאת משאבים לפי התפוקה שנקבעה על בסיס כל בקשה.
קוראים את כל האפשרויות כדי להבין מה צריך לעשות כדי להתאים את המדיניות לתרחיש השימוש.
התנהגות ברירת מחדל
אם בקשה חורגת ממכסת הקצאת המשאבים לפי התפוקה שנקבעה שנותרה, כברירת מחדל המערכת מעבדת את הבקשה כבקשה על פי דרישה ומחייבת עליה לפי תעריף התשלום לפי שימוש. במצב כזה, התנועה מופיעה כגלישה בלוחות הבקרה של המעקב. למידע נוסף על מעקב אחר השימוש בהקצאת משאבים לפי התפוקה שנקבעה, ראו מעקב אחר הקצאת משאבים לפי התפוקה שנקבעה.
אחרי שההזמנה של הקצאת משאבים לפי התפוקה שנקבעה פעילה, מתבצעת אוטומטית פעולת ברירת מחדל. אתם לא צריכים לשנות את הקוד כדי להתחיל להשתמש בהזמנה, כל עוד אתם משתמשים בה באזור שהוקצה.
שימוש רק בהקצאת משאבים לפי התפוקה שנקבעה
אם אתם מנהלים את העלויות על ידי הימנעות מחיובים לפי דרישה, השתמשו רק ב-הקצאת משאבים לפי התפוקה שנקבעה. בקשות שחורגות מהסכום של הקצאת משאבים לפי התפוקה שנקבעה מחזירות שגיאה 429.
כששולחים בקשות ל-API, מגדירים את כותרת ה-HTTP X-Vertex-AI-LLM-Request-Type ל-dedicated.
שימוש רק בתשלום לפי שימוש
השימוש הזה נקרא גם שימוש על פי דרישה. הבקשות עוקפות את ההזמנה של הקצאת משאבים לפי התפוקה שנקבעה ונשלחות ישירות לשיטת התשלום לפי שימוש. זה יכול להיות שימושי לניסויים או לאפליקציות שנמצאות בפיתוח.
כששולחים בקשות ל-API, מגדירים את כותרת ה-HTTP X-Vertex-AI-LLM-Request-Type לערך shared.
דוגמה
Python
התקנה
pip install --upgrade google-genai
מידע נוסף מופיע ב מאמרי העזרה בנושא SDK.
מגדירים משתני סביבה כדי להשתמש ב-Gen AI SDK עם Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
מידע נוסף מופיע ב מאמרי העזרה בנושא SDK.
מגדירים משתני סביבה כדי להשתמש ב-Gen AI SDK עם Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
התקנה
npm install @google/genai
מידע נוסף מופיע ב מאמרי העזרה בנושא SDK.
מגדירים משתני סביבה כדי להשתמש ב-Gen AI SDK עם Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
כך מתקינים או מעדכנים את Java.
מידע נוסף מופיע ב מאמרי העזרה בנושא SDK.
מגדירים משתני סביבה כדי להשתמש ב-Gen AI SDK עם Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
אחרי הגדרת הסביבה, אפשר להשתמש ב-REST כדי לבדוק הנחיית טקסט. בדוגמה הבאה נשלחת בקשה לנקודת הקצה של מודל בעל התוכן הדיגיטלי.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
שימוש בהקצאת משאבים לפי התפוקה שנקבעה עם מפתח API
אם רכשתם הקצאת משאבים לפי התפוקה שנקבעה לפרויקט, למודל ולמיקום ספציפיים של Google, ואתם רוצים להשתמש בה כדי לשלוח בקשה עם מפתח API, אתם צריכים לכלול בבקשה את מזהה הפרויקט, המודל, המיקום ומפתח ה-API כפרמטרים.
Google Cloud כאן מוסבר איך ליצור מפתח API שמשויך לחשבון שירות Google Cloud . מידע על שליחת בקשות ל-Gemini API באמצעות מפתח API מופיע במאמר מדריך למתחילים של Gemini API ב-Vertex AI.
לדוגמה, הדוגמה הבאה מציגה איך שולחים בקשה עם מפתח API בזמן השימוש ב-הקצאת משאבים לפי התפוקה שנקבעה:
REST
אחרי הגדרת הסביבה, אפשר להשתמש ב-REST כדי לבדוק הנחיית טקסט. בדוגמה הבאה נשלחת בקשה לנקודת הקצה של מודל בעל התוכן הדיגיטלי.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
מעקב אחרי הקצאת משאבים לפי התפוקה שנקבעה
אתם יכולים לעקוב בעצמכם אחרי השימוש בנפח התפוקה שהוקצה באמצעות קבוצה של מדדים שנמדדים בסוג המשאב aiplatform.googleapis.com/PublisherModel.
התכונה 'הקצאת משאבים לפי התפוקה שנקבעה' זמינה ב-Public Preview.
מידות
אפשר לסנן לפי מדדים באמצעות המאפיינים הבאים:
| מאפיין | ערכים |
|---|---|
type |
inputoutput |
request_type |
|
קידומת הנתיב
קידומת הנתיב של מדד היא aiplatform.googleapis.com/publisher/online_serving.
לדוגמה, הנתיב המלא של המדד /consumed_throughput הוא aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
מדדים
המדדים הבאים של Cloud Monitoring זמינים במשאב aiplatform.googleapis.com/PublisherModel עבור מודלים של Gemini. אפשר להשתמש ב-dedicated סוגי הבקשות כדי לסנן את השימוש בנפח התפוקה שהוקצה.
| מדד | השם המוצג | תיאור |
|---|---|---|
/dedicated_gsu_limit |
Limit (GSU) | מגבלה ייעודית ב-GSU. השתמש במדד זה כדי להבין את המכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה ב-GSU. |
/tokens |
טוקנים | התפלגות של מספר הטוקנים של הקלט והפלט. |
/token_count |
מספר הטוקנים | ספירת הטוקנים המצטברת של הקלט והפלט. |
/consumed_token_throughput |
קצב העברת נתונים של אסימונים | השימוש ברוחב הפס, שכולל את קצב השחיקה של הטוקנים ומשלב התאמה של המכסה. מידע נוסף זמין במאמר בנושא בדיקת מכסת הקצאת משאבים לפי התפוקה שנקבעה. המדד הזה עוזר להבין איך נעשה שימוש במכסת הקצאת משאבים לפי התפוקה שנקבעה. |
/dedicated_token_limit |
מגבלה (אסימונים לשנייה) | מגבלה ייעודית באסימונים לשנייה. השתמש במדד זה כדי להבין את המכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה עבור מודלים מבוססי-טוקנים. |
/characters |
תווים | התפלגות של מספר התווים בקלט ובפלט. |
/character_count |
מספר התווים | מספר התווים המצטבר של הקלט והפלט. |
/consumed_throughput |
קצב העברת נתונים של תווים | השימוש בתפוקה, שכולל את קצב הירידה של המכסה בתווים ומשלב את התאמת המכסה בבדיקת המכסה של הקצאת משאבים לפי התפוקה שנקבעה. בעזרת המדד הזה אפשר להבין איך נעשה שימוש במכסת הקצאת המשאבים לפי התפוקה שנקבעה. במודלים מבוססי-אסימונים, המדד הזה שווה לנתון התפוקה שנמדד באסימונים כפול 4. |
/dedicated_character_limit |
מגבלה (תווים לשנייה) | מגבלה ייעודית בתווים לשנייה. אפשר להשתמש במדד הזה כדי להבין מה המכסה המקסימלית של הקצאת משאבים לפי התפוקה שנקבעה במודלים מבוססי-תווים. |
/model_invocation_count |
מספר ההפעלות של המודל | מספר ההפעלות של המודל (בקשות לחיזוי). |
/model_invocation_latencies |
זמני האחזור של הפעלת המודל | זמני האחזור של הפעלת המודל (זמני האחזור של החיזוי). |
/first_token_latencies |
זמני האחזור של הטוקן הראשון | משך הזמן מרגע קבלת הבקשה ועד להחזרת הטוקן הראשון. |
למודלים של Anthropic יש גם מסנן ל-Provisioned Throughput, אבל רק ל-tokens ול-token_count.
מרכזי שליטה
לוחות הבקרה של ניטור ברירת המחדל של הקצאת משאבים לפי התפוקה שנקבעה מספקים מדדים שמאפשרים להבין טוב יותר את השימוש ואת הניצול של הקצאת משאבים לפי התפוקה שנקבעה. כדי לגשת למרכזי הבקרה:
במסוף Google Cloud , עוברים לדף הקצאת משאבים לפי התפוקה שנקבעה.
כדי לראות את ניצול הקצאת משאבים לפי התפוקה שנקבעה של כל מודל בהזמנות, בוחרים בכרטיסייה Utilization summary.
בטבלה Provisioned Throughput utilization by model (ניצול של הקצאת משאבים לפי התפוקה שנקבעה לפי מודל), אפשר לראות את הנתונים הבאים עבור טווח התאריכים שנבחר:
המספר הכולל של יחידות GSU שהיו לכם.
שיא השימוש בתפוקה במונחים של יחידות GSU.
השימוש הממוצע ב-GSU.
מספר הפעמים שהגעתם למגבלת התפוקה שהוקצתה.
בוחרים מודל מהטבלה ניצול הקצאת משאבים לפי התפוקה שנקבעה לפי מודל כדי לראות מדדים נוספים שספציפיים למודל שנבחר.
איך מפרשים מרכזי בקרה למעקב
הקצאת משאבים לפי התפוקה שנקבעה בודקת את המכסה הזמינה בזמן אמת ברמת המילישנייה עבור בקשות שמוגשות, אבל משווה את הנתונים האלה לתקופה של אכיפת מכסה מתמשכת, על סמך השעה הפנימית של Vertex AI. ההשוואה הזו לא תלויה בזמן שבו נשלחות הבקשות. במרכזי הבקרה של הניטור מדווחים על מדדי שימוש אחרי שמתבצעת התאמה של המכסה. עם זאת, המדדים האלה מצטברים כדי לספק ממוצעים לתקופות ההשוואה בלוח הבקרה, על סמך טווח התאריכים שנבחר. רמת הפירוט הנמוכה ביותר שמרכזי הבקרה של המעקב תומכים בה היא ברמת הדקה. בנוסף, השעה שמוצגת בלוחות הבקרה של המעקב שונה מהשעה שמוצגת ב-Vertex AI.
ההבדלים בתזמון יכולים לגרום מדי פעם לאי-התאמות בין הנתונים בלוחות הבקרה של המעקב לבין הביצועים בזמן אמת. הסיבות האפשריות לכך:
המכסה נאכפת בזמן אמת, אבל בתרשימי המעקב הנתונים מצטברים לתקופות של דקה אחת או יותר של התאמה ממוצעת ללוח הבקרה, בהתאם לטווח הזמן שצוין בלוחות הבקרה של המעקב.
מערכות השעונים של Vertex AI ושל לוחות הבקרה של המעקב שונות.
במהלך שנייה אחת, אם פרץ תנועה חורג מהמכסה של הקצאת משאבים לפי התפוקה שנקבעה על סמך חלון האכיפה, הבקשה כולה מעובדת כתנועה עודפת. עם זאת, יכול להיות ששיעור הניצול הכולל של הקצאת משאבים לפי התפוקה שנקבעה ייראה נמוך, כי הנתונים של המעקב באותה שנייה מחושבים כממוצע בתוך תקופת היישור של דקה אחת, והממוצע של שיעור הניצול לאורך כל תקופת היישור לא יעלה על 100%. אם אתם רואים תנועה שחורגת מהמכסה, זה מאשר שהמכסה שלכם של הקצאת משאבים לפי התפוקה שנקבעה נוצלה במלואה במהלך התקופה שבה המכסה נאכפת, כשבוצעו הבקשות הספציפיות האלה. הנתון הזה לא תלוי בממוצע השימוש שמוצג בלוחות הבקרה של המעקב.
דוגמה לפער אפשרי בנתוני המעקב
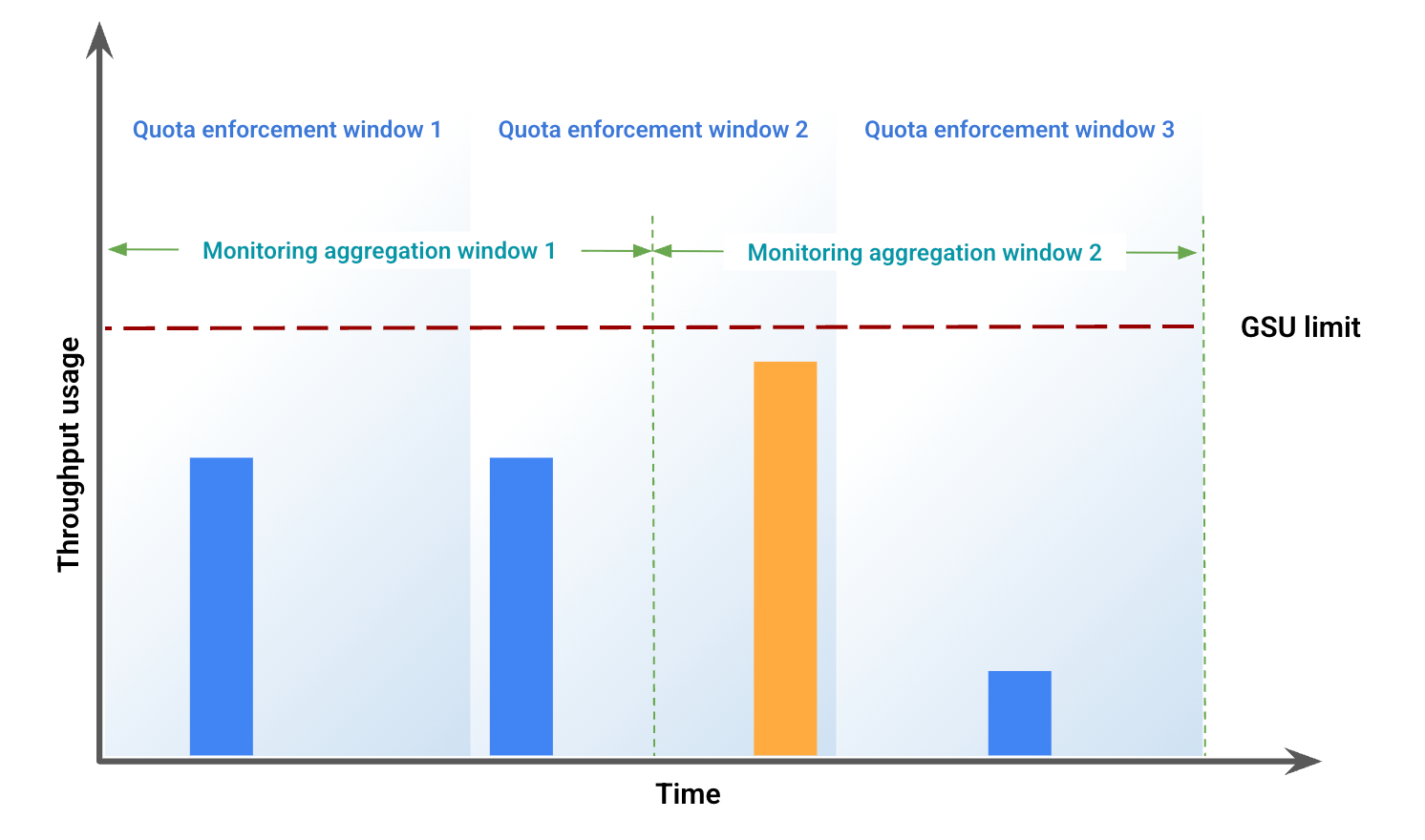
בדוגמה הזו אפשר לראות חלק מההבדלים שנובעים מחוסר התאמה בין חלונות. איור 1 מייצג את השימוש ברוחב פס במהלך תקופת זמן ספציפית. באיור הזה:
העמודות הכחולות מייצגות את התנועה שהתקבלה כהקצאת משאבים לפי התפוקה שנקבעה.
הפס הכתום מייצג תעבורה שגורמת לחריגה ממגבלת השימוש ב-GSU ומעובדת כעודף שימוש.
בהתבסס על השימוש בתפוקה, איור 2 מייצג אי התאמות חזותיות אפשריות, עקב אי התאמה בעיבוד החלק הנצפה בלבד. באיור הזה:
הקו הכחול מייצג את התנועה של הקצאת משאבים לפי התפוקה שנקבעה.
הקו הכתום מייצג תנועה שנובעת מהשפעה של מודעות בערוצים סמוכים.
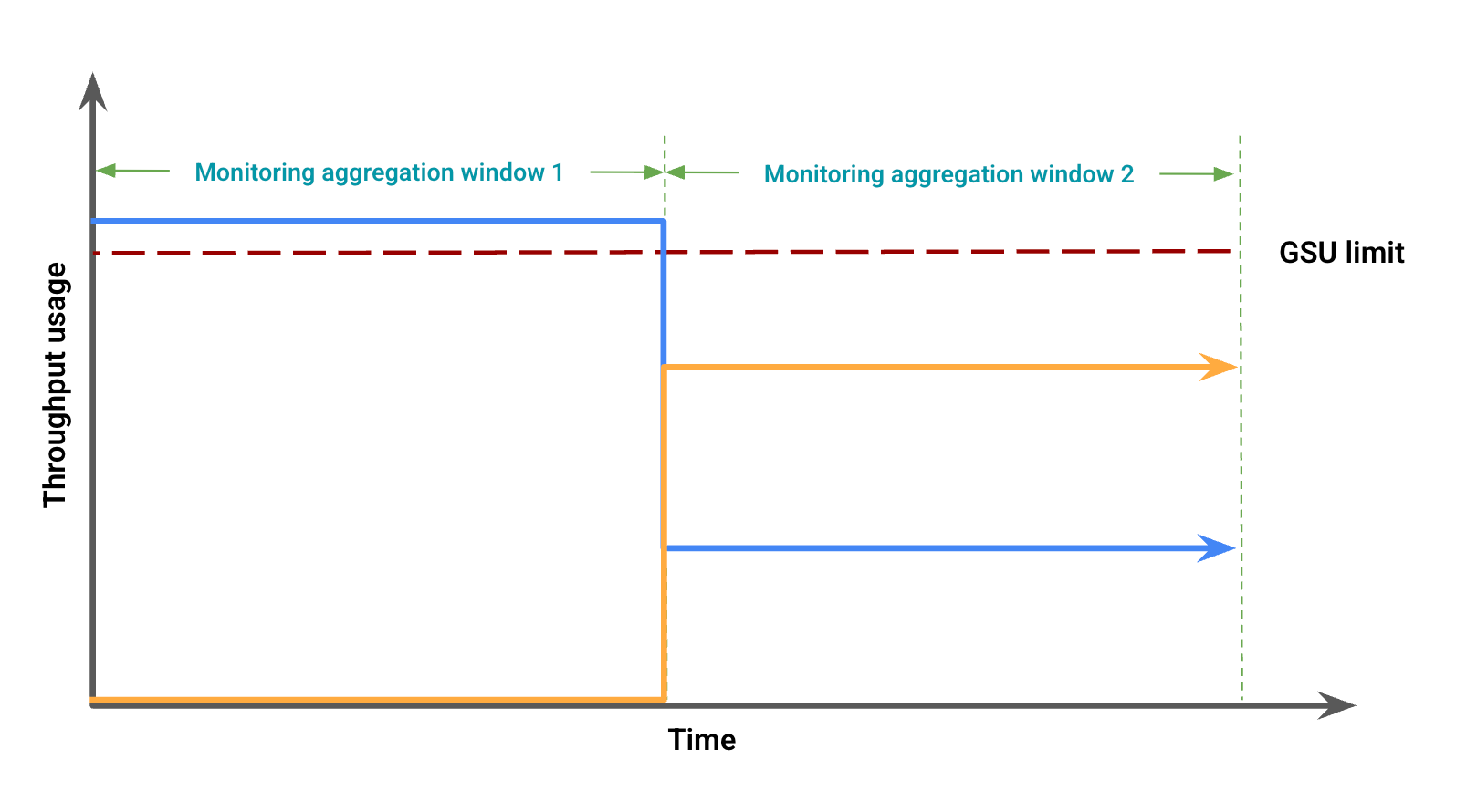
במקרה כזה, יכול להיות שבנתוני המעקב יופיע שימוש בהקצאת משאבים לפי התפוקה שנקבעה ללא חריגה במסגרת זמן של צבירת נתונים למעקב, ובמקביל יופיע שימוש בהקצאת משאבים לפי התפוקה שנקבעה מתחת למכסת GSU שחורג במסגרת זמן אחרת של צבירת נתונים למעקב.
פתרון בעיות בלוחות בקרה למעקב
כדי לפתור בעיות של הצפה לא צפויה בלוחות הבקרה או שגיאות 429, אפשר לבצע את השלבים הבאים:
הגדלת התצוגה: מגדירים את טווח הזמן בלוח הבקרה ל-12 שעות או פחות כדי לקבל את תקופת ההתאמה המפורטת ביותר של דקה אחת. טווחים גדולים של זמן מחליקים את העליות החדות שגורמות להגבלת קצב הבקשות, ומגדילים את הממוצעים של תקופת ההתאמה.
בדיקת התנועה הכוללת: בלוחות הבקרה הספציפיים למודל, התנועה הייעודית והתנועה העודפת מוצגות כשני קווים נפרדים, מה שעלול להוביל למסקנה שגויה שלפיה מכסת הקצאת משאבים לפי התפוקה שנקבעה לא מנוצלת במלואה ויש תנועה עודפת לפני הזמן. אם נפח התנועה חורג מהמכסה הזמינה, כל הבקשה מעובדת כחריגה. כדי להוסיף ללוח הבקרה שאילתה באמצעות Metrics Explorer ולכלול את קצב העברת הטוקנים של המודל והאזור הספציפיים, אפשר להשתמש בהדמיה מועילה נוספת. כדי לראות את סך התעבורה בכל סוגי התעבורה (ייעודית, עודפת ומשותפת), אל תכללו צבירות או מסננים נוספים.
מעקב אחרי מודלים של מדיה גנרטיבית
מעקב אחר הקצאת משאבים לפי התפוקה שנקבעה לא זמין במודלים של Veo 3 ו-Imagen.
שליחת התראות
אחרי שמפעילים את ההתראות, מגדירים התראות ברירת מחדל כדי לעזור לכם לנהל את השימוש בתעבורה.
הפעלת התראות
כדי להפעיל התראות במרכז הבקרה:
במסוף Google Cloud , עוברים לדף הקצאת משאבים לפי התפוקה שנקבעה.
כדי לראות את ניצול הקצאת משאבים לפי התפוקה שנקבעה של כל מודל בהזמנות, בוחרים בכרטיסייה Utilization summary.
בוחרים באפשרות התראות מומלצות. יוצגו ההתראות הבאות:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
כדאי לבדוק את ההתראות שיעזרו לכם לנהל את התנועה.
הצגת פרטים נוספים על ההתראה
כדי לראות מידע נוסף על התראות:
עוברים לדף שילובים.
מזינים vertex בשדה Filter (סינון) ומקישים על Enter. מופיע Google Vertex AI.
כדי לראות מידע נוסף, לוחצים על הצגת פרטים. יוצג החלונית פרטים על Google Vertex AI.
בוחרים בכרטיסייה התראות ואז בוחרים תבנית של מדיניות התראות.
המאמרים הבאים
- פתרון בעיות שקשורות לקוד השגיאה
429.